Esta publicación fue coescrita con Babu Srinivasan y Robert Walters de MongoDB.
Streaming administrado por Amazon para Apache Kafka (Amazon MSK) es un servicio Apache Kafka totalmente administrado y de alta disponibilidad. Amazon MSK facilita la ingesta y el procesamiento de datos de transmisión en tiempo real y utiliza esos datos fácilmente dentro del ecosistema de AWS. Con Amazon MSK sin servidor, puede aprovisionar y administrar automáticamente los recursos necesarios para proporcionar almacenamiento y capacidad de transmisión bajo demanda para sus aplicaciones.
Amazon MSK también admite la integración de fuentes de datos como MongoDB Atlas a través de Conexión de Amazon MSK. MSK Connect permite la integración sin servidor de los datos de MongoDB con Amazon MSK utilizando el Conector MongoDB para Apache Kafka.
MongoDB Atlas sin servidor proporciona servicios de base de datos que se escalan dinámicamente hacia arriba y hacia abajo con el tamaño y el rendimiento de los datos, y el costo se escala en consecuencia. Es más adecuado para aplicaciones con demandas variables que deben administrarse con una configuración mínima. Proporciona un alto rendimiento y confiabilidad con funciones automatizadas de actualización, cifrado, seguridad, métricas y respaldo integradas con la infraestructura MongoDB Atlas.
MSK Serverless es un tipo de clúster para Amazon MSK. Al igual que MongoDB Atlas Serverless, MSK Serverless aprovisiona y escala automáticamente los recursos informáticos y de almacenamiento. Ahora puede crear flujos de trabajo sin servidor de extremo a extremo. Puede crear una canalización de transmisión sin servidor con ingesta sin servidor usando MSK Serverless y almacenamiento sin servidor usando MongoDB Atlas. Además, MSK Connect ahora admite nombres de host DNS privados. Esto permite que las instancias de MSK sin servidor se conecten a clústeres de MongoDB sin servidor a través de Enlace privado de AWS, brindándole conectividad segura entre plataformas.
Si está interesado en usar un clúster sin servidor, consulte Integración de MongoDB con Amazon Managed Streaming para Apache Kafka (MSK).
Esta publicación demuestra cómo implementar una canalización de transmisión sin servidor con MSK Serverless, MSK Connect y MongoDB Atlas.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de nuestra solución.
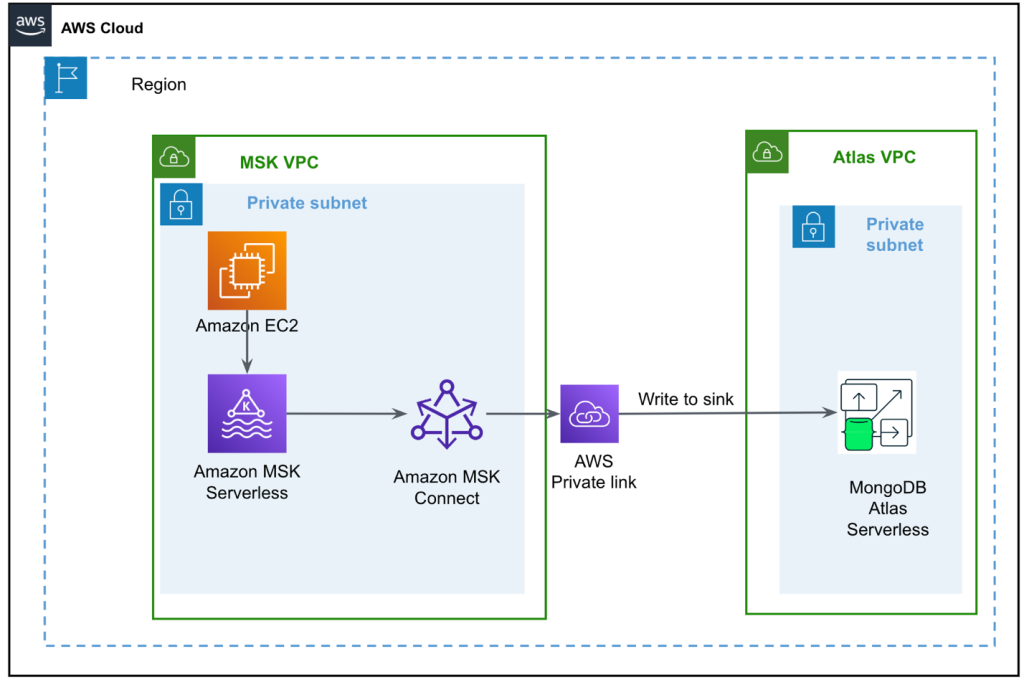
El flujo de datos comienza con un Nube informática elástica de Amazon (Amazon EC2) instancia de cliente que escribe registros en un tema de MSK. A medida que llegan los datos, una instancia de MongoDB Connector para Apache Kafka escribe los datos en una colección en el clúster MongoDB Atlas Serverless. Para una conectividad segura entre las dos plataformas, se crea una conexión de AWS PrivateLink entre el clúster de MongoDB Atlas y la VPC que contiene la instancia de MSK.
