Desplazamiento al rojo de Amazon es un servicio de almacenamiento de datos a escala de petabyte totalmente administrado en la nube. Puede comenzar con unos pocos cientos de gigabytes de datos y escalar a un petabyte o más. En la actualidad, decenas de miles de clientes de AWS, desde empresas Fortune 500, empresas emergentes y todo lo demás, utilizan Amazon Redshift para ejecutar paneles de inteligencia comercial (BI) de misión crítica, analizar datos de transmisión en tiempo real y ejecutar análisis predictivos. Con el aumento constante de los datos generados, los clientes de Amazon Redshift continúan logrando éxitos para brindar un mejor servicio a sus usuarios finales, mejorar sus productos y administrar un negocio eficiente y eficaz.
En esta publicación, hablamos de un cliente que actualmente usa Snowflake para almacenar datos analíticos. El cliente debe ofrecer estos datos a los clientes que utilizan Amazon Redshift a través de Intercambio de datos de AWS, el servicio más completo del mundo para conjuntos de datos de terceros. Explicamos en detalle cómo implementar un proceso completamente integrado que ingiera automáticamente datos de Snowflake en Amazon Redshift y los ofrezca a los clientes a través de AWS Data Exchange.
Resumen de la solución
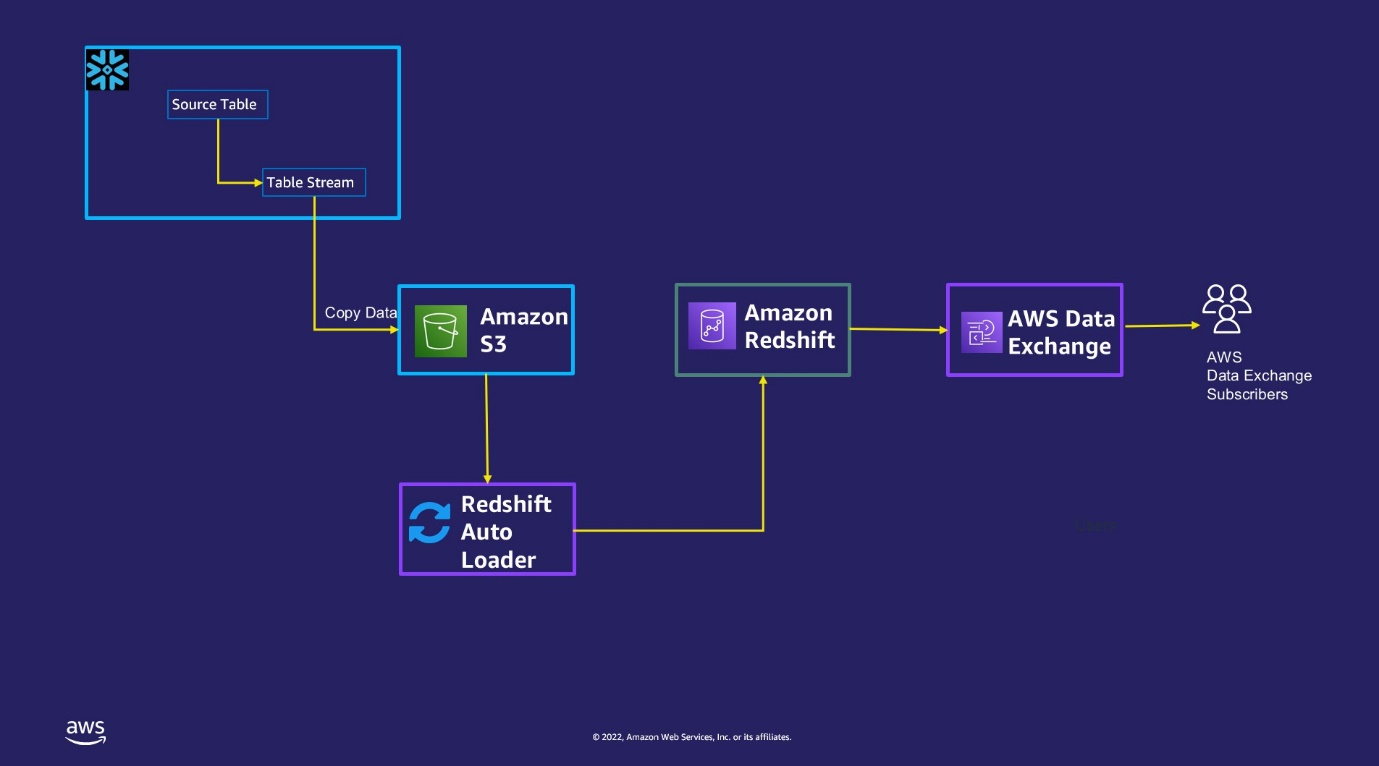
La solución consta de cuatro pasos de alto nivel:
- Configure Snowflake para enviar los datos modificados de las tablas identificadas a un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
- Utilice un personalizado Cargador automático Redshift para cargar estos datos aterrizados de Amazon S3 en Amazon Redshift.
- Combine los datos de las tablas provisionales de S3 de captura de datos de cambios (CDC) con las tablas de Amazon Redshift.
- Utilice el uso compartido de datos de Amazon Redshift para licenciar los datos a los clientes a través de AWS Data Exchange como una oferta pública o privada.
El siguiente diagrama ilustra este flujo de trabajo.
Requisitos previos
Para comenzar, necesita los siguientes requisitos previos:
Configure Snowflake para realizar un seguimiento de los datos modificados y descargarlos en Amazon S3
En Snowflake, identifique las tablas que necesita replicar en Amazon Redshift. Para el propósito de esta demostración, usamos los datos en el TPCH_SF1 esquema Customer, LineItemy Orders mesas de la SNOWFLAKE_SAMPLE_DATA base de datos, que viene de fábrica con su cuenta de Snowflake.
