Imagen del autor
La ciencia de datos es un campo en crecimiento. Permítanme apoyar esto con dos investigaciones diferentes.
El primero es por LinkedIn, realizado en 2022. El estudio muestra los títulos de trabajo de más rápido crecimiento en los últimos 5 años. El título de ingeniero de aprendizaje automático es el cuarto trabajo de más rápido crecimiento. Es una subrama de la ciencia de datos.
Como científico de datos, debe crear su propio modelo de aprendizaje automático y ponerlo en producción. Por supuesto, también debe saber sobre el web scraping y todas las demás etapas de un proyecto de ciencia de datos. Puede encontrarlo todo en las siguientes partes del artículo.

Imagen de Etiqueta LinkedIn
La segunda investigación proviene de Glassdoor. Muestra que la ciencia de datos se encuentra entre los tres primeros de los 50 mejores trabajos en Estados Unidos. Además, ha sido lo mismo durante los últimos siete años. Veamos las estadísticas. Las 10,071 ofertas de trabajo y el índice de satisfacción laboral de 4.1/5 pueden ser la razón de ser uno de los mejores trabajos. Además, el salario base promedio es de $ 120,000 por año.
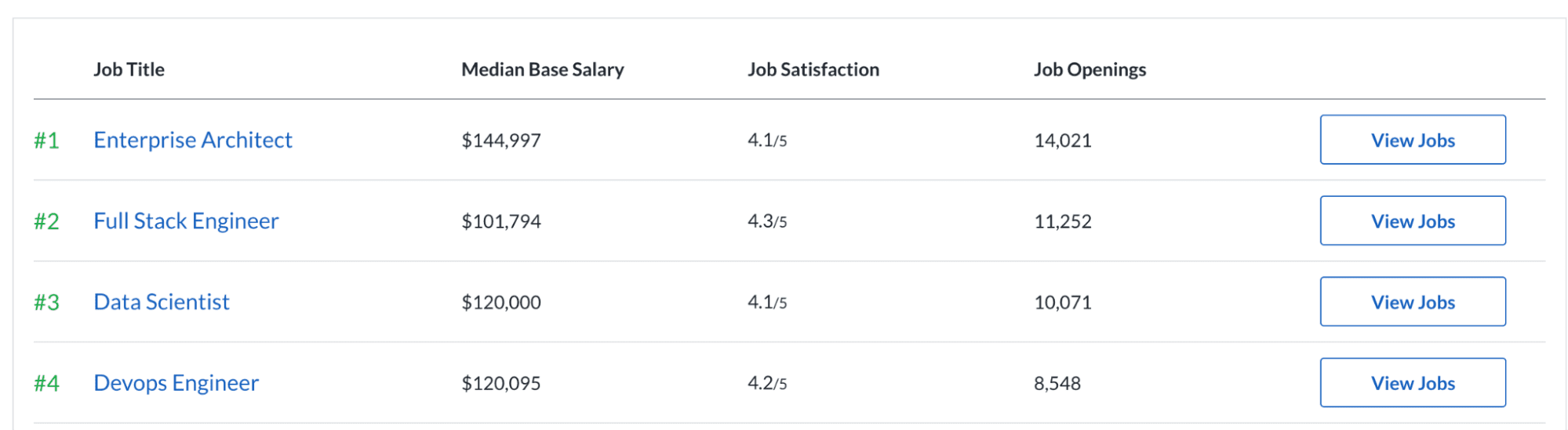
Imagen de Glassdoor
Ahora, es más evidente que la ciencia de datos es un campo en crecimiento. Y también, la demanda en la industria parece prometedora.
Debido a esta demanda, las opciones para aprender Data Science son cada vez mayores. Los cursos en línea y los sitios web son formas populares de aprender conceptos de ciencia de datos.
Después de dominar la teoría, hacer proyectos reales te preparará para las entrevistas de trabajo. También ayuda a enriquecer su cartera.
