Esta es una publicación de blog de invitado coescrita con Addison Higley y Ramzi Yassine de Hudl.
Tecnologías deportivas ágiles de Hudl, Inc. es una empresa con sede en Lincoln, Nebraska, que proporciona herramientas para entrenadores y atletas para revisar imágenes de juegos y mejorar el juego individual y en equipo. Su línea de productos inicial sirvió a equipos de fútbol americano universitarios y profesionales. En la actualidad, la empresa brinda servicios de video a equipos juveniles, aficionados y profesionales de fútbol americano, así como de otros deportes, como fútbol, baloncesto, voleibol y lacrosse. Ahora sirve a 170,000 equipos en 50 deportes diferentes en todo el mundo. El objetivo general de Hudl es capturar y aportar valor a cada momento en los deportes.
La misión de Hudl es hacer que cada momento en los deportes cuente. Hudl hace esto ampliando el acceso a más momentos a través de video y datos y poniendo esos momentos en contexto. Nuestro objetivo es aumentar el acceso de diferentes personas y aumentar el contexto con más puntos de datos para cada cliente que servimos. Al usar datos para generar análisis, Hudl puede convertir los datos en información procesable, contando historias poderosas con videos y datos.
Para servir mejor a nuestros clientes y proporcionar los conocimientos más poderosos posibles, debemos poder comparar grandes conjuntos de datos entre diferentes fuentes. Por ejemplo, enriquecer nuestro MongoDB y Amazon DocumentDB (con compatibilidad con MongoDB) Los datos con nuestra aplicación de registro de datos conducen a nuevos conocimientos. Esto requiere canalizaciones de datos resilientes.
En esta publicación, discutimos cómo Hudl ha iterado en una de esas canalizaciones de datos usando Pegamento AWS para mejorar el rendimiento y la escalabilidad. Hablamos sobre la arquitectura inicial de esta canalización y algunas de las limitaciones asociadas con este enfoque. También discutimos cómo iteramos en ese diseño usando Apache Hudi para mejorar drásticamente el rendimiento.
Planteamiento del problema
Una canalización de datos que garantiza que los datos estadísticos de MongoDB y Amazon DocumentDB de alta calidad estén disponibles en nuestro lago de datos central, y es un requisito para que Hudl pueda ofrecer análisis deportivos. Es importante mantener la integridad de los datos entre MongoDB y los datos transaccionales de Amazon DocumentDB con el lago de datos capturando los cambios casi en tiempo real junto con las actualizaciones en los registros del lago de datos. Debido a que las estadísticas de Hudl están respaldadas por las bases de datos de MongoDB y Amazon DocumentDB, además de una amplia gama de otras fuentes de datos, es importante que los datos relevantes de MongoDB y Amazon DocumentDB estén disponibles en un lago de datos central donde podemos ejecutar consultas de análisis para comparar datos estadísticos entre fuentes.
Diseño inicial
El siguiente diagrama demuestra la arquitectura de nuestro diseño inicial.
Analicemos los servicios clave de AWS de esta arquitectura:
- Servicio de migración de datos de AWS (AWS DMS) permitió a nuestro equipo avanzar rápidamente en la entrega de esta canalización. AWS DMS brinda a nuestro equipo una instantánea completa de los datos y también ofrece captura de datos de cambios (CDC) en curso. Al combinar estos dos conjuntos de datos, podemos asegurarnos de que nuestra canalización entregue los datos más recientes.
- Servicio de almacenamiento simple de Amazon (Amazon S3) es la columna vertebral del lago de datos de Hudl debido a su durabilidad, escalabilidad y rendimiento líder en la industria.
- Pegamento AWS nos permite ejecutar nuestras cargas de trabajo de Spark sin servidor, con una configuración mínima. Elegimos AWS Glue por su facilidad de uso y velocidad de desarrollo. Además, características como los marcadores de AWS Glue simplificaron nuestra lógica de administración de archivos.
- Desplazamiento al rojo de Amazon ofrece almacenamiento de datos a escala de petabytes. Amazon Redshift proporciona un rendimiento consistentemente rápido e integraciones sencillas con nuestro lago de datos S3.
El flujo de procesamiento de datos incluye los siguientes pasos:
- Amazon DocumentDB contiene los datos estadísticos de Hudl.
- AWS DMS nos brinda una exportación completa de datos estadísticos de Amazon DocumentDB y cambios continuos en los mismos datos.
- En S3 Raw Zone, los datos se almacenan en formato JSON.
