Esta publicación está coescrita con Aruna Abeyakoon y Denisse Colin de Light and Wonder (L&W).
Con sede en Las Vegas, luz y maravilla, inc. es la empresa líder mundial de juegos multiplataforma que ofrece productos y servicios de juego. Trabajando con AWS, Light & Wonder desarrolló recientemente una solución segura pionera en la industria, Light & Wonder Connect (LnW Connect), para transmitir datos de telemetría y estado de la máquina de aproximadamente medio millón de máquinas de juego electrónicas distribuidas en su base de clientes de casinos en todo el mundo cuando LnW Connect alcanza todo su potencial. Se monitorean más de 500 eventos de la máquina casi en tiempo real para brindar una imagen completa de las condiciones de la máquina y sus entornos operativos. Al utilizar datos transmitidos a través de LnW Connect, L&W tiene como objetivo crear una mejor experiencia de juego para sus usuarios finales y brindar más valor a sus clientes de casino.
Light & Wonder se asoció con el Laboratorio de soluciones de Amazon ML para usar datos de eventos transmitidos desde LnW Connect para habilitar el mantenimiento predictivo basado en aprendizaje automático (ML) para máquinas tragamonedas. El mantenimiento predictivo es un caso de uso común de ML para empresas con equipos físicos o activos de maquinaria. Con el mantenimiento predictivo, L&W puede recibir una advertencia anticipada de las fallas de la máquina y enviar de manera proactiva un equipo de servicio para inspeccionar el problema. Esto reducirá el tiempo de inactividad de las máquinas y evitará pérdidas significativas de ingresos para los casinos. Sin un sistema de diagnóstico remoto, la resolución de problemas por parte del equipo de servicio de Light & Wonder en el piso del casino puede ser costosa e ineficiente, al tiempo que degrada gravemente la experiencia de juego del cliente.
La naturaleza del proyecto es altamente exploratoria: este es el primer intento de mantenimiento predictivo en la industria del juego. El equipo de Amazon ML Solutions Lab y L&W se embarcó en un viaje integral desde la formulación del problema de ML y la definición de las métricas de evaluación hasta la entrega de una solución de alta calidad. El modelo ML final combina CNN y Transformer, que son las arquitecturas de redes neuronales de última generación para modelar datos de registro de máquinas secuenciales. La publicación presenta una descripción detallada de este viaje, ¡y esperamos que lo disfrutes tanto como nosotros!
En esta publicación, discutimos lo siguiente:
- Cómo formulamos el problema de mantenimiento predictivo como un problema de ML con un conjunto de métricas adecuadas para la evaluación
- Cómo preparamos los datos para el entrenamiento y las pruebas
- Técnicas de preprocesamiento de datos e ingeniería de características que empleamos para obtener modelos de alto rendimiento.
- Realización de un paso de ajuste de hiperparámetros con Ajuste automático de modelos de Amazon SageMaker
- Comparaciones entre el modelo de referencia y el modelo final de CNN+Transformer
- Técnicas adicionales que utilizamos para mejorar el rendimiento del modelo, como el ensamblaje
Antecedentes
En esta sección, discutimos los problemas que requirieron esta solución.
Conjunto de datos
Los entornos de máquinas tragamonedas están altamente regulados y se implementan en un entorno con espacios de aire. En LnW Connect, se diseñó un proceso de cifrado para proporcionar un mecanismo seguro y confiable para que los datos se transfieran a un lago de datos de AWS para el modelado predictivo. Los archivos agregados están cifrados y la clave de descifrado solo está disponible en Servicio de administración de claves de AWS (AWS KMS). Se configura una red privada basada en celular en AWS a través de la cual se cargaron los archivos en Servicio de almacenamiento simple de Amazon (Amazon S3).
