Sumérgete en el aprendizaje profundo (D2L.ai) es un libro de texto de código abierto que hace que el aprendizaje profundo sea accesible para todos. Cuenta con cuadernos Jupyter interactivos con código autónomo en PyTorch, JAX, TensorFlow y MXNet, así como ejemplos del mundo real, figuras de exposición y matemáticas. Hasta el momento, D2L ha sido adoptado por más de 400 universidades de todo el mundo, como la Universidad de Cambridge, la Universidad de Stanford, el Instituto de Tecnología de Massachusetts, la Universidad Carnegie Mellon y la Universidad de Tsinghua. Este trabajo también está disponible en chino, japonés, coreano, portugués, turco y vietnamita, con planes de lanzamiento en español y otros idiomas.
Es un esfuerzo desafiante tener un libro en línea que se mantenga actualizado continuamente, escrito por varios autores y disponible en varios idiomas. En esta publicación, presentamos una solución que D2L.ai usó para abordar este desafío mediante el uso de Función de traducción personalizada activa (ACT) of Traductor de Amazon y la creación de un canal de traducción automática multilingüe.
Demostramos cómo usar el Consola de administración de AWS y API pública de Amazon Translate para ofrecer traducción automática por lotes y analizar las traducciones entre dos pares de idiomas: inglés y chino, e inglés y español. También recomendamos las mejores prácticas al usar Amazon Translate en esta canalización de traducción automática para garantizar la calidad y la eficiencia de la traducción.
Resumen de la solución
Creamos canalizaciones de traducción automática para varios idiomas utilizando la función ACT en Amazon Translate. ACT le permite personalizar la salida de traducción sobre la marcha al proporcionar ejemplos de traducción personalizados en forma de datos paralelos. Los datos paralelos consisten en una colección de ejemplos textuales en un idioma de origen y las traducciones deseadas en uno o más idiomas de destino. Durante la traducción, ACT selecciona automáticamente los segmentos más relevantes de los datos paralelos y actualiza el modelo de traducción sobre la marcha en función de esos pares de segmentos. Esto da como resultado traducciones que se adaptan mejor al estilo y contenido de los datos paralelos.
La arquitectura contiene múltiples canalizaciones secundarias; cada canal secundario maneja la traducción de un idioma, como inglés a chino, inglés a español, etc. Se pueden procesar múltiples subcanales de traducción en paralelo. En cada canal secundario, primero construimos los datos paralelos en Amazon Translate utilizando el conjunto de datos de alta calidad de ejemplos de traducción continua de los libros D2L traducidos por personas. Luego, generamos la salida de traducción automática personalizada sobre la marcha en tiempo de ejecución, lo que logra una mejor calidad y precisión.
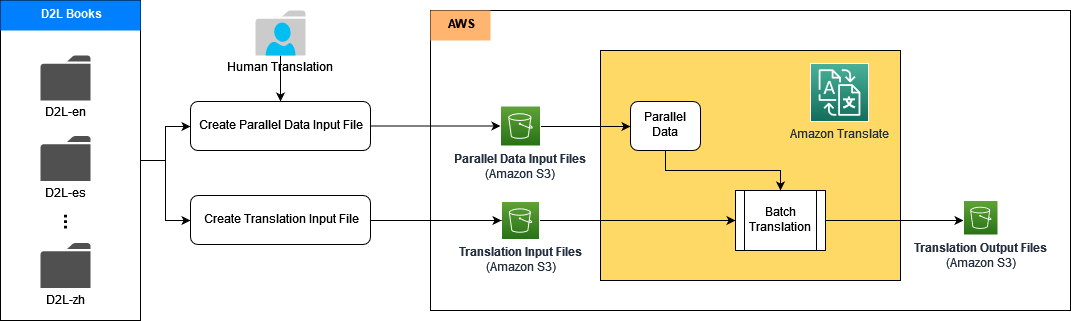
En las siguientes secciones, demostramos cómo crear cada canal de traducción utilizando Amazon Translate con ACT, junto con Amazon SageMaker y Servicio de almacenamiento simple de Amazon (Amazon S3).
Primero, colocamos los documentos de origen, los documentos de referencia y el conjunto de entrenamiento de datos paralelos en un depósito S3. Luego creamos cuadernos Jupyter en SageMaker para ejecutar el proceso de traducción mediante las API públicas de Amazon Translate.
