Introducción
Una categoría específica de modelos de inteligencia artificial conocida como modelos de lenguaje grande (LLM) está diseñado para comprender y generar texto similar al humano. El término "grande" a menudo se cuantifica por la cantidad de parámetros que poseen. Por ejemplo, el modelo GPT-3 de OpenAI tiene 175 mil millones de parámetros. Úselo para una variedad de tareas, como traducir texto, responder preguntas, escribir ensayos, resumir texto. A pesar de la abundancia de recursos que demuestran las capacidades de los LLM y brindan orientación sobre cómo configurar aplicaciones de chat con ellos, existen pocos esfuerzos que examinen a fondo su idoneidad para escenarios comerciales de la vida real. En este artículo, aprenderá cómo crear un sistema de consulta de documentos utilizando LangChain y Flan-T5 XXL aprovechando la creación de aplicaciones basadas en lenguajes grandes.
OBJETIVOS DE APRENDIZAJE
Antes de profundizar en los entresijos técnicos, establezcamos los objetivos de aprendizaje de este artículo:
- Comprender cómo se puede aprovechar LangChain para crear aplicaciones basadas en lenguajes grandes
- Una descripción general concisa del marco de texto a texto y el modelo Flan-T5
- Cómo crear un sistema de consulta de documentos usando LangChain y cualquier modelo LLM
Profundicemos ahora en estas secciones para comprender cada uno de estos conceptos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Papel de LangChain en la creación de aplicaciones LLM
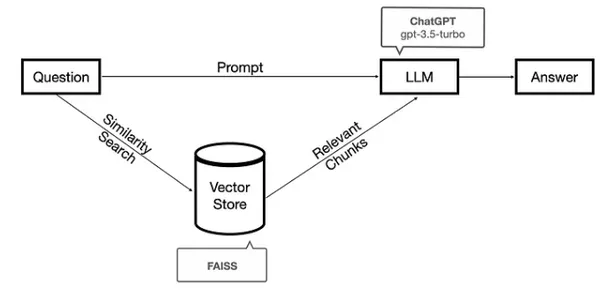
El marco LangChain ha sido diseñado para desarrollar diversas aplicaciones, como chatbots, respuesta generativa a preguntas (GQA) y resúmenes que aprovechan las capacidades de grandes modelos de lenguaje (LLM). LangChain proporciona una solución integral para construir sistemas de consulta de documentos. Esto implica preprocesar un corpus mediante fragmentación, convertir estos fragmentos en espacio vectorial, identificar fragmentos similares cuando se plantea una consulta y aprovechar un modelo de lenguaje para refinar los documentos recuperados y obtener una respuesta adecuada.
Descripción general del modelo Flan-T5
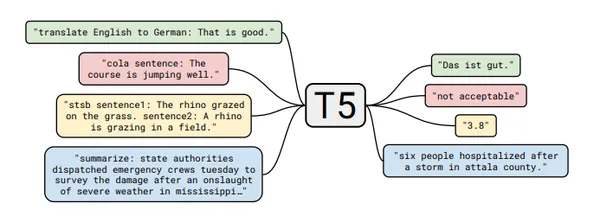
Flan-T5 es un LLM de código abierto disponible comercialmente realizado por investigadores de Google. Es una variante del modelo T5 (Transformador de transferencia de texto a texto). T5 es un modelo de lenguaje de última generación que se entrena en un marco de "texto a texto". Está capacitado para realizar una variedad de tareas de PNL convirtiéndolas a un formato basado en texto. FLAN es la abreviatura de Finetuned Language Net.
Profundicemos en la construcción del sistema de consulta de documentos
Podemos construir este sistema de consulta de documentos aprovechando el modelo LangChain y Flan-T5 XXL en la capa gratuita de Google Colab. Para ejecutar el siguiente código en Google Colab, debemos elegir la “GPU T4” como nuestro tiempo de ejecución. Siga los pasos a continuación para construir el sistema de consulta de documentos:
1: Importar las bibliotecas necesarias
Necesitaríamos importar las siguientes bibliotecas:
from langchain.document_loaders import TextLoader #for textfiles
from langchain.text_splitter import CharacterTextSplitter #text splitter
from langchain.embeddings import HuggingFaceEmbeddings #for using HugginFace models
from langchain.vectorstores import FAISS from langchain.chains.question_answering import load_qa_chain
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub
from langchain.document_loaders import UnstructuredPDFLoader #load pdf
from langchain.indexes import VectorstoreIndexCreator #vectorize db index with chromadb
from langchain.chains import RetrievalQA
from langchain.document_loaders import UnstructuredURLLoader #load urls into docoument-loader
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "xxxxx"
2: Cargando el PDF usando PyPDFLoader
Usamos PyPDFLoader de la biblioteca LangChain aquí para cargar nuestro archivo PDF: "Data-Analysis.pdf". El objeto "cargador" tiene un atributo llamado "load_and_split()" que divide el PDF según las páginas.
