
Foto por marqués thomas on Unsplash
El objetivo del proyecto es recrear parcialmente las Sistema de recomendación de productos de Amazon para Electrónica categoria de producto.
es noviembre y Black Friday ¡es aquí! que tipo de comprador eres? ¿Guarda todos los productos que le gustaría comprar para el día o prefiere abrir el sitio web y ver el ofertas en vivo con sus grandes descuentos?
Aunque las tiendas en línea han tenido un éxito increíble en la última década, mostrando un gran potencial y crecimiento, una de las diferencias fundamentales entre una tienda física y una en línea es la percepción de los consumidores. compras impulsivas.
Si a los clientes se les presenta una surtido de productos, es mucho más probable que compren un artículo que originalmente no planeaban comprar. El un fenómeno mundial of compras impulsivas es increiblemente limitado por la configuración de un en línea almacenar. Lo mismo No sucede para su los libros físicos contrapartes Las mayores cadenas de retail físico hacen pasar a sus clientes por un trayectoria precisa para asegurarse de que visiten todos los pasillos antes de salir de la tienda.
Una forma en que las tiendas en línea como Amazon pensaron que podrían recrear un fenómeno de compra impulsiva es a través de sistemas de recomendación. Los sistemas de recomendación identifican más similar or complementario productos que el cliente acaba de comprar o ver. La intención es maximizar la compras aleatorias fenómeno del que normalmente carecen las tiendas online.
Comprando en Amazon hizo que me interesara bastante la mecánica y quería recrear (incluso parcialmente) los resultados de su sistema de recomendación.
Según el blog “Recostream”, el sistema de recomendación de productos de Amazon ha tres tipos de dependencias, uno de ellos es recomendaciones de producto a producto. Cuando un usuario prácticamente no tiene historial de búsqueda, el algoritmo agrupa los productos y se los sugiere a ese mismo usuario en función de los metadatos de los elementos.
Los datos
El primer paso del proyecto es reunir a los datos. Afortunadamente, los investigadores del equipo de Manejo Integrado de Plagas de la Universidad de California en San Diego tiene un repositorio para permitir que los estudiantes y personas ajenas a la organización usen los datos para investigaciones y proyectos. Se puede acceder a los datos a través de los siguientes liga para cada año fiscal junto con la muchos otros conjuntos de datos interesantes relacionados con los sistemas de recomendación[2][3]. Los metadatos del producto fueron última actualización en 2014; muchos de los productos podrían no estar disponibles hoy.
Los metadatos de la categoría electrónica contienen Registros 498,196 y tiene 8 columnas en total:
asin— la identificación única asociada con cada productoimUrl— el enlace URL de la imagen asociada con cada productodescription— La descripción del productocategories- una lista de Python de todas las categorías en las que se incluye cada productotitle— el título del productoprice— el precio del productosalesRank— la clasificación de cada producto dentro de una categoría específicarelated— productos vistos y comprados por clientes relacionados con cada productobrand— la marca del producto.
Notará que el archivo está en un "suelto" JSON formato, donde cada línea es una JSON que contiene todas las columnas mencionadas anteriormente como uno de los campos. Veremos cómo lidiar con esto en la sección de implementación de código.
EDA
Comencemos con un análisis de datos exploratorio rápido. Después limpiando todos los registros que contenía al menos un NaN valor en una de las columnas, creé las visualizaciones para la categoría de electrónica.
