ChatGPT es un GPT (Generativo Pre-entrenado Transformer) herramienta de aprendizaje automático (ML) que ha sorprendido al mundo. Sus asombrosas capacidades impresionan a usuarios ocasionales, profesionales, investigadores e incluso a sus propios creadores. Además, su capacidad para ser un modelo de ML entrenado para tareas generales y desempeñarse muy bien en situaciones de dominio específico es impresionante. Soy investigador y me interesa su capacidad para hacer análisis de sentimiento (SA).
Si le hace a ChatGPT esta pregunta de investigación, que es el título de este artículo, le dará una respuesta humilde (continúe, inténtelo). Pero, oh, querido lector, por lo general no te estropearía esto, pero no tienes idea de cuán sorprendentemente modesta fue esta respuesta de ChatGPT...
Aún así, como investigador de IA, profesional de la industria y aficionado, estoy acostumbrado a ajustar las herramientas de aprendizaje automático de NLP de dominio general (por ejemplo, GloVe) para su uso en tareas específicas de dominio. Este es el caso porque era poco común para la mayoría de los dominios encontrar una solución lista para usar que pudiera funcionar lo suficientemente bien sin algunos ajustes. Te mostraré cómo esto ya no podría ser el caso.
En este texto, comparo ChatGPT con un modelo de aprendizaje automático específico de dominio al analizar los siguientes temas:
SemEval 2017 Tarea 5: un desafío específico de dominio
Uso de la API de ChatGPT para etiquetar un conjunto de datos con ejemplos de código
Veredicto y resultados de la comparación con detalles de reproducibilidad
Conclusión y discusión de resultados
BONUS: Cómo se puede hacer esta comparación en un escenario aplicado
notas 1: Este es solo un experimento práctico simple que arroja algo de luz sobre el tema, NO una exhaustiva investigación científica.
notas 2: Todas las imágenes, a menos que se indique lo contrario, son del autor.
1. SemEval 2017 Tarea 5 — Un desafío específico de dominio
SemEval (Singrotesco evaluaruación) es un taller de PNL de renombre donde los equipos de investigación compiten científicamente en análisis de sentimientos, similitud de textos y tareas de respuesta a preguntas. Los organizadores proporcionan datos textuales y conjuntos de datos estándar creados por anotadores (especialistas en el dominio) y lingüistas para evaluar soluciones de vanguardia para cada tarea.
En particular, la de SemEval Tarea 5 de la edición 2017 pidió a los investigadores que calificaran microblogs financieros y titulares de noticias para el análisis de sentimientos en una escala de -1 (más negativa) a 1 (más positiva). Usaremos el conjunto de datos estándar de oro de SemEval de ese año para probar el rendimiento de ChatGPT en una tarea específica del dominio. El conjunto de datos de la subtarea 2 (titulares de noticias) tenía dos conjuntos de oraciones (con un máximo de 30 palabras cada uno): los conjuntos de entrenamiento (1,142 oraciones) y de prueba (491 oraciones).
Teniendo en cuenta estos conjuntos, la distribución de datos de las puntuaciones de opinión y las frases de texto se muestra a continuación. El siguiente gráfico muestra las distribuciones bimodales en los conjuntos de entrenamiento y prueba. Además, el gráfico indica más oraciones positivas que negativas en el conjunto de datos. Esta será una pieza de información útil en la sección de evaluación.
SemEval 2017 Tarea 5 Subtarea 2 (titulares de noticias) puntaje de sentimiento de distribución de datos considerando los conjuntos de entrenamiento (izquierda: 1,142 oraciones) y prueba (derecha: 491 oraciones).
Para esta subtarea, el equipo de investigación ganador (es decir, el que obtuvo la mejor calificación en el conjunto de prueba) nombró a su arquitectura ML Fortia-FBK. Inspirados por los descubrimientos de esta competencia, algunos colegas y yo hicimos un artículo de investigación (Evaluación de técnicas de análisis de sentimiento basadas en regresión en textos financieros) donde implementamos nuestra versión de Fortia-FBK y evaluamos formas de mejorar esta arquitectura.
Además, investigamos los factores que hicieron de esta arquitectura la ganadora. Por lo tanto, nuestra implementación (el código está aquí) de esta arquitectura ganadora (es decir, Fortia-FBK) se utilizará para la comparación con ChatGPT. La arquitectura (CNN+GloVe+Vader) empleada es la que se muestra a continuación.
