Los ingenieros de datos y los científicos de datos dependen de la infraestructura de procesamiento de datos distribuidos como EMR de Amazon para realizar trabajos de procesamiento de datos y análisis avanzados en grandes volúmenes de datos. En la mayoría de las organizaciones medianas y empresariales, los equipos de operaciones en la nube se encargan de la adquisición, el aprovisionamiento y el mantenimiento de las infraestructuras de TI, y sus objetivos y mejores prácticas difieren de los equipos de ingeniería y ciencia de datos. Hacer cumplir las mejores prácticas de infraestructura y los controles de gobierno presenta desafíos interesantes para los equipos de análisis:
- agilidad limitada – El diseño y la implementación de un clúster con la configuración de red, seguridad y monitoreo requerida requiere una gran experiencia en infraestructura de nube. Esto da como resultado una alta dependencia de los equipos de operaciones para realizar tareas simples de experimentación y desarrollo. Esto normalmente resulta en semanas o meses para implementar un entorno.
- Riesgos de seguridad y rendimiento – Las actividades de experimentación y desarrollo generalmente requieren compartir entornos existentes con otros equipos, lo que presenta riesgos de seguridad y rendimiento debido a la falta de aislamiento de la carga de trabajo.
- Colaboración limitada – La complejidad de la seguridad de ejecutar entornos compartidos y la falta de una interfaz de usuario web compartida limita la capacidad del equipo de análisis para compartir y colaborar durante las tareas de desarrollo.
Para promover la experimentación y resolver el desafío de la agilidad, las organizaciones deben reducir la complejidad de la implementación y eliminar las dependencias de los equipos de operaciones en la nube mientras mantienen medidas de seguridad para optimizar los costos, la seguridad y la utilización de recursos. En esta publicación, lo explicamos cómo implementar una plataforma de análisis de autoservicio con Amazon EMR y Estudio de Amazon EMR para mejorar la agilidad de sus equipos de ingeniería y ciencia de datos sin comprometer la seguridad, la escalabilidad, la resiliencia y la rentabilidad de sus cargas de trabajo de big data.
Resumen de la solución
Una plataforma de análisis de datos de autoservicio con Amazon EMR y Amazon EMR Studio ofrece las siguientes ventajas:
- Es fácil de iniciar y acceder para ingenieros de datos y científicos de datos.
- El sólido entorno de desarrollo integrado (IDE) es interactivo, hace que los datos sean fáciles de explorar y proporciona todas las herramientas necesarias para depurar, crear y programar canalizaciones de datos.
- Permite la colaboración de los equipos de análisis con el nivel adecuado de aislamiento de la carga de trabajo para mayor seguridad.
- Elimina la dependencia de los equipos de operaciones en la nube al permitir que los administradores dentro de cada organización de análisis autoaprovisionen, escalen y desaprovisionen recursos desde la misma interfaz de usuario, sin exponer las complejidades de la infraestructura del clúster de EMR y sin comprometer la seguridad, la gobernanza y la costos
- Simplifica el paso de la creación de prototipos a un entorno de producción.
- Los equipos de operaciones en la nube pueden administrar de forma independiente las configuraciones de clústeres de EMR como productos y optimizar continuamente los costos y mejorar la seguridad, la confiabilidad y el rendimiento de sus clústeres de EMR.
Amazon EMR Studio es un IDE basado en web que proporciona portátiles Jupyter totalmente administrados donde los equipos pueden desarrollar, visualizar y depurar aplicaciones escritas en R, Python, Scala y PySpark, y herramientas como Spark UI para brindar una experiencia de desarrollo interactiva y simplificar depuración de trabajos. Los científicos de datos y los ingenieros de datos pueden acceder directamente a Amazon EMR Studio a través de una URL habilitada para el inicio de sesión único y colaborar con sus pares utilizando estos cuadernos dentro del concepto de un espacio de trabajo de Amazon EMR Studio, código de versión con repositorios como GitHub y Bitbucket, o ejecutar cuadernos parametrizados. como parte de flujos de trabajo programados mediante servicios de orquestación. Las aplicaciones de notebook de Amazon EMR Studio se ejecutan en clústeres de EMR, por lo que obtiene el beneficio de un motor de procesamiento de datos altamente escalable que utiliza el rendimiento optimizado Tiempo de ejecución de Amazon EMR para Apache Spark.