Esta publicación lo guía a través de los siguientes pasos:
- Cree el clúster de MSK sin servidor.
- Cree el clúster sin servidor de MongoDB Atlas.
- Configure el complemento MSK.
- Cree el cliente EC2.
- Configurar un tema de MSK.
- Configure MongoDB Connector para Apache Kafka como sumidero.
Configurar el clúster de MSK sin servidor
Para crear un clúster MSK sin servidor, complete los siguientes pasos:
- En la consola de Amazon MSK, elija Clusters en el panel de navegación.
- Elige Crear clúster.
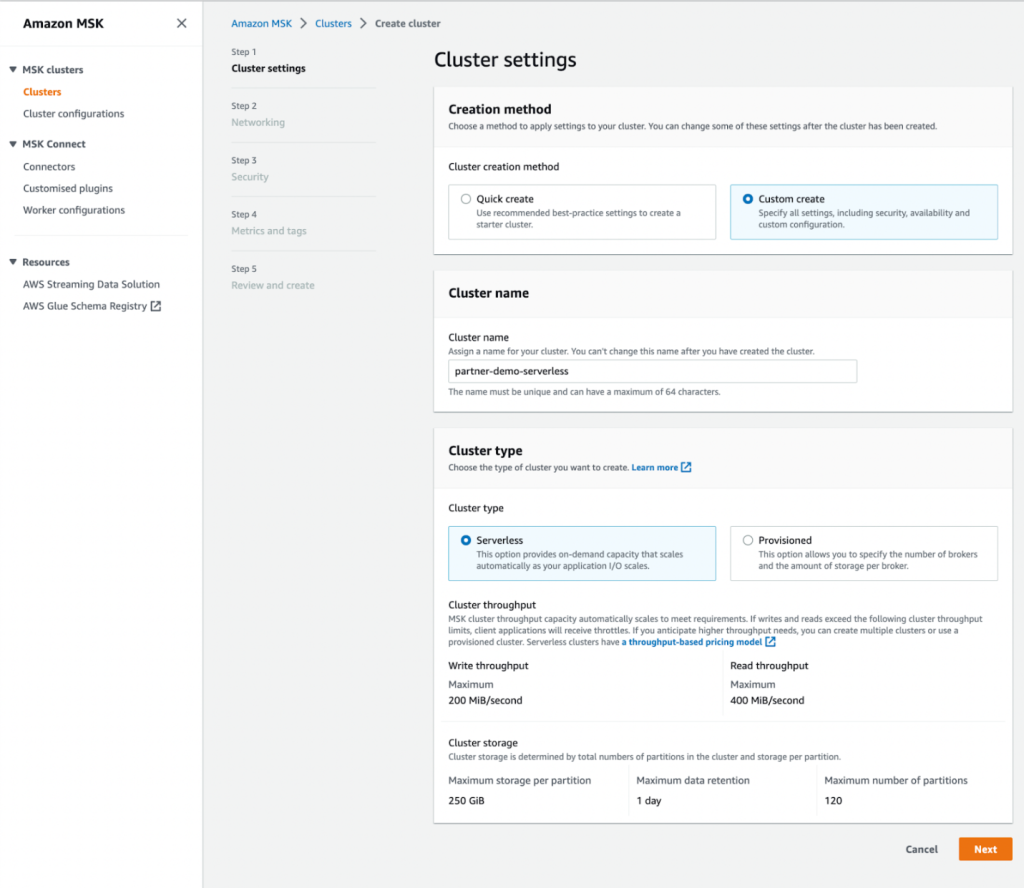
- Método de creación, seleccione Creación personalizada.
- Nombre del clúster, introduzca
MongoDBMSKCluster. - Tipo de clústerSeleccione Sin servidor.
- Elige Siguiente.
- En Networking página, especifique su VPC, las zonas de disponibilidad y las subredes correspondientes.
- Tenga en cuenta las zonas de disponibilidad y las subredes para usarlas más adelante.
