Esta es una publicación invitada escrita por Axfood AB.
En esta publicación, compartimos cómo Axfood, un gran minorista de alimentos sueco, mejoró las operaciones y la escalabilidad de sus operaciones existentes de inteligencia artificial (IA) y aprendizaje automático (ML) mediante la creación de prototipos en estrecha colaboración con expertos de AWS y el uso de Amazon SageMaker.
Axefood es el segundo minorista de alimentación más grande de Suecia, con más de 13,000 empleados y más de 300 tiendas. Axfood tiene una estructura con múltiples equipos de ciencia de datos descentralizados con diferentes áreas de responsabilidad. Junto con un equipo de plataforma de datos central, los equipos de ciencia de datos aportan innovación y transformación digital a la organización a través de soluciones de IA y ML. Axfood ha estado utilizando Amazon SageMaker para cultivar sus datos mediante ML y ha tenido modelos en producción durante muchos años. Últimamente, el nivel de sofisticación y la gran cantidad de modelos en producción está aumentando exponencialmente. Sin embargo, aunque el ritmo de innovación es alto, los diferentes equipos habían desarrollado sus propias formas de trabajar y estaban buscando nuevas mejores prácticas de MLOps.
Nuestro desafío
Para seguir siendo competitivo en términos de servicios en la nube e IA/ML, Axfood eligió asociarse con AWS y ha estado colaborando con ellos durante muchos años.
Durante una de nuestras sesiones recurrentes de lluvia de ideas con AWS, estábamos discutiendo cómo colaborar mejor entre equipos para aumentar el ritmo de innovación y la eficiencia de los profesionales de la ciencia de datos y el aprendizaje automático. Decidimos hacer un esfuerzo conjunto para construir un prototipo sobre las mejores prácticas para MLOps. El objetivo del prototipo era crear una plantilla de modelo para que todos los equipos de ciencia de datos crearan modelos de ML escalables y eficientes, la base de una nueva generación de plataformas de IA y ML para Axfood. La plantilla debe unir y combinar las mejores prácticas de los expertos de AWS ML y los modelos de mejores prácticas específicos de la empresa: lo mejor de ambos mundos.
Decidimos construir un prototipo a partir de uno de los modelos de ML más desarrollados actualmente dentro de Axfood: pronosticar las ventas en las tiendas. Más concretamente, la previsión de frutas y hortalizas de las próximas campañas para las tiendas de alimentación. Los pronósticos diarios precisos respaldan el proceso de pedidos de las tiendas, lo que aumenta la sostenibilidad al minimizar el desperdicio de alimentos como resultado de optimizar las ventas al predecir con precisión los niveles de existencias necesarios en las tiendas. Este fue el lugar perfecto para comenzar con nuestro prototipo: Axfood no solo obtendría una nueva plataforma de IA/ML, sino que también tendríamos la oportunidad de comparar nuestras capacidades de ML y aprender de los principales expertos de AWS.
Nuestra solución: una nueva plantilla de aprendizaje automático en Amazon SageMaker Studio
Crear un proceso de aprendizaje automático completo diseñado para un caso de negocio real puede ser un desafío. En este caso, estamos desarrollando un modelo de pronóstico, por lo que hay dos pasos principales a completar:
- Entrene el modelo para hacer predicciones utilizando datos históricos.
- Aplicar el modelo entrenado para hacer predicciones de eventos futuros.
En el caso de Axfood, ya se configuró un canal que funcionaba bien para este propósito utilizando portátiles SageMaker y orquestado por la plataforma de gestión de flujo de trabajo de terceros Airflow. Sin embargo, existen muchos beneficios claros al modernizar nuestra plataforma ML y pasar a Estudio Amazon SageMaker y Canalizaciones de Amazon SageMaker. Pasar a SageMaker Studio proporciona muchas funciones predefinidas listas para usar:
- Monitoreo de la calidad de los datos y del modelo, así como de la explicabilidad del modelo.
- Herramientas integradas de entorno de desarrollo integrado (IDE), como la depuración
- Monitoreo de costo/rendimiento
- Marco de aceptación del modelo
- registro modelo
Sin embargo, el incentivo más importante para Axfood es la capacidad de crear plantillas de proyectos personalizadas utilizando Proyectos de Amazon SageMaker para ser utilizado como modelo para todos los equipos de ciencia de datos y profesionales de ML. El equipo de Axfood ya tenía un nivel sólido y maduro de modelado de ML, por lo que el enfoque principal fue construir la nueva arquitectura.
