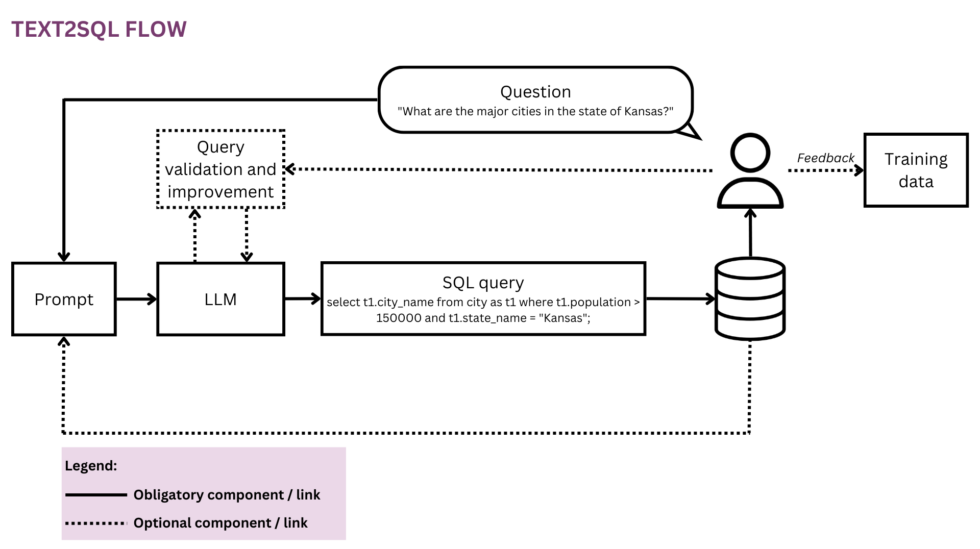
Figura 1: Representación del flujo Text2SQL
A medida que nuestro mundo se vuelve más global y dinámico, las empresas dependen cada vez más de los datos para tomar decisiones informadas, objetivas y oportunas. Sin embargo, a partir de ahora, liberar todo el potencial de los datos organizacionales suele ser un privilegio de un puñado de científicos y analistas de datos. La mayoría de los empleados no dominan el conjunto de herramientas de ciencia de datos convencional (SQL, Python, R, etc.). Para acceder a los datos deseados, pasan por una capa adicional donde los analistas o los equipos de BI “traducen” la prosa de las preguntas comerciales al lenguaje de los datos. El potencial de fricción e ineficiencia en este viaje es alto; por ejemplo, los datos pueden entregarse con retrasos o incluso cuando la pregunta ya se ha vuelto obsoleta. La información puede perderse en el camino cuando los requisitos no se traducen con precisión en consultas analíticas. Además, generar información de alta calidad requiere un enfoque iterativo que se desaconseja con cada paso adicional en el ciclo. Por otro lado, estas interacciones ad-hoc crean disrupción para el costoso talento de datos y los distraen del trabajo de datos más estratégico, como se describe en estas "confesiones" de un científico de datos:
Cuando estaba en Square y el equipo era más pequeño, teníamos una temida rotación de "análisis de guardia". Se rotaba estrictamente semanalmente, y si era su turno, sabía que haría muy poco trabajo "real" esa semana y pasaría la mayor parte de su tiempo respondiendo preguntas ad-hoc de los diversos equipos de productos y operaciones en el empresa (Moning SQL, lo llamamos). Hubo una competencia feroz por los puestos de gerente en el equipo de análisis y creo que esto se debió completamente a que los gerentes quedaron exentos de esta rotación: ningún premio de estatus podría rivalizar con la zanahoria de no hacer el trabajo de guardia.[1]
De hecho, ¿no sería genial hablar directamente con sus datos en lugar de tener que pasar por múltiples rondas de interacción con su personal de datos? Esta visión es adoptada por las interfaces conversacionales que permiten a los humanos interactuar con los datos utilizando el lenguaje, nuestro canal de comunicación más intuitivo y universal. Después de analizar una pregunta, un algoritmo la codifica en una forma lógica estructurada en el lenguaje de consulta elegido, como SQL. Por lo tanto, los usuarios no técnicos pueden chatear con sus datos y obtener rápidamente información específica, relevante y oportuna, sin desviarse a través de un equipo de BI. En este artículo, consideraremos los diferentes aspectos de implementación de Text2SQL y nos centraremos en los enfoques modernos con el uso de modelos de lenguaje grande (LLM), que logran el mejor rendimiento hasta el momento (cf. [2]; para una encuesta sobre enfoques alternativos más allá de los LLM, se hace referencia a los lectores [3]). El artículo está estructurado de acuerdo con el siguiente "modelo mental" de los principales elementos a considerar al planificar y construir una función de IA:
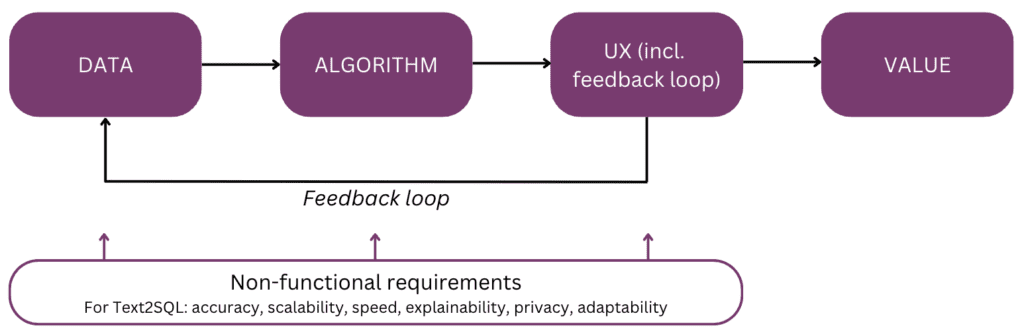
Comencemos con el final en mente y recapitulemos el valor: por qué crearía una función de Text2SQL en su producto de datos o análisis. Los tres principales beneficios son:
- Usuarios empresariales puede acceder a los datos de la organización de manera directa y oportuna.
