Las entrevistas de Data Science varían en su profundidad. Algunas entrevistas son realmente profundas y ponen a prueba a los candidatos sobre su conocimiento de modelos avanzados o ajustes complicados. Pero muchas entrevistas se realizan en un nivel de entrada, tratando de evaluar los conocimientos básicos del candidato. En este artículo veremos una pregunta que se puede discutir en una entrevista de este tipo. Aunque la pregunta es muy simple, la discusión plantea muchos aspectos interesantes de los fundamentos del aprendizaje automático.
Pregunta: ¿Cuál es la diferencia entre la regresión lineal y la regresión logística?
En realidad, hay muchas similitudes entre los dos, comenzando con el hecho de que sus nombres suenan muy similares. Ambos usan líneas como funciones del modelo. Sus gráficos también se ven muy similares.
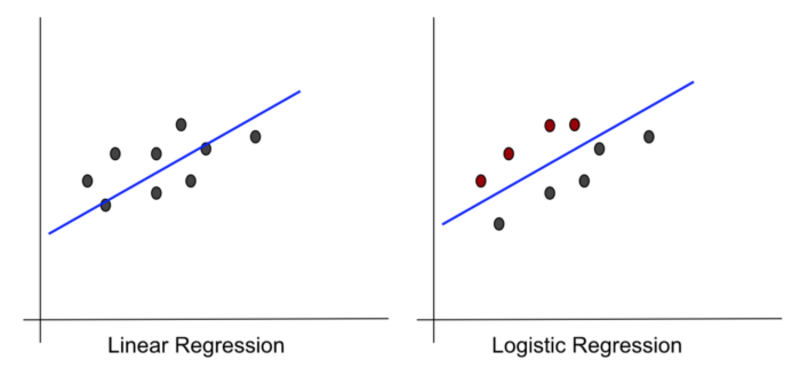
Imagen del autor
Pero a pesar de estas similitudes, son muy diferentes tanto en el método como en la aplicación. Destacaremos estas diferencias ahora. A modo de comparación, utilizaremos los siguientes puntos que generalmente se consideran al analizar cualquier modelo de aprendizaje automático:
- Hipótesis o familia modelo
- De entrada y de salida
- Función de pérdida
- Técnica de optimización
- Aplicación
Ahora compararemos la regresión lineal (LinReg) y la regresión logística (LogReg) en cada uno de estos puntos. Comencemos con la aplicación, para poner la discusión en el camino correcto.

Imagen del autor
La regresión lineal se utiliza para estimar una cantidad en función de otras cantidades. Como ejemplo, imagina que como estudiante tienes un puesto de limonada durante las vacaciones de verano. Quiere saber cuántos vasos de limonada se venderán mañana para poder comprar suficientes limones y azúcar. A partir de tu larga experiencia en la venta de limonada, has descubierto que la venta tiene una fuerte relación con la temperatura máxima del día. Por lo tanto, desea utilizar la temperatura máxima pronosticada para predecir la venta de limonada. Esta es una aplicación clásica de LinReg, generalmente llamada predicción en la literatura de ML.
LinReg también se usa para averiguar cómo una entrada en particular afecta la salida. En el ejemplo del puesto de limonada, suponga que tiene dos entradas: la temperatura máxima y si el día es feriado. Desea saber qué afecta más a la venta: la temperatura máxima o las vacaciones. LinReg será útil para identificar esto.
LogReg se utiliza principalmente para la clasificación. La clasificación es el acto de categorizar la entrada en una de las muchas cestas posibles. La clasificación es tan fundamental para la inteligencia humana que no estaría mal decir que "la mayor parte de la inteligencia es clasificación". Un buen ejemplo de clasificación es el diagnóstico clínico. Piense en el médico de familia anciano y fiable. Una señora entra y se queja de tos incesante. El médico realiza varios exámenes para decidir entre muchas condiciones posibles. Algunas condiciones posibles son relativamente inofensivas, como un ataque de infección de garganta. Pero algunos son graves, como la tuberculosis o incluso el cáncer de pulmón. En función de varios factores, el médico decide qué padece y comienza el tratamiento adecuado. Esta es la clasificación en el trabajo.
Debemos tener en cuenta que tanto la estimación como la clasificación son tareas de adivinanzas más que cálculos. No hay una respuesta exacta o correcta en este tipo de tareas. Las tareas de adivinanzas son para lo que son buenos los sistemas de aprendizaje automático.