- Asegúrate de que el nombre artístico externo de Snowflake
unload_to_s3creado en los requisitos previos apunta al prefijo S3s3-redshift-loader-sourcecreado en el paso anterior. - Crear un nuevo esquema
BLOG_DEMOexistentesDEMO_DBbase de datos:CREATE SCHEMA demo_db.blog_demo; - Duplica el
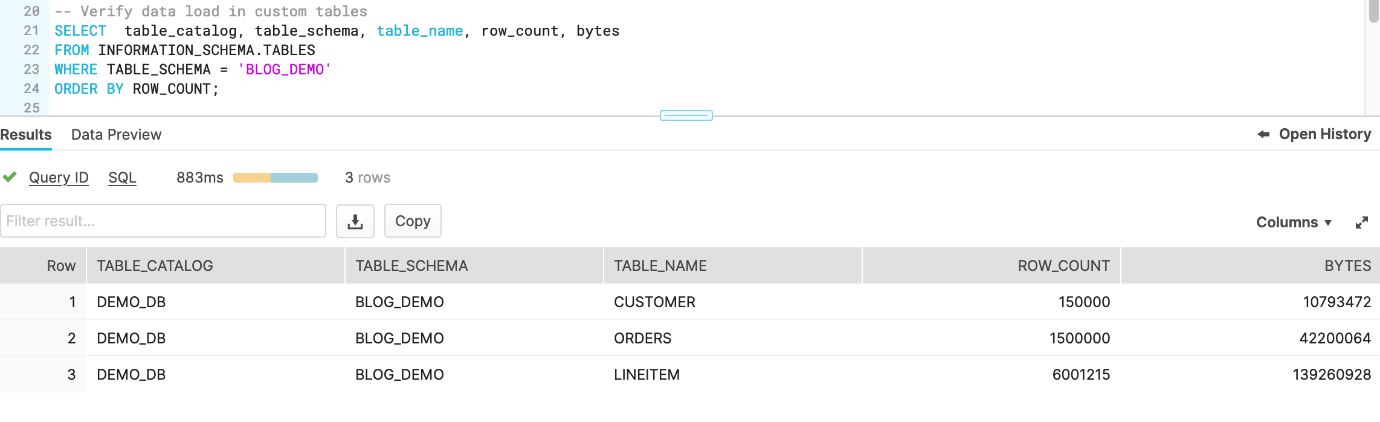
Customer,LineItemyOrderstablas en elTPCH_SF1esquema a laBLOG_DEMOesquema: - Verifique que las tablas se hayan duplicado correctamente:
- Crear flujos de mesa para realizar un seguimiento de los cambios del lenguaje de manipulación de datos (DML) realizados en las tablas, incluidas las inserciones, actualizaciones y eliminaciones:
- Realice cambios DML en las tablas (para esta publicación, ejecutamos UPDATE en todas las tablas y MERGE en el
customermesa): - Valide que las tablas de flujo hayan registrado todos los cambios:
- Ejecute el comando COPY para descargar el CDC de las tablas de flujo al depósito S3 usando el nombre de la etapa externa
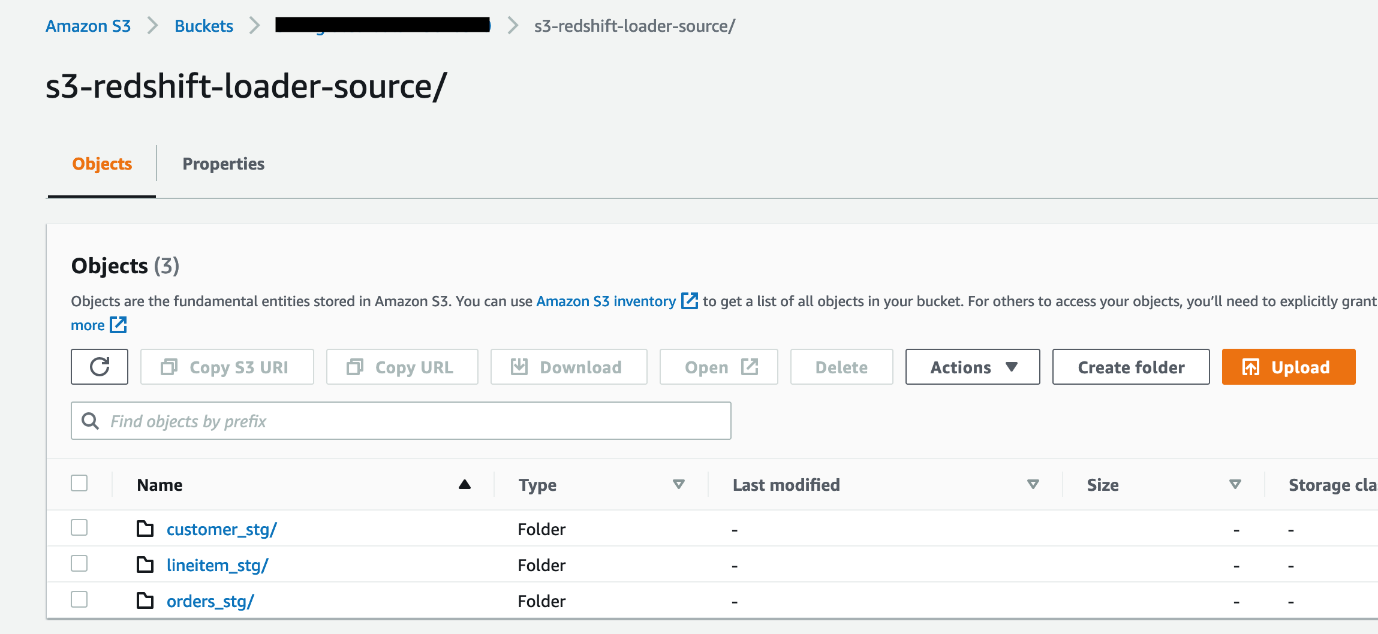
unload_to_s3.En el siguiente código, también estamos copiando los datos a las carpetas S3 que terminan en_stgpara asegurarse de que cuando Redshift Auto Loader cree automáticamente estas tablas en Amazon Redshift, se creen y marquen como tablas provisionales: - Verifique los datos en el depósito S3. Se crearán tres subcarpetas en la carpeta s3-redshift-loader-source del depósito S3, y cada una tendrá archivos de datos .parquet.
 También puede automatizar los comandos COPY anteriores mediante tareas, que se pueden programar para que se ejecuten con una frecuencia establecida para la copia automática de datos de CDC de Snowflake a Amazon S3.
También puede automatizar los comandos COPY anteriores mediante tareas, que se pueden programar para que se ejecuten con una frecuencia establecida para la copia automática de datos de CDC de Snowflake a Amazon S3. - Ingrese al
ACCOUNTADMINpapel para asignar elEXECUTE TASKprivilegio. En este escenario, estamos asignando los privilegios alSYSADMINpapel: - Ingrese al
SYSADMINrol para crear tres tareas separadas para ejecutar tres comandos COPY cada 5 minutos:USE ROLE sysadmin;Cuando las tareas se crean por primera vez, están en un
SUSPENDEDestado. - Modifique las tres tareas y configúrelas en el estado REANUDAR:
- Valide que las tres tareas se hayan reanudado correctamente:
SHOW TASKS;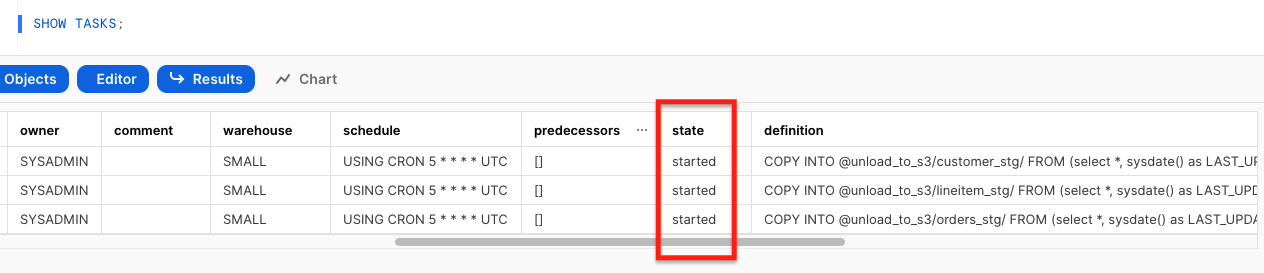 Ahora las tareas se ejecutarán cada 5 minutos y buscarán nuevos datos en las tablas de transmisión para descargarlos en Amazon S3. Tan pronto como los datos se migren de Snowflake a Amazon S3, Redshift Auto Loader infiere automáticamente el esquema y crea instantáneamente las tablas correspondientes en Amazon Redshift. . Luego, de manera predeterminada, comienza a cargar datos de Amazon S3 a Amazon Redshift cada 5 minutos. Tú también puedes cambiar la configuración predeterminada de 5 minutos
Ahora las tareas se ejecutarán cada 5 minutos y buscarán nuevos datos en las tablas de transmisión para descargarlos en Amazon S3. Tan pronto como los datos se migren de Snowflake a Amazon S3, Redshift Auto Loader infiere automáticamente el esquema y crea instantáneamente las tablas correspondientes en Amazon Redshift. . Luego, de manera predeterminada, comienza a cargar datos de Amazon S3 a Amazon Redshift cada 5 minutos. Tú también puedes cambiar la configuración predeterminada de 5 minutos - En la consola de Amazon Redshift, inicie el editor de consultas v2 y conéctese a su clúster de Amazon Redshift.
