Las organizaciones están otorgando una alta prioridad a la integración de datos, especialmente para respaldar el análisis, el aprendizaje automático (ML), la inteligencia comercial (BI) y las iniciativas de desarrollo de aplicaciones. Los datos están creciendo exponencialmente y son generados por fuentes de datos cada vez más diversas. La integración de datos se vuelve un desafío cuando se procesan datos a escala y el trabajo pesado inherente asociado con la infraestructura necesaria para administrarlo. Esta es una de las razones clave por las que las organizaciones buscan constantemente soluciones de integración de datos fáciles de usar y de bajo mantenimiento para mover datos de una ubicación a otra o para consolidar sus datos comerciales de varias fuentes en una ubicación centralizada para tomar decisiones comerciales estratégicas. .
La mayoría de las organizaciones usan Spark para sus necesidades de procesamiento de big data. Si está buscando simplificar la integración de datos y no quiere la molestia de poner en marcha servidores, administrar recursos o configurar clústeres de Spark, tenemos la solución para usted.
Pegamento AWS es un servicio de integración de datos sin servidor que facilita el descubrimiento, la preparación y la combinación de datos para análisis, aprendizaje automático y desarrollo de aplicaciones. AWS Glue proporciona interfaces visuales y basadas en código para que la integración de datos sea simple y accesible para todos.
Si prefiere una experiencia basada en código y desea crear trabajos de integración de datos de forma interactiva, le recomendamos sesiones interactivas. Las sesiones interactivas son una función de AWS Glue lanzada recientemente que le permite desarrollar procesos de AWS Glue de forma interactiva, ejecutar y probar cada paso y ver los resultados.
Existen diferentes opciones para utilizar sesiones interactivas. Puede crear y trabajar con sesiones interactivas a través del Interfaz de línea de comandos de AWS (AWS CLI) y API. También puede usar cuadernos compatibles con Jupyter para crear y probar visualmente los scripts de su cuaderno. Las sesiones interactivas proporcionan un kernel de Jupyter que se integra en casi cualquier lugar donde lo haga Jupyter, incluida la integración con IDE como PyCharm, IntelliJ y Visual Studio Code. Esto le permite crear código en su entorno local y ejecutarlo sin problemas en el backend de la sesión interactiva. También puede iniciar un cuaderno a través de AWS Glue Studio; todos los pasos de configuración se realizan por usted para que pueda explorar sus datos y comenzar a desarrollar su script de trabajo después de solo unos segundos. Cuando el código esté listo, puede configurar, programar y monitorear cuadernos de trabajo como trabajos de AWS Glue.
Si no ha probado las sesiones interactivas de AWS Glue antes, esta publicación es muy recomendable. Trabajamos a través de un escenario simple en el que es posible que necesite cargar datos de forma incremental desde Servicio de almacenamiento simple de Amazon (Amazon S3) en Desplazamiento al rojo de Amazon o transforme y enriquezca sus datos antes de cargarlos en Amazon Redshift. En esta publicación, usamos sesiones interactivas dentro de un cuaderno de AWS Glue Studio para cargar el Conjunto de datos de NYC Taxi en una Amazon Redshift sin servidor clúster, consulte el conjunto de datos cargado, guarde nuestro cuaderno Jupyter como un trabajo y programe su ejecución mediante una expresión cron. Empecemos.
Resumen de la solución
Lo guiamos a través de los siguientes pasos:
- Configure un cuaderno AWS Glue Jupyter con sesiones interactivas.
- Utilice la magia del cuaderno, incluida la conexión y los marcadores de AWS Glue.
- Lea datos de Amazon S3 y transfórmelos y cárguelos en Redshift Serverless.
- Guarde el cuaderno como un trabajo de AWS Glue y prográmelo para que se ejecute.
Requisitos previos
Para este tutorial, debemos completar los siguientes requisitos previos:
- Subir Datos de registros de viaje de taxi amarillo y del tabla de búsqueda de zona de taxis conjuntos de datos en Amazon S3. Los pasos para hacerlo se enumeran en la siguiente sección.
- Prepara lo necesario Gestión de identidades y accesos de AWS (IAM) políticas y roles para trabajar con AWS Glue Studio Jupyter notebooks, sesiones interactivas y AWS Glue.
- Cree la conexión de AWS Glue para Redshift Serverless.
Cargue conjuntos de datos en Amazon S3
Descargar Datos de registros de viaje de taxi amarillo y datos de la tabla de búsqueda de zona de rodaje a su entorno local. Para esta publicación, descargamos los datos de enero de 2022 para los registros de viaje de taxi amarillo en formato Parquet. Los datos de búsqueda de la zona de rodaje están en formato CSV. También puede descargar el Diccionario de datos para el conjunto de datos del registro de viaje.
- En la consola de Amazon S3, crear un cubo , que son
my-first-aws-glue-is-project-<random number>existentesus-east-1Región para almacenar los datos.Los nombres de los depósitos de S3 deben ser únicos en todas las cuentas de AWS en todas las regiones. - Crear carpetas
nyc_yellow_taxiytaxi_zone_lookupen el depósito que acaba de crear y cargue los archivos que descargó.
Las estructuras de carpetas deben parecerse a las siguientes capturas de pantalla.

