Imagen del autor
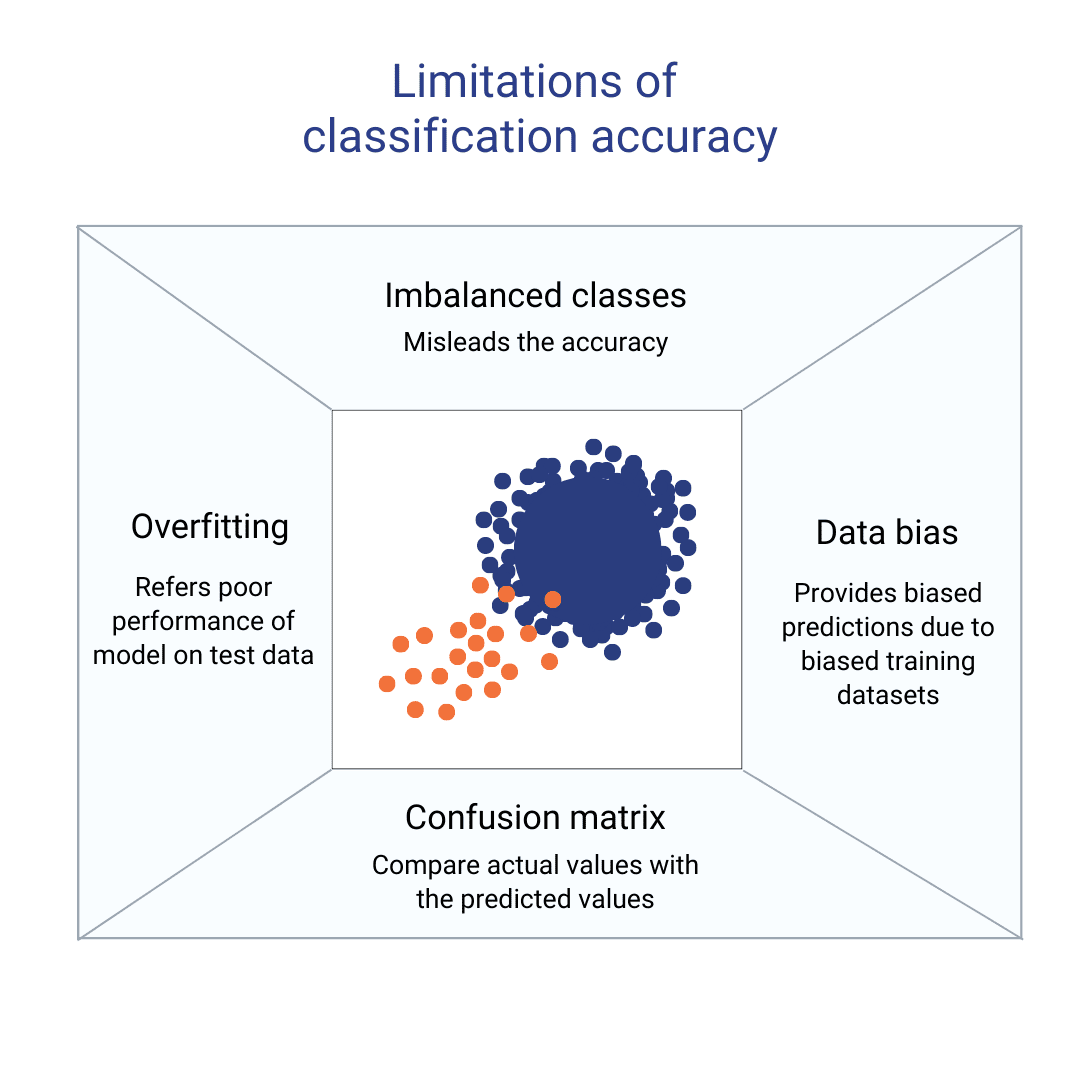
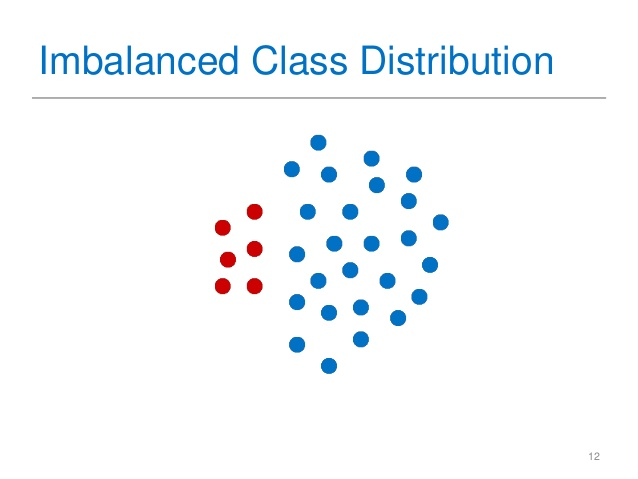
La precisión puede ser engañosa si el conjunto de datos contiene clasificaciones que son desiguales. Por ejemplo, un modelo que simplemente predice la clase mayoritaria tendrá una precisión del 99 % si la clase dominante comprende el 99 % de los datos. Desafortunadamente, no podrá clasificar adecuadamente a la clase minoritaria. Se deben utilizar otras métricas, como la precisión, la recuperación y la puntuación F1, para abordar este problema.
