El lanzamiento de ChatGPT y el aumento de la popularidad de la IA generativa han capturado la imaginación de los clientes que sienten curiosidad por saber cómo pueden utilizar esta tecnología para crear nuevos productos y servicios en AWS, como los chatbots empresariales, que son más conversacionales. Esta publicación le muestra cómo puede crear una interfaz de usuario web, a la que llamamos Chat Studio, para iniciar una conversación e interactuar con los modelos básicos disponibles en JumpStart de Amazon SageMaker como Llama 2, Stable Diffusion y otros modelos disponibles en Amazon SageMaker. Después de implementar esta solución, los usuarios pueden comenzar rápidamente y experimentar las capacidades de múltiples modelos básicos en IA conversacional a través de una interfaz web.
Chat Studio también puede invocar opcionalmente el punto final del modelo Stable Diffusion para devolver un collage de imágenes y videos relevantes si el usuario solicita que se muestren los medios. Esta característica puede ayudar a mejorar la experiencia del usuario con el uso de medios como activos que acompañan a la respuesta. Este es solo un ejemplo de cómo puedes enriquecer Chat Studio con integraciones adicionales para alcanzar tus objetivos.
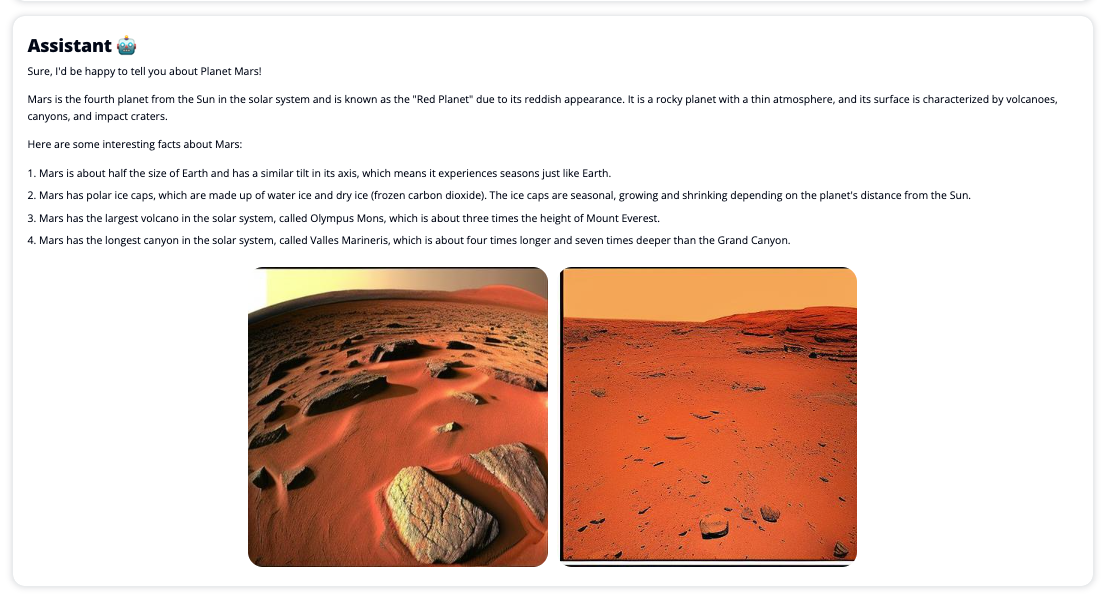
Las siguientes capturas de pantalla muestran ejemplos de cómo se ven la consulta y la respuesta de un usuario.

Grandes modelos de idiomas
Los chatbots de IA generativa, como ChatGPT, funcionan con grandes modelos de lenguaje (LLM), que se basan en una red neuronal de aprendizaje profundo que se puede entrenar con grandes cantidades de texto sin etiquetar. El uso de LLM permite una mejor experiencia de conversación que se asemeja mucho a las interacciones con humanos reales, fomentando una sensación de conexión y una mayor satisfacción del usuario.
