Pandas es una biblioteca de código abierto potente y ampliamente utilizada para la manipulación y el análisis de datos mediante Python. Una de sus características clave es la capacidad de agrupar datos usando la función groupby dividiendo un DataFrame en grupos basados en una o más columnas y luego aplicando varias funciones de agregación a cada uno de ellos.

Imagen de Unsplash
La groupby La función es increíblemente poderosa, ya que le permite resumir y analizar rápidamente grandes conjuntos de datos. Por ejemplo, puede agrupar un conjunto de datos por una columna específica y calcular la media, la suma o el recuento de las columnas restantes para cada grupo. También puede agrupar por varias columnas para obtener una comprensión más granular de sus datos. Además, le permite aplicar funciones de agregación personalizadas, que pueden ser una herramienta muy poderosa para tareas complejas de análisis de datos.
En este tutorial, aprenderá cómo usar la función groupby en Pandas para agrupar diferentes tipos de datos y realizar diferentes operaciones de agregación. Al final de este tutorial, debería poder usar esta función para analizar y resumir datos de varias maneras.
Los conceptos se internalizan cuando se practican bien y esto es lo que vamos a hacer a continuación, es decir, ponernos manos a la obra con la función groupby de Pandas. Se recomienda utilizar un Cuaderno Jupyter para este tutorial, ya que puede ver el resultado en cada paso.
Generar datos de muestra
Importe las siguientes bibliotecas:
- Pandas: para crear un marco de datos y aplicar el grupo por
- Aleatorio: para generar datos aleatorios
- Pprint – Para imprimir diccionarios
import pandas as pd
import random
import pprint
A continuación, inicializaremos un marco de datos vacío y completaremos los valores para cada columna como se muestra a continuación:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Consejo adicional: una forma más limpia de hacer la misma tarea es crear un diccionario de todas las variables y valores y luego convertirlo en un marco de datos.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
El marco de datos se parece al que se muestra a continuación. Al ejecutar este código, algunos de los valores no coincidirán ya que estamos usando una muestra aleatoria.