2. Uso de la API de ChatGPT para etiquetar un conjunto de datos
El uso de la API de ChatGPT ya se ha discutido aquí en Medium para sintetizar datos. Además, puede encontrar ejemplos de etiquetado de opiniones en el Sección de ejemplos de código API de ChatGPT (Tenga en cuenta que el uso de la API no es gratuito). Para este ejemplo de código, considere el conjunto de datos estándar de oro de Task 2017 de SemEval que puede Llegar aquí.
Luego, para usar la API para etiquetar varias oraciones a la vez, use un código como tal, donde preparo un mensaje completo con oraciones de un marco de datos con el conjunto de datos Gold-Standard con la oración a etiquetar y la empresa objetivo a la que se dirige el sentimiento. se refiere.
def prepare_long_prompt(df): initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:nn" prompt = """ + df['company'] + """ + " [" + df['title'] + ")]" return initial_txt + 'n'.join(prompt.tolist())
Luego, llame a la API para el texto-davinci-003motor (versión GPT-3). Aquí realicé algunos ajustes al código para tener en cuenta el número máximo de caracteres totales en el indicador más la respuesta, que debe tener como máximo 4097 caracteres.
def call_chatgpt_api(prompt): # getting the maxium amount of tokens allowed to the response, based on the # api Max of 4097, and considering the length of the prompt text prompt_length = len(prompt) max_tokens = 4097 - prompt_length # this rule of dividing by 10 is just a empirical estimation and is not a precise rule if max_tokens < (prompt_length / 10): raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size') response = openai.Completion.create( model="text-davinci-003", prompt=prompt, temperature=0, max_tokens=max_tokens, top_p=1, frequency_penalty=0, presence_penalty=0 ) return response.choices[0]['text'] long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)
En última instancia, al hacer eso para un total de 1633 (conjuntos de entrenamiento + prueba) oraciones en el conjunto de datos estándar de oro, obtendrá los siguientes resultados con las etiquetas API de ChatGPT.
Ejemplo de SemEval 2017 Tarea 5 Subtarea 2 (titulares de noticias) Conjunto de datos Gold-Standard con sentimiento etiquetado usando la API de ChatGPT.
2.1. Problemas con ChatGPT y su API a escala
Al igual que con cualquier otra API, existen algunos requisitos típicos
Límite de tasa de solicitudes que requiere ajustes de limitación
Límite de solicitud de 25000 tokens (es decir, unidad de subpalabra o codificación de par de bytes)
Longitud máxima de 4096 tokens por solicitud (solicitud + respuesta incluida)
Costo de $0.0200 / 1K tokens (Nota: nunca gasté más de U$ 2 después de todo lo que hice)
Sin embargo, estos son solo los requisitos típicos cuando se trata de la mayoría de las API. Además, recuerde que en este problema de dominio específico, hay una entidad de destino (es decir, una empresa) para cada frase del sentimiento. Así que tuve que jugar hasta que diseñé un patrón rápido que hizo posible etiquetar el sentimiento de varias oraciones a la vez y facilitar el procesamiento posterior de los resultados. Además, esas son otras limitaciones que afectaron el indicador y el código que mostré anteriormente. Específicamente, encontré problemas al usar esta API de texto para varias oraciones (>1000).
Reproducibilidad: Las evaluaciones de sentimiento de ChatGPT sobre el sentimiento pueden cambiar significativamente con muy pocos cambios en el aviso (por ejemplo, agregar o eliminar una coma o un punto de la oración).
Consistencia: Si no especifica claramente la respuesta del patrón, ChatGPT se volverá creativo (incluso si selecciona un parámetro de aleatoriedad muy bajo), lo que dificultará el procesamiento de los resultados. Además, incluso cuando especifica el patrón, puede generar formatos de salida inconsistentes.
Desajustes: Aunque puede identificar con mucha precisión la entidad de destino (por ejemplo, una empresa) para la que desea que se evalúe el sentimiento en una oración, puede confundir los resultados al hacer esto a escala. Por ejemplo, suponga que transmite 10 oraciones cada una con una empresa objetivo. Aún así, algunas de las empresas aparecen en otras oraciones o se repiten. En ese caso, ChatGPT puede no coincidir con los objetivos y las opiniones de las oraciones, cambiar el orden de las etiquetas de opiniones o proporcionar menos de 10 etiquetas.
