Esta es una publicación invitada coescrita por Maik Leuthold y Nick Harmening de BMW Group.
El BMW Group tiene su sede en Munich, Alemania, donde la empresa supervisa a 149,000 30 empleados y fabrica automóviles y motocicletas en más de 15 sitios de producción en XNUMX países. Esta estrategia de producción multinacional sigue una red de proveedores aún más internacional y extensa.
Al igual que muchas empresas automovilísticas de todo el mundo, BMW Group se ha enfrentado a desafíos en su cadena de suministro debido a la escasez mundial de semiconductores. Crear transparencia sobre la demanda actual y futura de semiconductores de BMW Group es un aspecto estratégico clave para resolver la escasez junto con proveedores y fabricantes de semiconductores. Los fabricantes necesitan conocer la información exacta del volumen de semiconductores actual y futuro de BMW Group, lo que ayudará de manera efectiva a dirigir el suministro mundial disponible.
El requisito principal es tener un pronóstico de demanda de semiconductores automatizado, transparente y de largo plazo. Además, este sistema de pronóstico debe proporcionar pasos de enriquecimiento de datos, incluidos los subproductos, servir como datos maestros en torno a la gestión de semiconductores y permitir más casos de uso en BMW Group.
Para habilitar este caso de uso, utilizamos la plataforma de datos nativa de la nube de BMW Group llamada Cloud Data Hub. En 2019, BMW Group decidió rediseñar y trasladar su lago de datos local a la nube de AWS para permitir la innovación basada en datos mientras escala con las necesidades dinámicas de la organización. Cloud Data Hub procesa y combina datos anónimos de sensores de vehículos y otras fuentes en toda la empresa para que sean fácilmente accesibles para los equipos internos que crean aplicaciones internas y orientadas al cliente. Para obtener más información sobre Cloud Data Hub, consulte BMW Group utiliza un lago de datos basado en AWS para liberar el poder de los datos.
En esta publicación, compartimos cómo BMW Group analiza la demanda de semiconductores utilizando Pegamento AWS.
Lógica y sistemas detrás de la previsión de la demanda
El primer paso hacia el pronóstico de la demanda es la identificación de componentes relevantes para semiconductores de un tipo de vehículo. Cada componente se describe mediante un número de pieza único, que sirve como clave en todos los sistemas para identificar este componente. Un componente puede ser un faro o un volante, por ejemplo.
Por razones históricas, los datos requeridos para este paso de agregación están aislados y representados de manera diferente en diversos sistemas. Debido a que cada sistema de origen y tipo de datos tiene su propio esquema y formato, es particularmente difícil realizar análisis basados en estos datos. Algunos sistemas de origen ya están disponibles en Cloud Data Hub (por ejemplo, datos maestros parciales), por lo tanto, es sencillo consumirlos desde nuestra cuenta de AWS. Para acceder a las fuentes de datos restantes, necesitamos crear trabajos de ingesta específicos que lean datos del sistema respectivo.
El siguiente diagrama ilustra el enfoque.
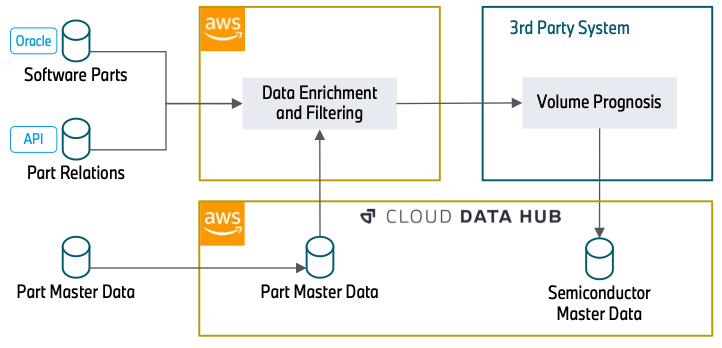
El enriquecimiento de datos comienza con una base de datos Oracle (piezas de software) que contiene números de pieza relacionados con el software. Puede ser la unidad de control de un faro o un sistema de cámara para la conducción automatizada. Debido a que los semiconductores son la base para ejecutar el software, esta base de datos constituye la base de nuestro procesamiento de datos.
