Al implementar un modelo de lenguaje grande (LLM), los profesionales del aprendizaje automático (ML) generalmente se preocupan por dos medidas para el rendimiento del servicio de modelos: la latencia, definida por el tiempo que lleva generar un único token, y el rendimiento, definido por la cantidad de tokens generados. por segundo. Aunque una sola solicitud al punto final implementado exhibiría un rendimiento aproximadamente igual a la inversa de la latencia del modelo, este no es necesariamente el caso cuando se envían simultáneamente varias solicitudes simultáneas al punto final. Debido a las técnicas de servicio de modelos, como el procesamiento por lotes continuo de solicitudes simultáneas del lado del cliente, la latencia y el rendimiento tienen una relación compleja que varía significativamente según la arquitectura del modelo, las configuraciones de servicio, el tipo de hardware de instancia, el número de solicitudes simultáneas y las variaciones en las cargas útiles de entrada, como como número de tokens de entrada y tokens de salida.
Esta publicación explora estas relaciones a través de una evaluación comparativa integral de los LLM disponibles en Amazon SageMaker JumpStart, incluidas las variantes Llama 2, Falcon y Mistral. Con SageMaker JumpStart, los profesionales de ML pueden elegir entre una amplia selección de modelos básicos disponibles públicamente para implementar en sitios dedicados. Amazon SageMaker instancias dentro de un entorno de red aislado. Proporcionamos principios teóricos sobre cómo las especificaciones del acelerador impactan la evaluación comparativa de LLM. También demostramos el impacto de implementar múltiples instancias detrás de un único punto final. Finalmente, brindamos recomendaciones prácticas para adaptar el proceso de implementación de SageMaker JumpStart para alinearlo con sus requisitos de latencia, rendimiento, costo y restricciones en los tipos de instancias disponibles. Todos los resultados de la evaluación comparativa, así como las recomendaciones, se basan en un versátil cuaderno que puedes adaptar a tu caso de uso.
Evaluación comparativa de terminales implementada
La siguiente figura muestra las latencias más bajas (izquierda) y los valores de rendimiento más altos (derecha) para configuraciones de implementación en una variedad de tipos de modelos y tipos de instancias. Es importante destacar que cada una de estas implementaciones de modelos utiliza configuraciones predeterminadas proporcionadas por SageMaker JumpStart según el ID del modelo deseado y el tipo de instancia para la implementación.
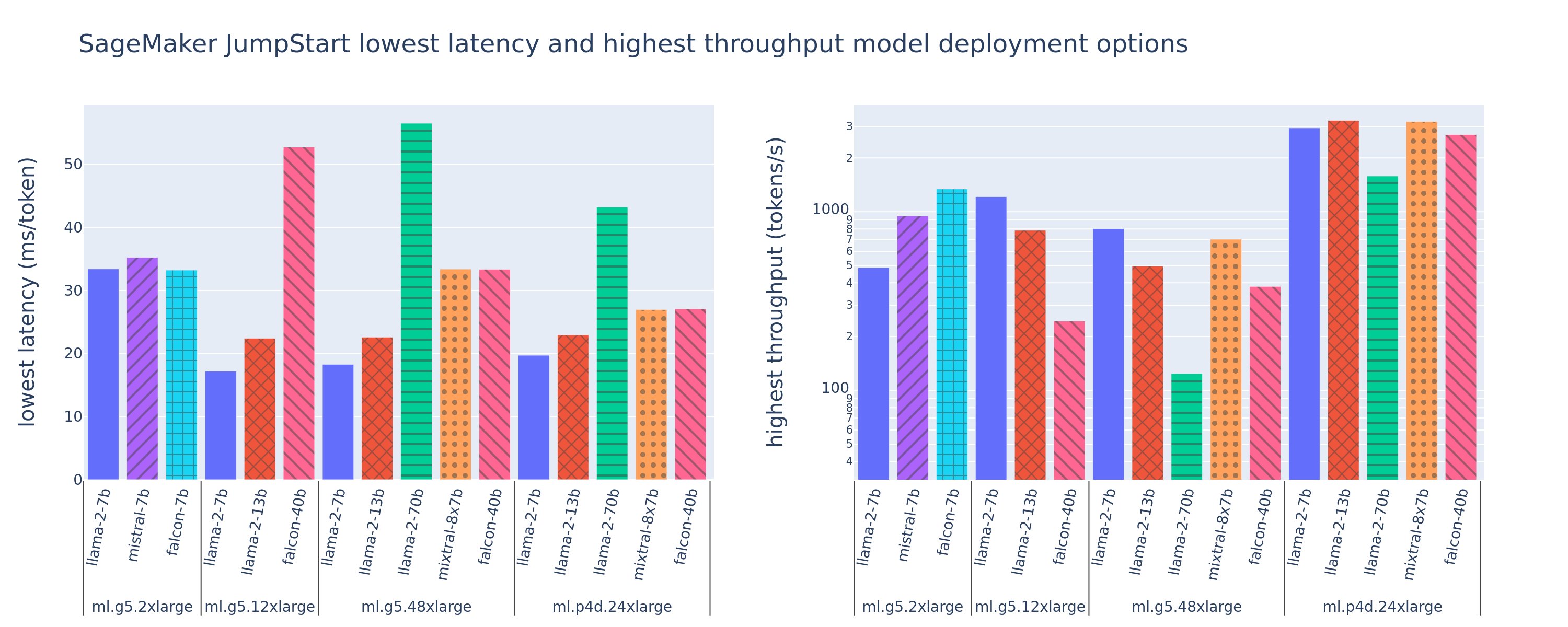
Estos valores de latencia y rendimiento corresponden a cargas útiles con 256 tokens de entrada y 256 tokens de salida. La configuración de latencia más baja limita el modelo que atiende a una única solicitud simultánea, y la configuración de mayor rendimiento maximiza el número posible de solicitudes simultáneas. Como podemos ver en nuestra evaluación comparativa, el aumento de las solicitudes simultáneas aumenta monótonamente el rendimiento con una mejora decreciente para las solicitudes simultáneas grandes. Además, los modelos están completamente fragmentados en la instancia compatible. Por ejemplo, debido a que la instancia ml.g5.48xlarge tiene 8 GPU, todos los modelos SageMaker JumpStart que usan esta instancia están fragmentados mediante paralelismo tensorial en los ocho aceleradores disponibles.