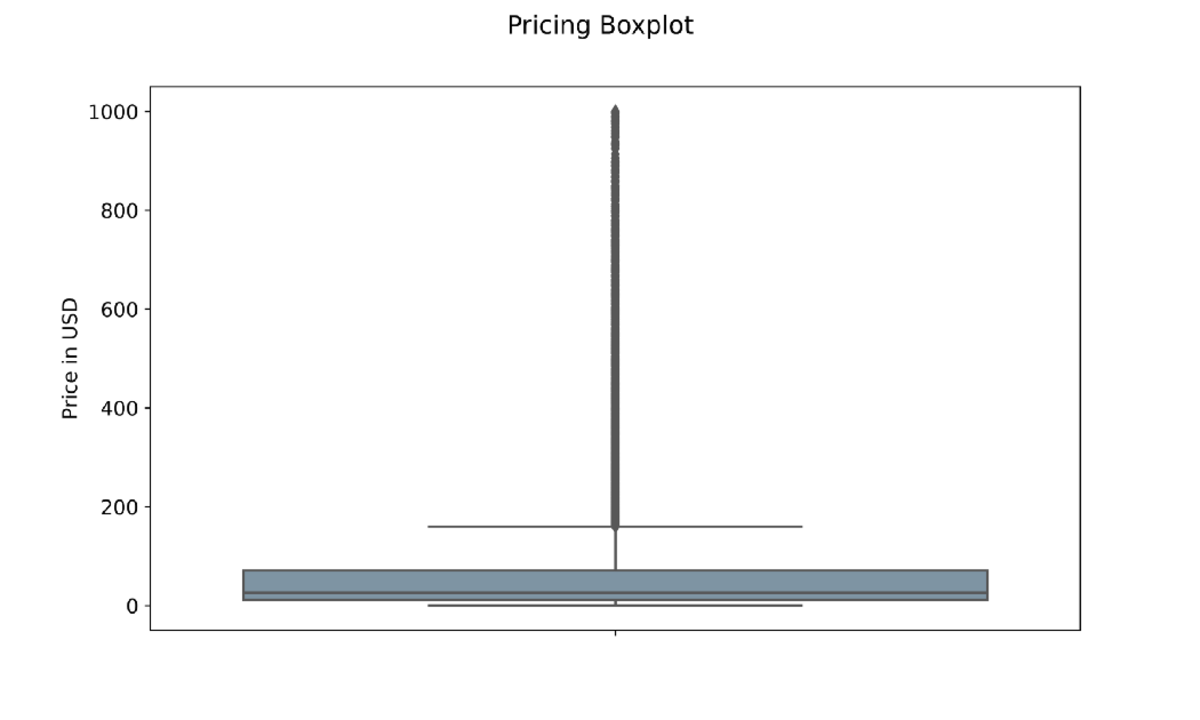
Diagrama de caja de precios con valores atípicos — Imagen del autor
El primer gráfico es un diagrama de caja mostrando el precio máximo, mínimo, percentil 25, percentil 75 y precio promedio de cada producto. Por ejemplo, conocemos la máximas valor de un producto va a ser de $ 1000, mientras que el mínimo es alrededor de $ 1. La línea por encima de la marca de $160 está hecha de puntos, y cada uno de estos puntos identifica un atípico. Un valor atípico representa un registro que solo ocurre una vez en todo el conjunto de datos. Como resultado, sabemos que solo hay 1 producto con un precio de alrededor de $ 1000.
