En los últimos años, ha habido un énfasis creciente en la transparencia de precios en la industria de la salud. Bajo la Regla de transparencia en la cobertura (TCR), hospitales y pagadores publiquen sus datos de precios en un formato legible por máquina. Con esta medida, los pacientes pueden comparar precios entre diferentes hospitales y tomar decisiones de atención médica informadas. Para obtener más información, consulte Brindar transparencia en la cobertura de atención médica amigable para el consumidor en AWS.
Los datos de los archivos legibles por máquina pueden proporcionar información valiosa para comprender el costo real de los servicios de atención médica y comparar precios y calidad entre hospitales. La disponibilidad de archivos legibles por máquina abre nuevas posibilidades para el análisis de datos, permitiendo a las organizaciones analizar grandes cantidades de datos de precios. Utilizando herramientas de aprendizaje automático (ML) y visualización de datos, estos conjuntos de datos se pueden transformar en conocimientos prácticos que pueden informar la toma de decisiones.
En esta publicación, explicamos cómo las organizaciones de atención médica pueden utilizar los servicios de AWS para incorporar, analizar y generar información a partir de los datos de transparencia de precios creados por los hospitales. Utilizamos datos de muestra de tres hospitales diferentes, analizamos los datos y creamos tendencias comparativas y conocimientos a partir de los datos.
Resumen de la solución
Como parte de Centro de servicios de Medicare y Medicaid (CMS), todos los hospitales ahora tienen su archivo legible por máquina que contiene los datos de precios. A medida que los hospitales generan estos datos, pueden utilizar los datos de su organización o ingerir datos de otros hospitales para obtener análisis y comparaciones competitivas. Esta comparación puede ayudar a los hospitales a hacer lo siguiente:
- Deducir una base de precios para todos los servicios médicos y realizar un análisis de brechas
- Analizar tendencias de precios e identificar servicios donde los competidores no participan
- Evaluar e identificar los servicios donde la diferencia de costos está por encima de un umbral específico
El tamaño de los archivos legibles por máquina de los hospitales es menor que los generados por los pagadores. Esto se debe a la complejidad de la estructura JSON, los contratos y el proceso de evaluación de riesgos por parte del pagador. Debido a esta baja complejidad, la solución utiliza servicios sin servidor de AWS para ingerir los datos, transformarlos y ponerlos a disposición para análisis. El análisis de los archivos legibles por máquina de los pagadores requiere capacidades computacionales avanzadas debido a la complejidad y la interrelación en el archivo JSON.
Requisitos previos
Como requisito previo, evalúe los hospitales para los cuales se realizará el análisis de precios e identifique los archivos legibles por máquina para el análisis. Servicio de almacenamiento simple de Amazon (Amazon S3) es un servicio de almacenamiento de objetos que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento líderes en la industria. Cree carpetas separadas para cada hospital dentro del depósito S3.
Descripción de la arquitectura
La arquitectura utiliza tecnología sin servidor de AWS para la implementación. La arquitectura sin servidor presenta escalamiento automático, alta disponibilidad y un modelo de facturación de pago por uso para aumentar la agilidad y optimizar los costos. El enfoque arquitectónico se divide en una capa de entrada de datos, una capa de análisis de datos y una capa de visualización de datos.
La arquitectura contiene tres etapas independientes:
- Ingestión de archivos – Los hospitales negocian su contrato y precios con los pagadores una vez al año con revisiones periódicas trimestrales o mensuales. El proceso de ingesta de datos copia los archivos legibles por máquina de los hospitales, valida los datos y mantiene los archivos validados disponibles para su análisis.
- El análisis de datos – En esta etapa, los archivos se transforman usando Pegamento AWS y almacenado en el catálogo de datos de AWS Glue. AWS Glue es un servicio de integración de datos sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, aprendizaje automático y desarrollo de aplicaciones. Entonces puedes usar Atenea amazónica V3 para consultar las tablas del Catálogo de datos.
