Desplazamiento al rojo de Amazon es un servicio de almacenamiento de datos a escala de petabytes completamente administrado en la nube que brinda información poderosa y segura sobre todos sus datos con la mejor relación precio-rendimiento. Con Amazon Redshift, puede analizar sus datos para obtener información holística sobre su empresa y sus clientes. En muchas organizaciones, uno o varios almacenes de datos de Amazon Redshift se ejecutan a diario con fines analíticos y de datos. Por lo tanto, con el tiempo, múltiples Lenguaje de definición de datos (DDL) or Lenguaje de control de datos (DCL) Las consultas, como CREATE, ALTER, DROP, GRANT o REVOKE SQL, se ejecutan en el almacén de datos de Amazon Redshift, que son de naturaleza confidencial porque podrían provocar la eliminación de tablas o la eliminación de datos, lo que provocaría interrupciones o interrupciones. El seguimiento de las consultas de los usuarios como parte de la gobernanza centralizada del almacén de datos ayuda a las partes interesadas a comprender los riesgos potenciales y a tomar medidas inmediatas para mitigarlos siguiendo el pilar de excelencia operativa del Lente de análisis de datos de AWS. Por lo tanto, para un mecanismo de gobierno sólido, es crucial alertar o notificar a los administradores de la base de datos y de seguridad sobre el tipo de consultas confidenciales que se ejecutan en el almacén de datos, de modo que se puedan tomar medidas correctivas rápidas si es necesario.
Para abordar esto, en esta publicación le mostramos cómo puede automatizar notificaciones casi en tiempo real en un Flojo canal cuando ciertas consultas se ejecutan en el almacén de datos. También creamos un tablero de mando simple usando una combinación de Amazon DynamoDB, Atenea amazónicay Amazon QuickSight.
Resumen de la solución
Un almacén de datos de Amazon Redshift registra información sobre las conexiones y las actividades de los usuarios que tienen lugar en las bases de datos, lo que ayuda a monitorear la base de datos con fines de seguridad y solución de problemas. Estos registros se pueden almacenar en Servicio de almacenamiento simple de Amazon (Amazon S3) baldes o Reloj en la nube de Amazon. Amazon Redshift registra información en los siguientes archivos de registro y esta solución se basa en el uso de un Registro de auditoría de Amazon Redshift a CloudWatch como destino:
- Registro de conexión – Registra intentos de autenticación, conexiones y desconexiones
- registro de usuario – Registra información sobre cambios en las definiciones de usuario de la base de datos
- Registro de actividad del usuario – Registra cada consulta antes de que se ejecute en la base de datos
El siguiente diagrama ilustra la arquitectura de la solución.
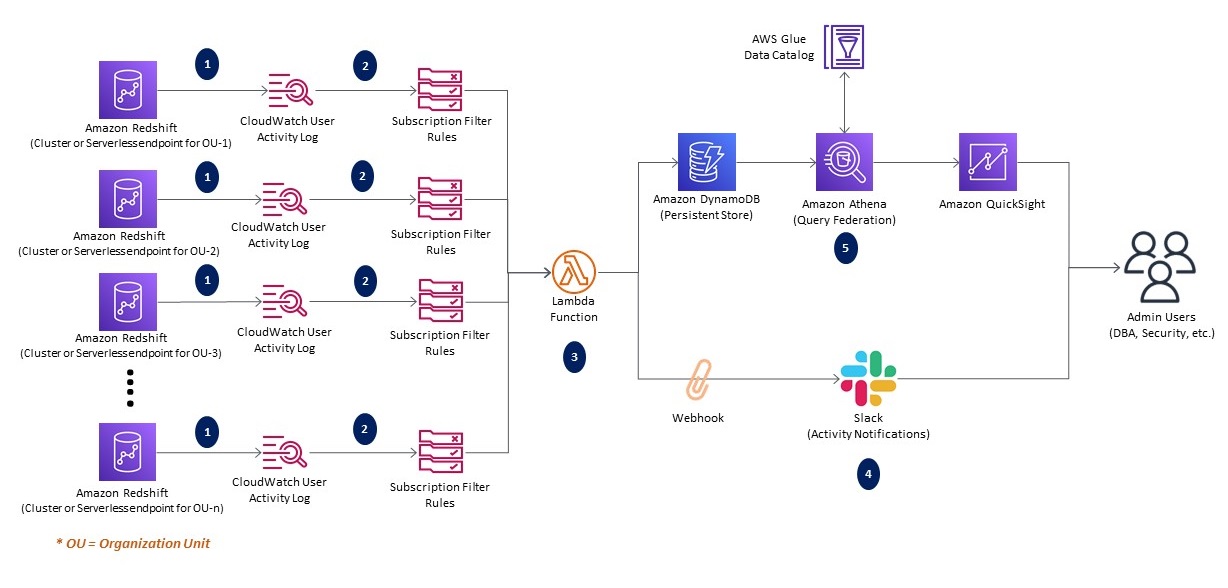
El flujo de trabajo de la solución consta de los siguientes pasos:
- El registro de auditoría está habilitado en cada almacén de datos de Amazon Redshift para capturar el registro de actividad del usuario en CloudWatch.
- Los filtros de suscripción en CloudWatch capturan los comandos DDL y DCL requeridos proporcionando criterios de filtro.
- El filtro de suscripción desencadena una AWS Lambda función para la coincidencia de patrones.
- La función Lambda procesa los datos del evento y envía la notificación a través de un canal de Slack mediante un webhook.
- La función de Lambda almacena los datos en una tabla de DynamoDB sobre la que se construye un tablero simple usando Athena y QuickSight.
Requisitos previos
Antes de comenzar la implementación, asegúrese de que se cumplan los siguientes requisitos:
- Tienes un Cuenta de AWS.
- El proyecto Región de AWS utilizado para esta publicación es us-east-1. Sin embargo, esta solución es relevante en cualquier otra región donde estén disponibles los servicios de AWS necesarios.
- Permisos para crear un espacio de trabajo en Slack.
Crear y configurar un clúster de Amazon Redshift
Para configurar su clúster, complete los siguientes pasos:
Para esta publicación, utilizamos tres almacenes de datos de Amazon Redshift: demo-cluster-ou1, demo-cluster-ou2y demo-cluster-ou3. En esta publicación, todos los almacenes de datos de Amazon Redshift son clústeres aprovisionados. Sin embargo, la misma solución se aplica para Amazon Redshift sin servidor.
- Para permitir registro de auditoría con CloudWatch como destino de entrega de registros, abra un clúster de Amazon Redshift y vaya a la Propiedades .
- En Editar menú, seleccione Editar registro de auditoría.
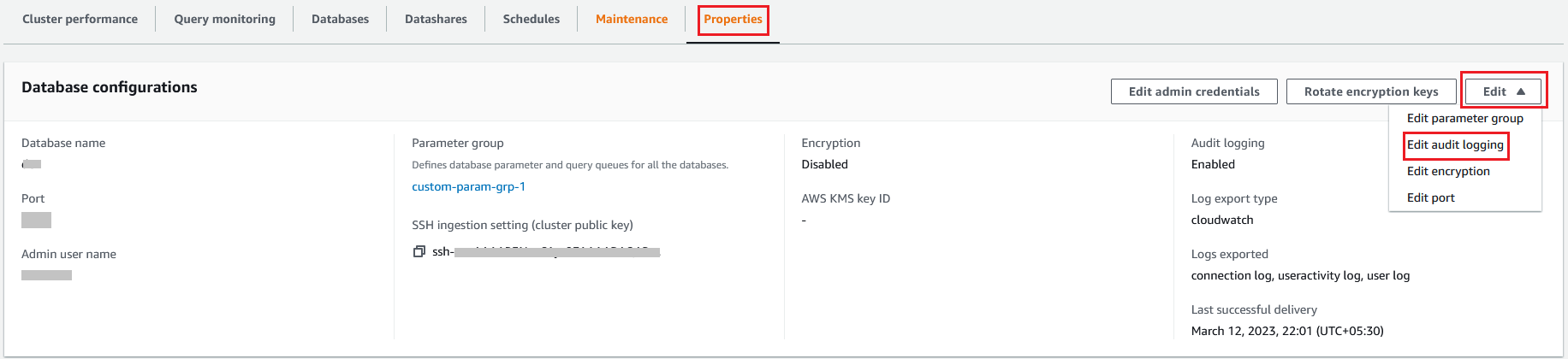
- Seleccione "Permitir" bajo Configurar el registro de auditoría.
- Seleccione Vigilancia de la nube para Tipo de exportación de registro.
- Seleccione las tres opciones para registro de usuario, Registro de conexióny Registro de actividad del usuario.
- Elige Guardar los cambios.