Requisitos previos
Para seguir los pasos de esta publicación, asegúrese de tener una cuenta de AWS con lo siguiente:
- El acceso a Gestión de identidades y accesos de AWS (IAM) para la configuración de roles y políticas
- Acceso a Amazon Translate, SageMaker y Amazon S3
- Un depósito de S3 para almacenar los documentos de origen, los documentos de referencia, el conjunto de datos de datos paralelos y la salida de la traducción
Cree un rol y políticas de IAM para Amazon Translate con ACT
Nuestro rol de IAM debe contener una política de confianza personalizada para Amazon Translate:
Este rol también debe tener una política de permisos que otorgue a Amazon Translate acceso de lectura a la carpeta y subcarpetas de entrada en Amazon S3 que contienen los documentos de origen, y acceso de lectura/escritura a la carpeta y el depósito de S3 de salida que contiene los documentos traducidos:
Para ejecutar cuadernos de Jupyter en SageMaker para los trabajos de traducción, debemos otorgar una política de permisos en línea a la función de ejecución de SageMaker. Este rol pasa el rol de servicio de Amazon Translate a SageMaker, lo que permite que los cuadernos de SageMaker tengan acceso a los documentos de origen y traducidos en los depósitos de S3 designados:
Preparar muestras de entrenamiento de datos paralelos
Los datos paralelos en ACT deben ser entrenados por un archivo de entrada que consta de una lista de pares de ejemplos textuales, por ejemplo, un par de idioma de origen (inglés) y el idioma de destino (chino). El archivo de entrada puede estar en formato TMX, CSV o TSV. La siguiente captura de pantalla muestra un ejemplo de un archivo de entrada CSV. La primera columna son los datos del idioma de origen (en inglés) y la segunda columna son los datos del idioma de destino (en chino). El siguiente ejemplo se extrae del libro D2L-en y del libro D2L-zh.

Realice un entrenamiento de datos paralelos personalizado en Amazon Translate
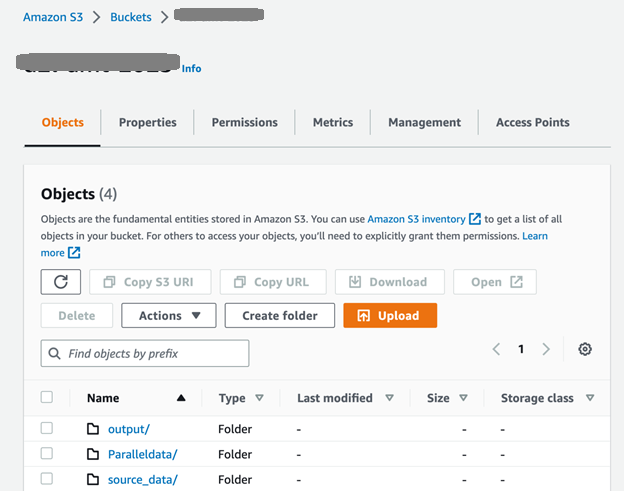
Primero, configuramos el depósito y las carpetas de S3 como se muestra en la siguiente captura de pantalla. El source_data la carpeta contiene los documentos originales antes de la traducción; los documentos generados después de la traducción por lotes se colocan en la carpeta de salida. El ParallelData La carpeta contiene el archivo de entrada de datos paralelos preparado en el paso anterior.
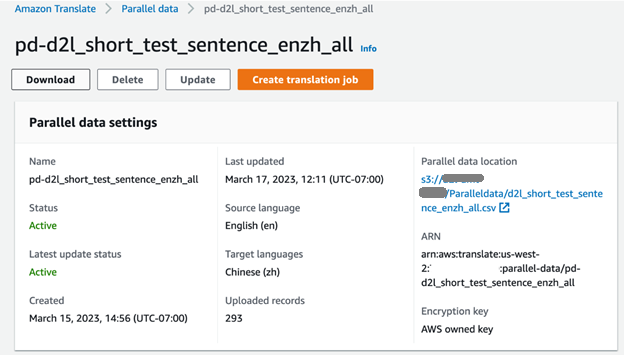
Después de cargar los archivos de entrada al source_data carpeta, podemos usar la API CreateParallelData para ejecutar un trabajo de creación de datos en paralelo en Amazon Translate:
Para actualizar los datos paralelos existentes con nuevos conjuntos de datos de entrenamiento, podemos usar el Actualizar API de datos paralelos:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
Podemos verificar el progreso del trabajo de capacitación en la consola de Amazon Translate. Cuando se completa el trabajo, el estado de los datos paralelos se muestra como Active y está listo para usar.