Resumen de la solución
El nuevo marco de aprendizaje automático propuesto por Axfood se estructura en torno a dos canales principales: el canal de construcción del modelo y el canal de inferencia por lotes:
- Estas canalizaciones están versionadas en dos repositorios Git separados: un repositorio de compilación y un repositorio de implementación (inferencia). Juntos, forman un sistema sólido para pronosticar frutas y verduras.
- Las canalizaciones se empaquetan en una plantilla de proyecto personalizada utilizando SageMaker Projects en integración con un repositorio Git de terceros (Bitbucket) y canalizaciones de Bitbucket para componentes de integración e implementación continua (CI/CD).
- La plantilla del proyecto SageMaker incluye el código inicial correspondiente a cada paso de las canalizaciones de compilación e implementación (analizamos estos pasos con más detalle más adelante en esta publicación), así como la definición de la canalización: la receta sobre cómo se deben ejecutar los pasos.
- La automatización de la creación de nuevos proyectos basados en la plantilla se optimiza a través de Catálogo de servicios de AWS, donde se crea una cartera, que sirve como abstracción para múltiples productos.
- Cada producto se traduce en un Formación en la nube de AWS plantilla, que se implementa cuando un científico de datos crea un nuevo proyecto de SageMaker con nuestro modelo MLOps como base. Esto activa un AWS Lambda función que crea un proyecto de Bitbucket con dos repositorios (construcción de modelo e implementación de modelo) que contienen el código semilla.
El siguiente diagrama ilustra la arquitectura de la solución. El flujo de trabajo A representa el intrincado flujo entre los dos canales de modelos: construcción e inferencia. El flujo de trabajo B muestra el flujo para crear un nuevo proyecto de ML.

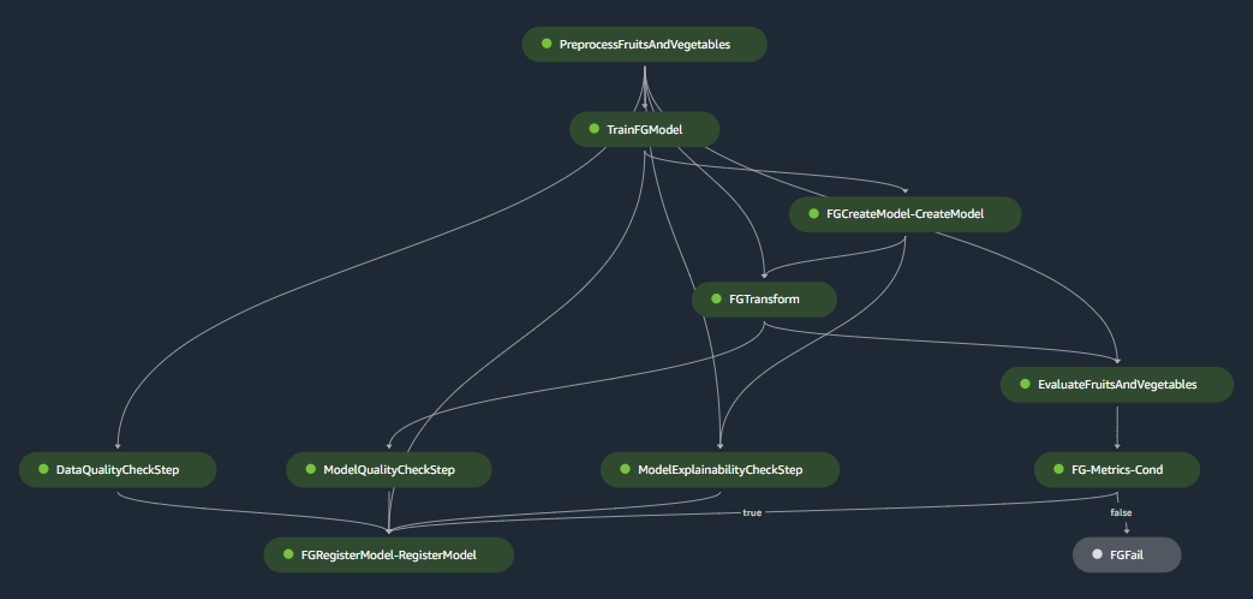
Canalización de construcción de modelos
La canalización de construcción del modelo organiza el ciclo de vida del modelo, comenzando desde el preprocesamiento, pasando por la capacitación y culminando con su registro en el registro del modelo:
- preprocesamiento – Aquí, el SageMaker
ScriptProcessorLa clase se emplea para la ingeniería de características, lo que da como resultado el conjunto de datos en el que se entrenará el modelo. - Entrenamiento y transformación por lotes – Los contenedores de inferencia y entrenamiento personalizados de SageMaker se aprovechan para entrenar el modelo con datos históricos y crear predicciones sobre los datos de evaluación utilizando un Estimador y un Transformador de SageMaker para las tareas respectivas.