- Navega hasta el
devbase de datos,publicesquema y ampliar Mesas.
Puede ver tres tablas provisionales creadas con el mismo nombre que las carpetas correspondientes en Amazon S3. - Valide los datos en una de las tablas ejecutando la siguiente consulta:
SELECT * FROM "dev"."public"."customer_stg";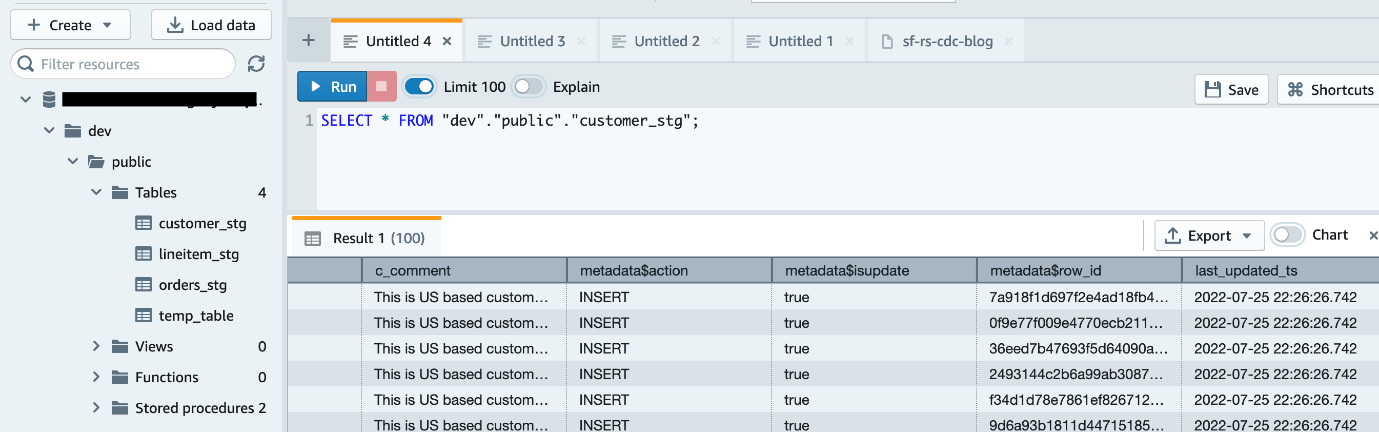
Configurar la utilidad Redshift Auto Loader
Redshift Auto Loader facilita significativamente la ingesta de datos en Amazon Redshift porque carga automáticamente los archivos de datos de Amazon S3 a Amazon Redshift. Los archivos se asignan a las tablas respectivas con solo colocar los archivos en ubicaciones preconfiguradas en Amazon S3. Para obtener más detalles sobre la arquitectura y el flujo de trabajo interno, consulte el Repositorio GitHub.
Usamos un Formación en la nube de AWS plantilla para configurar Redshift Auto Loader. Complete los siguientes pasos:
- Inicie CloudFormation plantilla.
- Elige Siguiente.
- Nombre de pila, ingresa un nombre.
- Proporcione los parámetros enumerados en la siguiente tabla.
Parámetro de plantilla de CloudFormation Valores permitidos Descripción RedshiftClusterIdentifierIdentificador de clúster de Amazon Redshift Ingrese el identificador del clúster de Amazon Redshift. DatabaseUserNameNombre de usuario de la base de datos en el clúster de Amazon Redshift El nombre de usuario de la base de datos de Amazon Redshift que tiene acceso para ejecutar el script SQL. DatabaseNameNombre del depósito S3 El nombre de la base de datos principal de Amazon Redshift donde se ejecuta el script SQL. DatabaseSchemaNameNombre de la base de datos en Amazon Redshift El nombre del esquema de Amazon Redshift donde se crean las tablas. RedshiftIAMRoleARNARN de rol de IAM predeterminado o válido adjunto al clúster de Amazon Redshift El ARN del rol de IAM asociado con el clúster de Amazon Redshift. Su rol de IAM predeterminado está configurado para el clúster y tiene acceso a su depósito S3, déjelo en el valor predeterminado. CopyCommandOptionsOpción de copia; el valor predeterminado es el delimitador '|' gzip Proporcione los parámetros adicionales de formato de datos del comando COPY.
Si InitiateSchemaDetection = Sí, el proceso intenta detectar el esquema y establece automáticamente las opciones de comando de copia adecuadas.
En caso de falla en la detección del esquema o cuando InitiateSchemaDetection = No, este valor se usa como las opciones predeterminadas del comando COPY para cargar datos.
SourceS3BucketNombre del depósito S3 El depósito de S3 donde se almacenan los datos. Asegúrese de que el rol de IAM asociado al clúster de Amazon Redshift tenga acceso a este depósito. InitiateSchemaDetectionSi no Se establece en Sí para detectar dinámicamente el esquema antes de cargar el archivo y crear una tabla en Amazon Redshift si aún no existe. Si ya existe una tabla, no la eliminará ni la volverá a crear en Amazon Redshift.