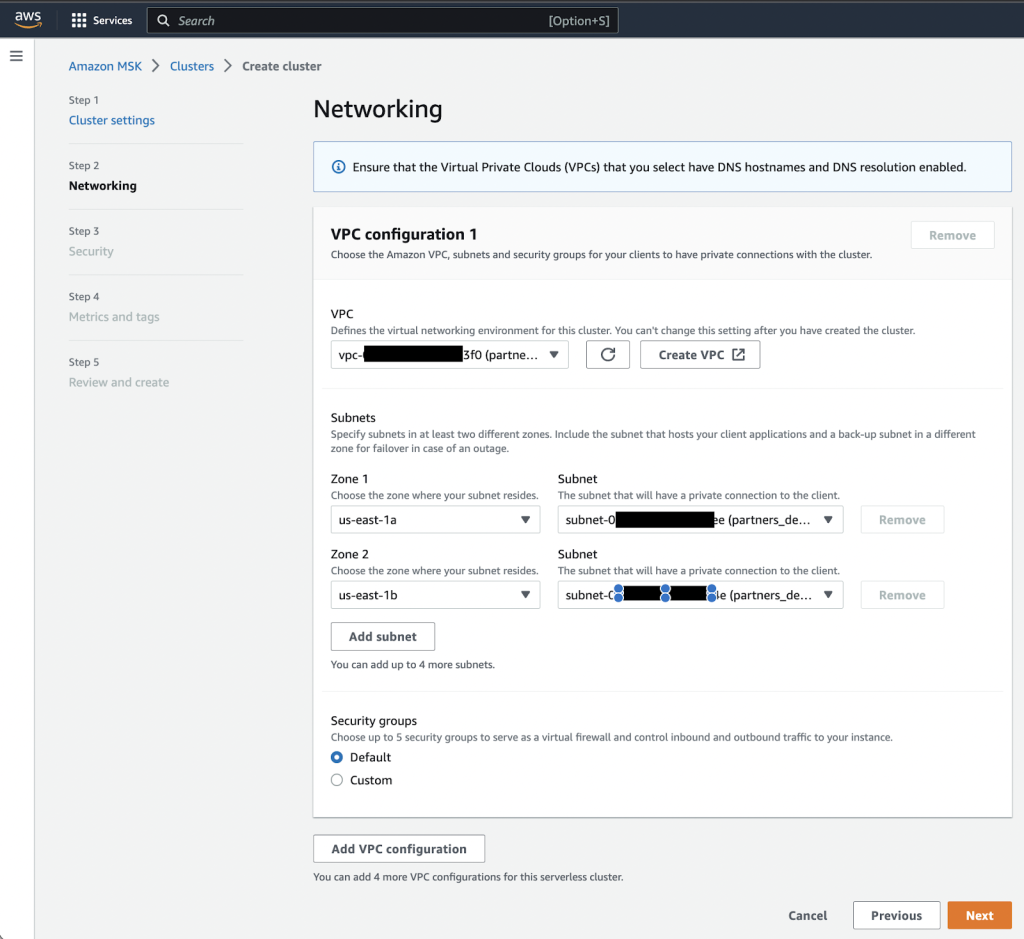
- Elige Siguiente.
- Elige Crear clúster.
Cuando el clúster está disponible, su estado pasa a ser Active.

Cree el clúster sin servidor MongoDB Atlas
Para crear un clúster de MongoDB Atlas, siga las Primeros pasos con Atlas tutorial. Tenga en cuenta que para los fines de esta publicación, debe crear una instancia sin servidor.

Después de crear el clúster, configure un punto de enlace privado de AWS con los siguientes pasos:
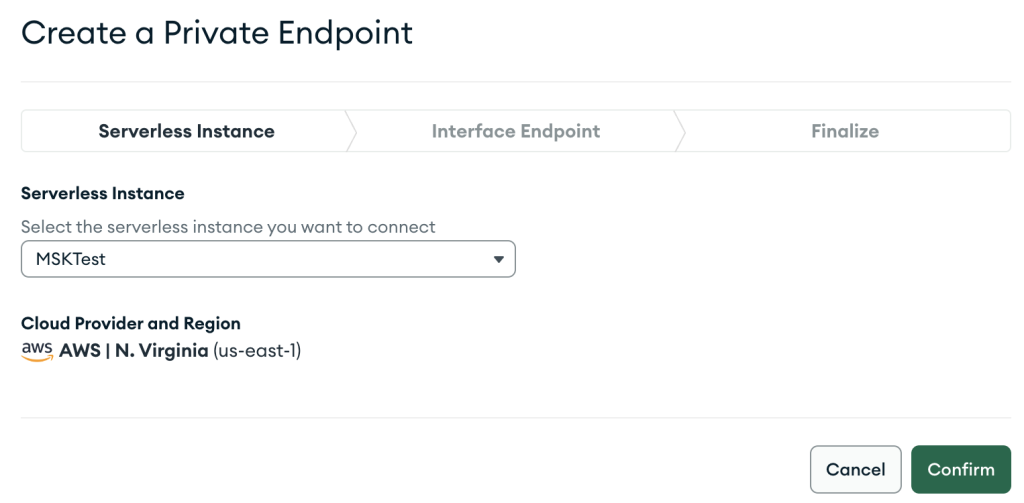
- En Seguridad menú, seleccione Acceso a la red.