- Evaluación – El modelo entrenado se evalúa comparando las predicciones generadas en los datos de evaluación con la verdad fundamental utilizando
ScriptProcessor. - Trabajos de referencia – La canalización crea líneas de base basadas en estadísticas en los datos de entrada. Estos son esenciales para monitorear los datos y la calidad del modelo, así como las atribuciones de características.
- registro modelo – El modelo entrenado se registra para uso futuro. El modelo será aprobado por científicos de datos designados para implementarlo y utilizarlo en producción.
Para entornos de producción, la ingesta de datos y los mecanismos de activación se gestionan a través de una orquestación de Airflow principal. Mientras tanto, durante el desarrollo, la canalización se activa cada vez que se introduce una nueva confirmación en el repositorio de Bitbucket de compilación del modelo. La siguiente figura visualiza el proceso de construcción del modelo.
Canalización de inferencia por lotes
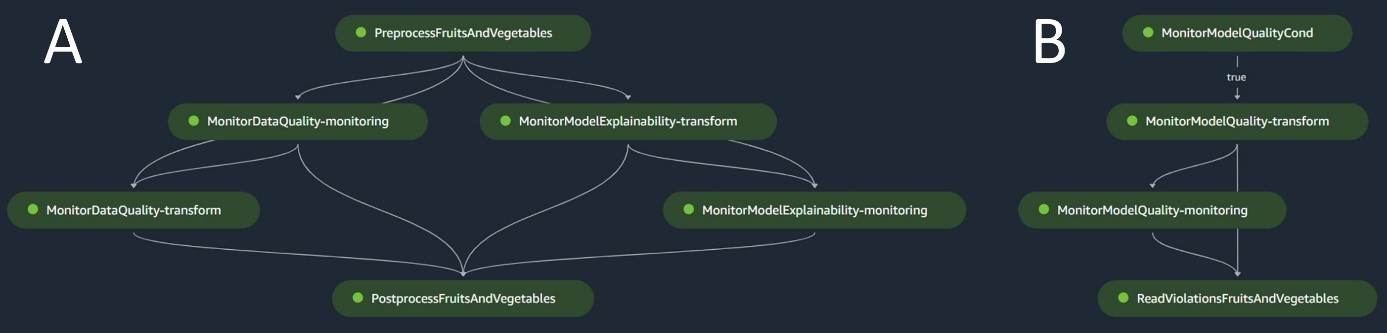
La canalización de inferencia por lotes maneja la fase de inferencia, que consta de los siguientes pasos:
- preprocesamiento – Los datos se preprocesan utilizando
ScriptProcessor. - Transformación por lotes – El modelo utiliza el contenedor de inferencia personalizado con un SageMaker Transformer y genera predicciones dados los datos preprocesados de entrada. El modelo utilizado es el último modelo entrenado aprobado en el registro de modelos.
- Postprocesamiento – Las predicciones se someten a una serie de pasos de posprocesamiento utilizando
ScriptProcessor. - Monitoreo – La vigilancia continua completa las comprobaciones de desviaciones relacionadas con la calidad de los datos, la calidad del modelo y la atribución de características.
Si surgen discrepancias, una lógica empresarial dentro del script de posprocesamiento evalúa si es necesario volver a entrenar el modelo. Está previsto que el oleoducto funcione a intervalos regulares.
El siguiente diagrama ilustra el proceso de inferencia por lotes. El flujo de trabajo A corresponde al preprocesamiento, la calidad de los datos y las comprobaciones de deriva de atribución de características, la inferencia y el posprocesamiento. El flujo de trabajo B corresponde a las comprobaciones de desviación de la calidad del modelo. Estos procesos están divididos porque la verificación de la deriva de la calidad del modelo solo se ejecutará si hay nuevos datos reales disponibles.
Monitor modelo SageMaker
Con Monitor de modelo de Amazon SageMaker Integrados, los ductos se benefician del monitoreo en tiempo real de lo siguiente:
- Calidad de datos – Supervisa cualquier desviación o inconsistencia en los datos.
- Calidad del modelo – Vigila cualquier fluctuación en el rendimiento del modelo.
- Atribución de funciones – Comprueba la desviación en las atribuciones de funciones.
El seguimiento de la calidad del modelo requiere acceso a datos reales sobre el terreno. Aunque obtener la verdad sobre el terreno puede ser un desafío a veces, el uso de datos o monitoreo de deriva de atribución de características sirve como un proxy competente para la calidad del modelo.