Modelos básicos de SageMaker
En 2021, el Instituto Stanford para la Inteligencia Artificial Centrada en el Humano denominó algunos LLM como modelos de cimientos. Los modelos básicos están previamente entrenados en un conjunto grande y amplio de datos generales y están destinados a servir como base para optimizaciones adicionales en una amplia gama de casos de uso, desde la generación de arte digital hasta la clasificación de textos multilingües. Estos modelos básicos son populares entre los clientes porque entrenar un nuevo modelo desde cero lleva tiempo y puede resultar costoso. SageMaker JumpStart brinda acceso a cientos de modelos básicos mantenidos por proveedores externos de código abierto y propietarios.
Resumen de la solución
Esta publicación recorre un flujo de trabajo de código bajo para implementar LLM personalizados y previamente capacitados a través de SageMaker y crear una interfaz de usuario web para interactuar con los modelos implementados. Cubrimos los siguientes pasos:
- Implementar modelos básicos de SageMaker.
- Despliegue AWS Lambda y Gestión de identidades y accesos de AWS (IAM) permisos usando Formación en la nube de AWS.
- Configure y ejecute la interfaz de usuario.
- Opcionalmente, agregue otros modelos de base de SageMaker. Este paso amplía la capacidad de Chat Studio para interactuar con modelos básicos adicionales.
- Opcionalmente, implemente la aplicación usando AWS amplificar. Este paso implementa Chat Studio en la web.
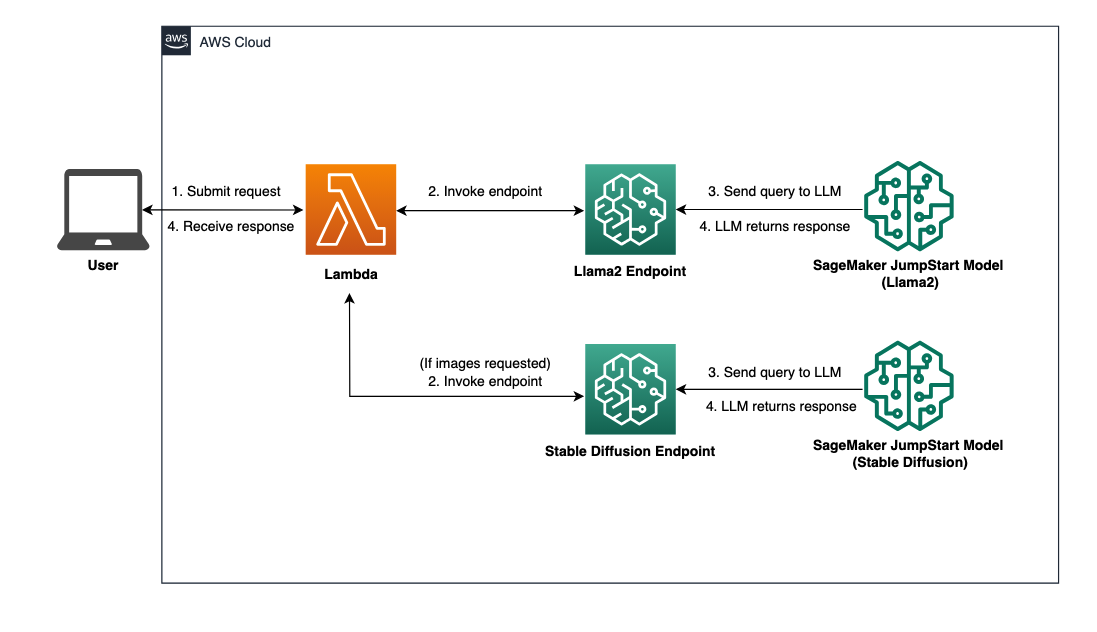
Consulte el siguiente diagrama para obtener una descripción general de la arquitectura de la solución.
Requisitos previos
Para recorrer la solución, debe tener los siguientes requisitos previos:
- An Cuenta de AWS con suficientes privilegios de usuario de IAM.
npminstalado en su entorno local. Para obtener instrucciones sobre cómo instalarnpm, Referirse a Descargando e instalando Node.js y npm.- Una cuota de servicio de 1 para los puntos finales de SageMaker correspondientes. Para Llama 2 13b Chat, usamos una instancia ml.g5.48xlarge y para Stable Diffusion 2.1, usamos una instancia ml.p3.2xlarge.