- Esto alivia científicos y analistas de datos de la carga de las solicitudes ad-hoc de los usuarios comerciales y les permite concentrarse en los desafíos de datos avanzados.
- Esto permite que el para aprovechar sus datos de una manera más fluida y estratégica, convirtiéndolos finalmente en una base sólida para la toma de decisiones.
Ahora, ¿cuáles son los escenarios de productos en los que podría considerar Text2SQL? Los tres ajustes principales son:
- estas ofreciendo un producto escalable de datos/BI y desea permitir que más usuarios accedan a sus datos de una manera no técnica, aumentando así tanto el uso como la base de usuarios. Como ejemplo, ServiceNow tiene consultas de datos integradas en una oferta conversacional más grandey Atlan recientemente ha exploración de datos en lenguaje natural anunciada.
- Está buscando construir algo en el espacio de datos/IA para democratizar el acceso a los datos en las empresas, en cuyo caso podría considerar potencialmente un MVP con Text2SQL en el núcleo. Proveedores como AI2SQL y Texto2sql.ai ya están haciendo una entrada en este espacio.
- Estás trabajando en un sistema de BI personalizado y quieren maximizar y democratizar su uso en la empresa individual.
Como veremos en las siguientes secciones, Text2SQL requiere una configuración inicial no trivial. Para estimar el ROI, considere la naturaleza de las decisiones que se van a respaldar, así como los datos disponibles. Text2SQL puede ser una victoria absoluta en entornos dinámicos donde los datos cambian rápidamente y se utilizan de forma activa y frecuente en la toma de decisiones, como inversiones, marketing, fabricación y la industria energética. En estos entornos, las herramientas tradicionales para la gestión del conocimiento son demasiado estáticas y formas más fluidas de acceder a datos e información ayudan a las empresas a generar una ventaja competitiva. En términos de datos, Text2SQL proporciona el mayor valor con una base de datos que es:
- grande y en crecimiento, para que Text2SQL pueda desarrollar su valor con el tiempo a medida que se aprovechan más y más datos.
- Alta calidad, para que el algoritmo Text2SQL no tenga que lidiar con ruido excesivo (inconsistencias, valores vacíos, etc.) en los datos. En general, los datos generados automáticamente por las aplicaciones tienen una mayor calidad y consistencia que los datos creados y mantenidos por humanos.
- Semánticamente maduro a diferencia de crudo, para que los humanos puedan consultar los datos en función de conceptos centrales, relaciones y métricas que existen en su modelo mental. Tenga en cuenta que la madurez semántica se puede lograr mediante un paso de transformación adicional que conforma los datos sin procesar en una estructura conceptual (consulte la sección "Enriquecimiento del indicador con información de la base de datos").
A continuación, profundizaremos en los datos, el algoritmo, la experiencia del usuario, así como en los requisitos no funcionales relevantes de una característica de Text2SQL. El artículo está escrito para gerentes de producto, diseñadores de UX y aquellos científicos e ingenieros de datos que están al comienzo de su viaje Text2SQL. Para estas personas, proporciona no solo una guía para comenzar, sino también un terreno común de conocimiento para las discusiones sobre las interfaces entre el producto, la tecnología y el negocio, incluidas las compensaciones relacionadas. Si ya está más avanzado en su implementación, las referencias al final brindan una variedad de inmersiones profundas para explorar.
Si este contenido educativo en profundidad es útil para usted, puede suscríbete a nuestra lista de correo de investigación de IA ser alertado cuando lancemos nuevo material.
1. Datos
Cualquier esfuerzo de aprendizaje automático comienza con datos, por lo que comenzaremos aclarando la estructura de los datos de entrada y de destino que se utilizan durante el entrenamiento y la predicción. A lo largo del artículo, usaremos el flujo de Text2SQL de la Figura 1 como nuestra representación en ejecución y resaltaremos en amarillo los componentes y las relaciones considerados actualmente.