Ejecute la traducción por lotes asíncrona utilizando datos paralelos
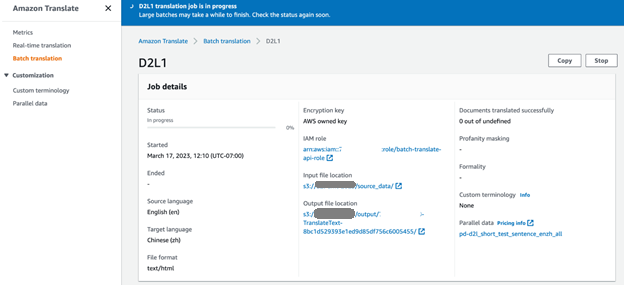
La traducción por lotes se puede realizar en un proceso en el que varios documentos de origen se traducen automáticamente a documentos en los idiomas de destino. El proceso consiste en cargar los documentos de origen en la carpeta de entrada del depósito S3 y luego aplicar el API StartTextTranslationJob de Amazon Translate para iniciar un trabajo de traducción asíncrono:
Seleccionamos cinco documentos fuente en inglés del libro D2L (D2L-en) para la traducción masiva. En la consola de Amazon Translate, podemos monitorear el progreso del trabajo de traducción. Cuando el estado del trabajo cambia a Completado, podemos encontrar los documentos traducidos en chino (D2L-zh) en la carpeta de salida del depósito S3.
Evaluar la calidad de la traducción
Para demostrar la eficacia de la función ACT en Amazon Translate, también aplicamos el método tradicional de traducción en tiempo real de Amazon Translate sin datos paralelos para procesar los mismos documentos y comparamos la salida con la salida de traducción por lotes con ACT. Usamos el puntaje BLEU (suplente de evaluación bilingüe) para comparar la calidad de la traducción entre los dos métodos. La única forma de medir con precisión la calidad de la traducción automática es hacer que un experto revise y califique la calidad. Sin embargo, BLEU proporciona una estimación de la mejora relativa de la calidad entre dos resultados. Una puntuación BLEU suele ser un número entre 0 y 1; calcula la similitud de la traducción automática con la traducción humana de referencia. La puntuación más alta representa una mejor calidad en la comprensión del lenguaje natural (NLU).
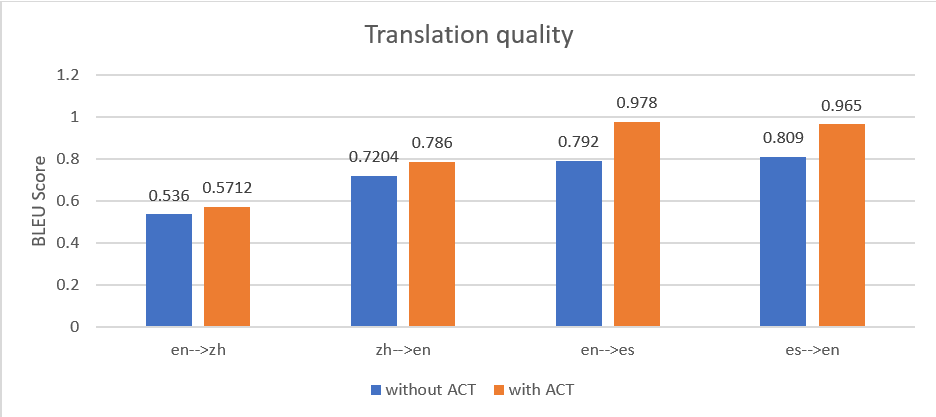
Hemos probado un conjunto de documentos en cuatro canalizaciones: inglés a chino (en a zh), chino a inglés (zh a en), inglés a español (en a es) y español a inglés (es a en). La siguiente figura muestra que la traducción con ACT produjo un puntaje BLEU promedio más alto en todas las canalizaciones de traducción.
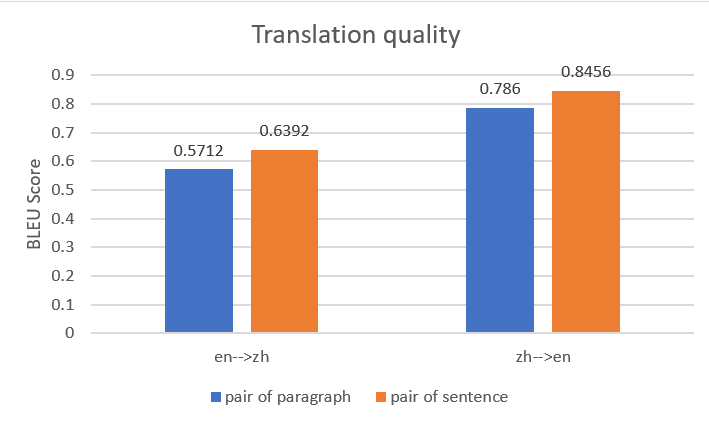
También observamos que, cuanto más granulares son los pares de datos paralelos, mejor es el rendimiento de la traducción. Por ejemplo, usamos el siguiente archivo de entrada de datos paralelos con pares de párrafos, que contiene 10 entradas.

