En esta publicación, demostramos cómo Kubeflow en AWS (una distribución de Kubeflow específica de AWS) utilizada con Contenedores de aprendizaje profundo de AWS y Sistema de archivos elástico de Amazon (Amazon EFS) simplifica la colaboración y brinda flexibilidad en la capacitación de modelos de aprendizaje profundo a escala en ambos Servicio Amazon Elastic Kubernetes (Amazon EKS) y Amazon SageMaker utilizando un enfoque de arquitectura híbrida.
El desarrollo del aprendizaje automático (ML) se basa en marcos y conjuntos de herramientas de código abierto complejos y en constante evolución, así como en ecosistemas de hardware complejos y en constante evolución. Esto plantea un desafío al escalar el desarrollo de ML a un clúster. Los contenedores ofrecen una solución, porque pueden encapsular completamente no solo el código de entrenamiento, sino toda la pila de dependencias hasta las bibliotecas de hardware. Esto garantiza un entorno de aprendizaje automático coherente y portátil, y facilita la reproducibilidad del entorno de formación en cada nodo individual del clúster de formación.
Kubernetes es un sistema ampliamente adoptado para automatizar la implementación de infraestructura, el escalado de recursos y la gestión de estas aplicaciones en contenedores. Sin embargo, Kubernetes no se creó teniendo en cuenta el aprendizaje automático, por lo que puede resultar contradictorio para los científicos de datos debido a su gran dependencia de los archivos de especificación YAML. No hay una experiencia de Jupyter y no hay muchas capacidades específicas de ML, como gestión de flujo de trabajo y canalizaciones, y otras capacidades que los expertos de ML esperan, como ajuste de hiperparámetros, alojamiento de modelos y otras. Tales capacidades se pueden construir, pero Kubernetes no fue diseñado para hacer esto como su objetivo principal.
La comunidad de código abierto se dio cuenta y desarrolló una capa sobre Kubernetes llamada Kubeflow. Kubeflow tiene como objetivo hacer que la implementación de flujos de trabajo de ML de extremo a extremo en Kubernetes sea simple, portátil y escalable. Puede usar Kubeflow para implementar los mejores sistemas de código abierto para ML en diversas infraestructuras.
Kubeflow y Kubernetes brindan flexibilidad y control a los equipos de científicos de datos. Sin embargo, garantizar una alta utilización de los clústeres de capacitación que se ejecutan a escala con gastos generales operativos reducidos sigue siendo un desafío.
Esta publicación demuestra cómo los clientes que tienen restricciones locales o inversiones existentes en Kubernetes pueden abordar este desafío mediante el uso de Amazon EKS y Kubeflow en AWS para implementar una canalización de aprendizaje automático para capacitación distribuida basada en un enfoque autogestionado y utilizar SageMaker completamente administrado para un infraestructura de capacitación optimizada en costos, totalmente administrada y a escala de producción. Esto incluye la implementación paso a paso de una arquitectura de capacitación distribuida híbrida que le permite elegir entre los dos enfoques en tiempo de ejecución, lo que le otorga el máximo control y flexibilidad con necesidades estrictas para sus implementaciones. Verá cómo puede continuar usando bibliotecas de código abierto en su secuencia de comandos de capacitación de aprendizaje profundo y aún hacer que sea compatible para ejecutarse tanto en Kubernetes como en SageMaker de una manera independiente de la plataforma.
¿Cómo ayuda Kubeflow en AWS y SageMaker?
Los modelos de redes neuronales creados con marcos de aprendizaje profundo como TensorFlow, PyTorch, MXNet y otros brindan una precisión mucho mayor mediante el uso de conjuntos de datos de entrenamiento significativamente más grandes, especialmente en casos de uso de procesamiento de lenguaje natural y visión por computadora. Sin embargo, con grandes conjuntos de datos de entrenamiento, lleva más tiempo entrenar los modelos de aprendizaje profundo, lo que en última instancia ralentiza el tiempo de comercialización. Si pudiéramos escalar un clúster y reducir el tiempo de capacitación del modelo de semanas a días u horas, podría tener un gran impacto en la productividad y la velocidad del negocio.
Amazon EKS ayuda a aprovisionar el plano de control de Kubernetes administrado. Puede usar Amazon EKS para crear clústeres de capacitación a gran escala con instancias de CPU y GPU y usar el kit de herramientas de Kubeflow para proporcionar herramientas de código abierto compatibles con ML y poner en funcionamiento flujos de trabajo de ML que son portátiles y escalables mediante Kubeflow Pipelines para mejorar la productividad y la productividad de su equipo. reducir el tiempo de comercialización.