Sin embargo, los proyectos que están haciendo los desarrolladores junior se superponen a menudo. Por ejemplo, la predicción del precio de la vivienda, la identificación de plantas de iris o la predicción de los supervivientes del Titanic. Aunque son proyectos útiles, incluirlos en tu portafolio podría no ser la mejor idea.
¿Por qué?
Porque el reclutador tiene un tiempo muy limitado para mirar tu CV. Aquí hay otra investigación que debería hacerte más consciente de esto. Es una investigación de seguimiento ocular realizada por escaleras. Este sitio de carreras muestra que los reclutadores miran su currículum por solo 6 segundos en promedio.

Imagen de las escaleras
Ahora, ya mencioné la popularidad de Data Science. Debido a su popularidad, muchos desarrolladores ya han dado un paso hacia ella. Eso hace que el campo sea extremadamente competitivo.
Para diferenciarte de los demás, debes hacer proyectos novedosos que destaquen. Debes seguir ciertas etapas para sacar lo mejor de estos proyectos. De esa forma, destacarás tanto por hacer proyectos diferentes a los demás como por ser minucioso y sistemático. En otras palabras, atraerá la atención del reclutador y luego la mantendrá mostrándole que sabe lo que está haciendo.
Aquí está el resumen de las etapas del proyecto.
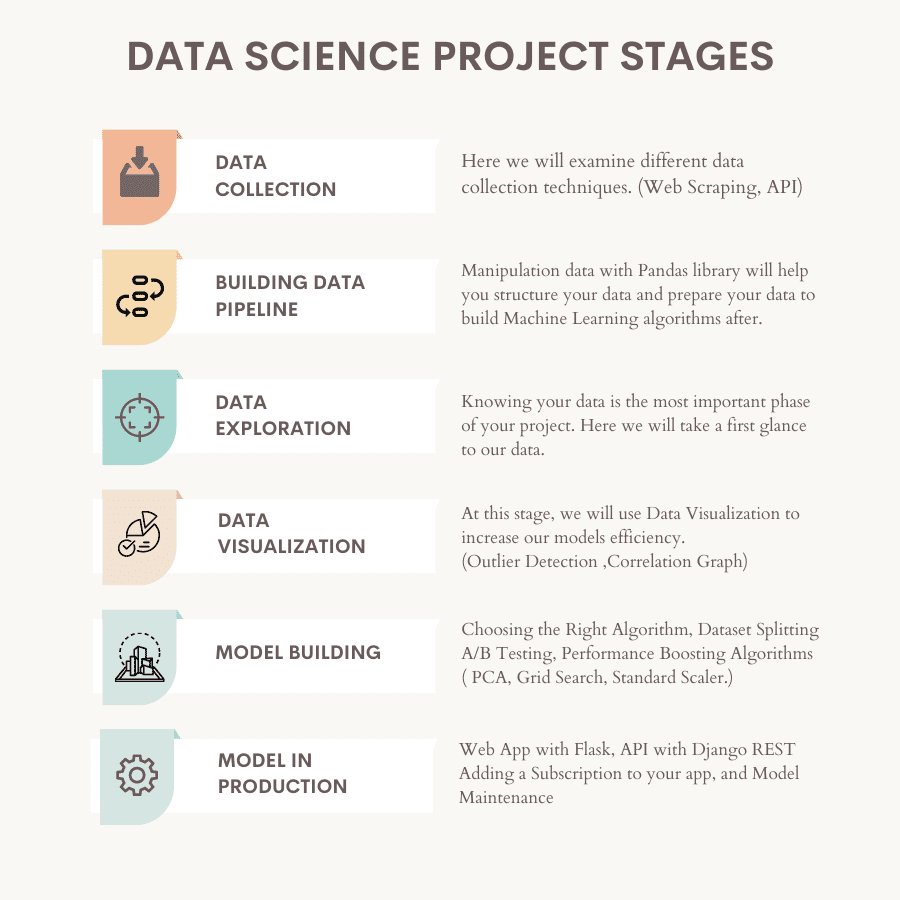
Imagen del autor
Ahora echemos un vistazo a cada uno. También te daré enlaces a diferentes proyectos y bibliotecas de codificación. No es necesario reinventar la rueda en este caso.