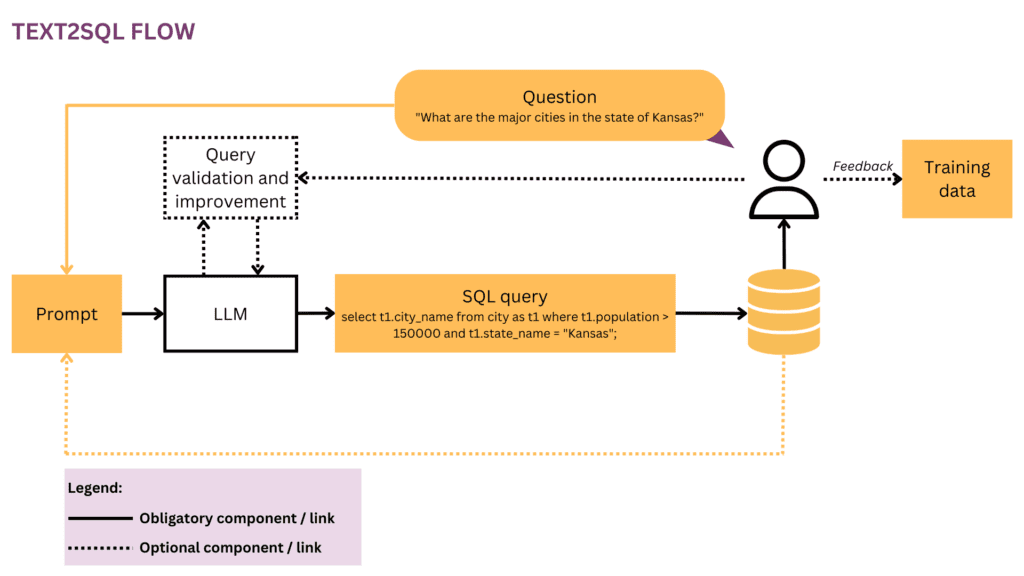
1.1 Formato y estructura de los datos
Por lo general, un par de entrada-salida Text2SQL sin procesar consta de una pregunta en lenguaje natural y la consulta SQL correspondiente, por ejemplo:
Pregunta"Enumere el nombre y el número de seguidores de cada usuario”.
Consulta SQL:
seleccionar nombre, seguidores de user_profiles
En el espacio de datos de entrenamiento, el mapeo entre preguntas y consultas SQL es de muchos a muchos:
- Una consulta SQL se puede asignar a muchas preguntas diferentes en lenguaje natural; por ejemplo, la semántica de consulta anterior se puede expresar mediante: “muéstrame los nombres y números de seguidores por usuario,¿Cuántos seguidores hay para cada usuario?”Etc.
- La sintaxis de SQL es muy versátil y casi todas las preguntas se pueden representar en SQL de varias maneras. El ejemplo más simple son los diferentes ordenamientos de las cláusulas WHERE. En una postura más avanzada, cualquiera que haya realizado la optimización de consultas SQL sabrá que muchos caminos conducen al mismo resultado, y las consultas semánticamente equivalentes pueden tener una sintaxis completamente diferente.
La recopilación manual de datos de entrenamiento para Text2SQL es particularmente tediosa. No solo requiere el dominio de SQL por parte del anotador, sino también más tiempo por ejemplo que las tareas lingüísticas más generales, como el análisis de opiniones y la clasificación de textos. Para garantizar una cantidad suficiente de ejemplos de capacitación, se puede usar el aumento de datos; por ejemplo, los LLM se pueden usar para generar paráfrasis para la misma pregunta. [3] proporciona un estudio más completo de las técnicas de aumento de datos de Text2SQL.
1.2 Enriquecer el indicador con información de la base de datos
Text2SQL es un algoritmo en la interfaz entre datos estructurados y no estructurados. Para un rendimiento óptimo, ambos tipos de datos deben estar presentes durante el entrenamiento y la predicción. Específicamente, el algoritmo debe conocer la base de datos consultada y poder formular la consulta de tal manera que pueda ejecutarse contra la base de datos. Este conocimiento puede abarcar:
- Columnas y tablas de la base de datos.
- Relaciones entre tablas (claves foráneas)
- Contenido de la base de datos
Hay dos opciones para incorporar el conocimiento de la base de datos: por un lado, los datos de entrenamiento pueden restringirse a ejemplos escritos para la base de datos específica, en cuyo caso el esquema se aprende directamente de la consulta SQL y su asignación a la pregunta. Esta configuración de base de datos única permite optimizar el algoritmo para una base de datos individual y/o empresa. Sin embargo, elimina cualquier ambición de escalabilidad, ya que el modelo debe ajustarse para cada cliente o base de datos. Alternativamente, en una configuración de base de datos múltiple, el esquema de la base de datos se puede proporcionar como parte de la entrada, lo que permite que el algoritmo se "generalice" a esquemas de base de datos nuevos e invisibles. Si bien es absolutamente necesario optar por este enfoque si desea utilizar Text2SQL en muchas bases de datos diferentes, tenga en cuenta que requiere un esfuerzo de ingeniería rápido y considerable. Para cualquier base de datos comercial razonable, incluir la información completa en el indicador será extremadamente ineficiente y muy probablemente imposible debido a las limitaciones de longitud del indicador. Por lo tanto, la función responsable de la formulación rápida debe ser lo suficientemente inteligente como para seleccionar un subconjunto de la información de la base de datos que sea más "útil" para una pregunta determinada, y hacer esto para las bases de datos potencialmente invisibles.