Podemos observar algunas conclusiones de esta figura. En primer lugar, no todos los modelos son compatibles con todas las instancias; Algunos modelos más pequeños, como el Falcon 7B, no admiten la fragmentación de modelos, mientras que los modelos más grandes tienen mayores requisitos de recursos informáticos. En segundo lugar, a medida que aumenta la fragmentación, el rendimiento normalmente mejora, pero no necesariamente puede mejorar en modelos pequeños.. Esto se debe a que los modelos pequeños como el 7B y el 13B incurren en una sobrecarga de comunicación sustancial cuando se dividen en demasiados aceleradores. Hablaremos de esto con más profundidad más adelante. Finalmente, las instancias ml.p4d.24xlarge tienden a tener un rendimiento significativamente mejor debido a las mejoras en el ancho de banda de la memoria de las GPU A100 respecto a las A10G. Como veremos más adelante, la decisión de utilizar un tipo de instancia particular depende de sus requisitos de implementación, incluida la latencia, el rendimiento y las restricciones de costos.
¿Cómo se pueden obtener estos valores de configuración de latencia más baja y rendimiento más alto? Comencemos trazando la latencia frente al rendimiento para un punto final Llama 2 7B en una instancia ml.g5.12xlarge para una carga útil con 256 tokens de entrada y 256 tokens de salida, como se ve en la siguiente curva. Existe una curva similar para cada punto final de LLM implementado.

A medida que aumenta la concurrencia, el rendimiento y la latencia también aumentan monótonamente. Por lo tanto, el punto de latencia más bajo se produce con un valor de solicitud simultánea de 1 y puede aumentar de manera rentable el rendimiento del sistema aumentando las solicitudes simultáneas. Existe una clara "rodilla" en esta curva, donde es obvio que las ganancias de rendimiento asociadas con la simultaneidad adicional no superan el aumento asociado en la latencia. La ubicación exacta de esta rodilla depende del caso de uso; Algunos profesionales pueden definir la rodilla en el punto donde se excede un requisito de latencia preespecificado (por ejemplo, 100 ms/token), mientras que otros pueden usar puntos de referencia de pruebas de carga y métodos de teoría de colas como la regla de media latencia, y otros pueden usar Especificaciones teóricas del acelerador.
También observamos que el número máximo de solicitudes simultáneas es limitado. En la figura anterior, el seguimiento de línea termina con 192 solicitudes simultáneas. La fuente de esta limitación es el límite de tiempo de espera de invocación de SageMaker, donde los puntos finales de SageMaker agotan el tiempo de espera de una respuesta de invocación después de 60 segundos. Esta configuración es específica de la cuenta y no se puede configurar para un punto final individual. Para los LLM, generar una gran cantidad de tokens de salida puede llevar segundos o incluso minutos. Por lo tanto, las cargas útiles de entrada o salida grandes pueden provocar que las solicitudes de invocación fallen. Además, si el número de solicitudes simultáneas es muy grande, muchas solicitudes experimentarán largos tiempos de cola, lo que impulsará este límite de tiempo de espera de 60 segundos. Para los fines de este estudio, utilizamos el límite de tiempo de espera para definir el rendimiento máximo posible para la implementación de un modelo. Es importante destacar que, aunque un punto final de SageMaker puede manejar una gran cantidad de solicitudes simultáneas sin observar un tiempo de espera de respuesta de invocación, es posible que desee definir el máximo de solicitudes simultáneas con respecto al codo en la curva de latencia-rendimiento. Este es probablemente el punto en el que comienza a considerar el escalamiento horizontal, donde un único punto final aprovisiona múltiples instancias con réplicas de modelos y equilibra la carga de las solicitudes entrantes entre las réplicas, para admitir más solicitudes simultáneas.
