Esta es una publicación invitada coescrita por Alex Naumov, arquitecto principal de datos de smava.
smava GmbH es una de las empresas de servicios financieros líderes en Alemania y ofrece préstamos personales transparentes, justos y asequibles para los consumidores. Basándose en procesos digitales, smava compara ofertas de préstamos de más de 20 bancos. De esta forma, los prestatarios pueden elegir las ofertas que les resulten más favorables de forma rápida, digitalizada y eficiente.
smava cree en las decisiones basadas en datos y las aprovecha para convertirse en líder del mercado. El equipo de Data Platform es responsable de respaldar las decisiones basadas en datos en smava proporcionando productos de datos en todos los departamentos y sucursales de la empresa. Los departamentos incluyen equipos que van desde ingeniería hasta ventas y marketing. Las sucursales varían por productos, a saber, préstamos B2C, préstamos B2B y, anteriormente, también hipotecas B2C. Los productos de datos utilizados dentro de la empresa incluyen información sobre los recorridos de los usuarios, informes operativos y resultados de campañas de marketing, entre otros. La plataforma de datos atiende en promedio 60 mil consultas por día. El volumen de datos es de TB de dos dígitos con un crecimiento constante a medida que evolucionan los negocios y las fuentes de datos.
El equipo de plataforma de datos de smava enfrentó el desafío de entregar datos a las partes interesadas con diferentes SLA, manteniendo al mismo tiempo la flexibilidad de escalar hacia arriba y hacia abajo sin dejar de ser rentable. Se necesitaron hasta 3 horas para generar informes diarios, lo que afectó la toma de decisiones comerciales cuando era necesario realizar nuevos cálculos durante el día. Para acelerar el análisis de autoservicio y fomentar la innovación basada en datos, se necesitaba una solución que proporcionara formas que permitieran a cualquier equipo crear productos de datos por su cuenta de forma descentralizada. Para crear y gestionar los productos de datos, smava utiliza Desplazamiento al rojo de Amazon, un almacén de datos en la nube.
En esta publicación, mostramos cómo smava optimizó su plataforma de datos utilizando Amazon Redshift sin servidor y Uso compartido de datos de Amazon Redshift para superar los desafíos de dimensionamiento adecuado para cargas de trabajo impredecibles y mejorar aún más la relación precio-rendimiento. Gracias a las optimizaciones, smava logró un ahorro de costos de hasta un 50 % y una generación de informes hasta tres veces más rápida en comparación con la infraestructura de análisis anterior.
Resumen de la solución
Como empresa basada en datos, smava confía en la nube de AWS para impulsar sus casos de uso de análisis. Para ofrecer a sus clientes las mejores ofertas y experiencia de usuario, smava sigue el arquitectura de datos moderna principios con un lago de datos como un almacén de datos escalable y duradero y almacenes de datos diseñados específicamente para el procesamiento analítico y el consumo de datos.
smava ingiere datos de varias fuentes de datos externas e internas en una etapa de aterrizaje en el lago de datos en función de Servicio de almacenamiento simple de Amazon (Amazon S3). Para ingerir los datos, smava utiliza un conjunto de plataformas populares de datos de clientes de terceros complementadas con scripts personalizados.
Después de que los datos llegan a Amazon S3, smava utiliza el Pegamento AWS Catálogo de datos y rastreadores para catalogar automáticamente los datos disponibles, capturar los metadatos y proporcionar una interfaz que permita consultar todos los activos de datos.
Los analistas de datos que requieren acceso a los activos sin procesar en el uso del lago de datos Atenea amazónica, un servicio de análisis interactivo sin servidor para exploración con consultas ad hoc. Para el consumo posterior de todos los departamentos de la organización, el equipo de plataforma de datos de smava prepara productos de datos seleccionados siguiendo las extraer, cargar y transformar (ELT) patrón. smava utiliza Amazon Redshift como su almacén de datos en la nube para transformar, almacenar y analizar datos, y utiliza Espectro de Redshift de Amazon para consultar y recuperar de manera eficiente datos estructurados y semiestructurados del lago de datos utilizando SQL.