Imagen del autor
La recopilación de datos es el proceso de recopilación de datos de diferentes fuentes. En los últimos 10 años, la cantidad de datos creados por diferentes fuentes ha ido en aumento.
Para 2025, la cantidad de datos recopilados habrá aumentado casi tres veces más que en la actualidad.
Aquí está la la investigación realizado por IDC, mostrando los cambios en los datos creados por su tipo.
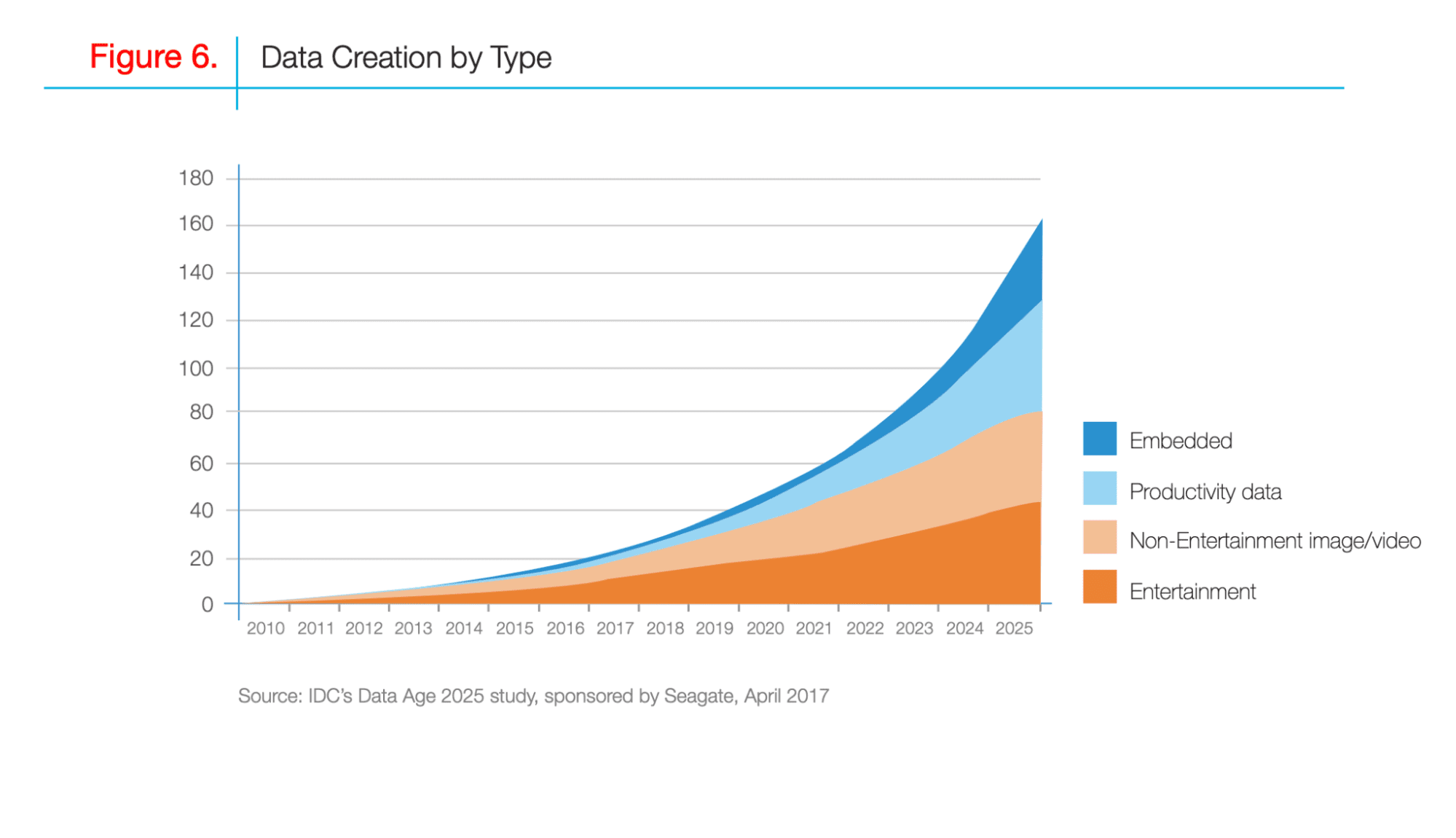
Imagen de importar.io
Significa que la cantidad de datos recopilados seguirá aumentando. Esta es la oportunidad para que las empresas y los desarrolladores obtengan aún más datos.