Para solicitar un aumento de cuota de servicio, en el Consola de cuotas de servicio de AWS, navegar a Servicios de AWS, SageMakery solicite un aumento de la cuota de servicio a un valor de 1 para ml.g5.48xlarge para uso de endpoints y ml.p3.2xlarge para uso de endpoints.
La solicitud de cuota de servicio puede tardar algunas horas en aprobarse, según la disponibilidad del tipo de instancia.
Implementar modelos básicos de SageMaker
SageMaker es un servicio de aprendizaje automático (ML) totalmente administrado para que los desarrolladores creen y entrenen rápidamente modelos de ML con facilidad. Complete los siguientes pasos para implementar los modelos básicos de Llama 2 13b Chat y Stable Diffusion 2.1 usando Estudio Amazon SageMaker:
- Cree un dominio de SageMaker. Para obtener instrucciones, consulte Incorporación al dominio de Amazon SageMaker mediante la configuración rápida.
Un dominio configura todo el almacenamiento y le permite agregar usuarios para acceder a SageMaker.
- En la consola de SageMaker, elija creativo en el panel de navegación, luego elija Open Studio.
- Al iniciar Studio, en Inicio rápido de SageMaker en el panel de navegación, elija Maquetas, cuadernos, soluciones..
- En la barra de búsqueda, busque Llama 2 13b Chat.
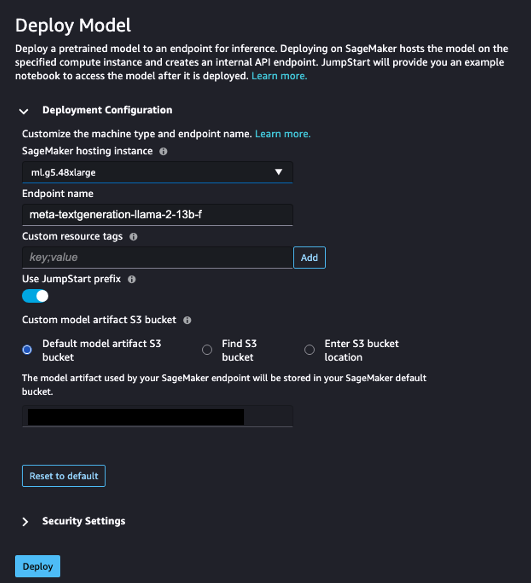
- under Configuración de implementación, Para Instancia de alojamiento de SageMaker, escoger ml.g5.48xgrande y para Nombre de punto final, introduzca
meta-textgeneration-llama-2-13b-f. - Elige Implementar.
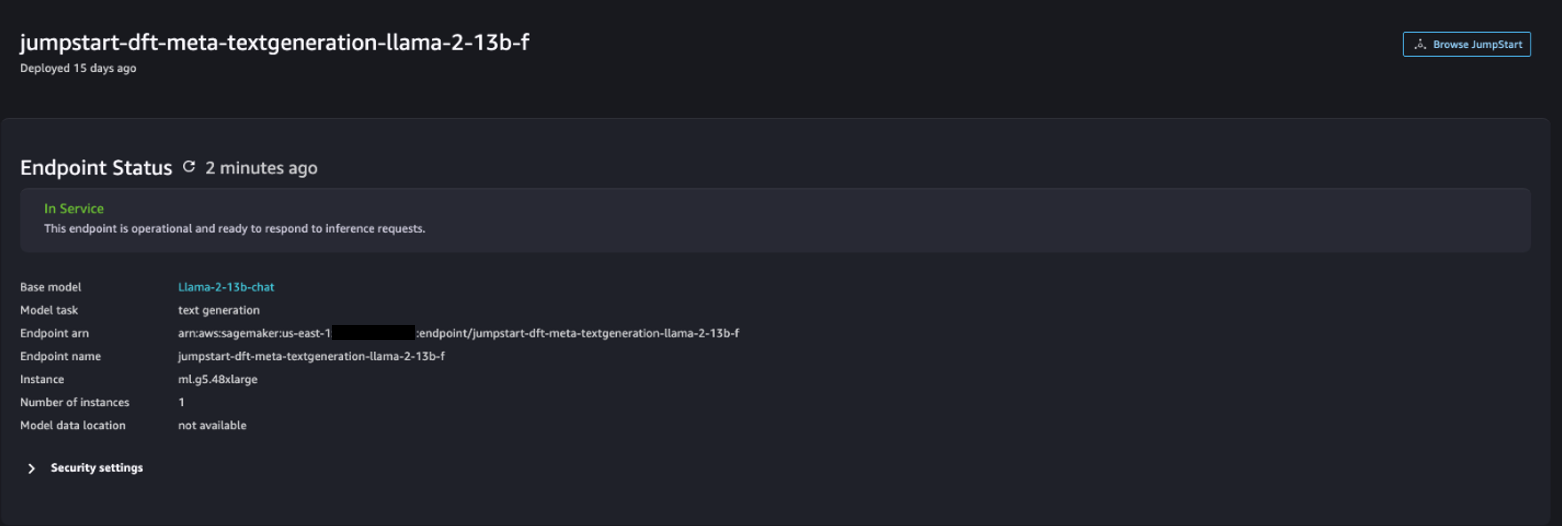
Una vez que la implementación sea exitosa, debería poder ver el In Service de estado.