smava sigue el modelado de bóveda de datos metodología con las etapas Raw Vault, Business Vault y Data Mart para preparar los productos de datos para los consumidores finales. Raw Vault describe objetos cargados directamente desde las fuentes de datos y representa una copia de la etapa de aterrizaje en el lago de datos. Business Vault se completa con datos procedentes de Raw Vault y se transforman de acuerdo con las reglas comerciales. Finalmente, los datos se agregan en productos de datos específicos orientados a una línea de negocio específica. Este es el Data Mart escenario. Los productos de datos de las etapas Business Vault y Data Mart ahora están disponibles para los consumidores. smava decidió utilizar Tableau para inteligencia empresarial, visualización de datos y análisis adicionales. Las transformaciones de datos se gestionan con dbt para simplificar la gobernanza del flujo de trabajo y la colaboración en equipo.
El siguiente diagrama muestra la arquitectura de la plataforma de datos de alto nivel antes de las optimizaciones.
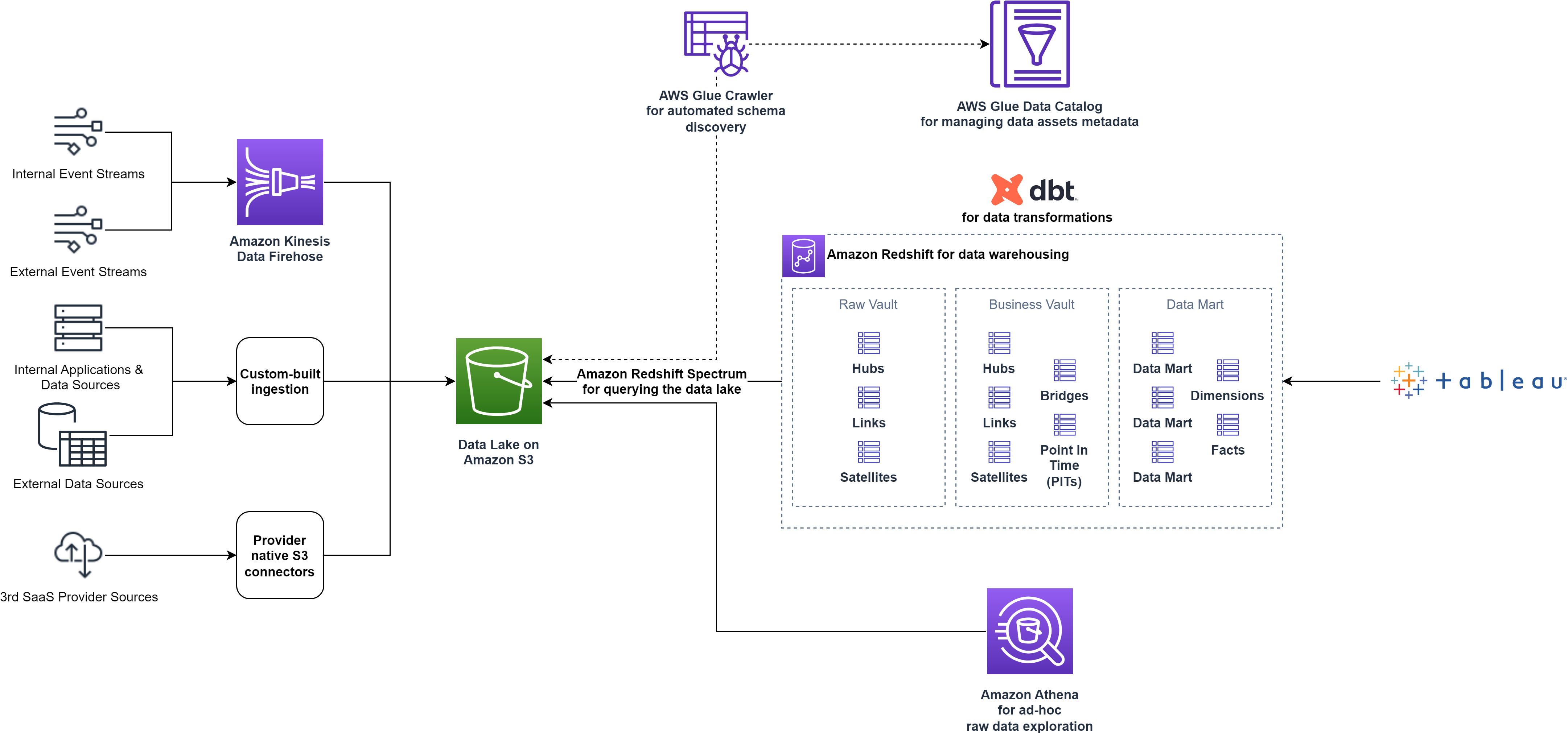
Evolución de los requisitos de la plataforma de datos.