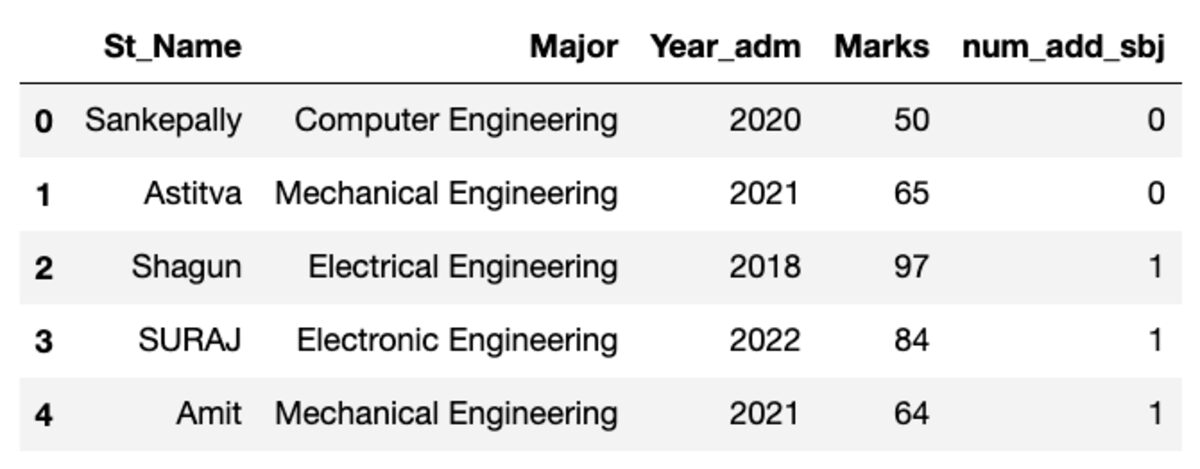
Hacer grupos
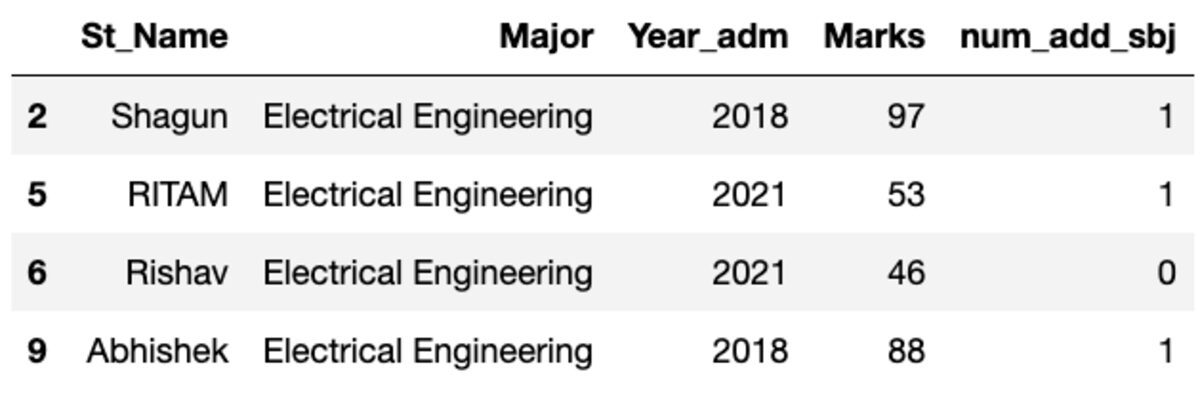
Agrupemos los datos por el tema "Principal" y apliquemos el filtro de grupo para ver cuántos registros caen en este grupo.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Entonces, cuatro estudiantes pertenecen a la carrera de Ingeniería Eléctrica.
También puede agrupar por más de una columna (Major y num_add_sbj en este caso).
groups = df.groupby(['Major', 'num_add_sbj'])
Tenga en cuenta que todas las funciones agregadas que se pueden aplicar a grupos con una columna se pueden aplicar a grupos con varias columnas. Para el resto del tutorial, centrémonos en los diferentes tipos de agregaciones usando una sola columna como ejemplo.
Vamos a crear grupos usando groupby en la columna "Major".
groups = df.groupby('Major')Aplicar funciones directas
Digamos que desea encontrar las calificaciones promedio en cada Major. ¿Qué harías?
- Elija la columna Marcas
- Aplicar función media
- Aplicar la función de redondeo para redondear las marcas a dos decimales (opcional)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Agregados