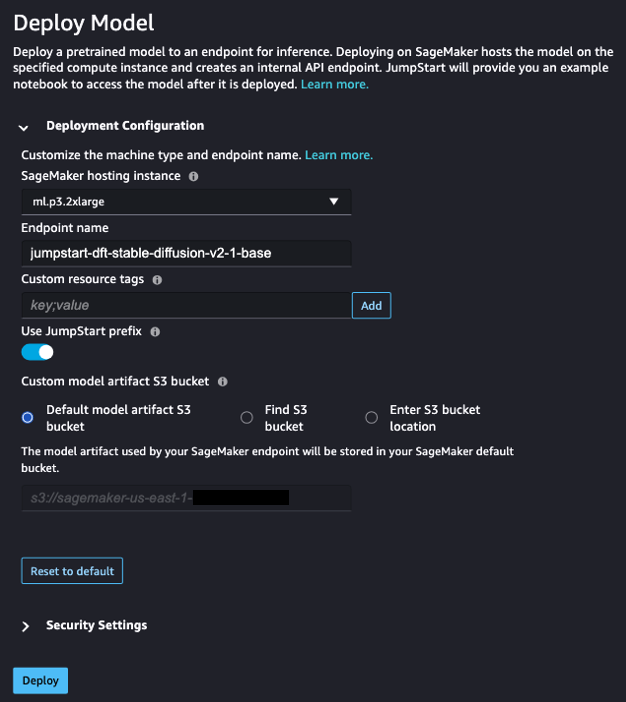
- En Maquetas, cuadernos, soluciones. página, busque Difusión estable 2.1.
- under Configuración de implementación, Para Instancia de alojamiento de SageMaker, escoger ml.p3.2xgrande y para Nombre de punto final, introduzca
jumpstart-dft-stable-diffusion-v2-1-base. - Elige Despliegue.
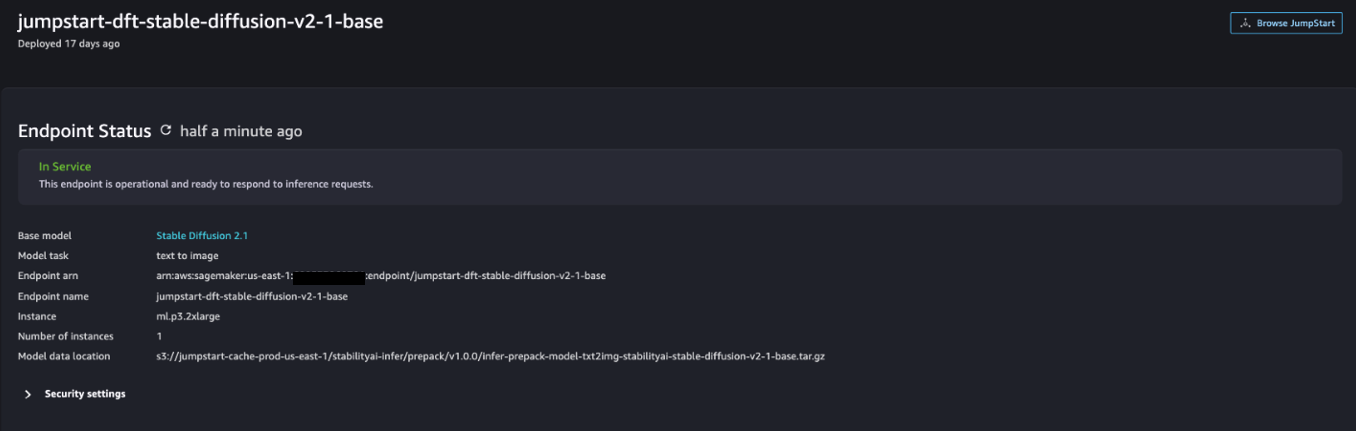
Una vez que la implementación sea exitosa, debería poder ver el In Service de estado.