La promedio el precio parece estar alrededor de la marca de $ 25. Es importante señalar que la biblioteca matplotlib excluye automáticamente los valores atípicos con la opciónshowfliers=False. Para que nuestro diagrama de caja se vea más limpio, podemos establecer el parámetro igual a falso.
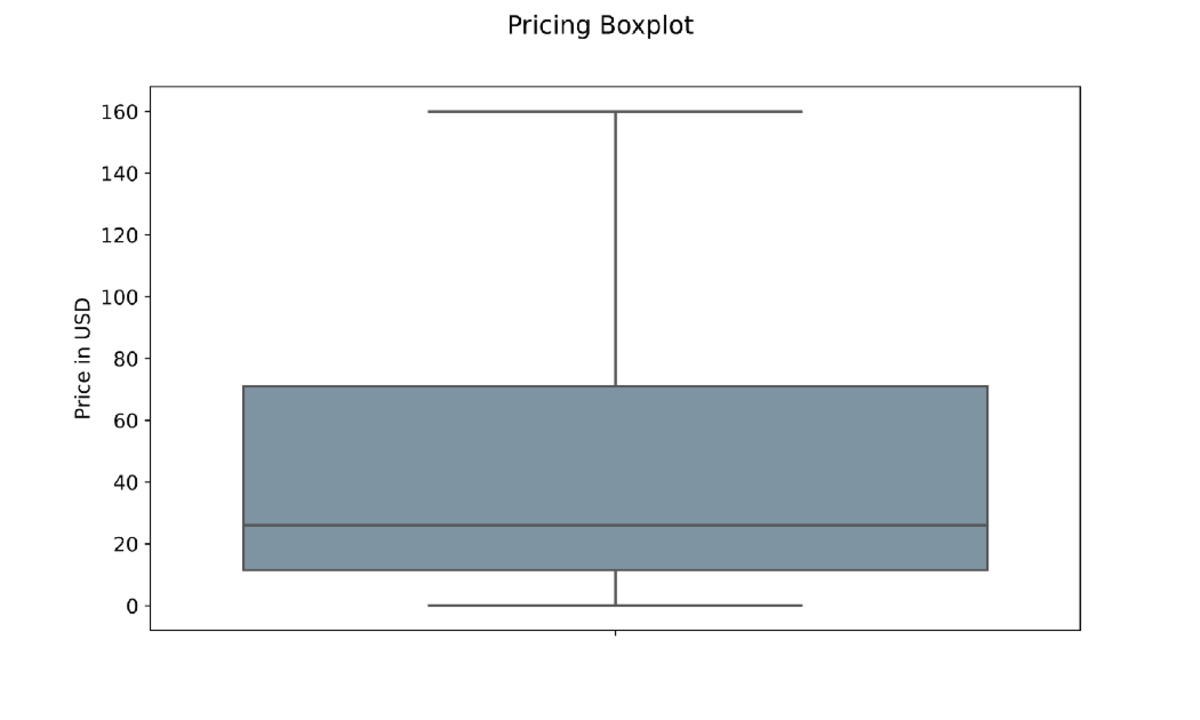
Diagrama de caja de precios — Imagen del autor
El resultado es un Boxplot mucho más limpio sin los valores atípicos. El gráfico también sugiere que la gran mayoría de los productos electrónicos tienen un precio de alrededor de $ 1 a $ 160.
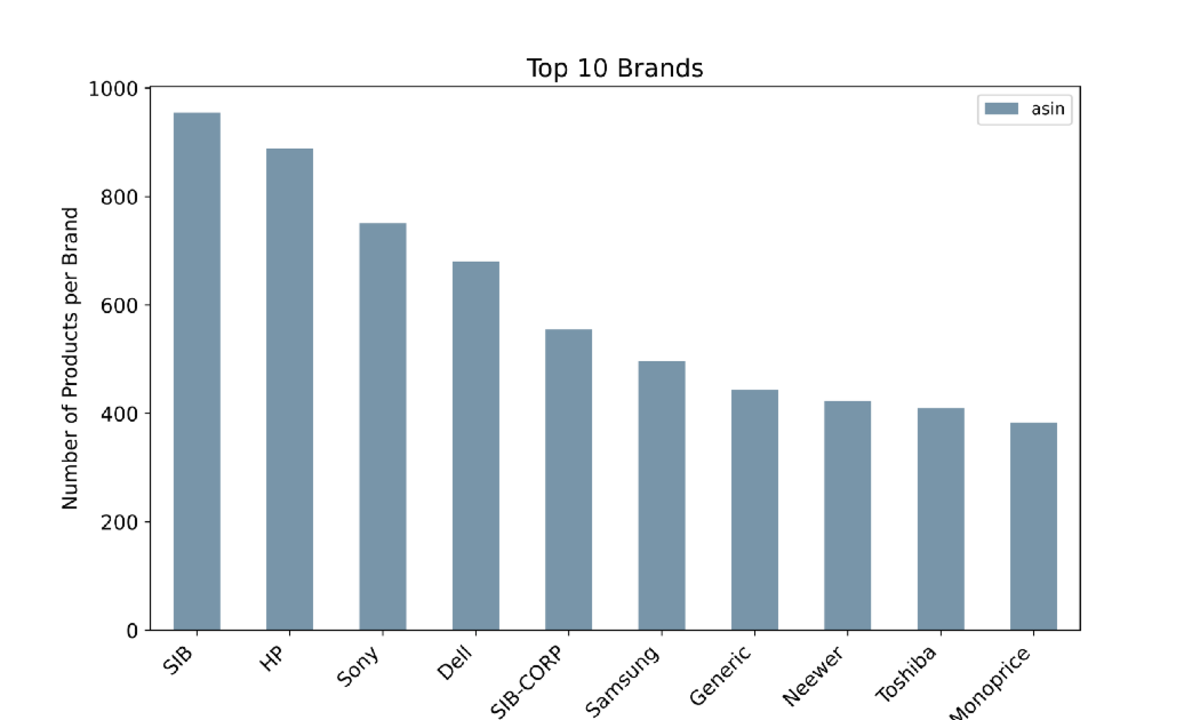
Las 10 mejores marcas por número de productos enumerados: imagen del autor
El gráfico muestra la las 10 mejores marcas por el número de productos enumerados vendiendo en Amazon dentro de la categoría Electrónica. Entre ellos, están HP, Sony, Dell y Samsung.