LnW Connect transmite una amplia gama de eventos de la máquina, como el inicio del juego, el final del juego y más. El sistema recopila más de 500 tipos diferentes de eventos. Como se muestra a continuación
, cada evento se registra junto con una marca de tiempo de cuándo ocurrió y la identificación de la máquina que registra el evento. LnW Connect también registra cuando una máquina entra en un estado no reproducible, y se marcará como una falla o avería de la máquina si no se recupera a un estado reproducible dentro de un período de tiempo lo suficientemente corto.
| Identificador de máquina | Identificación del tipo de evento | Timestamp |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
Además de los eventos dinámicos de la máquina, también están disponibles metadatos estáticos sobre cada máquina. Esto incluye información como el identificador único de la máquina, el tipo de gabinete, la ubicación, el sistema operativo, la versión del software, el tema del juego y más, como se muestra en la siguiente tabla. (Todos los nombres en la tabla están anonimizados para proteger la información del cliente).
| Identificador de máquina | Tipo de gabinete | OS | Destino | Tema del juego |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | Resort y casino AA | Tormenta de soltera |
| 167 | B | OS_Ver1 | BB Casino Resort & Spa | UHMLIndia |
| 13 | C | OS_Ver0 | CC Casino y Hotel | excelentetigre |
| 307 | D | OS_Ver0 | DD Casino Resort | Reino de Neptuno |
| 70 | E | OS_Ver0 | EE Resort & Casino | RLPBoleto De Comida |
Definición del problema
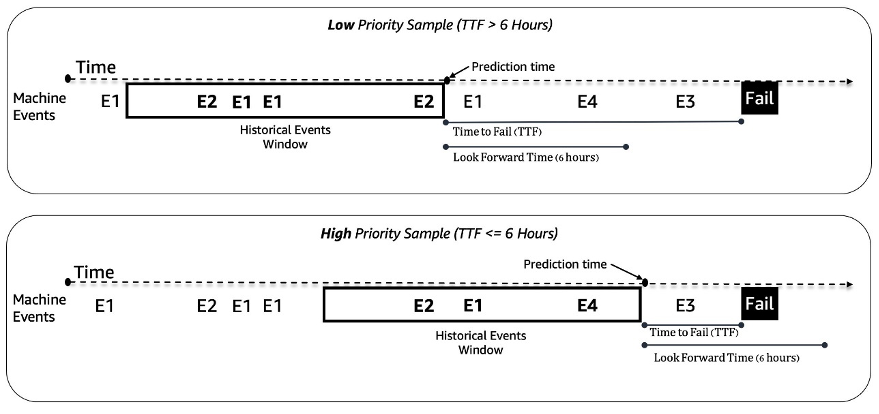
Tratamos el problema de mantenimiento predictivo de las máquinas tragamonedas como un problema de clasificación binaria. El modelo ML toma la secuencia histórica de eventos de la máquina y otros metadatos y predice si una máquina encontrará una falla en una ventana de tiempo futura de 6 horas. Si una máquina se descompone dentro de las 6 horas, se considera una máquina de alta prioridad para el mantenimiento. De lo contrario, es de baja prioridad. La siguiente figura ofrece ejemplos de muestras de prioridad baja (superior) y prioridad alta (inferior). Utilizamos una ventana de tiempo retrospectiva de longitud fija para recopilar datos históricos de eventos de la máquina para la predicción. Los experimentos muestran que las ventanas de tiempo retrospectivo más largas mejoran significativamente el rendimiento del modelo (más detalles más adelante en esta publicación).
Desafíos de modelado
Enfrentamos un par de desafíos para resolver este problema:
- Tenemos una gran cantidad de registros de eventos que contienen alrededor de 50 millones de eventos al mes (de aproximadamente 1,000 muestras de juegos). Se necesita una optimización cuidadosa en la etapa de extracción y preprocesamiento de datos.
- El modelado de secuencias de eventos fue un desafío debido a la distribución extremadamente desigual de los eventos a lo largo del tiempo. Una ventana de 3 horas puede contener desde decenas hasta miles de eventos.
- Las máquinas están en buen estado la mayor parte del tiempo y el mantenimiento de alta prioridad es una clase rara, lo que introdujo un problema de desequilibrio de clase.