Si la detección del esquema falla, el proceso usa las opciones COPY predeterminadas como se especifica en
CopyCommandOptions.Redshift Auto Loader utiliza el comando COPY para cargar datos en Amazon Redshift. Para esta publicación, establezca
CopyCommandOptionsde la siguiente manera, y configure cualquier opción de comando COPY admitida: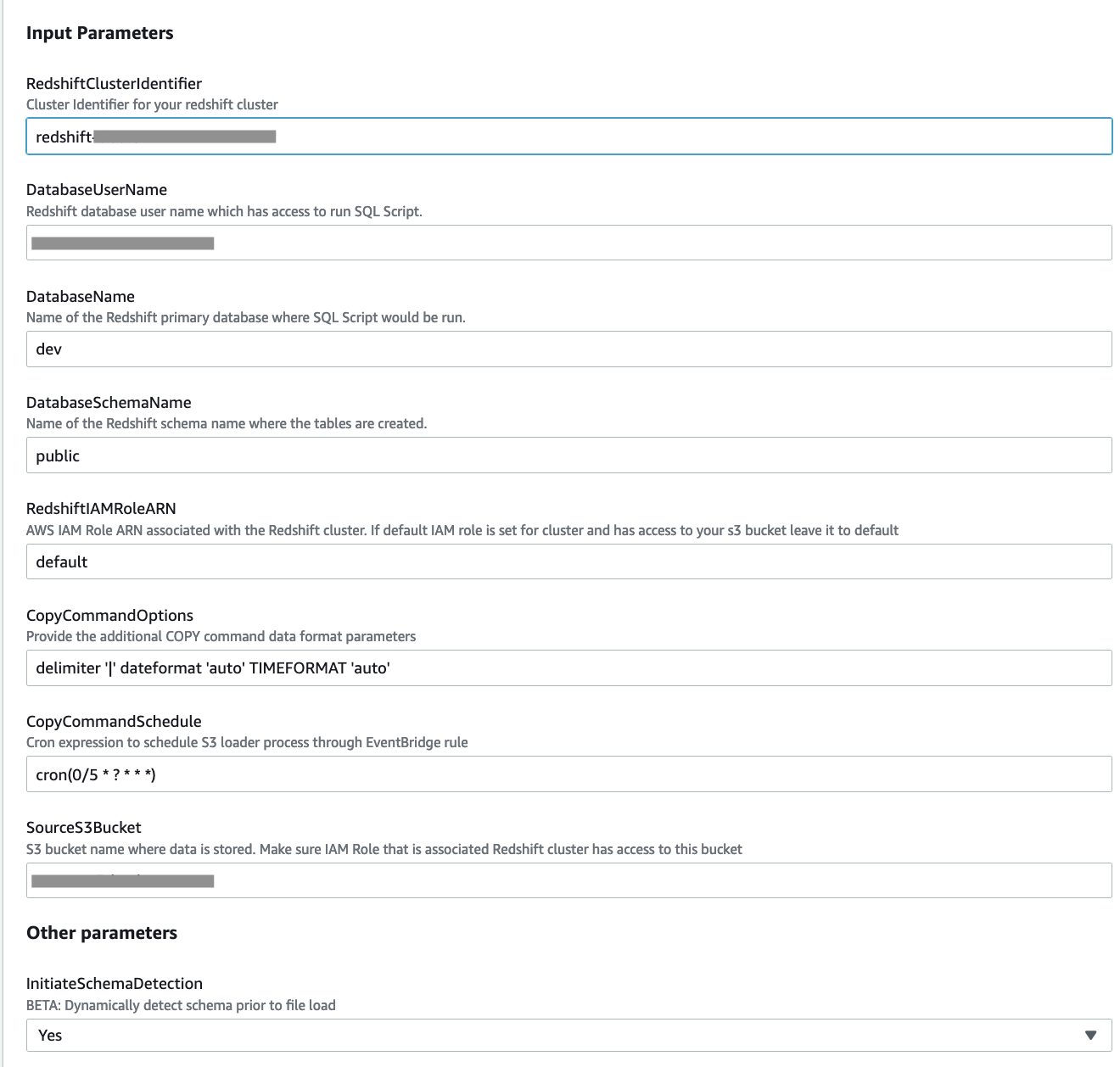
- Elige Siguiente.
- Acepte los valores predeterminados en la página siguiente y elija Siguiente.
- Seleccione la casilla de verificación de acuse de recibo y elija Crear pila.
- Supervise el progreso de la creación de la pila y espere hasta que se complete.
- Para verificar la configuración del cargador automático de Redshift, inicie sesión en la consola de Amazon S3 y navegue hasta el depósito de S3 que proporcionó.
Deberías ver un nuevo directorio.s3-redshift-loader-sourcees creado.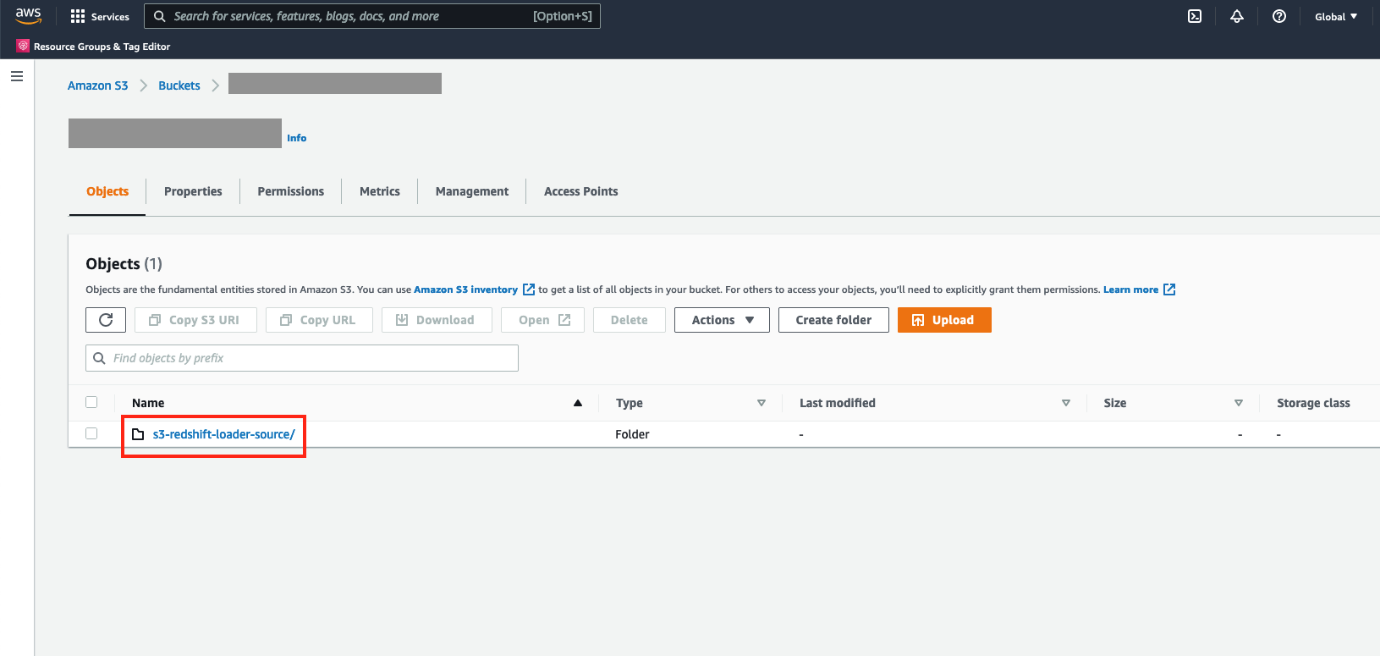
Copie todos los archivos de datos exportados de Snowflake en s3-redshift-loader-source.