Sin embargo, podría haber un par de desafíos con este enfoque:
- Garantizar la máxima utilización de un clúster en los equipos de ciencia de datos. Por ejemplo, debe aprovisionar instancias de GPU a pedido y garantizar su alta utilización para tareas exigentes a escala de producción, como capacitación de aprendizaje profundo, y usar instancias de CPU para tareas menos exigentes, como preprocesamiento de datos.
- Garantizar la alta disponibilidad de los componentes pesados de la infraestructura de Kubeflow, incluida la base de datos, el almacenamiento y la autenticación, que se implementan en el nodo de trabajo del clúster de Kubernetes. Por ejemplo, el plano de control de Kubeflow genera artefactos (como instancias de MySQL, registros de pod o almacenamiento MinIO) que crecen con el tiempo y necesitan volúmenes de almacenamiento redimensionables con capacidades de monitoreo continuo.
- Compartir el conjunto de datos de entrenamiento, el código y los entornos informáticos entre desarrolladores, clústeres de entrenamiento y proyectos es un desafío. Por ejemplo, si está trabajando en su propio conjunto de bibliotecas y esas bibliotecas tienen fuertes interdependencias, se vuelve muy difícil compartir y ejecutar la misma pieza de código entre científicos de datos en el mismo equipo. Además, cada ejecución de entrenamiento requiere que descargue el conjunto de datos de entrenamiento y cree la imagen de entrenamiento con nuevos cambios de código.
Kubeflow en AWS ayuda a abordar estos desafíos y proporciona un producto Kubeflow semiadministrado de nivel empresarial. Con Kubeflow en AWS, puede reemplazar algunos servicios del plano de control de Kubeflow como base de datos, almacenamiento, monitoreo y administración de usuarios con servicios administrados de AWS como Servicio de base de datos relacional de Amazon (Amazon RDS), Servicio de almacenamiento simple de Amazon (Amazon S3), Sistema de archivos elástico de Amazon (EFS de Amazon), Amazonas FSx, Reloj en la nube de Amazony Cognito Amazonas.
Reemplazar estos componentes de Kubeflow desacopla partes críticas del plano de control de Kubeflow de Kubernetes, proporcionando un diseño seguro, escalable, resistente y rentable. Este enfoque también libera recursos informáticos y de almacenamiento del plano de datos de EKS, que pueden ser necesarios para aplicaciones como el entrenamiento de modelos distribuidos o los servidores de portátiles de usuarios. Kubeflow en AWS también proporciona integración nativa de cuadernos Jupyter con imágenes de contenedor de aprendizaje profundo (DLC), que están preempaquetadas y preconfiguradas con marcos de trabajo de aprendizaje profundo optimizados para AWS, como PyTorch y TensorFlow, que le permiten comenzar a escribir su código de capacitación de inmediato sin tener que preocuparse por nada. con resoluciones de dependencia y optimizaciones de marco. Además, la integración de Amazon EFS con los clústeres de capacitación y el entorno de desarrollo le permite compartir su código y el conjunto de datos de capacitación procesados, lo que evita crear la imagen del contenedor y cargar grandes conjuntos de datos después de cada cambio de código. Estas integraciones con Kubeflow en AWS lo ayudan a acelerar la creación de modelos y el tiempo de capacitación y permiten una mejor colaboración con datos y códigos compartidos más fáciles.
Kubeflow en AWS ayuda a crear una plataforma de aprendizaje automático robusta y de alta disponibilidad. Esta plataforma proporciona flexibilidad para crear y entrenar modelos de aprendizaje profundo y proporciona acceso a muchos kits de herramientas de código abierto, información sobre registros y depuración interactiva para la experimentación. Sin embargo, lograr la máxima utilización de los recursos de infraestructura mientras se entrenan modelos de aprendizaje profundo en cientos de GPU todavía implica muchos gastos generales operativos. Esto podría abordarse mediante el uso de SageMaker, que es un servicio completamente administrado diseñado y optimizado para manejar clústeres de capacitación rentables y de alto rendimiento que solo se aprovisionan cuando se solicitan, se escalan según sea necesario y se apagan automáticamente cuando se completan los trabajos, proporcionando así cerca de 100 % utilización de recursos. Puede integrar SageMaker con Kubeflow Pipelines mediante componentes administrados de SageMaker. Esto le permite hacer operativos los flujos de trabajo de ML como parte de las canalizaciones de Kubeflow, donde puede usar Kubernetes para capacitación local y SageMaker para capacitación a escala de productos en una arquitectura híbrida.
Resumen de la solución
La siguiente arquitectura describe cómo usamos Kubeflow Pipelines para crear e implementar flujos de trabajo de ML portátiles y escalables de un extremo a otro para ejecutar condicionalmente capacitación distribuida en Kubernetes mediante la capacitación de Kubeflow o SageMaker en función del parámetro de tiempo de ejecución.