Los sistemas de ML resuelven problemas de adivinanzas mediante la detección de patrones. Detectan un patrón a partir de los datos proporcionados y luego lo utilizan para realizar tareas como estimación o clasificación. Un patrón importante que se encuentra en los fenómenos naturales es el patrón de relación. En este patrón, una cantidad está relacionada con la otra cantidad. Esta relación se puede aproximar mediante una función matemática en la mayoría de los casos.
La identificación de una función matemática a partir de los datos dados se llama 'aprendizaje' o 'entrenamiento'. Hay dos pasos de aprendizaje:
- El 'tipo' de función (por ejemplo, lineal, exponencial, polinomial) es elegido por un ser humano
- El algoritmo de aprendizaje aprende los parámetros (como la pendiente y la intersección de una línea) a partir de los datos proporcionados.
Entonces, cuando decimos que los sistemas ML aprenden de los datos, solo es parcialmente cierto. El primer paso para seleccionar el tipo de función es manual y forma parte del diseño del modelo. El tipo de función también se denomina 'hipótesis' o 'familia modelo'.
Tanto en LinReg como en LogReg, la familia de modelos es la función lineal. Como sabes, una línea tiene dos parámetros: pendiente e intersección. Pero esto es cierto solo si la función toma solo una entrada. Para la mayoría de los problemas del mundo real, hay más de una entrada. La función modelo para estos casos se llama función lineal, no recta. Una función lineal tiene más parámetros para aprender. Si hay n entradas al modelo, la función lineal tiene n+1 parámetros. Como se mencionó, estos parámetros se aprenden de los datos proporcionados. A los efectos de este artículo, seguiremos asumiendo que la función es la línea simple con dos parámetros. La función modelo para LogReg es un poco más compleja. La línea está ahí, pero se combina con otra función. Veremos esto en un momento.
Como dijimos anteriormente, tanto LinReg como LogReg aprenden los parámetros de la función lineal a partir de los datos dados, llamados datos de entrenamiento. ¿Qué contienen los datos de entrenamiento?
Los datos de entrenamiento se preparan registrando algunos fenómenos del mundo real (RWP). Por ejemplo, la relación entre la temperatura máxima diurna y la venta de limonada es un RWP. No tenemos visibilidad de la relación subyacente. Todo lo que podemos ver son los valores de la temperatura y la venta todos los días. Mientras registramos las observaciones, designamos algunas cantidades como entradas del RWP y otras como salidas. En el ejemplo de la limonada, llamamos entrada a la temperatura máxima y salida a la venta de limonada.

Imagen del autor
Nuestros datos de entrenamiento contienen pares de entradas y salidas. En este ejemplo, los datos tendrán filas de temperatura máxima diaria y vasos de limonada vendidos. Tal será la entrada y salida a LinReg.
La tarea que realiza LogReg es la clasificación, por lo que su salida debe ser una clase. Imaginemos que hay dos clases llamadas 0 y 1. La salida del modelo también debería ser 0 o 1.
Sin embargo, este método de especificar la salida no es muy adecuado. Vea el siguiente diagrama:
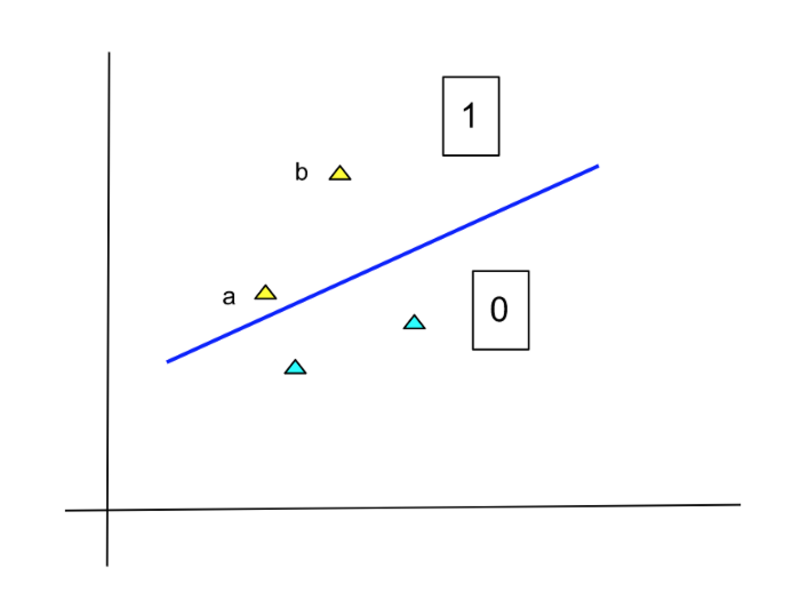
Imagen del autor
Los puntos en amarillo pertenecen a la clase 1 y los de color azul claro pertenecen a la 0. La línea es nuestra función modelo que separa las dos clases. Según este separador, los dos puntos amarillos (a y b) pertenecen a la Clase 1. Sin embargo, la pertenencia del punto b es mucho más segura que la del punto a. Si el modelo simplemente genera 0 y 1, entonces este hecho se pierde.
