El cálculo con la granularidad correcta siempre debe manejarse con cuidado al realizar análisis de datos. Especialmente cuando los datos se generan mediante la combinación de varias tablas, la desnormalización de los conjuntos de datos puede agregar muchas complicaciones para hacer que los cálculos precisos sean un desafío. Amazon QuickSight lanzó recientemente una nueva funcionalidad llamada cálculos conscientes del nivel (LAC), que le permite especificar cualquier nivel de granularidad en el que desea que se realicen las funciones agregadas (en qué nivel agrupar) o las funciones de ventana (en qué ventana particionar). Esto aporta flexibilidad y simplificación para que pueda crear cálculos avanzados y análisis potentes. Sin LAC, debe preparar tablas previamente agregadas en su fuente de datos original o ejecutar consultas en la fase de preparación de datos para habilitar esos cálculos.
En esta publicación, demostramos cómo crear conocimientos avanzados utilizando LAC en QuickSight. Antes de comenzar a recorrer las funciones, primero presentemos el importante concepto de orden de evaluación en QuickSight y luego hablemos sobre LAC con más detalle.
Orden de evaluación QuickSight
Cada vez que abre o actualiza un análisis, QuickSight evalúa todo lo que está configurado en el análisis en una secuencia específica y traduce la configuración en una consulta que puede ejecutar un motor de base de datos. Este es el orden de evaluación. El nivel de complicación depende de cuántos elementos están incrustados en una imagen, multiplicados por la cantidad de imágenes más las interacciones entre las imágenes. Pero si abstraemos el concepto, el orden de la lógica de evaluación se puede demostrar mediante el siguiente cuadro.
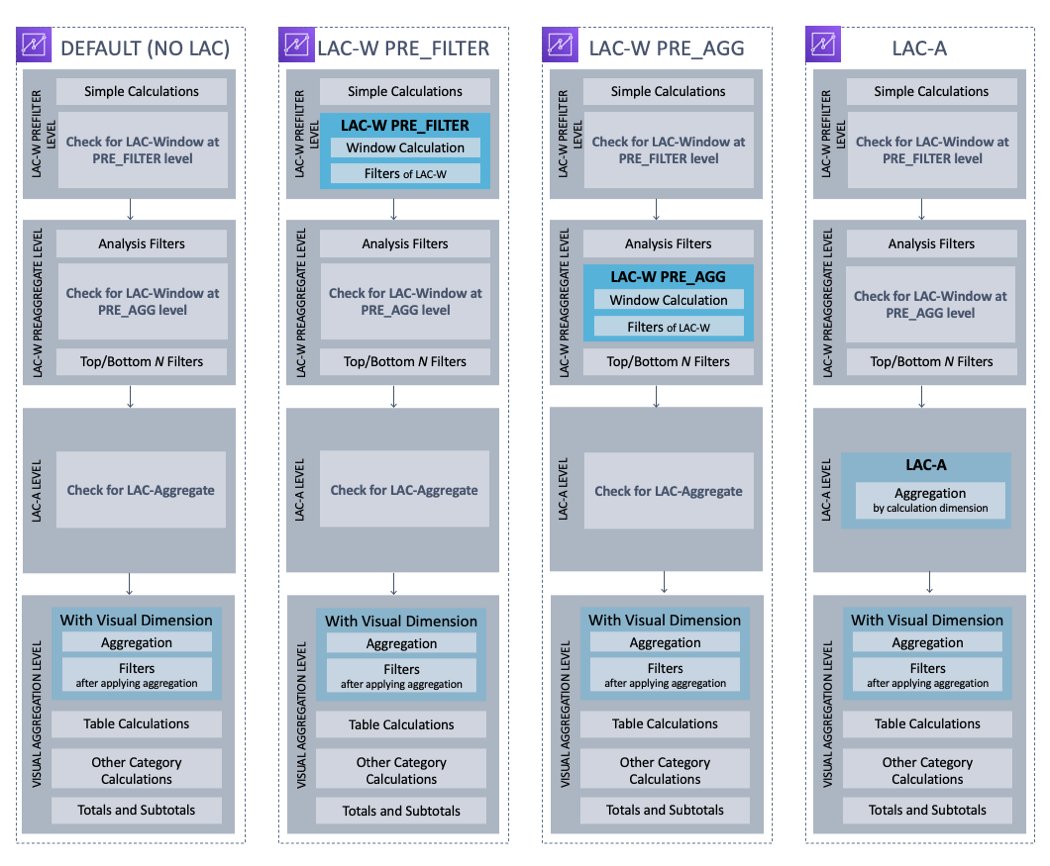
En la primera ruta DEFAULT, QuickSight evalúa cálculos simples a nivel de fila para el conjunto de datos sin procesar, luego aplica los filtros WHERE. Después de eso, en función de las dimensiones que se agregan al objeto visual, QuickSight evalúa la agregación de las medidas seleccionadas en las dimensiones visuales y aplica filtros HAVING. Los cálculos de la tabla, como el total acumulado o el porcentaje del total, se evalúan después de que se forma el objeto visual, con el subtotal y el total calculados en último lugar.