El entrenamiento de Kubeflow es un grupo de operadores de Kubernetes que agregan a Kubeflow el soporte para el entrenamiento distribuido de modelos ML utilizando diferentes marcos como TensorFlow, PyTorch y otros. pytorch-operator es la implementación de Kubeflow de Kubernetes recurso personalizado (PyTorchJob) para ejecutar trabajos de entrenamiento de PyTorch distribuidos en Kubernetes.
Usamos el componente PyTorchJob Launcher como parte de la canalización de Kubeflow para ejecutar el entrenamiento distribuido de PyTorch durante la fase de experimentación cuando necesitamos flexibilidad y acceso a todos los recursos subyacentes para la depuración y el análisis interactivos.
También usamos componentes de SageMaker para Kubeflow Pipelines para ejecutar nuestra capacitación de modelos a escala de producción. Esto nos permite aprovechar las potentes funciones de SageMaker, como los servicios totalmente administrados, los trabajos de capacitación distribuidos con la máxima utilización de la GPU y la capacitación rentable a través de Nube informática elástica de Amazon (Amazon EC2) Instancias puntuales.
Como parte del proceso de creación del flujo de trabajo, complete los siguientes pasos (como se muestra en el diagrama anterior) para crear esta canalización:
- Utilice el archivo de manifiesto de Kubeflow para crear un panel de Kubeflow y acceder a los cuadernos de Jupyter desde el panel central de Kubeflow.
- Utilice el SDK de canalización de Kubeflow para crear y compilar canalizaciones de Kubeflow mediante código Python. La compilación de canalización convierte la función de Python en un recurso de flujo de trabajo, que es un formato YAML compatible con Argo.
- Use el cliente SDK de Kubeflow Pipelines para llamar al extremo del servicio de canalización para ejecutar la canalización.
- La canalización evalúa las variables de tiempo de ejecución condicionales y decide entre SageMaker o Kubernetes como entorno de ejecución de destino.
- Use el componente Kubeflow PyTorch Launcher para ejecutar la capacitación distribuida en el entorno nativo de Kubernetes o use el componente SageMaker para enviar la capacitación en la plataforma administrada de SageMaker.
La siguiente figura muestra los componentes de Kubeflow Pipelines involucrados en la arquitectura que nos brindan la flexibilidad de elegir entre entornos distribuidos de Kubernetes o SageMaker.

Flujo de trabajo de caso de uso
Usamos el siguiente enfoque paso a paso para instalar y ejecutar el caso de uso para la capacitación distribuida con Amazon EKS y SageMaker con Kubeflow en AWS.

Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
- An Cuenta de AWS.
- Una máquina con Docker y el Interfaz de línea de comandos de AWS (AWS CLI) instalado.
- Opcionalmente, puede utilizar Nube de AWS9, un entorno de desarrollo integrado (IDE) basado en la nube que permite completar todo el trabajo desde su navegador web. Para obtener instrucciones de configuración, consulte Configurar el IDE de Cloud9. Desde su entorno Cloud9, elija el signo más y abra una nueva terminal.
- Crear un rol con el nombre
sagemakerrole. Agregar políticas administradasAmazonSageMakerFullAccessyAmazonS3FullAccesspara otorgar a SageMaker acceso a depósitos de S3. Este rol lo utiliza el trabajo de SageMaker enviado como parte del paso de Kubeflow Pipelines. - Asegúrese de que su cuenta tenga un límite de tipo de recurso de capacitación de SageMaker para
ml.p3.2xlargeaumentó a 2 usando Consola de cuotas de servicio
1. Instale Amazon EKS y Kubeflow en AWS
Puede usar varios enfoques diferentes para crear un clúster de Kubernetes e implementar Kubeflow. En esta publicación, nos enfocamos en un enfoque que creemos que aporta simplicidad al proceso. Primero, creamos un clúster de EKS, luego implementamos Kubeflow en AWS v1.5 en él. Para cada una de estas tareas, utilizamos un proyecto de código abierto correspondiente que sigue los principios de la hacer marco. En lugar de instalar un conjunto de requisitos previos para cada tarea, construimos contenedores Docker que tienen todas las herramientas necesarias y realizan las tareas desde dentro de los contenedores.
Usamos Do Framework en esta publicación, que automatiza la implementación de Kubeflow con Amazon EFS como complemento. Para conocer las opciones de implementación oficiales de Kubeflow en AWS para implementaciones de producción, consulte Despliegue.