Todos estos problemas implican una curva de aprendizaje para usar correctamente la API (parcial). Requirió algunos ajustes para obtener lo que necesitaba. A veces tuve que hacer muchas pruebas hasta alcanzar el resultado deseado con una mínima consistencia.
Debe enviar tantas oraciones como sea posible a la vez en una situación ideal por dos razones. Primero, desea obtener sus etiquetas lo más rápido posible. En segundo lugar, el aviso cuenta como tokens en el costo, por lo que menos solicitudes significan menos costo. Sin embargo, tenemos un límite de 4096 tokens por solicitud. Además, dados los problemas que mencioné, existe otra limitación API notable. Pasar demasiadas oraciones a la vez aumenta la posibilidad de desajustes e inconsistencias. Por lo tanto, depende de usted seguir aumentando y disminuyendo el número de oraciones hasta que encuentre su punto óptimo de consistencia y costo. Si no lo hace correctamente, sufrirá en la fase de resultados del posprocesamiento.
En resumen, si tiene miles de oraciones para procesar, comience con un lote de media docena de oraciones y no más de 10 indicaciones para verificar la confiabilidad de las respuestas. Luego, aumente lentamente el número para verificar la capacidad y la calidad hasta que encuentre el indicador y la velocidad óptimos que se ajusten a su tarea.
3. Veredicto y resultados de la comparación
3.1. Detalles de la comparación
ChatGPT, en su versión GPT-3, no puede atribuir sentimiento a oraciones de texto usando valores numéricos (sin importar cuánto lo intente). Sin embargo, los especialistas atribuyeron puntajes numéricos a los sentimientos de las oraciones en este conjunto de datos Gold-Standard en particular.
Entonces, para hacer una comparación viable, tuve que:
Categorizar las puntuaciones del conjunto de datos en Positivo, Neutroo Negativo etiquetas.
Haga lo mismo con las puntuaciones producidas a partir del modelo de aprendizaje automático específico del dominio.
Defina un rango de umbrales posibles (con pasos de 0.001) para determinar dónde comienza y termina una categoría. Entonces, dado el umbral TH,puntajes arriba +TH son considerados Positivo sentimiento, abajo –TH is Negarive, y entre son Neutro.
Itere sobre el rango de umbrales y evalúe la precisión de ambos modelos en cada punto.
Investigue su desempeño por conjuntos (es decir, entrenamiento o prueba), dado que el modelo específico de dominio tendría una ventaja injusta en el conjunto de entrenamiento.
El código para el paso 3 se encuentra a continuación. Y el código completo para replicar toda la comparación. es aquí.
3.2. Veredicto: Sí, ChatGPT no solo puede ganar sino destrozar la competencia
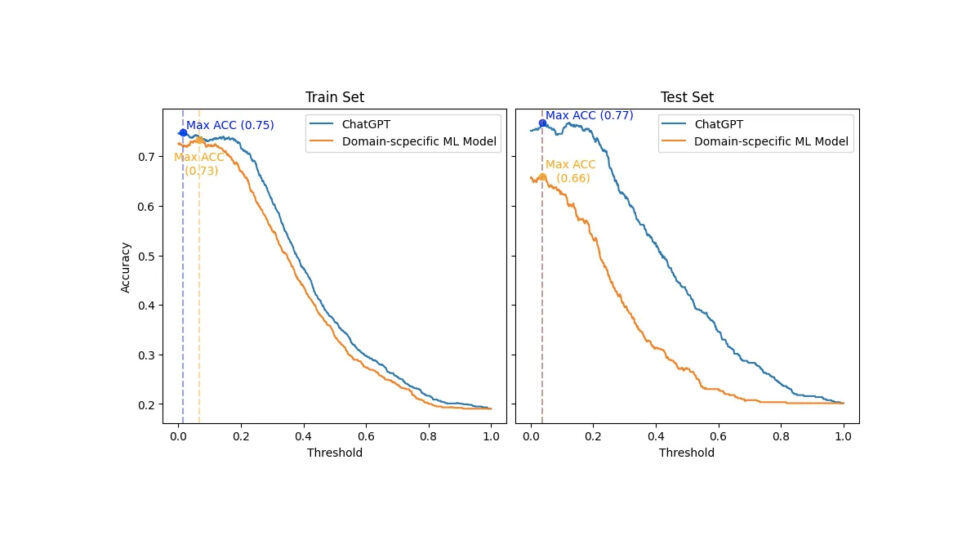
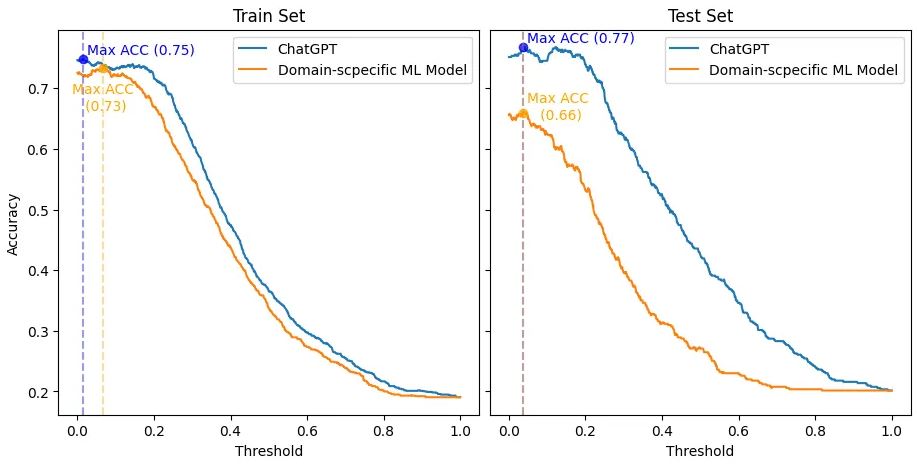
El resultado final se muestra en el siguiente gráfico, que muestra cómo cambia la precisión (eje y) para ambos modelos al categorizar el conjunto de datos Gold-Standard numérico, a medida que se ajusta el umbral (eje x). Además, los conjuntos de entrenamiento y prueba están en los lados izquierdo y derecho, respectivamente.
Comparación entre ChatGPT y el modelo de aprendizaje automático específico del dominio que considera el conjunto de entrenamiento (lado izquierdo) y prueba (lado derecho) por separado. Esta evaluación evalúa cómo cambia la precisión (eje y) con respecto al umbral (eje x) para categorizar el conjunto de datos Gold-Standard numérico para ambos modelos.
Primero, debo ser honesto. No esperaba este resultado aplastante. En consecuencia, para no ser injusto con ChatGPT, reproduje la configuración original de la competencia SemEval 2017, donde el modelo de aprendizaje automático específico del dominio se construiría con el conjunto de entrenamiento. Entonces, la clasificación y la comparación reales solo ocurrirían sobre el conjunto de prueba.
Sin embargo, incluso en el conjunto de entrenamiento, con el escenario más favorable (umbral de 0.066 frente a 0.014 para ChatGPT), el modelo de aprendizaje automático específico del dominio logró como máximo una precisión 2pp peor que la mejor precisión de ChatGPT (0.73 frente a 0.75). Además, ChatGPT mostró una precisión superior en todos los umbrales que el modelo de dominio específico en los conjuntos de entrenamiento y prueba.
Curiosamente, el mejor umbral para ambos modelos (0.038 y 0.037) estuvo cerca en el conjunto de prueba. Y en este umbral, ChatGPT logró una precisión 11 pp mayor que el modelo de dominio específico (0.66 frente a 077). Además, ChatGPT mostró una consistencia mucho mejor en los cambios de umbral que el modelo específico de dominio. Por lo tanto, es visible que la precisión de ChatGPT disminuyó mucho menos abruptamente.
En resumen, ChatGPT superó con creces al modelo de aprendizaje automático específico de dominio en precisión. Además, la idea es que ChatGPT podría ajustarse a tareas específicas. Por lo tanto, imagina cuánto mejor podría llegar a ser ChatGPT.
3.3. Investigando el etiquetado de opiniones de ChatGPT
Siempre tuve la intención de hacer una investigación más micro tomando ejemplos en los que ChatGPT era inexacto y comparándolo con el modelo específico de dominio. Sin embargo, como ChatGPT funcionó mucho mejor de lo previsto, pasé a investigar solo los casos en los que no se obtuvo el sentimiento correcto.
Inicialmente, realicé una evaluación similar a la anterior, pero ahora utilicé el conjunto de datos Gold-Standard completo a la vez. Luego, seleccioné el umbral (0.016) para convertir los valores numéricos Gold-Standard en las etiquetas Positivo, Neutral y Negativo que incurrieron en la mejor precisión de ChatGPT (0.75). Luego, hice una matriz de confusión. Las parcelas están abajo.