Preparar políticas y roles de IAM
Preparemos las políticas y el rol de IAM necesarios para trabajar con los cuadernos y las sesiones interactivas de AWS Glue Studio Jupyter. Para comenzar con los cuadernos en AWS Glue Studio, consulte Introducción a los cuadernos en AWS Glue Studio.
Cree políticas de IAM para el rol de cuaderno de AWS Glue
Crear la política AWSGlueInteractiveSessionPassRolePolicy con los siguientes permisos:
Esta política permite que el rol del cuaderno de AWS Glue pase a sesiones interactivas para que se pueda usar el mismo rol en ambos lugares. Tenga en cuenta que AWSGlueServiceRole-GlueIS es el rol que creamos para el cuaderno Jupyter de AWS Glue Studio en un paso posterior. A continuación, cree la política. AmazonS3Access-MyFirstGlueISProject con los siguientes permisos:
Esta política permite que el rol del cuaderno de AWS Glue acceda a los datos en el depósito de S3.
Cree un rol de IAM para el cuaderno de AWS Glue
Cree un nuevo rol de AWS Glue llamado AWSGlueServiceRole-GlueIS con las siguientes pólizas adjuntas:
Cree la conexión de AWS Glue para Redshift Serverless
Ahora estamos listos para configurar un grupo de seguridad de Redshift Serverless para conectarse con los componentes de AWS Glue.
- En la consola de Redshift Serverless, abra el grupo de trabajo que está utilizando.
Puede encontrar todos los espacios de nombres y grupos de trabajo en el panel de Redshift Serverless. - under Acceso a los datos, escoger red y seguridad.
- Elija el enlace para el grupo de seguridad de VPC sin servidor de Redshift.
 Eres redirigido a Nube informática elástica de Amazon (Amazon EC2) consola.
Eres redirigido a Nube informática elástica de Amazon (Amazon EC2) consola. - En los detalles del grupo de seguridad de Redshift Serverless, en Reglas de entrada, escoger Editar reglas de entrada.