Configure el directorio de trabajo actual y la CLI de AWS
Configuramos un directorio de trabajo para que podamos referirnos a él como el punto de partida para los siguientes pasos:
También configuramos un perfil AWS CLI. Para ello, necesita un ID de clave de acceso y una clave de acceso secreta de un Gestión de identidades y accesos de AWS (YO SOY) usuario cuenta con privilegios administrativos (adjunte la política administrada existente) y acceso programático. Ver el siguiente código:
1.1 Crear un clúster de EKS
Si ya tiene un clúster de EKS disponible, puede pasar a la siguiente sección. Para esta publicación, usamos el proyecto aws-do-eks para crear nuestro clúster.
- Primero clone el proyecto en su directorio de trabajo
- Luego compila y ejecuta el
aws-do-eksenvase:La
build.shscript crea una imagen de contenedor de Docker que tiene todas las herramientas y scripts necesarios para el aprovisionamiento y el funcionamiento de los clústeres de EKS. losrun.shEl script inicia un contenedor usando la imagen de Docker creada y la mantiene, para que podamos usarla como nuestro entorno de administración de EKS. Para ver el estado de tuaws-do-ekscontenedor, puede ejecutar./status.sh. Si el contenedor está en estado Salido, puede usar el./start.shsecuencia de comandos para abrir el contenedor, o para reiniciar el contenedor, puede ejecutar./stop.shseguido por./run.sh. - Abrir una concha en la carrera
aws-do-eksenvase: - Para revisar la configuración del clúster de EKS para nuestra implementación de KubeFlow, ejecute el siguiente comando:
De forma predeterminada, esta configuración crea un clúster denominado
eks-kubeflowexistentesus-west-2Región con seis nodos m5.xlarge. Además, el cifrado de volúmenes de EBS no está habilitado de forma predeterminada. Puede habilitarlo agregando"volumeEncrypted: true"al grupo de nodos y se cifrará utilizando la clave predeterminada. Modifique otros ajustes de configuración si es necesario. - Para crear el clúster, ejecute el siguiente comando:
El proceso de aprovisionamiento del clúster puede tardar hasta 30 minutos.
- Para verificar que el clúster se creó correctamente, ejecute el siguiente comando:
El resultado del comando anterior para un clúster que se creó correctamente se parece al siguiente código:
Cree un volumen de EFS para el trabajo de capacitación de SageMaker
En este caso de uso, acelera el trabajo de entrenamiento de SageMaker entrenando modelos de aprendizaje profundo a partir de datos ya almacenados en Amazon EFS. Esta opción tiene la ventaja de iniciar directamente sus trabajos de capacitación desde los datos de Amazon EFS sin necesidad de movimiento de datos, lo que da como resultado tiempos de inicio de capacitación más rápidos.
Creamos un volumen EFS e implementamos el controlador EFS Container Storage Interface (CSI). Esto se logra mediante un script de implementación ubicado en /eks/deployment/csi/efs en la pestaña aws-do-eks recipiente.
Este script asume que tiene un clúster de EKS en su cuenta. Establecer CLUSTER_NAME= en caso de que tenga más de un clúster EKS.
Este script aprovisiona un volumen EFS y crea destinos de montaje para las subredes de la VPC del clúster. A continuación, implementa el controlador EFS CSI y crea el efs-sc clase de almacenamiento y efs-pv volumen persistente en el clúster de EKS.
Al completar con éxito el script, debería ver un resultado como el siguiente:
Crear un punto de enlace de la VPC de Amazon S3
Utiliza una VPC privada a la que tienen acceso su trabajo de capacitación de SageMaker y el sistema de archivos EFS. Para otorgar acceso al clúster de capacitación de SageMaker a los depósitos de S3 desde su VPC privada, cree un punto de enlace de la VPC:
Ahora puede salir de la aws-do-eks caparazón del contenedor y continúe con la siguiente sección:
1.2 Implementar Kubeflow en AWS en Amazon EKS
Para implementar Kubeflow en Amazon EKS, usamos el proyecto aws-do-kubeflow.
- Clona el repositorio usando los siguientes comandos:
- Luego configure el proyecto:
Este script abre el archivo de configuración del proyecto en un editor de texto. es importante para AWS_REGION establecerse en la región en la que se encuentra su clúster, así como AWS_CLUSTER_NOMBRE para que coincida con el nombre del clúster que creó anteriormente. De forma predeterminada, su configuración ya está establecida correctamente, por lo que si no necesita realizar ningún cambio, simplemente cierre el editor.