¿Por qué necesitas más datos?
Después de recopilar datos, la etapa final será la construcción del modelo y su implementación en producción. Por lo tanto, aumentar el rendimiento de este modelo será muy importante. Una forma de hacerlo es recolectando más datos. Aquí, lo principal en lo que hay que centrarse es cómo se puede mejorar el rendimiento de su modelo a medida que aumenta la cantidad de datos.
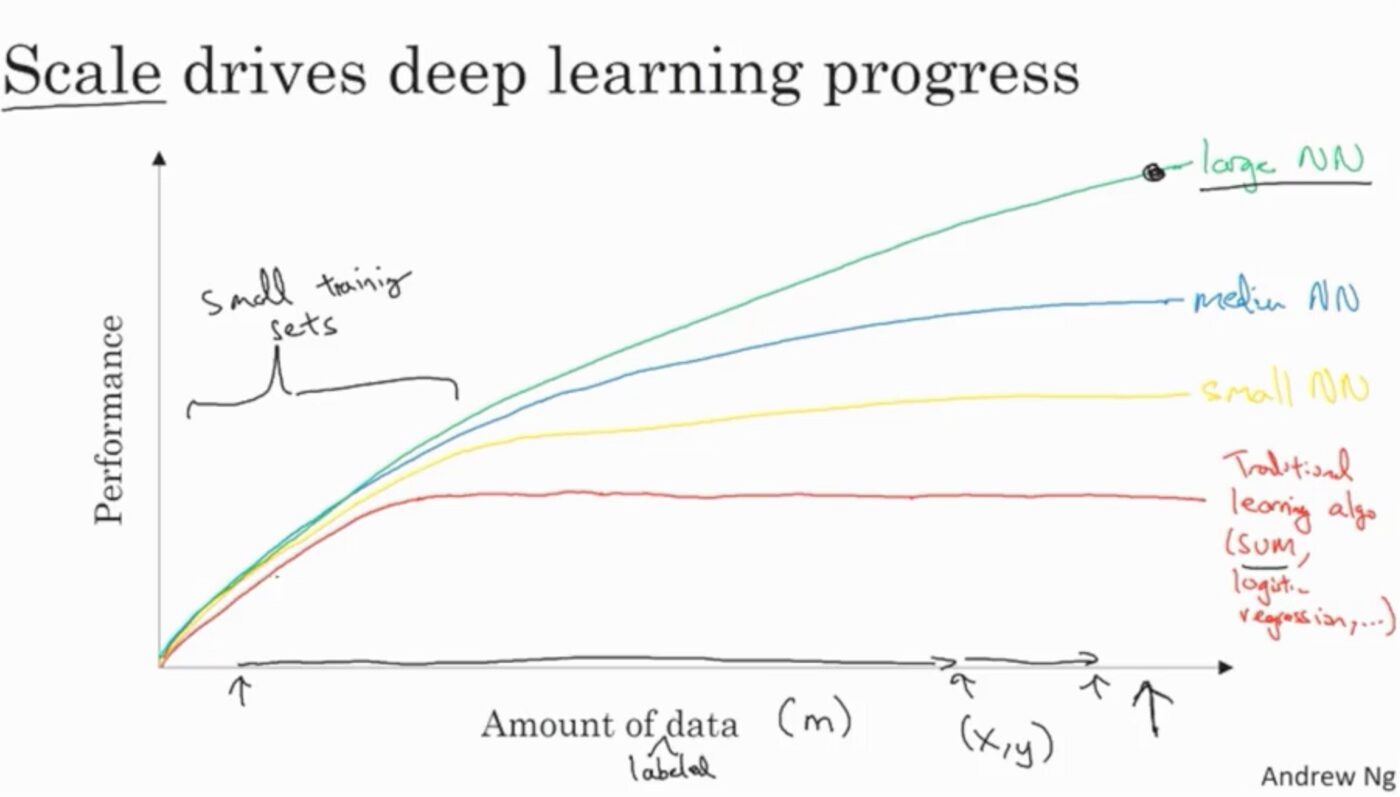
Imagen de Aprendizaje profundo.AI
Ahora, existen muchas técnicas diferentes para recopilar datos. Aquí explicaré 3 de ellos: lectura de diferentes fuentes de archivos, web scraping y API.