- Se agregan nuevas máquinas continuamente al sistema, por lo que teníamos que asegurarnos de que nuestro modelo pudiera manejar la predicción en nuevas máquinas que nunca se habían visto en entrenamiento.
Preprocesamiento de datos e ingeniería de funciones
En esta sección, analizamos nuestros métodos para la preparación de datos y la ingeniería de características.
Ingeniería de características
Los feeds de máquinas tragamonedas son flujos de eventos de series de tiempo desigualmente espaciados; por ejemplo, la cantidad de eventos en una ventana de 3 horas puede oscilar entre decenas y miles. Para manejar este desequilibrio, usamos frecuencias de eventos en lugar de datos de secuencia sin procesar. Un enfoque directo es agregar la frecuencia de eventos para toda la ventana retrospectiva e introducirla en el modelo. Sin embargo, al usar esta representación, la información temporal se pierde y el orden de los eventos no se conserva. En su lugar, utilizamos la agrupación temporal dividiendo la ventana de tiempo en N subventanas iguales y calculando las frecuencias de eventos en cada una. Las características finales de una ventana de tiempo son la concatenación de todas sus características de subventana. Aumentar el número de contenedores conserva más información temporal. La siguiente figura ilustra el agrupamiento temporal en una ventana de muestra.
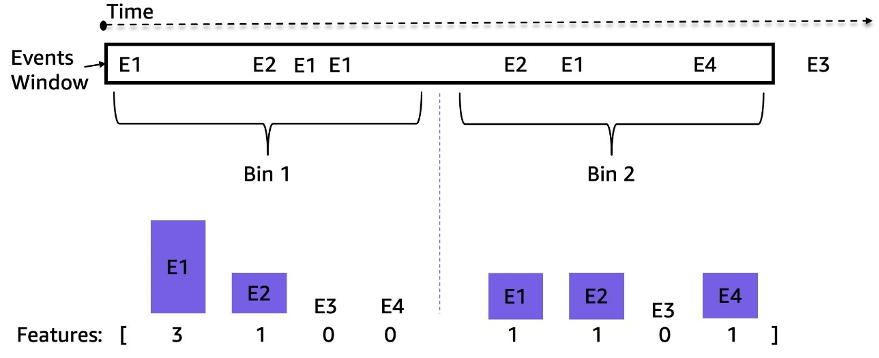
Primero, la ventana de tiempo de la muestra se divide en dos subventanas iguales (contenedores); aquí usamos solo dos contenedores para simplificar la ilustración. Luego, se calculan los recuentos de los eventos E1, E2, E3 y E4 en cada intervalo. Por último, se concatenan y se utilizan como características.
Junto con las funciones basadas en la frecuencia de eventos, utilizamos funciones específicas de la máquina, como la versión del software, el tipo de gabinete, el tema del juego y la versión del juego. Además, agregamos funciones relacionadas con las marcas de tiempo para capturar la estacionalidad, como la hora del día y el día de la semana.
Preparación de datos
Para extraer datos de manera eficiente para la capacitación y las pruebas, utilizamos Amazon Athena y el catálogo de datos de AWS Glue. Los datos de eventos se almacenan en Amazon S3 en formato Parquet y se dividen según el día/mes/hora. Esto facilita la extracción eficiente de muestras de datos dentro de una ventana de tiempo específica. Usamos los datos de todas las máquinas en el último mes para las pruebas y el resto de los datos para el entrenamiento, lo que ayuda a evitar posibles fugas de datos.
Metodología ML y entrenamiento de modelos
En esta sección, analizamos nuestro modelo de referencia con AutoGluon y cómo creamos una red neuronal personalizada con el ajuste automático del modelo de SageMaker.
Creación de un modelo de referencia con AutoGluon
Con cualquier caso de uso de ML, es importante establecer un modelo de referencia que se utilizará para la comparación y la iteración. Nosotros usamos AutoGluón para explorar varios algoritmos clásicos de ML. AutoGluon es una herramienta AutoML fácil de usar que utiliza el procesamiento automático de datos, el ajuste de hiperparámetros y el conjunto de modelos. La mejor línea de base se logró con un conjunto ponderado de modelos de árboles de decisión potenciados por gradiente. La facilidad de uso de AutoGluon nos ayudó en la etapa de descubrimiento a navegar de manera rápida y eficiente a través de una amplia gama de datos posibles y direcciones de modelado de ML.