Otra forma de lograr el mismo resultado es usando una función agregada como se muestra a continuación:
groups['Marks'].aggregate('mean').round(2)
También puede aplicar múltiples agregaciones a los grupos pasando las funciones como una lista de cadenas.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
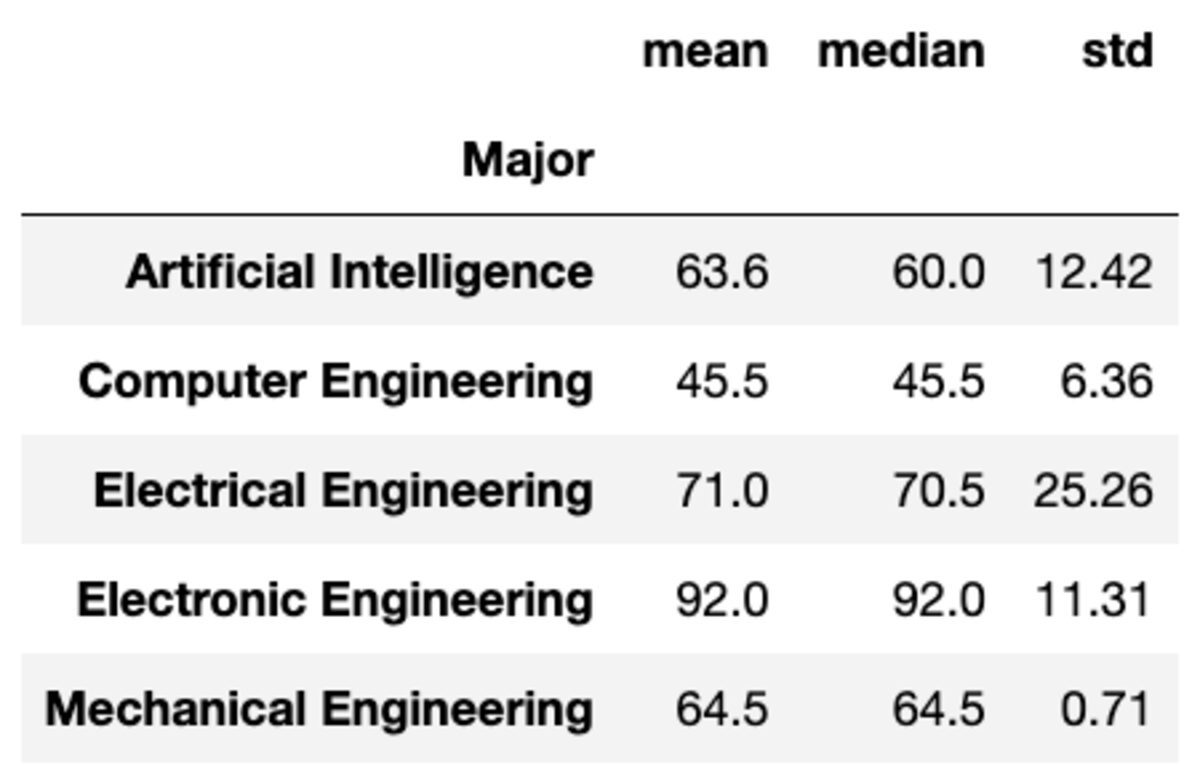
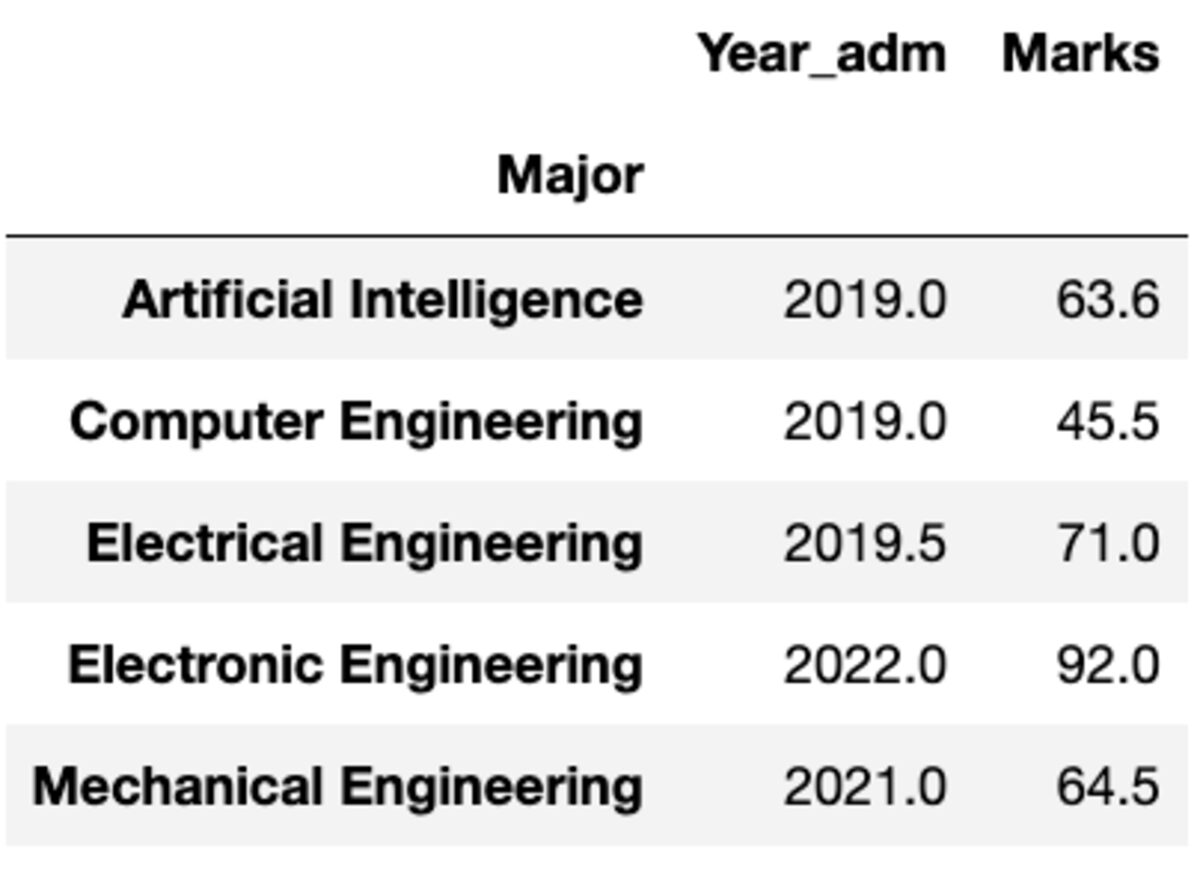
Pero, ¿qué sucede si necesita aplicar una función diferente a una columna diferente? No te preocupes. También puede hacerlo pasando el par {column: function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Transforma
Es muy posible que necesite realizar transformaciones personalizadas en una columna en particular que se puede lograr fácilmente usando groupby(). Definamos un escalar estándar similar al disponible en el módulo de preprocesamiento de sklearn. Puede transformar todas las columnas llamando al método de transformación y pasando la función personalizada.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
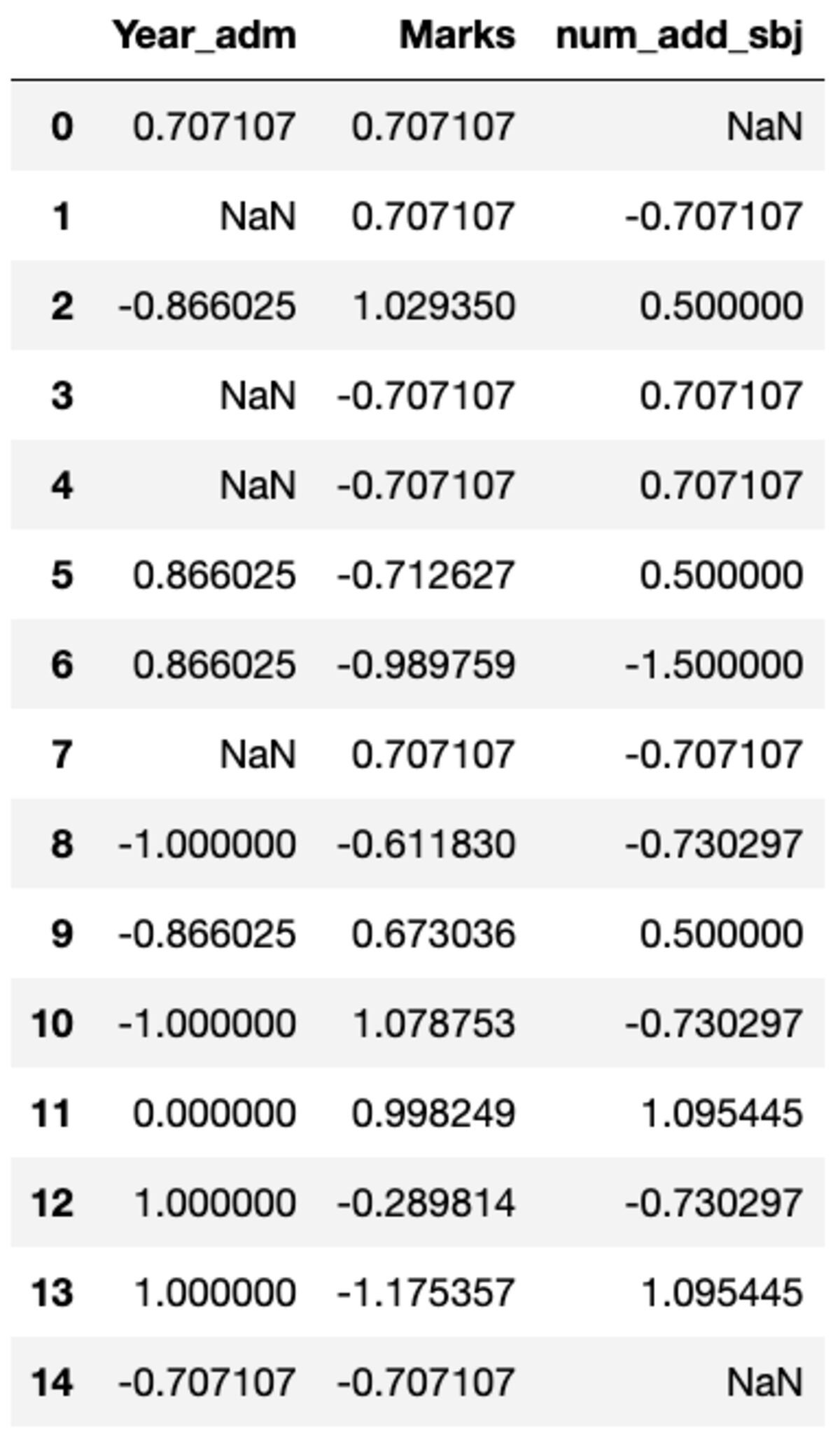
Tenga en cuenta que "NaN" representa grupos con desviación estándar cero.