smava comenzó con un único clúster Redshift para alojar las tres etapas de datos. Eligieron nodos de clúster aprovisionados del tipo RA3 Instancias reservadas (RI) para la optimización de costos. A medida que los volúmenes de datos crecieron un 53 % año tras año, también lo hicieron la complejidad y los requisitos de diversas cargas de trabajo analíticas.
smava abordó rápidamente los crecientes volúmenes de datos ajustando el tamaño correcto del clúster y utilizando Escalado de simultaneidad de Amazon Redshift para cargas de trabajo máximas. Además, smava quería dar a todos los equipos la opción de crear sus propios productos de datos de forma autoservicio para acelerar el ritmo de innovación. Para evitar cualquier interferencia con los productos de datos administrados centralmente, los entornos de desarrollo de productos descentralizados debían estar estrictamente aislados. También se aplicó el mismo requisito para el aislamiento de diferentes etapas del producto seleccionadas por el equipo de Data Platform.
Optimización de la arquitectura con intercambio de datos y Redshift Serverless
Para cumplir con los requisitos evolucionados, smava decidió separar la carga de trabajo dividiendo el único clúster Redshift aprovisionado en múltiples almacenes de datos, donde cada almacén atiende una etapa diferente. Además, smava agregó nuevos entornos de prueba en Business Vault para desarrollar nuevos productos de datos sin el riesgo de interferir con los canales de productos existentes. Para evitar cualquier interferencia con los productos de datos administrados centralmente del equipo de la plataforma de datos, smava introdujo un clúster Redshift adicional, aislando las cargas de trabajo descentralizadas.
smava buscaba una solución lista para usar para lograr el aislamiento de la carga de trabajo sin administrar un proceso complejo de replicación de datos.
Justo después del lanzamiento de Intercambio de datos de corrimiento al rojo capacidades en 2021, el equipo de Data Platform reconoció que esta era la solución que habían estado buscando. smava adoptó la función de intercambio de datos para tener los datos de los grupos de productores disponibles para acceso de lectura en diferentes grupos de consumidores, y cada uno de esos grupos de consumidores sirve a una etapa diferente.
El intercambio de datos de Redshift permite un acceso instantáneo, granular y rápido a los datos en todos los clústeres de Redshift sin necesidad de copiar datos. Proporciona acceso en vivo a los datos para que los usuarios siempre vean la información más actualizada y consistente a medida que se actualiza en el almacén de datos. Al compartir datos, puede compartir de forma segura datos en vivo con clústeres de Redshift en la misma o diferentes cuentas de AWS y entre regiones.
Con el intercambio de datos de Redshift, smava pudo optimizar la arquitectura de datos separando las cargas de trabajo de datos en grupos de consumidores individuales sin tener que replicar los datos. El siguiente diagrama ilustra la arquitectura de la plataforma de datos de alto nivel después de dividir el único clúster de Redshift en varios clústeres.