En concreto, en el caso de una desviación de la calidad de los datos, el sistema vigila lo siguiente:
- Deriva del concepto – Esto se refiere a cambios en la correlación entre entrada y salida, lo que requiere verdad sobre el terreno.
- Desplazamiento covariable – Aquí, el énfasis está en las alteraciones en la distribución de las variables de entrada independientes.
La funcionalidad de deriva de datos de SageMaker Model Monitor captura y examina meticulosamente los datos de entrada, implementando reglas y comprobaciones estadísticas. Se generan alertas cada vez que se detectan anomalías.
Paralelamente al uso de comprobaciones de desviación de la calidad de los datos como indicador para monitorear la degradación del modelo, el sistema también monitorea la desviación de la atribución de características utilizando la puntuación de ganancia acumulativa descontada normalizada (NDCG). Esta puntuación es sensible tanto a los cambios en el orden de clasificación de la atribución de funciones como a las puntuaciones de atribución brutas de las funciones. Al monitorear la deriva en la atribución de características individuales y su importancia relativa, es sencillo detectar la degradación en la calidad del modelo.
Explicabilidad del modelo
La explicabilidad del modelo es una parte fundamental de las implementaciones de ML, porque garantiza la transparencia en las predicciones. Para una comprensión detallada, utilizamos Amazon SageMaker aclarar.
Ofrece explicaciones de modelos tanto globales como locales a través de una técnica de atribución de características independiente del modelo basada en el concepto de valor de Shapley. Esto se utiliza para decodificar por qué se hizo una predicción particular durante la inferencia. Estas explicaciones, que son intrínsecamente contrastantes, pueden variar según diferentes puntos de referencia. SageMaker Clarify ayuda a determinar esta línea de base utilizando K-medias o K-prototipos en el conjunto de datos de entrada, que luego se agrega a la canalización de construcción del modelo. Esta funcionalidad nos permite crear aplicaciones de IA generativa en el futuro para una mayor comprensión de cómo funciona el modelo.
Industrialización: del prototipo a la producción
El proyecto MLOps incluye un alto grado de automatización y puede servir como modelo para casos de uso similares:
- La infraestructura se puede reutilizar por completo, mientras que el código semilla se puede adaptar para cada tarea, y la mayoría de los cambios se limitan a la definición de la canalización y la lógica empresarial para el preprocesamiento, la capacitación, la inferencia y el posprocesamiento.
- Los scripts de entrenamiento e inferencia se alojan mediante contenedores personalizados de SageMaker, por lo que se puede acomodar una variedad de modelos sin cambios en los datos y en los pasos de monitoreo o explicabilidad del modelo, siempre que los datos estén en formato tabular.
Después de terminar el trabajo en el prototipo, pasamos a cómo deberíamos usarlo en producción. Para ello, sentimos la necesidad de realizar algunos ajustes adicionales a la plantilla MLOps:
- El código inicial original utilizado en el prototipo de la plantilla incluía pasos de preprocesamiento y posprocesamiento ejecutados antes y después de los pasos principales de ML (entrenamiento e inferencia). Sin embargo, al ampliar para utilizar la plantilla en múltiples casos de uso en producción, los pasos de preprocesamiento y posprocesamiento integrados pueden conducir a una menor generalidad y reproducción del código.
- Para mejorar la generalidad y minimizar el código repetitivo, decidimos reducir aún más las canalizaciones. En lugar de ejecutar los pasos de preprocesamiento y posprocesamiento como parte de la canalización de ML, los ejecutamos como parte de la orquestación principal de Airflow antes y después de activar la canalización de ML.
- De esta manera, las tareas de procesamiento específicas de casos de uso se abstraen de la plantilla y lo que queda es una canalización central de ML que realiza tareas que son generales en múltiples casos de uso con una mínima repetición de código. Los parámetros que difieren entre los casos de uso se proporcionan como entrada a la canalización de ML desde la orquestación principal de Airflow.
El resultado: un enfoque rápido y eficiente para la creación e implementación de modelos
El prototipo en colaboración con AWS ha dado como resultado una plantilla MLOps que sigue las mejores prácticas actuales y que ahora está disponible para que la utilicen todos los equipos de ciencia de datos de Axfood. Al crear un nuevo proyecto de SageMaker dentro de SageMaker Studio, los científicos de datos pueden comenzar con nuevos proyectos de ML de forma rápida y realizar una transición fluida a producción, lo que permite una gestión del tiempo más eficiente. Esto es posible gracias a la automatización de tareas MLOps tediosas y repetitivas como parte de la plantilla.