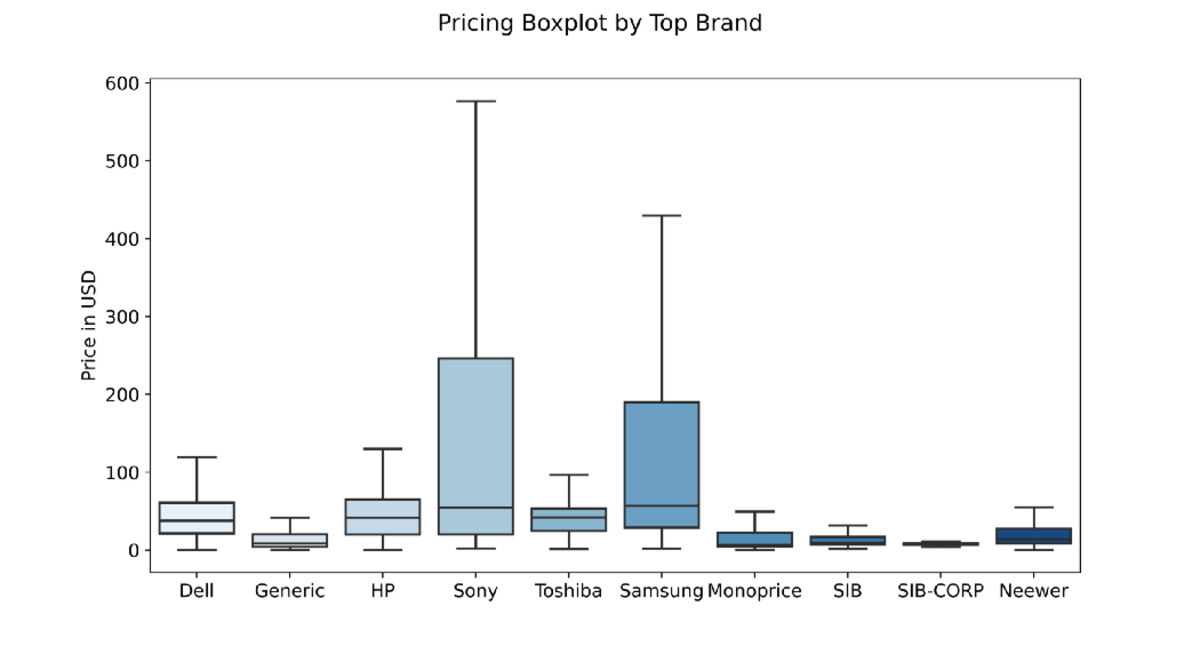
Diagrama de caja de precios de los 10 minoristas principales: imagen del autor
Finalmente, podemos ver la distribución de precios para cada uno de los los 10 mejores vendedores. Sony y Samsung definitivamente ofrecen una amplio rango de productos, desde unos pocos dólares hasta $ 500 y $ 600, como resultado, su precio promedio es más alto que el de la mayoría de los principales competidores. Suficientemente interesante, SIB y SIB-CORP ofrecer más productos pero a un precio mucho más asequible en promedio.
El gráfico también nos dice que Sony ofrece productos que representan aproximadamente el 60% del producto de mayor precio en el conjunto de datos.
Similitud de coseno
Una posible solución para agrupar productos por sus características es similitud de coseno. Necesitamos entender este concepto a fondo para luego construir nuestro sistema de recomendación.
Similitud de coseno mide qué tan "cercanas" están dos secuencias de números. ¿Cómo se aplica a nuestro caso? Sorprendentemente, las oraciones se pueden transformar en números, o mejor, en vectores.
