Introducción
Si los estudiantes entusiastas quieren aprender Ciencia de los datos y máquina de aprendizaje, deberían aprender la familia potenciada. Hay muchos algoritmos que provienen de la familia de Boosted, como AdaBoost, Gradient Boosting, XGBoost y muchos más. Uno de los algoritmos de la familia Boosted es un algoritmo CatBoost. Cat Boost es un algoritmo de aprendizaje automático, y sus siglas en inglés para Categorical Boost. Yandex lo desarrolló. Es una biblioteca de código abierto. Se usa en ambos Python y R idiomas CatBoost funciona muy bien con variables categóricas en el conjunto de datos. Al igual que otros algoritmos de impulso, CatBoost también crea múltiples árboles de decisión en segundo plano, conocidos como conjunto de árboles, para predecir una etiqueta de clasificación. Se basa en el aumento de gradiente.
Lea también CatBoost: una biblioteca de aprendizaje automático para manejar datos categóricos (CAT) automáticamente

OBJETIVOS DE APRENDIZAJE
- Comprender el concepto de algoritmos potenciados y su importancia en la ciencia de datos y el aprendizaje automático.
- Explore el algoritmo CatBoost como uno de los miembros de la familia impulsada, su origen y su función en el manejo de variables categóricas.
- Comprenda las características clave de CatBoost, incluido el manejo de variables categóricas, el aumento de gradiente, el impulso ordenado y las técnicas de regularización.
- Obtenga información sobre las ventajas de CatBoost, como su sólido manejo de variables categóricas y su excelente rendimiento predictivo.
- Aprenda a implementar CatBoost en Python para tareas de regresión y clasificación, explorando parámetros de modelos y haciendo predicciones sobre datos de prueba.
Este artículo se publicó como parte del Data Science Blogathon.
Características importantes de CatBoost
- Manejo de variables categóricas: CatBoost sobresale en el manejo de conjuntos de datos que contienen características categóricas. Usando varios métodos, tratamos automáticamente con variables categóricas transformándolas en representaciones numéricas. Incluye estadísticas de destino, codificación one-hot o una combinación de las dos. Esta capacidad ahorra tiempo y esfuerzo al eliminar el requisito de preprocesamiento manual de características categóricas.
- Aumento de gradiente: Usos de CatBoost aumento de gradiente, una técnica de conjunto que combina varios aprendices débiles (árboles de decisión), para crear modelos predictivos efectivos. Agregar árboles entrenados e instruidos para rectificar los errores causados por los árboles anteriores crea árboles iterativamente mientras minimiza una función de pérdida diferenciable. Este enfoque iterativo mejora progresivamente la capacidad predictiva del modelo.
- Impulso ordenado: CatBoost propone una técnica novedosa llamada "impulso ordenado" para manejar de manera efectiva las características categóricas. Al construir el árbol, utiliza una técnica conocida como clasificación previa de variables categóricas impulsada por permutación para identificar los puntos de división óptimos. Este método permite que CatBoost considere todas las posibles configuraciones divididas, mejorando las predicciones y reduciendo el sobreajuste.
- Regularización: Las técnicas de regularización se utilizan en CatBoost para reducir el sobreajuste y mejorar la generalización. Cuenta con regularización L2 en valores de hoja, lo que modifica la función de pérdida agregando un término de penalización para evitar valores de hoja excesivos. Además, utiliza un método de vanguardia conocido como "Codificación de destino ordenado" para evitar el sobreajuste al codificar datos categóricos.
Ventajas de Cat Boost
- Manejo robusto de la variable categórica: El manejo automático de CatBoost hace que el preprocesamiento sea conveniente y efectivo. Elimina la necesidad de métodos de codificación manual y reduce la posibilidad de pérdida de información relacionada con los procedimientos convencionales.
- Excelente rendimiento predictivo: Las predicciones realizadas con el marco de aumento de gradiente de CatBoost y el aumento ordenado suelen ser precisas. Puede producir modelos sólidos que superan a muchos otros algoritmos y capturan de manera efectiva relaciones complicadas en los datos.
Casos de uso
En varios concursos de Kaggle que involucran datos tabulares, Catboost ha demostrado tener un desempeño superior. CatBoost utiliza una variedad de tareas de regresión y clasificación con éxito. Aquí hay algunos casos en los que CatBoost se ha utilizado con éxito:
- Cloudflare usa Catboost para identificar bots que se dirigen a los sitios web de sus usuarios.
- El servicio de transporte compartido Careem, con sede en Dubái, utiliza Catboost para predecir el próximo viaje de sus clientes.
Implementación
Como CatBoost es una biblioteca de código abierto, asegúrese de haberla instalado. Si no, aquí está el comando para instalar el paquete CatBoost.
#installing the catboost library
!pip install catboostPuede entrenar y crear un algoritmo catboost en los lenguajes Python y R, pero solo usaremos Python como lenguaje en esta implementación.
Una vez instalado el paquete CatBoost, importaremos catboost y otras bibliotecas necesarias.
#import libraries
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns import catboost as cb
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score import warnings
warnings.filterwarnings('ignore')
Aquí usamos el conjunto de datos de ventas de Big Mart y realizamos algunas comprobaciones de cordura de datos.
