Las organizaciones de salud pública tienen una gran cantidad de datos sobre diferentes tipos de enfermedades, tendencias de salud y factores de riesgo. Su personal ha utilizado durante mucho tiempo modelos estadísticos y análisis de regresión para tomar decisiones importantes, como dirigirse a poblaciones con los factores de riesgo más altos para una enfermedad con terapias, o pronosticar la progresión de brotes preocupantes.
Cuando surgen amenazas para la salud pública, la velocidad de los datos aumenta, los conjuntos de datos entrantes pueden crecer y la gestión de datos se vuelve más desafiante. Esto hace que sea más difícil analizar los datos de manera holística y capturar información a partir de ellos. Y cuando el tiempo es esencial, la velocidad y la agilidad en el análisis de datos y la obtención de información a partir de ellos son bloqueadores clave para formar respuestas de salud rápidas y sólidas.
Las preguntas típicas que enfrentan las organizaciones de salud pública en tiempos de estrés incluyen:
- ¿Habrá suficientes terapias en un lugar determinado?
- ¿Qué factores de riesgo están impulsando los resultados de salud?
- ¿Qué poblaciones tienen un mayor riesgo de reinfección?
Debido a que responder a estas preguntas requiere comprender relaciones complejas entre muchos factores diferentes, a menudo cambiantes y dinámicos, una herramienta poderosa que tenemos a nuestra disposición es el aprendizaje automático (ML), que se puede implementar para analizar, predecir y resolver estos problemas cuantitativos complejos. Hemos visto cada vez más ML aplicado para abordar problemas difíciles relacionados con la salud, como clasificación de los tumores cerebrales con análisis de imagen y predecir la necesidad de salud mental implementar programas de intervención temprana.
Pero, ¿qué sucede si las organizaciones de salud pública carecen de las habilidades necesarias para aplicar ML a estas preguntas? Se impide la aplicación de ML a los problemas de salud pública y las organizaciones de salud pública pierden la capacidad de aplicar poderosas herramientas cuantitativas para abordar sus desafíos.
Entonces, ¿cómo eliminamos estos cuellos de botella? La respuesta es democratizar el aprendizaje automático y permitir que un mayor número de profesionales de la salud con una amplia experiencia en el dominio lo usen y lo apliquen a las preguntas que desean resolver.
Lienzo de Amazon SageMaker es una herramienta de ML sin código que permite a los profesionales de la salud pública, como epidemiólogos, informáticos y bioestadísticos, aplicar ML a sus preguntas, sin necesidad de tener experiencia en ciencia de datos o ML. Pueden dedicar su tiempo a los datos, aplicar su experiencia en el dominio, probar hipótesis rápidamente y cuantificar los conocimientos. Canvas ayuda a que la salud pública sea más equitativa al democratizar ML, lo que permite a los expertos en salud evaluar grandes conjuntos de datos y empoderarlos con conocimientos avanzados mediante ML.
En esta publicación, mostramos cómo los expertos en salud pública pueden pronosticar la demanda disponible de un determinado tratamiento para los próximos 30 días utilizando Canvas. Canvas le proporciona una interfaz visual que le permite generar predicciones precisas de ML por su cuenta sin necesidad de experiencia en ML ni tener que escribir una sola línea de código.
Resumen de la solución
Digamos que estamos trabajando en datos que recopilamos de estados de EE. UU. Podemos formar una hipótesis de que cierto municipio o ubicación no tiene suficientes terapias en las próximas semanas. ¿Cómo podemos probar esto rápidamente y con un alto grado de precisión?
Para esta publicación, utilizamos un conjunto de datos disponible públicamente del Departamento de Salud y Servicios Humanos de EE. UU., que contiene datos de series de tiempo agregados por estado relacionados con COVID-19, incluida la utilización hospitalaria, la disponibilidad de ciertas terapias y mucho más. El conjunto de datos (COVID-19 Impacto informado en el paciente y capacidad hospitalaria por State Timeseries (RAW)) se puede descargar desde healthdata.gov y tiene 135 columnas y más de 60,000 XNUMX filas. El conjunto de datos se actualiza periódicamente.
En las siguientes secciones, demostramos cómo realizar análisis y preparación de datos exploratorios, construir el modelo de pronóstico de ML y generar predicciones usando Canvas.
Realizar análisis y preparación de datos exploratorios.