La similitud del coseno puede tomar valores entre -1 y 1, Donde 1 indica que dos vectores son formalmente lo mismo mientras -1 indica que son como una experiencia diferente como pueden conseguir.
Matemáticamente, similitud de coseno es el producto punto de dos vectores multidimensionales dividido por el producto de su magnitud [4]. Entiendo que hay muchas malas palabras aquí, pero intentemos desglosarlo usando un ejemplo práctico.
Supongamos que estamos analizando el documento A y documento B. El documento A tiene los tres términos más comunes: "hoy", "bueno" y "sol", que aparecen respectivamente 4, 2 y 3 veces. Los mismos tres términos en el documento B aparecen 3, 2 y 2 veces. Por lo tanto, podemos escribirlos de la siguiente manera:
A = (2, 2, 3); B = (3, 2, 2)
La fórmula para el producto de punto de dos vectores se puede escribir como:
su vector producto de punto no es otro que 2×3 + 2×2 + 3×2 = 16
La magnitud de un solo vector por otro lado se calcula como:
Si aplico la fórmula obtengo
||A|| = 4.12 ; ||B|| = 4.12
su similitud de coseno es por lo tanto
16 / 17 = 0.94 = 19.74°
los dos vectores son muy similares.
A partir de ahora, calculamos la puntuación solo entre dos vectores tres dimensiones. Un vector de palabra virtualmente puede tener un numero infinito de dimensiones (dependiendo de cuántas palabras contenga) pero la lógica detrás del proceso es matemáticamente la misma. En la siguiente sección, veremos cómo aplicar todos los conceptos en la práctica.
Pasemos al fase de despliegue de código para construir nuestro sistema de recomendación en el conjunto de datos.
Importación de las bibliotecas
La primera celda de cada cuaderno de ciencia de datos debe importar las bibliotecas, los que necesitamos para el proyecto son:
#Importing libraries for data management import gzip
import json
import pandas as pd
from tqdm import tqdm_notebook as tqdm #Importing libraries for feature engineering
import nltk
import re
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similaritygzipdescomprime los archivos de datosjsonlos decodificapandastransforma los datos JSON en un formato de marco de datos más manejabletqdmcrea barras de progresonltkpara procesar cadenas de textoreproporciona soporte para expresiones regulares- finalmente,
sklearnes necesario para el preprocesamiento de texto
leyendo los datos
Como se mencionó anteriormente, los datos se cargaron en un JSON suelto formato. La solución a este problema es primero transformar el archivo en Líneas de formato legible JSON con el comando json.dumps . Entonces, podemos transformar este archivo en un lista de Python hecho de líneas JSON configurando n como el salto de línea. Finalmente, podemos añadir cada línea a la data lista vacía al leerla como JSON con el comando json.loads .
Con el comando pd.DataFrame las data list se lee como un marco de datos que ahora podemos usar para construir nuestro recomendador.
#Creating an empty list
data = [] #Decoding the gzip file
def parse(path): g = gzip.open(path, 'r') for l in g: yield json.dumps(eval(l)) #Defining f as the file that will contain json data
f = open("output_strict.json", 'w') #Defining linebreak as 'n' and writing one at the end of each line
for l in parse("meta_Electronics.json.gz"): f.write(l + 'n') #Appending each json element to the empty 'data' list
with open('output_strict.json', 'r') as f: for l in tqdm(f): data.append(json.loads(l)) #Reading 'data' as a pandas dataframe
full = pd.DataFrame(data)Para darle una idea de cómo cada línea de la data lista parece que podemos ejecutar una comando simple print(data[0]) , la consola imprime la línea en el índice 0.
print(data[0]) output: { 'asin': '0132793040', 'imUrl': 'http://ecx.images-amazon.com/images/I/31JIPhp%2BGIL.jpg', 'description': 'The Kelby Training DVD Mastering Blend Modes in Adobe Photoshop CS5 with Corey Barker is a useful tool for...and confidence you need.', 'categories': [['Electronics', 'Computers & Accessories', 'Cables & Accessories', 'Monitor Accessories']], 'title': 'Kelby Training DVD: Mastering Blend Modes in Adobe Photoshop CS5 By Corey Barker'
}Como puede ver, la salida es un archivo JSON, tiene el {} para abrir y cerrar la cadena, y cada nombre de columna va seguido del : y la cadena correspondiente. Puede notar que a este primer producto le falta el price, salesRank, relatedy brand information . Esas columnas se rellenan automáticamente con NaN valores.