El siguiente diagrama ilustra la arquitectura de la plataforma de análisis de autoservicio con Amazon EMR y Amazon EMR Studio.

Los equipos de operaciones en la nube pueden asignar un entorno de Amazon EMR Studio a cada equipo para aislar y aprovisionar usuarios desarrolladores y administradores de Amazon EMR Studio dentro de cada equipo. Los equipos de operaciones en la nube tienen control total sobre los permisos que tiene cada usuario de Amazon EMR Studio a través de Políticas de permisos de Amazon EMR Studio y controle las configuraciones de clústeres de EMR que los administradores de Amazon EMR Studio pueden implementar a través de plantillas de clústeres. Los administradores de Amazon EMR Studio dentro de cada equipo pueden asignar espacios de trabajo a cada desarrollador y adjuntarlos a clústeres de EMR existentes o, si está permitido, autoaprovisionar clústeres de EMR a partir de plantillas predefinidas. Cada espacio de trabajo es una instancia de Jupyter sin servidor con archivos de notebook respaldados continuamente en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubeta. Los usuarios pueden conectarse o desconectarse de los clústeres de EMR aprovisionados y usted solo paga por la capacidad de cómputo del clúster de EMR utilizada.
Los equipos de operaciones en la nube organizan configuraciones de clústeres de EMR como productos en la pestaña Catálogo de servicios de AWS. En AWS Service Catalog, las plantillas de clúster de EMR se organizan como productos en un portafolio que comparte con los usuarios de Amazon EMR Studio. Las plantillas ocultan las complejidades de la configuración de la infraestructura y pueden tener parámetros personalizados para permitir una mayor optimización según los requisitos de la carga de trabajo. Después de publicar una plantilla de clúster, los administradores de Amazon EMR Studio pueden lanzar nuevos clústeres y conectarse a espacios de trabajo nuevos o existentes dentro de Amazon EMR Studio sin depender de los equipos de operaciones en la nube. Esto hace que sea más fácil para los equipos probar actualizaciones, compartir plantillas predefinidas entre equipos y permitir que los usuarios de análisis se centren en lograr resultados comerciales.
El siguiente diagrama ilustra la arquitectura de desacoplamiento.
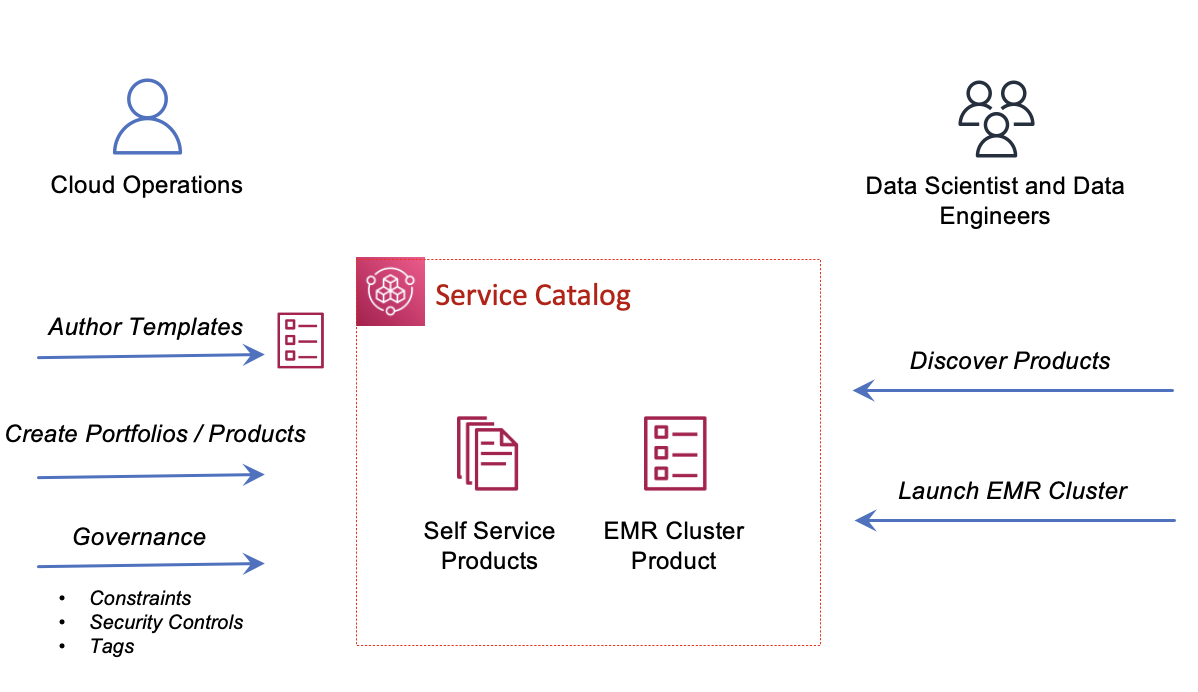
Puede desvincular la definición de las configuraciones de clústeres de EMR como productos y permitir que equipos independientes implementen espacios de trabajo sin servidor y adjunten clústeres de EMR autoaprovisionados dentro de Amazon EMR Studio en minutos. Esto permite a las organizaciones crear un entorno ágil y de autoservicio para el procesamiento de datos y la ciencia de datos a escala, manteniendo el nivel adecuado de seguridad y gobernanza.