En el siguiente paso, usamos las API REST (Relaciones de partes) para enriquecer los datos con más atributos. Esto incluye cómo se relacionan las piezas (por ejemplo, una unidad de control específica que se instalará en un faro) y durante qué período de tiempo se integrará un número de pieza en un vehículo. El conocimiento de las relaciones de las piezas es esencial para comprender cómo un semiconductor específico, en este caso la unidad de control, es relevante para una pieza más general, el faro. La información temporal sobre el uso de números de pieza nos permite filtrar números de pieza obsoletos, que no se utilizarán en el futuro y, por lo tanto, no tienen relevancia en el pronóstico.
Los datos (Part Master Data) se pueden consumir directamente desde Cloud Data Hub. Esta base de datos incluye atributos sobre el estado y los tipos de materiales de un número de pieza. Esta información es necesaria para filtrar los números de pieza que recopilamos en los pasos anteriores pero que no tienen relevancia para los semiconductores. Con la información que se recopiló de las API, estos datos también se consultan para extraer más números de pieza que no se recopilaron en los pasos anteriores.
Después del enriquecimiento y filtrado de datos, un sistema de terceros lee los datos de la pieza filtrados y enriquece la información del semiconductor. Posteriormente, añade la información de volumen de los componentes. Finalmente, proporciona el pronóstico general de demanda de semiconductores de forma centralizada al Cloud Data Hub.
servicios aplicados
Nuestra solución utiliza los servicios sin servidor Pegamento AWS y Servicio de almacenamiento simple de Amazon (Amazon S3) para ejecutar flujos de trabajo ETL (extracción, transformación y carga) sin administrar una infraestructura. También reduce los costos al pagar solo por el tiempo que se ejecutan los trabajos. El enfoque sin servidor se adapta muy bien a la programación de nuestro flujo de trabajo porque ejecutamos la carga de trabajo solo una vez a la semana.
Debido a que estamos utilizando diversos sistemas de origen de datos, así como procesamiento y agregación complejos, es importante desacoplar los trabajos de ETL. Esto nos permite procesar cada fuente de datos de forma independiente. También dividimos la transformación de datos en varios módulos (agregación de datos, filtrado de datos y preparación de datos) para que el sistema sea más transparente y fácil de mantener. Este enfoque también ayuda en caso de ampliar o modificar trabajos existentes.
Aunque cada módulo es específico para una fuente de datos o una transformación de datos en particular, utilizamos bloques reutilizables dentro de cada trabajo. Esto nos permite unificar cada tipo de operación y simplifica el procedimiento de agregar nuevas fuentes de datos y pasos de transformación en el futuro.
En nuestra configuración, seguimos la mejor práctica de seguridad del principio de privilegio mínimo, para garantizar que la información esté protegida contra el acceso accidental o innecesario. Por lo tanto, cada módulo tiene Gestión de identidades y accesos de AWS (IAM) con solo los permisos necesarios, es decir, acceso solo a fuentes de datos y depósitos con los que trata el trabajo. Para obtener más información sobre las mejores prácticas de seguridad, consulte Mejores prácticas de seguridad en IAM.
Resumen de la solución
El siguiente diagrama muestra el flujo de trabajo general en el que varios trabajos de AWS Glue interactúan entre sí de forma secuencial.