Llevando esto un paso más allá, la siguiente tabla contiene resultados de evaluación comparativa para diferentes configuraciones para el modelo Llama 2 7B, incluida una cantidad diferente de tokens de entrada y salida, tipos de instancias y cantidad de solicitudes simultáneas. Tenga en cuenta que la figura anterior solo representa una fila de esta tabla.
| . | Rendimiento (tokens/seg) | Latencia (ms/token) | ||||||||||||||||||
| Solicitudes concurrentes | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Número de tokens totales: 512, Número de tokens de salida: 256 | ||||||||||||||||||||
| ml.g5.2xgrande | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xgrande | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xgrande | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xgrande | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Número de tokens totales: 4096, Número de tokens de salida: 256 | ||||||||||||||||||||
| ml.g5.2xgrande | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xgrande | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xgrande | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xgrande | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Observamos algunos patrones adicionales en estos datos. Al aumentar el tamaño del contexto, la latencia aumenta y el rendimiento disminuye. Por ejemplo, en ml.g5.2xlarge con una simultaneidad de 1, el rendimiento es de 30 tokens/s cuando el número total de tokens es 512, frente a 20 tokens/s si el número total de tokens es 4,096. Esto se debe a que lleva más tiempo procesar la entrada más grande. También podemos ver que el aumento de la capacidad de la GPU y la fragmentación afectan el rendimiento máximo y las solicitudes simultáneas máximas admitidas. La tabla muestra que Llama 2 7B tiene valores de rendimiento máximo notablemente diferentes para diferentes tipos de instancias, y estos valores de rendimiento máximo ocurren en diferentes valores de solicitudes simultáneas. Estas características llevarían a un practicante de ML a justificar el costo de una instancia sobre otra. Por ejemplo, dado un requisito de latencia baja, el profesional podría seleccionar una instancia ml.g5.12xlarge (4 GPU A10G) en lugar de una instancia ml.g5.2xlarge (1 GPU A10G). Si se presenta un requisito de alto rendimiento, el uso de una instancia ml.p4d.24xlarge (8 GPU A100) con fragmentación completa solo se justificaría en condiciones de alta concurrencia. Sin embargo, tenga en cuenta que a menudo resulta beneficioso cargar varios componentes de inferencia de un modelo 7B en una única instancia ml.p4d.24xlarge; Este soporte multimodelo se analiza más adelante en esta publicación.
Las observaciones anteriores se realizaron para el modelo Llama 2 7B. Sin embargo, patrones similares siguen siendo válidos para otros modelos. Una conclusión principal es que las cifras de latencia y rendimiento dependen de la carga útil, el tipo de instancia y la cantidad de solicitudes simultáneas, por lo que deberá encontrar la configuración ideal para su aplicación específica. Para generar los números anteriores para su caso de uso, puede ejecutar el enlace cuaderno, donde puede configurar este análisis de prueba de carga para su modelo, tipo de instancia y carga útil.
Dar sentido a las especificaciones del acelerador
La selección del hardware adecuado para la inferencia de LLM depende en gran medida de casos de uso específicos, objetivos de experiencia del usuario y el LLM elegido. Esta sección intenta crear una comprensión del punto de inflexión en la curva de latencia-rendimiento con respecto a principios de alto nivel basados en especificaciones de aceleradores. Estos principios por sí solos no bastan para tomar una decisión: son necesarios verdaderos puntos de referencia. El término dispositivo se utiliza aquí para abarcar todos los aceleradores de hardware de ML. Afirmamos que el punto de inflexión en la curva de latencia-rendimiento está impulsado por uno de dos factores:
- El acelerador ha agotado la memoria para almacenar en caché las matrices KV, por lo que las solicitudes posteriores se ponen en cola
- El acelerador todavía tiene memoria adicional para la caché KV, pero utiliza un tamaño de lote lo suficientemente grande como para que el tiempo de procesamiento dependa de la latencia de la operación informática en lugar del ancho de banda de la memoria.
Normalmente preferimos estar limitados por el segundo factor porque esto implica que los recursos del acelerador están saturados. Básicamente, estás maximizando los recursos por los que pagaste. Exploremos esta afirmación con mayor detalle.
Almacenamiento en caché KV y memoria del dispositivo
Los mecanismos de atención del transformador estándar calculan la atención para cada nuevo token en comparación con todos los tokens anteriores. La mayoría de los servidores de ML modernos almacenan en caché las claves y los valores de atención en la memoria del dispositivo (DRAM) para evitar volver a calcularlos en cada paso. Esto se llama esto el caché KVy crece con el tamaño del lote y la longitud de la secuencia. Define cuántas solicitudes de usuario se pueden atender en paralelo y determinará el límite en la curva de latencia-rendimiento si el régimen vinculado a la computación en el segundo escenario mencionado anteriormente aún no se cumple, dada la DRAM disponible. La siguiente fórmula es una aproximación aproximada del tamaño máximo de caché de KV.

En esta fórmula, B es el tamaño del lote y N es el número de aceleradores. Por ejemplo, el modelo Llama 2 7B en FP16 (2 bytes/parámetro) servido en una GPU A10G (24 GB DRAM) consume aproximadamente 14 GB, dejando 10 GB para la caché KV. Al conectar la longitud completa del contexto del modelo (N = 4096) y los parámetros restantes (n_layers=32, n_kv_attention_heads=32 y d_attention_head=128), esta expresión muestra que estamos limitados a atender un tamaño de lote de cuatro usuarios en paralelo debido a restricciones de DRAM. . Si observa los puntos de referencia correspondientes en la tabla anterior, esta es una buena aproximación para la rodilla observada en esta curva de latencia-rendimiento. Métodos como atención de consultas agrupadas (GQA) puede reducir el tamaño de la caché de KV; en el caso de GQA, por el mismo factor reduce el número de cabezas de KV.
Intensidad aritmética y ancho de banda de memoria del dispositivo.
El crecimiento en el poder computacional de los aceleradores de ML ha superado el ancho de banda de su memoria, lo que significa que pueden realizar muchos más cálculos en cada byte de datos en el tiempo que lleva acceder a ese byte.
