Introducción
La recuperación de generación aumentada ha estado aquí por un tiempo. Se están creando muchas herramientas y aplicaciones en torno a este concepto, como almacenes de vectores, marcos de recuperación y LLM, lo que hace que sea conveniente trabajar con documentos personalizados, especialmente datos semiestructurados con Langchain. Trabajar con textos largos y densos nunca ha sido tan fácil y divertido. lo convencional RAG funciona bien con archivos con mucho texto no estructurado como DOC, PDF, etc. Sin embargo, este enfoque no funciona bien con datos semiestructurados, como tablas incrustadas en archivos PDF.
Al trabajar con datos semiestructurados, suelen surgir dos preocupaciones.
- Los métodos convencionales de extracción y división de texto no tienen en cuenta las tablas en archivos PDF. Suelen acabar rompiendo las mesas. Por lo tanto, se produce una pérdida de información.
- Es posible que la inserción de tablas no se traduzca en una búsqueda semántica precisa.
Entonces, en este artículo, construiremos un canal de generación de recuperación para datos semiestructurados con Langchain para abordar estas dos preocupaciones con los datos semiestructurados.
OBJETIVOS DE APRENDIZAJE
- Comprenda la diferencia entre datos estructurados, no estructurados y semiestructurados.
- Un ligero repaso sobre Retrieval Augement Generation y Langchain.
- Aprenda a crear un recuperador de vectores múltiples para manejar datos semiestructurados con Langchain.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Tipos de datos
Generalmente hay tres tipos de datos. Estructurados, Semiestructurados y No Estructurados.
- Datos estructurados: Los datos estructurados son los datos estandarizados. Los datos siguen un esquema predefinido, como filas y columnas. Bases de datos SQL, Hojas de cálculo, marcos de datos, etc.
- Datos no estructurados: Los datos no estructurados, a diferencia de los datos estructurados, no siguen ningún modelo de datos. Los datos son lo más aleatorios posible. Por ejemplo, archivos PDF, textos, imágenes, etc.
- Datos semiestructurados: Es la combinación de los tipos de datos anteriores. A diferencia de los datos estructurados, no tiene un esquema rígido predefinido. Sin embargo, los datos aún mantienen un orden jerárquico basado en algunos marcadores, lo que contrasta con los tipos no estructurados. Por ejemplo, CSV, HTML, tablas incrustadas en PDF, XML, etc.

¿Qué es RAG?
RAG significa Generación aumentada de recuperación. Es la forma más sencilla de alimentar los modelos de lenguaje grande con información novedosa. Entonces, veamos una introducción rápida a RAG.
En una canalización RAG típica, tenemos fuentes de conocimiento, como archivos locales, páginas web, bases de datos, etc., un modelo de integración, una base de datos vectorial y un LLM. Recopilamos los datos de varias fuentes, dividimos los documentos, obtenemos incrustaciones de fragmentos de texto y los almacenamos en una base de datos vectorial. Ahora, pasamos las incorporaciones de consultas al almacén de vectores, recuperamos los documentos del almacén de vectores y finalmente generamos respuestas con el LLM.
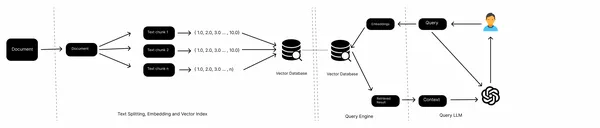
Este es un flujo de trabajo de un RAG convencional y funciona bien con datos no estructurados como textos. Sin embargo, cuando se trata de datos semiestructurados, por ejemplo, tablas incrustadas en un PDF, a menudo no funciona bien. En este artículo, aprenderemos cómo manejar estas tablas incrustadas.
¿Qué es Langchain?
Langchain es un marco de código abierto para crear aplicaciones basadas en LLM. Desde su lanzamiento, el proyecto ha obtenido una amplia adopción entre los desarrolladores de software. Proporciona una gama unificada de herramientas y tecnologías para crear aplicaciones de IA más rápidamente. Langchain alberga herramientas como almacenes de vectores, cargadores de documentos, recuperadores, modelos de incrustación, divisores de texto, etc. Es una solución integral para crear aplicaciones de IA. Pero hay dos propuestas de valor fundamentales que lo distinguen.
