
Imagen del autor
Apache Kafka es un sistema de paso de mensajes distribuido que funciona en un modelo de editor-suscriptor. Está desarrollado por Apache Software Foundation y escrito en Java y Scala. Kafka se creó para superar el problema que enfrentaba la distribución y escalabilidad de los sistemas tradicionales de paso de mensajes. Puede manejar y almacenar grandes volúmenes de datos con una latencia mínima y un alto rendimiento. Debido a estos beneficios, puede ser adecuado para realizar aplicaciones de procesamiento de datos en tiempo real y servicios de transmisión. Actualmente es de código abierto y lo utilizan muchas organizaciones como Netflix, Walmart y Linkedin.
Un sistema de paso de mensajes hace que varias aplicaciones envíen o reciban datos entre sí sin preocuparse por la transmisión y el intercambio de datos. Punto a punto y Editor-Suscriptor son dos sistemas extendidos de paso de mensajes. En punto a punto, el remitente empuja los datos a la cola y el receptor sale de ella como un sistema de cola estándar siguiendo el principio FIFO (primero en entrar, primero en salir). Además, los datos se eliminan una vez que se leen, y solo se permite un único receptor a la vez. No se establece una dependencia de tiempo para que el receptor lea el mensaje.

Fig.1 Sistema de mensajes punto a punto | Imagen por autor
En el modelo de publicador-suscriptor, el remitente se denomina publicador y el receptor se denomina suscriptor. En esto, múltiples emisores y receptores pueden leer o escribir datos simultáneamente. Pero hay una dependencia del tiempo en ello. El consumidor tiene que consumir el mensaje antes de un cierto período de tiempo, ya que se elimina después de eso, incluso si no se leyó. Dependiendo de la configuración del usuario, este límite de tiempo puede ser de un día, una semana o un mes.

Fig.2 Sistema de mensajes editor-suscriptor | Imagen por autor
La arquitectura Kafka consta de varios componentes clave:
- Tema
- tabique
- Broker
- Productor
- Consumidores
- Clúster de Kafka
- Zookeeper
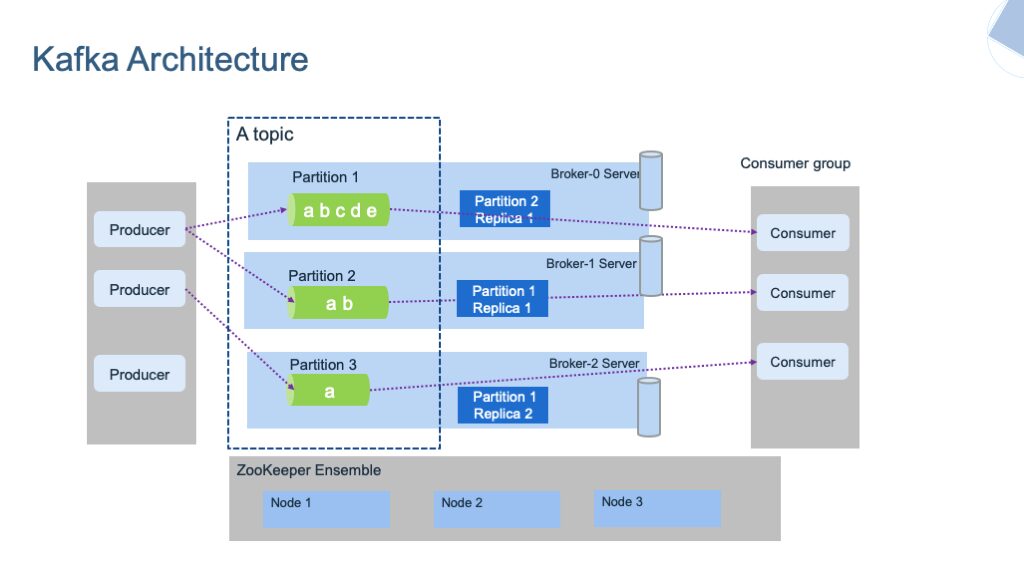
Fig.3 Arquitectura Kafka | Imagen por ibm-cloud-arquitectura
Entendamos brevemente cada componente.
Kafka almacena los mensajes en diferentes Temas. Un tema es un grupo que contiene los mensajes de una categoría particular. Es similar a una tabla en una base de datos. Un tema se puede identificar únicamente por su nombre. No podemos crear dos temas con el mismo nombre.