Creación y ajuste de un modelo de red neuronal personalizado con el ajuste automático de modelos de SageMaker
Después de experimentar con diferentes arquitecturas de redes neuronales, creamos un modelo personalizado de aprendizaje profundo para el mantenimiento predictivo. Nuestro modelo superó el modelo de referencia de AutoGluon en un 121 % en recuperación con un 80 % de precisión. El modelo final ingiere datos de secuencias de eventos de máquinas históricas, características de tiempo como la hora del día y metadatos de máquinas estáticas. utilizamos Ajuste automático del modelo SageMaker trabajos para buscar los mejores hiperparámetros y arquitecturas modelo.
La siguiente figura muestra la arquitectura del modelo. Primero normalizamos los datos de la secuencia de eventos agrupados por frecuencias promedio de cada evento en el conjunto de entrenamiento para eliminar el efecto abrumador de los eventos de alta frecuencia (comienzo del juego, final del juego, etc.). Las incrustaciones de eventos individuales se pueden aprender, mientras que las incrustaciones de características temporales (día de la semana, hora del día) se extraen mediante el paquete Gluones. Luego concatenamos los datos de la secuencia de eventos con las incrustaciones de características temporales como entrada al modelo. El modelo consta de las siguientes capas:
- Capas convolucionales (CNN) – Cada capa CNN consta de dos operaciones convolucionales unidimensionales con conexiones residuales. La salida de cada capa CNN tiene la misma longitud de secuencia que la entrada para permitir un fácil apilamiento con otros módulos. El número total de capas CNN es un hiperparámetro sintonizable.
- Capas de codificador de transformador (TRANS) – La salida de las capas CNN se alimenta junto con la codificación posicional a una estructura de autoatención de varios cabezales. Usamos TRANS para capturar directamente las dependencias temporales en lugar de usar redes neuronales recurrentes. Aquí, el agrupamiento de los datos de secuencia sin procesar (reduciendo la longitud de miles a cientos) ayuda a aliviar los cuellos de botella de la memoria de la GPU, al tiempo que mantiene la información cronológica en un grado ajustable (el número de contenedores es un hiperparámetro ajustable).
- Capas de agregación (AGG) – La capa final combina la información de metadatos (tipo de tema de juego, tipo de gabinete, ubicaciones) para producir la predicción de probabilidad de nivel de prioridad. Consta de varias capas de agrupación y capas totalmente conectadas para la reducción de la dimensión incremental. Las incrustaciones multiactivas de metadatos también se pueden aprender y no pasan por las capas CNN y TRANS porque no contienen información secuencial.