Como ingeniero de operaciones en la nube, la tarea principal es asegurarse de que sus plantillas sigan configuraciones de clúster adecuadas que sean seguras, se ejecuten a un costo óptimo y sean fáciles de usar. Las siguientes secciones analizan las recomendaciones clave para la seguridad, la optimización de costos y la facilidad de uso al definir plantillas de clústeres de EMR para su uso en Amazon EMR Studio. Para obtener más prácticas recomendadas de Amazon EMR, consulte el Guía de mejores prácticas de EMR.
Seguridad
La seguridad es una misión crítica para cualquier carga de trabajo de ciencia de datos y preparación de datos. Asegúrese de seguir estas recomendaciones:
- Aislamiento basado en equipos – Mantenga el aislamiento de la carga de trabajo aprovisionando un entorno de Amazon EMR Studio por equipo y un espacio de trabajo por usuario.
- Autenticación - Utilizar Centro de identidad de AWS IAM (sucesor de AWS Single Sign-On) o acceso federado con Gestión de identidades y accesos de AWS (IAM) para centralizar la gestión de usuarios.
- Autorización – Establezca permisos detallados dentro de su entorno de Amazon EMR Studio. Establezca usuarios limitados (1 o 2) con la función de administrador de Amazon EMR Studio para permitir el aprovisionamiento de espacios de trabajo y clústeres. La mayoría de los ingenieros y científicos de datos tendrán un rol de desarrollador. Para obtener más información sobre cómo definir permisos, consulte Configurar los permisos de usuario de EMR Studio.
- Cifrado – Al definir las plantillas de configuración de su clúster, asegúrese de que se aplique el cifrado tanto en tránsito como en reposo. Por ejemplo, el tráfico entre lagos de datos debe usar la última versión de TLS, los datos se cifran con Servicio de administración de claves de AWS (AWS KMS) en reposo para Amazon S3, Tienda de bloques elásticos de Amazon (Amazon EBS), y Servicio de base de datos relacional de Amazon (Amazon RDS).
Cost
Para optimizar el costo de su clúster EMR en ejecución, considere las siguientes opciones de optimización de costos en sus plantillas de clúster:
- Usar instancias de spot EC2 – Las instancias de spot le permiten aprovechar los no utilizados Nube informática elástica de Amazon (Amazon EC2) en la nube de AWS y ofrece hasta un 90 % de descuento en comparación con los precios bajo demanda. Spot es más adecuado para las cargas de trabajo que se pueden interrumpir o tienen acuerdos de nivel de servicio flexibles, como las cargas de trabajo de prueba y desarrollo.
- Utilizar flotas de instancias - Utilizar flotas de instancia al usar EC2 Spot para aumentar la probabilidad de disponibilidad de Spot. Una flota de instancias es un grupo de instancias EC2 que alojan un tipo de nodo particular (principal, principal o de tarea) en un clúster de EMR. Debido a que las flotas de instancias pueden consistir en una combinación de tipos de instancias, tanto bajo demanda como puntuales, esto aumentará la probabilidad de disponibilidad de instancias puntuales cuando alcance su capacidad objetivo. Considere al menos 10 tipos de instancias en todas las zonas de disponibilidad.