Los temas se clasifican a su vez en Particiones. Cada registro de estas particiones está asociado con un identificador único denominado Compensación, que denota la posición del registro en esa partición.
Aparte de esto, hay Productores y Consumidores en el sistema. Los productores escriben o publican los datos en los temas utilizando las API de producción. Estos productores pueden escribir sobre el tema o los niveles de partición.
Los consumidores leen o consumen los datos de los temas mediante las API de consumidores. También pueden leer los datos a nivel de tema o de partición. Los consumidores que realizan tareas similares formarán un grupo conocido como el Grupo de consumidores.
Hay otros sistemas como Broker y guardián del zoológico, que se ejecutan en segundo plano de Kafka Server. Los intermediarios son el software que mantiene y lleva el registro de los mensajes publicados. También es responsable de entregar el mensaje correcto al consumidor correcto en el orden correcto usando compensaciones. El conjunto de intermediarios que se comunican colectivamente entre sí se puede llamar Clústeres de Kafka. Los agentes se pueden agregar o eliminar dinámicamente del clúster de Kafka sin enfrentar ningún tiempo de inactividad en el sistema. Y uno de los intermediarios del clúster de Kafka se denomina Control. Administra estados y réplicas dentro del clúster y realiza tareas administrativas.
Por otro lado, Zookeeper es responsable de mantener el estado de salud del clúster de Kafka y de coordinarse con cada intermediario de ese clúster. Mantiene los metadatos de cada clúster en forma de pares clave-valor.
Este tutorial se centra principalmente en la implementación práctica de Apache Kafka. Si quieres leer más sobre su arquitectura, puedes leer así artículo de Upsolver.
Considere el caso de uso de un servicio de reserva de taxis como Uber. Esta aplicación utiliza Apache Kafka para enviar y recibir mensajes a través de varios servicios como transacciones, correos electrónicos, análisis, etc.
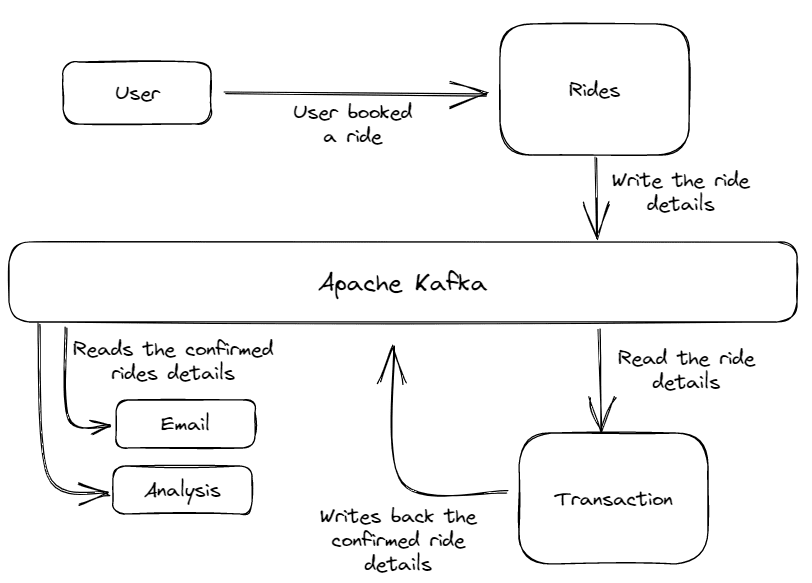
Fig.4 Arquitectura de la App Taxi | Imagen por autor
La arquitectura consta de varios servicios. El Rides El servicio recibe la solicitud de viaje del cliente y escribe los detalles del viaje en el sistema de mensajes de Kafka.
Luego, estos detalles de la orden fueron leídos por el Transaction servicio, que confirma el pedido y el estado del pago. Después de confirmar ese viaje, este Transaction El servicio vuelve a escribir el viaje confirmado en el sistema de mensajes con algunos detalles adicionales. Y finalmente, los detalles del viaje confirmado son leídos por otros servicios como correo electrónico o análisis de datos para enviar el correo de confirmación al cliente y realizar algún análisis.
Podemos ejecutar todos estos procesos en tiempo real con un rendimiento muy alto y una latencia mínima. Además, debido a la capacidad de escalado horizontal de Apache Kafka, podemos escalar esta aplicación para manejar millones de usuarios.