Al hacer un pronóstico de serie temporal en Canvas, debemos reducir la cantidad de funciones o columnas de acuerdo con las cuotas del servicio. Inicialmente, reducimos el número de columnas a las 12 que probablemente sean las más relevantes. Por ejemplo, eliminamos las columnas específicas por edad porque buscamos pronosticar la demanda total. También descartamos columnas cuyos datos eran similares a otras columnas que mantuvimos. En iteraciones futuras, es razonable experimentar con la retención de otras columnas y el uso de la explicabilidad de funciones en Canvas para cuantificar la importancia de estas funciones y cuáles queremos mantener. También renombramos el state columna a location.
Mirando el conjunto de datos, también decidimos eliminar todas las filas para 2020, porque había terapias limitadas disponibles en ese momento. Esto nos permite reducir el ruido y mejorar la calidad de los datos para que aprenda el modelo de ML.
La reducción del número de columnas se puede hacer de diferentes maneras. Puede editar el conjunto de datos en una hoja de cálculo o directamente dentro de Canvas usando la interfaz de usuario.
Puede importar datos a Canvas desde varias fuentes, incluso desde archivos locales de su computadora, Servicio de almacenamiento simple de Amazon (Amazon S3) baldes, Atenea amazónica, Copo de nieve (consulta: Prepare un conjunto de datos de entrenamiento y validación para la clasificación de facies usando la integración de Snowflake y entrene usando Amazon SageMaker Canvas), o más de 40 fuentes de datos adicionales.
Después de importar nuestros datos, podemos explorarlos y visualizarlos para obtener información adicional, como diagramas de dispersión o gráficos de barras. También observamos la correlación entre las diferentes características para asegurarnos de haber seleccionado las que creemos que son las mejores. La siguiente captura de pantalla muestra una visualización de ejemplo.

Cree el modelo de pronóstico de ML
Ahora estamos listos para crear nuestro modelo, lo que podemos hacer con solo unos pocos clics. Elegimos la columna que identifica la terapia disponible como nuestro objetivo. Canvas identifica automáticamente nuestro problema como un pronóstico de serie de tiempo basado en la columna objetivo que acabamos de seleccionar, y podemos configurar los parámetros necesarios.
Configuramos el item_id, el identificador único, como ubicación porque nuestro conjunto de datos se proporciona por ubicación (estados de EE. UU.). Debido a que estamos creando un pronóstico de serie temporal, debemos seleccionar una marca de tiempo, que es date en nuestro conjunto de datos. Finalmente, especificamos cuántos días en el futuro queremos pronosticar (para este ejemplo, elegimos 30 días). Canvas también ofrece la posibilidad de incluir un calendario de vacaciones para mejorar la precisión. En este caso, usamos días festivos de EE. UU. porque se trata de un conjunto de datos basado en EE. UU.
Con Canvas, puede obtener información de sus datos antes de crear un modelo eligiendo Modelo de vista previa. Esto le ahorra tiempo y dinero al no crear un modelo si es poco probable que los resultados sean satisfactorios. Al obtener una vista previa de nuestro modelo, nos damos cuenta de que el impacto de algunas columnas es bajo, lo que significa que el valor esperado de la columna para el modelo es bajo. Eliminamos columnas deseleccionándolas en Canvas (flechas rojas en la siguiente captura de pantalla) y vemos una mejora en una métrica de calidad estimada (flecha verde).

Pasando a construir nuestro modelo, tenemos dos opciones, Construcción rápida y Construcción estándar. Quick build produce un modelo entrenado en menos de 20 minutos, priorizando la velocidad sobre la precisión. Esto es excelente para la experimentación y es un modelo más completo que el modelo de vista previa. La construcción estándar produce un modelo entrenado en menos de 4 horas, priorizando la precisión sobre la latencia, iterando a través de una serie de configuraciones de modelo para seleccionar automáticamente el mejor modelo.
Primero, experimentamos con la compilación rápida para validar la vista previa de nuestro modelo. Luego, como estamos contentos con el modelo, elegimos la construcción estándar para que Canvas ayude a construir el mejor modelo posible para nuestro conjunto de datos. Si el modelo de compilación rápida hubiera producido resultados insatisfactorios, volveríamos atrás y ajustaríamos los datos de entrada para capturar un mayor nivel de precisión. Podríamos lograr esto, por ejemplo, agregando o eliminando columnas o filas en nuestro conjunto de datos original. El modelo de compilación rápida admite la experimentación rápida sin tener que depender de los escasos recursos de ciencia de datos o esperar a que se complete un modelo completo.