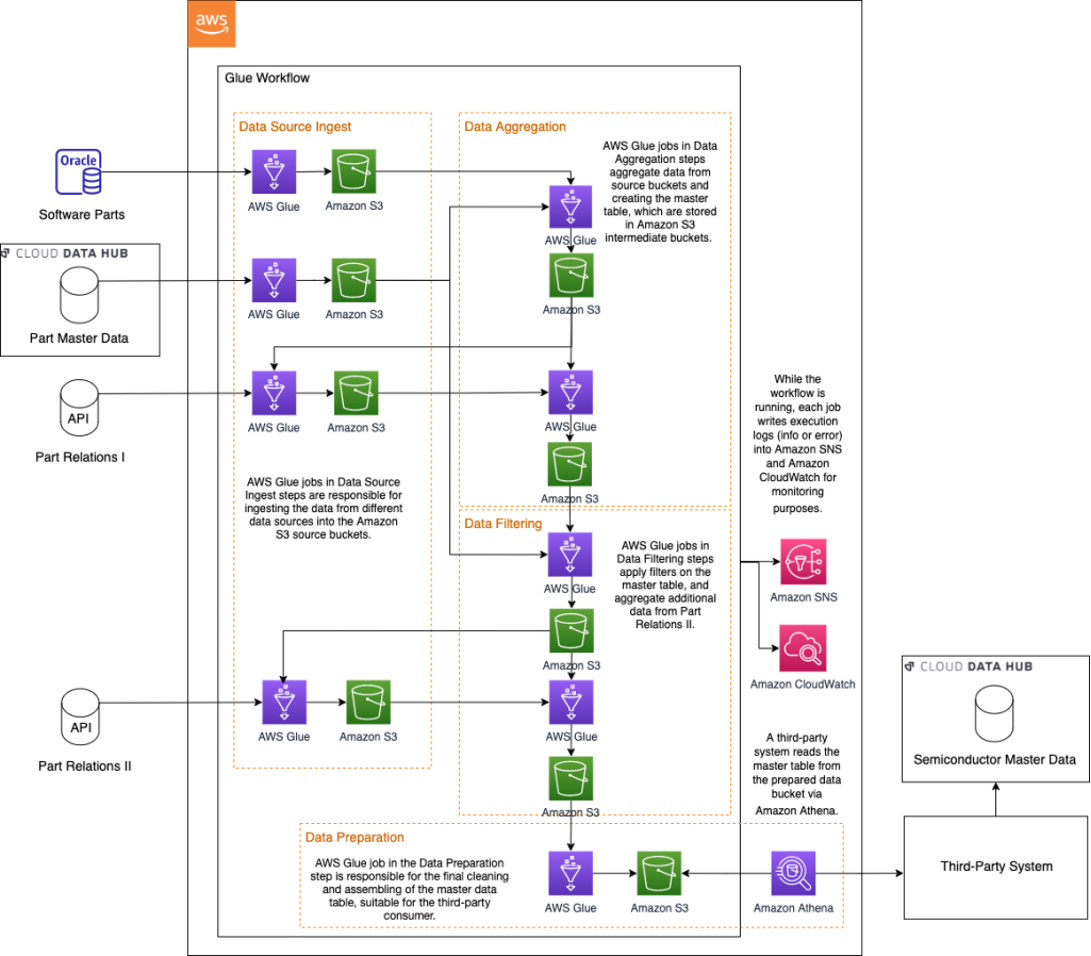
Como mencionamos anteriormente, usamos Cloud Data Hub, Oracle DB y otras fuentes de datos con las que nos comunicamos a través de la API REST. El primer paso de la solución es el módulo Ingesta de fuente de datos, que ingiere los datos de diferentes fuentes de datos. Para ese fin, los trabajos de AWS Glue leen información de diferentes orígenes de datos y la escriben en los depósitos de origen de S3. Los datos ingeridos se almacenan en depósitos cifrados y las claves son administradas por Servicio de administración de claves de AWS (AWS KMS).
Después del paso de ingesta de fuentes de datos, los trabajos intermedios agregan y enriquecen las tablas con otras fuentes de datos, como la versión y las categorías de los componentes, las fechas de fabricación del modelo, etc. Luego, los escriben en los cubos intermedios en el módulo Agregación de datos, creando una representación de datos completa y abundante. Además, de acuerdo con el flujo de trabajo de la lógica empresarial, los módulos Filtrado de datos y Preparación de datos crean la tabla de datos maestros final con solo información real y relevante para la producción.
El flujo de trabajo de AWS Glue administra todos estos trabajos de ingestión y filtrado de principio a fin. Una programación de flujo de trabajo de AWS Glue se configura semanalmente para ejecutar el flujo de trabajo los miércoles. Mientras se ejecuta el flujo de trabajo, cada trabajo escribe registros de ejecución (información o error) en Servicio de notificación simple de Amazon (Amazon SNS) y Reloj en la nube de Amazon con fines de seguimiento. Amazon SNS reenvía los resultados de la ejecución a las herramientas de monitoreo, como los canales Mail, Teams o Slack. En caso de algún error en los trabajos, Amazon SNS también alerta a los oyentes sobre el resultado de la ejecución del trabajo para que tomen medidas.
