amazona kendra es un servicio de búsqueda inteligente impulsado por aprendizaje automático (ML). Indexa los documentos almacenados en una amplia gama de repositorios y encuentra el documento más relevante en función de las palabras clave o preguntas de lenguaje natural que el usuario ha buscado. En algunos escenarios, necesita que los resultados de la búsqueda se filtren según el contexto del usuario que realiza la búsqueda. Se necesita un refinamiento adicional para encontrar los documentos específicos de ese usuario o grupo de usuarios como resultado de búsqueda superior.
En esta publicación de blog, nos enfocamos en recuperar resultados de búsqueda personalizados que se aplican a un usuario o grupo de usuarios específico. Por ejemplo, los profesores de una institución educativa pertenecen a diferentes departamentos, y si un profesor perteneciente al departamento de informática ingresa a la aplicación y busca con las palabras clave “cursos de la facultad”, luego los documentos relevantes para el mismo departamento aparecen como los mejores resultados, según la disponibilidad de la fuente de datos.
Resumen de la solución
Para resolver este problema, puede identificar una o más información de metadatos única asociada con los documentos que se indexan y buscan. Cuando el usuario inicia sesión en un Amazon lex chatbot, la información de contexto del usuario se puede derivar de Cognito Amazonas. El chatbot de Amazon Lex se puede integrar en Amazon Kendra mediante una integración directa o a través de un AWS Lambda función. El uso de la función AWS Lambda le proporcionará un control detallado de las llamadas a la API de Amazon Kendra. Esto le permitirá pasar información contextual del chatbot de Amazon Lex a Amazon Kendra para afinar las consultas de búsqueda.
En Amazon Kendra, proporciona atributos de metadatos de documentos mediante atributos personalizados. Para personalizar los metadatos del documento durante el proceso de ingesta, consulte la Guía para desarrolladores de Amazon Kendra. Después de completar los pasos de indexación y generación de metadatos del documento, debe concentrarse en refinar los resultados de la búsqueda utilizando los atributos de los metadatos. Basándose en esto, por ejemplo, puede asegurarse de que los usuarios del departamento de informática obtendrán resultados de búsqueda clasificados según su relevancia para el departamento. Es decir, si hay un documento relevante para ese departamento, debe estar en la parte superior de la lista de resultados de búsqueda antes que cualquier otro documento sin información de departamento o departamento que no coincida.
Ahora exploremos cómo construir esta solución con más detalle.
Tutorial de la solución

Figura 1: Diagrama de arquitectura de la solución propuesta
La arquitectura de muestra utilizada en este blog para demostrar el caso de uso se muestra en la Figura 1. Configurará un índice de documentos de Amazon Kendra que consume datos de un Servicio de almacenamiento simple de Amazon (Amazon S3) cubeta. Configurará un chatbot simple con Amazon Lex que se conectará al índice de Amazon Kendra a través de una función de AWS Lambda. Los usuarios confiarán en Amazon Cognito para autenticarse y obtener acceso a la interfaz de usuario del chatbot de Amazon Lex. A los efectos de la demostración, tendrá dos usuarios diferentes en Amazon Cognito que pertenecen a dos departamentos diferentes. Con esta configuración, cuando inicia sesión con el Usuario 1 en el Departamento A, los resultados de la búsqueda serán documentos filtrados que pertenecen al Departamento A y viceversa para los usuarios del Departamento B.
Requisitos previos
Antes de que pueda intentar integrar el chatbot de Amazon Lex con un índice de Amazon Kendra, debe configurar los componentes básicos de la solución. En un nivel alto, debe realizar los siguientes pasos para habilitar esta demostración:
- Configure una fuente de datos de depósito de S3 con los documentos y la estructura de carpetas adecuados. Para obtener instrucciones sobre cómo crear depósitos S3, consulte Documentación de AWS: creación de un depósito. Almacene los metadatos del documento necesarios junto con los documentos de forma estática en el depósito de S3. Para comprender cómo almacenar metadatos de documentos para sus documentos en el depósito S3, consulte Documentación de AWS: metadatos de documentos de Amazon S3. Un archivo de metadatos de muestra podría parecerse al siguiente:
- Configure un índice de Amazon Kendra siguiendo las Documentación de AWS: creación de un índice.
- Agregue el depósito S3 como fuente de datos a su índice siguiendo las Documentación de AWS: uso de una fuente de datos de Amazon S3. Asegúrese de que Amazon Kendra conozca la información de los metadatos y permita que la información del departamento sea facetada.
- Debe asegurarse de que los atributos personalizados en el índice de Amazon Kendra estén configurados para ser facetable, buscable y visualizable. Puede hacerlo en la consola de Amazon Kendra, yendo a Gestión de datos y eligiendo Definición de faceta. Para hacer esto utilizando la interfaz de línea de comandos de AWS (AWS CLI), puede aprovechar el índice de actualización de Kendra mando.
- Configure un grupo de usuarios de Amazon Cognito con dos usuarios. Asocie un atributo personalizado con el usuario para capturar los valores de su departamento.
- Cree un bot de chat simple de Amazon Lex v2 con las intenciones, los espacios y las declaraciones necesarios para impulsar el caso de uso. En este blog, no proporcionaremos una guía detallada sobre la configuración del bot básico, ya que el objetivo del blog es comprender cómo enviar información de contexto del usuario desde el front-end al índice de Amazon Kendra. Para obtener detalles sobre cómo crear un bot de Amazon Lex simple, consulte el Creación de documentación de bots. Para el resto del blog, se supone que el chatbot de Amazon Lex tiene lo siguiente:
- Intención – Cursos de búsqueda
- Enunciado: "¿Qué cursos están disponibles en {subject_types}?"
- Slot – elective_year (puede tener valores – elective, nonelective)
- Debe crear una interfaz de chatbot que el usuario usará para autenticarse e interactuar con el chatbot. Puedes usar el Muestra de la interfaz web de Amazon Lex (lex-web-ui) proporcionado por AWS para comenzar. Esto simplificará el proceso de prueba de las integraciones, ya que ya integra Amazon Cognito para la autenticación de usuarios y pasa la información contextual requerida y el token de identidad de Amazon Cognito JWT al chatbot de Amazon Lex.
Una vez que los componentes básicos estén en su lugar, su próximo paso será crear la función AWS Lambda que vinculará el cumplimiento de la intención del chatbot de Amazon Lex con el índice de Amazon Kendra. El resto de este blog se centrará específicamente en este paso y brindará detalles sobre cómo lograr esta integración.
Integración de Amazon Lex con Amazon Kendra para pasar el contexto del usuario
Ahora que se cumplen los requisitos previos, puede comenzar a trabajar en la integración de su chatbot de Amazon Lex con el índice de Amazon Kendra. Como parte de la integración, deberá realizar las siguientes tareas:
- Escriba una función AWS Lambda que será adjunto a su chatbot de Amazon Lex. En esta función de Lambda, analizará el evento de entrada entrante para extraer la información del usuario, como el ID de usuario y atributos adicionales para el usuario del token de identidad de Amazon Cognito que se pasa como parte de los atributos de sesión en el objeto de evento.
- Una vez que toda la información para formar la consulta de Amazon Kendra está en su lugar, envía una consulta al índice de Amazon Kendra, incluidos todos los atributos personalizados que desea usar para reducir el alcance de la vista de resultados de búsqueda.
- Finalmente, una vez que la consulta de Amazon Kendra devuelve los resultados, genera un objeto de respuesta de Amazon Lex adecuado para enviar la respuesta de los resultados de búsqueda al usuario.
- Asocie la función AWS Lambda con el chatbot de Amazon Lex para que cada vez que el chatbot reciba una consulta del usuario, active la función AWS Lambda.
Veamos estos pasos con más detalle a continuación.
Extracción del contexto del usuario en la función AWS Lambda
Lo primero que debe hacer es codificar y configurar la función Lambda que puede actuar como un puente entre la intención del chatbot de Amazon Lex y el índice de Amazon Kendra. El formato de evento de entrada La documentación proporciona la estructura de eventos de entrada de notación de objetos Javascript (JSON) de entrada completa. Si el sistema de autenticación proporciona el ID de usuario como una solicitud HTTP POST a Amazon Lex, el valor estará disponible en el “userId” clave del objeto JSON. Cuando la autenticación se realiza mediante Amazon Cognito, el “sessionState”.”sessionAttributes”.”idtokenjwt” key contendrá un objeto de token JSON Web Token (JWT). Si está programando la función AWS Lambda en Python, las dos líneas de código para leer los atributos del objeto de evento serán las siguientes:
El token JWT está codificado. Una vez que haya decodificado el token JWT, podrá leer el valor del atributo personalizado asociado con el usuario de Amazon Cognito. Referirse a ¿Cómo puedo descodificar y verificar la firma de un token web JSON de Amazon Cognito? para comprender cómo descodificar el token JWT, verificarlo y recuperar los valores personalizados. Una vez que tenga los reclamos del token, puede extraer el atributo personalizado, como “department” en Python, de la siguiente manera:
Cuando utilice un proveedor de identidad (IDP) de terceros para autenticarse en el chatbot, debe asegurarse de que el IDP envíe un token con los atributos requeridos. El token debe incluir los datos necesarios para los atributos personalizados, como departamento, pertenencia a grupos, etc. Esto se pasará al chatbot de Amazon Lex en las variables de contexto de la sesión. Si está utilizando lex-web-ui como interfaz de chatbot, consulte el sección de gestión de credenciales del archivo Léame de lex-web-ui documentación para comprender cómo se integra Amazon Cognito con lex-web-ui. Para comprender cómo puede integrar proveedores de identidades de terceros con un grupo de identidades de Amazon Cognito, consulte la documentación en Grupos de identidades (identidades federadas) proveedores de identidades externas.
Para el tema de consulta del usuario, puede extraer del objeto de evento leyendo el valor de las ranuras identificadas por Amazon Lex. El valor real de la ranura se puede leer desde el atributo con la clave “sessionState”.”intent”.”slots”.”slot name”.”value”.”interpretedValue” en función del tipo de datos identificado. En el ejemplo de este blog, usando Python, podría usar las siguientes líneas de código para leer los valores de la consulta:
Como se describe en el documentación para el formato de evento de entrada, el valor de las ranuras es un objeto que puede tener múltiples entradas de diferentes tipos de datos. El tipo de datos para cualquier valor dado se indicará mediante “'sessionState”.”intent”.”slots”.”slot name”.”shape”. Si el atributo está vacío o falta, entonces el tipo de datos es una cadena. En el ejemplo de este blog, usando Python, podría usar las siguientes líneas de código para leer los valores de la consulta:
Una vez que conozca el formato de datos para la ranura, puede interpretar el valor de 'valorranura' basado en el tipo de datos identificado en 'tipo de ranura'.
Consulta el índice de Amazon Kendra desde AWS Lambda
Ahora que logró extraer toda la información relevante del objeto de evento de entrada, debe construir una consulta de Amazon Kendra dentro de Lambda. Amazon Kendra le permite filtrar consultas a través de atributos específicos. Cuando envía una consulta a Amazon Kendra utilizando el API de consulta, puede proporcionar un atributo de documento como filtro de atributo para que los resultados de búsqueda de sus usuarios se basen en valores que coincidan con ese filtro. Los filtros se pueden combinar lógicamente cuando necesite consultar una jerarquía de atributos. Una consulta filtrada de muestra tendrá el siguiente aspecto:
Para comprender el filtrado de consultas en Amazon Kendra con más detalle, puede consultar Documentación de AWS: consultas de filtrado. En función de la consulta anterior, los resultados de búsqueda de Amazon Kendra se analizarán para incluir documentos en los que el atributo de metadatos para "documento" coincide con el valor del filtro proporcionado. En Python, esto se verá de la siguiente manera:
Como se destacó anteriormente, consulte API de consulta de Amazon Kendra documentación para comprender todos los diversos atributos que se pueden proporcionar en la consulta, incluidas las condiciones de filtro complejas para filtrar la búsqueda del usuario.
Manejar la respuesta de Amazon Kendra en la función AWS Lambda
Tras una consulta exitosa dentro del índice de Amazon Kendra, recibirá un objeto JSON como respuesta de la API de consulta. La estructura completa del objeto de respuesta, incluidos todos los detalles de sus atributos, se enumeran en el API de consulta de Amazon Kendra documentación. Puedes leer el “TotalNumberOfResults” para verificar el número total de resultados devueltos para la consulta que envió. Tenga en cuenta que el SDK solo le permitirá recuperar hasta un máximo de 100 elementos. Los resultados de la consulta se devuelven en el “ResultItems” atributo como una matriz de "Elemento de resultado de consulta" objetos. Desde el “QueryResultItem”, los atributos de interés inmediato son “DocumentTitle”, “DocumentExcerpt”y “DocumentURI”. En Python, puede usar el siguiente código para extraer estos valores de la primera “ResultItems” en la respuesta de Amazon Kendra:
Idealmente, debe comprobar el valor de “TotalNumberOfResults” e iterar a través del “ResultItems” matriz para recuperar todos los resultados de interés. Luego, debe empaquetarlo correctamente en un objeto de respuesta de AWS Lambda válido para enviarlo al chatbot de Amazon Lex. La estructura de la respuesta esperada del chatbot de Amazon Lex v2 se documenta en el Sección de formato de respuesta. Como mínimo, debe completar los siguientes atributos en el objeto de respuesta antes de devolverlo al chatbot:
- objeto sessionState – El atributo obligatorio en este objeto es
“dialogAction”. Esto se usará para definir a qué estado/acción debe pasar el chatbot a continuación. Si este es el final de la conversación porque ha obtenido todos los resultados requeridos y está listo para presentar, la configurará para que se cierre. Debe indicar con qué intención en el chatbot está relacionada su respuesta y cuál es el estado de cumplimiento al que el chatbot necesita hacer la transición. Esto puede hacerse de la siguiente manera:
- objeto de mensajes – Debe volver a enviar los resultados de su búsqueda al chatbot completando el objeto de mensajes en la respuesta en función de los valores que extrajo de la consulta de Amazon Kendra. Puede usar el siguiente código como ejemplo para lograr esto:
Conexión de la función AWS Lambda con el chatbot de Amazon Lex
En este punto, tiene una función de AWS Lambda completa que puede extraer el contexto del usuario del evento entrante, realizar una consulta filtrada en Amazon Kendra según el contexto del usuario y responder al chatbot de Amazon Lex. El siguiente paso es configurar el chatbot de Amazon Lex para usar esta función de AWS Lambda como parte del proceso de cumplimiento de intenciones. Puede lograr esto siguiendo los pasos documentados en Adjuntar una función Lambda a un alias de bot. En este punto, ahora tiene un chatbot de Amazon Lex completamente funcional integrado con el índice de Amazon Kendra que puede realizar consultas contextuales basadas en la interacción del usuario con el chatbot.
En nuestro ejemplo, tenemos 2 usuarios, Usuario 1 y Usuario 2. El Usuario 1 es del departamento de informática y el Usuario 2 es del departamento de ingeniería civil. En función de su información contextual relacionada con el departamento, la Figura 2 mostrará cómo la misma conversación puede generar resultados diferentes en una captura de pantalla en paralelo de dos interacciones de chatbot:
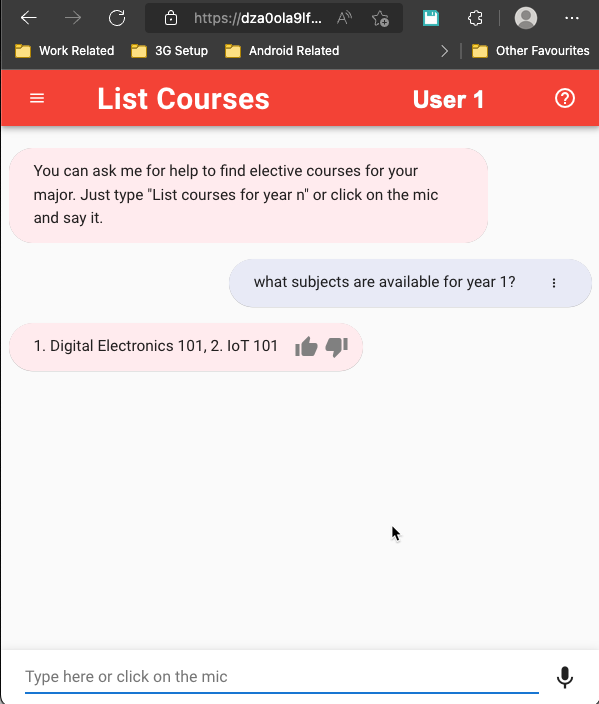 |
 |
Figura 2: Comparación en paralelo de varias sesiones de chat de usuarios
Limpiar
Si siguió la configuración de ejemplo, debe limpiar los recursos que creó para evitar cargos adicionales a largo plazo. Para realizar una limpieza de los recursos, debe:
- Eliminar el índice de Amazon Kendra y la fuente de datos de Amazon S3 asociada
- Eliminar el chatbot de Amazon Lex
- Vaciar el cubo S3
- Eliminar el cubo S3
- Elimine la función Lambda siguiendo las Sección de limpieza.
- Elimine los recursos de lex-web-ui eliminando los asociados Formación en la nube de AWS montón
- Eliminar los recursos de Amazon Cognito
Conclusión
Amazon Kendra es un servicio de búsqueda empresarial de alta precisión. La combinación de su función de procesamiento de lenguaje natural con un chatbot inteligente crea una solución robusta para cualquier caso de uso que necesite resultados personalizados basados en el contexto del usuario. Aquí consideramos un caso de uso de muestra de una organización con varios departamentos, pero este mecanismo se puede aplicar a cualquier otro caso de uso relevante con cambios mínimos.
¿Listo para comenzar? El Grupo empresarial Accenture AWS (AABG) ayuda a los clientes a acelerar su ritmo de innovación digital y obtener un valor comercial incremental a partir de la adopción y transformación de la nube. Conéctate con nuestro equipo en Accentureaws@amazon.com para aprender a crear soluciones de chatbot inteligentes para sus clientes.
Sobre la autora
 Rohit Satyana Rayana es arquitecto de soluciones de socios en AWS en Singapur y forma parte del equipo de AWS GSI que trabaja con Accenture a nivel mundial. Sus hobbies son leer fantasía y ciencia ficción, ver películas y escuchar música.
Rohit Satyana Rayana es arquitecto de soluciones de socios en AWS en Singapur y forma parte del equipo de AWS GSI que trabaja con Accenture a nivel mundial. Sus hobbies son leer fantasía y ciencia ficción, ver películas y escuchar música.
 leo un es un Arquitecto de Soluciones Sénior que ha demostrado la capacidad de diseñar y ofrecer soluciones de infraestructura rentables y de alto rendimiento en una nube pública y privada. Le gusta ayudar a los clientes a usar tecnologías en la nube para abordar sus desafíos comerciales y está especializado en aprendizaje automático y se enfoca en ayudar a los clientes a aprovechar AI/ML para sus resultados comerciales.
leo un es un Arquitecto de Soluciones Sénior que ha demostrado la capacidad de diseñar y ofrecer soluciones de infraestructura rentables y de alto rendimiento en una nube pública y privada. Le gusta ayudar a los clientes a usar tecnologías en la nube para abordar sus desafíos comerciales y está especializado en aprendizaje automático y se enfoca en ayudar a los clientes a aprovechar AI/ML para sus resultados comerciales.
 Hemalatha Katari es Arquitecto de Soluciones en Accenture. Forma parte del equipo de creación rápida de prototipos dentro de Accenture AWS Business Group (AABG). Ayuda a las organizaciones a migrar y administrar sus negocios en la nube de AWS. Le gusta cultivar plantas ornamentales de interior y le encanta dar largos paseos por senderos naturales.
Hemalatha Katari es Arquitecto de Soluciones en Accenture. Forma parte del equipo de creación rápida de prototipos dentro de Accenture AWS Business Group (AABG). Ayuda a las organizaciones a migrar y administrar sus negocios en la nube de AWS. Le gusta cultivar plantas ornamentales de interior y le encanta dar largos paseos por senderos naturales.
 Sruthi Mamidipalli es arquitecta de soluciones de AWS en Accenture, donde ayuda a los clientes a adoptar con éxito la arquitectura nativa de la nube. Fuera del trabajo, le encanta la jardinería, cocinar y pasar tiempo con su hijo pequeño.
Sruthi Mamidipalli es arquitecta de soluciones de AWS en Accenture, donde ayuda a los clientes a adoptar con éxito la arquitectura nativa de la nube. Fuera del trabajo, le encanta la jardinería, cocinar y pasar tiempo con su hijo pequeño.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/building-ai-chatbots-using-amazon-lex-and-amazon-kendra-for-filtering-query-results-based-on-user-context/