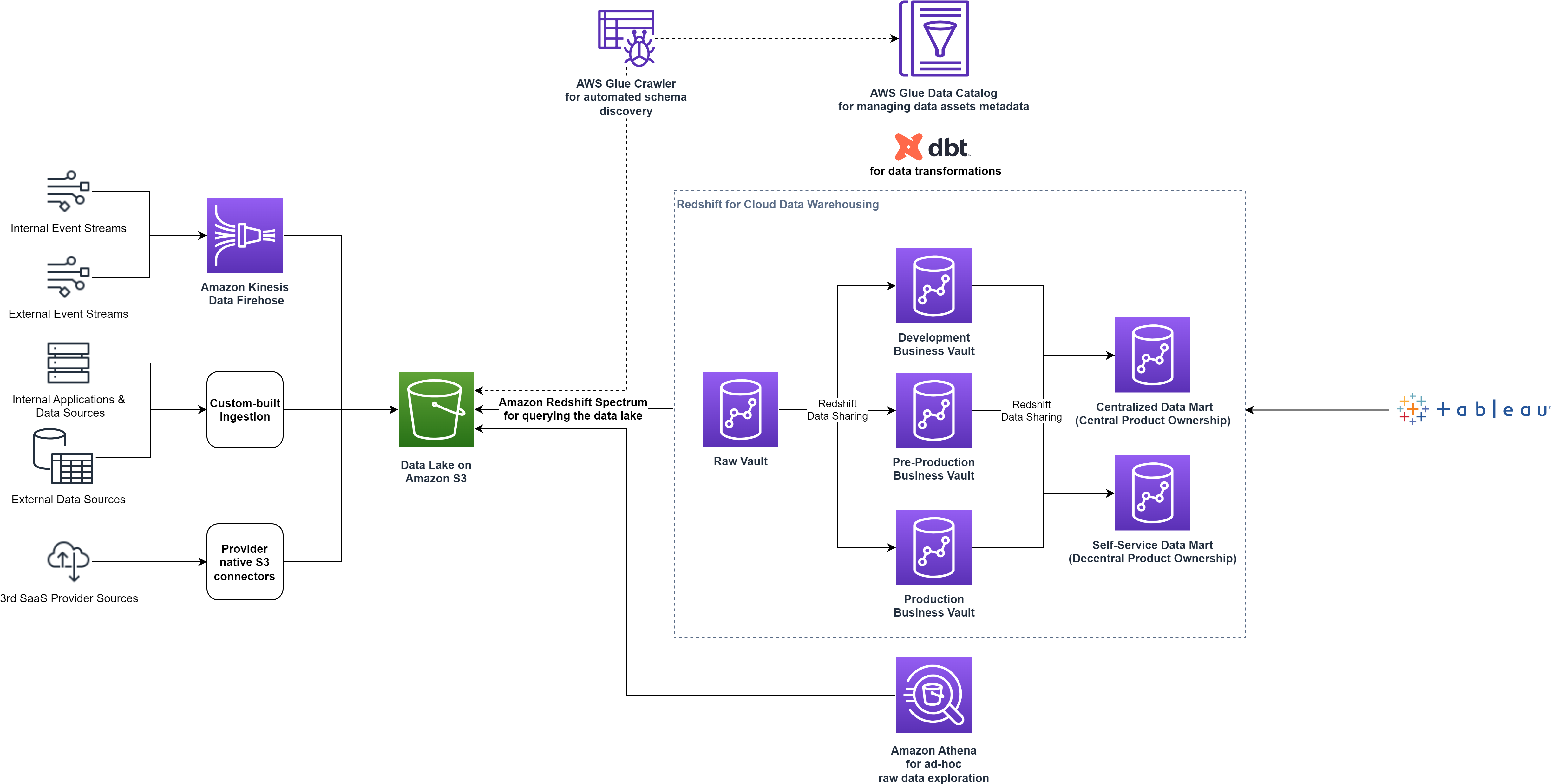
Al proporcionar un mercado de datos de autoservicio, smava aumentó la democratización de los datos al brindar a los usuarios acceso a todos los aspectos de los datos. También proporcionaron a los equipos un conjunto de herramientas personalizadas para el descubrimiento de datos, el análisis ad hoc, la creación de prototipos y la operación del ciclo de vida completo de productos de datos maduros.
Después de recopilar datos operativos de los clústeres individuales, el equipo de la plataforma de datos identificó otras optimizaciones potenciales: el clúster Raw Vault estaba bajo carga constante las 24 horas del día, los 7 días de la semana, pero los clústeres Business Vault solo se actualizaban cada noche. Para optimizar los costes, smava utilizó el capacidades de pausa y reanudación de clústeres aprovisionados por Redshift. Estas capacidades son útiles para clústeres que necesitan estar disponibles en momentos específicos. Mientras el clúster está en pausa, se suspende la facturación bajo demanda. Sólo el almacenamiento del clúster genera cargos.