- Crear un grupo de parámetros para los racimos con
enable_user_activity_loggingestablecer como verdadero para cada uno de los clústeres. - Modificar el clúster para adjuntar el nuevo grupo de parámetros al clúster de Amazon Redshift.
Para esta publicación, creamos tres grupos de parámetros personalizados: custom-param-grp-1, custom-param-grp-2y custom-param-grp-3 para tres racimos.

Tenga en cuenta que si habilita solo la función de registro de auditoría, pero no el parámetro asociado, la auditoría de la base de datos registra la información solo para el registro de conexión y el registro de usuario, pero no para el registro de actividad del usuario.
- En la consola de CloudWatch, elija Grupos de registros bajo Troncos en el panel de navegación.
- Busque
/aws/redshift/cluster/demo.
Esto mostrará todos los grupos de registros creados para los clústeres de Amazon Redshift.

Crear una tabla de auditoría de DynamoDB
Para crear su tabla de auditoría, complete los siguientes pasos:
- En la consola DynamoDB, elija Mesas en el panel de navegación.
- Elige Crear una tabla.
- Nombre de la tabla, introduzca
demo_redshift_audit_logs. - Clave de partición, introduzca
partKeycon el tipo de datos como String.

- Mantenga la configuración de la tabla como predeterminada.
- Elige Crear una tabla.
Crear recursos de Slack
Los webhooks entrantes de Slack esperan un JSON solicitud con una cadena de mensaje correspondiente a un "text" llave. También admiten la personalización de mensajes, como agregar un nombre de usuario y un ícono, o anular el canal predeterminado del webhook. Para más información, ver Envío de mensajes mediante webhooks entrantes en el sitio web de Slack.
Los siguientes recursos se crean para esta publicación:
- Un espacio de trabajo de Slack llamado
demo_rc - Un canal llamado
#blog-demoen el espacio de trabajo de Slack recién creado - Una nueva aplicación de Slack en el espacio de trabajo de Slack llamada
demo_redshift_ntfn(utilizando la Desde cero opción) - Anote la URL del webhook entrante, que se utilizará en esta publicación para enviar las notificaciones.
Crear un rol y una política de IAM
En esta sección, creamos un Gestión de identidades y accesos de AWS (YO SOY) política que se adjuntará a un Rol de IAM. Luego, el rol se usa para otorgar acceso a una función de Lambda a una tabla de DynamoDB. La política también incluye permisos para permitir que la función Lambda escriba archivos de registro en Registros de Amazon CloudWatch.
- En la consola de IAM, elija Políticas internas en el panel de navegación.
- Elige Crear política.
- En Crear política sección, elija el JSON e ingrese la siguiente política de IAM. Asegúrese de reemplazar su ID de cuenta de AWS en la política (reemplace XXXXXXXX con su ID de cuenta de AWS).
- Elige Siguiente: Etiquetas, A continuación, elija Siguiente: Revisión.
- Proporcione el nombre de la política
demo_post_policyy elige Crear política.
Aplicar demo_post_policy a una función de Lambda, primero debe adjuntar la política a un rol de IAM.
- En la consola de IAM, elija Roles en el panel de navegación.
- Elige Crear rol.
- Seleccione Servicio de AWS Y luego seleccione lambda.
- Elige Siguiente.

- En Agregar permisos página, buscar
demo_post_policy. - Seleccione
demo_post_policyde la lista de resultados de búsqueda devueltos, luego elija Siguiente.

- En Revisar página, ingrese
demo_post_rolepara el rol y una descripción apropiada, luego seleccione Crear rol.

Crear una función Lambda
Creamos una función Lambda con Python 3.9. En el siguiente código, reemplace el slack_hook parámetro con el webhook de Slack que copió anteriormente:
Crea tu función con los siguientes pasos:
- En la consola Lambda, elija Crear función.
- Seleccione Autor desde cero y para Nombre de la función, introduzca
demo_function. - Runtime, elija Python 3.9.
- Rol de ejecución, seleccione Use un rol existente y elige
demo_post_rolecomo el rol de IAM. - Elige Crear función.

- En Código , ingrese la función Lambda anterior y reemplace la URL del webhook de Slack.
- Elige Despliegue.