Una vez que leemos la lista completa como un marco de datos, los productos electrónicos muestran las siguientes 8 características:
| asin | imUrl | description | categories |
|--------|---------|---------------|--------------|
| price | salesRank | related | brand |
|---------|-------------|-----------|---------|Ingeniería de características
Ingeniería de características es responsable de limpieza y creación de datos la columna en la que calcularemos la puntuación de similitud del coseno. Debido a las limitaciones de la memoria RAM, no quería que las columnas fueran particularmente largas, como podría ser una reseña o una descripción del producto. Por el contrario, decidí crear un "sopa de datos" con el categories, titley brand columnas Sin embargo, antes de eso, debemos eliminar cada fila que contenga un valor de NaN en cualquiera de esas tres columnas.
Las columnas seleccionadas contienen información valiosa y esencial en forma de texto que necesitamos para nuestro recomendador. El description La columna también podría ser un candidato potencial, pero la cadena suele ser demasiado larga y no está estandarizada en todo el conjunto de datos. No representa una información lo suficientemente confiable para lo que estamos tratando de lograr.
#Dropping each row containing a NaN value within selected columns
df = full.dropna(subset=['categories', 'title', 'brand']) #Resetting index count
df = df.reset_index()Después de ejecutar esta primera porción de código, las filas disminuyen vertiginosamente de 498,196 a aproximadamente 142,000, un gran cambio. Solo en este punto podemos crear la llamada sopa de datos:
#Creating datasoup made of selected columns
df['ensemble'] = df['title'] + ' ' + df['categories'].astype(str) + ' ' + df['brand'] #Printing record at index 0
df['ensemble'].iloc[0] output: "Barnes & Noble NOOK Power Kit in Carbon BNADPN31 [['Electronics', 'eBook Readers & Accessories', 'Power Adapters']] Barnes & Noble"El nombre de la marca debe incluirse ya que el título no siempre lo contiene.
Ahora puedo pasar a la porción de limpieza. La función text_cleaning es responsable de eliminar cada amp cuerda de la columna del conjunto. Además de eso, la cadena[^A-Za-z0–9] filtra cada personaje especial. Finalmente, la última línea de la función elimina todos los palabra de parada contiene la cadena.
#Defining text cleaning function
def text_cleaning(text): forbidden_words = set(stopwords.words('english')) text = re.sub(r'amp','',text) text = re.sub(r's+', ' ', re.sub('[^A-Za-z0-9]', ' ', text.strip().lower())).strip() text = [word for word in text.split() if word not in forbidden_words] return ' '.join(text)Con la función lambda, podemos aplicar text_cleaning a toda la columna llamada ensemble , podemos seleccionar aleatoriamente una sopa de datos de un producto aleatorio llamando iloc e indicando el índice del registro aleatorio.
#Applying text cleaning function to each row
df['ensemble'] = df['ensemble'].apply(lambda text: text_cleaning(text)) #Printing line at Index 10000
df['ensemble'].iloc[10000] output: 'vcool vga cooler electronics computers accessories computer components fans cooling case fans antec'El registro en el 10001st fila (la indexación comienza desde 0) es el Enfriador vcool VGA de Antec. Este es un escenario en el que el nombre de la marca no estaba en el título.
Cálculo de coseno y función de recomendación
El cálculo de la similitud del coseno comienza con construir una matriz que contenga todas las palabras que alguna vez aparecen en la columna del conjunto. El método que vamos a utilizar se llama “Vectorización de conteo” o más comúnmente “Bolsa de palabras”. Si desea leer más sobre la vectorización de conteo, puede leer uno de mis artículos anteriores en el siguiente liga.
Debido a las limitaciones de RAM, la puntuación de similitud del coseno se calculará solo en el primer 35,000 registros fuera del 142,000 disponible después de la fase de preprocesamiento. Es muy probable que esto afecte el rendimiento final del recomendador.