Recopilación de datos de diferentes fuentes de archivos
Muchos sitios web y empresas le presentarán datos en buen estado. Sin embargo, leer eso en su entorno de codificación necesitará un par de líneas de código.
Por ejemplo, este proyecto tiene como objetivo analizar los datos de las personas que tienen grandes deudas pero que tienen dificultades para pagarlas. Como puede ver, este proyecto también comienza con la lectura de datos usando el leer_csv función en pandas.
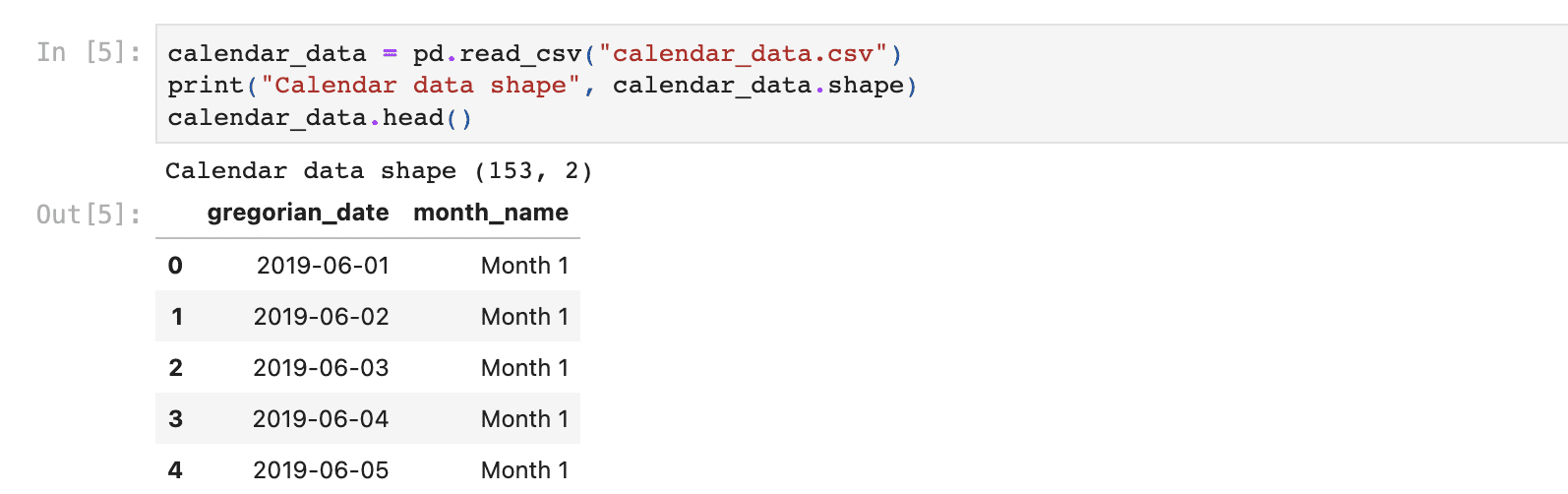
Ahora que tiene datos, puede realizar el análisis exploratorio de datos que le pide este proyecto.