Crear un filtro de suscripción de CloudWatch
Necesitamos crear el filtro de suscripción de CloudWatch en el useractivitylog grupo de registro creado por los clústeres de Amazon Redshift.
- En la consola de CloudWatch, vaya al grupo de registro
/aws/redshift/cluster/demo-cluster-ou1/useractivitylog. - En Filtros de suscripción pestaña, en la Crear menú, seleccione Crear filtro de suscripción de Lambda.

- Elige
demo_functioncomo la función Lambda. - Formato de registro, escoger Otro.
- Proporcione el patrón de filtro de suscripción como
?create ?alter ?drop ?grant ?revoke. - Proporcione el nombre del filtro como
Sensitive Queries demo-cluster-ou1. - Pruebe el filtro seleccionando el flujo de registro real. Si tiene alguna consulta con un patrón de coincidencia, puede ver algunos resultados. Para probar, use el siguiente patrón y elija Patrón de prueba.

- Elige Iniciar la transmisión.

- Repita los mismos pasos para
/aws/redshift/cluster/demo-cluster-ou2/useractivitylogy/aws/redshift/cluster/demo-cluster-ou3/useractivitylogdando nombres de filtro de suscripción únicos. - Complete los pasos anteriores para crear un segundo filtro de suscripción para cada uno de los almacenes de datos de Amazon Redshift con el patrón de filtro
?CREATE ?ALTER ?DROP ?GRANT ?REVOKE, lo que garantiza que los comandos SQL en mayúsculas también se capturen a través de esta solución.

Prueba la solución
En esta sección, probamos la solución en los tres clústeres de Amazon Redshift que creamos en los pasos anteriores y verificamos las notificaciones de los comandos en el canal de Slack según los filtros de suscripción de CloudWatch, así como los datos que se ingieren en la tabla de DynamoDB. Usamos los siguientes comandos para probar la solución; sin embargo, esto no está restringido solo a estos comandos. Puede verificar con otros comandos DDL según los criterios de filtro en su clúster de Amazon Redshift.
En el canal de Slack, los detalles de las notificaciones se ven como la siguiente captura de pantalla.

Para obtener los resultados en DynamoDB, complete los siguientes pasos:
- En la consola DynamoDB, elija Explorar elementos bajo Mesas en el panel de navegación.
- En Mesas panel, seleccione
demo_redshift_audit_logs. - Seleccione Escanear y Ejecutar para obtener los resultados en la tabla.

Federación de Athena sobre la tabla de DynamoDB
El proyecto Conector Athena DynamoDB permite que Athena se comunique con DynamoDB para que pueda consultar sus tablas con SQL. Como parte de los requisitos previos para esto, implemente el conector en su cuenta de AWS mediante la consola de Athena o el Repositorio de aplicaciones sin servidor de AWS. Para obtener más detalles, consulte Implementación de un conector de origen de datos or Uso del repositorio de aplicaciones sin servidor de AWS para implementar un conector de origen de datos. Para esta publicación, usamos la consola de Athena.
- En la consola de Athena, debajo Administración en el panel de navegación, elija Fuentes de datos.
- Elige Crear fuente de datos.

- Seleccione la fuente de datos como Amazon DynamoDB, A continuación, elija Siguiente.

- Nombre de fuente de datos, introduzca
dynamo_db. - función lambda, escoger Crear función Lambda para abrir una nueva ventana con la consola de Lambda.

- under Configuración de la aplicación, ingrese la siguiente informacion:
- Nombre de la aplicación, introduzca
AthenaDynamoDBConnector. - DerrameCubo, ingrese el nombre de un depósito S3.
- AthenaNombre del catálogo, introduzca
dynamo. - DeshabilitarSpillEncryption, introduzca
false. - LambdaMemoria, introduzca
3008. - Tiempo de espera Lambda, introduzca
900. - DerramePrefijo, introduzca
athena-spill-dynamo.
- Nombre de la aplicación, introduzca

- Seleccione Reconozco que esta aplicación crea roles de IAM personalizados y elige Despliegue.
- Espere a que se implemente la función, luego regrese a la ventana de Athena y elija el icono de actualización junto a función lambda.
- Seleccione la función Lambda recién implementada y elija Siguiente.

- Revisa la información y elige Crear fuente de datos.
- Navegue de regreso al editor de consultas, luego elija
dynamo_dbpara Fuente de datos ydefaultpara Base de datos. - Ejecute la siguiente consulta en el editor para verificar los datos de muestra:

Visualice los datos en QuickSight
En esta sección, creamos un panel de gobierno simple en QuickSight usando Athena en modo de consulta directa para consultar el conjunto de registros, que se almacena de forma persistente en una tabla de DynamoDB.
- Regístrese en QuickSight en la consola QuickSight.
- Seleccione Atenea amazónica como un recurso
- Elige lambda y seleccione la función Lambda creada para la federación de DynamoDB.