- En Punto final privado pestaña, elegir Instancia sin servidor.

- Elige Crear nuevo punto final.
- Instancia sin servidor, elija la instancia que acaba de crear.
- Elige Confirmar.
- Proporcione la configuración de su punto de enlace de la VPC y elija Siguiente.
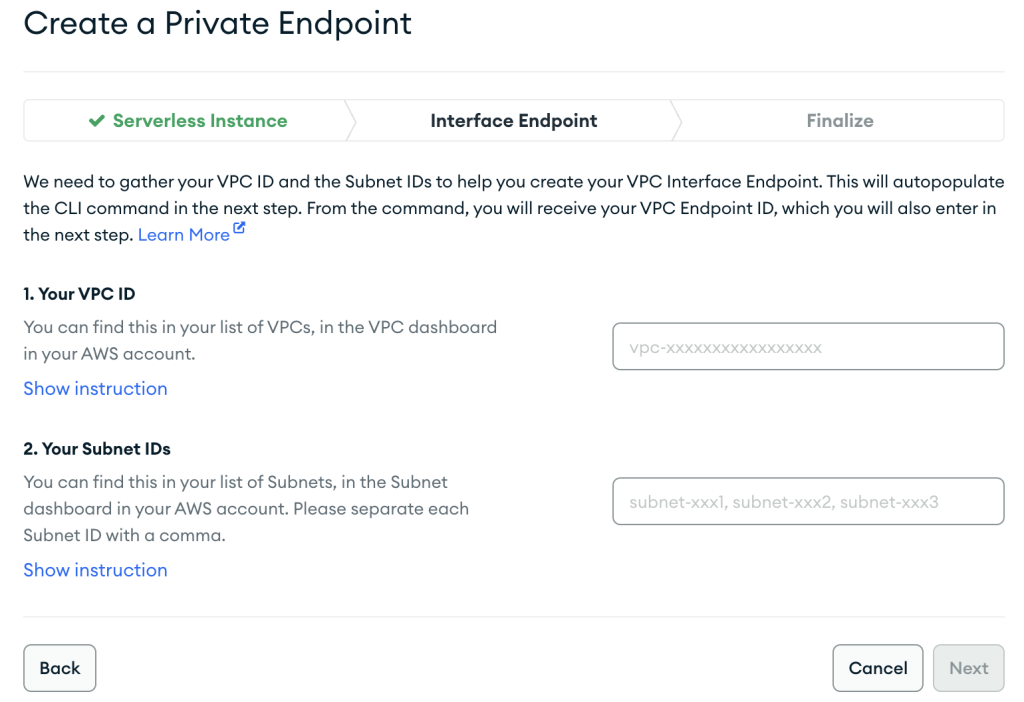
- Al crear el recurso de AWS PrivateLink, asegúrese de especificar exactamente las mismas VPC y subredes que utilizó anteriormente al crear la configuración de red para la instancia de MSK sin servidor.
- Elige Siguiente.
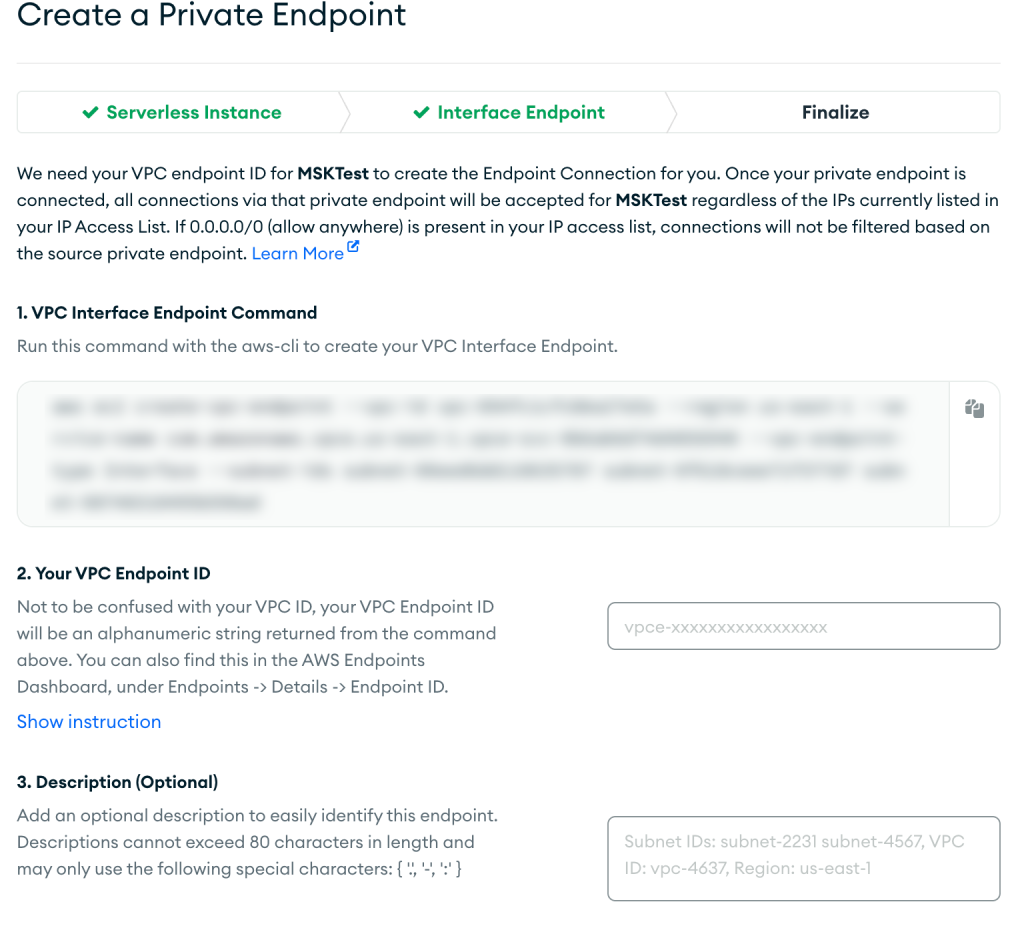
- Siga las instrucciones del Finalizar página, luego elija Confirmar después de crear su punto de enlace de la VPC.
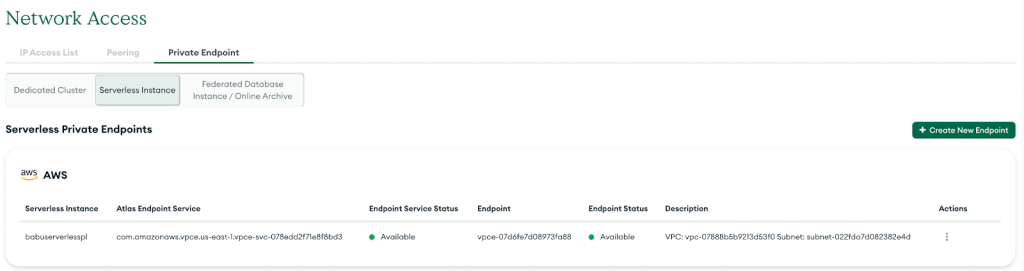
En caso de éxito, el nuevo punto final privado aparecerá en la lista, como se muestra en la siguiente captura de pantalla.
Configurar el complemento MSK
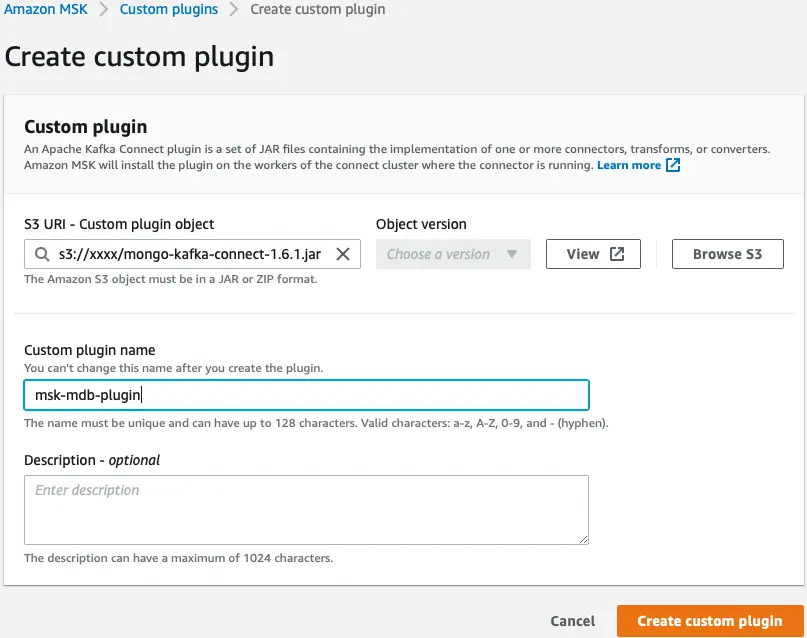
A continuación, creamos un complemento personalizado en Amazon MSK utilizando MongoDB Connector para Apache Kafka. El conector debe cargarse en un Servicio de almacenamiento simple de Amazon (Amazon S3) antes de poder crear el complemento. Para descargar MongoDB Connector para Apache Kafka, consulte Descargar un archivo JAR del conector.
- En la consola de Amazon MSK, elija Complementos personalizados en el panel de navegación.
- Elige Crear complemento personalizado.
- URI de S3, ingrese la ubicación S3 del conector descargado.