La función de pausa y reanudación ayudó a smava a optimizar los costos, pero requirió una sobrecarga operativa adicional para activar las operaciones del clúster. Además, los clusters de desarrollo continuaron sujetos a tiempos muertos durante las horas de trabajo. Estos desafíos finalmente se resolvieron mediante la adopción de Redshift Serverless en 2022. El equipo de Data Platform decidió trasladar los clústeres de la etapa Business Data Vault a Redshift Serverless, lo que les permite pagar por el almacén de datos solo cuando está en uso, de manera confiable y eficiente.
Redshift Serverless es ideal para casos en los que es difícil predecir las necesidades informáticas, como cargas de trabajo variables, cargas de trabajo periódicas con tiempo de inactividad y cargas de trabajo de estado estable con picos. Además, a medida que la demanda de uso evoluciona con nuevas cargas de trabajo y más usuarios simultáneos, Redshift Serverless aprovisiona automáticamente los recursos informáticos adecuados y el almacén de datos se escala de forma fluida y automática, sin necesidad de intervención manual. El intercambio de datos se admite en ambas direcciones entre Redshift Serverless y los clústeres Redshift aprovisionados con nodos RA3, por lo que no fue necesario realizar cambios en la arquitectura smava. El siguiente diagrama muestra la configuración de la arquitectura de alto nivel después del cambio a Redshift Serverless.
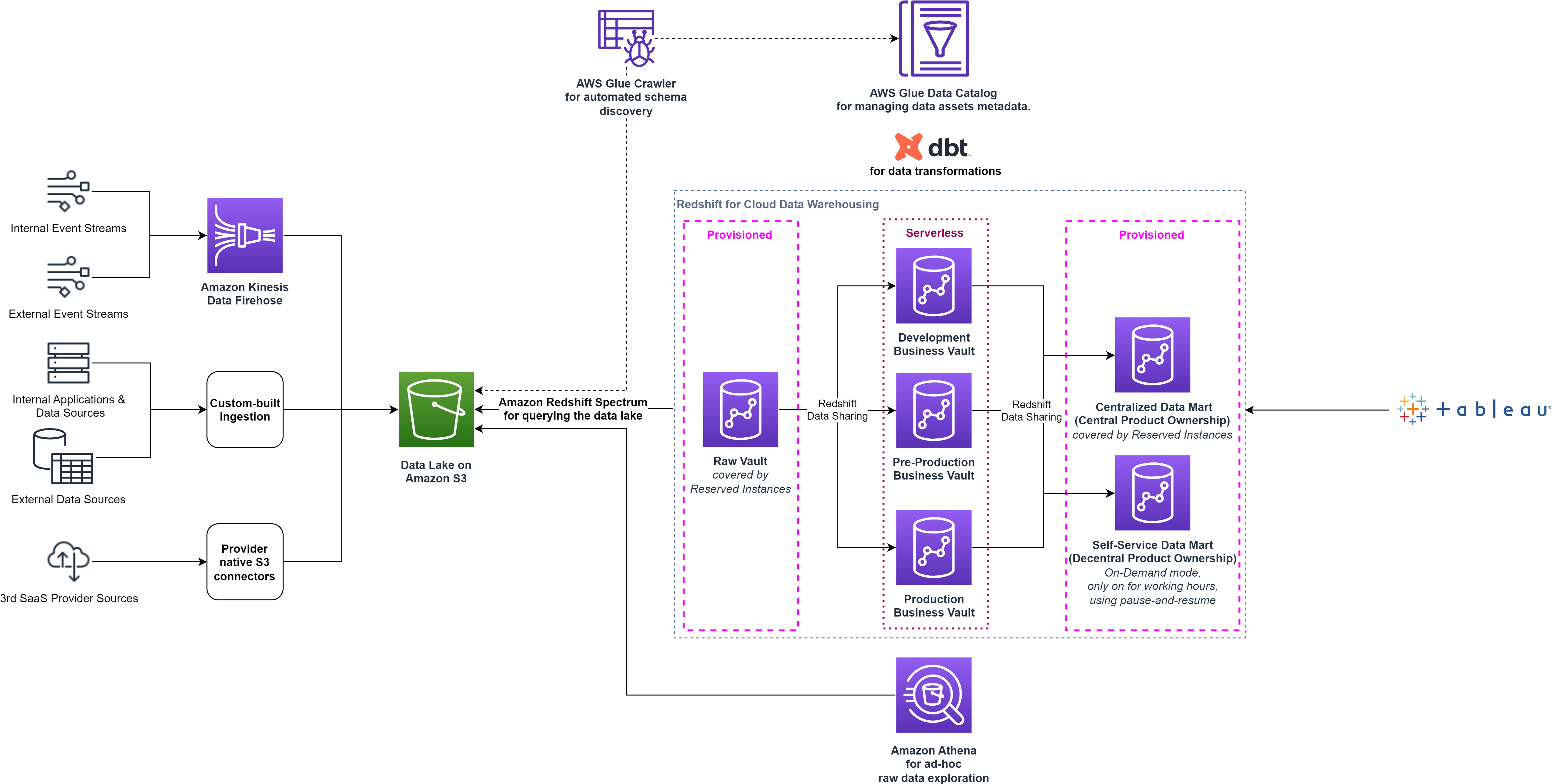
smava combinó los beneficios de Redshift Serverless y dbt a través de un canal CI/CD fluido, adoptando una metodología de desarrollo basada en troncales. Los cambios en el repositorio de Git se implementan automáticamente en una etapa de prueba y se validan mediante pruebas de integración automatizadas. Este enfoque aumentó la eficiencia de los desarrolladores y redujo el tiempo promedio de producción de días a minutos.
smava adoptó una arquitectura que utiliza almacenes de datos Redshift aprovisionados y sin servidor, junto con la capacidad de compartir datos para aislar las cargas de trabajo. Al elegir los patrones arquitectónicos adecuados para sus necesidades, smava pudo lograr lo siguiente:
- Simplifique las canalizaciones de datos y reduzca los gastos operativos
- Reduzca el tiempo de lanzamiento de funciones de días a minutos
- Aumente la relación precio-rendimiento reduciendo los tiempos de inactividad y ajustando el tamaño de la carga de trabajo