Como último paso de la solución, el sistema de terceros lee la tabla maestra del depósito de datos preparado a través de Atenea amazónica. Después de más pasos de ingeniería de datos, como el enriquecimiento de la información de semiconductores y la integración de información de volumen, el activo de datos maestros final se escribe en Cloud Data Hub. Con los datos proporcionados ahora en Cloud Data Hub, otros casos de uso pueden usar estos datos maestros de semiconductores sin crear varias interfaces para diferentes sistemas de origen.
Resultado empresarial
Los resultados del proyecto brindan a BMW Group una transparencia sustancial sobre su demanda de semiconductores para toda su cartera de vehículos en el presente y en el futuro. La creación de una base de datos de esa magnitud permite a BMW Group establecer aún más casos de uso en beneficio de una mayor transparencia de la cadena de suministro y un intercambio más claro y profundo con proveedores de primer nivel y fabricantes de semiconductores. Ayuda no solo a resolver la exigente situación actual del mercado, sino también a ser más resistente en el futuro. Por lo tanto, es un paso importante hacia una cadena de suministro digital y transparente.
Conclusión
Esta publicación describe cómo analizar la demanda de semiconductores de muchas fuentes de datos con trabajos de big data en un flujo de trabajo de AWS Glue. Una arquitectura sin servidor con una diversidad mínima de servicios hace que el código base y la arquitectura sean fáciles de entender y mantener. Para obtener más información sobre cómo usar los flujos de trabajo y trabajos de AWS Glue para la orquestación sin servidor, visite el Pegamento AWS página de servicio.
Sobre los autores
 maik leuthold es líder de proyecto en BMW Group para análisis avanzados en el campo comercial de la cadena de suministro y adquisiciones, y lidera la estrategia de digitalización para la gestión de semiconductores.
maik leuthold es líder de proyecto en BMW Group para análisis avanzados en el campo comercial de la cadena de suministro y adquisiciones, y lidera la estrategia de digitalización para la gestión de semiconductores.
 Nick Harmening es líder de proyectos de TI en BMW Group y arquitecto de soluciones certificado por AWS. Construye y opera aplicaciones nativas de la nube con un enfoque en la ingeniería de datos y el aprendizaje automático.
Nick Harmening es líder de proyectos de TI en BMW Group y arquitecto de soluciones certificado por AWS. Construye y opera aplicaciones nativas de la nube con un enfoque en la ingeniería de datos y el aprendizaje automático.
 Goksel Sarikaya es Arquitecto sénior de aplicaciones en la nube en Servicios profesionales de AWS. Permite a los clientes diseñar aplicaciones escalables, rentables y competitivas a través de la producción innovadora de la plataforma AWS. Les ayuda a acelerar los resultados comerciales de clientes y socios durante su proceso de transformación digital.
Goksel Sarikaya es Arquitecto sénior de aplicaciones en la nube en Servicios profesionales de AWS. Permite a los clientes diseñar aplicaciones escalables, rentables y competitivas a través de la producción innovadora de la plataforma AWS. Les ayuda a acelerar los resultados comerciales de clientes y socios durante su proceso de transformación digital.
 Alejandro Tselikov es un Arquitecto de datos en Servicios profesionales de AWS apasionado por ayudar a los clientes a crear soluciones escalables de datos, análisis y aprendizaje automático para permitir conocimientos oportunos y tomar decisiones comerciales críticas.
Alejandro Tselikov es un Arquitecto de datos en Servicios profesionales de AWS apasionado por ayudar a los clientes a crear soluciones escalables de datos, análisis y aprendizaje automático para permitir conocimientos oportunos y tomar decisiones comerciales críticas.
 raul shaurya es Arquitecto Senior de Big Data en Amazon Web Services. Ayuda y trabaja en estrecha colaboración con los clientes en la creación de plataformas de datos y aplicaciones analíticas en AWS. Fuera del trabajo, a Rahul le encanta dar largos paseos con su perro Barney.
raul shaurya es Arquitecto Senior de Big Data en Amazon Web Services. Ayuda y trabaja en estrecha colaboración con los clientes en la creación de plataformas de datos y aplicaciones analíticas en AWS. Fuera del trabajo, a Rahul le encanta dar largos paseos con su perro Barney.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-the-bmw-group-analyses-semiconductor-demand-with-aws-glue/

