Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Oye, ¿estás trabajando en un proyecto de ciencia de datos, resolviendo el enunciado de un problema relacionado con la ciencia de datos o experimentando con una prueba estadística para tomar más decisiones y manejar el término estadístico más citado, "correlación"? ¿Está dispuesto a interpretar correctamente estos términos estadísticos (covarianza, correlación paramétrica y no paramétrica)? ¿Está confundido acerca de comprender las suposiciones antes de seleccionar un método apropiado? ¿Qué método tendrá un rendimiento superior o inferior en la declaración de su problema en un escenario específico (es decir, sensible a valores atípicos, tipo de distribución, etc.)? ¿Está trabajando con datos de muestra y está dispuesto a conocer el error probable del coeficiente? ……pronto….?
….” entonces, créame, este artículo lo ayudará a concretar su comprensión de todos estos términos estadísticos junto con su aplicación'…”
Sin embargo, la 'correlación' no se limita sólo a hacer selección de características basadas en filtros técnicas para reducir funciones redundantes o innecesarias para ahorrar costos computacionales y mejorar la eficiencia del modelo, pero ayuda a obtener resultados comerciales finales (por ejemplo, en Agricultura, como la cantidad de fertilizantes y el rendimiento del cultivo, en medicina, como Nuevo fármaco y % de pacientes curados, en Operación, como gasto social y productividad, etc., en sociología como desempleo y delincuencia, etc., en economía como precio y demanda, etc.). Por lo tanto, se vuelve más fácil tomar decisiones adicionales para considerar o rechazar las variables/características en función de ciertos valores de umbral a discreción de la experiencia del dominio y el científico de datos.
Este artículo cubrirá los siguientes temas para fortalecer nuestra comprensión.
-
-
- Covarianza, correlación y su significado
- Correlación paramétrica (lineal) y su coeficiente (Pearson)
- , correlación no paramétrica (no lineal) y su coeficiente (Spearman y Kendall)
- Correlación de grupo
- Error probable del coeficiente de correlación
-
¡Así que comencemos y hagamos algunas prácticas!
Antes de comprender la correlación, intentemos comprender el término de covarianza y sus limitaciones.
¿Qué es la covarianza?
La covarianza mide la fuerza de la relación entre dos variables numéricas y su tendencia a moverse juntas. Pero de su interpretación no es fácil derivar ideas al respecto.
La covarianza entre las variables de muestra x e y se puede formular matemáticamente según la siguiente ecuación.
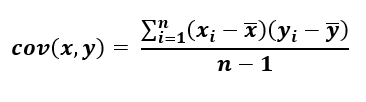
Ecuación-1: Covarianza de las variables X e Y de la muestra, n-1 representa una corrección basal
Tratemos de entender la covarianza con el siguiente ejemplo.
A conjunto de datos de muestra se ha tomado solo para experimentar con tres posibles correlaciones entre los ingresos del equipo de la NBA y el valor de la NBA en un escenario diferente:
importar pandas como pd importar matplotlib.pyplot como plt importar seaborn como sns
d1 = pd.read_excel(r"C:Usuarios..Covariancedata.xlsx",sheet_name='d1') d2 = pd.read_excel(r"C:Usuarios..Covariancedata.xlsx",sheet_name='d2') d3 = pd.read_excel(r"C:Usuarios..Covariancedata.xlsx",sheet_name='d3')
d1.forma, d2.forma, d3.forma
Fuente de datos :
d1.cov().redondo(2)
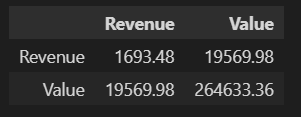
La covarianza es cualquier valor numérico (en nuestro caso, es 19,569.98), por lo que es imposible determinar la fuerza de la relación en función de estos valores; por lo tanto, se considera que el coeficiente de correlaciones obtiene el valor correcto. Antes de entenderlo, tratemos de entender la correlación.