Finalmente, la estructura de la base de datos juega un papel crucial. En aquellos escenarios en los que tiene suficiente control sobre la base de datos, puede facilitarle la vida a su modelo al dejar que aprenda de una estructura intuitiva. Como regla general, cuanto más refleje su base de datos cómo los usuarios comerciales hablan sobre el negocio, mejor y más rápido su modelo podrá aprender de él. Por lo tanto, considere aplicar transformaciones adicionales a los datos, como ensamblar datos normalizados o dispersos en tablas anchas o una bóveda de datos, nombrar tablas y columnas de manera explícita e inequívoca, etc. Todo el conocimiento comercial que pueda codificar por adelantado reducirá la carga del aprendizaje probabilístico en su modelo y ayudarlo a lograr mejores resultados.
2. Algoritmo

Text2SQL es un tipo de análisis semántico — la correspondencia de textos con representaciones lógicas. Por lo tanto, el algoritmo no solo tiene que "aprender" el lenguaje natural, sino también la representación de destino, en nuestro caso, SQL. Específicamente, tiene que adquirir y los siguientes conocimientos:
- Sintaxis y semántica de SQL
- Estructura de la base de datos
- Comprensión del lenguaje natural (NLU)
- Mapeo entre lenguaje natural y consultas SQL (sintácticas, léxicas y semánticas)
2.1 Resolviendo la variabilidad lingüística en la entrada
En la entrada, el principal desafío de Text2SQL radica en la flexibilidad del lenguaje: como se describe en la sección Formato y estructura de los datos, la misma pregunta se puede parafrasear de muchas maneras diferentes. Además, en el contexto conversacional de la vida real, tenemos que lidiar con una serie de problemas, como errores ortográficos y gramaticales, entradas incompletas y ambiguas, entradas multilingües, etc.

Los LLM como los modelos GPT, T5 y CodeX están cada vez más cerca de resolver este desafío. Aprendiendo de grandes cantidades de texto diverso, aprenden a lidiar con una gran cantidad de patrones e irregularidades lingüísticas. Al final, se vuelven capaces de generalizar sobre preguntas que son semánticamente similares a pesar de tener diferentes formas superficiales. Los LLM se pueden aplicar listos para usar (disparo cero) o después de un ajuste fino. El primero, aunque conveniente, conduce a una menor precisión. Este último requiere más habilidad y trabajo, pero puede aumentar significativamente la precisión.
En términos de precisión, como se esperaba, los modelos con mejor rendimiento son los últimos modelos de la familia GPT, incluidos los modelos CodeX. En abril de 2023, GPT-4 condujo a un aumento espectacular de la precisión de más del 5 % con respecto al estado de la técnica anterior y logró una precisión del 85.3 % (en la métrica "ejecución con valores").[4] En el campo del código abierto, los intentos iniciales de resolver el rompecabezas de Text2SQL se centraron en modelos de codificación automática como BERT, que sobresalen en las tareas de NLU.[5, 6, 7] Sin embargo, en medio de la exageración en torno a la IA generativa, los enfoques recientes se centran en modelos autorregresivos como el modelo T5. T5 está preentrenado utilizando el aprendizaje de tareas múltiples y, por lo tanto, se adapta fácilmente a nuevas tareas lingüísticas, incl. Diferentes variantes de análisis semántico. Sin embargo, los modelos autorregresivos tienen un defecto intrínseco cuando se trata de tareas de análisis semántico: tienen un espacio de salida sin restricciones y no tienen barreras semánticas que restrinjan su salida, lo que significa que pueden volverse sorprendentemente creativos en su comportamiento. Si bien esto es increíble para generar contenido de forma libre, es una molestia para tareas como Text2SQL, donde esperamos un resultado de destino limitado y bien estructurado.
2.2 Validación y mejora de consultas
Para restringir la salida de LLM, podemos introducir mecanismos adicionales para validar y mejorar la consulta. Esto se puede implementar como un paso de validación adicional, como se propone en el sistema PICARD.[8] PICARD utiliza un analizador SQL que puede verificar si una consulta SQL parcial puede conducir a una consulta SQL válida después de completarse. En cada paso de generación por parte del LLM, los tokens que invalidarían la consulta se rechazan y se conservan los tokens válidos de mayor probabilidad. Al ser determinista, este enfoque garantiza una validez de SQL del 100 % siempre que el analizador observe las reglas de SQL correctas. También desvincula la validación de consultas de la generación, lo que permite mantener ambos componentes de forma independiente y actualizar y modificar el LLM.