Implemente permisos de Lambda e IAM mediante AWS CloudFormation
Esta sección describe cómo puede iniciar una pila de CloudFormation que implemente una función Lambda que procese su solicitud de usuario y llame al punto final de SageMaker que implementó, e implemente todos los permisos de IAM necesarios. Complete los siguientes pasos:
- Navegue hasta la Repositorio GitHub y descargue la plantilla de CloudFormation (
lambda.cfn.yaml) a su máquina local. - En la consola de CloudFormation, elija el Crear pila menú desplegable y elija Con nuevos recursos (estándar).
- En Especificar plantilla página, seleccione Subir un archivo de plantilla y Elija el archivo.
- Elija el
lambda.cfn.yamlarchivo que descargaste, luego elige Siguiente. - En Especificar detalles de la pila página, ingrese un nombre de pila y la clave API que obtuvo en los requisitos previos, luego elija Siguiente.
- En Configurar opciones de pila página, elige Siguiente.
- Revise y reconozca los cambios y elija Enviar.
Configurar la interfaz de usuario web
Esta sección describe los pasos para ejecutar la interfaz de usuario web (creada usando Sistema de diseño de paisajes con nubes) en su máquina local:
- En la consola de IAM, navegue hasta el usuario
functionUrl. - En Credenciales de seguridad pestaña, elegir Crear clave de acceso.
- En Acceda a mejores prácticas y alternativas clave página, seleccione Interfaz de línea de comandos (CLI) y elige Siguiente.
- En Establecer etiqueta de descripción página, elige Crear clave de acceso.
- Copie la clave de acceso y la clave de acceso secreta.
- Elige Terminado.
- Navegue hasta la Repositorio GitHub y descargar el
react-llm-chat-studiocódigo. - Inicie la carpeta en su IDE preferido y abra una terminal.
- Navegue hasta
src/configs/aws.jsone ingrese la clave de acceso y la clave de acceso secreta que obtuvo. - Ingrese los siguientes comandos en la terminal:
- Abierto http://localhost:3000 en tu navegador y comienza a interactuar con tus modelos!
Para usar Chat Studio, elija un modelo fundamental en el menú desplegable e ingrese su consulta en el cuadro de texto. Para obtener imágenes generadas por IA junto con la respuesta, agregue la frase "con imágenes" al final de su consulta.
Agregue otros modelos de base de SageMaker
Puede ampliar aún más la capacidad de esta solución para incluir modelos básicos de SageMaker adicionales. Debido a que cada modelo espera diferentes formatos de entrada y salida al invocar su punto final de SageMaker, deberá escribir algún código de transformación en la función Lambda callSageMakerEndpoints para interactuar con el modelo.
Esta sección describe los pasos generales y los cambios de código necesarios para implementar un modelo adicional de su elección. Tenga en cuenta que se requieren conocimientos básicos del lenguaje Python para los pasos 6 a 8.
- En SageMaker Studio, implemente el modelo básico de SageMaker de su elección.
- Elige Inicio rápido de SageMaker y Lanzar recursos JumpStart.
- Elija el punto final del modelo recién implementado y elija cuaderno abierto.
- En la consola de la computadora portátil, busque los parámetros de carga útil.
Estos son los campos que espera el nuevo modelo al invocar su punto final de SageMaker. La siguiente captura de pantalla muestra un ejemplo.