La
build.shEl script crea una imagen de contenedor de Docker que tiene todas las herramientas necesarias para implementar y administrar Kubeflow en un clúster de Kubernetes existente. losrun.shEl script inicia un contenedor, usando la imagen de Docker, y el script exec.sh abre un shell de comando en el contenedor, que podemos usar como nuestro entorno de administración de Kubeflow. Puedes usar el./status.shguión para ver si elaws-do-kubeflowel contenedor está funcionando y el./stop.shy./run.shscripts para reiniciarlo según sea necesario. - Después de haber abierto un caparazón en el
aws-do-ekscontenedor, puede verificar que el contexto del clúster configurado es el esperado: - Para implementar Kubeflow en el clúster de EKS, ejecute el
deploy.shscript:La implementación se realiza correctamente cuando todos los pods en el espacio de nombres de kubeflow ingresan al estado En ejecución. Una salida típica se parece al siguiente código:
- Para monitorear el estado de los pods de KubeFlow, en una ventana separada, puede usar el siguiente comando:
- Prensa Ctrl + C cuando todos los pods se estén ejecutando, exponga el panel de control de Kubeflow fuera del clúster ejecutando el siguiente comando:
Debería ver un resultado similar al siguiente código:
Este comando reenvía el servicio de puerta de enlace de entrada de Istio desde su clúster a su puerto local 8080. Para acceder al panel de control de Kubeflow, visite http://localhost:8080 e inicie sesión con las credenciales de usuario predeterminadas (user@example.com/12341234). Si está ejecutando el aws-do-kubeflow contenedor en AWS Cloud9, entonces puede elegir Vista previa, A continuación, elija Vista previa de la aplicación en ejecución. Si está ejecutando en Docker Desktop, es posible que deba ejecutar el ./kubeflow-expose.sh guión fuera de la aws-do-kubeflow recipiente.

2. Configure el entorno de Kubeflow en AWS
Para configurar su entorno Kubeflow en AWS, creamos un volumen EFS y un cuaderno Jupyter.
2.1 Crear un volumen EFS
Para crear un volumen EFS, complete los siguientes pasos:
- En el panel de control de Kubeflow, elija Volúmenes en el panel de navegación.
- Elija Nuevo volumen.
- Nombre, introduzca
efs-sc-claim. - Tamaño del volumen, introduzca
10. - Clase de almacenamiento, escoger efs-sc.
- Modo de acceso, escoger LecturaEscrituraOnce.
- Elige Crear.

2.2 Crear un cuaderno Jupyter
Para crear un nuevo cuaderno, complete los siguientes pasos:
- En el panel de control de Kubeflow, elija Cuadernos en el panel de navegación.
- Elige cuaderno nuevo.
- Nombre, introduzca
aws-hybrid-nb. - Imagen del expediente de Jupyter, elige la imagen
c9e4w0g3/notebook-servers/jupyter-pytorch:1.11.0-cpu-py38-ubuntu20.04-e3-v1.1(la última imagen DLC de jupyter-pytorch disponible). - CPU, introduzca
1. - Salud Cerebral, introduzca
5. - GPU, dejar como Ninguna.
- No realice ningún cambio en el Volumen del espacio de trabajo .
- En Volúmenes de datos sección, elija Adjuntar volumen existente y expanda la sección Volumen existente
- Nombre, escoger
efs-sc-claim. - ruta de montaje, introduzca
/home/jovyan/efs-sc-claim.
Esto monta el volumen EFS en su pod de notebook Jupyter y puede ver la carpetaefs-sc-claimen su interfaz de laboratorio de Jupyter. Guarde el conjunto de datos de entrenamiento y el código de entrenamiento en esta carpeta para que los clústeres de entrenamiento puedan acceder a él sin necesidad de reconstruir las imágenes del contenedor para la prueba.
- Seleccione Permitir el acceso a las canalizaciones de Kubeflow en la sección Configuración.
- Elige Más información.
Verifique que su cuaderno se haya creado correctamente (puede tardar un par de minutos).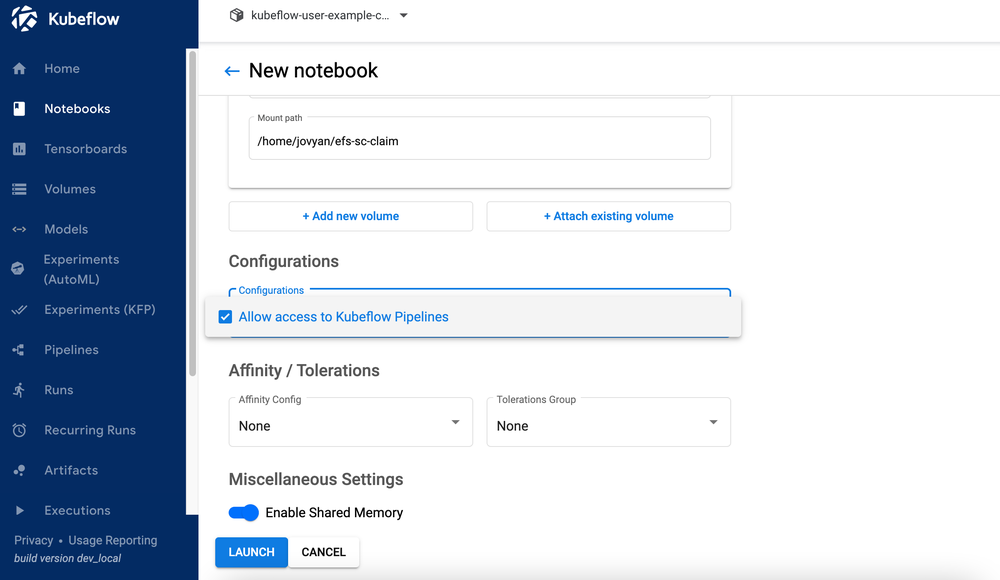
- En Cuadernos página, elige Contacto para iniciar sesión en el entorno de JupyterLab.