- Crea un nuevo conjunto de datos en QuickSight con Athena como fuente.
- Proporcione el nombre de la fuente de datos como
demo_blog. - Elige
dynamo_dbpara Catálogo,defaultpara Base de datosydemo_redshift_audit_logspara Mesa. - Elige Editar / Vista previa de datos.

- Elige Cordón existentes
sqlTimestampcolumna y elija Fecha.

- En el cuadro de diálogo que aparece, ingrese el formato de datos
yyyy-MM-dd'T'HH:mm:ssZZ. - Elige Validar y Actualizar.

- Elige PUBLICAR Y VISUALIZAR.
- Elige Ficha interactiva y elige CREAR.
Esto lo llevará a la página de visualización para crear el análisis en QuickSight.
- Cree un panel de gobierno con el tipo de visualización adecuado.
Para obtener más detalles sobre cómo diseñar y realizar los esfuerzos de seguimiento y evaluación, refierase a Vídeos de aprendizaje de Amazon QuickSight en la comunidad QuickSight para el nivel básico a avanzado de autoría. La siguiente captura de pantalla es una visualización de muestra creada en estos datos.

Limpiar
Limpie sus recursos con los siguientes pasos:
- Eliminar todos los clústeres de Amazon Redshift.
- Eliminar la función Lambda.
- Elimine los grupos de registro de CloudWatch para Amazon Redshift y Lambda.
- Elimine la fuente de datos de Athena para DynamoDB.
- Eliminar la tabla de DynamoDB.
Conclusión
Amazon Redshift es un almacén de datos potente y completamente administrado que puede ofrecer un rendimiento significativamente mayor y un menor costo en la nube. En esta publicación, discutimos un patrón para implementar un mecanismo de gobierno para identificar y notificar consultas confidenciales de DDL/DCL en un almacén de datos de Amazon Redshift, y creamos un tablero rápido para permitir que el DBA y el equipo de seguridad tomen medidas oportunas y rápidas según sea necesario. Además, puede ampliar esta solución para incluir comandos DDL utilizados para Uso compartido de datos de Amazon Redshift a través de clústeres.
Excelencia operacional es una parte fundamental del gobierno de datos general en la creación de una arquitectura de datos moderna, ya que es un gran habilitador para impulsar el negocio de nuestros clientes. Idealmente, cualquier implementación de gobierno de datos es una combinación de personas, procesos y tecnología que las organizaciones utilizan para garantizar la calidad y seguridad de sus datos a lo largo de su ciclo de vida. Utilice estas instrucciones para configurar su mecanismo de notificación automatizado a medida que se detectan consultas confidenciales, así como para crear un panel rápido en QuickSight para realizar un seguimiento de las actividades a lo largo del tiempo.
Acerca de los autores
 Rajdip Chaudhuri es Arquitecto de Soluciones Sénior en Amazon Web Services y se especializa en datos y análisis. Le gusta trabajar con los clientes y socios de AWS en los requisitos de análisis y datos. En su tiempo libre le gusta el fútbol y el cine.
Rajdip Chaudhuri es Arquitecto de Soluciones Sénior en Amazon Web Services y se especializa en datos y análisis. Le gusta trabajar con los clientes y socios de AWS en los requisitos de análisis y datos. En su tiempo libre le gusta el fútbol y el cine.
 Dhiraj Thakur es un arquitecto de soluciones con Amazon Web Services. Trabaja con los clientes y socios de AWS para proporcionar orientación sobre la adopción, la migración y la estrategia de la nube empresarial. Es un apasionado de la tecnología y disfruta construyendo y experimentando en el espacio analítico y AI / ML.
Dhiraj Thakur es un arquitecto de soluciones con Amazon Web Services. Trabaja con los clientes y socios de AWS para proporcionar orientación sobre la adopción, la migración y la estrategia de la nube empresarial. Es un apasionado de la tecnología y disfruta construyendo y experimentando en el espacio analítico y AI / ML.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/centralize-near-real-time-governance-through-alerts-on-amazon-redshift-data-warehouses-for-sensitive-queries/