A veces, es posible que desee que los pasos analíticos se lleven a cabo con una secuencia diferente. Por ejemplo, es posible que desee realizar una agregación antes de que se filtren los datos, o realizar una agregación primero para algunas dimensiones específicas y luego agregar nuevamente para las dimensiones visuales. Basado en esas diferentes necesidades, QuickSight ofrece tres variaciones de orden de evaluación (como se muestra en el gráfico anterior). Específicamente, puede usar las palabras clave de PRE_FILTER para agregar un paso de cálculo antes del filtro WHERE, usar PRE_AGG para agregar un paso de cálculo antes de la agregación visual o usar un conjunto completo de funciones de agregación de cálculo con reconocimiento de nivel para definir una agregación en dimensiones independientes y luego agregarlas en la dimensión visual (una agregación anidada).
La mayoría de las veces, sus imágenes incluirán más de un campo calculado. Deberá tener cuidado al definir cada uno de ellos y comprender cómo interactúan con las imágenes y con los diferentes filtros. Aplicar un filtro antes o después de una función de ventana puede generar resultados y significados comerciales totalmente diferentes.
Con todos los antecedentes presentados, ahora hablemos sobre las nuevas funciones de LAC y sus capacidades, y demostremos varios casos de uso típicos.
Cálculos conscientes del nivel (LAC)
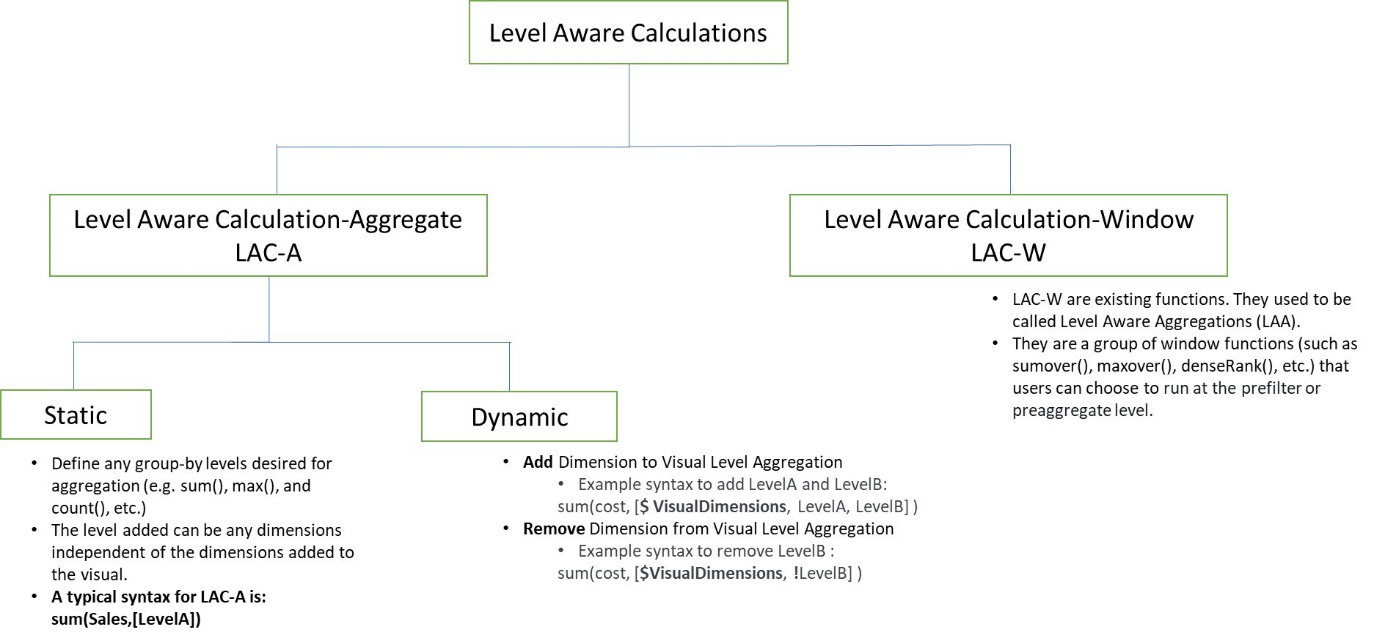
Hay dos grupos de funciones LAC:
- Cálculos conscientes del nivel: funciones agregadas (LAC-A) – Estas son nuestras funciones recién lanzadas. Al agregar un argumento a una función agregada existente (por ejemplo,