Las 5 técnicas más comunes que se pueden utilizar para abordar el problema de la clase desequilibrada en la precisión de la clasificación son:
Clase desequilibrada | Ingeniería del conocimiento
- Sobremuestreo de la clase minoritaria: en esta técnica, duplicamos los ejemplos en la clase minoritaria para equilibrar la distribución de clases.
- Reducción de muestreo de la clase mayoritaria: en esta técnica eliminamos ejemplos de la clase mayoritaria para equilibrar la distribución de clases.
- Generación de datos sintéticos: Una técnica utilizada para generar nuevas muestras de la clase minoritaria. Cuando se introduce ruido aleatorio en los ejemplos existentes o mediante la generación de nuevos ejemplos a través de la interpolación o extrapolación, se produce la generación de datos sintéticos.
- Detección de anomalías: la clase minoritaria se trata como una anomalía en esta técnica, mientras que la clase mayoritaria se trata como datos normales.
- Cambio del umbral de decisión: esta técnica ajusta el umbral de decisión del clasificador para aumentar la sensibilidad a la clase minoritaria.
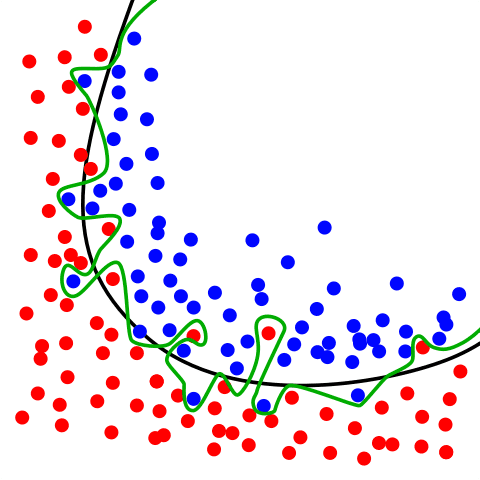
Cuando un modelo está sobreentrenado con los datos de entrenamiento y tiene un rendimiento inferior al de los datos de prueba, se dice que está sobreajustado. Como resultado, la precisión puede ser alta en el conjunto de entrenamiento pero pobre en el conjunto de prueba. Técnicas como validación cruzada y regularización se debe aplicar para resolver este problema.
Reequipamiento | Freepik
Hay varias técnicas que se pueden utilizar para abordar el sobreajuste.
- Entrenar el modelo con más datos: Esto permite que el algoritmo detecte mejor la señal y minimice los errores.
- Regularización: esto implica agregar un término de penalización a la función de costo durante el entrenamiento, lo que ayuda a restringir la complejidad del modelo y reducir el sobreajuste.
- Validación cruzada: esta técnica ayuda a evaluar el rendimiento del modelo al dividir los datos en conjuntos de entrenamiento y validación, y luego entrenar y evaluar el modelo en cada conjunto.
- Métodos de conjunto. Esta es una técnica que implica entrenar varios modelos y luego combinar sus predicciones, lo que ayuda a reducir la varianza y el sesgo del modelo.