- Agregue una regla de autorreferencia para permitir que los componentes de AWS Glue se comuniquen:
- Tipo de Propiedad, escoger Todo TCP.
- Protocolo, escoger TCP.
- Rango de puertos, incluir todos los puertos.
- Fuente, utilice el mismo grupo de seguridad que el ID de grupo.

- Del mismo modo, agregue las siguientes reglas de salida:
- Una regla autorreferencial con Tipo de Propiedad as Todo TCP, Protocolo as TCP, Rango de puertos incluyendo todos los puertos, y Destino como el mismo grupo de seguridad que el ID de grupo.
- Una regla HTTPS para el acceso a Amazon S3. los
s3-prefix-list-idSe requiere un valor en la regla del grupo de seguridad para permitir el tráfico desde la VPC al punto de enlace de la VPC de Amazon S3.
Si no tiene un punto de enlace de la VPC de Amazon S3, puede crear uno en el Nube privada virtual de Amazon (Amazon VPC) consola.

Puede comprobar el valor de s3-prefix-list-id en Listas de prefijos administrados en la consola de Amazon VPC.

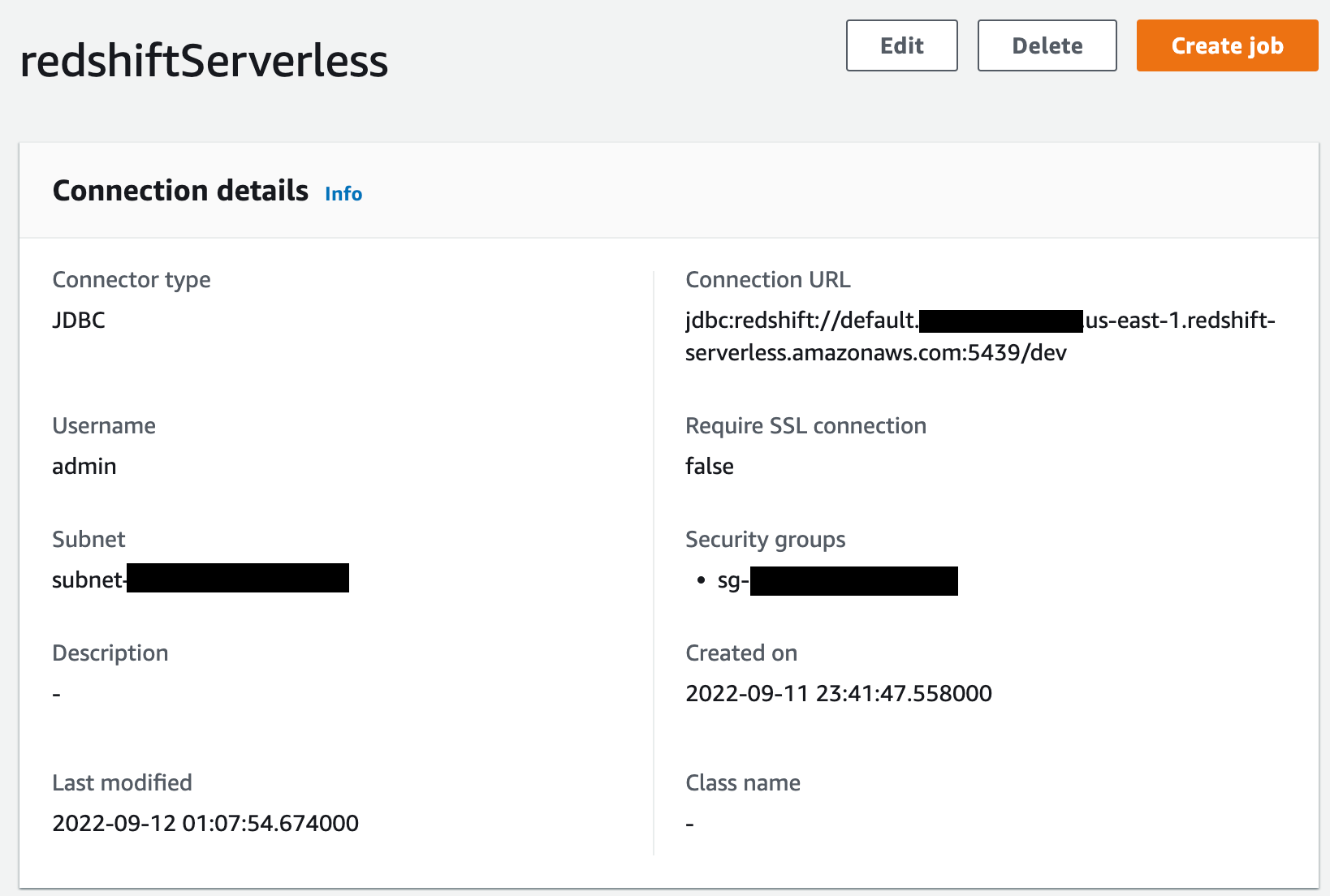
A continuación, vaya a la Conectores página en AWS Glue Studio y crear una nueva conexión JDBC , que son redshiftServerless a su clúster de Redshift Serverless (a menos que ya exista uno). Puede encontrar los detalles del punto final de Redshift Serverless en la cuenta de su grupo de trabajo. Información General
sección. La configuración de conexión se parece a la siguiente captura de pantalla.
Escriba código interactivo en un cuaderno AWS Glue Studio Jupyter con tecnología de sesiones interactivas
Ahora puede comenzar a escribir código interactivo con el cuaderno AWS Glue Studio Jupyter con tecnología de sesiones interactivas. Tenga en cuenta que es una buena práctica seguir guardando el bloc de notas a intervalos regulares mientras trabaja en él.
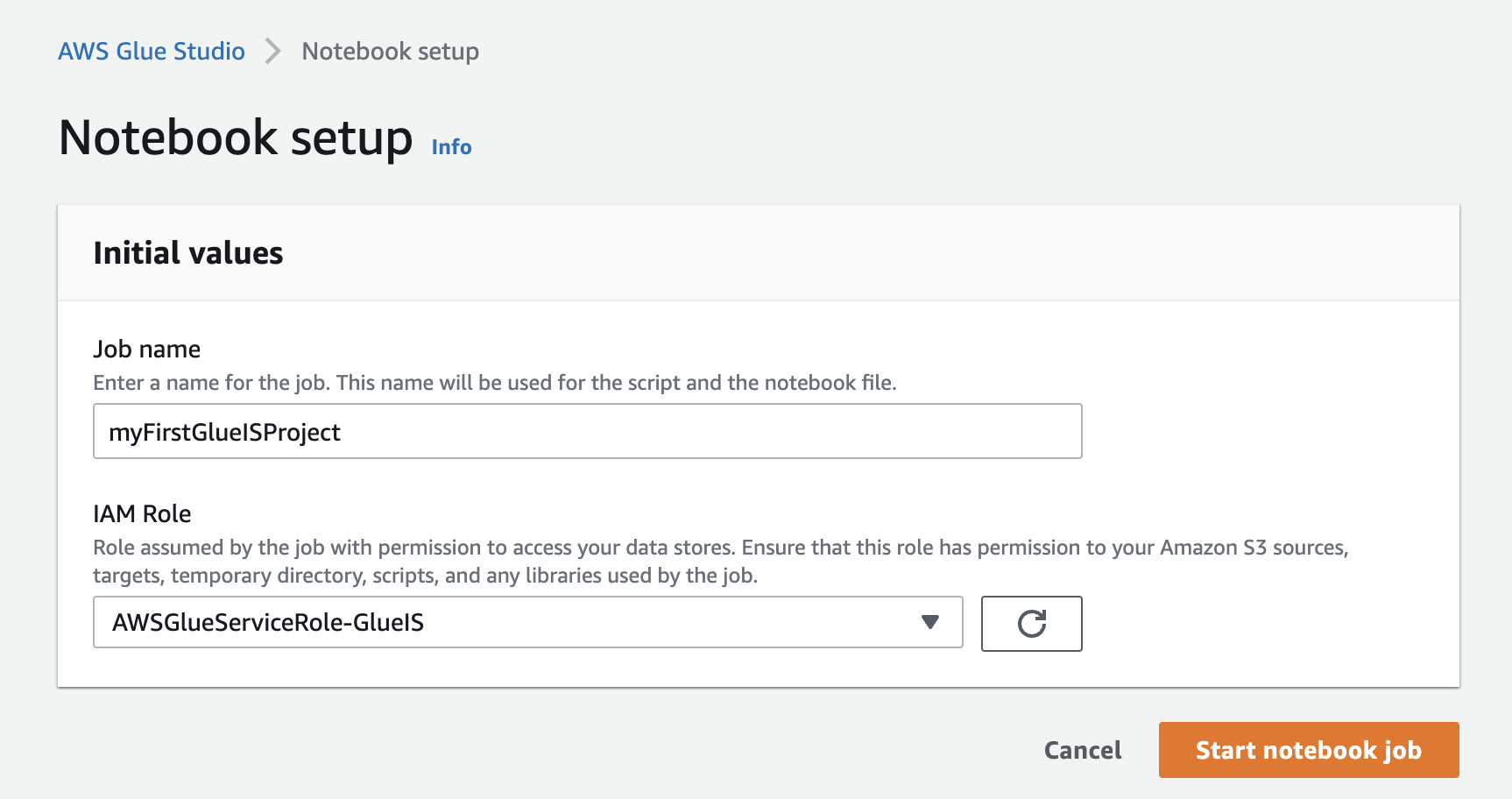
- En la consola de AWS Glue Studio, cree un nuevo trabajo.