- En Git menú, seleccione Clonar un repositorio.
- Clonar un repositorio, introduzca
https://github.com/aws-samples/aws-do-kubeflow.
3. Ejecutar entrenamiento distribuido
Después de configurar el cuaderno Jupyter, puede ejecutar la demostración completa siguiendo los siguientes pasos de alto nivel desde la carpeta aws-do-kubeflow/workshop en el repositorio clonado:
- Script de entrenamiento de PyTorch Distributed Data Parallel (DDP): Consulte el script de entrenamiento PyTorch DDP cifar10-distributed-gpu-final.py, que incluye una red neuronal convolucional de muestra y lógica para distribuir el entrenamiento en un clúster de CPU y GPU de varios nodos. (Consulte 3.1 para más detalles)
- Instalar bibliotecas: ejecutar el cuaderno
0_initialize_dependencies.ipynbpara inicializar todas las dependencias. (Consulte 3.2 para más detalles) - Ejecute la capacitación laboral distribuida de PyTorch en Kubernetes: ejecutar el cuaderno
1_submit_pytorchdist_k8s.ipynbpara crear y enviar capacitación distribuida en un contenedor principal y dos trabajadores mediante el archivo PyTorchJob YAML de recursos personalizados de Kubernetes mediante el código de Python. (Consulte 3.3 para más detalles) - Cree una canalización híbrida de Kubeflow: ejecutar el cuaderno
2_create_pipeline_k8s_sagemaker.ipynbpara crear la canalización híbrida de Kubeflow que ejecuta la capacitación distribuida en SageMaker o Amazon EKS mediante la variable de tiempo de ejecucióntraining_runtime. (Consulte 3.4 para más detalles)
Asegúrate de ejecutar el cuaderno 1_submit_pytorchdist_k8s.ipynb antes de empezar cuaderno 2_create_pipeline_k8s_sagemaker.ipynb.
En las secciones siguientes, analizamos cada uno de estos pasos en detalle.
3.1 Script de entrenamiento PyTorch Distributed Data Parallel (DDP)
Como parte del entrenamiento distribuido, entrenamos un modelo de clasificación creado por una red neuronal convolucional simple que opera en el conjunto de datos CIFAR10. El guion de entrenamiento cifar10-distributed-gpu-final.py contiene solo las bibliotecas de código abierto y es compatible para ejecutarse en clústeres de capacitación de Kubernetes y SageMaker en dispositivos GPU o instancias de CPU. Veamos algunos aspectos importantes del script de entrenamiento antes de ejecutar los ejemplos de nuestro cuaderno.
Usamos la torch.distributed módulo, que contiene compatibilidad con PyTorch y primitivas de comunicación para el paralelismo multiproceso entre los nodos del clúster:
Creamos un modelo de clasificación de imágenes simple utilizando una combinación de capas convolucionales, de agrupación máxima y lineales a las que se aplica una función de activación de relu en el paso hacia adelante del entrenamiento del modelo:
Usamos la antorcha DataLoader que combina el conjunto de datos y DistributedSampler (carga un subconjunto de datos de manera distribuida utilizando torch.nn.parallel.DistributedDataParallel) y proporciona un iterador de proceso único o multiproceso sobre los datos:
Si el clúster de entrenamiento tiene GPU, el script ejecuta el entrenamiento en dispositivos CUDA y la variable del dispositivo contiene el dispositivo CUDA predeterminado:
Antes de ejecutar el entrenamiento distribuido con PyTorch DistributedDataParallel para ejecutar el procesamiento distribuido en varios nodos, debe inicializar el entorno distribuido llamando init_process_group. Esto se inicializa en cada máquina del clúster de entrenamiento.