Filtrar
Es posible que desee verificar qué "especialización" tiene un rendimiento inferior, es decir, aquella en la que las "marcas" promedio de los estudiantes son inferiores a 60. Requiere que aplique un método de filtro a los grupos con una función dentro. El siguiente código utiliza un función lambda para lograr los resultados filtrados.
groups.filter(lambda x: x['Marks'].mean() 60)

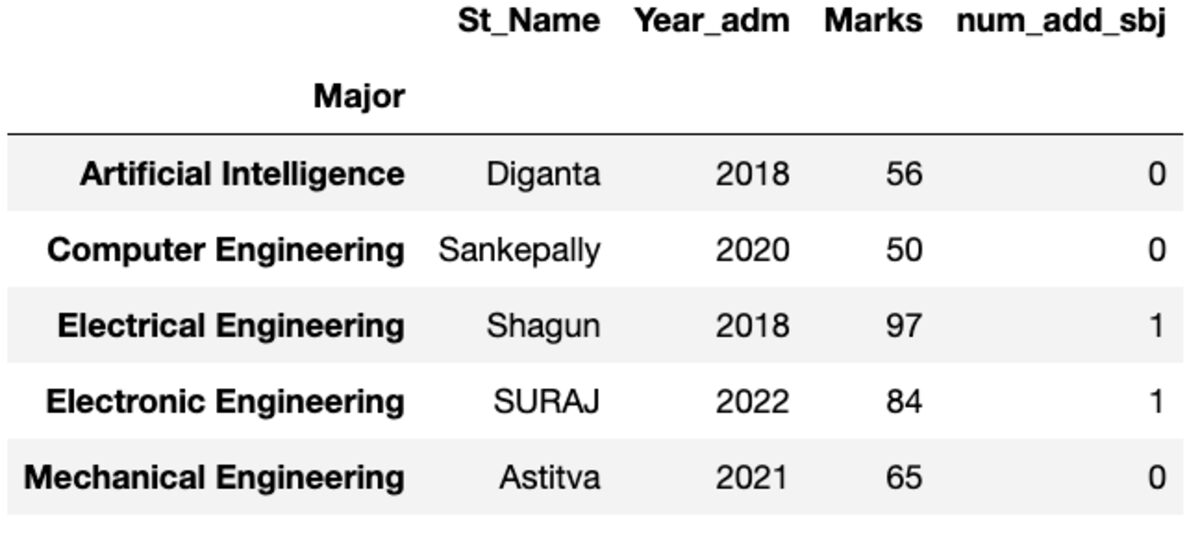
Nombre
Te da su primera instancia ordenada por índice.
groups.first()
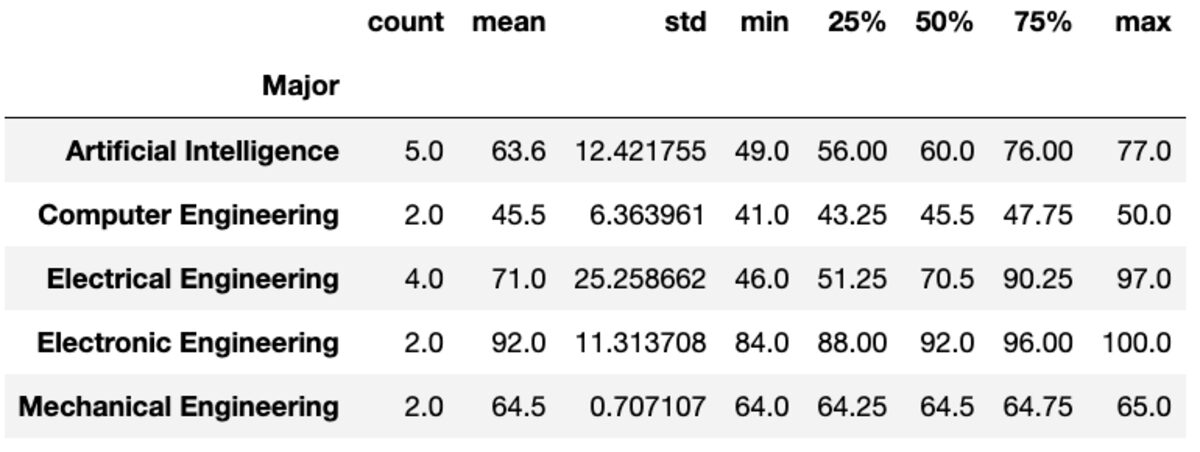
Describir
El método "describir" devuelve estadísticas básicas como recuento, media, estándar, mínimo, máximo, etc. para las columnas dadas.