- Visualización de datos – Amazon QuickSight es un servicio de análisis empresarial basado en la nube que simplifica la creación de visualizaciones, la realización de análisis ad hoc y la obtención rápida de información empresarial a partir de los datos de precios. Esta etapa utiliza QuickSight para analizar visualmente los datos en el archivo legible por máquina mediante consultas de Athena.
Ingestión de archivos
El proceso de ingesta de archivos funciona como se define en la siguiente figura. La arquitectura utiliza AWS Lambda, un servicio informático sin servidor y controlado por eventos que le permite ejecutar código sin aprovisionar ni administrar servidores.
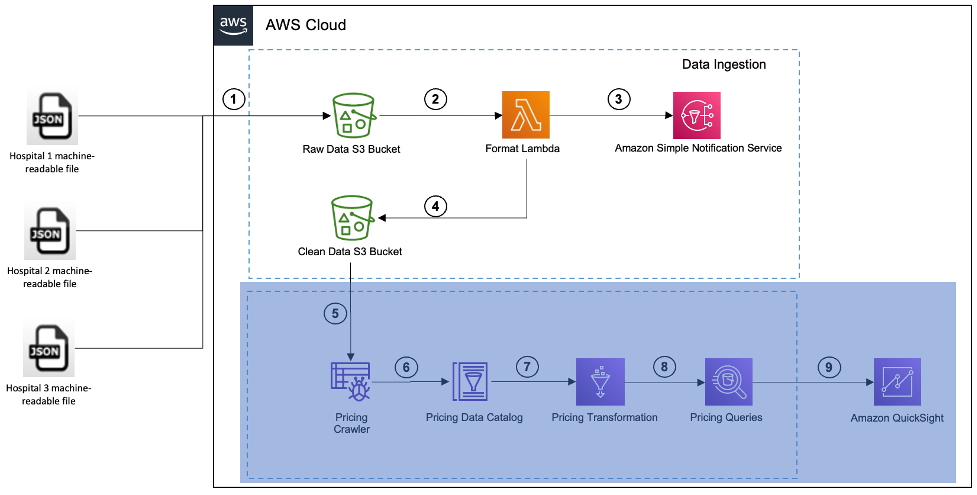
El siguiente flujo define el proceso para ingerir y analizar los datos:
- Copie los archivos legibles por máquina de los hospitales en el depósito S3 de datos sin procesar respectivo.
- La carga del archivo en el depósito de S3 desencadena un evento de S3, que invoca una función Lambda de formato.
- La función Lambda activa una notificación cuando identifica problemas en el archivo.
- La función Lambda ingiere el archivo, transforma los datos y almacena el archivo limpio en un nuevo depósito S3 de datos limpios.
Las organizaciones pueden crear nuevas funciones Lambda según la diferencia en los formatos de archivo.
El análisis de datos
Los procesos de admisión de archivos y análisis de datos son independientes entre sí. Mientras que la ingesta de archivos se realiza de forma programada o periódica, el análisis de datos se realiza periódicamente según las necesidades de la operación comercial. La arquitectura para el análisis de datos se muestra en la siguiente figura.
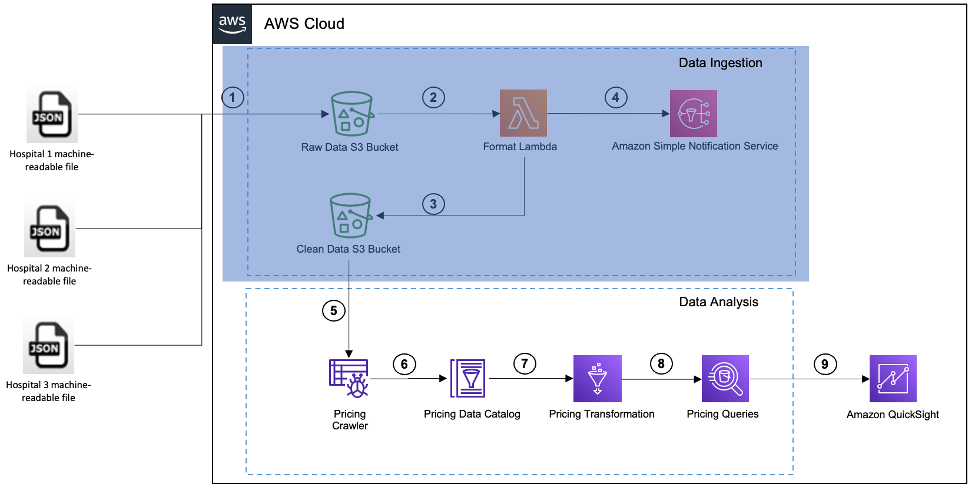
Esta etapa utiliza un rastreador de AWS Glue, el catálogo de datos de AWS Glue y Athena v3 para analizar los datos de los archivos legibles por máquina.
- Un pegamento AWS rastreador escanea los datos limpios en el depósito de S3 y crea o actualiza las tablas en el Catálogo de datos de AWS Glue. El rastreador puede ejecutarse según demanda o según una programación, y puede rastrear varios archivos legibles por máquina en una sola ejecución.
- El catálogo de datos ahora contiene referencias a los datos legibles por máquina. El catálogo de datos contiene la definición de la tabla, que contiene metadatos sobre los datos en el archivo legible por máquina. Las tablas se escriben en una base de datos, que actúa como contenedor.
- Utilice el Catálogo de datos y transforme los datos de transparencia de precios hospitalarios.
- Cuando los datos estén disponibles en el catálogo de datos, podrá desarrollar la consulta analítica utilizando Athena. Athena es un servicio de análisis interactivo sin servidor que proporciona una forma simplificada y flexible de analizar petabytes de datos mediante consultas SQL.
- Cualquier falla durante el proceso será capturada en el Reloj en la nube de Amazon registros, que se pueden utilizar para la resolución de problemas y el análisis. El catálogo de datos debe actualizarse solo cuando hay un cambio en la estructura del archivo legible por máquina o se carga un nuevo archivo legible por máquina en el depósito S3 limpio. Cuando el rastreador se ejecuta periódicamente, identifica automáticamente los cambios y actualiza el catálogo de datos.
Visualización de datos
Cuando se completa el análisis de datos y se desarrollan las consultas con Athena, podemos analizar visualmente los resultados y obtener información utilizando QuickSight. Como se muestra en la siguiente figura, una vez que se completan la ingesta y el análisis de datos, las consultas se crean utilizando Athena.
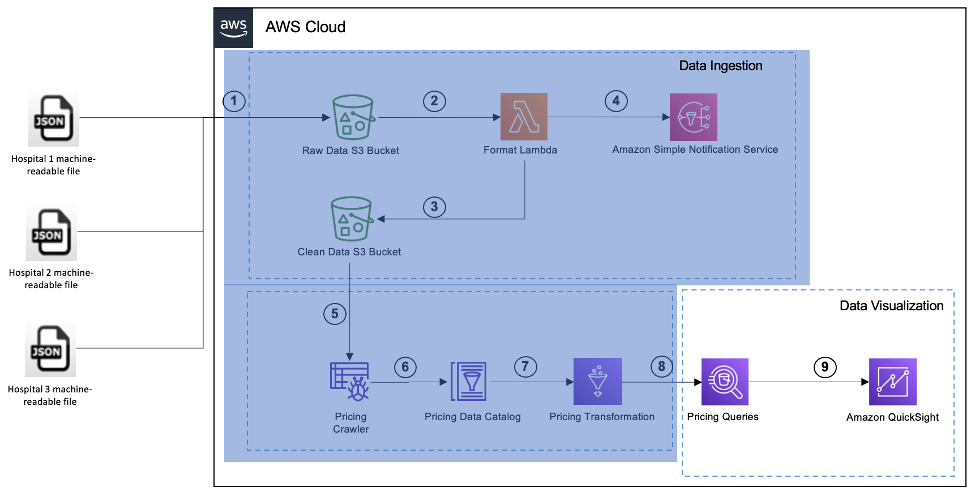
En esta etapa, utilizamos QuickSight para crear conjuntos de datos utilizando las consultas de Athena, crear visualizaciones e implementar paneles para análisis visuales e información.
