Imagen del autor
Julia es un lenguaje de propósito general de alto nivel diseñado para cálculos de alto rendimiento. Se está volviendo popular entre la comunidad de datos y los investigadores debido a la sintaxis del lenguaje natural, la ejecución más rápida del código y un sólido ecosistema de aprendizaje automático.
Debido a la popularidad de los cuadernos integrados, los científicos e investigadores de datos ahora ejecutan Python, R, Bash, Scala, Ruby y SQL en el cuaderno Jupyter. Y ahora, aprenderemos a instalar Julia y configurarla para el cuaderno Jupyter. Además, cargaremos un archivo CSV y realizaremos una visualización de datos de series temporales.
Julia se puede usar ejecutando el código en un REPL o ejecutando el archivo `.jl`, pero ejecutar el código en un cuaderno Jupyter nos da más control sobre la experimentación. Puede realizar análisis de datos, entrenar modelos de aprendizaje automático o incluso crear un paquete de Julia usando el cuaderno.
Paso 1: Descargue e instale el paquete
Puede descargar e instalar la versión estable actual de Julia visitando el sitio oficial página web del NDN Collective . La versión estable está disponible para Windows, Linux y macOS.
Me tomó unos minutos descargar e instalar Julia para Windows. Para ejecutar Julia REPL, escriba "Julia” en PowerShell, Terminal o Bash. También puede encontrar el icono de Julia al principio y hacer clic en él para iniciar el REPL.
Paso 2: Instalar IJulia
Para integrar Julia con Jupyter Notebook, debe instalar el ijulia paquete.
En Julia REPL, escriba:
using Pkg
Pkg.add("IJulia")
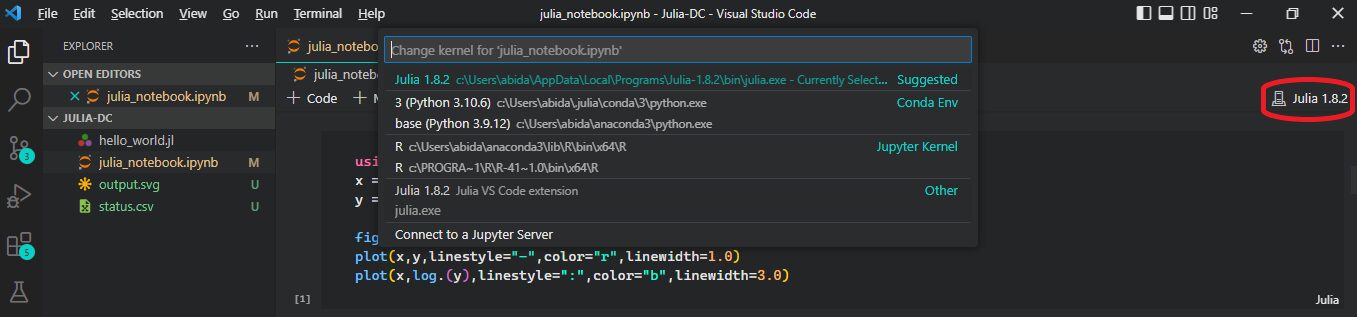
Imagen por autor | Julia REPL
También puede instalar el paquete de Julia escribiendo "]" para ingresar en el menú del paquete. Después de eso, escriba `add Ijulia` para instalar el paquete.

Imagen por autor | Instalando Ijulia
Paso 3: Ejecutar Julia en Jupyter Notebook
Ahora estamos listos para usar Jupyter Notebook. Inicie el cuaderno Jupyter, haga clic en el Nuevo botón y seleccione la Julia ambiente.
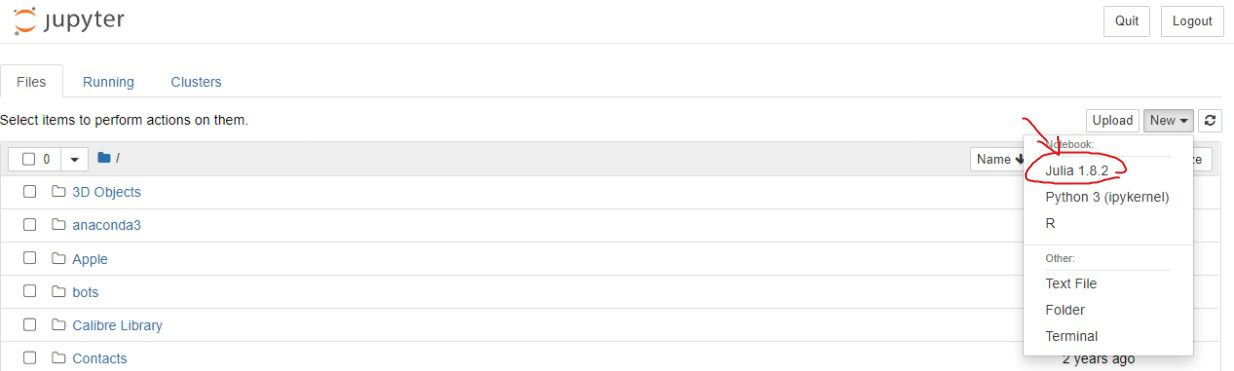
Imagen por Autor | Cuaderno Jupyter
Para VSCode, cree un nuevo archivo de Jupyter Notebook y cambie el Kernel de Python a Julia haciendo clic en el nombre del Kernel como se muestra a continuación.