groups['Marks'].describe()
Tamaño
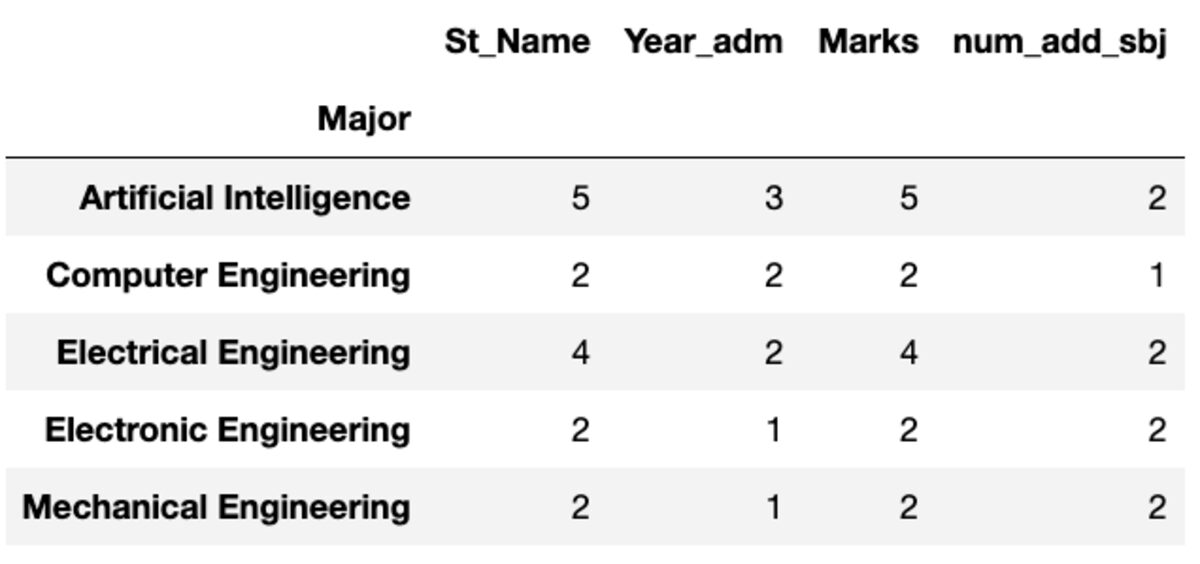
Tamaño, como sugiere el nombre, devuelve el tamaño de cada grupo en términos de número de registros.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
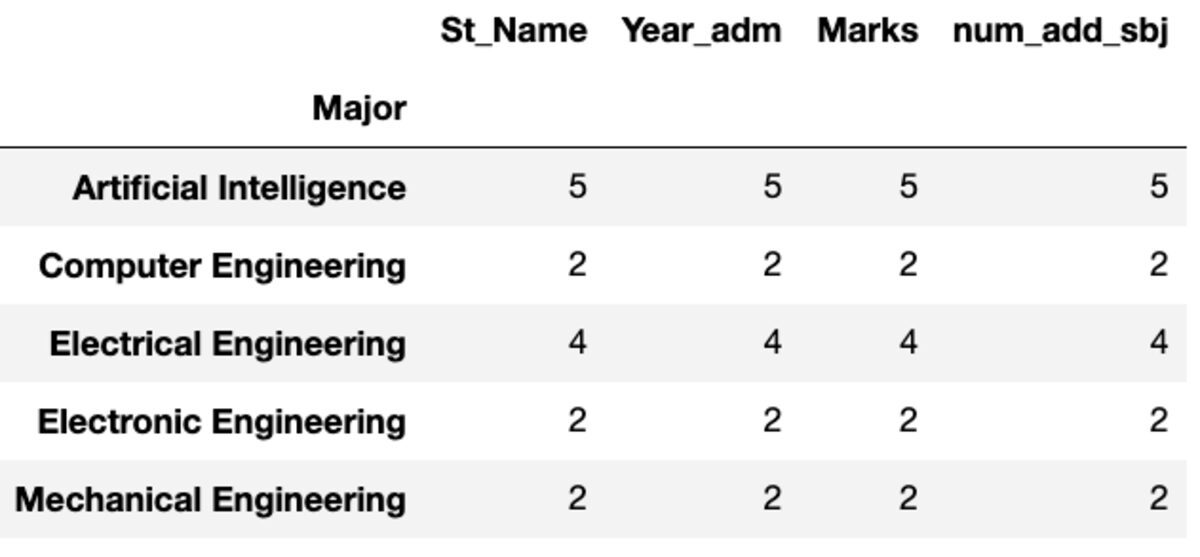
dtype: int64Conde y Nunique
“Count” devuelve todos los valores mientras que “Nunique” devuelve solo los valores únicos en ese grupo.