En el lado izquierdo, un gráfico de líneas para evaluar cómo cambia la precisión de ChatGPT (eje y) con respecto al umbral (eje x) para categorizar el conjunto de datos completo Gold-Standard numérico. La matriz de confusión para las etiquetas positiva, neutra y negativa está en el lado derecho, dado que el umbral que conduce al máximo rendimiento de ChatGPT es 0.016. Además, la matriz de confusión contiene el porcentaje de aciertos y errores de ChatGPT según las etiquetas convertidas.
Recuerde que mostré una distribución de oraciones de datos con puntajes más positivos que oraciones negativas en una sección anterior. Aquí en la matriz de confusión, observe que considerando el umbral de 0.016, hay 922 (56.39%) frases positivas, 649 (39.69%) negativas y 64 (3.91%) neutras.
Además, tenga en cuenta que ChatGPT es menos preciso con etiquetas neutrales. Esto es de esperar, ya que estas son las etiquetas que son más propensas a verse afectadas por los límites del umbral. Curiosamente, ChatGPT tendía a categorizar la mayoría de estas oraciones neutrales como positivas. Sin embargo, dado que se consideran neutrales menos oraciones, este fenómeno puede estar relacionado con mayores puntajes de sentimiento positivo en el conjunto de datos.
Por otro lado, al considerar las otras etiquetas, ChatGPT mostró la capacidad de identificar correctamente 6pp más categorías positivas que negativas (78.52% vs. 72.11%). En este caso, no estoy seguro de que esto esté relacionado con el número de oraciones de cada espectro de puntuación. Primero, porque hay muchas más oraciones de cada tipo de categoría. En segundo lugar, observe la cantidad de fallas de ChatGPT que fueron a las etiquetas en la dirección opuesta (positiva a negativa o viceversa). Nuevamente, ChatGPT comete más errores de este tipo con la categoría negativa, que es mucho menos numerosa. Por lo tanto, ChatGPT parece tener más problemas con las oraciones negativas que con las positivas.
3.4. Algunos casos específicos y comparación con los especialistas humanos
Seleccioné algunas oraciones con las particularidades más notables entre Gold-Standard (puntajes humanos) y ChatGPT. Luego, utilicé el mismo umbral establecido anteriormente para convertir las puntuaciones numéricas en etiquetas de sentimiento (0.016). Además, Ya se ha informado que ChatGPT supera a los humanos. Por lo tanto, investigué las discrepancias y di mi decisión, en la que Humans o Chatgpt que encontré fueron más precisos.
La tabla muestra ejemplos de frases con discrepancias entre las etiquetas Gold-Standard (convertidas a partir de puntuaciones de especialistas humanos utilizando los umbrales de 0.016) y ChatGPT. Además, di mi decisión sobre cuál estaba mejor de acuerdo.
Comenzando con los casos en los que fallé a favor de los especialistas humanos. En los casos de las oraciones 3 y 4, ChatGPT debería haberse dado cuenta de que recuperar los pagos y las alianzas de empresas generalmente se consideran beneficiosos en el dominio financiero. Sin embargo, en el caso de la sentencia 7, le pedí que explicara su decisión, y esto es lo que respondió ChatGPT:
El sentimiento positivo hacia Barclays se transmite por la palabra "récord", que implica un logro significativo para la empresa en la resolución exitosa de problemas legales con los organismos reguladores.
En el caso de esta oración, ChatGPT no entendió que, aunque cerrar un contrato discográfico generalmente puede ser bueno, la SEC es un organismo regulador. Por lo tanto, llegar a un acuerdo discográfico con la SEC significa que Barclays y Credit Suisse tuvieron que pagar un valor récord en multas.
Pasando a las oraciones 5 y 8, estas fueron llamadas muy difíciles. Permítanme ser claro, los humanos tenían razón en sus evaluaciones. Sin embargo, el caso es que ChatGPT simplemente no podría haber adivinado esos. En la oración 5, se requería conocimiento de la situación en ese momento para entender que la oración representó un buen resultado. Y para la oración 8, se necesita saber que una caída del precio del petróleo se correlaciona con una caída del precio de las acciones de esa empresa objetivo específica.