sum(),max()ocount()), puede definir cualquier dimensión de grupo que desee para la agregación. Una sintaxis típica para LAC-A essum(measure,[group_field_A]). Con LAC-A, puede agregar un paso de agregación antes de la agregación visual. La capa añadida se puede arreglar, lo cual es independiente de la dimensión visual. También puede interactuar dinámicamente con las dimensiones visuales. Damos algunos ejemplos detallados más adelante en esta publicación. Para obtener una lista de las funciones de agregación admitidas, consulte Cálculo consciente del nivel: funciones agregadas (LAC-A). - Funciones de ventana de cálculo conscientes del nivel (LAC-W) – Estas son las funciones existentes. Solían llamarse agregaciones conscientes del nivel (LAA). Recientemente cambiamos su nombre para reflejar mejor la naturaleza de la función, debido a la diferencia subyacente entre las funciones de ventana y las funciones agregadas. LAC-W es un grupo de funciones de ventana (como
sumover(),maxover()ydenseRank()) donde, utilizando un tercer parámetro, puede optar por ejecutar el cálculo en la etapa PRE_FILTER o PRE-AGG. Una sintaxis típica para LAC-W essumOver(measure,[partition_field_A],pre_agg). Para obtener una lista de las funciones de ventana admitidas, consulte Cálculo consciente del nivel: funciones de ventana (LAC-W).
El siguiente diagrama de alto nivel muestra diferentes ramas de LAC. En esta publicación, nos enfocamos principalmente en las nuevas funciones de LAC-A.
Con las nuevas funciones de LAC-A, puede ejecutar dos capas de cálculos de agregación. Esto ofrece los siguientes beneficios:
- Ejecute cálculos de agregación que sean independientes de los campos de agrupación en el cálculo visual