- Elige Crear complemento personalizado.
Configurar un cliente EC2
A continuación, configuremos una instancia EC2. Usamos esta instancia para crear el tema e insertar datos en el tema. Para obtener instrucciones, consulte la sección Configurar un cliente EC2 en el post Integración de MongoDB con Amazon Managed Streaming para Apache Kafka (MSK).
Crear un tema en el clúster de MSK
Para crear un tema de Kafka, primero debemos instalar la CLI de Kafka.
- En la instancia EC2 del cliente, primero instale Java:
sudo yum install java-1.8.0
- A continuación, ejecute el siguiente comando para descargar Apache Kafka:
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Descomprima el archivo tar usando el siguiente comando:
tar -xzf kafka_2.12-2.6.2.tgz
La distribución de Kafka incluye una carpeta bin con herramientas que se pueden usar para administrar temas.
- Visite la
kafka_2.12-2.6.2y emita el siguiente comando para crear un tema de Kafka en el clúster de MSK sin servidor:
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
Puede copiar el punto final del servidor de arranque en el Ver información del cliente página para su clúster MSK sin servidor.
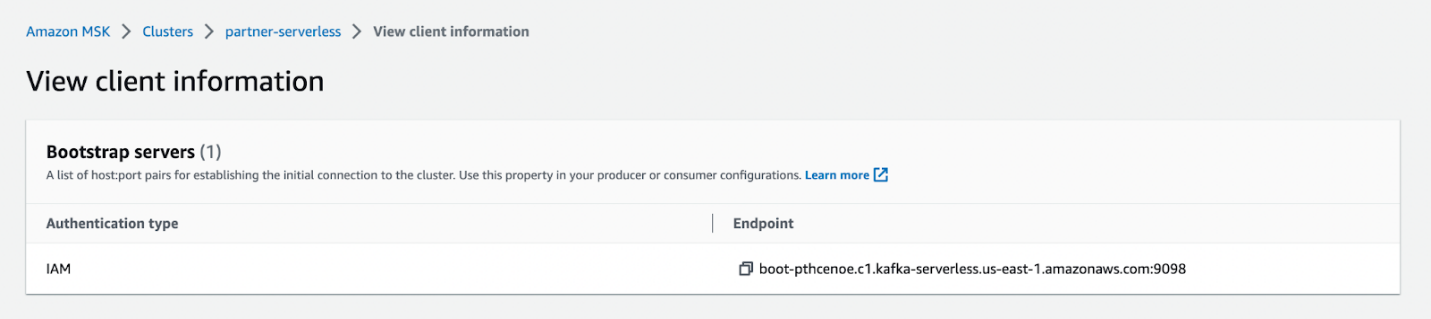
Puede configurar la autenticación de IAM siguiendo estos Instrucciones.
Configurar el conector del fregadero
Ahora, configuremos un conector receptor para enviar los datos a la instancia sin servidor de MongoDB Atlas.
- En la consola de Amazon MSK, elija Conectores en el panel de navegación.
- Elige Crear conector.
- Seleccione el complemento que creó anteriormente.
- Elige Siguiente.
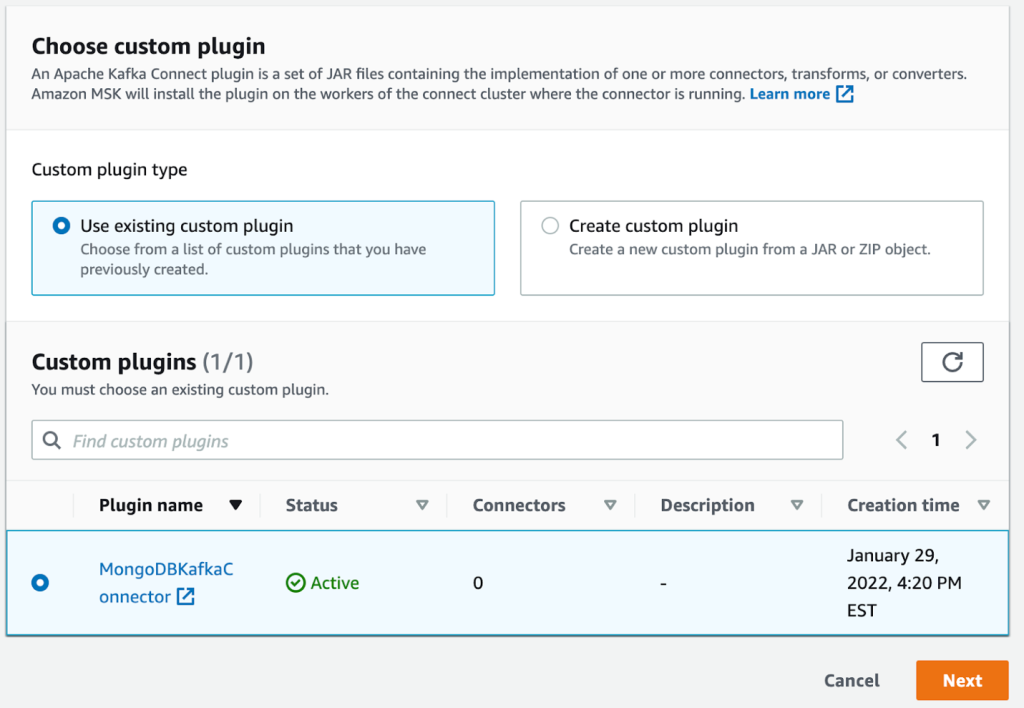
- Seleccione la instancia de MSK sin servidor que creó anteriormente.