Esta sección contiene un tutorial rápido para implementar el sistema de mensajes kafka en nuestra aplicación. Incluye los pasos para descargar kafka, configurarlo y crear funciones de productor-consumidor.
Nota: Este tutorial se basa en el lenguaje de programación python y utiliza una máquina con Windows.
Pasos de descarga de Apache Kafka
1.Descargue la última versión de Apache Kafka desde esa enlace. Kafka se basa en lenguajes JVM, por lo que Java 7 o una versión superior debe estar instalada en su sistema.
- Extraiga el archivo zip descargado de la unidad (C:) de su computadora y cambie el nombre de la carpeta como
/apache-kafka.
- El directorio principal contiene dos subdirectorios,
/biny/config, que contiene los archivos ejecutables y de configuración para zookeeper y el servidor kafka.
Pasos de configuración
Primero, necesitamos crear directorios de registro para los servidores Kafka y Zookeeper. Estos directorios almacenarán todos los metadatos de estos clústeres y los mensajes de los temas y particiones.
Nota: De forma predeterminada, estos directorios de registro se crean dentro del /tmp directorio, un directorio volátil que desaparece todos los datos en el interior cuando el sistema se apaga o se reinicia. Necesitamos establecer la ruta permanente para los directorios de registro para resolver este problema. Veamos cómo.
Navegue hasta apache-kafka >> config y abre el server.properties archivo. Aquí puede configurar muchas propiedades de kafka, como rutas para directorios de registros, horas de retención de registros, número de particiones, etc.
Dentro del server.properties archivo, tenemos que cambiar la ruta del archivo del directorio de registro del archivo temporal /tmp directorio a un directorio permanente. El directorio de registro contiene los datos generados o escritos en el servidor Kafka. Para cambiar la ruta, actualice el log.dirs variable de /tmp/kafka-logs a c:/apache-kafka/kafka-logs. Esto hará que sus registros se almacenen permanentemente.
log.dirs=c:/apache-kafka/kafka-logs
El servidor de Zookeeper también contiene algunos archivos de registro para almacenar los metadatos de los servidores de Kafka. Para cambiar la ruta, repita el paso anterior, es decir, abra zookeeper.properties archivo y reemplace la ruta de la siguiente manera.
dataDir=c:/apache-kafka/zookeeper-logs
Este servidor zookeeper actuará como administrador de recursos para nuestro servidor kafka.
Ejecute los servidores Kafka y Zookeeper
Para ejecutar el servidor zookeeper, abra un nuevo indicador cmd dentro de su directorio principal y ejecute el siguiente comando.
$ .binwindowszookeeper-server-start.bat .configzookeeper.properties
Imagen del autor
Mantenga la instancia de zookeeper en ejecución.
Para ejecutar el servidor kafka, abra un indicador cmd separado y ejecute el siguiente código.
$ .binwindowskafka-server-start.bat .configserver.properties
Mantenga los servidores kafka y zookeeper en ejecución y, en la siguiente sección, crearemos funciones de productor y consumidor que leerán y escribirán datos en el servidor kafka.
Creación de funciones de productor y consumidor
Para crear las funciones de productor y consumidor, tomaremos el ejemplo de nuestra aplicación de comercio electrónico que discutimos anteriormente. El servicio "Pedidos" funcionará como un productor, que escribe los detalles del pedido en el servidor kafka, y el servicio de correo electrónico y análisis funcionará como un consumidor, que lee los datos del servidor. El servicio Transaction funcionará como consumidor y como productor. Lee los detalles del pedido y los vuelve a escribir después de la confirmación de la transacción.
Pero primero, necesitamos instalar la biblioteca python de Kafka, que contiene funciones integradas para productores y consumidores.
$ pip install kafka-python
Ahora, crea un nuevo directorio llamado kafka-tutorial. Crearemos los archivos python dentro de ese directorio que contienen las funciones requeridas.