- Ejecute cálculos de agregación para las dimensiones que NO están en el objeto visual
- Elimine la duplicación de datos sin procesar antes de ejecutar los cálculos
- Ejecute cálculos de agregación con campos agrupados anidados que se adaptan dinámicamente a campos visuales agrupados
Exploremos cómo podemos lograr esos beneficios demostrando algunos casos de uso.
Caso de uso n.º 1: identificar pedidos en los que la cantidad real ordenada de un producto es mayor que la cantidad promedio
En este caso, nuestro visual está a nivel de orden; sin embargo, queremos calcular la cantidad promedio de un producto y usarla para mostrar la diferencia en cada fila individual/nivel de pedido. Con la función LAC-A, podemos crear fácilmente una agregación que sea independiente del nivel en el visual.
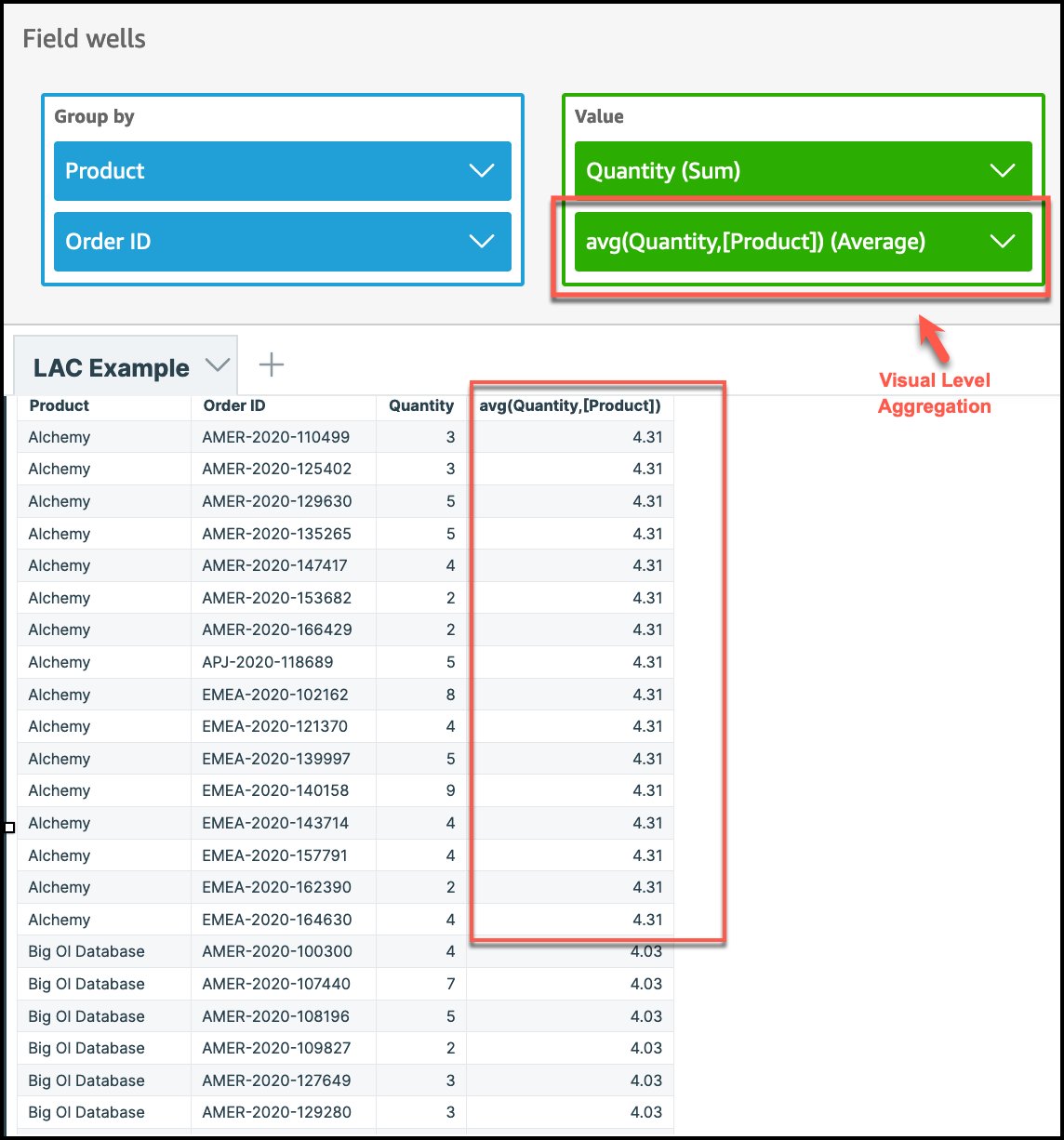
Primero calculamos la cantidad promedio vendida a nivel de producto usando la expresión de avg(Quantity,[Product]). Para hacerlo, cambie la agregación de nivel visual a Normal. En este caso, la agregación a nivel visual no importa porque tenemos product como columna y el LAC-A están al mismo nivel. En la tabla de resultados, el valor de cantidad promedio para product se repite en todos los pedidos porque se calcula a nivel de producto.
Ahora que hemos calculado la cantidad promedio a nivel de producto, podemos extender esto para calcular la diferencia entre la cantidad real ordenada y la cantidad promedio de producto usando la expresión sum(Quantity) - avg(avg(Quantity,[Product])). Esta diferencia calculada se puede usar para formatear condicionalmente la vista para resaltar los pedidos que tienen una cantidad mayor que la cantidad promedio de un producto.