- Seleccione Cuaderno Jupyter y seleccionar Crear un nuevo cuaderno desde cero.
- Elige Crear.

- Nombre del trabajo, ingrese un nombre (por ejemplo,
myFirstGlueISProject). - Rol de gestión de identidades y accesos, elige el rol que creaste (
AWSGlueServiceRole-GlueIS). - Elige Iniciar trabajo de cuaderno.
 Después de inicializar el cuaderno, puede ver algunas de las magias disponibles y una celda con código repetitivo. Para ver toda la magia de las sesiones interactivas, ejecute
Después de inicializar el cuaderno, puede ver algunas de las magias disponibles y una celda con código repetitivo. Para ver toda la magia de las sesiones interactivas, ejecute %helpen una celda para imprimir una lista completa. Con la excepción de%%sql, ejecutar una celda de solo magia no inicia una sesión, pero establece la configuración para la sesión que comienza cuando ejecuta su primera celda de código. Para esta publicación, configuramos AWS Glue con la versión 3.0, tres trabajadores G.1X, tiempo de espera inactivo y una conexión de Amazon Redshift con la ayuda de la magia disponible.
Para esta publicación, configuramos AWS Glue con la versión 3.0, tres trabajadores G.1X, tiempo de espera inactivo y una conexión de Amazon Redshift con la ayuda de la magia disponible. - Ingresemos la siguiente magia en nuestra primera celda y ejecútela:
Obtenemos la siguiente respuesta:
- Ejecutemos nuestra primera celda de código (código repetitivo) para iniciar una sesión de cuaderno interactivo en unos segundos:
Obtenemos la siguiente respuesta:
- A continuación, lea los datos del taxi amarillo de la ciudad de Nueva York del depósito S3 en un marco dinámico de AWS Glue:
Contemos el número de filas, observemos el esquema y algunas filas del conjunto de datos.
- Cuente las filas con el siguiente código:
Obtenemos la siguiente respuesta:
- Ver el esquema con el siguiente código:
Obtenemos la siguiente respuesta:
- Vea algunas filas del conjunto de datos con el siguiente código:
Obtenemos la siguiente respuesta:
- Ahora, lea los datos de búsqueda de la zona de rodaje del depósito S3 en un marco dinámico de AWS Glue:
Contemos el número de filas, observemos el esquema y algunas filas del conjunto de datos.
- Cuente las filas con el siguiente código:
Obtenemos la siguiente respuesta:
- Ver el esquema con el siguiente código:
Obtenemos la siguiente respuesta:
- Vea algunas filas con el siguiente código:
Obtenemos la siguiente respuesta:
- Con base en el diccionario de datos, recalibremos los tipos de datos de los atributos en marcos dinámicos correspondientes a ambos marcos dinámicos:
- Ahora vamos a comprobar su esquema:
Obtenemos la siguiente respuesta:
Obtenemos la siguiente respuesta:
- Agreguemos la columna
trip_durationpara calcular la duración de cada viaje en minutos al cuadro dinámico de viajes en taxi:Contemos el número de filas, observemos el esquema y algunas filas del conjunto de datos después de aplicar la transformación anterior.
- Obtenga un recuento de registros con el siguiente código:
Obtenemos la siguiente respuesta:
- Ver el esquema con el siguiente código:
Obtenemos la siguiente respuesta:
- Vea algunas filas con el siguiente código:
Obtenemos la siguiente respuesta:
- A continuación, cargue ambos marcos dinámicos en nuestro clúster sin servidor de Amazon Redshift:
Ahora validemos los datos cargados en el clúster sin servidor de Amazon Redshift ejecutando algunas consultas en Editor de consultas de Amazon Redshift v2. También puede utilizar su editor de consultas preferido.