- cadenas de llm: Langchain proporciona múltiples cadenas. Estas cadenas encadenan varias herramientas para realizar una sola tarea. Por ejemplo, ConversationalRetrievalChain encadena un LLM, un recuperador de tienda Vector, un modelo de incrustación y un objeto de historial de chat para generar respuestas a una consulta. Las herramientas están codificadas y deben definirse explícitamente.
- Agentes de Maestría en Derecho: A diferencia de las cadenas LLM, los agentes de IA no tienen herramientas codificadas. En lugar de encadenar una herramienta tras otra, dejamos que el LLM decida cuál seleccionar y cuándo en función de las descripciones textuales de las herramientas. Esto lo hace ideal para crear aplicaciones LLM complejas que impliquen razonamiento y toma de decisiones.
Construyendo el oleoducto RAG
Ahora que tenemos una introducción a los conceptos. Analicemos el enfoque para construir el oleoducto. Trabajar con datos semiestructurados puede resultar complicado ya que no siguen un esquema convencional para almacenar información. Y para trabajar con datos no estructurados, necesitamos herramientas especializadas hechas a medida para extraer información. Entonces, en este proyecto usaremos una de esas herramientas llamada "no estructurada"; es una herramienta de código abierto para extraer información de diferentes formatos de datos no estructurados, como tablas en PDF, HTML, XML, etc. Unstructured utiliza Tesseract y Poppler internamente para procesar múltiples formatos de datos en archivos. Entonces, configuremos nuestro entorno e instalemos dependencias antes de sumergirnos en la parte de codificación.
Configurar el entorno de desarrollo
Como cualquier otro proyecto de Python, abra un entorno Python e instale Poppler y Tesseract.
!sudo apt install tesseract-ocr
!sudo apt-get install poppler-utilsAhora, instala las dependencias que necesitaremos en nuestro proyecto.
!pip install "unstructured[all-docs]" Langchain openaiAhora que hemos instalado las dependencias, extraeremos datos de un archivo PDF.
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf(
"mistral7b.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path="./"
)Ejecutarlo instalará varias dependencias como YOLOx que son necesarias para OCR y devolverá tipos de objetos basados en los datos extraídos. Habilitar extract_images_in_pdf permitirá extraer imágenes incrustadas de archivos de forma no estructurada. Esto puede ayudar a implementar soluciones multimodales.
Ahora, exploremos las categorías de elementos de nuestro PDF.
# Create a dictionary to store counts of each type
category_counts = {}
for element in pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
# Unique_categories will have unique elements
unique_categories = set(category_counts.keys())
category_countsAl ejecutar esto, se generarán categorías de elementos y su recuento.
Ahora, separamos los elementos para facilitar su manejo. Creamos un tipo de Elemento que hereda del tipo de Documento de Langchain. Esto es para garantizar datos más organizados, que sean más fáciles de manejar.
from unstructured.documents.elements import CompositeElement, Table
from langchain.schema import Document
class Element(Document):
type: str
# Categorize by type
categorized_elements = []
for element in pdf_elements:
if isinstance(element, Table):
categorized_elements.append(Element(type="table", page_content=str(element)))
elif isinstance(element, CompositeElement):
categorized_elements.append(Element(type="text", page_content=str(element)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
# Text
text_elements = [e for e in categorized_elements if e.type == "text"]Recuperador multivectorial
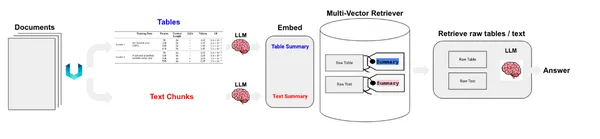
Disponemos de elementos de tabla y texto. Ahora, hay dos maneras en que podemos manejar esto. Podemos almacenar los elementos en bruto en un almacén de documentos o almacenar resúmenes de textos. Las tablas pueden plantear un desafío para la búsqueda semántica; en ese caso, creamos los resúmenes de tablas y los almacenamos en un almacén de documentos junto con las tablas sin formato. Para lograr esto, usaremos MultiVectorRetriever. Este recuperador gestionará un almacén de vectores donde almacenaremos las incrustaciones de textos resumidos y un almacén de documentos en memoria simple para almacenar documentos sin procesar.