La intensidad aritmética, o la proporción de operaciones informáticas y accesos a la memoria, para una operación determina si está limitada por el ancho de banda de la memoria o la capacidad informática del hardware seleccionado. Por ejemplo, una GPU A10G (familia de tipo de instancia g5) con 70 TFLOPS FP16 y 600 GB/s de ancho de banda puede calcular aproximadamente 116 operaciones/byte. Una GPU A100 (familia de tipo de instancia p4d) puede calcular aproximadamente 208 operaciones/byte. Si la intensidad aritmética de un modelo de transformador está por debajo de ese valor, está ligado a la memoria; si está por encima, está vinculado a la computación. El mecanismo de atención para Llama 2 7B requiere 62 operaciones/byte para el tamaño de lote 1 (para obtener una explicación, consulte Una guía para la inferencia y el desempeño de LLM), lo que significa que está ligado a la memoria. Cuando el mecanismo de atención está vinculado a la memoria, los costosos FLOPS quedan sin utilizar.
Hay dos maneras de utilizar mejor el acelerador y aumentar la intensidad aritmética: reducir los accesos a la memoria necesarios para la operación (esto es lo que FlashAtención se centra) o aumentar el tamaño del lote. Sin embargo, es posible que no podamos aumentar el tamaño de nuestro lote lo suficiente como para alcanzar un régimen vinculado a la computación si nuestra DRAM es demasiado pequeña para contener la caché KV correspondiente. La siguiente expresión describe una aproximación burda del tamaño de lote crítico B* que separa los regímenes vinculados a la computación de los vinculados a la memoria para la inferencia del decodificador GPT estándar, donde A_mb es el ancho de banda de la memoria del acelerador, A_f son los FLOPS del acelerador y N es el número de aceleradores. Este tamaño de lote crítico se puede derivar encontrando dónde el tiempo de acceso a la memoria es igual al tiempo de cálculo. Referirse a esta entrada del blog comprender la Ecuación 2 y sus supuestos con mayor detalle.
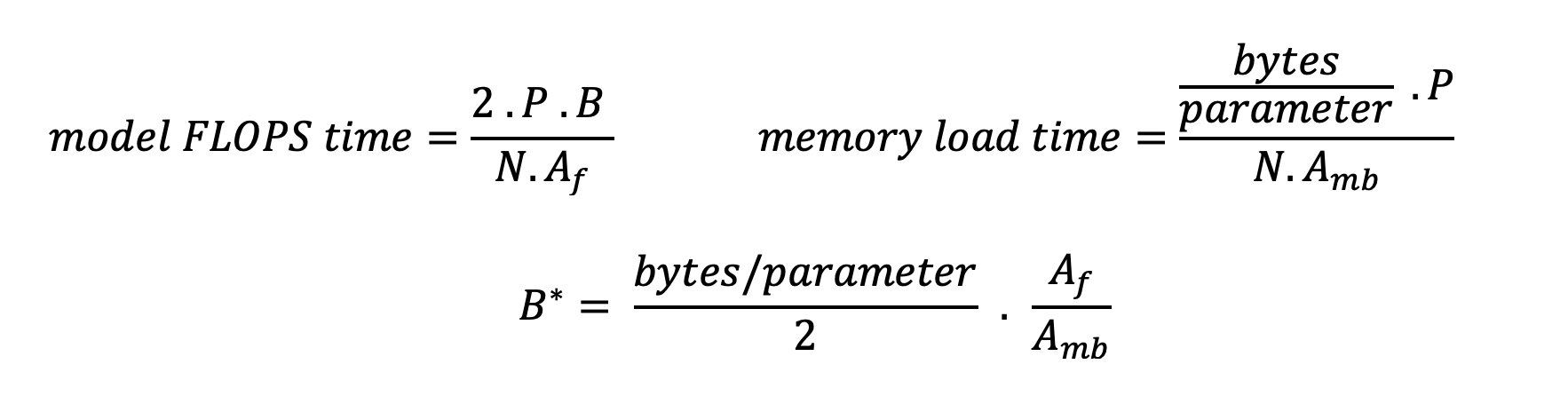
Esta es la misma relación de operaciones/bytes que calculamos anteriormente para A10G, por lo que el tamaño de lote crítico en esta GPU es 116. Una forma de abordar este tamaño de lote crítico teórico es aumentar la fragmentación del modelo y dividir el caché entre más N aceleradores. Esto aumenta efectivamente la capacidad de la caché KV, así como el tamaño del lote vinculado a la memoria.
Otro beneficio de la fragmentación de modelos es dividir el trabajo de carga de datos y parámetros del modelo entre N aceleradores. Este tipo de fragmentación es un tipo de paralelismo de modelo también conocido como paralelismo tensorial. Ingenuamente, hay N veces el ancho de banda de la memoria y la potencia de cálculo en conjunto. Suponiendo que no haya gastos generales de ningún tipo (comunicación, software, etc.), esto disminuiría la latencia de decodificación por token en N si estamos limitados a la memoria, porque la latencia de decodificación de tokens en este régimen está limitada por el tiempo que lleva cargar el modelo. pesos y caché. Sin embargo, en la vida real, aumentar el grado de fragmentación da como resultado una mayor comunicación entre dispositivos para compartir activaciones intermedias en cada capa del modelo. Esta velocidad de comunicación está limitada por el ancho de banda de interconexión del dispositivo. Es difícil estimar su impacto con precisión (para más detalles, consulte Paralelismo modelo), pero esto eventualmente puede dejar de generar beneficios o deteriorar el rendimiento; esto es especialmente cierto para los modelos más pequeños, porque las transferencias de datos más pequeñas conducen a tasas de transferencia más bajas.