Ahora tenemos entornos R, Python y Julia. Puede cambiar entre ellos según sus requisitos.
Imagen por autor | Cuaderno VScode Jupyter
Después de instalar Julia, escribamos un código simple para imprimir el texto. Al igual que Python, ejecutó el comando sin problemas.
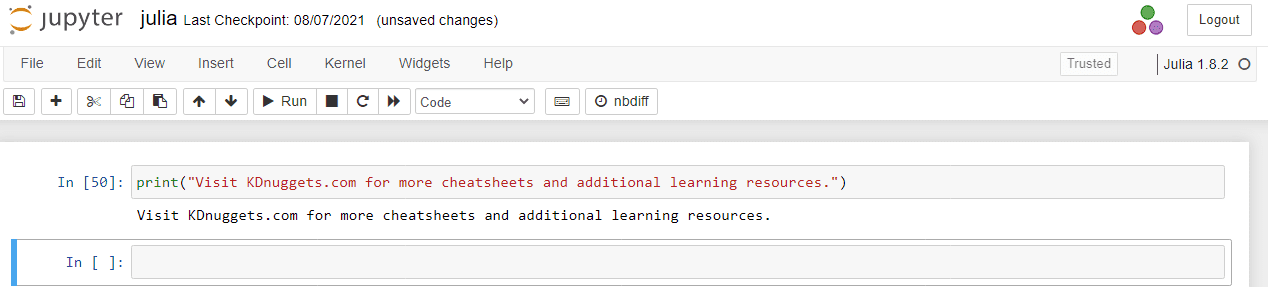
Imagen por autor | Ejecución de código en Jupyter Notebook
print("Visit KDnuggets.com for more cheat sheets and additional learning resources.") >>> Visit KDnuggets.com for more cheat sheets and additional learning resources.
Instalación de paquetes
Puede instalar cualquier paquete de Julia dentro de la celda de Juypter escribiendo `using Pkg` y `Pkg.add( )`.
Instalaremos DataFrame, CSV, Plots, PyPlot y RollingFunctions.
using Pkg Pkg.add("DataFrames")
Pkg.add("CSV")
Pkg.add("Plots")
Pkg.add("PyPlot")
Pkg.add("RollingFunctions")
Leyendo archivo CSV
Para acceder al paquete, debe escribir `usando` y luego escriba todos los nombres de los paquetes separados por comas ",.
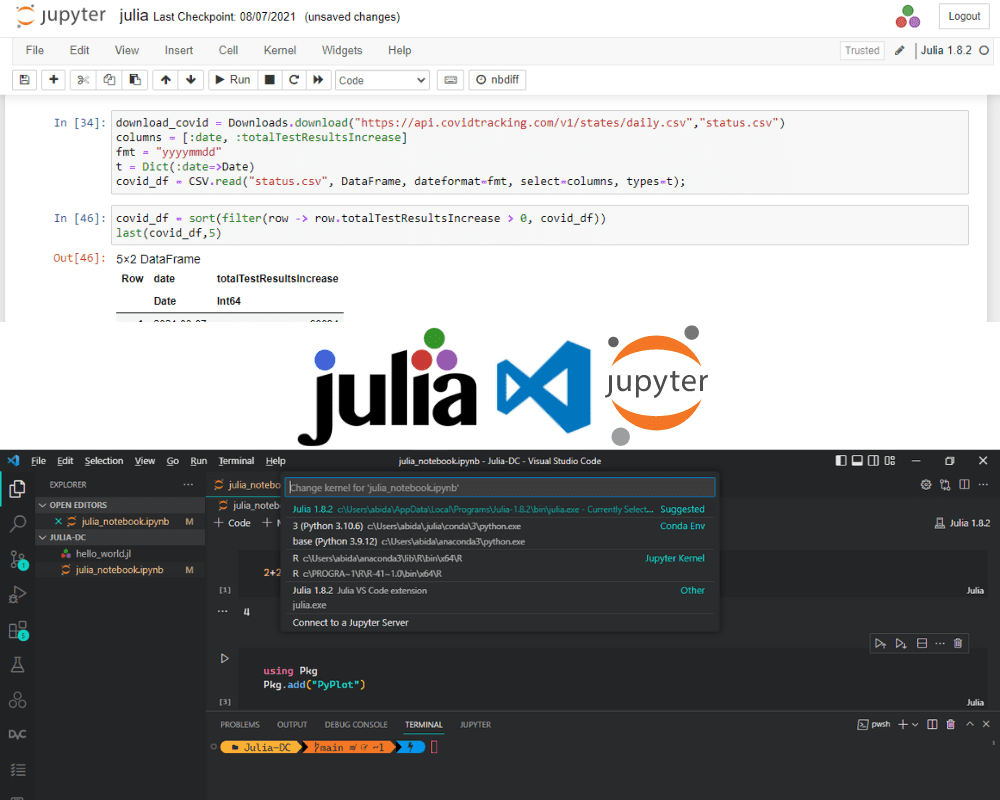
A continuación, vamos a descargar los datos de seguimiento de covid de EE. UU. y guardaremos el archivo CSV como "covid_us.csv".