Generar predicciones
Ahora que se ha construido el modelo, podemos predecir la disponibilidad de terapias por location. Veamos cómo se ve nuestro inventario disponible estimado para los próximos 30 días, en este caso para Washington, DC.
Canvas genera pronósticos probabilísticos para la demanda terapéutica, lo que nos permite comprender tanto el valor medio como los límites superior e inferior. En la siguiente captura de pantalla, puede ver el final de los datos históricos (los datos del conjunto de datos original). A continuación, puede ver tres líneas nuevas: el pronóstico de la mediana (cuartil 50) en púrpura, el límite inferior (cuartil 10) en azul claro y el límite superior (cuartil 90) en azul oscuro.
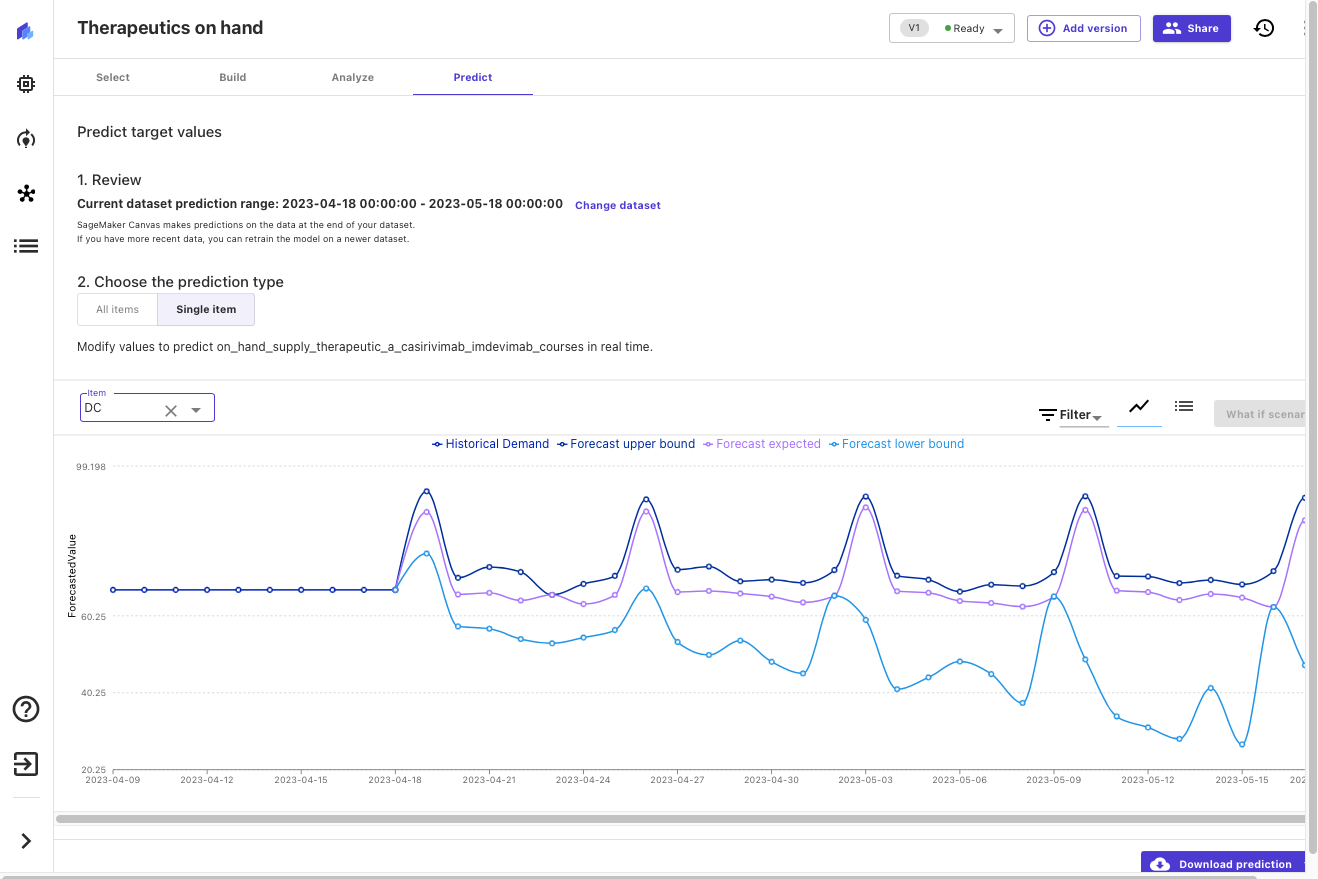
Examinar los límites superior e inferior proporciona información sobre la distribución de probabilidad del pronóstico y nos permite tomar decisiones informadas sobre los niveles deseados de inventario local para este tratamiento. Podemos agregar esta información a otros datos (por ejemplo, pronósticos de progresión de la enfermedad o eficacia y aceptación terapéutica) para tomar decisiones informadas sobre futuros pedidos y niveles de inventario.