- Un trabajo de AWS Glue combina la carga inicial de datos estadísticos con los datos estadísticos modificados para brindar una instantánea de los datos estadísticos en formato JSON como referencia, eliminando los duplicados.
- En S3 Cleansed Zone, los datos JSON se normalizan y se convierten al formato Parquet.
- AWS Glue utiliza un comando COPY para insertar datos de Parquet en las tablas base de consumo de Amazon Redshift.
- Amazon Redshift almacena la tabla final para el consumo.
El siguiente es un fragmento de código de muestra del trabajo de AWS Glue en la canalización de datos inicial:
Desafios
Aunque esta solución inicial satisfizo nuestra necesidad de calidad de los datos, sentimos que había espacio para mejorar:
- El oleoducto era lento – La tubería funcionó lentamente (más de 2 horas) porque para cada lote, se comparó todo el conjunto de datos. Cada registro tuvo que compararse, aplanarse y convertirse a Parquet, incluso cuando solo se cambiaron unos pocos registros de la ejecución diaria anterior.
- El oleoducto era caro – A medida que el tamaño de los datos creció diariamente, la duración del trabajo también creció significativamente (especialmente en el paso 4). Para mitigar el impacto, necesitábamos asignar más DPU (Unidades de procesamiento de datos) de AWS Glue para escalar el trabajo, lo que generó un mayor costo.
- El oleoducto limitó nuestra capacidad de escalar – Los datos de Hudl tienen una larga historia de rápido crecimiento con el aumento de clientes y eventos deportivos. Dada esta tendencia, nuestra tubería necesitaba ejecutarse de la manera más eficiente posible para manejar solo conjuntos de datos cambiantes para tener un rendimiento predecible.
Nuevo diseño
El siguiente diagrama ilustra nuestra arquitectura de tubería actualizada.
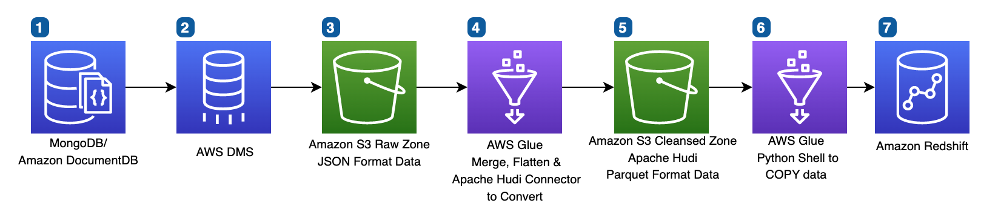
Aunque la arquitectura general se ve más o menos igual, la lógica interna en AWS Glue cambió significativamente, junto con la adición de apache hudi conjuntos de datos
En el paso 4, AWS Glue ahora interactúa con los conjuntos de datos de Apache HUDI en la zona limpia de S3 para modificar o eliminar los registros modificados según lo identificado por AWS DMS CDC. El Conector de AWS Glue a Apache Hudi ayuda a convertir datos JSON a formato Parquet y los actualiza en el conjunto de datos Apache HUDI. Conservar los documentos completos en nuestro conjunto de datos Apache HUDI nos permite realizar fácilmente cambios de esquema en nuestras tablas finales de Amazon Redshift sin necesidad de volver a exportar los datos de nuestros sistemas de origen.
El siguiente es un fragmento de código de muestra de la nueva canalización de AWS Glue:
Resultados
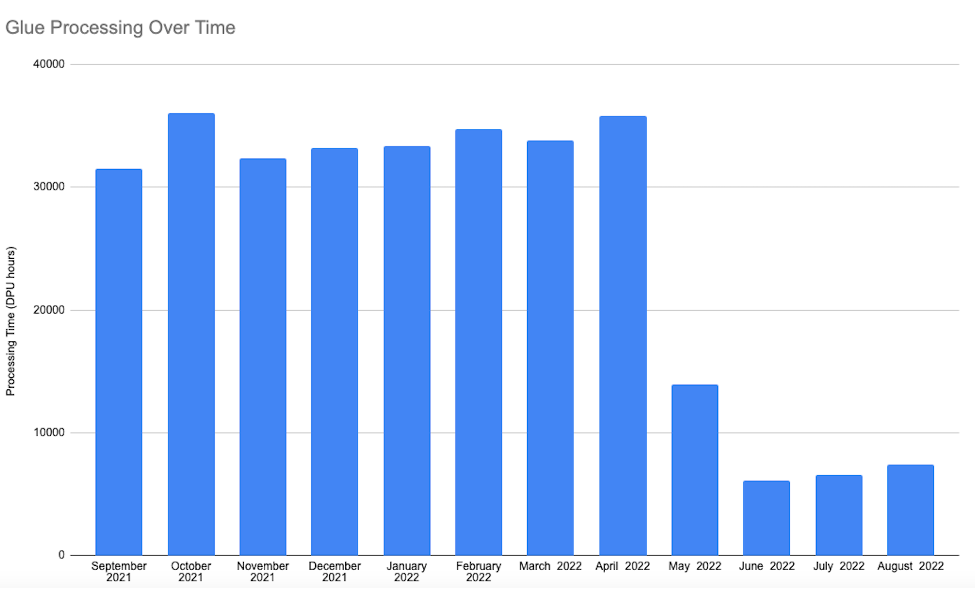
Con este nuevo enfoque que usa conjuntos de datos de Apache Hudi con AWS Glue implementado después de mayo de 2022, el tiempo de ejecución de la canalización fue predecible y menos costoso que el enfoque inicial. Debido a que solo manejamos registros nuevos o modificados mediante la eliminación de la unión externa completa en todo el conjunto de datos, observamos una reducción del 80 al 90 % en el tiempo de ejecución de esta canalización, lo que redujo los costos en un 80 a 90 % en comparación con el enfoque inicial. El siguiente diagrama ilustra nuestro tiempo de procesamiento antes y después de implementar la nueva canalización.