Para comparar aceleradores de ML según sus especificaciones, recomendamos lo siguiente. Primero, calcule el tamaño de lote crítico aproximado para cada tipo de acelerador según la segunda ecuación y el tamaño de caché KV para el tamaño de lote crítico según la primera ecuación. Luego puede usar la DRAM disponible en el acelerador para calcular la cantidad mínima de aceleradores necesarios para ajustarse a la caché KV y a los parámetros del modelo. Si decide entre varios aceleradores, priorice los aceleradores en orden de menor costo por GB/s de ancho de banda de memoria. Finalmente, compare estas configuraciones y verifique cuál es el mejor costo/token para su límite superior de latencia deseada.
Seleccione una configuración de implementación de endpoints
Muchos LLM distribuidos por SageMaker JumpStart utilizan el inferencia-de-generación-de-texto (TGI) Contenedor SageMaker para servir modelos. La siguiente tabla analiza cómo ajustar una variedad de parámetros de servicio de modelos para afectar el servicio de modelos, lo que afecta la curva de latencia-rendimiento, o proteger el punto final contra solicitudes que sobrecargarían el punto final. Estos son los parámetros principales que puede utilizar para configurar la implementación de su punto final para su caso de uso. A menos que se especifique lo contrario, utilizamos default parámetros de carga útil de generación de texto y Variables de entorno TGI.
| Variable ambiental | Descripción | Valor predeterminado de SageMaker JumpStart |
| Configuraciones de publicación de modelos | . | . |
MAX_BATCH_PREFILL_TOKENS |
Limita la cantidad de tokens en la operación de precarga. Esta operación genera la caché KV para una nueva secuencia de solicitud de entrada. Requiere mucha memoria y está vinculado a la computación, por lo que este valor limita la cantidad de tokens permitidos en una única operación de precarga. Los pasos de decodificación para otras consultas se pausan mientras se realiza el precompletado. | 4096 (valor predeterminado de TGI) o longitud de contexto máxima admitida específica del modelo (se proporciona SageMaker JumpStart), lo que sea mayor. |
MAX_BATCH_TOTAL_TOKENS |
Controla la cantidad máxima de tokens que se incluirán dentro de un lote durante la decodificación o un único paso hacia adelante a través del modelo. Idealmente, esto está configurado para maximizar el uso de todo el hardware disponible. | No especificado (predeterminado TGI). TGI establecerá este valor con respecto a la memoria CUDA restante durante el calentamiento del modelo. |
SM_NUM_GPUS |
La cantidad de fragmentos que se usarán. Es decir, la cantidad de GPU utilizadas para ejecutar el modelo utilizando paralelismo tensorial. | Dependiente de la instancia (se proporciona SageMaker JumpStart). Para cada instancia admitida para un modelo determinado, SageMaker JumpStart proporciona la mejor configuración para el paralelismo tensorial. |
| Configuraciones para proteger su punto final (configúrelas para su caso de uso) | . | . |
MAX_TOTAL_TOKENS |
Esto limita el presupuesto de memoria de una única solicitud de cliente al limitar el número de tokens en la secuencia de entrada más el número de tokens en la secuencia de salida (el max_new_tokens parámetro de carga útil). |
Longitud de contexto máxima admitida específica del modelo. Por ejemplo, 4096 para Llama 2. |
MAX_INPUT_LENGTH |
Identifica el número máximo permitido de tokens en la secuencia de entrada para una única solicitud de cliente. Los aspectos a considerar al aumentar este valor incluyen: las secuencias de entrada más largas requieren más memoria, lo que afecta el procesamiento por lotes continuo, y muchos modelos tienen una longitud de contexto admitida que no debe excederse. | Longitud de contexto máxima admitida específica del modelo. Por ejemplo, 4095 para Llama 2. |
MAX_CONCURRENT_REQUESTS |
El número máximo de solicitudes simultáneas permitidas por el punto final implementado. Las nuevas solicitudes que superen este límite generarán inmediatamente un error de modelo sobrecargado para evitar una latencia deficiente para las solicitudes de procesamiento actuales. | 128 (valor predeterminado de TGI). Esta configuración le permite obtener un alto rendimiento para una variedad de casos de uso, pero debe fijar según corresponda para mitigar los errores de tiempo de espera de invocación de SageMaker. |
El servidor TGI utiliza procesamiento por lotes continuo, que agrupa dinámicamente solicitudes simultáneas para compartir un único paso hacia adelante de inferencia del modelo. Hay dos tipos de pases directos: precarga y decodificación. Cada nueva solicitud debe ejecutar un único pase de avance previo para llenar la caché KV para los tokens de secuencia de entrada. Una vez que se completa la caché de KV, un paso directo de decodificación realiza una única predicción del siguiente token para todas las solicitudes por lotes, que se repite de forma iterativa para producir la secuencia de salida. A medida que se envían nuevas solicitudes al servidor, el siguiente paso de decodificación debe esperar para que se pueda ejecutar el paso de precarga para las nuevas solicitudes. Esto debe ocurrir antes de que esas nuevas solicitudes se incluyan en pasos posteriores de decodificación por lotes continuos. Debido a limitaciones de hardware, es posible que el procesamiento por lotes continuo utilizado para la decodificación no incluya todas las solicitudes. En este punto, las solicitudes ingresan a una cola de procesamiento y la latencia de inferencia comienza a aumentar significativamente con solo una ganancia de rendimiento menor.