- Logre una generación de informes hasta tres veces más rápida (cálculos más rápidos y mayor paralelización) con un 50 % de los costos de configuración originales.
- Aumente la agilidad de todos los departamentos y respalde la toma de decisiones basada en datos democratizando el acceso a los datos.
- Aumente la velocidad de la innovación exponiendo capacidades de datos de autoservicio para los equipos de todos los departamentos y fortaleciendo las capacidades de prueba A/B para cubrir todo el recorrido del cliente.
Ahora, todos los departamentos de smava están utilizando los productos de datos disponibles para tomar decisiones ágiles, precisas y basadas en datos.
Visión de futuro
Para el futuro, smava planea continuar optimizando la plataforma de datos en función de métricas operativas. Están considerando cambiar más clústeres aprovisionados, como el clúster Self-Service Data Mart, a sistemas sin servidor. Además, smava está optimizando la cadena de herramientas de orquestación ELT para aumentar la cantidad de canales de datos paralelos que se ejecutarán. Esto aumentará la utilización de los recursos Redshift aprovisionados y permitirá reducciones de costos.
Con la introducción del autoservicio descentralizado para la creación de productos de datos, smava dio un paso adelante hacia una arquitectura de malla de datos. En el futuro, el equipo de la plataforma de datos planea evaluar más a fondo las necesidades de los usuarios de sus servicios y establecer más principios de malla de datos, como la gobernanza de datos federados.
Conclusión
En esta publicación, mostramos cómo smava optimizó su plataforma de datos aislando entornos y cargas de trabajo utilizando Redshift Serverless y funciones de intercambio de datos. Esos entornos de Redshift están bien integrados con su infraestructura, son flexibles para escalar según demanda, tienen alta disponibilidad y requieren esfuerzos mínimos de administración. En general, smava ha triplicado el rendimiento y ha reducido los costes totales de la plataforma en un 50%. Además, redujeron los gastos operativos al mínimo y al mismo tiempo mantuvieron los SLA existentes para los tiempos de generación de informes. Además, smava ha fortalecido la cultura de innovación al proporcionar capacidades de productos de datos de autoservicio para acelerar su tiempo de comercialización.