Otro enfoque es incorporar conocimientos estructurales y de SQL directamente en el LLM. Por ejemplo, Graphix [9] utiliza capas con reconocimiento de gráficos para inyectar conocimiento de SQL estructurado en el modelo T5. Debido a la naturaleza probabilística de este enfoque, sesga el sistema hacia las consultas correctas, pero no proporciona una garantía de éxito.
Finalmente, el LLM se puede usar como un agente de varios pasos que puede verificar y mejorar la consulta de manera autónoma.[10] Usando varios pasos en una cadena de pensamiento, se le puede pedir al agente que reflexione sobre la corrección de sus propias consultas y mejore cualquier falla. Si aún no se puede ejecutar la consulta validada, el rastreo de excepción de SQL se puede pasar al agente como un comentario adicional para la mejora.
Más allá de estos métodos automatizados que ocurren en el backend, también es posible involucrar al usuario durante el proceso de verificación de consultas. Describiremos esto con más detalle en la sección sobre Experiencia del usuario.
Evaluación 2.3
Para evaluar nuestro algoritmo Text2SQL, necesitamos generar un conjunto de datos de prueba (validación), ejecutar nuestro algoritmo en él y aplicar métricas de evaluación relevantes en el resultado. Un conjunto de datos ingenuo dividido en datos de capacitación, desarrollo y validación se basaría en pares de preguntas y consultas y conduciría a resultados subóptimos. Las consultas de validación pueden revelarse al modelo durante el entrenamiento y conducir a una visión demasiado optimista sobre sus habilidades de generalización. A división basada en consultas, donde el conjunto de datos se divide de tal manera que no aparece ninguna consulta tanto durante el entrenamiento como durante la validación, brinda resultados más veraces.
En términos de métricas de evaluación, lo que nos importa en Text2SQL no es generar consultas que sean completamente idénticas al estándar de oro. Este "coincidencia de cadena exacta" El método es demasiado estricto y generará muchos falsos negativos, ya que diferentes consultas SQL pueden conducir al mismo conjunto de datos devuelto. En cambio, queremos lograr un alto precisión semántica y evalúe si las consultas predichas y "estándar de oro" siempre devolverían los mismos conjuntos de datos. Hay tres métricas de evaluación que se aproximan a este objetivo:
- Precisión de coincidencia de conjunto exacto: las consultas SQL generadas y de destino se dividen en sus constituyentes, y los conjuntos resultantes se comparan para determinar su identidad.[11] La deficiencia aquí es que solo tiene en cuenta las variaciones de orden en la consulta SQL, pero no las diferencias sintácticas más pronunciadas entre consultas semánticamente equivalentes.
- Precisión de ejecución: los conjuntos de datos resultantes de las consultas SQL generadas y de destino se comparan para determinar su identidad. Con suerte, las consultas con diferentes semánticas aún pueden pasar esta prueba en una instancia de base de datos específica. Por ejemplo, suponiendo una base de datos donde todos los usuarios tienen más de 30 años, las siguientes dos consultas arrojarían resultados idénticos a pesar de tener una semántica diferente:
seleccione * del usuario
seleccione * del usuario donde la edad> 30 - Precisión del conjunto de pruebas: la precisión del conjunto de pruebas es una versión más avanzada y menos permisiva de la precisión de ejecución. Para cada consulta se genera un conjunto (“conjunto de pruebas”) de bases de datos muy diferenciadas en cuanto a las variables, condiciones y valores de la consulta. Luego, la precisión de la ejecución se prueba en cada una de estas bases de datos. Si bien requiere un esfuerzo adicional para diseñar la generación del conjunto de pruebas, esta métrica también reduce significativamente el riesgo de falsos positivos en la evaluación..[ 12 ]
3. Experiencia de usuario
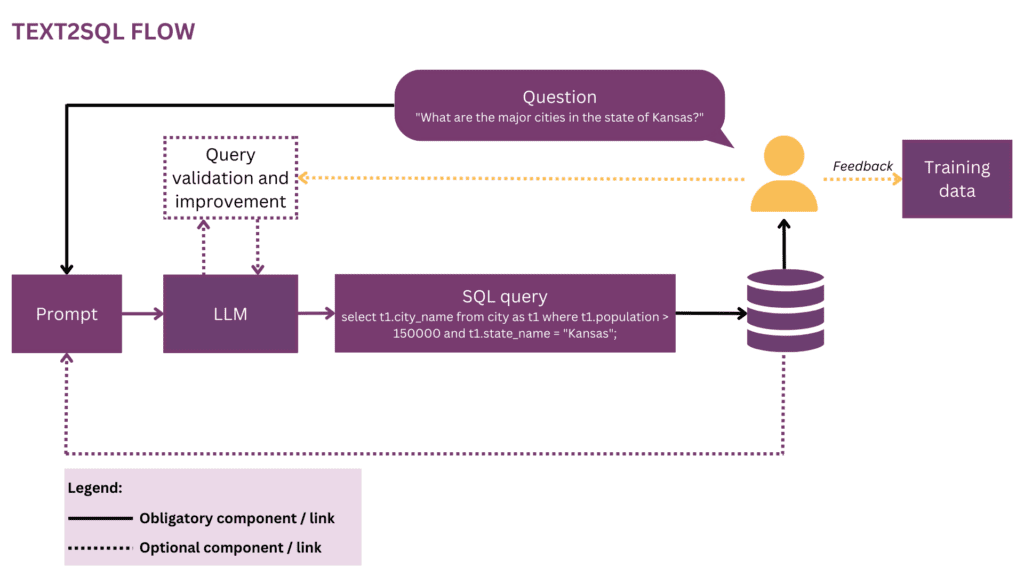
El estado del arte actual de Text2SQL no permite una integración completamente fluida en los sistemas de producción; en cambio, es necesario gestionar activamente las expectativas y el comportamiento del usuario, quien siempre debe ser consciente de que está interactuando con un sistema de IA.