Es posible separar los análisis comparativos de latencia de LLM en latencia de precarga, latencia de decodificación y latencia de cola. El tiempo consumido por cada uno de estos componentes es de naturaleza fundamentalmente diferente: el prellenado es un cálculo único, la decodificación ocurre una vez para cada token en la secuencia de salida y la puesta en cola implica procesos por lotes del servidor. Cuando se procesan varias solicitudes simultáneas, resulta difícil separar las latencias de cada uno de estos componentes porque la latencia experimentada por cualquier solicitud de cliente determinada implica latencias de cola impulsadas por la necesidad de completar previamente nuevas solicitudes simultáneas, así como latencias de cola impulsadas por la inclusión. de la solicitud en procesos de decodificación por lotes. Por este motivo, esta publicación se centra en la latencia del procesamiento de un extremo a otro. El punto de inflexión en la curva de latencia-rendimiento se produce en el punto de saturación donde las latencias de la cola comienzan a aumentar significativamente. Este fenómeno ocurre para cualquier servidor de inferencia de modelos y está impulsado por las especificaciones del acelerador.
Los requisitos comunes durante la implementación incluyen satisfacer un rendimiento mínimo requerido, una latencia máxima permitida, un costo máximo por hora y un costo máximo para generar 1 millón de tokens. Debe condicionar estos requisitos a las cargas útiles que representan solicitudes de los usuarios finales. Un diseño que cumpla con estos requisitos debe considerar muchos factores, incluida la arquitectura del modelo específico, el tamaño del modelo, los tipos de instancias y el recuento de instancias (escalado horizontal). En las siguientes secciones, nos centramos en implementar puntos finales para minimizar la latencia, maximizar el rendimiento y minimizar los costos. Este análisis considera 512 tokens en total y 256 tokens de salida.
Minimizar la latencia
La latencia es un requisito importante en muchos casos de uso en tiempo real. En la siguiente tabla, analizamos la latencia mínima para cada modelo y cada tipo de instancia. Puede lograr una latencia mínima configurando MAX_CONCURRENT_REQUESTS = 1.
| Latencia mínima (ms/token) | |||||
| Modelo ID | ml.g5.2xgrande | ml.g5.12xgrande | ml.g5.48xgrande | ml.p4d.24xgrande | ml.p4de.24xgrande |
| Llama 2 7B | 33 | 17 | 18 | 20 | - |
| Llama 2 7B Chat | 33 | 17 | 18 | 20 | - |
| Llama 2 13B | - | 22 | 23 | 23 | - |
| Llama 2 13B Chat | - | 23 | 23 | 23 | - |
| Llama 2 70B | - | - | 57 | 43 | - |
| Llama 2 70B Chat | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Instrucción Mistral 7B | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Instrucción Falcon 7B | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Instrucción Falcon 40B | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Halcón 180B Charla | - | - | - | - | 42 |
Para lograr una latencia mínima para un modelo, puede utilizar el siguiente código mientras sustituye el ID del modelo y el tipo de instancia que desee:
Tenga en cuenta que los números de latencia cambian según la cantidad de tokens de entrada y salida. Sin embargo, el proceso de implementación sigue siendo el mismo excepto las variables de entorno. MAX_INPUT_TOKENS y MAX_TOTAL_TOKENS. Aquí, estas variables de entorno se configuran para ayudar a garantizar los requisitos de latencia del punto final porque secuencias de entrada más grandes pueden violar el requisito de latencia. Tenga en cuenta que SageMaker JumpStart ya proporciona otras variables de entorno óptimas al seleccionar el tipo de instancia; por ejemplo, usar ml.g5.12xlarge establecerá SM_NUM_GPUS a 4 en el entorno del modelo.
Maximizar el rendimiento
En esta sección, maximizamos la cantidad de tokens generados por segundo. Esto normalmente se logra con el máximo de solicitudes simultáneas válidas para el modelo y el tipo de instancia. En la siguiente tabla, informamos el rendimiento alcanzado en el valor de solicitud simultánea más grande logrado antes de encontrar un tiempo de espera de invocación de SageMaker para cualquier solicitud.
| Rendimiento máximo (tokens/seg), solicitudes simultáneas | |||||
| Modelo ID | ml.g5.2xgrande | ml.g5.12xgrande | ml.g5.48xgrande | ml.p4d.24xgrande | ml.p4de.24xgrande |
| Llama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Llama 2 7B Chat | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Llama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Llama 2 13B Chat | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Llama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Llama 2 70B Chat | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Instrucción Mistral 7B | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Instrucción Falcon 7B | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Instrucción Falcon 40B | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Halcón 180B Charla | - | - | - | - | 1081 (128) |
Para lograr el máximo rendimiento para un modelo, puede utilizar el siguiente código:
Tenga en cuenta que la cantidad máxima de solicitudes simultáneas depende del tipo de modelo, el tipo de instancia, la cantidad máxima de tokens de entrada y la cantidad máxima de tokens de salida. Por lo tanto, debe configurar estos parámetros antes de configurar MAX_CONCURRENT_REQUESTS.