La correlación
La correlación es una estadística destinada a cuantificar la fuerza de la relación entre dos variables. En la práctica, medir la relación entre dos variables nunca es tan fácil ya que, en muchos casos, ambas variables tienen diferentes escalas y unidades siguiendo distribuciones disímiles. Con base en la distribución y el tipo de relación, las correlaciones se pueden interpretar en dos categorías de la siguiente manera.
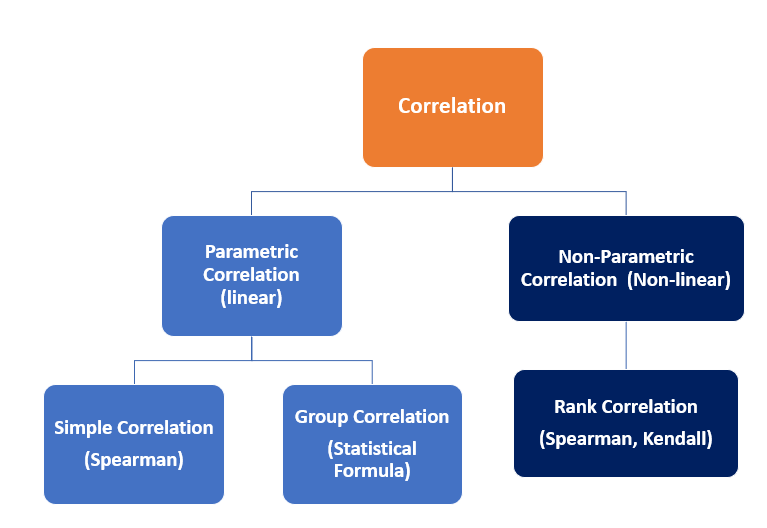
Correlación paramétrica (lineal)
Los siguientes bocetos muestran un vistazo de la correlación lineal entre dos variables. Sin embargo, para las variables continuas que están linealmente correlacionadas, las correlaciones formadas entre ellas pueden interpretarse como una correlación paramétrica (lineal), y la fuerza de la relación puede medirse mediante el coeficiente de correlación de Pearson.
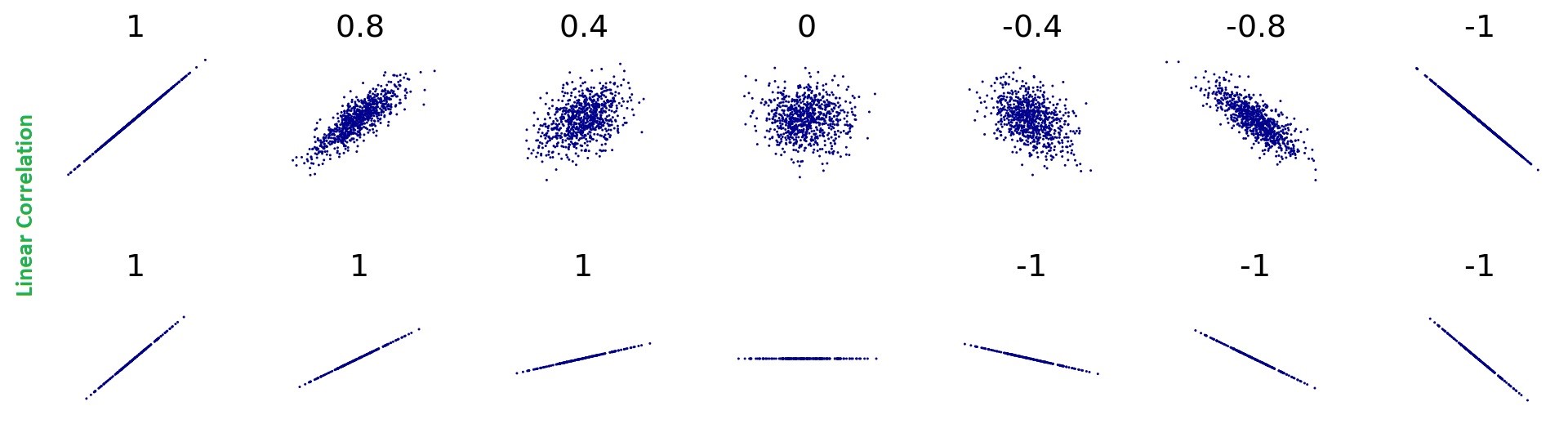
Coeficiente de correlación de Pearson:
Para calcular la correlación entre dos series (por ejemplo, las variables x e y), el coeficiente de correlación se calcula dividiendo la covarianza de las variables previstas (supongamos x e y) por su desviación estándar respectivamente, y la expresión matemática dada mide la fuerza relativa de una relación lineal entre dos variables que varía (-1 ≤ r ≤ 1) donde -1 para correlación negativa perfecta d +1 para correlación positiva perfecta y se conoce como coeficiente de correlación de Pearson.
Esto significa que las variables x e y se mueven juntas en una proporción constante y se denotan con 'r'.

Ecuación: 2 Coeficiente de correlación de Pearson
Antes de utilizar la Correlación de Pearson, se deben verificar las siguientes suposiciones:
(1) La relación entre dos variables (por ejemplo, x e y) debe ser lineal, donde la cantidad de variación en x tiene una relación constante con la cantidad correspondiente de variación en y.
(2) Ambas variables se distribuirán aproximadamente normalmente
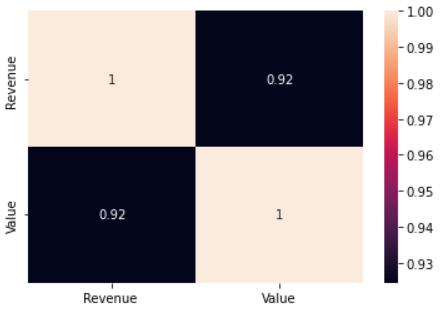
Usando la biblioteca seaborn, podemos calcular las correlaciones con una sola línea de código como se muestra a continuación:
sns.heatmap(d1.corr(método='pearson'), annot=True)
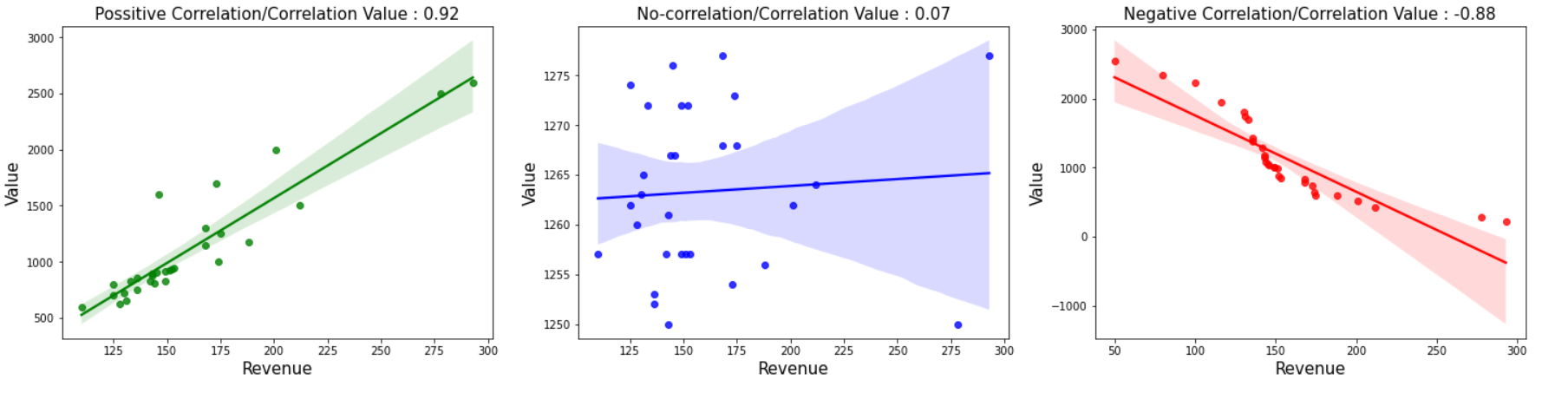
Trazar las pocas correlaciones posibles usando regplot. Sin embargo, el diagrama de dispersión también hace el trabajo. representar lo mismo.
plt.subplots(figsize=(10,5)) plt.subplot(1,3,1) sns.regplot(x = d1['Ingresos'], y=d1['Valor'], color='Verde') plt.title('Correlación positiva/Valor de correlación: 0.92', tamaño de fuente=(15)) plt.xlabel('Ingresos', tamaño de fuente=(15)) plt.ylabel('Valor', tamaño de fuente=(15)) plt. subplot(1,3,2) sns.regplot(x = d2['Ingresos'], y=d2['Valor'], color='azul') plt.title('Sin correlación/Valor de correlación: 0.07' , tamaño de fuente=(15)) plt.xlabel('Ingresos', tamaño de fuente=(15)) plt.ylabel('Valor', tamaño de fuente=(15)) plt.subplots_adjust(abajo=0.1, derecha=2, arriba=0.9 ) plt.subplot(1,3,3) sns.regplot(x = d3['Ingresos'], y=d3['Valor'], color='rojo') plt.title('Correlación negativa/Valor de correlación: -0.88', tamaño de fuente=(15)) plt.xlabel('Ingresos', tamaño de fuente=(15)) plt.ylabel('Valor', tamaño de fuente=(15)) plt.subplots_adjust(abajo=0.1, derecha=2, superior = 0.9)
Correlación no paramétrica (no lineal)
Acercar el valor del coeficiente de Pearson a cero enfatiza la no correlación de dos variables. Aún así, no valida la prueba ya que solo mide las correlaciones lineales y subestima la fuerza de la relación para las variables no linealmente correlacionadas. Por lo tanto, las limitaciones de las correlaciones de Pearson son sobredimensionadas por la correlación no paramétrica llamada coeficiente de correlación clasificada, que se basa en la clasificación de las variables. Esto fue introducido por Charles Edward Spearman y conocido como correlación de rango de Spearman.
Correlación de rango de Spearman:
Para datos sin distribución (datos clasificados), se utilizan métodos estadísticos no paramétricos para medir el grado de correlación entre dos variables clasificadas. Las correlaciones de rango pueden evaluarse en series discretas de naturaleza cualitativa. Se puede calcular con la ayuda de la siguiente expresión matemática: Se denota por R, y su valor se encuentra en el intervalo cerrado (-1 ≤ R ≤ 1). Correlación de Spearman
Aplicación: ayuda a medir la correlación cualitativa, es decir, la puntuación de belleza, la inteligencia (CI), los méritos, etc.
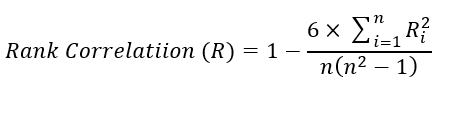
Ecuación-3: Rango de Spearman Correlación del coeficiente
Ri = Diferencia simétrica entre dos conjuntos de pares ordenados (Digamos x – y)
n = número de observación
Solo como referencia, algunos bocetos muestran correlaciones cero entre dos variables que tienen una relación no lineal.

Intentemos experimentar tanto con parámetros paramétricos como no paramétricos en el conjunto de datos (ventas de chatarra de acero) usando un gráfico de dispersión para verificar las correlaciones lineales y un gráfico de distribución para verificar la distribución de 'Tasa' y 'Cantidad'.
df1 = pd.read_excel(r"C:UsersshailGoogle Drive22-23Scrapcleaned_Qty_rate.xlsx") df1.shape, df1.head()

sns.scatterplot(x=df1['Cantidad'], y=df1['Tasa'])
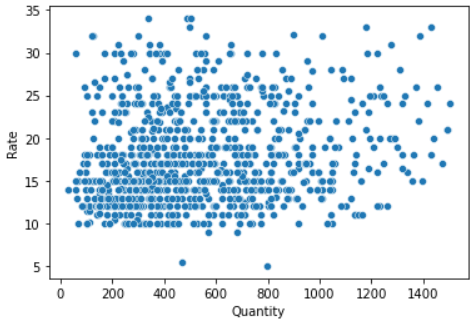
Intentemos verificar la segunda suposición (las variables tienen una distribución aproximadamente normal o no) de Pearson usando un gráfico de distribución.
plt.figure (figsize = (15,5))
plt.subplot(1,2,1) sns.distplot(df1['Cantidad']) plt.subplot(1,2,2) sns.distplot(df1['Tasa'])
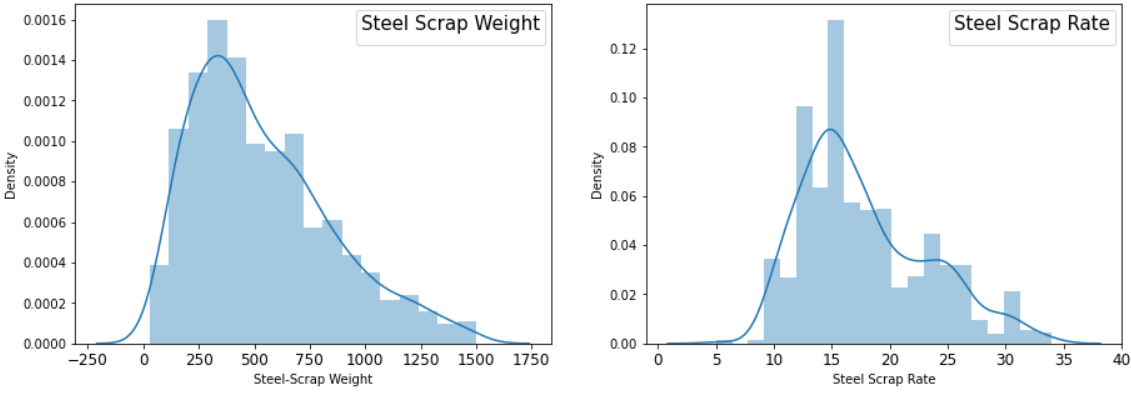
Sin duda, al observar la distribución anterior, no cumple con el supuesto de la correlación de Pearson debido a (1) tener una distribución sesgada y (2) no tener una relación lineal. Aun así, nos gustaría comprobar los coeficientes de correlación de Pearson y Spearman.
imprimir('Pearson:', df1.corr(método='pearson'))
print('n') print('Pearson:', df1.corr(método='spearman'))

Mirando los resultados anteriores, el coeficiente de Spearman muestra una mejor fuerza de correlación de 0.21 en lugar del coeficiente de Pearson de 0.19.
Coeficiente de correlación de Kendall:
Mide el grado de similitud entre dos conjuntos de rangos. Se puede derivar normalizando la diferencia simétrica de modo que tome valores entre -1 para la distancia más grande posible (cuando el orden/rango son exactamente inversos) y +1 para la distancia más pequeña posible. Cero en este caso, representa que ambos conjuntos son idénticos. Se puede expresar matemáticamente como:
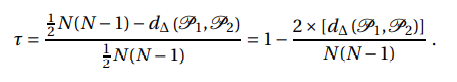
Aquí, P1 y P2 son dos conjuntos de pares ordenados
d∆ (P1, P2) es la diferencia simétrica entre dos conjuntos apareados P1 y P2
1/2* N(N-1) representa el número máximo de pares que pueden diferir entre dos conjuntos
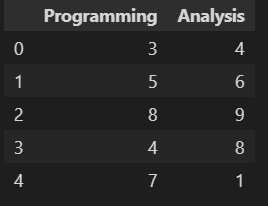
Veamos la parte de implementación que se refiere a un ejemplo para calcular correlaciones para datos de clasificación (datos ordinales) donde la clasificación de 10 alumnos (Conjunto de datos 4) en dos habilidades, a saber, 'Programación' y 'Análisis'.
d4=pd.read_excel(r"C:Usuarios..Covariancedata.xlsx", nombre_hoja='d4') d4.head()
Aquí, aplicaremos ambos métodos no paramétricos para verificar las correlaciones de coeficientes usando una sola línea de código. Tan sencillo !!
imprimir (d4.corr (método = 'spearman'))
imprimir (d4.corr (método = 'kendall'))

Por lo tanto, ambos métodos tienen resultados diferentes donde el coeficiente de correlación de Spearman da una correlación negativa correcta de -0.24 en lugar del coeficiente de Kendall calculado en -0.15. Entonces, dependiendo de los datos, la declaración del problema y los resultados, se seleccionará un método apropiado de manera intercambiable.
El Probable Error de la C de Correlación
Prácticamente, trabajamos con datos muestrales debido a las limitaciones en el acceso a los datos poblacionales; por lo tanto, para reducir las posibilidades de error al calcular el coeficiente de correlación, surge el error probable que se puede expresar matemáticamente de la siguiente manera:

En nuestro caso, el error probable puede ser alto debido a que hay menos muestras de datos disponibles, pero a medida que aumenta la muestra, el error probable disminuirá en consecuencia. Habiendo dicho esto, cuanto más grande sea la muestra, mejor se puede representar el coeficiente de correlación a través de la siguiente expresión matemática.
En nuestro caso, para el conjunto de datos/d1 (ingresos y valor del equipo de la NBA), verifiquemos el error probable ya que estamos tratando con un conjunto de datos limitado. Aquí hemos supuesto que la distribución de ambas variables es normal.
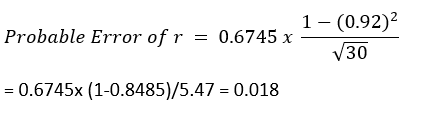
El cálculo de error probable solo se puede utilizar cuando todos los datos son normales o casi normales.
[Nota: las correlaciones de los coeficientes solo son significativas si r > 6* PE ]
En nuestro caso, el error probable no es significativo ya que r (0.92) > 0.108 ( 6* 0.018)
Correlación de grupo
Esta medida se puede evaluar en la serie continua de datos agrupados, denotada por r, y los valores de r se encuentran en el intervalo cerrado ((-1 ≤ r ≤ 1). Cuanto mayor sea el valor de r, más fuerte será la relación entre x e y .

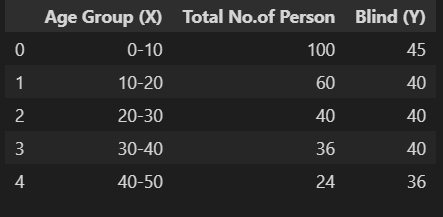
Por ejemplo, considere un informe de encuesta (conjunto de datos5) de un total o parcialmente ciego Grupo de edad de 0 años a 80 años; Los siguientes datos se han registrado para verificar la correlación del grupo:
d5=pd.read_excel(r"C:Usuarios...Analytics VidhyaCovariancedata.xlsx", sheet_name='d5') d5.head()
A partir de los datos anteriores, considerando el intervalo de clase (h= 10) y cualquier valor medio (A=45 y B=1.5) para las Variables X e Y, se toman para calcular la desviación en x e y como dx y dy con ref. a su valor medio A y B. Para facilitar la comprensión, he usado una hoja de Excel para mostrar el cálculo, ya que las observaciones son menos para calcular. Al definir funciones en python, lo mismo se puede hacer fácilmente.