Primero, cree una cadena de resumen para resumir la tabla y los datos de texto que extrajimos anteriormente.
from langchain.chat_models import cohere
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt_text = """You are an assistant tasked with summarizing tables and text.
Give a concise summary of the table or text. Table or text chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
model = cohere.ChatCohere(cohere_api_key="your_key")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
tables = [i.page_content for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
texts = [i.page_content for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})He utilizado Cohere LLM para resumir datos; puede utilizar modelos OpenAI como GPT-4. Mejores modelos producirán mejores resultados. A veces, es posible que los modelos no capturen perfectamente los detalles de la tabla. Por tanto, es mejor utilizar modelos capaces.
Ahora creamos el MultivectorRetriever.
from langchain.retrievers import MultiVectorRetriever
from langchain.prompts import ChatPromptTemplate
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="collection",
embedding_function=OpenAIEmbeddings(openai_api_key="api_key"))
# The storage layer for the parent documents
store = InMemoryStore()
id_key = ""id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Usamos el almacén de vectores Chroma para almacenar incrustaciones resumidas de textos y tablas y un almacén de documentos en memoria para almacenar datos sin procesar.
RAG
Ahora que nuestro recuperador está listo, podemos construir una canalización RAG utilizando Langchain Expression Language.
from langchain.schema.runnable import RunnablePassthrough
# Prompt template
template = """Answer the question based only on the following context,
which can include text and tables::
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature=0.0, openai_api_key="api_key")
# RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
Ahora podemos hacer preguntas y recibir respuestas basadas en incrustaciones recuperadas del almacén de vectores.
chain.invoke(input = "What is the MT bench score of Llama 2 and Mistral 7B Instruct??")Conclusión
Mucha información permanece oculta en formato de datos semiestructurados. Y resulta complicado extraer y realizar RAG convencional con estos datos. En este artículo, pasamos de extraer textos y tablas incrustadas en PDF a construir un recuperador multivectorial y un canal RAG con Langchain. Entonces, aquí están las conclusiones clave del artículo.
Puntos clave
- El RAG convencional a menudo enfrenta desafíos al tratar con datos semiestructurados, como dividir tablas durante la división del texto y búsquedas semánticas imprecisas.
- Unstructured, una herramienta de código abierto para datos semiestructurados, puede extraer tablas incrustadas de archivos PDF o datos semiestructurados similares.
- Con Langchain, podemos crear un recuperador de múltiples vectores para almacenar tablas, textos y resúmenes en almacenes de documentos para una mejor búsqueda semántica.
Preguntas frecuentes
R: Los datos semiestructurados, a diferencia de los datos estructurados, no tienen un esquema rígido pero tienen otras formas de marcadores para imponer jerarquías.
R. Ejemplos de datos semiestructurados son CSV, correos electrónicos, HTML, XML, archivos parquet, etc.
R. LangChain es un marco de código abierto que simplifica la creación de aplicaciones utilizando modelos de lenguaje grandes. Se puede utilizar para diversas tareas, incluidos chatbots, RAG, preguntas y respuestas y tareas generativas.
R. Una canalización RAG recupera documentos de almacenes de datos externos, los procesa para almacenarlos en una base de conocimiento y proporciona herramientas para consultarlos.
R. Llama Index diseña explícitamente aplicaciones de búsqueda y recuperación, mientras que Langchain ofrece flexibilidad para crear agentes de IA personalizados.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/12/building-a-rag-pipeline-for-semi-structured-data-with-langchain/