También tenga en cuenta que un usuario interesado en minimizar la latencia suele estar en desacuerdo con un usuario interesado en maximizar el rendimiento. El primero está interesado en respuestas en tiempo real, mientras que el segundo está interesado en el procesamiento por lotes de modo que la cola del punto final esté siempre saturada, minimizando así el tiempo de inactividad del procesamiento. Los usuarios que desean maximizar el rendimiento condicionado a los requisitos de latencia a menudo están interesados en operar en el punto más bajo de la curva de latencia-rendimiento.
Minimizar costo
La primera opción para minimizar el costo implica minimizar el costo por hora. Con esto, puede implementar un modelo seleccionado en la instancia de SageMaker con el menor costo por hora. Para conocer los precios en tiempo real de las instancias de SageMaker, consulte Precios de Amazon SageMaker. En general, el tipo de instancia predeterminado para los LLM de SageMaker JumpStart es la opción de implementación de menor costo.
La segunda opción para minimizar el costo implica minimizar el costo de generar 1 millón de tokens. Esta es una transformación simple de la tabla que analizamos anteriormente para maximizar el rendimiento, donde primero puede calcular el tiempo que lleva en horas generar 1 millón de tokens (1e6/rendimiento/3600). Luego puedes multiplicar este tiempo para generar 1 millón de tokens con el precio por hora de la instancia de SageMaker especificada.
Tenga en cuenta que las instancias con el costo por hora más bajo no son las mismas que las instancias con el costo más bajo para generar 1 millón de tokens. Por ejemplo, si las solicitudes de invocación son esporádicas, una instancia con el menor costo por hora podría ser óptima, mientras que en los escenarios de limitación, el menor costo para generar un millón de tokens podría ser más apropiado.
Compensación entre tensor paralelo y multimodelo
En todos los análisis anteriores, consideramos implementar una réplica de modelo único con un grado de tensor paralelo igual a la cantidad de GPU en el tipo de instancia de implementación. Este es el comportamiento predeterminado de SageMaker JumpStart. Sin embargo, como se señaló anteriormente, fragmentar un modelo puede mejorar la latencia y el rendimiento del modelo solo hasta un cierto límite, más allá del cual los requisitos de comunicación entre dispositivos dominan el tiempo de cálculo. Esto implica que a menudo es beneficioso implementar varios modelos con un grado de tensor paralelo más bajo en una sola instancia en lugar de un único modelo con un grado de tensor paralelo más alto.
Aquí, implementamos puntos finales Llama 2 7B y 13B en instancias ml.p4d.24xlarge con grados de tensor paralelo (TP) de 1, 2, 4 y 8. Para mayor claridad en el comportamiento del modelo, cada uno de estos puntos finales solo carga un único modelo.
| . | Rendimiento (tokens/seg) | Latencia (ms/token) | ||||||||||||||||||
| Solicitudes concurrentes | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Grado TP | Llama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Llama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Nuestros análisis anteriores ya mostraron importantes ventajas de rendimiento en instancias ml.p4d.24xlarge, lo que a menudo se traduce en un mejor rendimiento en términos de costo para generar 1 millón de tokens en comparación con la familia de instancias g5 en condiciones de alta carga de solicitudes simultáneas. Este análisis demuestra claramente que se debe considerar el equilibrio entre la fragmentación del modelo y la replicación del modelo dentro de una sola instancia; es decir, un modelo completamente fragmentado no suele ser el mejor uso de los recursos informáticos ml.p4d.24xlarge para las familias de modelos 7B y 13B. De hecho, para la familia de modelos 7B, se obtiene el mejor rendimiento para una réplica de un solo modelo con un grado de tensor paralelo de 4 en lugar de 8.
A partir de aquí, puede extrapolar que la configuración de mayor rendimiento para el modelo 7B implica un tensor paralelo de grado 1 con ocho réplicas del modelo, y la configuración de mayor rendimiento para el modelo 13B es probablemente un tensor paralelo de grado 2 con cuatro réplicas del modelo. Para obtener más información sobre cómo lograr esto, consulte Reduzca los costos de implementación de modelos en un 50 % en promedio utilizando las funciones más recientes de Amazon SageMaker., que demuestra el uso de puntos finales basados en componentes de inferencia. Debido a las técnicas de equilibrio de carga, el enrutamiento del servidor y el uso compartido de recursos de CPU, es posible que no logre mejoras de rendimiento exactamente iguales al número de réplicas multiplicado por el rendimiento de una única réplica.
Escala horizontal
Como se observó anteriormente, cada implementación de punto final tiene una limitación en la cantidad de solicitudes simultáneas según la cantidad de tokens de entrada y salida, así como el tipo de instancia. Si esto no cumple con su rendimiento o requisito de solicitud simultánea, puede ampliar para utilizar más de una instancia detrás del punto final implementado. SageMaker realiza automáticamente el equilibrio de carga de consultas entre instancias. Por ejemplo, el siguiente código implementa un punto final compatible con tres instancias:
La siguiente tabla muestra la ganancia de rendimiento como factor del número de instancias para el modelo Llama 2 7B.
| . | . | Rendimiento (tokens/seg) | Latencia (ms/token) | ||||||||||||||
| . | Solicitudes concurrentes | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Recuento de instancias | Tipo de instancia | Número de tokens totales: 512, Número de tokens de salida: 256 | |||||||||||||||
| 1 | ml.g5.2xgrande | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xgrande | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xgrande | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
En particular, el codo en la curva de latencia-rendimiento se desplaza hacia la derecha porque un mayor número de instancias puede manejar un mayor número de solicitudes simultáneas dentro del punto final de múltiples instancias. Para esta tabla, el valor de la solicitud simultánea es para todo el punto final, no el número de solicitudes simultáneas que recibe cada instancia individual.