Para más detalles sobre cómo hacerlo, esta página es el video de youtube
Hay muchos sitios web diferentes donde puede encontrar datos de código abierto.
Aquí hay 4 de ellos.
Encuentre los datos allí y léalos usando las funciones de Python como se ha hecho anteriormente. Si sus datos vienen en otros formatos (HTML, JSON, sobresalir), también puede leerlos usando Funciones de pandas.
Raspado web
El raspado web es un proceso de uso de herramientas automatizadas para rastrear la web y recopilar datos. Esto significa usar orugas y raspadores. Mapean el HTML del sitio web y luego recopilan datos utilizando las instrucciones dadas.
El rastreador
Los rastreadores web buscan cualquier información para tomar del sitio web. Le ayuda a encontrar direcciones URL que contienen la información que desea extraer.
el raspador
El raspador recopila la información que usted preestablece. Cada raspador tiene un selector para ubicar la información que desea tomar del sitio web.
¿Cómo funciona?
Por lo general, trabajan juntos. Primero, el rastreador toma la información sobre su tema y encuentra las URL. Luego, el raspador localiza la información que necesita utilizando el selector. En el paso final, extrae estos datos.
Bibliotecas Python de raspado de datos
En Python, puede raspar datos trabajando con diferentes bibliotecas. Aquí hay 4 de ellos para ti.
Aquí está la video por Ken Jee. Puede ver su serie de Youtube de proyectos de ciencia de datos dividiéndolos en diferentes pasos. En el segundo video, explica la importancia de la recopilación de datos. Luego extrae datos de Glassdoor usando Selenium para hacer un análisis de datos del salario del científico de datos.
API

Imagen del autor
API significa Interfaz de programación de aplicaciones, que se utiliza para la comunicación entre diferentes programas. Ayuda a dos programas o aplicaciones a pasar información entre ellos.
API de raspador de YouTube
Aquí hay una API de Youtube que se utilizará para recopilar datos en el próximo video. Le permite obtener estadísticas del canal, como el número total de suscriptores y el número de vistas, los nombres de los videos, los comentarios y más.
En este video en el canal de análisis de datos de Vu, los datos se extraen de Youtube utilizando la API de Youtube.
En primer lugar, se procesan los datos. Después de eso, hay un análisis exploratorio de datos, visualización y más.
Puedes ver algunas similitudes con el video anterior, como limpiar datos y hacer un análisis explicativo. Esto es normal porque la mayoría de los proyectos de datos pasan por las mismas etapas. Pero los datos que utilice en estas etapas y cómo los utilice mejorarán sus proyectos y enriquecerán su cartera.
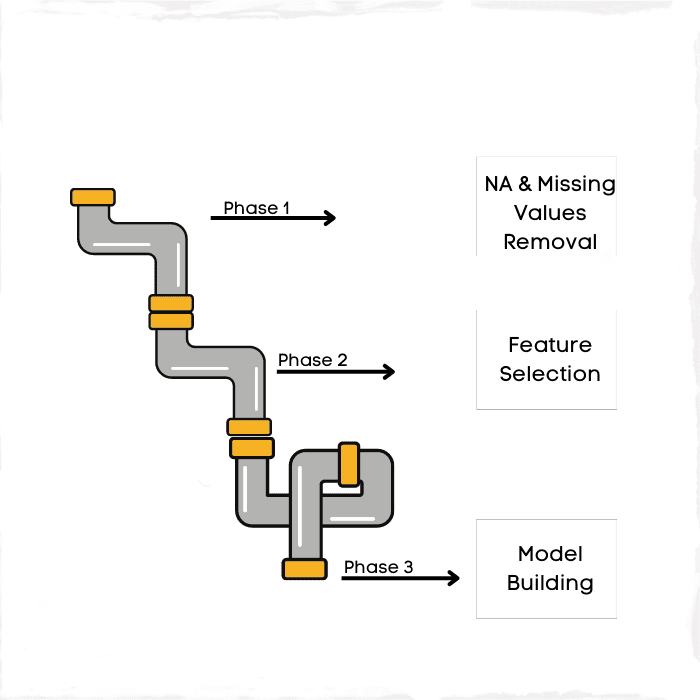
Imagen del autor
Es la fase de convertir sus datos no estructurados en una versión significativa. El término tubería aquí se centra en la transformación. A veces, esta fase también se denomina limpieza de datos, pero tiene sentido visualizar las canalizaciones y asignarlas a las etapas de los datos.