- Ingrese su configuración de conexión como el siguiente código:
Asegúrese de que la conexión a la instancia de MongoDB Atlas Serverless sea a través de AWS PrivateLink. Para obtener más información, consulte Conexión segura de aplicaciones a un plano de datos de MongoDB Atlas con AWS PrivateLink.
- En Permisos de acceso sección, cree una Gestión de identidades y accesos de AWS (IAM) rol con el política de confianza requerida.
- Elige Siguiente.
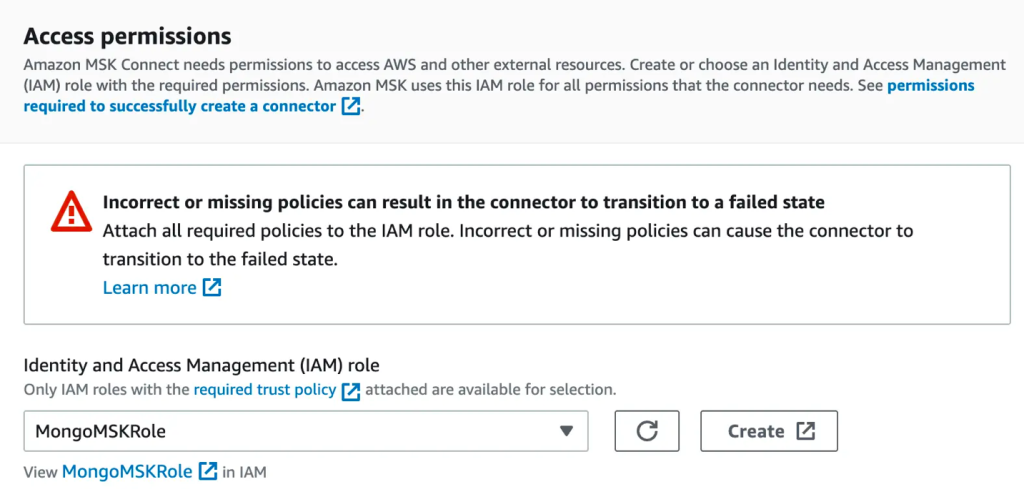
- Especificar Registros de Amazon CloudWatch como su opción de entrega de registros.
- Completa tu conector.
Cuando el estado del conector cambia a Activo, la canalización está lista.

Insertar datos en el tema MSK
En su cliente EC2, inserte datos en el tema MSK usando el kafka-console-producer como sigue:
Para verificar que los datos fluyan con éxito desde el tema de Kafka al clúster de MongoDB sin servidor, usamos la interfaz de usuario de MongoDB Atlas.
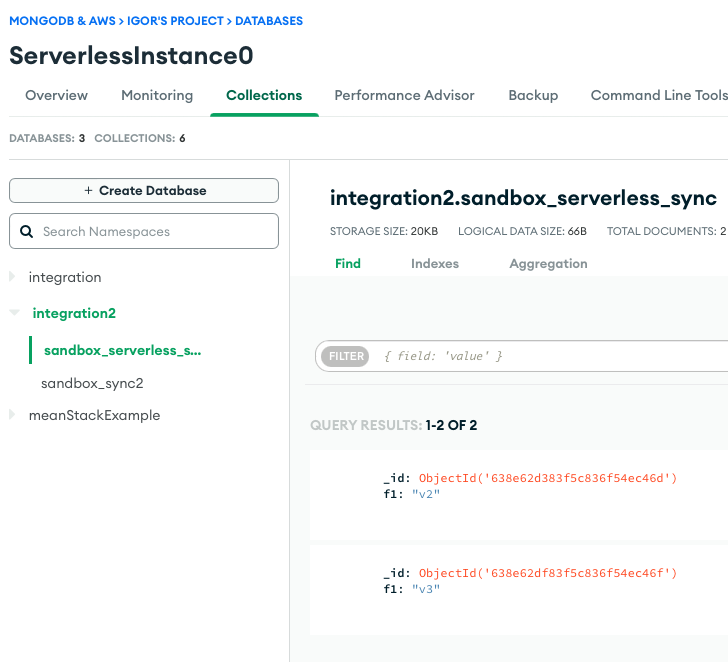
Si tiene algún problema, asegúrese de revisar los archivos de registro. En este ejemplo, usamos CloudWatch para leer los eventos que se generaron desde Amazon MSK y MongoDB Connector para Apache Kafka.