- Primero, contamos el número de registros y seleccionamos algunas filas en ambas tablas de destino (
f_nyc_yellow_taxi_tripyd_nyc_taxi_zone_lookup):
El número de registros en
f_nyc_yellow_taxi_trip(2,463,931) yd_nyc_taxi_zone_lookup(265) coinciden con el número de registros en nuestro marco dinámico de entrada. Esto valida que todos los registros de archivos en Amazon S3 se hayan cargado correctamente en Amazon Redshift.Puede ver algunos de los registros de cada tabla con los siguientes comandos:


- Una de las ideas que queremos generar a partir de los conjuntos de datos es obtener las cinco rutas principales con la duración de su viaje. Ejecutemos el SQL para eso en Amazon Redshift:
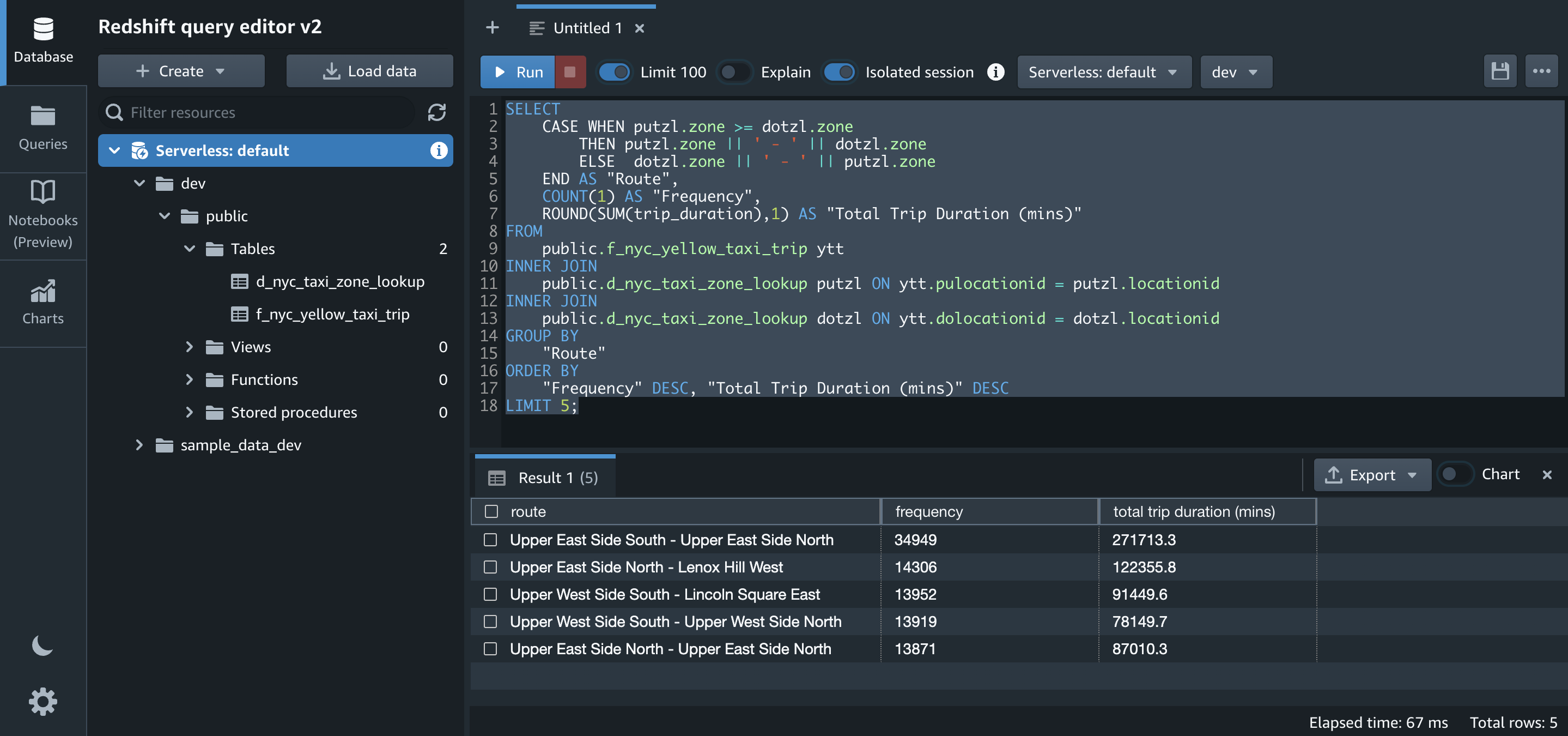
Transforme el cuaderno en un trabajo de AWS Glue y prográmelo
Ahora que hemos creado el código y probado su funcionalidad, guardémoslo como un trabajo y programémoslo.
Primero habilitemos marcadores de trabajo. Los marcadores de trabajo ayudan a AWS Glue a mantener la información de estado y evitar el reprocesamiento de datos antiguos. Con los marcadores de trabajo, puede procesar nuevos datos cuando se vuelve a ejecutar en un intervalo programado.
- Agregue el siguiente comando mágico después de la primera celda que contiene otros comandos mágicos inicializados durante la creación del código:
Para inicializar los marcadores de trabajo, ejecutamos el siguiente código con el nombre del trabajo como argumento predeterminado (
myFirstGlueISProjectpara esta publicación). Los marcadores de trabajo almacenan los estados de un trabajo. siempre debes tenerjob.init()al comienzo del guión y eljob.commit()al final del guión. Estas dos funciones se utilizan para inicializar el servicio de marcadores y actualizar el cambio de estado del servicio. Los marcadores no funcionarán sin llamarlos. - Agregue el siguiente fragmento de código después del código repetitivo:
- Luego, comente todas las líneas de código que se crearon para verificar el resultado deseado y que no son necesarias para que el trabajo entregue su propósito:
- Guarde el cuaderno.