- Utilice el modo de clúster de Spark y asegurarse de que los maestros de aplicaciones se ejecuten en nodos bajo demanda – El maestro de aplicaciones (AM) es el contenedor principal que lanza y monitorea los ejecutores de aplicaciones. Por lo tanto, es importante asegurarse de que el AM sea lo más resistente posible. En un entorno de Amazon EMR Studio, puede esperar que los usuarios ejecuten varias aplicaciones al mismo tiempo. En modo de clúster, sus aplicaciones de Spark pueden ejecutarse como conjuntos independientes de procesos distribuidos en sus nodos de trabajo dentro de los AM. De forma predeterminada, un AM puede ejecutarse en cualquiera de los nodos trabajadores. Modifique el comportamiento para garantizar que los AM se ejecuten solo en nodos bajo demanda. Para obtener detalles sobre esta configuración, consulte Uso puntual.
- Utilice el escalado administrado de Amazon EMR – Esto evita el aprovisionamiento excesivo de clústeres y escala automáticamente sus clústeres hacia arriba o hacia abajo en función de la utilización de recursos. Con el escalado administrado de Amazon EMR, AWS administra la actividad de escalado automático evaluando continuamente las métricas del clúster y tomando decisiones de escalado optimizadas.
- Implementar una política de terminación automática – Esto evita los clústeres inactivos o la necesidad de monitorear y detener manualmente los clústeres de EMR no utilizados. Cuando estableces un política de terminación automática, especifica la cantidad de tiempo de inactividad después del cual el clúster debe apagarse automáticamente.
- Proporcione visibilidad y controle los costos de uso – Puede proporcionar visibilidad de los clústeres de EMR a los administradores de Amazon EMR Studio y a los equipos de operaciones en la nube configurando etiquetas de asignación de costos definidas por el usuario. Estas etiquetas ayudan a crear informes detallados de costos y uso en AWS Cost Explorer para clústeres de EMR en varias dimensiones.
Facilidad de uso
Con Amazon EMR Studio, los administradores dentro de los equipos de ciencia e ingeniería de datos pueden autoaprovisionar clústeres de EMR a partir de plantillas preconstruidas con Formación en la nube de AWS. Las plantillas se pueden parametrizar para optimizar la configuración del clúster de acuerdo con los requisitos de carga de trabajo de cada equipo. Para facilitar el uso y evitar las dependencias de los equipos de operaciones en la nube, los parámetros deben evitar solicitar detalles innecesarios o exponer las complejidades de la infraestructura. Aquí hay algunos consejos para abstraer los valores de entrada:
- Mantenga el número de preguntas al mínimo (menos de 5).
- Ocultar configuraciones de red y seguridad. Sea obstinado al definir su clúster de acuerdo con sus requisitos de seguridad y red siguiendo Prácticas recomendadas de Amazon EMR.
- Evite valores de entrada que requieran conocimientos de terminología específica de la nube de AWS, como tipos de instancias EC2, instancias puntuales frente a instancias bajo demanda, etc.
- Parámetros de entrada abstractos considerando la información disponible para los equipos de ingeniería de datos y ciencia de datos. Concéntrese en los parámetros que ayudarán a optimizar aún más el tamaño y los costos de sus clústeres de EMR.
La siguiente captura de pantalla es un ejemplo de los valores de entrada que puede solicitar a un equipo de ciencia de datos y cómo resolverlos a través de las características de la plantilla de CloudFormation.