- En la consola Lambda, navegue hasta
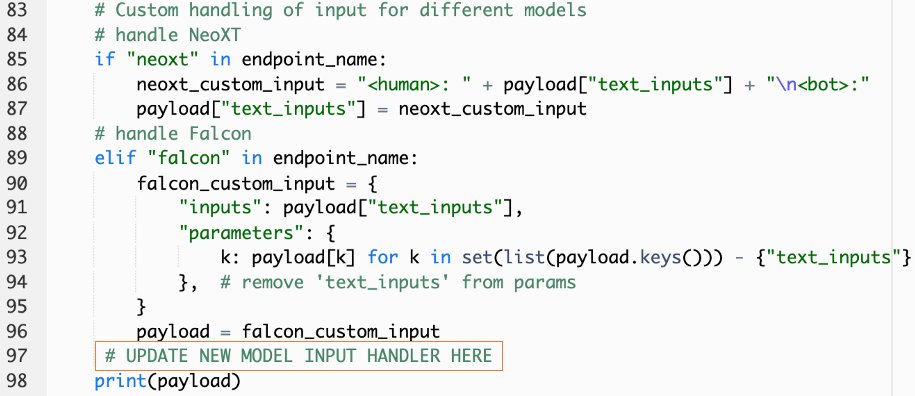
callSageMakerEndpoints. - Agregue un controlador de entrada personalizado para su nuevo modelo.
En la siguiente captura de pantalla, transformamos la entrada para Falcon 40B Instruct BF16 y GPT NeoXT Chat Base 20B FP16. Puede insertar su lógica de parámetros personalizada como se indica para agregar la lógica de transformación de entrada con referencia a los parámetros de carga útil que copió.
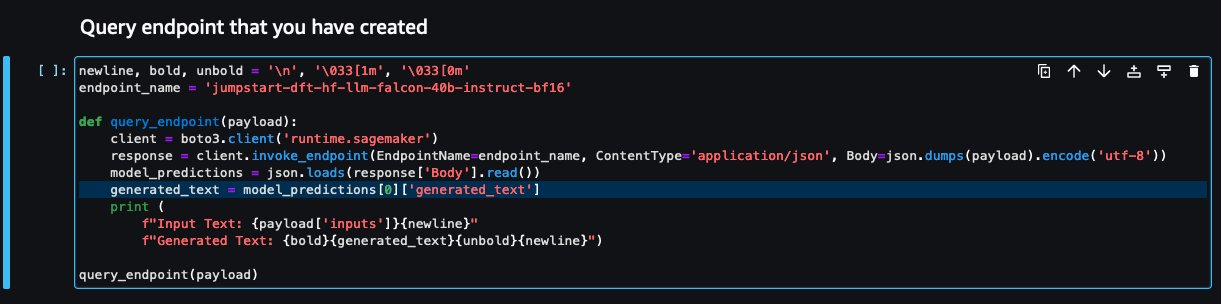
- Regrese a la consola del portátil y localice
query_endpoint.
Esta función le da una idea de cómo transformar la salida de los modelos para extraer la respuesta de texto final.
- Con referencia al código en
query_endpoint, agregue un controlador de salida personalizado para su nuevo modelo.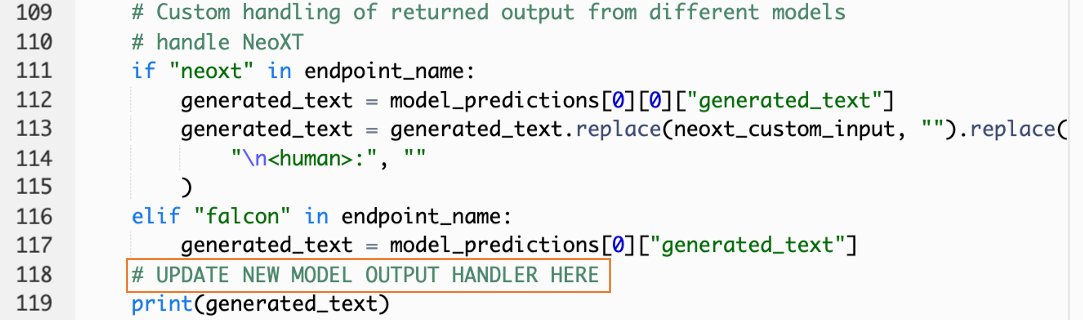
- Elige Implementar.
- Abra su IDE, inicie el
react-llm-chat-studiocódigo y navegue hastasrc/configs/models.json. - Agregue el nombre de su modelo y el punto final del modelo, e ingrese los parámetros de carga útil del Paso 4 en
payloadutilizando el siguiente formato: - ¡Actualiza tu navegador para comenzar a interactuar con tu nuevo modelo!