groups.count()
groups.nunique()
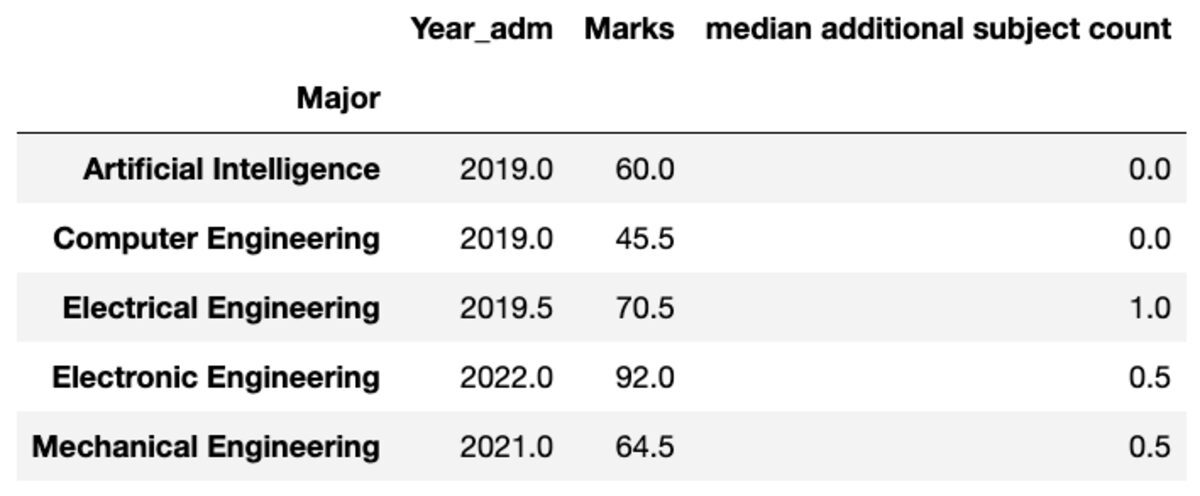
rebautizar
También puede cambiar el nombre de las columnas agregadas según sus preferencias.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Sea claro sobre el propósito del grupo: ¿Está tratando de agrupar los datos por una columna para obtener la media de otra columna? ¿O está tratando de agrupar los datos por varias columnas para obtener el recuento de filas en cada grupo?
- Comprender la indexación del marco de datos: La función groupby usa el índice para agrupar los datos. Si desea agrupar los datos por una columna, asegúrese de que la columna esté configurada como índice o puede usar .set_index()
- Usar la función agregada apropiada: Se puede usar con varias funciones de agregación como mean(), sum(), count(), min(), max()
- Utilice el parámetro as_index: Cuando se establece en False, este parámetro le dice a pandas que use las columnas agrupadas como columnas regulares en lugar de índice.
También puede usar groupby() junto con otras funciones de pandas como pivot_table(), crosstab() y cut() para extraer más información de sus datos.
Una función groupby es una herramienta poderosa para el análisis y la manipulación de datos, ya que le permite agrupar filas de datos en función de una o más columnas y luego realizar cálculos agregados en los grupos. El tutorial demostró varias formas de usar la función groupby con la ayuda de ejemplos de código. Espero que le proporcione una comprensión de las diferentes opciones que vienen con él y también cómo ayudan en el análisis de datos.
vidhi chugh es un estratega de inteligencia artificial y un líder de transformación digital que trabaja en la intersección de productos, ciencias e ingeniería para construir sistemas escalables de aprendizaje automático. Es una líder en innovación galardonada, autora y oradora internacional. Tiene la misión de democratizar el aprendizaje automático y romper la jerga para que todos sean parte de esta transformación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby