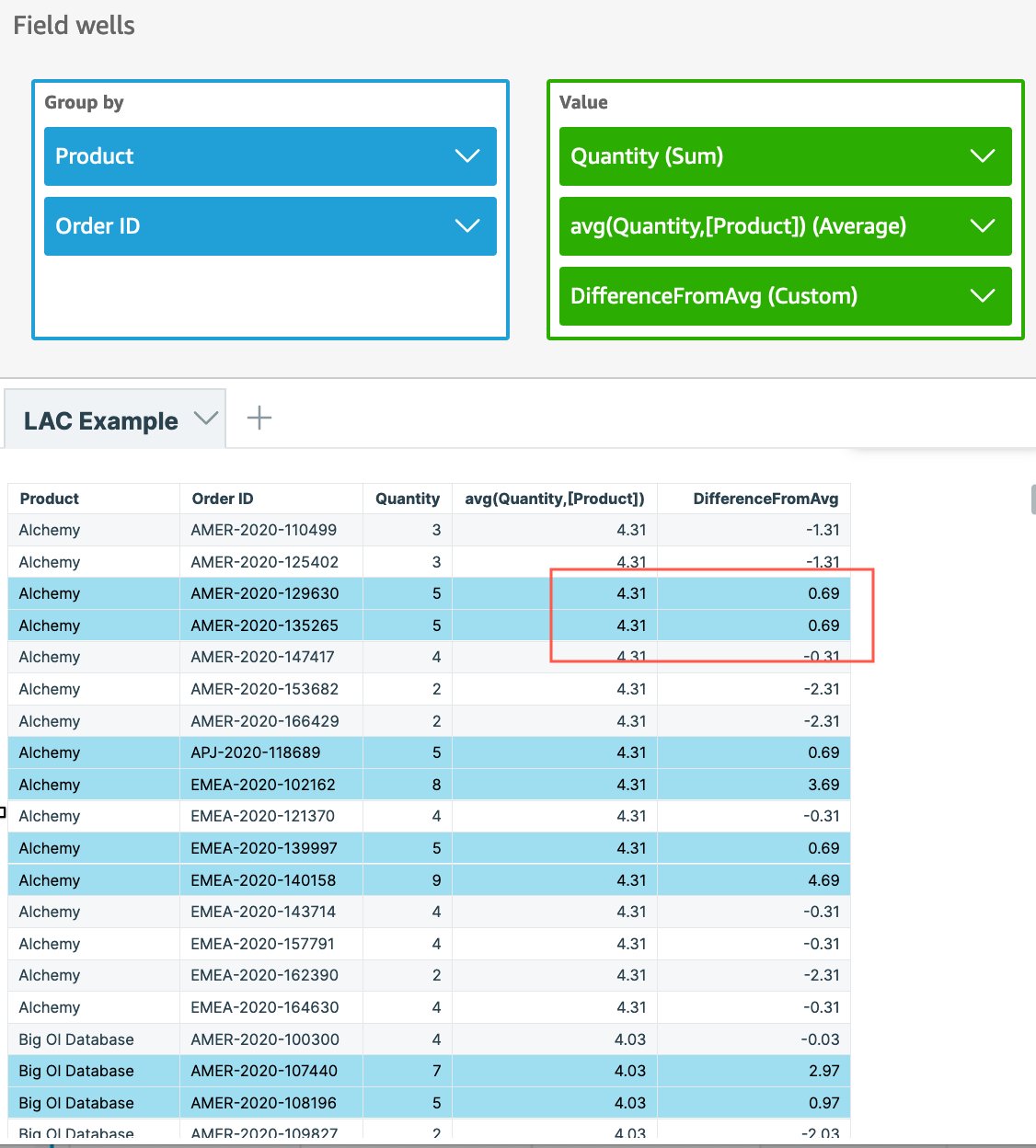
Como se ve en este ejemplo, aunque el objeto visual estaba en el nivel de pedido, creamos fácilmente una agregación como cantidad promedio de producto, que es independiente del nivel en el objeto visual, y la usamos para mostrar la diferencia en cada nivel de fila/pedido individual. .
Caso de uso #2: Identifique el promedio de las ventas totales del país por región
Aquí queremos agregar las ventas de cada país y luego calcular el promedio de ventas a nivel de país a nivel de región utilizando el mismo conjunto de datos.
Con la función LAC-A, podemos crear fácilmente una agregación en un nivel de dimensión que NO está en el objeto visual. En este ejemplo, aunque country no está incluido en el visual, la función LAC-A primero agrega las ventas a nivel de país y luego el cálculo a nivel visual genera el número promedio para cada región. Dentro de QuickSight, podemos implementar esto de dos maneras.