3.1 Gestión de fallas
Text2SQL puede fallar en dos modos, que deben detectarse de diferentes maneras:
- Errores SQL: la consulta generada no es válida: el SQL no es válido o no se puede ejecutar en la base de datos específica debido a fallas léxicas o semánticas. En este caso, no se puede devolver ningún resultado al usuario.
- Errores semánticos: la consulta generada es válida pero no refleja la semántica de la pregunta, lo que genera un conjunto de datos devuelto incorrecto.
El segundo modo es particularmente complicado ya que el riesgo de "fallas silenciosas" (errores que no son detectados por el usuario) es alto. El usuario prototípico no tendrá ni el tiempo ni la habilidad técnica para verificar la corrección de la consulta y/o los datos resultantes. Cuando los datos se utilizan para la toma de decisiones en el mundo real, este tipo de falla puede tener consecuencias devastadoras. Para evitar esto, es fundamental educar a los usuarios y establecer barandillas a nivel empresarial que limitan el impacto potencial, como verificaciones de datos adicionales para decisiones con un mayor impacto. Por otro lado, también podemos utilizar la interfaz de usuario para gestionar la interacción hombre-máquina y ayudar al usuario a detectar y mejorar las solicitudes problemáticas.
3.2 Interacción hombre-máquina
Los usuarios pueden involucrarse con su sistema de IA con diferentes grados de intensidad. Más interacción por solicitud puede conducir a mejores resultados, pero también ralentiza la fluidez de la experiencia del usuario. Además del posible impacto negativo de consultas y resultados erróneos, también considere qué tan motivados estarán sus usuarios para proporcionar comentarios de ida y vuelta para obtener resultados más precisos y también ayudar a mejorar el producto a largo plazo.
La forma más fácil y menos atractiva es trabajar con puntajes de confianza. Si bien el cálculo ingenuo de la confianza como un promedio de las probabilidades de los tokens generados es demasiado simplista, se pueden usar métodos más avanzados como la retroalimentación verbalizada. [13] La confianza puede mostrarse en la interfaz y resaltarse con una alerta explícita en caso de que sea peligrosamente baja. De esta manera, la responsabilidad de un seguimiento adecuado en el “mundo real”, ya sea un rechazo, una aceptación o una verificación adicional de los datos, recae sobre los hombros de su usuario. Si bien esta es una apuesta segura para usted como proveedor, transferir este trabajo al usuario también puede reducir el valor de su producto.
Una segunda posibilidad es involucrar al usuario en un diálogo de aclaración en el caso de consultas de baja confianza, ambiguas o sospechosas. Por ejemplo, su sistema podría sugerir correcciones ortográficas o gramaticales a la entrada y solicitar eliminar la ambigüedad de palabras o estructuras gramaticales específicas. También podría permitir al usuario solicitar de forma proactiva correcciones en la consulta:[14]
USUARIO: Muéstrame las tareas de John en este sprint.
ASISTENTE: ¿Le gustaría ver las tareas que John creó o aquellas en las que está trabajando?
USUARIO: tareas que John creó
ASISTENTE: Bien, aquí están los ID de tareas:

USUARIO: Gracias, también me gustaría ver más información sobre las tareas. Ordene también por urgencia.
ASISTENTE: Claro, aquí están las tareas junto con breves descripciones, asignaciones y fechas límite, ordenadas por fecha límite.