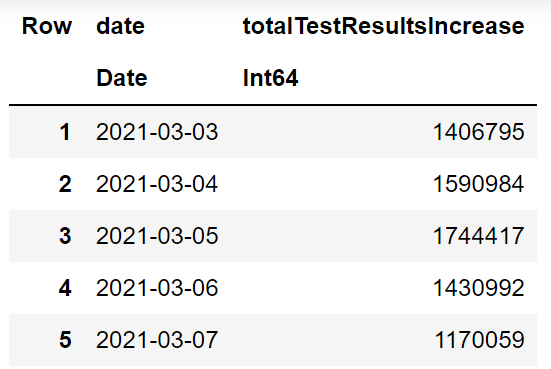
Luego, usaremos `CSV.read` para leer el archivo CSV y convertirlo en DataFrame. Seleccionaremos solo dos columnas "fecha" y "totalTestResultsIncrease", y cambiaremos el formato de fecha.
Al final, haremos lo siguiente:
- Filtrar los resultados para eliminar valores negativos
- Ordenar el marco de datos en orden ascendente
- Muestra las últimas 5 filas.
using Downloads, DataFrames, CSV, Plots, Dates download_covid = Downloads.download("https://api.covidtracking.com/v1/us/daily.csv", "covid_us.csv")
columns = [:date, :totalTestResultsIncrease]
fmt = "yyyymmdd"
t = Dict(:date=>Date) covid_df = CSV.read("covid_us.csv", DataFrame, dateformat=fmt, select=columns, types=t) covid_df = sort(filter(row -> row.totalTestResultsIncrease > 0, covid_df))
last(covid_df,5)
Visualización de datos con Plot y RollingFunctions
Yo he modificado jonathan dinupara mostrar el gráfico de barras de capacidad de prueba total de EE. UU.
Usaremos Plot.jl para mostrar gráficos de barras/palos y RollingFunctions.jl para obtener un promedio de 7 días de los resultados totales de las pruebas.
using RollingFunctions # plot daily test increase as sticks
Plots.plot(covid_df.date, covid_df.totalTestResultsIncrease, seriestype=:sticks, label="Test Increase", title = "USA Total Testing Capacity", lw = 2) # 7-day average using rolling mean
window = 7
average = rollmean(covid_df.totalTestResultsIncrease, window) # we mutate the existing plot
Plots.plot!(covid_df.date, cat(zeros(window - 1), average, dims=1), label="7-day Average", lw=3)
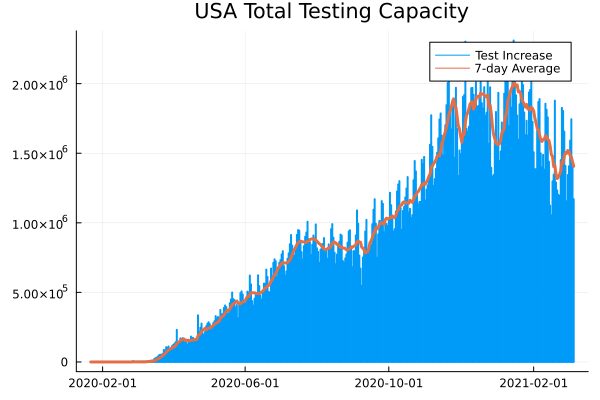
Esto es increíble.
Puede encontrar fácilmente paquetes alternativos de análisis de datos de Python y R en Julia visitando Paquetes de vacaciones en Julia .
Julia es fácil de usar y la ejecución del código es más rápida que Python. Si está haciendo la transición de R y Matlab a Julia, la sintaxis y el ecosistema de paquetes se sentirán naturales para que los adopte.
Es un lenguaje de propósito general y, recientemente, comenzó a atraer a la comunidad de aprendizaje automático debido a los paquetes nativos que se basan totalmente en Julia para proporcionar un tiempo de inferencia y capacitación más rápido.
Si tienes alguna pregunta sobre Julia, pregúntame en los comentarios. También puede unirse a la comunidad de Julia en Slack, Discord y Discourse para obtener más información sobre los últimos desarrollos.
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2022/11/setup-julia-jupyter-notebook.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-setup-julia-on-jupyter-notebook