El modelo producirá predicciones sesgadas si el conjunto de datos de entrenamiento está sesgado. Esto puede resultar en una alta precisión en los datos de entrenamiento, pero el rendimiento en datos no entrenados puede ser inferior. Se deben utilizar técnicas como el aumento de datos y el remuestreo para abordar este problema. Algunas otras formas de abordar este problema se enumeran a continuación:

Sesgo de datos | Explorium
- Una técnica es asegurarse de que los datos utilizados sean representativos de la población que se pretende modelar. Esto se puede hacer mediante un muestreo aleatorio de datos de la población o mediante el uso de técnicas como el sobremuestreo o el submuestreo para equilibrar los datos.
- Pruebe y evalúe los modelos cuidadosamente midiendo los niveles de precisión para diferentes categorías demográficas y grupos sensibles. Esto puede ayudar a identificar cualquier sesgo en los datos y el modelo y abordarlos.
- Tenga en cuenta el sesgo del observador, que ocurre cuando impone sus opiniones o deseos sobre los datos, ya sea consciente o accidentalmente. Esto se puede hacer siendo consciente del potencial de sesgo y tomando medidas para minimizarlo.
- Utilice técnicas de preprocesamiento para eliminar o corregir el sesgo de datos. Por ejemplo, utilizando técnicas como limpieza de datos, normalización de datos y escalado de datos.
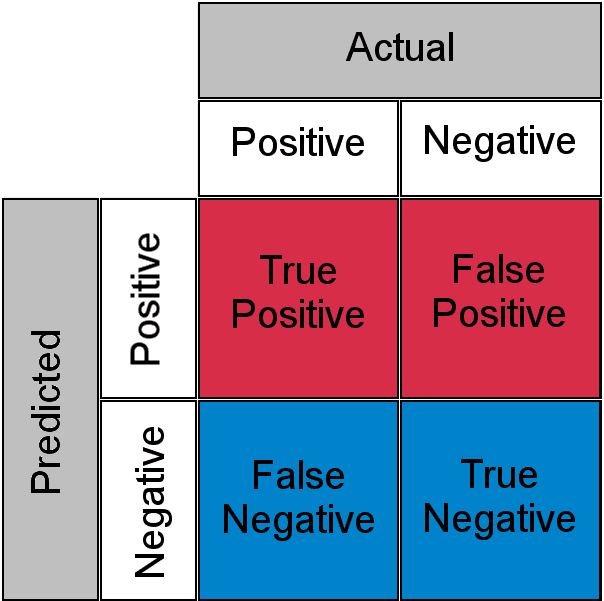
Imagen del autor
El rendimiento de un algoritmo de clasificación se describe utilizando una matriz de confusión. Es un diseño de tabla donde los valores reales se contrastan con los valores anticipados en la matriz para definir el rendimiento de un algoritmo de clasificación. Algunas formas de abordar este problema son:
- Analice los valores en la matriz e identifique cualquier patrón o tendencia en los errores. Por ejemplo, si hay muchos falsos negativos, podría indicar que el modelo no es lo suficientemente sensible a ciertas clases.
- Utilice métricas como precisión, recuperación y puntuación F1 para evaluar el rendimiento del modelo. Estas métricas brindan una comprensión más detallada del rendimiento del modelo y pueden ayudar a identificar áreas específicas en las que el modelo tiene problemas.
- Ajuste el umbral del modelo, si el umbral es demasiado alto o demasiado bajo, esto puede causar que el modelo produzca más falsos positivos o falsos negativos.
- Utilice métodos de conjunto, como bagging y boosting, que pueden ayudar a mejorar el rendimiento del modelo al combinar las predicciones de varios modelos.
Obtenga más información sobre la matriz de confusión en este video
En conclusión, la precisión de la clasificación es una métrica útil para evaluar el rendimiento de un modelo de aprendizaje automático, pero puede ser engañosa. Para adquirir una perspectiva más completa del rendimiento del modelo, también se deben usar métricas adicionales que incluyen precisión, recuperación, puntaje F1 y matriz de confusión. Para superar problemas como clases desequilibradas, sobreajuste y sesgo de datos, se deben aplicar técnicas que incluyen validación cruzada, normalización, aumento de datos y remuestreo.
Ayesha Saleem Poseer una pasión por renovar las marcas con redacción de contenido significativo, redacción publicitaria, marketing por correo electrónico, redacción SEO, marketing en redes sociales y escritura creativa.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/03/key-issues-associated-classification-accuracy.html?utm_source=rss&utm_medium=rss&utm_campaign=key-issues-associated-with-classification-accuracy