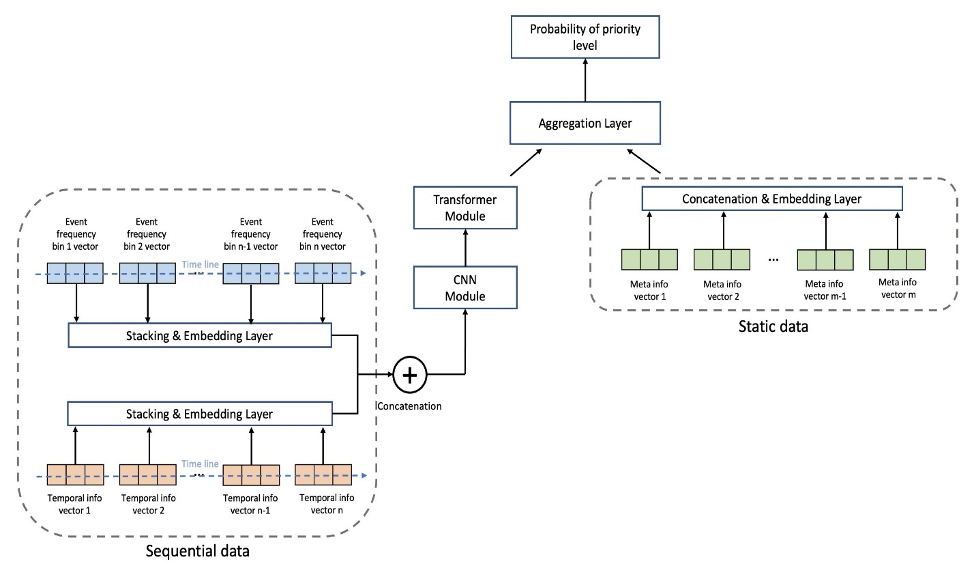
Usamos la pérdida de entropía cruzada con pesos de clase como hiperparámetros ajustables para ajustar el problema del desequilibrio de clase. Además, el número de capas CNN y TRANS son hiperparámetros cruciales con los valores posibles de 0, lo que significa que es posible que no siempre existan capas específicas en la arquitectura del modelo. De esta manera, tenemos un marco unificado donde se buscan las arquitecturas del modelo junto con otros hiperparámetros habituales.
Utilizamos el ajuste automático del modelo de SageMaker, también conocido como optimización de hiperparámetros (HPO), para explorar de manera eficiente las variaciones del modelo y el gran espacio de búsqueda de todos los hiperparámetros. El ajuste automático del modelo recibe el algoritmo personalizado, los datos de entrenamiento y las configuraciones del espacio de búsqueda de hiperparámetros, y busca los mejores hiperparámetros utilizando diferentes estrategias, como bayesiana, hiperbanda y más, con varias instancias de GPU en paralelo. Después de evaluar en un conjunto de validación de espera, obtuvimos la mejor arquitectura modelo con dos capas de CNN, una capa de TRANS con cuatro cabezas y una capa AGG.
Usamos los siguientes rangos de hiperparámetros para buscar la mejor arquitectura modelo:
Para mejorar aún más la precisión del modelo y reducir la varianza del modelo, entrenamos el modelo con múltiples inicializaciones de peso aleatorio independientes y agregamos el resultado con valores medios como la predicción de probabilidad final. Existe una compensación entre más recursos informáticos y un mejor rendimiento del modelo, y observamos que 5–10 debería ser un número razonable en el caso de uso actual (los resultados se muestran más adelante en esta publicación).
Resultados de rendimiento del modelo
En esta sección, presentamos las métricas y los resultados de la evaluación del desempeño del modelo.
Métricas de evaluación
La precisión es muy importante para este caso de uso de mantenimiento predictivo. La baja precisión significa informar más llamadas de mantenimiento falsas, lo que aumenta los costos debido a un mantenimiento innecesario. Debido a que la precisión promedio (AP) no se alinea completamente con el objetivo de alta precisión, introdujimos una nueva métrica denominada recuperación promedio con precisión alta (ARHP). ARHP es igual al promedio de retiros en puntos de precisión del 60%, 70% y 80%. También usamos la precisión en el K% superior (K=1, 10), AUPR y AUROC como métricas adicionales.
Resultados
La siguiente tabla resume los resultados utilizando los modelos de red neuronal de referencia y personalizados, con el 7/1/2022 como el punto de división de entrenamiento/prueba. Los experimentos muestran que aumentar la longitud de la ventana y el tamaño de los datos de muestra mejoran el rendimiento del modelo, ya que contienen más información histórica para ayudar con la predicción. Independientemente de la configuración de datos, el modelo de red neuronal supera a AutoGluon en todas las métricas. Por ejemplo, la recuperación con una precisión fija del 80 % aumenta en un 121 %, lo que le permite identificar rápidamente más máquinas que funcionan mal si utiliza el modelo de red neuronal.