Si está interesado en obtener más información sobre las capacidades de Amazon Redshift, le recomendamos ver el más reciente. Novedades de la sesión de Amazon Redshift en el canal AWS Events para obtener una descripción general de las funciones agregadas recientemente al servicio. También puedes explorar el Laboratorios prácticos y de autoservicio de Amazon Redshift experimentar con funcionalidades clave de Amazon Redshift de forma guiada.
También puedes profundizar en Casos de uso de Redshift sin servidor y casos de uso de intercambio de datos. Además, echa un vistazo a la mejores prácticas para compartir datos y descubre como otros clientes optimizados en términos de costo y rendimiento con el intercambio de datos de Redshift para inspirarte para tus propias cargas de trabajo.
Si prefieres los libros, echa un vistazo Amazon Redshift: la guía definitiva de O'Reilly, donde los autores detallan las capacidades de Amazon Redshift y brindan información sobre los patrones y técnicas correspondientes.
Acerca de los autores
 Alex Naumov es arquitecto principal de datos en smava GmbH y lidera los proyectos de transformación en el departamento de datos. Anteriormente, Alex trabajó durante 10 años como consultor y arquitecto de datos/soluciones en una amplia variedad de dominios, como telecomunicaciones, banca, energía y finanzas, utilizando diversas tecnologías y en muchos países diferentes. Tiene una gran pasión por los datos y por transformar las organizaciones para que estén impulsadas por los datos y sean las mejores en lo que hacen.
Alex Naumov es arquitecto principal de datos en smava GmbH y lidera los proyectos de transformación en el departamento de datos. Anteriormente, Alex trabajó durante 10 años como consultor y arquitecto de datos/soluciones en una amplia variedad de dominios, como telecomunicaciones, banca, energía y finanzas, utilizando diversas tecnologías y en muchos países diferentes. Tiene una gran pasión por los datos y por transformar las organizaciones para que estén impulsadas por los datos y sean las mejores en lo que hacen.
 Ling Li Zheng Trabaja como gerente de desarrollo comercial en la organización especializada mundial de AWS, brindando soporte a los clientes en la región DACH para obtener el mejor valor de los servicios de análisis de Amazon. Con más de 12 años de experiencia en la industria de la energía, la automatización y el software, con especial atención en el análisis de datos, la inteligencia artificial y el aprendizaje automático, se dedica a ayudar a los clientes a lograr resultados comerciales tangibles a través de la transformación digital.
Ling Li Zheng Trabaja como gerente de desarrollo comercial en la organización especializada mundial de AWS, brindando soporte a los clientes en la región DACH para obtener el mejor valor de los servicios de análisis de Amazon. Con más de 12 años de experiencia en la industria de la energía, la automatización y el software, con especial atención en el análisis de datos, la inteligencia artificial y el aprendizaje automático, se dedica a ayudar a los clientes a lograr resultados comerciales tangibles a través de la transformación digital.
 Alejandro Spivak es arquitecto sénior de soluciones de startups en AWS y se centra en clientes ISV B2B en toda EMEA Norte. Antes de AWS, Alexander trabajó como consultor en compromisos de servicios financieros, incluidos varios roles en arquitectura y desarrollo de software. Le apasiona el análisis de datos, las arquitecturas sin servidor y la creación de organizaciones eficientes.
Alejandro Spivak es arquitecto sénior de soluciones de startups en AWS y se centra en clientes ISV B2B en toda EMEA Norte. Antes de AWS, Alexander trabajó como consultor en compromisos de servicios financieros, incluidos varios roles en arquitectura y desarrollo de software. Le apasiona el análisis de datos, las arquitecturas sin servidor y la creación de organizaciones eficientes.
David Greenshtein, arquitecto sénior de soluciones analíticas, revisó la precisión técnica de esta publicación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/