Después del raspado, los datos generalmente no estarán en la mejor forma. Es por eso que será obligatorio cambiar su formato. Por ejemplo, si tiene una pequeña cantidad de datos pero contiene muchos NA o valores faltantes, completar estos valores en el promedio de la columna lo ayudará a usar estos datos.
O por ejemplo, si trabajas con el columna de fecha y hora, el tipo de datos de su columna podría ser un objeto. Eso evitará que aplique la función de fecha y hora a esa columna. Por lo tanto, debe cambiar el tipo de datos de esta columna a fecha y hora.
Tener más datos con mejor calidad lo ayuda a construir un modelo más efectivo.
Pongamos un ejemplo de la transformación necesaria en Machine Learning. Si construye un modelo, sus variables deben ser numéricas. Sin embargo, algunos datos tienen información categórica. Para convertir estas variables en numéricas, debes hacer una codificación caliente.

Imagen del autor
Conocer sus datos es realmente importante al hacer un proyecto. Para hacer eso, primero debes explorarlo usando diferentes funciones.
Aquí hay algunas funciones comunes de Pandas utilizadas en la exploración de datos.
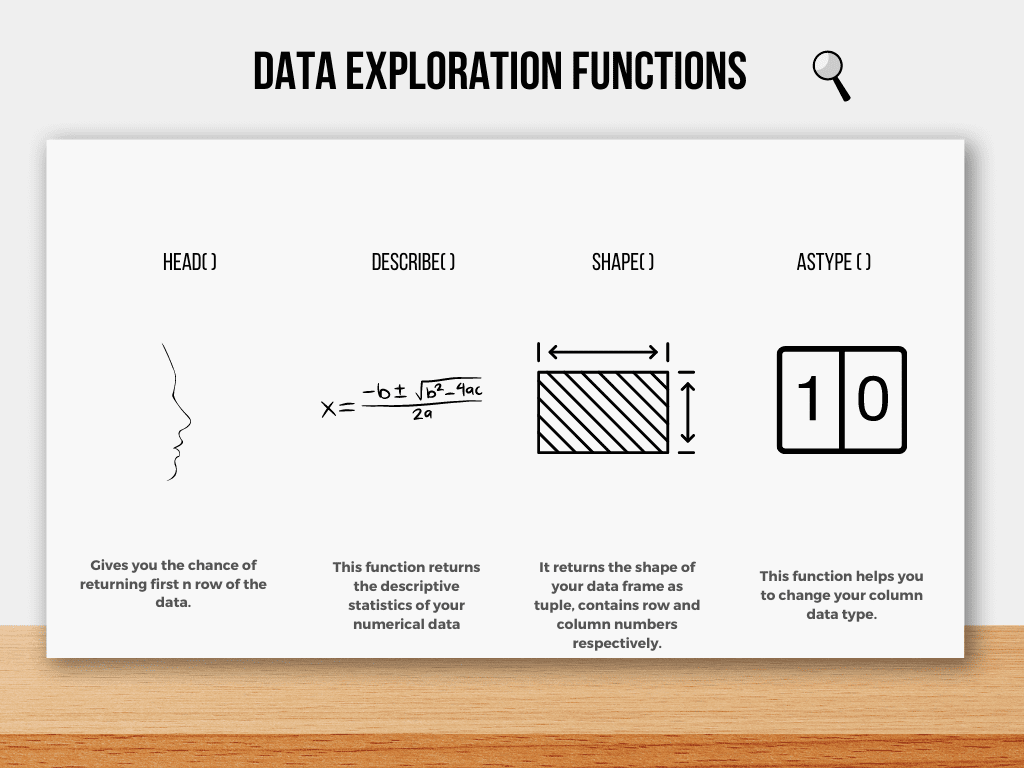
Imagen del autor
Primer vistazo a sus datos
cabeza( ) La función le da la oportunidad de ver las primeras filas de sus datos. Además, la función info() le dará información sobre las columnas de sus datos, como la longitud y los tipos de datos.