#uploading dataset
os.chdir('E:Dataset')
dt = pd.read_csv('big_mart_sales.csv') dt.head() dt.describe()
dt.info()
dt.shape
El conjunto de datos contiene más de 1k registros y 35 columnas, de las cuales 8 columnas son categóricas, pero no convertiremos esas columnas a formato numérico. Catboost mismo puede hacer tales cosas. Esta es la magia de Catboost. Puede mencionar tantas cosas como desee en el parámetro del modelo. Solo he tomado "iteración" con fines de demostración como parámetro.
#import csv
X = dt.drop('Attrition', axis=1)
y = dt['Attrition'] X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=14)
print(X_train.shape)
print(X_test.shape) cat_var = np.where(X_train.dtypes != np.float)[0] model = cb.CatBoostClassifier(iterations=10)
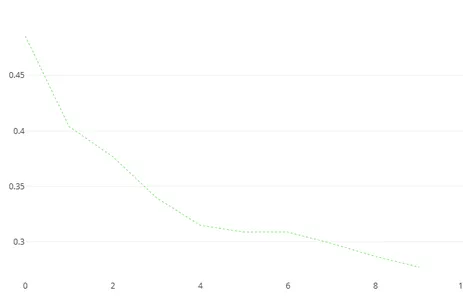
model.fit(X_train, y_train, cat_features=cat_var, plot=True)
Hay muchos parámetros de modelo que utiliza. A continuación se encuentran los parámetros importantes que puede mencionar al crear un modelo CatBoost.
parámetros
- ITeraciones: El número de iteraciones de refuerzo o árboles que se construirán. Los valores más altos pueden conducir a un mejor rendimiento pero a períodos de entrenamiento más prolongados. Es un valor entero que va de 1 a infinito [1, ∞].
- Ltasa_de_ganancias: El tamaño de paso en el que aprende el algoritmo de aumento de gradiente. Un número más bajo hace que el modelo converja más lentamente, pero podría mejorar la generalización. Debe ser un valor flotante, varía de 0 a 1
- Deph: La profundidad máxima de los árboles de decisión individuales en el conjunto. Aunque los árboles más profundos tienen una mayor probabilidad de sobreajuste, pueden capturar interacciones más complicadas. Es un valor entero que va de 1 a infinito [1, ∞].
- Lfunción_oss: Durante el entrenamiento, debemos optimizar la función de pérdida. Varios tipos de problemas, como "Logloss" para clasificación binaria, "MultiClass" para clasificación multiclase, "RMSE" para regresión, etc. tienen diferentes
soluciones Es un valor de cadena. - l2_hoja_reg: Los valores foliares se sometieron a regularización L2. Los valores de hoja grandes se penalizan con valores más altos, lo que ayuda a minimizar el sobreajuste. Es un valor flotante, que va de 0 a infinito [0, ∞].
- recuento_frontera: El número de divisiones para características numéricas. Aunque los números más altos ofrecen una división más precisa, también pueden causar un sobreajuste. 128 es el valor sugerido para conjuntos de datos más grandes. Es un valor entero que va de 1 a 255 [1, 255].
- fuerza_aleatoria: El nivel de aleatoriedad que se utilizará al seleccionar los puntos de división. Se introduce más aleatoriedad con un valor mayor, evitando el sobreajuste. Rango: [0, ∞].
- temperatura_de_empacado: Controla la intensidad del muestreo de las instancias de entrenamiento. Un valor mayor reduce la aleatoriedad del proceso de embolsado, mientras que un valor menor la aumenta. Es un valor flotante, que va de 0 a infinito [0, ∞].
Hacer predicciones en el modelo entrenado
#model prediction on the test set
y_pred = model.predict(X_test) print(accuracy_score(y_pred, y_test)) print(confusion_matrix(y_pred, y_test))También puede establecer el valor del umbral mediante la función predict_proba(). Aquí hemos logrado una puntuación de precisión de más del 85 %, lo cual es un buen valor teniendo en cuenta que no hemos procesado ninguna variable categórica en números. Eso nos muestra cuán poderoso es el algoritmo Catboost.
Conclusión
CatBoost es uno de los modelos innovadores y famosos en el campo del aprendizaje automático. Ganó mucho interés debido a su capacidad para manejar características categóricas por sí mismo. De este artículo, aprenderá lo siguiente:
- La implementación práctica de catboost.
- ¿Cuáles son las características importantes del algoritmo catboost?
- Casos de uso donde catboost ha funcionado bien
- Parámetros del modelo de catboost durante el entrenamiento de un modelo
Preguntas frecuentes
R. Catboost es un algoritmo de aprendizaje automático supervisado. Se puede utilizar tanto para problemas de regresión como de clasificación.
R. Catboost es una biblioteca potenciadora de gradientes de código abierto que maneja muy bien los datos categóricos; por lo tanto, utiliza la técnica de impulso.
R. El grupo es como un formato de datos interno en Catboost. Si le pasa una matriz numpy, primero la convertirá implícitamente a Pool, sin decírselo. Si necesita aplicar muchas fórmulas a un conjunto de datos, el uso de Pool aumenta drásticamente el rendimiento (como 10 veces), porque omitirá el paso de conversión cada vez.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/07/catboost-building-model-with-categorical-data/