| Modelo | Longitud de ventana/Tamaño de datos | AUROC | AUPR | ARHP | Recordar@Prec0.6 | Recordar@Prec0.7 | Recordar@Prec0.8 | Prec@superior1% | Prec@superior10% |
|---|---|---|---|---|---|---|---|---|---|
| Línea base de AutoGluon | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Red neuronal | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| Línea base de AutoGluon | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Red neuronal | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
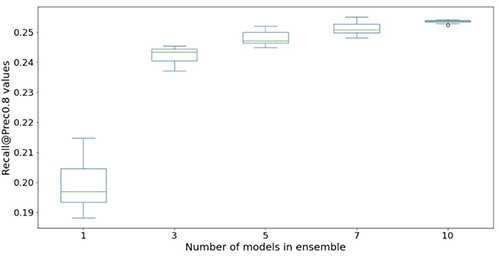
Las siguientes figuras ilustran el efecto del uso de conjuntos para mejorar el rendimiento del modelo de red neuronal. Se han mejorado todas las métricas de evaluación que se muestran en el eje x, con una media más alta (más precisa) y una varianza más baja (más estable). Cada diagrama de caja es de 12 experimentos repetidos, desde ningún conjunto hasta 10 modelos en conjuntos (eje x). Persisten tendencias similares en todas las métricas además de Prec@top1% y Recall@Prec80% que se muestran.
Después de tener en cuenta el costo computacional, observamos que el uso de 5 a 10 modelos en conjuntos es adecuado para conjuntos de datos de Light & Wonder.

Conclusión
Nuestra colaboración ha dado como resultado la creación de una innovadora solución de mantenimiento predictivo para la industria del juego, así como un marco reutilizable que podría utilizarse en una variedad de escenarios de mantenimiento predictivo. La adopción de tecnologías de AWS, como el ajuste automático de modelos de SageMaker, facilita que Light & Wonder navegue por nuevas oportunidades utilizando flujos de datos casi en tiempo real. Light & Wonder está comenzando la implementación en AWS.
Si desea ayuda para acelerar el uso de ML en sus productos y servicios, comuníquese con el Laboratorio de soluciones de Amazon ML .
Sobre los autores
 Aruna Abeyakoon es el director sénior de Data Science & Analytics en Light & Wonder Land-based Gaming Division. Aruna lidera la primera iniciativa Light & Wonder Connect de la industria y apoya tanto a los socios de casino como a las partes interesadas internas con el comportamiento del consumidor y los conocimientos del producto para crear mejores juegos, optimizar las ofertas de productos, administrar activos y monitorear la salud y el mantenimiento predictivo.
Aruna Abeyakoon es el director sénior de Data Science & Analytics en Light & Wonder Land-based Gaming Division. Aruna lidera la primera iniciativa Light & Wonder Connect de la industria y apoya tanto a los socios de casino como a las partes interesadas internas con el comportamiento del consumidor y los conocimientos del producto para crear mejores juegos, optimizar las ofertas de productos, administrar activos y monitorear la salud y el mantenimiento predictivo.
 Denisse Colín es gerente sénior de ciencia de datos en Light & Wonder, una empresa global líder en juegos multiplataforma. Es miembro del equipo de Gaming Data & Analytics que ayuda a desarrollar soluciones innovadoras para mejorar el rendimiento del producto y las experiencias de los clientes a través de Light & Wonder Connect.
Denisse Colín es gerente sénior de ciencia de datos en Light & Wonder, una empresa global líder en juegos multiplataforma. Es miembro del equipo de Gaming Data & Analytics que ayuda a desarrollar soluciones innovadoras para mejorar el rendimiento del producto y las experiencias de los clientes a través de Light & Wonder Connect.
 Tesfagabir Meharizghi es científico de datos en Amazon ML Solutions Lab, donde ayuda a los clientes de AWS en diversas industrias, como juegos, atención médica y ciencias de la vida, fabricación, automoción y deportes y medios, a acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus negocios. retos
Tesfagabir Meharizghi es científico de datos en Amazon ML Solutions Lab, donde ayuda a los clientes de AWS en diversas industrias, como juegos, atención médica y ciencias de la vida, fabricación, automoción y deportes y medios, a acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus negocios. retos
 Mohamad Al Jazaery es científico aplicado en Amazon ML Solutions Lab. Ayuda a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar sus desafíos comerciales en áreas como logística, personalización y recomendaciones, visión artificial, prevención de fraudes, pronósticos y optimización de la cadena de suministro.