#import csvfrom langchain.document_loaders import PyPDFLoader
# Load the PDF file from current working directory
loader = PyPDFLoader("Data-Analysis.pdf")
# Split the PDF into Pages
pages = loader.load_and_split()3: fragmentar el texto según el tamaño del fragmento
Utilice los modelos para generar vectores de incrustación que tengan límites máximos en los fragmentos de texto proporcionados como entrada. Si utilizamos estos modelos para generar incrustaciones para nuestros datos de texto, resulta importante fragmentar los datos a un tamaño específico antes de pasarlos a estos modelos. Aquí usamos RecursiveCharacterTextSplitter para dividir los datos, lo que funciona tomando un texto grande y dividiéndolo según un tamaño de fragmento específico. Lo hace utilizando un conjunto de caracteres.
#import from langchain.text_splitter import RecursiveCharacterTextSplitter
# Define chunk size, overlap and separators
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1024, chunk_overlap=64, separators=['nn', 'n', '(?=>. )', ' ', '']
)
docs = text_splitter.split_documents(pages)
4: Obteniendo incrustaciones numéricas para el texto
Para representar numéricamente datos no estructurados como texto, documentos, imágenes, audio, etc., necesitamos incrustaciones. La forma numérica captura el significado contextual de lo que estamos incorporando. Aquí, utilizamos el objeto HuggingFaceHubEmbeddings para crear incrustaciones para cada documento. Este objeto utiliza el modelo de transformador de oraciones “all-mpnet-base-v2” para mapear oraciones y párrafos en un espacio vectorial denso de 768 dimensiones.
# Embeddings
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()5: Almacenamiento de las incrustaciones en una tienda de vectores
Ahora necesitamos una tienda de vectores para nuestras incrustaciones. Aquí estamos usando FAISS. FAISS, abreviatura de Facebook AI Similarity Search, es una poderosa biblioteca diseñada para la búsqueda y agrupación eficiente de vectores densos que ofrece una variedad de algoritmos que pueden buscar conjuntos de vectores de cualquier tamaño, incluso aquellos que pueden exceder la capacidad de RAM disponible.
#Create the vectorized db
# Vectorstore: https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
from langchain.vectorstores import FAISS
db = FAISS.from_documents(docs, embeddings)6: Búsqueda de similitudes con Flan-T5 XXL
Nos conectamos aquí al hub de cara abrazadora para buscar el modelo Flan-T5 XXL.
Podemos definir una serie de configuraciones de modelo para el modelo, como temperatura y longitud máxima.
La función load_qa_chain proporciona un método simple para enviar documentos a un LLM. Al utilizar el tipo de cadena como "cosas", la función toma una lista de documentos, los combina en un solo mensaje y luego pasa ese mensaje al LLM.
llm=HuggingFaceHub(repo_id="google/flan-t5-xxl", model_kwargs={"temperature":1, "max_length":1000000})
chain = load_qa_chain(llm, chain_type="stuff") #QUERYING
query = "Explain in detail what is quantitative data analysis?"
docs = db.similarity_search(query)
chain.run(input_documents=docs, question=query)
7: Creación de una cadena de control de calidad con el modelo Flan-T5 XXL
Utilice RetrievalQAChain para recuperar documentos utilizando un Retriever y luego utilice una cadena de control de calidad para responder una pregunta basada en los documentos recuperados. Combina el modelo de lenguaje con las capacidades de recuperación de VectorDB.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=db.as_retriever(search_kwargs={"k": 3}))
8: Consultando nuestro PDF
query = "What are the different types of data analysis?"
qa.run(query)#Output "Descriptive data analysis Theory Driven Data Analysis Data or narrative driven analysis"query = "What is the meaning of Descriptive Data Analysis?"