Luego, para la oración 6, lo más neutral que una oración puede obtener con un puntaje de sentimiento de cero, ChatGPT explicó su decisión de la siguiente manera:
La sentencia es positiva ya que se anuncia el nombramiento de un nuevo Director de Operaciones de Banca de Inversión, lo que es una buena noticia para la compañía.
Sin embargo, esta fue una respuesta genérica y no muy perspicaz y no justificaba por qué ChatGPT piensa que el nombramiento de este ejecutivo en particular fue bueno. Por lo tanto, estuve de acuerdo con los especialistas humanos en este caso.
Curiosamente, fallé favorablemente en las oraciones 1, 2, 9 y 10 para ChatGPT. Además, mirando con atención, los especialistas humanos deberían haber prestado más atención a la empresa objetivo o al mensaje general. Esto es particularmente emblemático en la oración 1, donde los especialistas deberían haber reconocido que aunque el sentimiento era positivo para Glencore, la empresa objetivo era Barclays, que acaba de escribir el informe. En este sentido, ChatGPT discernió mejor el objetivo del sentimiento y el significado de estas oraciones.
4. Conclusión y Discusión de Resultados
Como se ve en la tabla a continuación, lograr tal desempeño requirió muchos recursos financieros y humanos.
Una comparación de aspectos de los modelos, como la cantidad de parámetros, el tamaño de inserción de palabras utilizado, el costo, la cantidad de investigadores para construirlo, la mejor precisión en el conjunto de prueba y si su decisión es explicable.
En este sentido, aunque ChatGPT superó al modelo específico de dominio, la última comparación necesitaría ajustar ChatGPT para una tarea específica de dominio. Hacerlo ayudaría a abordar si las ganancias en el rendimiento del ajuste fino superan los costos del esfuerzo.
En otra nota, con la popularidad de los modelos de texto generativo y los LLM, algunos versiones de código abierto podría ayudar a armar una interesante comparación futura. Además, la capacidad de LLM como ChatGPT para explicar sus decisiones es un logro sobresaliente, posiblemente inesperado, que puede revolucionar el campo.
5. BONO: Cómo se puede hacer esta comparación en un escenario aplicado
El análisis de sentimientos en diferentes dominios es un esfuerzo científico independiente en sí mismo. Aún así, aplicar los resultados del análisis de sentimiento en un escenario apropiado puede ser otro problema científico. Además, dado que estamos considerando oraciones del dominio financiero, sería conveniente experimentar agregando características de sentimiento a un sistema inteligente aplicado. Esto es precisamente lo que han estado haciendo algunos investigadores, y yo también estoy experimentando con eso.
En 2021, algunos colegas y yo publicamos un artículo de investigación sobre cómo emplear el análisis de sentimientos en un escenario aplicado. En este artículo, presentado en la Segunda Conferencia Internacional ACM sobre IA en Finanzas (ICAIF'21), propusimos una forma eficiente de incorporar el sentimiento del mercado en una arquitectura de aprendizaje de refuerzo. El código fuente para la implementación de esta arquitectura es disponible aquí, y una parte de su diseño general se muestra a continuación.
Una parte de un ejemplo de arquitectura de cómo incorporar el sentimiento del mercado en una arquitectura de aprendizaje de refuerzo para situaciones aplicadas. Fuente:Sistemas de comercio inteligentes: un enfoque de aprendizaje de refuerzo consciente de los sentimientos. Actas de la Segunda Conferencia Internacional ACM sobre IA en Finanzas (ICAIF '21). Lima Paiva FC; Felizardo, LK; Bianchi, RA d. BC; Costa, AHR
Esta arquitectura fue diseñada para trabajar con puntajes de opinión numéricos como los del conjunto de datos Gold-Standard. Sin embargo, existen técnicas (p. ej., Índice alcista) para convertir el sentimiento categórico generado por ChatGPT en valores numéricos apropiados. La aplicación de dicha conversión hace posible el uso de sentimientos etiquetados como ChatGPT en dicha arquitectura. Además, este es un ejemplo de lo que puedes hacer en una situación así y es lo que pretendo hacer en un futuro análisis.
5.1. Otros artículos en mi línea de investigación (PNL, RL)
Davis, B., Cortis, K., Vasiliu, L., Koumpis, A., Mcdermott, R. y Handschuh, S. Índices de Sentimiento Social Desarrollados por X-Scores. ALLDATA, La Segunda Conferencia Internacional sobre Big Data, Small Data, Linked Data y Open Data (2016).