Puede consultar el script correspondiente en el Guión .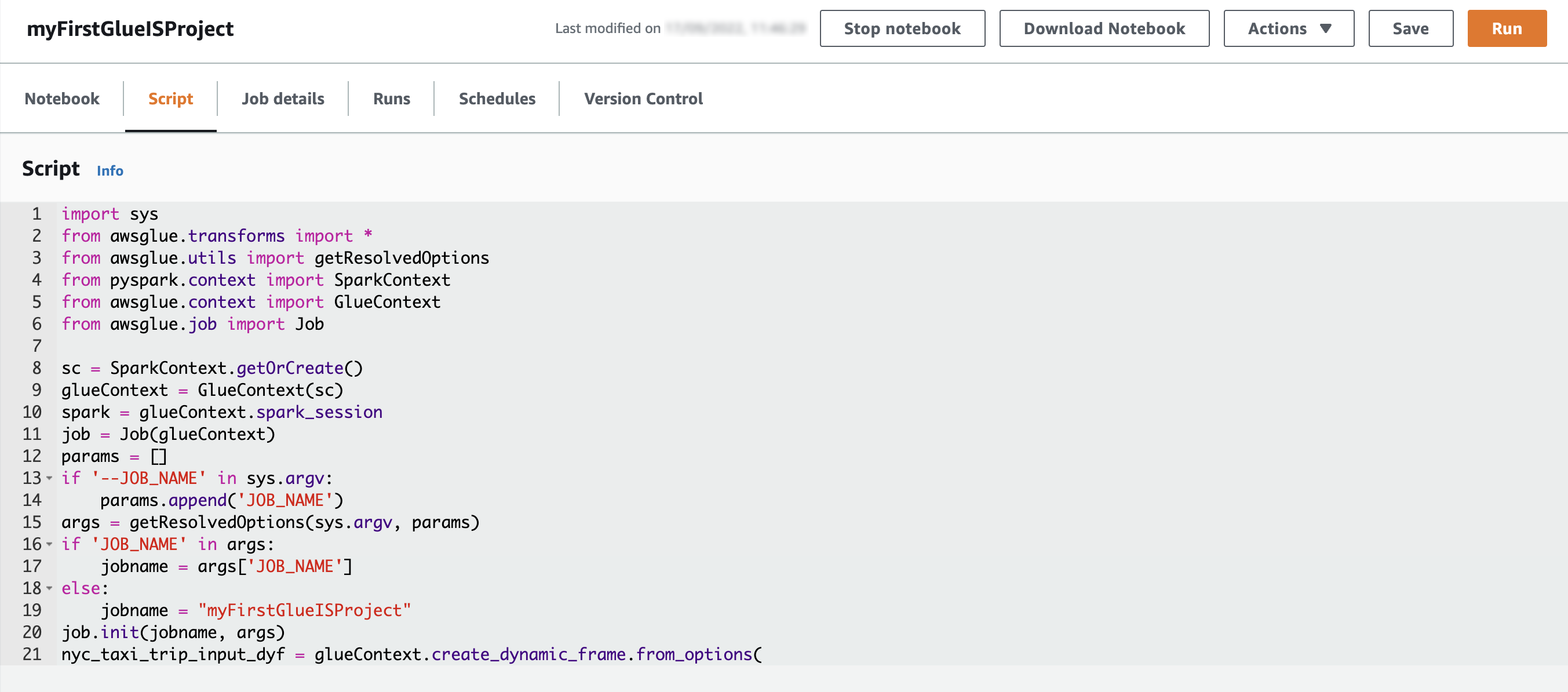 Tenga en cuenta que
Tenga en cuenta que job.commit()se agrega automáticamente al final del script. Vamos a ejecutar el cuaderno como un trabajo. - Primero, truncar
f_nyc_yellow_taxi_tripyd_nyc_taxi_zone_lookuptablas en Amazon Redshift usando el editor de consultas v2 para que no tengamos duplicados en ambas tablas: - Elige Ejecutar para ejecutar el trabajo.
 Puede comprobar su estado en la Ron .
Puede comprobar su estado en la Ron . El trabajo se completó en menos de 5 minutos con G1.x 3 DPU.
El trabajo se completó en menos de 5 minutos con G1.x 3 DPU. - Vamos a comprobar el recuento de registros en
f_nyc_yellow_taxi_tripyd_nyc_taxi_zone_lookuptablas en Amazon Redshift:
Con los marcadores de trabajos habilitados, incluso si vuelve a ejecutar el trabajo sin archivos nuevos en las carpetas correspondientes en el depósito de S3, no vuelve a procesar los mismos archivos. La siguiente captura de pantalla muestra una ejecución de trabajo posterior en mi entorno, que se completó en menos de 2 minutos porque no había archivos nuevos para procesar.