Combine los datos de las tablas provisionales de CDC S3 con las tablas de Amazon Redshift
Para fusionar sus datos de Amazon S3 a Amazon Redshift, complete los siguientes pasos:
- Crear una tabla de preparación temporal
merge_stge inserte todas las filas de la tabla provisional de S3 que tienenmetadata_actionasINSERT, usando el siguiente código. Esto incluye todas las nuevas inserciones, así como la actualización. - Usar la tabla de preparación de S3
customer_stgpara eliminar los registros de la tabla basecustomer, que se marcan como eliminaciones o actualizaciones: - Usar la tabla de preparación temporal
merge_stgpara insertar los registros marcados para actualizaciones o inserciones: - Trunca la tabla de etapas, porque ya hemos actualizado la tabla de destino:
truncate customer_stg; - También puede ejecutar los pasos anteriores como un procedimiento almacenado:
- Ahora, para actualizar la tabla de destino, podemos ejecutar el procedimiento almacenado de la siguiente manera:
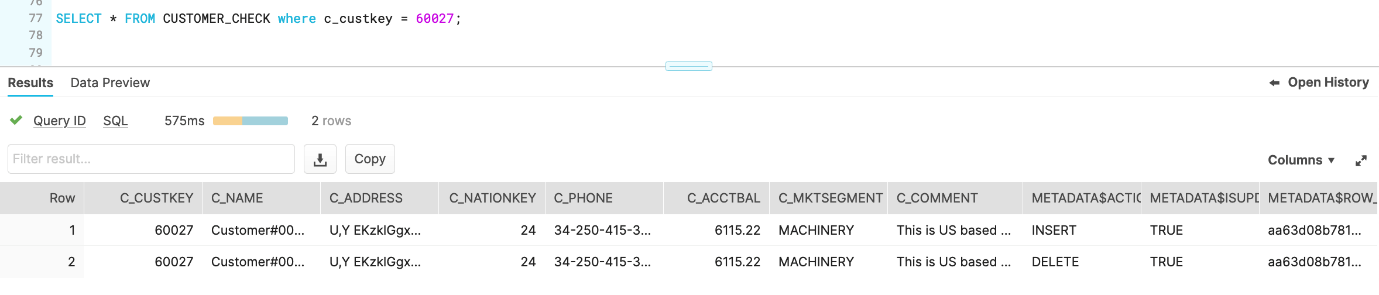
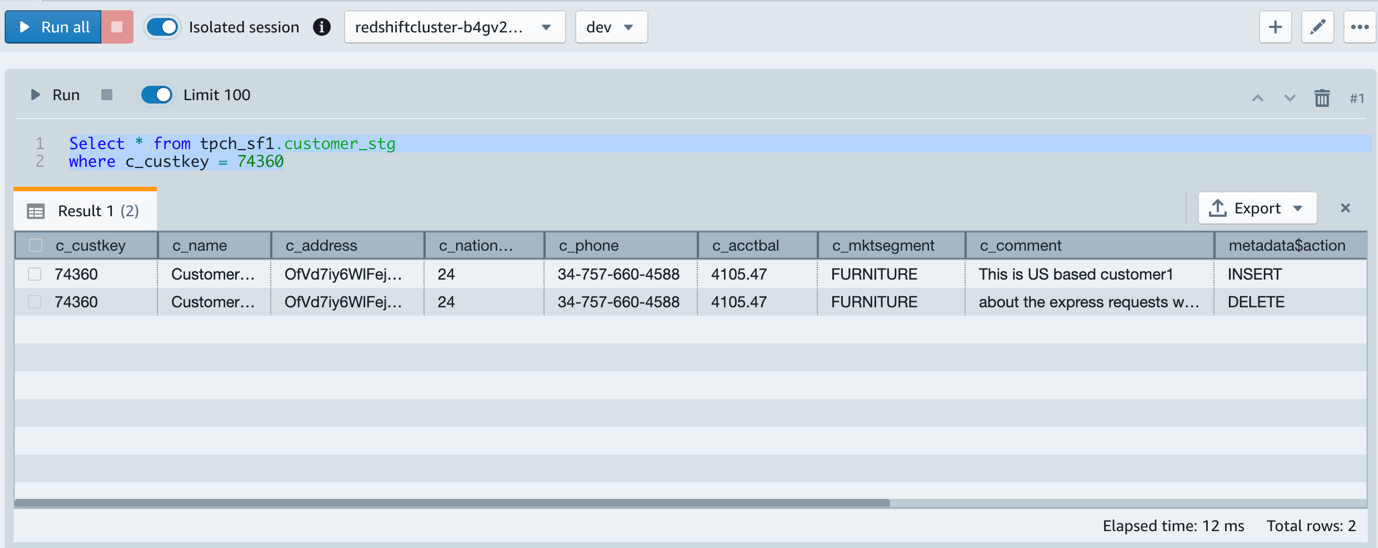
CALL merge_customer()La siguiente captura de pantalla muestra el estado final de la tabla de destino una vez que se completa el procedimiento almacenado.

Ejecutar el procedimiento almacenado en un horario
También puede ejecutar el procedimiento almacenado en un horario a través de Puente de eventos de Amazon. Los pasos de programación son los siguientes:
- En la consola de EventBridge, elija Crear regla.

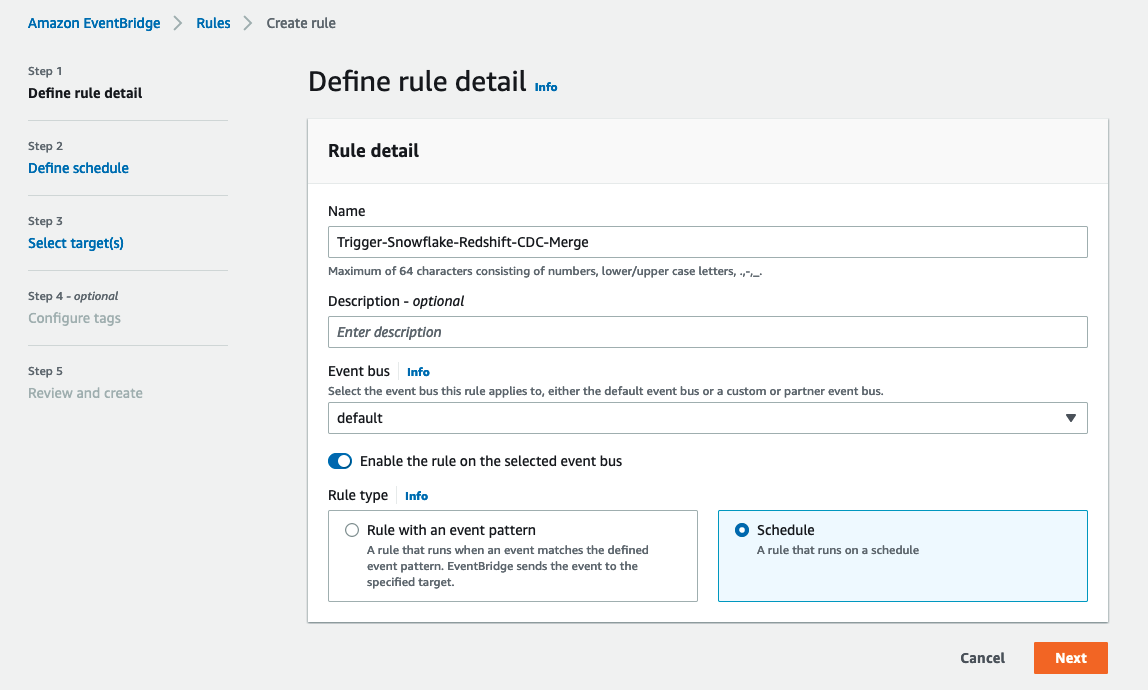
- Nombre, ingrese un nombre significativo, por ejemplo,
Trigger-Snowflake-Redshift-CDC-Merge. - Bus de eventos, escoger tu préstamo estudiantil.