Conclusión
Las herramientas de ML sin código permiten a los expertos en salud pública aplicar ML de forma rápida y eficaz a las amenazas para la salud pública. Esta democratización del ML hace que las organizaciones de salud pública sean más ágiles y eficientes en su misión de proteger la salud pública. Los análisis ad hoc que pueden identificar tendencias importantes o puntos de inflexión en problemas de salud pública ahora pueden ser realizados directamente por especialistas, sin tener que competir por recursos expertos limitados de ML y ralentizar los tiempos de respuesta y la toma de decisiones.
En esta publicación, mostramos cómo alguien sin ningún conocimiento de ML puede usar Canvas para pronosticar el inventario disponible de un determinado tratamiento. Este análisis puede ser realizado por cualquier analista en el campo, a través del poder de las tecnologías en la nube y el aprendizaje automático sin código. Hacerlo distribuye las capacidades ampliamente y permite que las agencias de salud pública sean más receptivas y utilicen de manera más eficiente los recursos centralizados y de la oficina de campo para brindar mejores resultados de salud pública.
¿Cuáles son algunas de las preguntas que podría estar haciendo y cómo las herramientas de código bajo/sin código pueden ayudarlo a responderlas? Si está interesado en obtener más información sobre Canvas, consulte Lienzo de Amazon SageMaker y comience a aplicar ML a sus propias preguntas de salud cuantitativas.
Sobre los autores
 henrik balle es un Arquitecto de Soluciones Sr. en AWS que apoya al Sector Público de EE. UU. Trabaja en estrecha colaboración con los clientes en una variedad de temas, desde el aprendizaje automático hasta la seguridad y la gobernanza a escala. En su tiempo libre, le encanta andar en bicicleta, andar en motocicleta, o puede que lo encuentre trabajando en otro proyecto de mejoras para el hogar.
henrik balle es un Arquitecto de Soluciones Sr. en AWS que apoya al Sector Público de EE. UU. Trabaja en estrecha colaboración con los clientes en una variedad de temas, desde el aprendizaje automático hasta la seguridad y la gobernanza a escala. En su tiempo libre, le encanta andar en bicicleta, andar en motocicleta, o puede que lo encuentre trabajando en otro proyecto de mejoras para el hogar.
 dan sinnreich dirige la gestión de productos Go to Market para Amazon SageMaker Canvas y Amazon Forecast. Se centra en democratizar el aprendizaje automático de código bajo/sin código y aplicarlo para mejorar los resultados comerciales. Antes de AWS, Dan creó plataformas SaaS empresariales y modelos de riesgo de series temporales utilizados por inversores institucionales para administrar el riesgo y crear carteras. Fuera del trabajo, se le puede encontrar jugando al hockey, buceando, viajando y leyendo ciencia ficción.
dan sinnreich dirige la gestión de productos Go to Market para Amazon SageMaker Canvas y Amazon Forecast. Se centra en democratizar el aprendizaje automático de código bajo/sin código y aplicarlo para mejorar los resultados comerciales. Antes de AWS, Dan creó plataformas SaaS empresariales y modelos de riesgo de series temporales utilizados por inversores institucionales para administrar el riesgo y crear carteras. Fuera del trabajo, se le puede encontrar jugando al hockey, buceando, viajando y leyendo ciencia ficción.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/capture-public-health-insights-more-quickly-with-no-code-machine-learning-using-amazon-sagemaker-canvas/