Limpiar
Para evitar incurrir en cargos futuros, limpie los recursos que creó. Primero, elimine el clúster MSK, el conector y la instancia EC2:
- En la consola de Amazon MSK, elija Clusters en el panel de navegación.
- Seleccione su clúster y en el Acciones menú, seleccione Borrar.
- Elige Conectores en el panel de navegación.
- Seleccione su conector y elija Borrar.
- Elige Complementos personalizados en el panel de navegación.
- Seleccione su complemento y elija Borrar.
- En la consola de Amazon EC2, elija Instancias en el panel de navegación.
- Elija la instancia que creó.
- Elige Estado de la instancia, A continuación, elija Terminar instancia.
- En VPC de Amazon consola, elige Endpoints en el panel de navegación.
- Seleccione el punto final que creó y en el Acciones menú, seleccione Eliminar puntos de enlace de la VPC.
Ahora puede eliminar el clúster de Atlas y AWS PrivateLink:
- Inicie sesión en la consola del clúster de Atlas.
- Navegue hasta el clúster sin servidor que desea eliminar.
- En el menú desplegable de opciones, elija Terminar.

- Navegue hasta la Acceso a la red .
- Elija el punto final privado.
- Seleccione la instancia sin servidor.
- En el menú desplegable de opciones, elija Terminar.

Resumen
En esta publicación, le mostramos cómo crear una canalización de ingesta de streaming sin servidor utilizando MSK Serverless y MongoDB Atlas Serverless. Con MSK Serverless, puede aprovisionar y administrar automáticamente los recursos necesarios según sea necesario. Usamos un conector MongoDB implementado en MSK Connect para integrar sin problemas los dos servicios y usamos un cliente EC2 para enviar datos de muestra al tema MSK. MSK Connect ahora admite Nombres de host DNS privados, lo que le permite utilizar nombres de dominio privados entre los servicios. En esta publicación, el conector usó los servidores DNS predeterminados de la VPC para resolver el nombre de DNS privado específico de la zona de disponibilidad. Esta configuración de AWS PrivateLink permitió una conectividad segura y privada entre la instancia sin servidor de MSK y la instancia sin servidor de MongoDB Atlas.
Para continuar con su aprendizaje, consulte los siguientes recursos:
Acerca de los autores

Igor Alekseev es socio sénior de arquitectura de soluciones en AWS en el dominio de datos y análisis. En su función, Igor está trabajando con socios estratégicos ayudándolos a construir arquitecturas complejas optimizadas para AWS. Antes de unirse a AWS, como arquitecto de soluciones/datos, implementó muchos proyectos en el dominio de Big Data, incluidos varios lagos de datos en el ecosistema de Hadoop. Como ingeniero de datos, participó en la aplicación de AI/ML a la detección de fraudes y la automatización de oficinas.
 kiran matty es gerente principal de productos de Amazon Web Services (AWS) y trabaja con el equipo Amazon Managed Streaming para Apache Kafka (Amazon MSK) con sede en Palo Alto, California. Le apasiona crear servicios analíticos y de transmisión de alto rendimiento que ayuden a las empresas a darse cuenta de sus casos de uso críticos.
kiran matty es gerente principal de productos de Amazon Web Services (AWS) y trabaja con el equipo Amazon Managed Streaming para Apache Kafka (Amazon MSK) con sede en Palo Alto, California. Le apasiona crear servicios analíticos y de transmisión de alto rendimiento que ayuden a las empresas a darse cuenta de sus casos de uso críticos.
 Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
 Robert Walters Actualmente es gerente senior de productos en MongoDB. Antes de MongoDB, Rob pasó 17 años en Microsoft trabajando en varios roles, incluida la gestión de programas en el equipo de SQL Server, consultoría y preventa técnica. Rob es coautor de tres patentes de tecnologías utilizadas en SQL Server y fue el autor principal de varios libros técnicos sobre SQL Server. Rob es actualmente un bloguero activo en MongoDB Blogs.
Robert Walters Actualmente es gerente senior de productos en MongoDB. Antes de MongoDB, Rob pasó 17 años en Microsoft trabajando en varios roles, incluida la gestión de programas en el equipo de SQL Server, consultoría y preventa técnica. Rob es coautor de tres patentes de tecnologías utilizadas en SQL Server y fue el autor principal de varios libros técnicos sobre SQL Server. Rob es actualmente un bloguero activo en MongoDB Blogs.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/