- Tipo de regla, selecciona Horarios.
- Elige Siguiente.
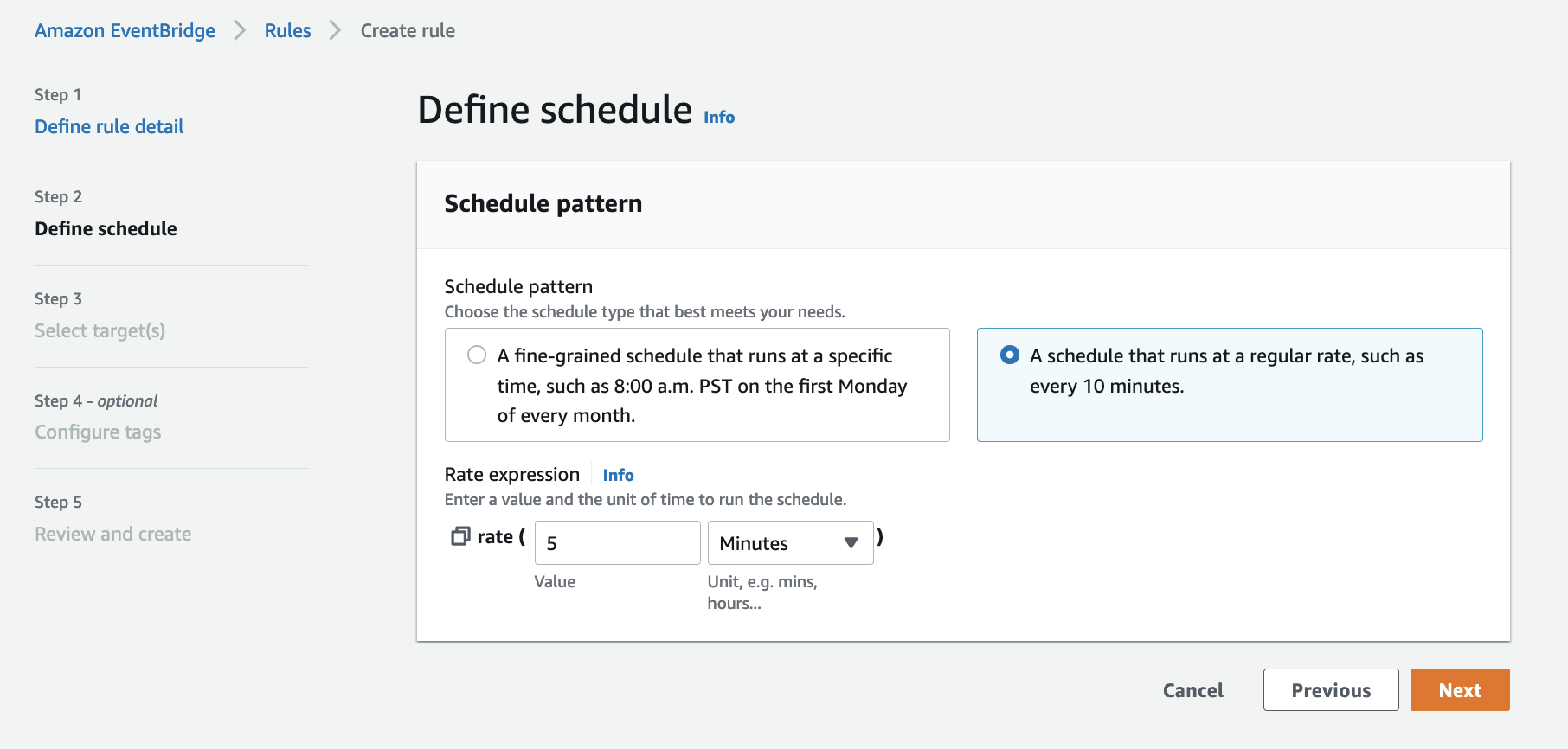
- Patrón de programación, seleccione Un programa que se ejecuta a un ritmo regular, como cada 10 minutos.
- Tasa de expresión, introduzca Valor como 5 y elige Unidad as Min.
- Elige Siguiente.
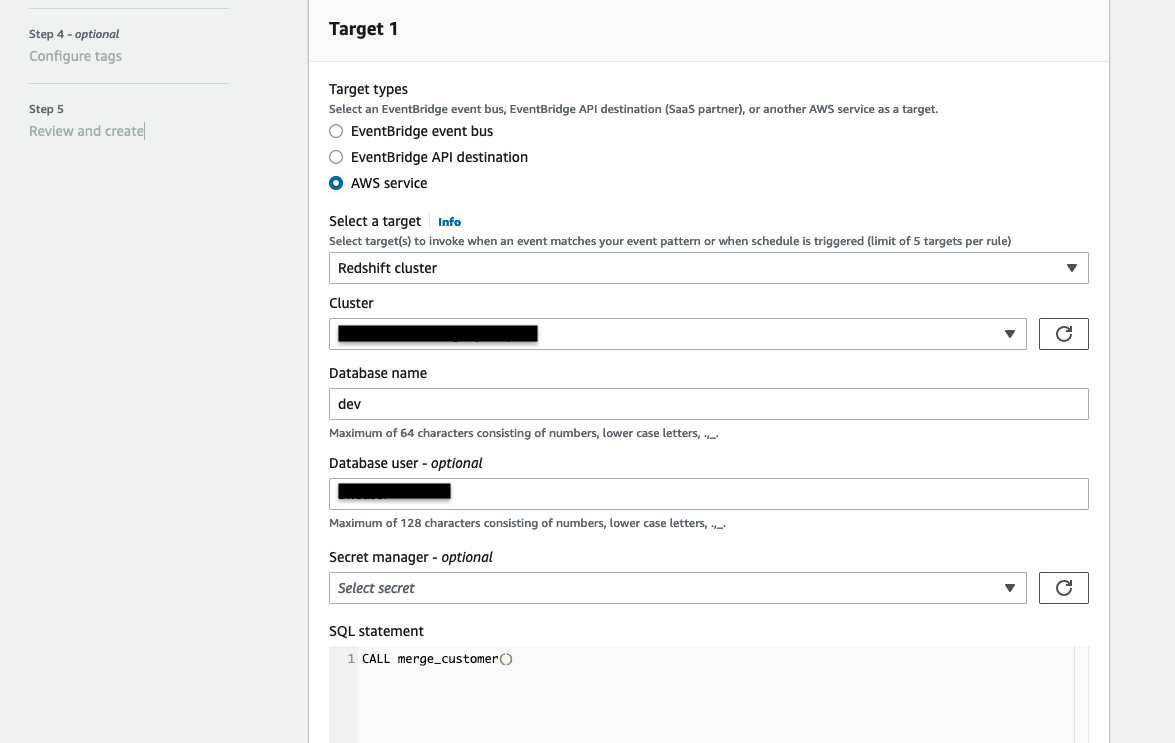
- Tipos de objetivo, escoger Servicio de AWS.
- Seleccione un objetivo, escoger Cúmulo de corrimiento al rojo.