Crear un conjunto de datos de QuickSight
Complete los siguientes pasos para crear un conjunto de datos QuickSight:
- En la consola de QuickSight, elija Administrar datos.
- En Conjuntos de datos página, elige Nuevo conjunto de datos.
- En Crear un conjunto de datos , elija el icono del perfil de conexión para la fuente de datos de Athena existente que desea utilizar.
- Elige Crear conjunto de datos.
- En Elige tu mesa página, elige Usar SQL personalizado e ingrese la consulta de Athena.
Una vez creado el conjunto de datos, puede agregar visualizaciones y analizar los datos del archivo legible por máquina. Con el panel QuickSight, las organizaciones pueden realizar fácilmente comparaciones de precios entre diferentes hospitales, identificar servicios de alto costo y encontrar otros valores atípicos de precios. Además, puede utilizar ML en QuickSight para obtener información basada en ML, detectar anomalías en los precios y crear pronósticos basados en archivos históricos.
La siguiente figura muestra un panel de QuickSight ilustrativo con información que compara los archivos legibles por máquina de tres hospitales diferentes. Con estos elementos visuales, puede comparar los datos de precios entre hospitales, crear puntos de referencia de precios, determinar hospitales rentables e identificar oportunidades para obtener ventajas competitivas.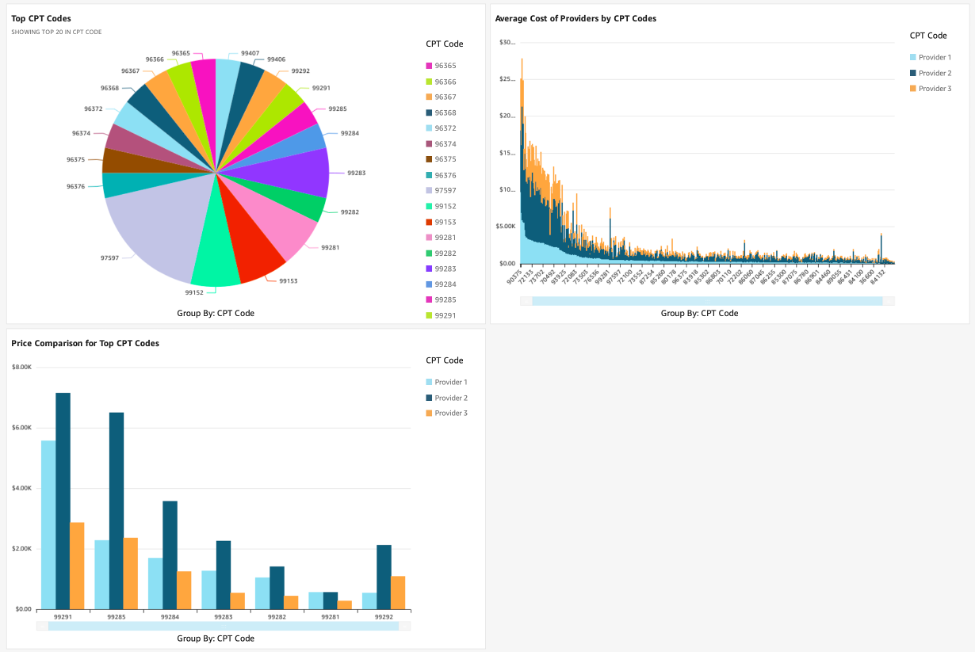
Consideraciones de rendimiento, operativas y de costos
La solución recomienda QuickSight Enterprise para visualización e información. Para los paneles de QuickSight, los resultados de la consulta de Athena se pueden almacenar en la base de datos SPICE para un mejor rendimiento.
El enfoque utiliza Atenea V3, que ofrece mejoras de rendimiento, mejoras de confiabilidad y funciones más nuevas. Utilizando el Función de reutilización de resultados de consultas de Athena permite el almacenamiento en caché y la reutilización de resultados de consultas. Cuando se ejecutan varias consultas idénticas con la opción de reutilización de resultados de la consulta, las consultas repetidas se ejecutan hasta cinco veces más rápido, lo que le brinda una mayor productividad para el análisis de datos interactivo. Como no escanea los datos, obtiene un rendimiento mejorado a un costo menor.