Conclusión
Con el marco de administración de datos de código abierto de Apache Hudi, simplificamos el procesamiento de datos incrementales en nuestra canalización de datos de AWS Glue para administrar los cambios de datos a nivel de registro en nuestro lago de datos S3 con CDC de Amazon DocumentDB.
Esperamos que esta publicación inspire a su organización a crear canalizaciones de AWS Glue con conjuntos de datos de Apache Hudi que reduzcan los costos y brinden mejoras de rendimiento utilizando tecnologías sin servidor para lograr sus objetivos comerciales.
Sobre los autores
 Addison Higley es ingeniero de datos sénior en Hudl. Administra más de 20 canalizaciones de datos para ayudar a garantizar que los datos estén disponibles para el análisis, de modo que Hudl pueda brindar información a los clientes.
Addison Higley es ingeniero de datos sénior en Hudl. Administra más de 20 canalizaciones de datos para ayudar a garantizar que los datos estén disponibles para el análisis, de modo que Hudl pueda brindar información a los clientes.
 ramzi yassine es ingeniero principal de datos en Hudl. Dirige la arquitectura, la implementación de las canalizaciones de datos y las aplicaciones de datos de Hudl, y se asegura de que nuestros datos permitan el análisis interno y externo.
ramzi yassine es ingeniero principal de datos en Hudl. Dirige la arquitectura, la implementación de las canalizaciones de datos y las aplicaciones de datos de Hudl, y se asegura de que nuestros datos permitan el análisis interno y externo.
 Swagat Kulkarni es un arquitecto de soluciones sénior en AWS y un entusiasta de AI/ML. Le apasiona resolver problemas del mundo real para clientes con servicios nativos en la nube y aprendizaje automático. Swagat tiene más de 15 años de experiencia en la entrega de varias iniciativas de transformación digital para clientes en múltiples dominios, incluidos el comercio minorista, los viajes y la hospitalidad, y la atención médica. Fuera del trabajo, a Swagat le gusta viajar, leer y meditar.
Swagat Kulkarni es un arquitecto de soluciones sénior en AWS y un entusiasta de AI/ML. Le apasiona resolver problemas del mundo real para clientes con servicios nativos en la nube y aprendizaje automático. Swagat tiene más de 15 años de experiencia en la entrega de varias iniciativas de transformación digital para clientes en múltiples dominios, incluidos el comercio minorista, los viajes y la hospitalidad, y la atención médica. Fuera del trabajo, a Swagat le gusta viajar, leer y meditar.
 Indira Balakrishnan es Arquitecto principal de soluciones en el equipo de AWS Analytics Specialist SA. Le apasiona ayudar a los clientes a crear soluciones de análisis basadas en la nube para resolver sus problemas comerciales utilizando decisiones basadas en datos. Fuera del trabajo, es voluntaria en las actividades de sus hijos y pasa tiempo con su familia.
Indira Balakrishnan es Arquitecto principal de soluciones en el equipo de AWS Analytics Specialist SA. Le apasiona ayudar a los clientes a crear soluciones de análisis basadas en la nube para resolver sus problemas comerciales utilizando decisiones basadas en datos. Fuera del trabajo, es voluntaria en las actividades de sus hijos y pasa tiempo con su familia.