#Selecting first 35000 rows
df = df.head(35000) #creating count_vect object
count_vect = CountVectorizer() #Create Matrix
count_matrix = count_vect.fit_transform(df['ensemble']) # Compute the cosine similarity matrix
cosine_sim = cosine_similarity(count_matrix, count_matrix)El comando cosine_similarity , como sugiere el nombre, calcula la similitud del coseno para cada línea en el count_matrix . Cada línea en el count_matrix no es más que un vector con el recuento de palabras de cada palabra que aparece en la columna del conjunto.
#Creating a Pandas Series from df's index
indices = pd.Series(df.index, index=df['title']).drop_duplicates()Antes de ejecutar el sistema de recomendación real, debemos asegurarnos de crear un índice y que este índice no tenga duplicados.
Sólo en este punto podemos definir el content_recommenderfunción. Tiene 4 argumentos: title, cosine_sim, dfy indices. El título será el único elemento a ingresar al llamar a la función.
content_recommender funciona de la siguiente manera:
- Encuentra el índice de productos asociado con el título que proporciona el usuario
- Busca en el índice de productos dentro de la matriz de similitud de coseno y reúne todas las puntuaciones de todos los productos
- It hechizos todas las puntuaciones de la producto más similar (más cercano a 1) al menos similar (más cercano a 0)
- Solo selecciona la primeros 30 mas parecidos productos
- Agrega un índice y devuelve una serie de pandas con el resultado
# Function that takes in product title as input and gives recommendations
def content_recommender(title, cosine_sim=cosine_sim, df=df,
indices=indices): # Obtain the index of the product that matches the title idx = indices[title] # Get the pairwsie similarity scores of all products with that product # And convert it into a list of tuples as described above sim_scores = list(enumerate(cosine_sim[idx])) # Sort the products based on the cosine similarity scores sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True) # Get the scores of the 30 most similar products. Ignore the first product. sim_scores = sim_scores[1:30] # Get the product indices product_indices = [i[0] for i in sim_scores] # Return the top 30 most similar products return df['title'].iloc[product_indices]Ahora vamos a probarlo en el "Vcool VGA Cooler". Queremos 30 productos que sean similares y que los clientes estén interesados en comprar. Al ejecutar el comando content_recommender(product_title) , el la función devuelve una lista de 30 recomendaciones.
#Define the product we want to recommend other items from
product_title = 'Vcool VGA Cooler' #Launching the content_recommender function
recommendations = content_recommender(product_title) #Associating titles to recommendations
asin_recommendations = df[df['title'].isin(recommendations)] #Merging datasets
recommendations = pd.merge(recommendations, asin_recommendations, on='title', how='left') #Showing top 5 recommended products
recommendations['title'].head()Entre los 5 productos más similares encontramos otros productos de Antec como el Tricool Computer Case Fan, el Expansion Slot Cooling Fan, etc.
1 Antec Big Boy 200 - 200mm Tricool Computer Case Fan 2 Antec Cyclone Blower, Expansion Slot Cooling Fan 3 StarTech.com 90x25mm High Air Flow Dual Ball Bearing Computer Case Fan with TX3 Cooling Fan FAN9X25TX3H (Black)
4 Antec 120MM BLUE LED FAN Case Fan (Clear) 5 Antec PRO 80MM 80mm Case Fan Pro with 3-Pin & 4-Pin Connector (Discontinued by Manufacturer)La related La columna en el conjunto de datos original contiene una lista de productos que los consumidores también compraron, compraron juntos y compraron después de ver VGA Cooler.
#Selecting the 'related' column of the product we computed recommendations for
related = pd.DataFrame.from_dict(df['related'].iloc[10000], orient='index').transpose() #Printing first 10 records of the dataset
related.head(10)Al imprimir el encabezado del diccionario de Python en esa columna, la consola devuelve el siguiente conjunto de datos.
| | also_bought | bought_together | buy_after_viewing |
|---:|:--------------|:------------------|:--------------------|
| 0 | B000051299 | B000233ZMU | B000051299 |
| 1 | B000233ZMU | B000051299 | B00552Q7SC |
| 2 | B000I5KSNQ | | B000233ZMU |
| 3 | B00552Q7SC | | B004X90SE2 |
| 4 | B000HVHCKS | | |
| 5 | B0026ZPFCK | | |
| 6 | B009SJR3GS | | |
| 7 | B004X90SE2 | | |
| 8 | B001NPEBEC | | |
| 9 | B002DUKPN2 | | |
| 10 | B00066FH1U | | |Probemos si a nuestro recomendador le fue bien. A ver si alguno de los asin identificadores en el also_bought lista están presentes en las recomendaciones.