Creamos una instancia del modelo clasificador y copiamos el modelo en el dispositivo de destino. Si el entrenamiento distribuido está habilitado para ejecutarse en múltiples nodos, el DistributedDataParallel La clase se usa como un objeto contenedor alrededor del objeto modelo, lo que permite un entrenamiento distribuido síncrono en varias máquinas. Los datos de entrada se dividen en la dimensión del lote y se coloca una réplica del modelo en cada máquina y cada dispositivo.
3.2 Instalar bibliotecas
Instalará todas las bibliotecas necesarias para ejecutar el ejemplo de capacitación distribuida de PyTorch. Esto incluye Kubeflow Pipelines SDK, Training Operator Python SDK, cliente de Python para Kubernetes y Amazon SageMaker Python SDK.
3.3 Ejecute la capacitación laboral distribuida de PyTorch en Kubernetes
El cuaderno 1_submit_pytorchdist_k8s.ipynb crea el archivo PyTorchJob YAML del recurso personalizado de Kubernetes mediante el entrenamiento de Kubeflow y el SDK de Python del cliente de Kubernetes. Los siguientes son algunos fragmentos importantes de este cuaderno.
Creamos PyTorchJob YAML con los contenedores principal y trabajador como se muestra en el siguiente código:
Esto se envía al plano de control de Kubernetes mediante PyTorchJobClient:
Ver los registros de entrenamiento de Kubernetes
Puede ver los registros de entrenamiento desde el mismo cuaderno de Jupyter con el código de Python o desde el shell del cliente de Kubernetes.
3.4 Crear una canalización híbrida de Kubeflow
El cuaderno 2_create_pipeline_k8s_sagemaker.ipynb crea una canalización híbrida de Kubeflow basada en una variable de tiempo de ejecución condicional training_runtime, como se muestra en el código siguiente. El cuaderno utiliza el SDK de Kubeflow Pipelines y se proporciona un conjunto de paquetes de Python para especificar y ejecutar las canalizaciones de flujo de trabajo de ML. Como parte de este SDK, usamos los siguientes paquetes:
- El decorador de paquetes de idioma específico del dominio (DSL)
dsl.pipeline, que decora las funciones de Python para devolver una canalización - La
dsl.Conditionpaquete, que representa un grupo de operaciones que solo se ejecutan cuando se cumple una determinada condición, como comprobar eltraining_runtimevalor comosagemakerorkubernetes
Ver el siguiente código:
Configuramos el entrenamiento distribuido de SageMaker usando dos instancias ml.p3.2xlarge.
Una vez definida la canalización, puede compilar la canalización en una especificación YAML de Argo mediante los SDK de canalizaciones de Kubeflow. kfp.compiler paquete. Puede ejecutar esta canalización con el cliente Kubeflow Pipeline SDK, que llama al extremo del servicio Pipelines y pasa los encabezados de autenticación apropiados directamente desde el cuaderno. Ver el siguiente código:
Si obtienes un sagemaker import error, ejecute !pip install sagemaker y reinicie el kernel (en el Núcleo menú, seleccione Reiniciar núcleo).
Elija el Ejecutar detalles enlace debajo de la última celda para ver la canalización de Kubeflow.
Repita el paso de creación de canalización con training_runtime='kubernetes' para probar la ejecución de la canalización en un entorno de Kubernetes. los training_runtime La variable también se puede pasar en su canalización de CI/CD en un escenario de producción.
Ver los registros de ejecución de la canalización de Kubeflow para el componente de SageMaker
La siguiente captura de pantalla muestra los detalles de nuestra canalización para el componente SageMaker.

Elija el paso del trabajo de entrenamiento y en el Troncos pestaña, elija el enlace de registros de CloudWatch para acceder a los registros de SageMaker.

La siguiente captura de pantalla muestra los registros de CloudWatch para cada una de las dos instancias ml.p3.2xlarge.

Elija cualquiera de los grupos para ver los registros.

Ver los registros de ejecución de la canalización de Kubeflow para el componente Kubeflow PyTorchJob Launcher
La siguiente captura de pantalla muestra los detalles de la tubería para nuestro componente Kubeflow.

Ejecute los siguientes comandos usando Kubectl en su shell de cliente de Kubernetes conectado al clúster de Kubernetes para ver los registros (sustituya su espacio de nombres y los nombres de los pods):
4.1 Limpiar
Para limpiar todos los recursos que creamos en la cuenta, debemos eliminarlos en orden inverso.
- Elimine la instalación de Kubeflow ejecutando
./kubeflow-remove.shexistentesaws-do-kubeflowenvase. El primer conjunto de comandos es opcional y se puede usar en caso de que aún no tenga un shell de comandos en suaws-do-kubeflowcontenedor abierto. - Desde el
aws-do-ekscarpeta contenedora, elimine el volumen EFS. El primer conjunto de comandos es opcional y se puede usar en caso de que aún no tenga un shell de comandos en suaws-do-ekscontenedor abierto.Es necesario eliminar Amazon EFS para liberar la interfaz de red asociada con la VPC que creamos para nuestro clúster. Tenga en cuenta que al eliminar el volumen EFS se destruyen todos los datos almacenados en él.