Mohamad Al Jazaery es científico aplicado en Amazon ML Solutions Lab. Ayuda a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar sus desafíos comerciales en áreas como logística, personalización y recomendaciones, visión artificial, prevención de fraudes, pronósticos y optimización de la cadena de suministro.
 YaweiWang es científico aplicado en Amazon ML Solution Lab. Ayuda a los socios comerciales de AWS a identificar y crear soluciones de aprendizaje automático para abordar los desafíos comerciales de su organización en un escenario del mundo real.
YaweiWang es científico aplicado en Amazon ML Solution Lab. Ayuda a los socios comerciales de AWS a identificar y crear soluciones de aprendizaje automático para abordar los desafíos comerciales de su organización en un escenario del mundo real.
 yun zhou es un científico aplicado en Amazon ML Solutions Lab, donde ayuda con la investigación y el desarrollo para garantizar el éxito de los clientes de AWS. Trabaja en soluciones pioneras para diversas industrias utilizando técnicas de modelado estadístico y aprendizaje automático. Su interés incluye modelos generativos y modelado secuencial de datos.
yun zhou es un científico aplicado en Amazon ML Solutions Lab, donde ayuda con la investigación y el desarrollo para garantizar el éxito de los clientes de AWS. Trabaja en soluciones pioneras para diversas industrias utilizando técnicas de modelado estadístico y aprendizaje automático. Su interés incluye modelos generativos y modelado secuencial de datos.
 Panpan Xu es administrador de ciencias aplicadas en Amazon ML Solutions Lab en AWS. Está trabajando en la investigación y el desarrollo de algoritmos de aprendizaje automático para aplicaciones de clientes de alto impacto en una variedad de verticales industriales para acelerar su adopción de la nube y la inteligencia artificial. Su interés de investigación incluye la interpretabilidad del modelo, el análisis causal, la IA humana en el circuito y la visualización interactiva de datos.
Panpan Xu es administrador de ciencias aplicadas en Amazon ML Solutions Lab en AWS. Está trabajando en la investigación y el desarrollo de algoritmos de aprendizaje automático para aplicaciones de clientes de alto impacto en una variedad de verticales industriales para acelerar su adopción de la nube y la inteligencia artificial. Su interés de investigación incluye la interpretabilidad del modelo, el análisis causal, la IA humana en el circuito y la visualización interactiva de datos.
 Raj Salvaji lidera la arquitectura de soluciones en el segmento de hospitalidad en AWS. Trabaja con clientes de la industria hotelera proporcionando orientación estratégica y experiencia técnica para crear soluciones a desafíos comerciales complejos. Se basa en 25 años de experiencia en múltiples roles de ingeniería en las industrias hotelera, financiera y automotriz.
Raj Salvaji lidera la arquitectura de soluciones en el segmento de hospitalidad en AWS. Trabaja con clientes de la industria hotelera proporcionando orientación estratégica y experiencia técnica para crear soluciones a desafíos comerciales complejos. Se basa en 25 años de experiencia en múltiples roles de ingeniería en las industrias hotelera, financiera y automotriz.
 shane rai es un estratega principal de ML en Amazon ML Solutions Lab en AWS. Trabaja con clientes en un espectro diverso de industrias para resolver sus necesidades comerciales más apremiantes e innovadoras utilizando la amplitud de servicios de IA/ML basados en la nube de AWS.
shane rai es un estratega principal de ML en Amazon ML Solutions Lab en AWS. Trabaja con clientes en un espectro diverso de industrias para resolver sus necesidades comerciales más apremiantes e innovadoras utilizando la amplitud de servicios de IA/ML basados en la nube de AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-light-wonder-built-a-predictive-maintenance-solution-for-gaming-machines-on-aws/