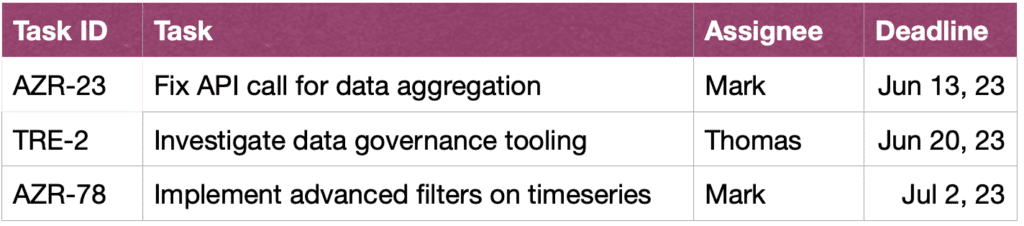
Finalmente, para facilitar la comprensión de las consultas por parte del usuario, su sistema también puede proporcionar una reformulación textual explícita de la consulta y pedirle al usuario que la confirme o la corrija.[15]
4. Requisitos no funcionales
En esta sección, analizamos los requisitos no funcionales específicos para Text2SQL, así como las compensaciones entre ellos. Nos centraremos en los seis requisitos que parecen más importantes para la tarea: precisión, escalabilidad, velocidad, explicabilidad, privacidad y adaptabilidad en el tiempo.
4.1 Precisión
Para Text2SQL, los requisitos de precisión son altos. Primero, Text2SQL generalmente se aplica en una configuración de conversación donde las predicciones se realizan una por una. Por lo tanto, la "Ley de los grandes números", que generalmente ayuda a equilibrar el error en las predicciones por lotes, no ayuda. En segundo lugar, la validez sintáctica y léxica es una condición "dura": el modelo debe generar una consulta SQL bien formada, potencialmente con una sintaxis y una semántica complejas, de lo contrario, la solicitud no se puede ejecutar en la base de datos. Y si esto va bien y la consulta se puede ejecutar, aún puede contener errores semánticos y generar un conjunto de datos devuelto incorrecto (consulte la sección 3.1 Gestión de fallas).
Escalabilidad 4.2
Las principales consideraciones de escalabilidad son si desea aplicar Text2SQL en una o varias bases de datos y, en el último caso, si el conjunto de bases de datos es conocido y cerrado. En caso afirmativo, le resultará más fácil ya que puede incluir la información sobre estas bases de datos durante el entrenamiento. Sin embargo, en el escenario de un producto escalable, ya sea una aplicación Text2SQL independiente o una integración en un producto de datos existente, su algoritmo tiene que hacer frente a cualquier nuevo esquema de base de datos sobre la marcha. Este escenario tampoco le brinda la oportunidad de transformar la estructura de la base de datos para que sea más intuitiva para el aprendizaje (¡enlace!). Todo esto conduce a una gran compensación con la precisión, lo que también podría explicar por qué los proveedores actuales de Text2SQL que ofrecen consultas ad-hoc de nuevas bases de datos aún no han logrado una penetración significativa en el mercado.
Velocidad 4.3
Dado que las solicitudes de Text2SQL normalmente se procesarán en línea en una conversación, el aspecto de la velocidad es importante para la satisfacción del usuario. En el lado positivo, los usuarios suelen ser conscientes del hecho de que las solicitudes de datos pueden llevar cierto tiempo y mostrar la paciencia necesaria. Sin embargo, esta buena voluntad puede verse socavada por la configuración del chat, donde los usuarios esperan inconscientemente una velocidad de conversación similar a la humana. Los métodos de optimización de fuerza bruta, como la reducción del tamaño del modelo, pueden tener un impacto inaceptable en la precisión, así que considere la optimización de inferencia para satisfacer esta expectativa.
4.4 Explicabilidad y transparencia
En el caso ideal, el usuario puede seguir cómo se generó la consulta a partir del texto, ver el mapeo entre palabras o expresiones específicas en la pregunta y la consulta SQL, etc. Esto permite verificar la consulta y realizar ajustes al interactuar con el sistema. . Además, el sistema también podría proporcionar una reformulación textual explícita de la consulta y solicitar al usuario que la confirme o la corrija.
Privacidad de 4.5
La función Text2SQL se puede aislar de la ejecución de consultas, por lo que la información de la base de datos devuelta se puede mantener invisible. Sin embargo, la pregunta crítica es cuánta información sobre la base de datos se incluye en el aviso. Las tres opciones (al disminuir el nivel de privacidad) son:
- No hay información
- Esquema de base de datos
- Contenido de la base de datos
La privacidad se compensa con la precisión: cuanto menos restringido esté para incluir información útil en el aviso, mejores serán los resultados.
4.6 Adaptabilidad en el tiempo
Para utilizar Text2SQL de forma duradera, debe adaptarse a la deriva de datos, es decir, la distribución cambiante de los datos a los que se aplica el modelo. Por ejemplo, supongamos que los datos utilizados para el ajuste fino inicial reflejan el comportamiento de consulta simple de los usuarios cuando comienzan a utilizar el sistema de BI. A medida que pasa el tiempo, las necesidades de información de los usuarios se vuelven más sofisticadas y requieren consultas más complejas, que abruman su modelo ingenuo. Además, los objetivos o la estrategia de cambio de una empresa también pueden derivar y dirigir las necesidades de información hacia otras áreas de la base de datos. Finalmente, un desafío específico de Text2SQL es la desviación de la base de datos. A medida que se amplía la base de datos de la empresa, aparecen nuevas columnas y tablas invisibles en el indicador. Si bien los algoritmos Text2SQL que están diseñados para aplicaciones de bases de datos múltiples pueden manejar este problema bien, puede afectar significativamente la precisión de un modelo de base de datos única. Todos estos problemas se resuelven mejor con un conjunto de datos de ajuste fino que refleje el comportamiento actual de los usuarios en el mundo real. Por lo tanto, es crucial registrar las preguntas y los resultados de los usuarios, así como cualquier comentario asociado que se pueda recopilar del uso. Además, los algoritmos de agrupamiento semántico, por ejemplo, mediante incrustaciones o modelado de temas, se pueden aplicar para detectar cambios subyacentes a largo plazo en el comportamiento del usuario y utilizarlos como una fuente adicional de información para perfeccionar su conjunto de datos de ajuste fino.