$ mkdir kafka-tutorial
$ cd .kafka-tutorial
Función del productor:
Ahora, cree un archivo python llamado `rides.py` y pegue el siguiente código en él.
rides.py
import kafka
import json
import time
import random topicName = "ride_details"
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092") for i in range(1, 10): ride = { "id": i, "customer_id": f"user_{i}", "location": f"Lat: {random.randint(-90, 90)}, Long: {random.randint(-90, 90)}", } producer.send(topicName, json.dumps(ride).encode("utf-8")) print(f"Ride Details Send Succesfully!") time.sleep(5)
Explicación:
En primer lugar, hemos importado todas las bibliotecas necesarias, incluida kafka. Luego, se define el nombre del tema y una lista de varios elementos. Recuerde que el tema es un grupo que contiene tipos de mensajes similares. En este ejemplo, este tema contendrá todos los pedidos.
Luego, creamos una instancia de una función KafkaProducer y la conectamos al servidor kafka que se ejecuta en localhost: 9092. Si su servidor kafka se ejecuta en una dirección y un puerto diferentes, debe mencionar allí la IP y el número de puerto del servidor.
Después de eso, generaremos algunos pedidos en formato JSON y los escribiremos en el servidor kafka en el nombre del tema definido. La función de suspensión se utiliza para generar un espacio entre los pedidos posteriores.
Funciones del consumidor:
transaction.py
import json
import kafka
import random RIDE_DETAILS_KAFKA_TOPIC = "ride_details"
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed" consumer = kafka.KafkaConsumer( RIDE_DETAILS_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092") print("Listening Ride Details")
while True: for data in consumer: print("Loading Transaction..") message = json.loads(data.value.decode()) customer_id = message["customer_id"] location = message["location"] confirmed_ride = { "customer_id": customer_id, "customer_email": f"{customer_id}@xyz.com", "location": location, "alloted_driver": f"driver_{customer_id}", "pickup_time": f"{random.randint(1, 20)}mins", } print(f"Transaction Completed..({customer_id})") producer.send( RIDES_CONFIRMED_KAFKA_TOPIC, json.dumps(confirmed_ride).encode("utf-8") )
Explicación:
El transaction.py El archivo se utiliza para confirmar las transiciones realizadas por los usuarios y asignarles un conductor y una hora estimada de recogida. Lee los detalles del viaje del servidor kafka y los vuelve a escribir en el servidor kafka después de confirmar el viaje.
Ahora, cree dos archivos python llamados email.py y analytics.py, que se utilizan para enviar correos electrónicos al cliente para la confirmación de su viaje y para realizar algunos análisis, respectivamente. Estos archivos solo se crean para demostrar que incluso varios consumidores pueden leer los datos del servidor Kafka simultáneamente.
email.py
import kafka
import json RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
consumer = kafka.KafkaConsumer( RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
) print("Listening Confirmed Rides!")
while True: for data in consumer: message = json.loads(data.value.decode()) email = message["customer_email"] print(f"Email sent to {email}!")
analysis.py
import kafka
import json RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
consumer = kafka.KafkaConsumer( RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
) print("Listening Confirmed Rides!")
while True: for data in consumer: message = json.loads(data.value.decode()) id = message["customer_id"] driver_details = message["alloted_driver"] pickup_time = message["pickup_time"] print(f"Data sent to ML Model for analysis ({id})!")
Ahora que hemos terminado con la aplicación, en la siguiente sección, ejecutaremos todos los servicios simultáneamente y verificaremos el rendimiento.
Prueba la aplicación
Ejecute cada archivo uno por uno en cuatro indicaciones de comando separadas.