qa.run(query)#import csv#Output "Descriptive data analysis is only concerned with processing and summarizing the data."Aplicaciones al Mundo Real
En la era actual de inundación de datos, existe el desafío constante de obtener información relevante a partir de una cantidad abrumadora de datos textuales. Los motores de búsqueda tradicionales a menudo no logran brindar respuestas precisas y sensibles al contexto a consultas específicas de los usuarios. En consecuencia, ha surgido una demanda creciente de metodologías sofisticadas de procesamiento del lenguaje natural (NLP), con el objetivo de facilitar sistemas precisos de respuesta a preguntas y documentos (DQA). Un sistema de consulta de documentos, como el que construimos, podría ser extremadamente útil para automatizar la interacción con cualquier tipo de documento como PDF, hojas de Excel, archivos html, entre otros. Con este enfoque, muchas personas conscientes del contexto extraen información valiosa de extensas colecciones de documentos.
Conclusión
En este artículo, comenzamos analizando cómo podríamos aprovechar LangChain para cargar datos desde un documento PDF. Amplíe esta capacidad a otros tipos de documentos como CSV, HTML, JSON, Markdown y más. Además, aprendimos formas de dividir los datos en función de un tamaño de fragmento específico, que es un paso necesario antes de generar las incrustaciones del texto. Luego, busqué las incrustaciones de los documentos usando HuggingFaceHubEmbeddings. Después de almacenar las incrustaciones en una tienda de vectores, combinamos Retrieval con nuestro modelo LLM 'Flan-T5 XXL' para responder a las preguntas. Los documentos recuperados y una pregunta del usuario se pasaron al LLM para generar una respuesta a la pregunta formulada.
Puntos clave
- LangChain ofrece un marco integral para una interacción perfecta con LLM, fuentes de datos externas, indicaciones e interfaces de usuario. Permite la creación de aplicaciones únicas construidas alrededor de un LLM "encadenando" componentes de múltiples módulos.
- Flan-T5 es un LLM de código abierto disponible comercialmente. Es una variante del modelo T5 (Text-To-Text Transfer Transformer) desarrollado por Google Research.
- Un almacén de vectores almacena datos en forma de vectores de alta dimensión. Estos vectores son representaciones matemáticas de diversas características o atributos. Diseñe los almacenes de vectores para gestionar de manera eficiente vectores densos y proporcionar capacidades avanzadas de búsqueda de similitudes.
- El proceso de construcción de un sistema de respuesta a preguntas basado en documentos utilizando el modelo LLM y Langchain implica buscar y cargar un archivo de texto, dividir el documento en secciones manejables, convertir estas secciones en incrustaciones, almacenarlas en una base de datos vectorial y crear una cadena de control de calidad para habilitar la respuesta a preguntas en el documento.
Preguntas frecuentes
R. Flan-T5 es un LLM de código abierto disponible comercialmente. Es una variante del modelo T5 (Text-To-Text Transfer Transformer) desarrollado por Google Research.
R. Flan-T5 se lanza con diferentes tamaños: Pequeño, Base, Grande, XL y XXL. XXL es la versión más grande de Flan-T5 y contiene 11B parámetros.
google/flan-t5-small: 80M de parámetros
google/flan-t5-base: 250 millones de parámetros
google/flan-t5-large: 780M parámetros
google/flan-t5-xl: parámetros 3B
google/flan-t5-xxl: 11B parámetros
R. Una de las formas más comunes de almacenar y buscar datos no estructurados es incrustarlos y almacenar los vectores de incrustación resultantes y luego, en el momento de la consulta, incrustar la consulta no estructurada y recuperar los vectores de incrustación que sean "más similares" a los incrustados. consulta. Un almacén de vectores se encarga de almacenar los datos incrustados y realizar la búsqueda de vectores por usted.
R. LangChain agiliza el desarrollo de diversas aplicaciones, como chatbots, respuesta generativa a preguntas (GQA) y resúmenes. Al "encadenar" componentes de múltiples módulos, permite la creación de aplicaciones únicas basadas en un LLM.
A. load_qa_chain es una de las formas de responder preguntas en un documento. Funciona cargando una cadena que puede responder preguntas en los documentos de entrada. load_qa_chain usa todo el texto del documento. Una de las otras formas de responder preguntas es la cadena RetrievalQA que usa load_qa_chain bajo el capó. Sin embargo, recupera el fragmento de texto más relevante y solo lo ingresa en el modelo de lenguaje grande.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/09/unlocking-langchain-flan-t5-xxl-a-guide-to-efficient-document-querying/