Conclusión
Resumamos los puntos clave del artículo:
- Text2SQL permite implementar un acceso a datos intuitivo y democrático en una empresa, maximizando así el valor de los datos disponibles.
- Los datos de Text2SQL consisten en preguntas en la entrada y consultas SQL en la salida. El mapeo entre preguntas y consultas SQL es de muchos a muchos.
- Es importante proporcionar información sobre la base de datos como parte del mensaje. Además, la estructura de la base de datos se puede optimizar para que sea más fácil de aprender y comprender para el algoritmo.
- En la entrada, el principal desafío es la variabilidad lingüística de las preguntas en lenguaje natural, que se pueden abordar utilizando LLM que fueron entrenados previamente en una amplia variedad de estilos de texto diferentes.
- La salida de Text2SQL debe ser una consulta SQL válida. Esta restricción se puede incorporar "inyectando" conocimiento de SQL en el algoritmo; alternativamente, mediante un enfoque iterativo, la consulta se puede comprobar y mejorar en varios pasos.
- Debido al impacto potencialmente alto de las "fallas silenciosas" que devuelven datos incorrectos para la toma de decisiones, la gestión de fallas es una preocupación principal en la interfaz de usuario.
- De manera "aumentada", los usuarios pueden participar activamente en la validación iterativa y la mejora de las consultas SQL. Si bien esto hace que la aplicación sea menos fluida, también reduce las tasas de fallas, permite a los usuarios explorar los datos de una manera más flexible y crea señales valiosas para un mayor aprendizaje.
- Los principales requisitos no funcionales a considerar son precisión, escalabilidad, velocidad, explicabilidad, privacidad y adaptabilidad en el tiempo. Las principales ventajas y desventajas consisten en la precisión, por un lado, y la escalabilidad, la velocidad y la privacidad, por el otro.
Referencias
[1]Ken Van Haren. 2023. Reemplazo de un analista de SQL con 26 avisos GPT recursivos
[2] Nitarshan Rajkumar y otros. 2022. Evaluación de las capacidades de texto a SQL de modelos de lenguaje grandes
[3] Naihao Deng et al. 2023. Avances recientes en Text-to-SQL: una encuesta de lo que tenemos y lo que esperamos
[4] Mohammadreza Pourreza et al. 2023. DIN-SQL: aprendizaje en contexto descompuesto de texto a SQL con autocorrección
[5] Víctor Zhong et al. 2021. Adaptación a tierra para el análisis semántico ejecutable de tiro cero
[6] Xi Victoria Lin et al. 2020. Conexión de datos textuales y tabulares para el análisis semántico de texto a SQL entre dominios
[7] Tong Guo et al. 2019. Generación de texto a SQL basado en BERT mejorado de contenido
[8]Torsten Scholak et al. 2021. PICARD: análisis incremental para la decodificación autorregresiva restringida de modelos de lenguaje
[9] Jinyang Li et al. 2023. Graphix-T5: mezcla de transformadores preentrenados con capas compatibles con gráficos para el análisis de texto a SQL
[10] Cadena Lang. 2023. LLM y SQL
[11] Tao Yu y otros. 2018. Spider: un conjunto de datos a gran escala etiquetado por humanos para análisis semántico complejo y entre dominios y tareas de conversión de texto a SQL
[12] Ruiqi Zhong et al. 2020. Evaluación semántica para Text-to-SQL con suites de prueba destiladas
[13] Katherine Tian et al. 2023. Solo pregunte por la calibración: estrategias para obtener puntajes de confianza calibrados a partir de modelos de lenguaje ajustados con retroalimentación humana
[14] Braden Hancock y otros. 2019. Aprendiendo del diálogo después de la implementación: ¡Aliméntate, chatbot!
[15] Ahmed Elgohary et al. 2020. Hable con su analizador: texto interactivo a SQL con comentarios en lenguaje natural
[16] Janna Lipenkova. 2022. ¡Háblame! Conversaciones de Text2SQL con los datos de su empresa, charla en la reunión de procesamiento del lenguaje natural de Nueva York.
Todas las imágenes son del autor.
Este artículo se publicó originalmente el Hacia la ciencia de datos y re-publicado a TOPBOTS con permiso del autor.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.topbots.com/conversational-ai-for-data-analysis/