Para el mismo contenido, usamos el siguiente archivo de entrada de datos en paralelo con pares de oraciones y 16 entradas.

Usamos ambos archivos de entrada de datos paralelos para construir dos entidades de datos paralelos en Amazon Translate, luego creamos dos trabajos de traducción por lotes con el mismo documento de origen. La siguiente figura compara las traducciones de salida. Muestra que la salida que usa datos paralelos con pares de oraciones superó a la que usa datos paralelos con pares de párrafos, tanto para la traducción del inglés al chino como para la traducción del chino al inglés.
Si está interesado en obtener más información sobre estos análisis de referencia, consulte Traducción automática automática y sincronización para "Dive into Deep Learning".
Limpiar
Para evitar costos recurrentes en el futuro, le recomendamos que limpie los recursos que creó:
- En la consola de Amazon Translate, seleccione los datos paralelos que creó y elija Borrar. Alternativamente, puede utilizar el API DeleteParallelData o de Interfaz de línea de comandos de AWS (CLI de AWS) borrar-datos-paralelos comando para eliminar los datos paralelos.
- Eliminar el cubo S3 se utiliza para alojar los documentos fuente y de referencia, los documentos traducidos y los archivos de entrada de datos paralelos.
- Elimine el rol y la política de IAM. Para obtener instrucciones, consulte Eliminación de roles o perfiles de instancia y Eliminación de políticas de IAM.
Conclusión
Con esta solución, nuestro objetivo es reducir la carga de trabajo de los traductores humanos en un 80 %, manteniendo la calidad de la traducción y admitiendo varios idiomas. Puede utilizar esta solución para mejorar la calidad y la eficiencia de su traducción. Estamos trabajando para mejorar aún más la arquitectura de la solución y la calidad de la traducción para otros idiomas.
Sus comentarios son siempre bienvenidos; por favor deje sus pensamientos y preguntas en la sección de comentarios.
Sobre los autores
 Yunfeibai es arquitecto sénior de soluciones en AWS. Con experiencia en IA/ML, ciencia de datos y análisis, Yunfei ayuda a los clientes a adoptar los servicios de AWS para obtener resultados comerciales. Diseña soluciones de análisis de datos y AI/ML que superan desafíos técnicos complejos e impulsan objetivos estratégicos. Yunfei tiene un doctorado en Ingeniería Electrónica y Eléctrica. Fuera del trabajo, Yunfei disfruta de la lectura y la música.
Yunfeibai es arquitecto sénior de soluciones en AWS. Con experiencia en IA/ML, ciencia de datos y análisis, Yunfei ayuda a los clientes a adoptar los servicios de AWS para obtener resultados comerciales. Diseña soluciones de análisis de datos y AI/ML que superan desafíos técnicos complejos e impulsan objetivos estratégicos. Yunfei tiene un doctorado en Ingeniería Electrónica y Eléctrica. Fuera del trabajo, Yunfei disfruta de la lectura y la música.
 raquel hu es científico aplicado en AWS Machine Learning University (MLU). Ha estado dirigiendo algunos diseños de cursos, incluidos ML Operations (MLOps) y Accelerator Computer Vision. Rachel es oradora sénior de AWS y ha hablado en las principales conferencias, incluidas AWS re:Invent, NVIDIA GTC, KDD y MLOps Summit. Antes de unirse a AWS, Rachel trabajó como ingeniera de aprendizaje automático creando modelos de procesamiento de lenguaje natural. Fuera del trabajo, disfruta del yoga, el ultimate frisbee, la lectura y los viajes.
raquel hu es científico aplicado en AWS Machine Learning University (MLU). Ha estado dirigiendo algunos diseños de cursos, incluidos ML Operations (MLOps) y Accelerator Computer Vision. Rachel es oradora sénior de AWS y ha hablado en las principales conferencias, incluidas AWS re:Invent, NVIDIA GTC, KDD y MLOps Summit. Antes de unirse a AWS, Rachel trabajó como ingeniera de aprendizaje automático creando modelos de procesamiento de lenguaje natural. Fuera del trabajo, disfruta del yoga, el ultimate frisbee, la lectura y los viajes.
 watson srivathsan es el director de producto principal de Amazon Translate, el servicio de procesamiento de lenguaje natural de AWS. Los fines de semana, lo encontrarás explorando el aire libre en el noroeste del Pacífico.
watson srivathsan es el director de producto principal de Amazon Translate, el servicio de procesamiento de lenguaje natural de AWS. Los fines de semana, lo encontrarás explorando el aire libre en el noroeste del Pacífico.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