Cost
Los hospitales crean archivos legibles por máquina mensualmente. Este enfoque utiliza una arquitectura sin servidor que mantiene el costo bajo y elimina el desafío de los gastos generales de mantenimiento. El análisis puede comenzar con los archivos legibles por máquina de algunos hospitales y pueden agregar nuevos hospitales a medida que escalan. El siguiente ejemplo ayuda a comprender el costo de diferentes hospitales según el tamaño de los datos:
- A hospital tipico con 100 GB de almacenamiento al mes, consultar 20 GB de datos con 2 autores y 5 lectores, cuesta alrededor de $2,500 al año
AWS le ofrece una enfoque de pago por uso para conocer los precios de la gran mayoría de nuestros servicios en la nube. Con AWS, usted paga solo por los servicios individuales que necesita, mientras los utilice y sin necesidad de contratos a largo plazo ni licencias complejas.

Conclusión
Esta publicación ilustró cómo recopilar y analizar datos de transparencia de precios creados por hospitales y generar información utilizando los servicios de AWS. Este tipo de análisis y las visualizaciones proporcionan el marco para analizar los archivos legibles por máquina. Los hospitales, pagadores, corredores, aseguradores y otras partes interesadas en la atención médica pueden utilizar esta arquitectura para analizar y extraer información de los datos de precios publicados por los hospitales de su elección. Nuestros equipos de AWS pueden ayudarlo a identificar la estrategia correcta ofreciéndole liderazgo intelectual y soporte técnico prescriptivo para el análisis de transparencia de precios.
Póngase en contacto con su equipo de cuentas de AWS para obtener más ayuda sobre el diseño y explorar precios privados. Si aún no tiene un contacto con AWS, Por favor extiende la mano para conectarse con un representante de AWS.
Acerca de los autores
![]() Gokhul Srinivasan es un arquitecto de soluciones de socios senior que lidera los socios emergentes globales de atención médica y ciencias biológicas (HCLS) de AWS. Gokhul tiene más de 19 años de experiencia en el sector sanitario ayudando a las organizaciones con la transformación digital, la modernización de plataformas y la obtención de resultados comerciales.
Gokhul Srinivasan es un arquitecto de soluciones de socios senior que lidera los socios emergentes globales de atención médica y ciencias biológicas (HCLS) de AWS. Gokhul tiene más de 19 años de experiencia en el sector sanitario ayudando a las organizaciones con la transformación digital, la modernización de plataformas y la obtención de resultados comerciales.
![]() Laks Sundararajan es un arquitecto empresarial experimentado que ayuda a las empresas a restablecer, transformar y modernizar sus estrategias de TI, digitales, de nube, de datos y de conocimiento. Laks, un líder comprobado con experiencia significativa en IA generativa, digital, nube y transformación de datos/análisis, es un arquitecto de soluciones senior en atención médica y ciencias biológicas (HCLS).
Laks Sundararajan es un arquitecto empresarial experimentado que ayuda a las empresas a restablecer, transformar y modernizar sus estrategias de TI, digitales, de nube, de datos y de conocimiento. Laks, un líder comprobado con experiencia significativa en IA generativa, digital, nube y transformación de datos/análisis, es un arquitecto de soluciones senior en atención médica y ciencias biológicas (HCLS).
 Anil Chinnam es arquitecto de soluciones en el segmento de negocios nativos digitales en Amazon Web Services (AWS). Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS. Fuera del trabajo, a Anil le gusta ser padre, nadar y viajar.
Anil Chinnam es arquitecto de soluciones en el segmento de negocios nativos digitales en Amazon Web Services (AWS). Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS. Fuera del trabajo, a Anil le gusta ser padre, nadar y viajar.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-healthcare-organizations-can-analyze-and-create-insights-using-price-transparency-data/