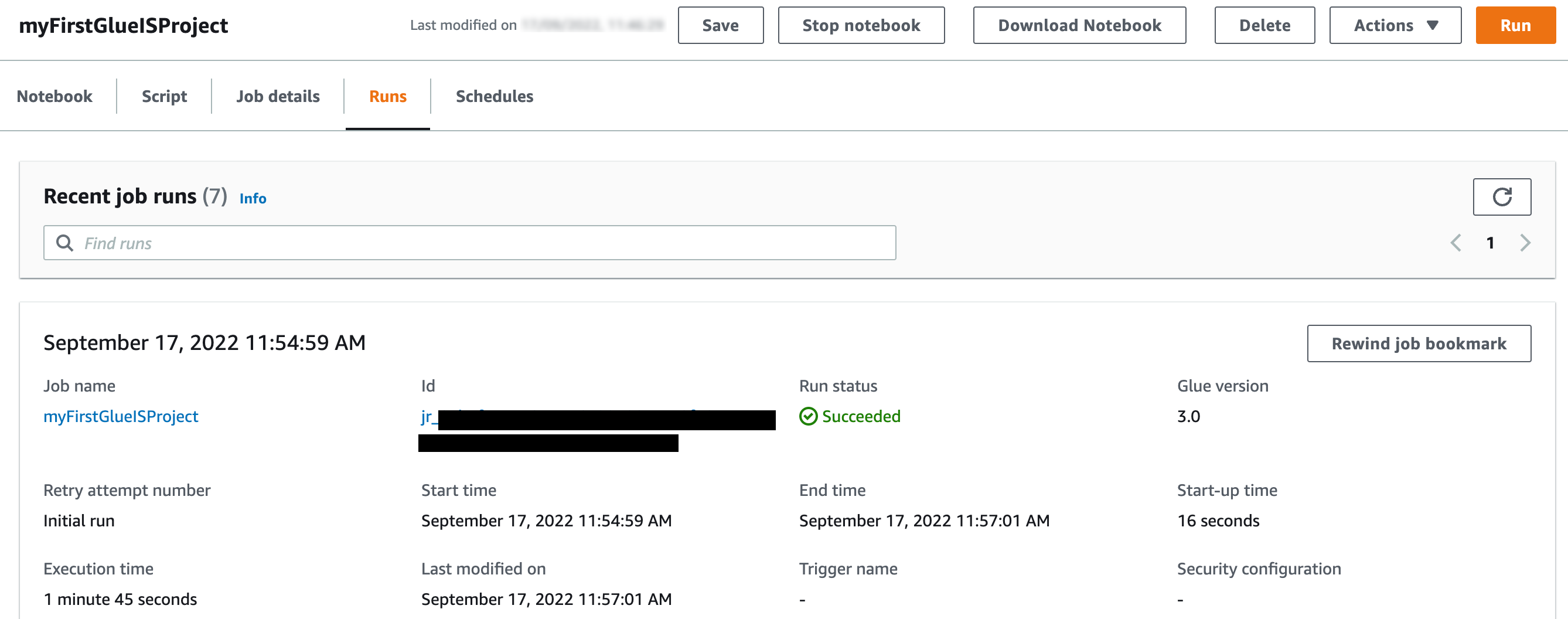
Ahora vamos a programar el trabajo.
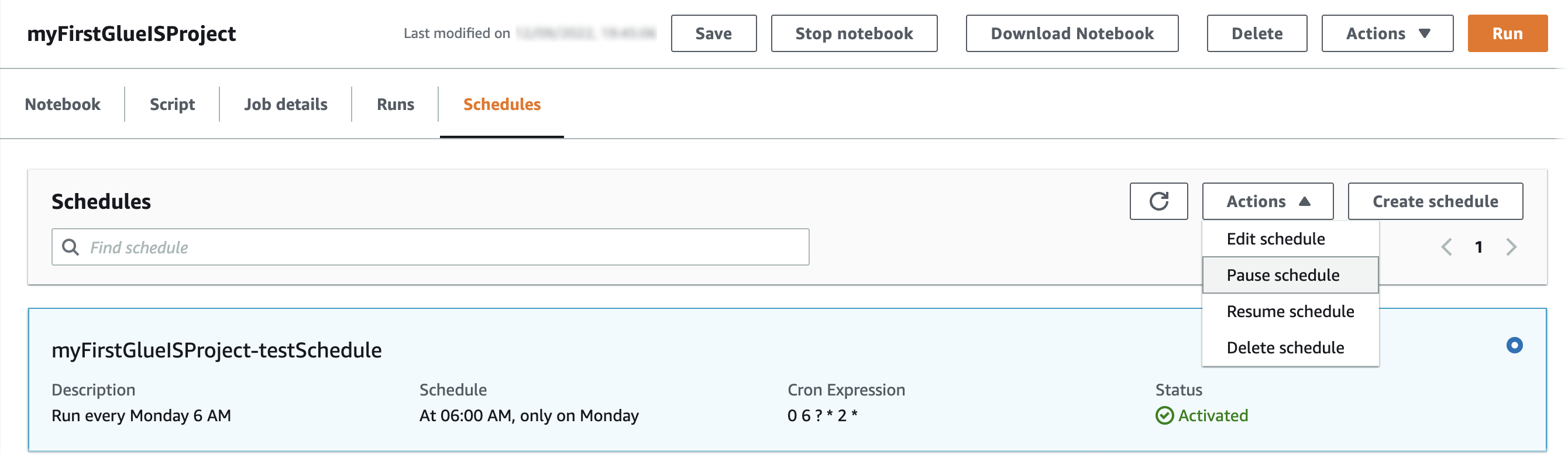
- En Horarios pestaña, elegir Crear horario.