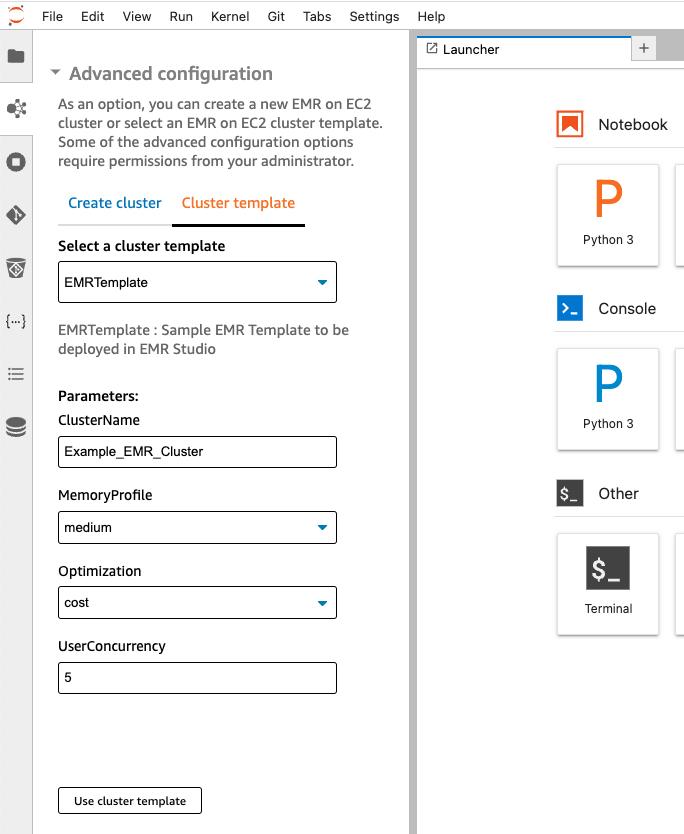
Los parámetros de entrada son los siguientes:
- Concurrencia de usuarios – Saber cuántos usuarios se espera que ejecuten trabajos simultáneamente ayudará a determinar la cantidad de ejecutores a aprovisionar
- Optimizado por costo o confiabilidad – Usar instancias de spot para optimizar el costo; para cargas de trabajo sensibles a SLA, use solo nodos bajo demanda
- Requisitos de memoria de carga de trabajo (pequeño, mediano, grande) – Determine la proporción de memoria por ejecutor de Spark en su clúster de EMR
Las siguientes secciones describen cómo resolver las configuraciones de clúster de EMR a partir de estos parámetros de entrada y qué características usar en sus plantillas de CloudFormation.
Simultaneidad de usuarios: ¿Cuántos usuarios simultáneos necesita?
Conocer la simultaneidad de usuarios esperada ayudará a determinar la capacidad del nodo de destino de su clúster o la capacidad mínima/máxima al usar la función de escalado automático de Amazon EMR. Considere cuánta capacidad (núcleos de CPU y memoria) necesita cada científico de datos para ejecutar su carga de trabajo promedio.
Por ejemplo, supongamos que desea aprovisionar 10 ejecutores para cada científico de datos del equipo. Si la simultaneidad esperada se establece en 7, debe aprovisionar 70 ejecutores. Un tipo de instancia r5.2xlarge tiene 8 núcleos y 64 Gib de RAM. Con la configuración predeterminada, el número de núcleos (spark.executor.cores) se establece en 1 y la memoria (spark.executor.memory) se establece en 6 Gib. Se reservará un núcleo para ejecutar la aplicación Spark, por lo que quedarán siete ejecutores por nodo. Necesitará un total de 10 nodos r5.2xlarge para satisfacer la demanda. La capacidad objetivo puede resolverse dinámicamente en 10 a partir de la entrada de simultaneidad del usuario, y los pesos de capacidad en su flota aseguran que se alcance la misma capacidad si se aprovisionan diferentes tamaños de instancia para cumplir con la capacidad esperada.
Uso de una formación en la nube transformar le permite resolver la capacidad objetivo en función de un valor de entrada numérico. Una transformación pasa su script de plantilla a un personalizado AWS Lambda para que pueda reemplazar cualquier marcador de posición en su plantilla de CloudFormation con valores resueltos a partir de sus parámetros de entrada.
El siguiente script de CloudFormation llama a la transformación emr-size-macro que reemplaza la custom::Target marcador de posición en el TargetSpotCapacity objeto basado en el valor de entrada UserConcurrency:
Optimizado por costo o confiabilidad: ¿Cómo optimiza su clúster de EMR?
Este parámetro determina si el clúster debe usar instancias de spot para nodos de tareas para optimizar el costo o aprovisionar solo nodos bajo demanda para cargas de trabajo sensibles a SLA que deben optimizarse para la confiabilidad.
Puede utilizar la función Condiciones de CloudFormation en su plantilla para resolver las configuraciones de flota de instancias que desee. El siguiente código muestra cómo se ve la función Condiciones en una plantilla de EMR de muestra:
Requisitos de memoria de carga de trabajo: ¿Qué tamaño de clúster necesita?