Opción 1: anide el LAC-A con funciones agregadas de nivel visual
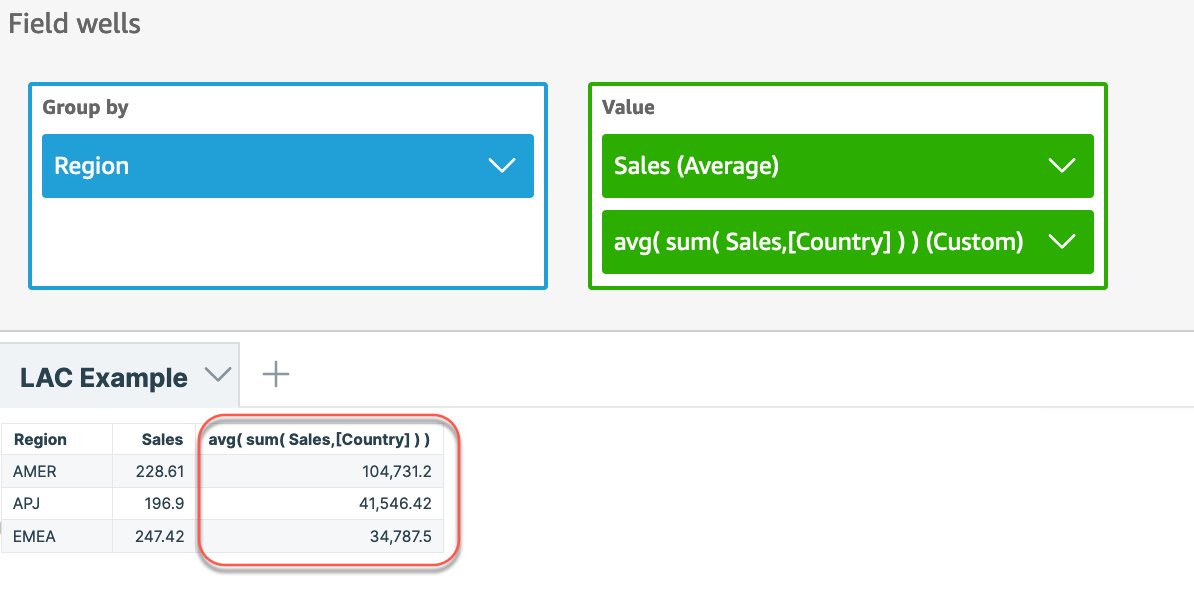
Cree una columna calculada para computar las ventas a nivel de país usando la expresión de sum(Sales,[Country] ), luego agregue el cálculo al objeto visual y cambie la agregación a Normal, como se muestra en la siguiente captura de pantalla. Tenga en cuenta que si no usamos LAC-A para especificar el nivel, las ventas promedio se calculan en el nivel granular más bajo (el nivel base del conjunto de datos) para cada región. Es por eso que los números son significativamente más pequeños para el sales columna.

Opción 2: Usar LAC-A combinado con otras funciones agregadas y anidarlas en la columna calculada
Cree una columna calculada para computar las ventas a nivel de país usando la expresión sum(Sales,[Country]) y luego anide eso con agregación adicional, en este caso Normal, usando la expresión avg(sum(Sales,[Country])).
Caso de uso #3: Calcule el total y el promedio para un conjunto de datos desnormalizados con duplicaciones
Los cálculos de LAC-A están diseñados para manejar de manera efectiva los datos duplicados mientras se realizan los cálculos. Le permite realizar cálculos como el promedio sin la necesidad de un manejo explícito de duplicados en los datos.
Considere un conjunto de datos que tenga detalles de empleados y proyectos junto con el salario de cada empleado. Un empleado puede estar asociado con múltiples proyectos, como se muestra en el siguiente ejemplo.
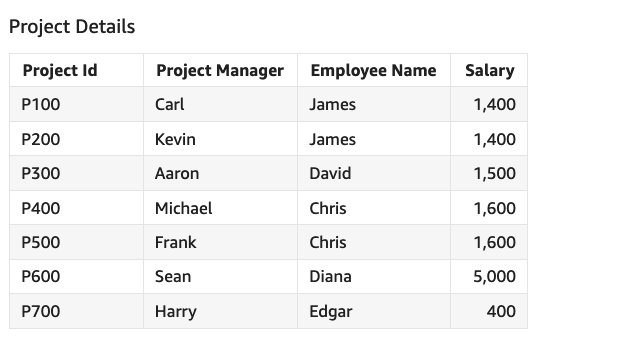
Ahora calculemos el salario total de los empleados, el salario promedio de los empleados y el salario mínimo y máximo utilizando este conjunto de datos de muestra.
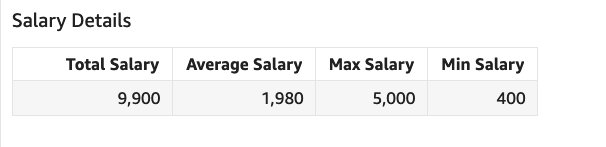
Para calcular el total y el promedio, debemos considerar el salario de cada empleado solo una vez, aunque un empleado puede ser parte de varios proyectos y el salario del empleado puede duplicarse en estos proyectos. Podemos lograr esto fácilmente usando LAC-A para calcular el salario máximo a nivel de empleado y luego usarlo para calcular el total y el promedio.