Implementar la aplicación usando Amplify
Amplify es una solución completa que le permite implementar su aplicación de manera rápida y eficiente. Esta sección describe los pasos para implementar Chat Studio en un Amazon CloudFront distribución usando Amplify si desea compartir su aplicación con otros usuarios.
- Navegue hasta la
react-llm-chat-studiocarpeta de código que creó anteriormente. - Ingrese los siguientes comandos en la terminal y siga las instrucciones de configuración:
- Inicialice un nuevo proyecto de Amplify utilizando el siguiente comando. Proporcione un nombre de proyecto, acepte las configuraciones predeterminadas y elija Claves de acceso de AWS cuando se le solicite que seleccione el método de autenticación.
- Aloje el proyecto Amplify usando el siguiente comando. Elegir Amazon CloudFront y S3 cuando se le solicite que seleccione el modo de complemento.
- Finalmente, cree e implemente el proyecto con el siguiente comando:
- Una vez que la implementación sea exitosa, abra la URL proporcionada en su navegador y comience a interactuar con sus modelos.
Limpiar
Para evitar incurrir en cargos futuros, complete los siguientes pasos:
- Elimine la pila de CloudFormation. Para obtener instrucciones, consulte Eliminación de una pila en la consola de AWS CloudFormation.
- Elimine el punto final de SageMaker JumpStart. Para obtener instrucciones, consulte Eliminar puntos finales y recursos.
- Elimine el dominio de SageMaker. Para obtener instrucciones, consulte Eliminar un dominio de Amazon SageMaker.
Conclusión
En esta publicación, explicamos cómo crear una interfaz de usuario web para interactuar con LLM implementados en AWS.
Con esta solución, puede interactuar con su LLM y mantener una conversación de manera fácil de usar para probar o hacer preguntas de LLM y obtener un collage de imágenes y videos si es necesario.
Puede ampliar esta solución de varias maneras, como integrar modelos de cimentación adicionales, integrarse con Amazon Kendra para habilitar la búsqueda inteligente basada en ML para comprender el contenido empresarial, ¡y más!
Te invitamos a experimentar con diferentes LLM previamente capacitados disponibles en AWS, o desarrolle o incluso cree sus propios LLM en SageMaker. ¡Háganos saber sus preguntas y hallazgos en los comentarios y diviértase!
Sobre los autores
 Jarrett Yeo Shan Wei es arquitecto de nube asociado en servicios profesionales de AWS que cubre el sector público en toda la ASEAN y aboga por ayudar a los clientes a modernizarse y migrar a la nube. Ha obtenido cinco certificaciones de AWS y también ha publicado un artículo de investigación sobre conjuntos de máquinas potenciadoras de gradiente en la 8ª Conferencia Internacional sobre IA. En su tiempo libre, Jarrett se concentra y contribuye a la escena de la IA generativa en AWS.
Jarrett Yeo Shan Wei es arquitecto de nube asociado en servicios profesionales de AWS que cubre el sector público en toda la ASEAN y aboga por ayudar a los clientes a modernizarse y migrar a la nube. Ha obtenido cinco certificaciones de AWS y también ha publicado un artículo de investigación sobre conjuntos de máquinas potenciadoras de gradiente en la 8ª Conferencia Internacional sobre IA. En su tiempo libre, Jarrett se concentra y contribuye a la escena de la IA generativa en AWS.
 Lee Xin es arquitecto asociado de la nube en AWS. Utiliza la tecnología para ayudar a los clientes a lograr los resultados deseados en su viaje de adopción de la nube y le apasiona la IA/ML. Fuera del trabajo, le encanta viajar, hacer senderismo y pasar tiempo con familiares y amigos.
Lee Xin es arquitecto asociado de la nube en AWS. Utiliza la tecnología para ayudar a los clientes a lograr los resultados deseados en su viaje de adopción de la nube y le apasiona la IA/ML. Fuera del trabajo, le encanta viajar, hacer senderismo y pasar tiempo con familiares y amigos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/create-a-web-ui-to-interact-with-llms-using-amazon-sagemaker-jumpstart/