$ python transaction.py
$ python email.py
$ python analysis.py
$ python ride.py
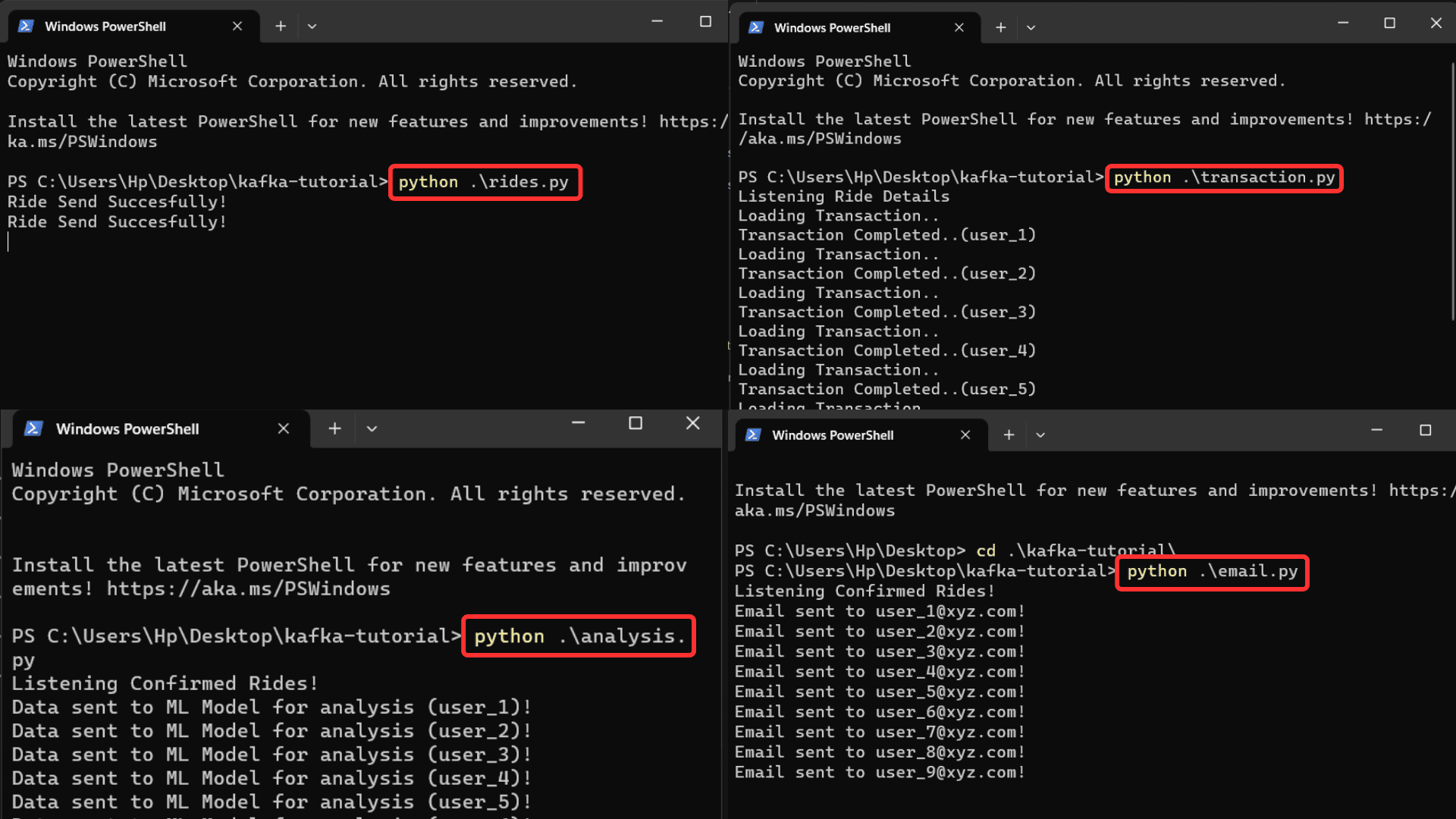
Imagen del autor
Puede recibir resultados de todos los archivos simultáneamente cuando los detalles del viaje se envían al servidor. También puede aumentar la velocidad de procesamiento eliminando la función de retraso en el rides.py archivo. El archivo `rides.py` empujó los datos al servidor kafka, y los otros tres archivos leen simultáneamente esos datos del servidor kafka y funcionan en consecuencia.
Espero que obtenga una comprensión básica de Apache Kafka y cómo implementarlo.
En este artículo, hemos aprendido sobre Apache Kafka, su funcionamiento y su implementación práctica utilizando un caso de uso de una aplicación de reserva de taxis. El diseño de una canalización escalable con Kafka requiere una planificación e implementación cuidadosas. Puede aumentar la cantidad de intermediarios y particiones para que estas aplicaciones sean más escalables. Cada partición se procesa de forma independiente para que la carga se pueda distribuir entre ellas. Además, puede optimizar la configuración de kafka configurando el tamaño del caché, el tamaño del búfer o la cantidad de subprocesos.
GitHub enlace para el código completo utilizado en el artículo.
Gracias por leer este artículo. Si tiene algún comentario o sugerencia, no dude en ponerse en contacto conmigo en LinkedIn.
Garg ario es un B.Tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y estoy ansioso por trabajar más en estas direcciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/04/build-scalable-data-architecture-apache-kafka.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-build-a-scalable-data-architecture-with-apache-kafka