- Nombre¸ ingrese un nombre (por ejemplo,
myFirstGlueISProject-testSchedule). - Frecuencia, escoger Personalizado.
- Ingrese una expresión cron para que el trabajo se ejecute todos los lunes a las 6:00 a. m.
- Agregue una descripción opcional.
- Elige Crear horario.

El horario ha sido guardado y activado. Puede editar, pausar, reanudar o eliminar la programación de la Acciones .
Limpiar
Para evitar incurrir en cargos futuros, elimine los recursos de AWS que creó.
- Elimine el trabajo de AWS Glue (
myFirstGlueISProjectpara esta publicación). - Elimine los objetos y el depósito de Amazon S3 (
my-first-aws-glue-is-project-<random number>para esta publicación). - Elimine las políticas y roles de AWS IAM (
AWSGlueInteractiveSessionPassRolePolicy,AmazonS3Access-MyFirstGlueISProjectyAWSGlueServiceRole-GlueIS). - Elimine las tablas de Amazon Redshift (
f_nyc_yellow_taxi_tripyd_nyc_taxi_zone_lookup). - Elimine la conexión JDBC de AWS Glue (
redshiftServerless). - Elimine también el grupo de seguridad sin servidor de Redshift que hace referencia a sí mismo y el punto final de Amazon S3 (si lo creó mientras seguía los pasos de esta publicación).
Conclusión
En esta publicación, demostramos cómo hacer lo siguiente:
- Configure un cuaderno AWS Glue Jupyter con sesiones interactivas
- Utilice la magia de la libreta, incluida la incorporación y los marcadores de conexión de AWS Glue
- Lea los datos de Amazon S3 y transfórmelos y cárguelos en Amazon Redshift Serverless
- Configure la magia para habilitar los marcadores de trabajo, guarde el cuaderno como un trabajo de AWS Glue y prográmelo usando una expresión cron
El objetivo de esta publicación es brindarle los fundamentos paso a paso para comenzar con las sesiones interactivas y los cuadernos Jupyter de AWS Glue Studio. Puede configurar un cuaderno Jupyter de AWS Glue en minutos, iniciar una sesión interactiva en segundos y mejorar en gran medida la experiencia de desarrollo con los trabajos de AWS Glue. Las sesiones interactivas tienen una facturación mínima de 1 minuto con funciones de control de costos que reducen el costo de desarrollar aplicaciones de preparación de datos. Puede crear y probar aplicaciones desde el entorno de su elección, incluso en su entorno local, utilizando el backend de sesiones interactivas.
Las sesiones interactivas proporcionan una forma más rápida, económica y flexible de crear y ejecutar aplicaciones de análisis y preparación de datos. Para obtener más información sobre las sesiones interactivas, consulte Desarrollo laboral (sesiones interactivas)y comience a explorar una experiencia de desarrollo completamente nueva con AWS Glue. Además, consulte las siguientes publicaciones para ver más ejemplos del uso de sesiones interactivas con diferentes opciones:
Acerca de los autores
 Vikas Ömer es un arquitecto de soluciones especialista en análisis principal en Amazon Web Services. Vikas tiene una sólida experiencia en análisis, gestión de la experiencia del cliente (CEM) y monetización de datos, con más de 13 años de experiencia en la industria a nivel mundial. Con seis certificaciones de AWS, incluida la especialidad de análisis, es un defensor de análisis de confianza para los clientes y socios de AWS. Le encanta viajar, conocer clientes y ayudarlos a tener éxito en lo que hacen.
Vikas Ömer es un arquitecto de soluciones especialista en análisis principal en Amazon Web Services. Vikas tiene una sólida experiencia en análisis, gestión de la experiencia del cliente (CEM) y monetización de datos, con más de 13 años de experiencia en la industria a nivel mundial. Con seis certificaciones de AWS, incluida la especialidad de análisis, es un defensor de análisis de confianza para los clientes y socios de AWS. Le encanta viajar, conocer clientes y ayudarlos a tener éxito en lo que hacen.
 Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Le gusta colaborar con diferentes equipos para obtener resultados como este post. En su tiempo libre, disfruta jugar videojuegos con su familia.
Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Le gusta colaborar con diferentes equipos para obtener resultados como este post. En su tiempo libre, disfruta jugar videojuegos con su familia.
 chica heyne es gerente de productos de AWS Glue y tiene más de 15 años de experiencia como gerente de productos, ingeniero de datos y arquitecto de datos. Le apasiona desarrollar una comprensión profunda de las necesidades comerciales de los clientes y colaborar con ingenieros para diseñar productos de datos elegantes, potentes y fáciles de usar. Gal tiene una maestría en ciencia de datos de UC Berkeley y le gusta viajar, jugar juegos de mesa e ir a conciertos de música.
chica heyne es gerente de productos de AWS Glue y tiene más de 15 años de experiencia como gerente de productos, ingeniero de datos y arquitecto de datos. Le apasiona desarrollar una comprensión profunda de las necesidades comerciales de los clientes y colaborar con ingenieros para diseñar productos de datos elegantes, potentes y fáciles de usar. Gal tiene una maestría en ciencia de datos de UC Berkeley y le gusta viajar, jugar juegos de mesa e ir a conciertos de música.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/get-started-with-data-integration-from-amazon-s3-to-amazon-redshift-using-aws-glue-interactive-sessions/