- Desde el
aws-do-ekscontenedor, ejecute eleks-delete.shsecuencia de comandos para eliminar el clúster y cualquier otro recurso asociado con él, incluida la VPC:
Resumen
En esta publicación, discutimos algunos de los desafíos típicos del entrenamiento de modelos distribuidos y los flujos de trabajo de ML. Brindamos una descripción general de la distribución de Kubeflow en AWS y compartimos dos proyectos de código abierto (aws-do-eks y aws-do-kubeflow) que simplifican el aprovisionamiento de la infraestructura y la implementación de Kubeflow en ella. Finalmente, describimos y demostramos una arquitectura híbrida que permite que las cargas de trabajo realicen una transición fluida entre la ejecución en una infraestructura de Kubernetes autogestionada y una infraestructura de SageMaker totalmente gestionada. Le recomendamos que utilice esta arquitectura híbrida para sus propios casos de uso.
Puede seguir el Repositorio de laboratorios de AWS para realizar un seguimiento de todas las contribuciones de AWS a Kubeflow. También puede encontrarnos en el Kubeflow #AWS Canal flojo; sus comentarios allí nos ayudarán a priorizar las próximas funciones para contribuir al proyecto Kubeflow.
Un agradecimiento especial a Sree Arasanagatta (Gerente de desarrollo de software AWS ML) y Suraj Kota (Ingeniero de desarrollo de software) por su apoyo en el lanzamiento de esta publicación.
Sobre los autores
 Kanwaljit Khurmi es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services. Trabaja con el producto, la ingeniería y los clientes de AWS para brindar orientación y asistencia técnica, ayudándolos a mejorar el valor de sus soluciones híbridas de aprendizaje automático cuando usan AWS. Kanwaljit se especializa en ayudar a los clientes con aplicaciones de aprendizaje automático y en contenedores.
Kanwaljit Khurmi es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services. Trabaja con el producto, la ingeniería y los clientes de AWS para brindar orientación y asistencia técnica, ayudándolos a mejorar el valor de sus soluciones híbridas de aprendizaje automático cuando usan AWS. Kanwaljit se especializa en ayudar a los clientes con aplicaciones de aprendizaje automático y en contenedores.
 Gautama Kumar es ingeniero de software con AWS AI Deep Learning. Ha desarrollado AWS Deep Learning Containers y AWS Deep Learning AMI. Le apasiona construir herramientas y sistemas para IA. En su tiempo libre, disfruta andar en bicicleta y leer libros.
Gautama Kumar es ingeniero de software con AWS AI Deep Learning. Ha desarrollado AWS Deep Learning Containers y AWS Deep Learning AMI. Le apasiona construir herramientas y sistemas para IA. En su tiempo libre, disfruta andar en bicicleta y leer libros.
 Alex Iankoulski es un arquitecto de software e infraestructura de pila completa al que le gusta hacer un trabajo profundo y práctico. Actualmente es arquitecto principal de soluciones para el aprendizaje automático autogestionado en AWS. En su función, se enfoca en ayudar a los clientes con la creación de contenedores y la orquestación de cargas de trabajo de ML e IA en servicios de AWS impulsados por contenedores. También es el autor del código abierto. hacer marco y un capitán de Docker al que le encanta aplicar tecnologías de contenedores para acelerar el ritmo de la innovación mientras resuelve los mayores desafíos del mundo. Durante los últimos 10 años, Alex ha trabajado para combatir el cambio climático, democratizar la IA y el ML, hacer que los viajes sean más seguros, que la atención médica sea mejor y que la energía sea más inteligente.
Alex Iankoulski es un arquitecto de software e infraestructura de pila completa al que le gusta hacer un trabajo profundo y práctico. Actualmente es arquitecto principal de soluciones para el aprendizaje automático autogestionado en AWS. En su función, se enfoca en ayudar a los clientes con la creación de contenedores y la orquestación de cargas de trabajo de ML e IA en servicios de AWS impulsados por contenedores. También es el autor del código abierto. hacer marco y un capitán de Docker al que le encanta aplicar tecnologías de contenedores para acelerar el ritmo de la innovación mientras resuelve los mayores desafíos del mundo. Durante los últimos 10 años, Alex ha trabajado para combatir el cambio climático, democratizar la IA y el ML, hacer que los viajes sean más seguros, que la atención médica sea mejor y que la energía sea más inteligente.