- Médico, elija el identificador de clúster de Amazon Redshift.
- Nombre de la base de datos, escoger dev.
- usuario de la base de datos, ingrese un nombre de usuario con acceso para ejecutar el procedimiento almacenado. Utiliza credenciales temporales para autenticarse.
- Opcionalmente, también puede utilizar Director de secretos de AWS para autenticación.
- Declaración SQL, introduzca
CALL merge_customer(). - Rol de ejecución, seleccione Cree un nuevo rol para este recurso específico.
- Elige Siguiente.
- Revise los parámetros de la regla y elija Crear regla.
Una vez creada la regla, activa automáticamente el procedimiento almacenado en Amazon Redshift cada 5 minutos para fusionar los datos de CDC en la tabla de destino.
Configure Amazon Redshift para compartir los datos identificados con AWS Data Exchange
Ahora que tiene los datos almacenados en Amazon Redshift, puede publicarlos para los clientes mediante AWS Data Exchange.
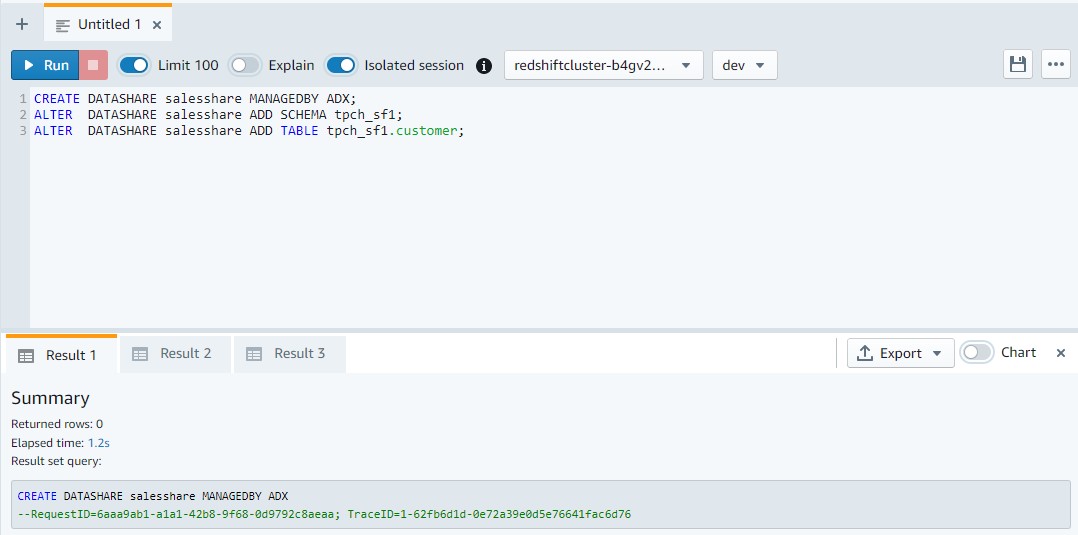
- En Amazon Redshift, con cualquier editor de consultas, cree el recurso compartido de datos y agregue las tablas para compartir:
- En la consola de AWS Data Exchange, cree su conjunto de datos.
- Seleccione Uso compartido de datos de Amazon Redshift.
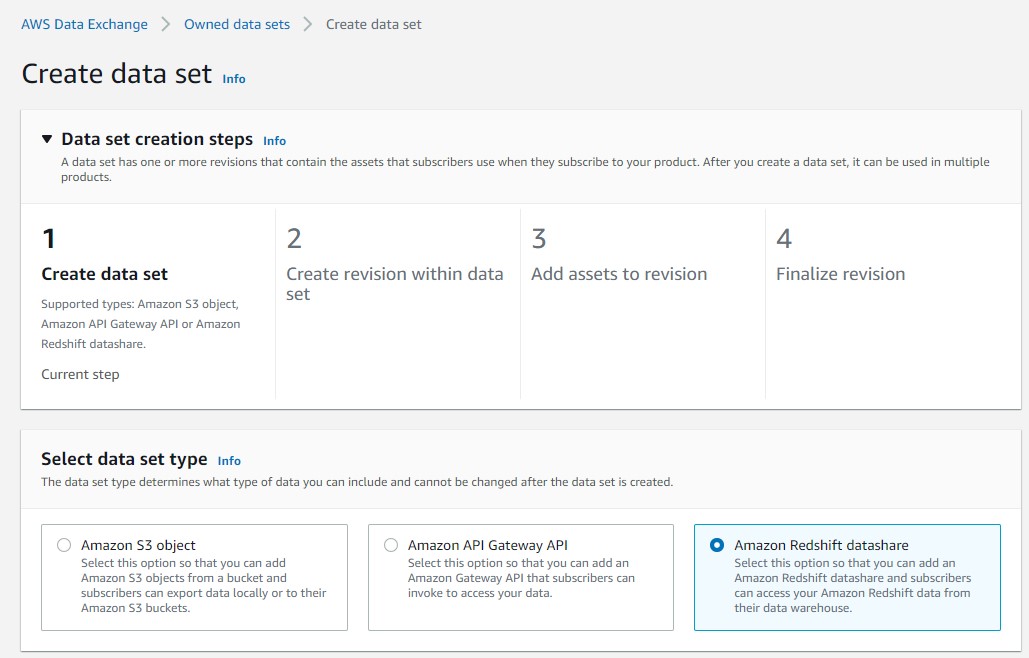
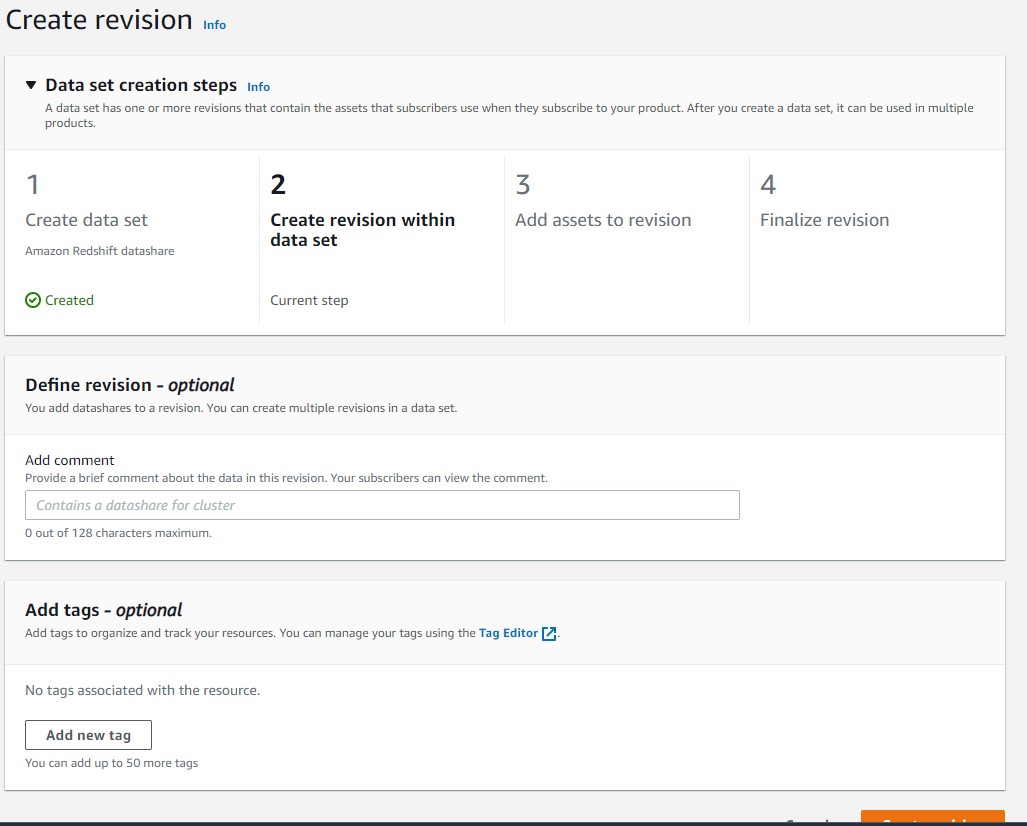
- Cree una revisión en el conjunto de datos.