Para corregir esta situación, el modelo LogReg produce la probabilidad de que cada punto pertenezca a una determinada clase. En el ejemplo anterior, la probabilidad de que el punto 'a' pertenezca a la Clase 1 es baja, mientras que la del punto 'b' es alta. Dado que la probabilidad es un número entre 0 y 1, también lo es la salida de LogReg.
Ahora vea el siguiente diagrama:
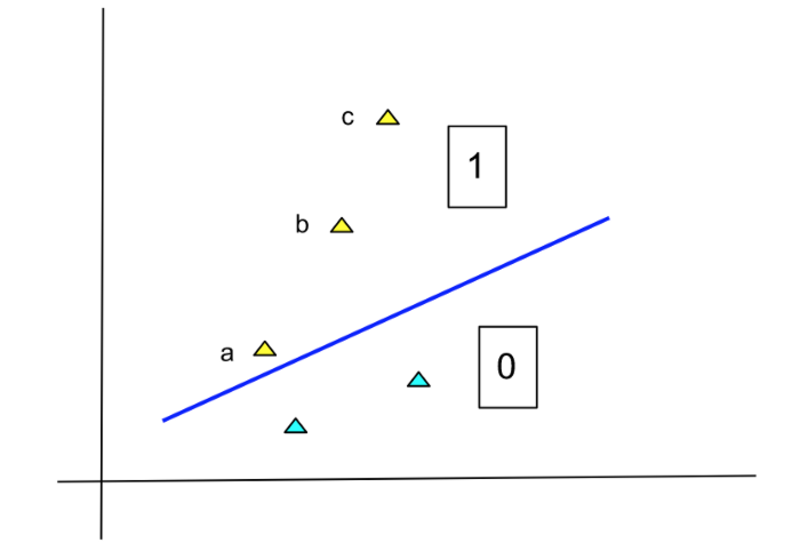
Imagen del autor
Este diagrama es el mismo que el anterior, con el punto c añadido. Este punto también pertenece a la Clase 1 y de hecho es más seguro que el punto b. Sin embargo, sería un error aumentar la probabilidad de un punto en proporción a su distancia a la línea. Intuitivamente, una vez que te alejas una cierta distancia de la línea, estamos más o menos seguros acerca de la pertenencia de esos puntos. No necesitamos aumentar más la probabilidad. Esto está en línea con la naturaleza de las probabilidades, cuyo valor máximo puede ser 1.
Para que el modelo LogReg pueda producir tal salida, la función de línea debe estar conectada a otra función. Esta segunda función se llama sigmoide y tiene la ecuación:
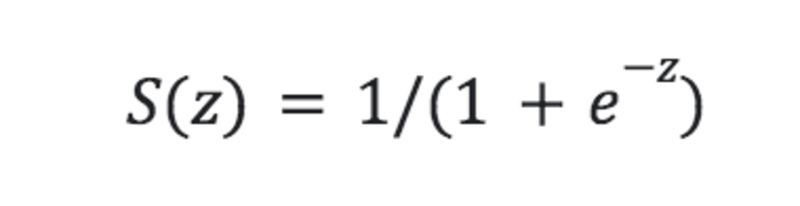
Imagen del autor
Por lo tanto, el modelo LogReg se parece a:
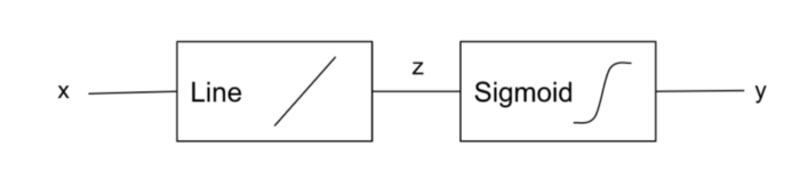
Imagen del autor
La función sigmoidea también se llama 'logística' y es la razón del nombre 'Regresión logística'.
Si hay más de dos clases, la salida de LogReg es un vector. Los elementos del vector de salida son probabilidades de que la entrada sea de esa clase en particular. Por ejemplo, si el primer elemento del modelo de diagnóstico clínico tiene el valor 0.8, significa que el modelo piensa que hay un 80% de probabilidad de que el paciente padezca catarro.