#Checking if recommended products are in the 'also_bought' column for
#final evaluation of the recommender related['also_bought'].isin(recommendations['asin'])Nuestro recomendador sugirió correctamente 5 de 44 productos.
[True False True False False False False False False False True False False False False False False True False False False False False False False False True False False False False False False False False False False False False False False False False False]estoy de acuerdo es no es un resultado óptimo pero considerando que solo usamos 35,000 fuera de la 498,196 filas disponibles en el conjunto de datos completo, es aceptable. Sin duda tiene mucho margen de mejora. Si los valores de NaN fueran menos frecuentes o incluso inexistentes para las columnas de destino, las recomendaciones podrían ser más precisas y cercanas a las reales de Amazon. En segundo lugar, tener acceso a mayor memoria RAM, o incluso la computación distribuida, podría permitirle al profesional calcular matrices aún más grandes.
Espero que hayas disfrutado el proyecto y que te sea útil para cualquier uso futuro.
Como se menciona en el artículo, el resultado final se puede mejorar aún más mediante incluyendo todas las líneas del conjunto de datos en la matriz de similitud de coseno. Además de eso, podríamos agregar cada producto revisar el puntaje promedio fusionando el conjunto de datos de metadatos con otros disponibles en el repositorio. Pudimos incluye el precio en el cálculo de la similitud del coseno. Otra posible mejora podría ser construir un sistema de recomendación completamente basado en cada descriptivo del producto imágenes.
Se han enumerado las principales soluciones para futuras mejoras. Incluso vale la pena seguir la mayoría de ellos desde la perspectiva de la implementación futura en la realidad. Production.
Como nota final, si le gustó el contenido, considere dejar un seguimiento para recibir una notificación cuando se publiquen nuevos artículos. Si tienes alguna observación sobre el artículo, ¡escríbela en los comentarios! Me encantaría leerlos 🙂 ¡Gracias por leer!
PD: Si te gusta mi escritura, significaría mucho para mí si pudieras suscribirte a una membresía mediana a través de este enlace. ¡Con la membresía, obtienes el increíble valor que brindan los artículos medianos y es una forma indirecta de apoyar mi contenido!
Referencia
[1] Sistema de recomendación de productos de Amazon en 2021: ¿cómo funciona el algoritmo del gigante del comercio electrónico? — Recostream. (2021). Recuperado el 1 de noviembre de 2022, del sitio web Recostream.com: https://recostream.com/blog/amazon-recommendation-system
[2] Él, R. y McAuley, J. (2016, abril). Altibajos: modelado de la evolución visual de las tendencias de la moda con filtrado colaborativo de una clase. En Actas de la 25ª conferencia internacional sobre la red mundial (págs. 507–517).
[3] McAuley, J., Targett, C., Shi, Q. y Van Den Hengel, A. (agosto de 2015). Recomendaciones basadas en imágenes sobre estilos y sustitutos. En Actas de la 38.ª conferencia internacional ACM SIGIR sobre investigación y desarrollo en recuperación de información (págs. 43–52).
[4] Rahutomo, F., Kitasuka, T. y Aritsugi, M. (2012, octubre). Semejanza semántica del coseno. En La 7ma conferencia internacional de estudiantes en ciencia y tecnología avanzada ICAST (Vol. 4, ?1, pág. 1).
[5] Rounak Banik. 2018. Sistemas prácticos de recomendación con Python: comience a crear motores de recomendación potentes y personalizados con Python. Publicación de paquetes.
giovanni valdata tiene dos BBA y un Msc. en Administración, al final de la cual aprovechó la PNL para su tesis en Data Science and Management. Giovanni disfruta ayudar a los lectores a aprender más sobre el campo mediante el desarrollo de proyectos técnicos con aplicaciones prácticas.
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/02/building-recommender-system-amazon-products-python.html?utm_source=rss&utm_medium=rss&utm_campaign=building-a-recommender-system-for-amazon-products-with-python