Cree una columna calculada llamada Salario total usando la expresión sum(max(Salary,[{Employee Name}])) y crea otra columna calculada llamada Salario promedio usando avg(max(Salary,[{Employee Name}])). Fácilmente podemos calcular Salario mínimo usando la expresión min(Salary) y Salario máximo usando max(Salary).
Si tratamos de resolver esto sin usar LAC-A, tenemos que manejar explícitamente la duplicación de salarios en nuestro cálculo, y tenemos que seguir varios pasos para llegar al resultado final. Consulte el blog de QuickSight Community para obtener una caso de uso similar.
Teclas de grupo dinámico para LAC-A
Además de definir un nivel estático de agregación como se ve en los ejemplos anteriores, también puede agregar o eliminar dinámicamente dimensiones de los campos de agrupación del nivel visual. Los siguientes son ejemplos de sintaxis para un nivel dinámico:
- Agregue dimensiones a las dimensiones visuales con
sum(cost, [$VisualDimensions, LevelA, LevelB]) - Eliminar dimensiones de las dimensiones visuales con
sum(cost, [$VisualDimensions, !LevelC, !LevelD])
Esta capacidad brinda mucha flexibilidad y escalabilidad para que usted pueda hacer que el LAC sea aún más poderoso. En primer lugar, puede definir un campo calculado de LAC y reutilizarlo en varios elementos visuales con intenciones comerciales similares. Además, si está creando los elementos visuales y continúa agregando o eliminando campos visuales, no necesita editar el campo calculado de LAC-A cada vez, y LAC-A se ajustará automáticamente a las dimensiones visuales y le dará el valor correcto. producción.
Caso de uso #4: Identifique las ventas promedio de los clientes dentro de cada región o país
Para calcular esto, podemos usar la expresión dinámica Sum(Sales, [$VisualDimensions, Customers]). Esto se debe a que cada cliente tiene compras en más de una región. Necesitamos calcular las ventas promedio de los clientes solo dentro de cada región. Podemos reutilizar la misma expresión en una imagen diferente con country como la dimensión visual si queremos calcular las ventas promedio de los clientes dentro de cada país.
Uso Normal como la métrica de nivel visual con Agrupar por as Región para obtener el promedio a nivel de la región. En este caso, “$visualDimensions” se adapta a Region. Entonces la expresión es equivalente a Sum(Sales, [Region, Customers]) en este visual.
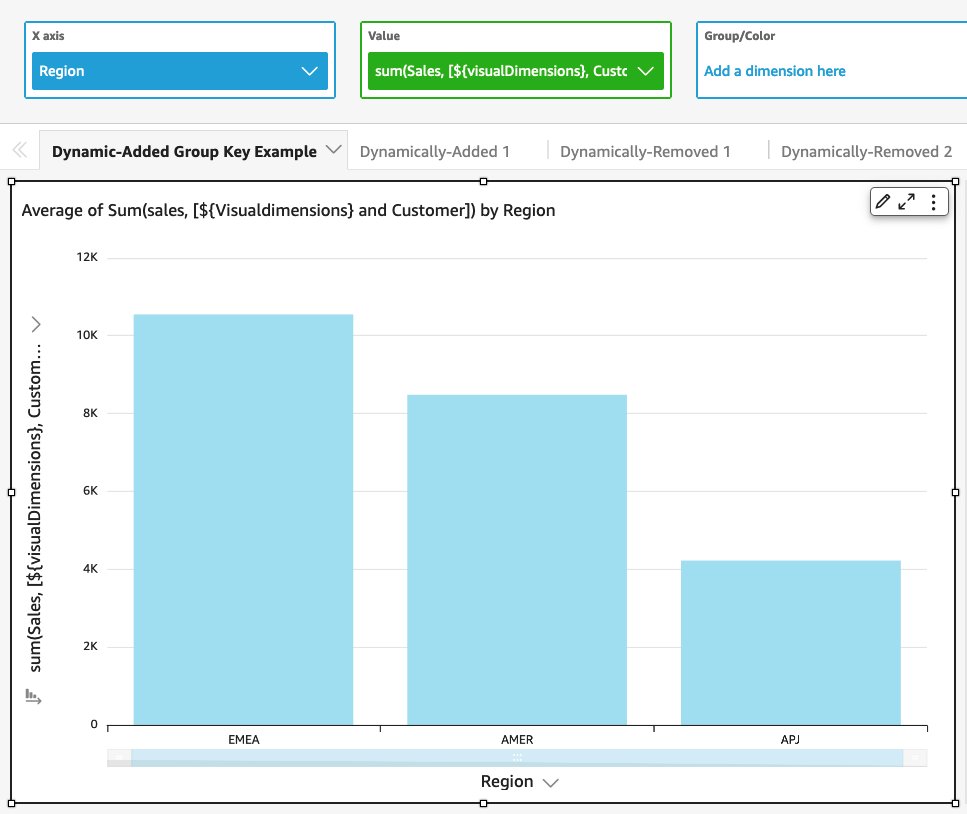
Si tienes una imagen similar con el Country dimensión, entonces la expresión dinámica es equivalente a Sum(Sales, [Country, Customers]). Reutilizar la misma expresión en diferentes imágenes nos ahorra mucho tiempo, especialmente cuando queremos crear imágenes similares con un contexto comercial ligeramente diferente.