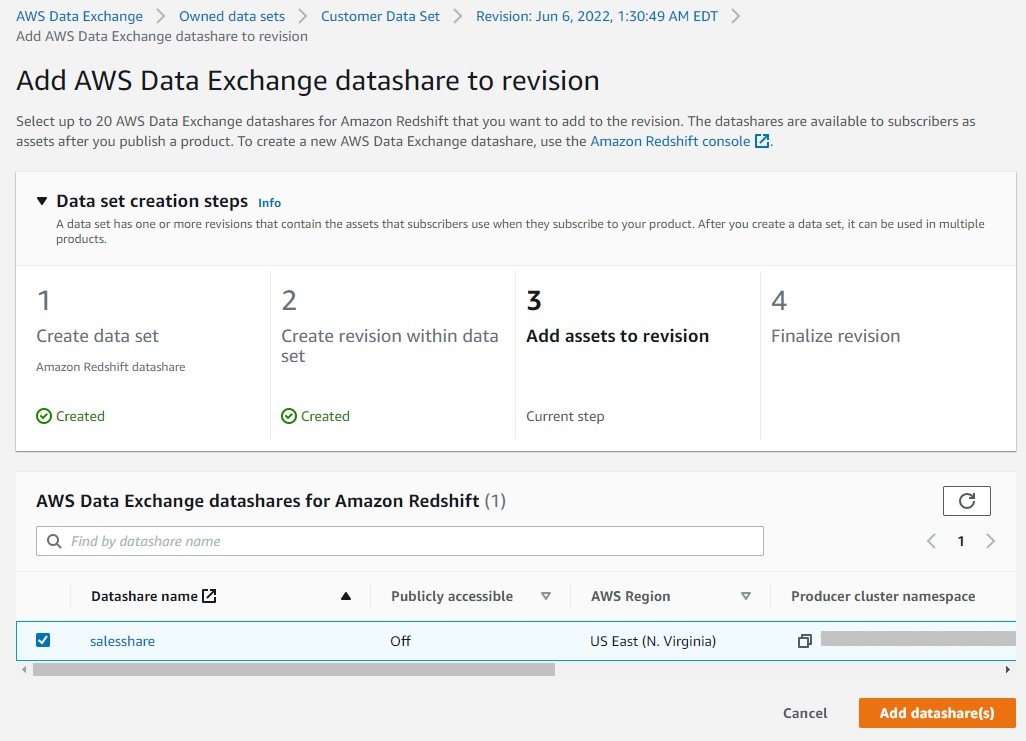
- Agregue activos a la revisión (en este caso, el recurso compartido de datos de Amazon Redshift).
- Finaliza la revisión.

Después de crear el conjunto de datos, puede publicarlo en el catálogo público o directamente a los clientes como un producto privado. Para obtener instrucciones sobre cómo crear y publicar productos, consulte NUEVO: intercambio de datos de AWS para Amazon Redshift
Limpiar
Para evitar incurrir en cargos futuros, complete los siguientes pasos:
- Elimine la pila de CloudFormation utilizada para crear el cargador automático Redshift.
- Elimine el clúster de Amazon Redshift creado para esta demostración.
- Si estaba usando un clúster existente, descarte la tabla externa creada y el esquema externo.
- Elimine el depósito S3 que creó.
- Elimine los objetos Snowflake que creó.
Conclusión
En esta publicación, demostramos cómo puede configurar un proceso completamente integrado que replique continuamente los datos de Snowflake a Amazon Redshift y luego use Amazon Redshift para ofrecer datos a los clientes intermedios a través de AWS Data Exchange. Puede utilizar la misma arquitectura para otros fines, como compartir datos con otros clústeres de Amazon Redshift dentro de la misma cuenta, entre cuentas o incluso entre regiones si es necesario.
Acerca de los autores
 Raks Khare es un arquitecto de soluciones especialista en análisis en AWS con sede en Pensilvania. Ayuda a los clientes a diseñar soluciones de análisis de datos a escala en la plataforma de AWS.
Raks Khare es un arquitecto de soluciones especialista en análisis en AWS con sede en Pensilvania. Ayuda a los clientes a diseñar soluciones de análisis de datos a escala en la plataforma de AWS.
 Ekta Ahuja es arquitecto sénior de soluciones especialista en análisis en AWS. Le apasiona ayudar a los clientes a crear soluciones de análisis y datos escalables y sólidas. Antes de AWS, trabajó en varios roles diferentes de análisis e ingeniería de datos. Fuera del trabajo, le gusta hornear, viajar y los juegos de mesa.
Ekta Ahuja es arquitecto sénior de soluciones especialista en análisis en AWS. Le apasiona ayudar a los clientes a crear soluciones de análisis y datos escalables y sólidas. Antes de AWS, trabajó en varios roles diferentes de análisis e ingeniería de datos. Fuera del trabajo, le gusta hornear, viajar y los juegos de mesa.
 Tahir Aziz es arquitecto de soluciones de análisis en AWS. Ha trabajado en la creación de almacenes de datos y soluciones de big data durante más de 13 años. Le encanta ayudar a los clientes a diseñar soluciones de análisis integrales en AWS. Fuera del trabajo, le gusta viajar.
Tahir Aziz es arquitecto de soluciones de análisis en AWS. Ha trabajado en la creación de almacenes de datos y soluciones de big data durante más de 13 años. Le encanta ayudar a los clientes a diseñar soluciones de análisis integrales en AWS. Fuera del trabajo, le gusta viajar.
y cocinar.
 Ahmed Shehat es arquitecto sénior de soluciones especialista en análisis en AWS con sede en Toronto. Tiene más de dos décadas de experiencia ayudando a los clientes a modernizar sus plataformas de datos. A Ahmed le apasiona ayudar a los clientes a crear soluciones analíticas eficientes, escalables y con buen rendimiento.
Ahmed Shehat es arquitecto sénior de soluciones especialista en análisis en AWS con sede en Toronto. Tiene más de dos décadas de experiencia ayudando a los clientes a modernizar sus plataformas de datos. A Ahmed le apasiona ayudar a los clientes a crear soluciones analíticas eficientes, escalables y con buen rendimiento.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/share-and-publish-your-snowflake-data-to-aws-data-exchange-using-amazon-redshift-data-sharing/