También puede utilizar el escalado automático, una función para monitorear sus cargas de trabajo y ajustar dinámicamente la capacidad para mantener un rendimiento estable y predecible al menor costo posible. Esto está más allá del alcance de esta publicación. Para obtener más información sobre el ajuste de escala automático, consulte Configuración de puntos de enlace de inferencia de ajuste de escala automático en Amazon SageMaker.
Invocar punto final con solicitudes simultáneas
Supongamos que tiene un gran lote de consultas que le gustaría utilizar para generar respuestas a partir de un modelo implementado en condiciones de alto rendimiento. Por ejemplo, en el siguiente bloque de código, compilamos una lista de 1,000 cargas útiles, y cada carga útil solicita la generación de 100 tokens. En total, solicitamos la generación de 100,000 tokens.
Al enviar una gran cantidad de solicitudes a la API de tiempo de ejecución de SageMaker, es posible que experimente errores de limitación. Para mitigar esto, puede crear un cliente de tiempo de ejecución de SageMaker personalizado que aumente la cantidad de reintentos. Puede proporcionar el objeto de sesión de SageMaker resultante al JumpStartModel constructor o sagemaker.predictor.retrieve_default si desea adjuntar un nuevo predictor a un punto final ya implementado. En el siguiente código, utilizamos este objeto de sesión al implementar un modelo Llama 2 con configuraciones predeterminadas de SageMaker JumpStart:
Este punto final implementado tiene MAX_CONCURRENT_REQUESTS = 128 por defecto. En el siguiente bloque, utilizamos la biblioteca de futuros concurrentes para iterar la invocación del punto final para todas las cargas útiles con 128 subprocesos de trabajo. Como máximo, el punto final procesará 128 solicitudes simultáneas y cada vez que una solicitud devuelva una respuesta, el ejecutor enviará inmediatamente una nueva solicitud al punto final.
Esto da como resultado la generación de 100,000 1255 tokens en total con un rendimiento de 5.2 tokens/s en una única instancia ml.g80xlarge. Esto tarda aproximadamente XNUMX segundos en procesarse.
Tenga en cuenta que este valor de rendimiento es notablemente diferente del rendimiento máximo para Llama 2 7B en ml.g5.2xlarge en las tablas anteriores de esta publicación (486 tokens/seg con 64 solicitudes simultáneas). Esto se debe a que la carga útil de entrada utiliza 8 tokens en lugar de 256, el recuento de tokens de salida es 100 en lugar de 256 y los recuentos de tokens más pequeños permiten 128 solicitudes simultáneas. ¡Este es un recordatorio final de que todas las cifras de latencia y rendimiento dependen de la carga útil! Cambiar los recuentos de tokens de carga útil afectará los procesos de procesamiento por lotes durante la entrega del modelo, lo que a su vez afectará los tiempos de precarga emergente, decodificación y cola de su aplicación.
Conclusión
En esta publicación, presentamos la evaluación comparativa de los LLM de SageMaker JumpStart, incluidos Llama 2, Mistral y Falcon. También presentamos una guía para optimizar la latencia, el rendimiento y el costo de la configuración de implementación de su terminal. Puede comenzar ejecutando el cuaderno asociado para comparar su caso de uso.
Acerca de los autores
 Dr.Kyle Ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
Dr.Kyle Ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
 Dr. Vivek Madán es un científico aplicado del equipo JumpStart de Amazon SageMaker. Obtuvo su doctorado en la Universidad de Illinois en Urbana-Champaign y fue investigador posdoctoral en Georgia Tech. Es un investigador activo en aprendizaje automático y diseño de algoritmos y ha publicado artículos en conferencias EMNLP, ICLR, COLT, FOCS y SODA.
Dr. Vivek Madán es un científico aplicado del equipo JumpStart de Amazon SageMaker. Obtuvo su doctorado en la Universidad de Illinois en Urbana-Champaign y fue investigador posdoctoral en Georgia Tech. Es un investigador activo en aprendizaje automático y diseño de algoritmos y ha publicado artículos en conferencias EMNLP, ICLR, COLT, FOCS y SODA.
 Dr. Ashish Khetan es un científico aplicado sénior de Amazon SageMaker JumpStart y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khetan es un científico aplicado sénior de Amazon SageMaker JumpStart y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
 joão moura es arquitecto senior de soluciones especializado en IA/ML en AWS. João ayuda a los clientes de AWS (desde pequeñas empresas emergentes hasta grandes empresas) a capacitar e implementar modelos grandes de manera eficiente y, de manera más amplia, a construir plataformas de aprendizaje automático en AWS.
joão moura es arquitecto senior de soluciones especializado en IA/ML en AWS. João ayuda a los clientes de AWS (desde pequeñas empresas emergentes hasta grandes empresas) a capacitar e implementar modelos grandes de manera eficiente y, de manera más amplia, a construir plataformas de aprendizaje automático en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