Caso de uso n.º 5: identifique el porcentaje de ventas de cada subregión en comparación con el nivel de región
En este ejemplo, queremos calcular el porcentaje de ventas de cada subregión, comparándolo con las ventas totales de la región. Puede usar la dimensión fija como mencionamos antes, pero imagine una situación en la que desee incluir más dimensiones en la imagen, como producto, año o proveedor. El uso de la clave de grupo dinámico eliminando solo {subregion} de las dimensiones visuales hace que el proceso de exploración sea mucho más fácil y rápido.
Primero, cree una expresión para calcular la suma de las ventas sin el nivel de subregión usando sum(Sales, [$visualDimensions, !subregion]), luego calcule el porcentaje usando sum(Sales) / sum(sum(Sales, [$visualDimensions, !subregion])).

Conclusión
En esta publicación, presentamos las nuevas funciones de QuickSight LAC-A, que permiten agregaciones potentes y avanzadas con dimensiones definidas por el usuario. Presentamos el orden de evaluación de QuickSight y analizamos tres casos de uso para claves estáticas LAC-A y dos casos de uso de claves dinámicas LAC-A. Los cálculos con reconocimiento de nivel ahora están disponibles de forma general en todas las regiones de QuickSight admitidas.
Esperamos sus comentarios e historias sobre cómo aplica estos cálculos para sus necesidades comerciales.
Acerca de los autores
 Karthik Tharmarajan es un arquitecto de soluciones especializado sénior para Amazon QuickSight. Karthik tiene más de 15 años de experiencia en la implementación de soluciones empresariales de inteligencia comercial (BI) y se especializa en la integración de soluciones de BI con aplicaciones comerciales y permite decisiones basadas en datos.
Karthik Tharmarajan es un arquitecto de soluciones especializado sénior para Amazon QuickSight. Karthik tiene más de 15 años de experiencia en la implementación de soluciones empresariales de inteligencia comercial (BI) y se especializa en la integración de soluciones de BI con aplicaciones comerciales y permite decisiones basadas en datos.
 emily zhu es gerente sénior de tecnología de productos en Amazon QuickSight, el servicio SaaS BI totalmente administrado y nativo de la nube de AWS. Dirige el desarrollo de la experiencia de análisis y consultas de QuickSight. Antes de unirse a AWS, trabajó en el programa de entrega de drones de Amazon Prime Air y en la empresa Boeing como estratega senior durante varios años. A Emily le apasiona el potencial de las soluciones de BI basadas en la nube y espera ayudar a los clientes a avanzar en la elaboración de su estrategia basada en datos.
emily zhu es gerente sénior de tecnología de productos en Amazon QuickSight, el servicio SaaS BI totalmente administrado y nativo de la nube de AWS. Dirige el desarrollo de la experiencia de análisis y consultas de QuickSight. Antes de unirse a AWS, trabajó en el programa de entrega de drones de Amazon Prime Air y en la empresa Boeing como estratega senior durante varios años. A Emily le apasiona el potencial de las soluciones de BI basadas en la nube y espera ayudar a los clientes a avanzar en la elaboración de su estrategia basada en datos.
 Feng Han es gerente de desarrollo de software en el equipo de AWS QuickSight Query Platform. Se centra en la plataforma de generación de consultas y el cálculo de funciones avanzadas, y está dirigiendo al equipo hacia la próxima generación de motores de cálculo.
Feng Han es gerente de desarrollo de software en el equipo de AWS QuickSight Query Platform. Se centra en la plataforma de generación de consultas y el cálculo de funciones avanzadas, y está dirigiendo al equipo hacia la próxima generación de motores de cálculo.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/create-advanced-insights-using-level-aware-calculations-in-amazon-quicksight/