Vimos que tanto LinReg como LogReg aprenden los parámetros de la función lineal a partir de los datos de entrenamiento. ¿Cómo aprenden estos parámetros?
Usan un método llamado 'optimización'. La optimización funciona generando muchas soluciones posibles para el problema dado. En nuestro caso, las posibles soluciones son los conjuntos de valores (pendiente, intersección). Evaluamos cada una de estas soluciones utilizando una medida de rendimiento. Finalmente se selecciona la solución que demuestra ser la mejor en esta medida.
En el aprendizaje de modelos ML, la medida de rendimiento a veces se denomina 'pérdida' y la función que nos ayuda a calcularla se denomina 'función de pérdida'. Esto lo podemos representar como:
Loss = Loss_Function (Parameters_being_evaluated)Los términos 'pérdida' y 'función de pérdida' tienen una connotación negativa, lo que significa que un menor valor de pérdida indica una mejor solución. En otras palabras, el aprendizaje es una optimización que tiene como objetivo encontrar parámetros que produzcan la mínima pérdida.
Ahora veremos las funciones de pérdida comunes utilizadas para optimizar LinReg y LogReg. Tenga en cuenta que en la práctica se utilizan muchas funciones de pérdida diferentes, por lo que podemos analizar las más comunes.
Para la optimización de los parámetros de LinReg, la función de pérdida más común se denomina error de suma de cuadrados (SSE). Esta función toma las siguientes entradas:
1) Todos los puntos de datos de entrenamiento. Para cada punto, especificamos:
a) las entradas, como la temperatura máxima de datos,
b) las salidas, como el número de vasos de limonada vendidos
2) La ecuación lineal con parámetros
La función luego calcula la pérdida usando la siguiente fórmula:
SSE Loss = Sum_for_all_points(
Square_of(
output_of_linear_equation_for_the_inputs — actual_output_from_the_data point
))La medida de optimización para LogReg se define de una manera muy diferente. En la función SSE, hacemos la siguiente pregunta:
If we use this line for fitting the training data, how much error will it make?Al diseñar la medida para la optimización de LogReg, preguntamos:
If this line is the separator, how likely is it that we will get the distribution of classes that is seen in the training data?El resultado de esta medida es, por tanto, una probabilidad. La forma matemática de la función de medida utiliza logaritmos, por lo que recibe el nombre de Log Likelihood (LL). Mientras discutíamos los resultados, vimos que la función LogReg involucra términos exponenciales (los términos con e 'elevado' a z) Los logaritmos ayudan a manejar estos exponenciales de manera efectiva.
Debe ser intuitivamente claro para usted que la optimización debe maximizar LL. Piense así: queremos encontrar la línea que hace que los datos de entrenamiento sean más probables. En la práctica, sin embargo, preferimos una medida que pueda minimizarse, por lo que simplemente tomamos el negativo de LL. Obtenemos así la función de pérdida Negative Log Likelihood (NLL), aunque, según yo, llamarla función de pérdida no es muy correcto.
Entonces tenemos las dos funciones de pérdida: SSE para LinReg y NLL para LogReg. Tenga en cuenta que estas funciones de pérdida tienen muchos nombres y debe familiarizarse con los términos.
Aunque la regresión lineal y la regresión logística se ven y suenan muy similares, en realidad son bastante diferentes. LinReg se usa para estimación/predicción y LogReg es para clasificación. Es cierto que ambos usan la función lineal como base, pero LogReg agrega además la función logística. Difieren en la forma en que consumen sus datos de entrenamiento y producen los resultados de su modelo. Los dos también usan una función de pérdida muy diferente.
Se pueden sondear más detalles. ¿Por qué ESS? ¿Cómo se calcula la probabilidad? No entramos en el método de optimización aquí para evitar más matemáticas. Sin embargo, debe tener en cuenta que la optimización de LogReg generalmente requiere el método de descenso de gradiente iterativo, mientras que LinReg generalmente puede funcionar con una solución rápida de forma cerrada. Podemos discutir estos y más puntos en otro artículo.
Devesh Rajadhyax han estado trabajando en el campo de la Inteligencia Artificial desde los últimos ocho años. Cere Labs es la empresa que fundó para trabajar en varios aspectos de la IA. Cere Labs ha creado una plataforma de IA llamada Cerescope basada en Deep Learning, Machine Learning y Cognitive Computing. La plataforma se ha utilizado para crear soluciones para servicios financieros, atención médica, comercio minorista, fabricación, etc.
Original. Publicado de nuevo con permiso.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2022/11/comparing-linear-logistic-regression.html?utm_source=rss&utm_medium=rss&utm_campaign=comparing-linear-and-logistic-regression