Este parámetro ayuda a determinar la cantidad de memoria y CPU para asignar a cada ejecutor de Spark. La proporción específica de memoria a CPU asignada a cada ejecutor debe configurarse adecuadamente para evitar errores de falta de memoria. Puede asignar el parámetro de entrada (pequeño, mediano, grande) a tipos de instancia específicos para seleccionar la relación CPU/memoria. Amazon EMR tiene configuraciones predeterminadas (spark.executor.cores, spark.executor.memory) en función de cada tipo de instancia. Por ejemplo, una solicitud de clúster de tamaño pequeño podría resolverse en instancias de propósito general como m5 (predeterminado: 2 núcleos y 4 gb por ejecutor), mientras que un flujo de trabajo mediano puede resolverse en un tipo R (predeterminado: 1 núcleo y 6 gb por ejecutor). Puede ajustar aún más la memoria predeterminada de Amazon EMR y la asignación de núcleos de CPU para cada tipo de instancia siguiendo las mejores prácticas descritas en el Spark sección de la Guías de mejores prácticas de EMR.
Utilice la sección Asignaciones de CloudFormation para resolver la configuración del clúster en su plantilla:
Conclusión
En esta publicación, mostramos cómo crear una plataforma de análisis de autoservicio con Amazon EMR y Amazon EMR Studio para aprovechar al máximo la agilidad que brinda la nube de AWS al reducir considerablemente los tiempos de implementación sin comprometer la gobernanza. También lo guiamos a través de las mejores prácticas en seguridad, costo y facilidad de uso al definir su entorno de Amazon EMR Studio para que los equipos de ingeniería y ciencia de datos puedan acelerar sus ciclos de desarrollo eliminando las dependencias de los equipos de operaciones en la nube al aprovisionar sus plataformas de procesamiento de datos.
Si es la primera vez que explora Amazon EMR Studio, le recomendamos que consulte el Talleres de Amazon EMR y refiriéndose a Cree un estudio EMR. Continúe haciendo referencia a la Guía de prácticas recomendadas de Amazon EMR cuando definas tus plantillas y echa un vistazo a las Repositorio de muestra de Amazon EMR Studio para referencias de plantillas de clúster de EMR.
Acerca de los autores
 pablo redondo es Arquitecto Principal de Soluciones en Amazon Web Services. Es un entusiasta de los datos con más de 16 años de experiencia en la industria de la tecnología financiera y la atención médica y es miembro de la comunidad de campo técnico (TFC) de AWS Analytics. Pablo ha estado liderando el programa AWS Gain Insights para ayudar a los clientes de AWS a obtener mejores conocimientos y valor comercial tangible a partir de sus iniciativas de análisis de datos.
pablo redondo es Arquitecto Principal de Soluciones en Amazon Web Services. Es un entusiasta de los datos con más de 16 años de experiencia en la industria de la tecnología financiera y la atención médica y es miembro de la comunidad de campo técnico (TFC) de AWS Analytics. Pablo ha estado liderando el programa AWS Gain Insights para ayudar a los clientes de AWS a obtener mejores conocimientos y valor comercial tangible a partir de sus iniciativas de análisis de datos.
 Malini Chatterjee es arquitecto sénior de soluciones en AWS. Brinda orientación a los clientes de AWS sobre sus cargas de trabajo en una variedad de tecnologías de AWS con una amplia experiencia en datos y análisis. Le apasiona mucho la danza semiclásica y actúa en eventos comunitarios. Le encanta viajar y pasar tiempo con su familia.
Malini Chatterjee es arquitecto sénior de soluciones en AWS. Brinda orientación a los clientes de AWS sobre sus cargas de trabajo en una variedad de tecnologías de AWS con una amplia experiencia en datos y análisis. Le apasiona mucho la danza semiclásica y actúa en eventos comunitarios. Le encanta viajar y pasar tiempo con su familia.
 Avijit Gosvami es Principal Solutions Architect en AWS, especializado en datos y análisis. Apoya a los clientes estratégicos de AWS en la creación de soluciones de lago de datos escalables, seguras y de alto rendimiento en AWS mediante el uso de servicios administrados por AWS y soluciones de código abierto. Fuera de su trabajo, a Avijit le gusta viajar, caminar por los senderos del Área de la Bahía de San Francisco, ver deportes y escuchar música.
Avijit Gosvami es Principal Solutions Architect en AWS, especializado en datos y análisis. Apoya a los clientes estratégicos de AWS en la creación de soluciones de lago de datos escalables, seguras y de alto rendimiento en AWS mediante el uso de servicios administrados por AWS y soluciones de código abierto. Fuera de su trabajo, a Avijit le gusta viajar, caminar por los senderos del Área de la Bahía de San Francisco, ver deportes y escuchar música.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-an-optimized-self-service-interactive-analytics-platform-with-amazon-emr-studio/