Además, se han agregado varias funcionalidades nuevas de forma automatizada a nuestra configuración de ML. Estas ganancias incluyen:
- Monitoreo de modelos – Podemos realizar comprobaciones de deriva para la calidad del modelo y de los datos, así como para la explicabilidad del modelo.
- Modelo y linaje de datos. – Ahora es posible rastrear exactamente qué datos se han utilizado para qué modelo
- registro modelo – Esto nos ayuda a catalogar modelos para producción y gestionar versiones de modelos.
Conclusión
En esta publicación, analizamos cómo Axfood mejoró las operaciones y la escalabilidad de nuestras operaciones de IA y ML existentes en colaboración con expertos de AWS y mediante el uso de SageMaker y sus productos relacionados.
Estas mejoras ayudarán a los equipos de ciencia de datos de Axfood a crear flujos de trabajo de ML de una manera más estandarizada y simplificarán enormemente el análisis y el seguimiento de los modelos en producción, garantizando la calidad de los modelos de ML creados y mantenidos por nuestros equipos.
Deje cualquier comentario o pregunta en la sección de comentarios.
Acerca de los autores
 Dr. Björn Blomqvist es el Jefe de Estrategia de IA en Axfood AB. Antes de unirse a Axfood AB, dirigió un equipo de científicos de datos en Dagab, una parte de Axfood, que creó soluciones innovadoras de aprendizaje automático con la misión de proporcionar alimentos buenos y sostenibles a personas de toda Suecia. Nacido y criado en el norte de Suecia, en su tiempo libre Björn se aventura a montañas nevadas y mares abiertos.
Dr. Björn Blomqvist es el Jefe de Estrategia de IA en Axfood AB. Antes de unirse a Axfood AB, dirigió un equipo de científicos de datos en Dagab, una parte de Axfood, que creó soluciones innovadoras de aprendizaje automático con la misión de proporcionar alimentos buenos y sostenibles a personas de toda Suecia. Nacido y criado en el norte de Suecia, en su tiempo libre Björn se aventura a montañas nevadas y mares abiertos.
 Oskar Klang es científico de datos senior en el departamento de análisis de Dagab, donde le gusta trabajar con todo lo relacionado con análisis y aprendizaje automático, por ejemplo, optimizando las operaciones de la cadena de suministro, creando modelos de pronóstico y, más recientemente, aplicaciones GenAI. Está comprometido a construir canales de aprendizaje automático más optimizados, mejorando la eficiencia y la escalabilidad.
Oskar Klang es científico de datos senior en el departamento de análisis de Dagab, donde le gusta trabajar con todo lo relacionado con análisis y aprendizaje automático, por ejemplo, optimizando las operaciones de la cadena de suministro, creando modelos de pronóstico y, más recientemente, aplicaciones GenAI. Está comprometido a construir canales de aprendizaje automático más optimizados, mejorando la eficiencia y la escalabilidad.
 pavel maslov es ingeniero senior de DevOps y ML en el equipo de Plataformas analíticas. Pavel tiene una amplia experiencia en el desarrollo de marcos, infraestructura y herramientas en los dominios de DevOps y ML/AI en la plataforma AWS. Pavel ha sido uno de los actores clave en la construcción de la capacidad fundamental dentro del ML en Axfood.
pavel maslov es ingeniero senior de DevOps y ML en el equipo de Plataformas analíticas. Pavel tiene una amplia experiencia en el desarrollo de marcos, infraestructura y herramientas en los dominios de DevOps y ML/AI en la plataforma AWS. Pavel ha sido uno de los actores clave en la construcción de la capacidad fundamental dentro del ML en Axfood.
 Joaquín Berg es el líder del equipo y propietario del producto de plataformas analíticas, con sede en Estocolmo, Suecia. Lidera un equipo de ingenieros de DevOps/MLOps de plataforma de datos que proporcionan plataformas de datos y aprendizaje automático para los equipos de ciencia de datos. Joakim tiene muchos años de experiencia liderando equipos senior de desarrollo y arquitectura de diferentes industrias.
Joaquín Berg es el líder del equipo y propietario del producto de plataformas analíticas, con sede en Estocolmo, Suecia. Lidera un equipo de ingenieros de DevOps/MLOps de plataforma de datos que proporcionan plataformas de datos y aprendizaje automático para los equipos de ciencia de datos. Joakim tiene muchos años de experiencia liderando equipos senior de desarrollo y arquitectura de diferentes industrias.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