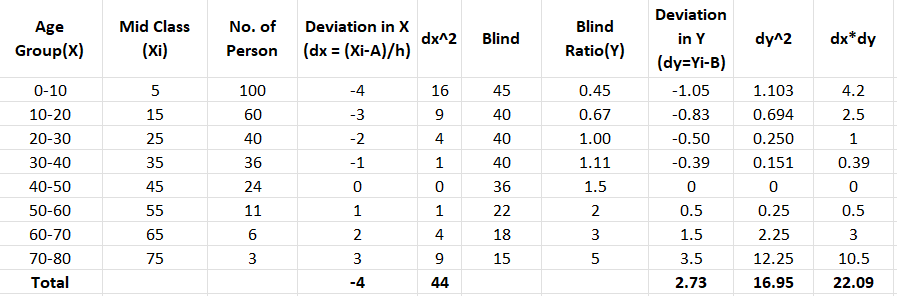
Cálculo de las correlaciones de grupo usando la ecuación 5:
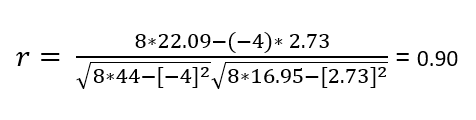
Por lo tanto, se puede concluir que existe una fuerte correlación positiva entre el grupo de edad y la ceguera.
Resumiendo el aprendizaje anterior para la correlación Paramétrica y No Paétrica de acuerdo a los métodos, supuestos a cumplir, características, etc.
| Supuestos/Características/ Métodos | Paramétrico La correlación |
no paramétrico La correlación |
| Métodos / Métricas | Karl's correlación de Pearson |
Lancero & Correlación de Kendall (usada indistintamente) |
| Suposición (1) | Debe ser variables numéricas continuas |
Valor clasificado, datos ordinales |
| Asunción (2) |
Relación lineal de formas variables (positiva o negativa) | Formas monótonas Relación |
| Asunción (3) |
ambas variables seguirá una distribución aproximadamente normal |
Las variables libres de distribución pueden formar un sesgado o uniforme |
| Características | Ambos las variables se mueven en una proporción constante y siguen una correlación lineal (es decir, y = mx, etc.) |
Variables muévase a una proporción constante pero no siga la correlación lineal; en su lugar, siga la exponencial, la curva, la parábola, etc. (es decir, y = ax+bx^2, a=b^2) |
| Impactado por/Sensible a: | Los valores atípicos debe ser manejado ya que afecta en gran medida la correlación |
Robusto y mitiga el efecto de los valores atípicos |
| Gama de Colores | -1 ≤ r ≤ 1 | -1 ≤ R/T ≤ 1 |
Después de experimentar con algunas intuiciones y definiciones matemáticas prácticas, llegamos a la conclusión de que el coeficiente de correlación muestra la fuerza de la relación entre dos variables antes de que sea obligatorio cumplir con cierta suposición para obtener el resultado correcto.
Los puntos clave de este artículo se pueden resumir a continuación:
- Se deben verificar dos suposiciones para datos numéricos continuos antes de aplicar la Correlación de Pearson. Si las variables no lo siguen, según el tipo de datos, aplique las matrices de Spearman/Kendall.
- Para datos sin distribución (clasificados/ordinales), el coeficiente de correlación de 'Spearman' o el de Kendall se pueden usar indistintamente. El método de Spearman es más fácil de entender e interpretar que el de Kendall.
- Al tratar con declaraciones de problemas de la vida real, el umbral para rechazar/descartar variables en función de su coeficiente de correlación debe establecerlo la experiencia en el dominio y los científicos de datos en función de su subjetividad y contextualidad.
- Para datos de grupo, especialmente para un número impar de observaciones, la selección del valor medio (A y B en nuestro caso) debe validarse repitiendo el cálculo. (en nuestro caso, al tener 8 números de observaciones, se tomará la 4ª o la 5ª observación para comprobar el resultado. Aquí hemos optado por la 5ª observación como valor medio).
- Las fuertes correlaciones positivas o negativas juegan un papel importante en los negocios; por lo tanto, su interpretación también necesita un conocimiento profundo sobre el dominio específico.
Dale me gusta y comenta si encuentras esto útil. Siéntete libre de conectarte conmigo!!
¡Feliz aprendizaje!
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/11/parametric-and-non-parametric-correlation-in-data-science/