describir( ) La función dará un resumen de las estadísticas descriptivas.
forma( ) La función dará información sobre la dimensión de sus datos, que genera una fila/columna como una tupla, respectivamente.
tipo( ) La función le ayuda a cambiar el formato de sus columnas.
Además, es probable que no trabaje con un conjunto de datos, por lo que la combinación de datos también es una operación común que usará.

Imagen del autor
Extraer información significativa de los datos se vuelve más fácil si la visualiza. En Python, hay muchas bibliotecas que puede usar para visualizar sus datos.
Debe usar esta etapa para detectar los valores atípicos y los predictores correlacionados. Si no se detectan, disminuirán el rendimiento de su modelo de aprendizaje automático.
La creación de gráficos facilita esta detección.
Detección de valores atípicos
Los valores atípicos a menudo ocurren debido a anomalías y no ayudan a las predicciones de su modelo. Después de detectar los valores atípicos, se eliminan de sus datos.
Aquí Podemos ver este gráfico de distribución, que muestra los precios máximos que la gente está dispuesta a pagar por una habitación en Airbnb en Dublín.
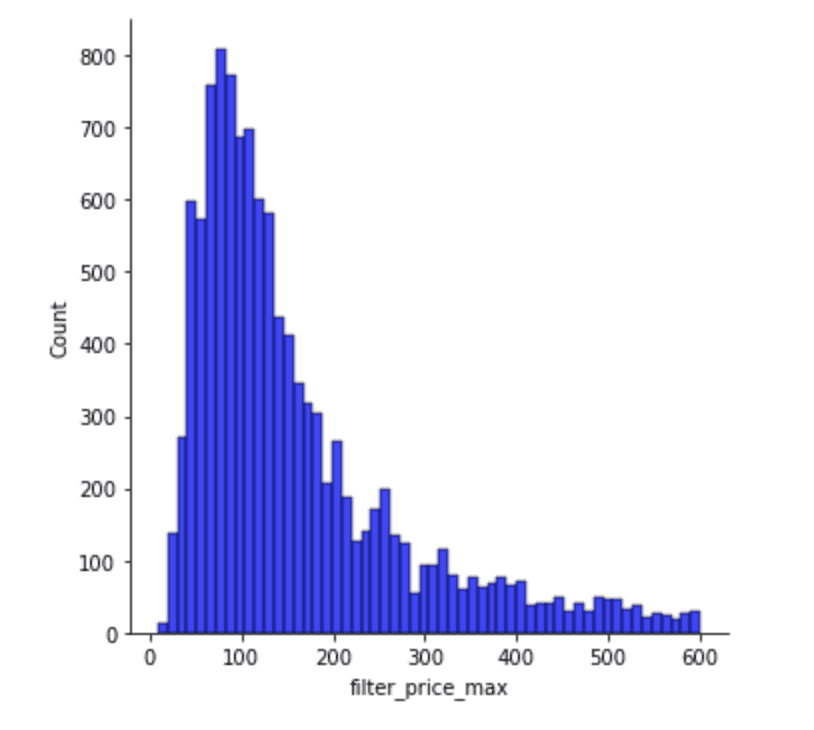
La mayoría de la gente busca una habitación por debajo de $200/noche, y especialmente alrededor de $100/noche. Sin embargo, hay otras personas que buscan habitaciones entre 500 y 600.
Al construir un modelo, filtrarlo en un cierto nivel lo ayudará a predecir el comportamiento con mayor precisión.
Gráfico de correlación
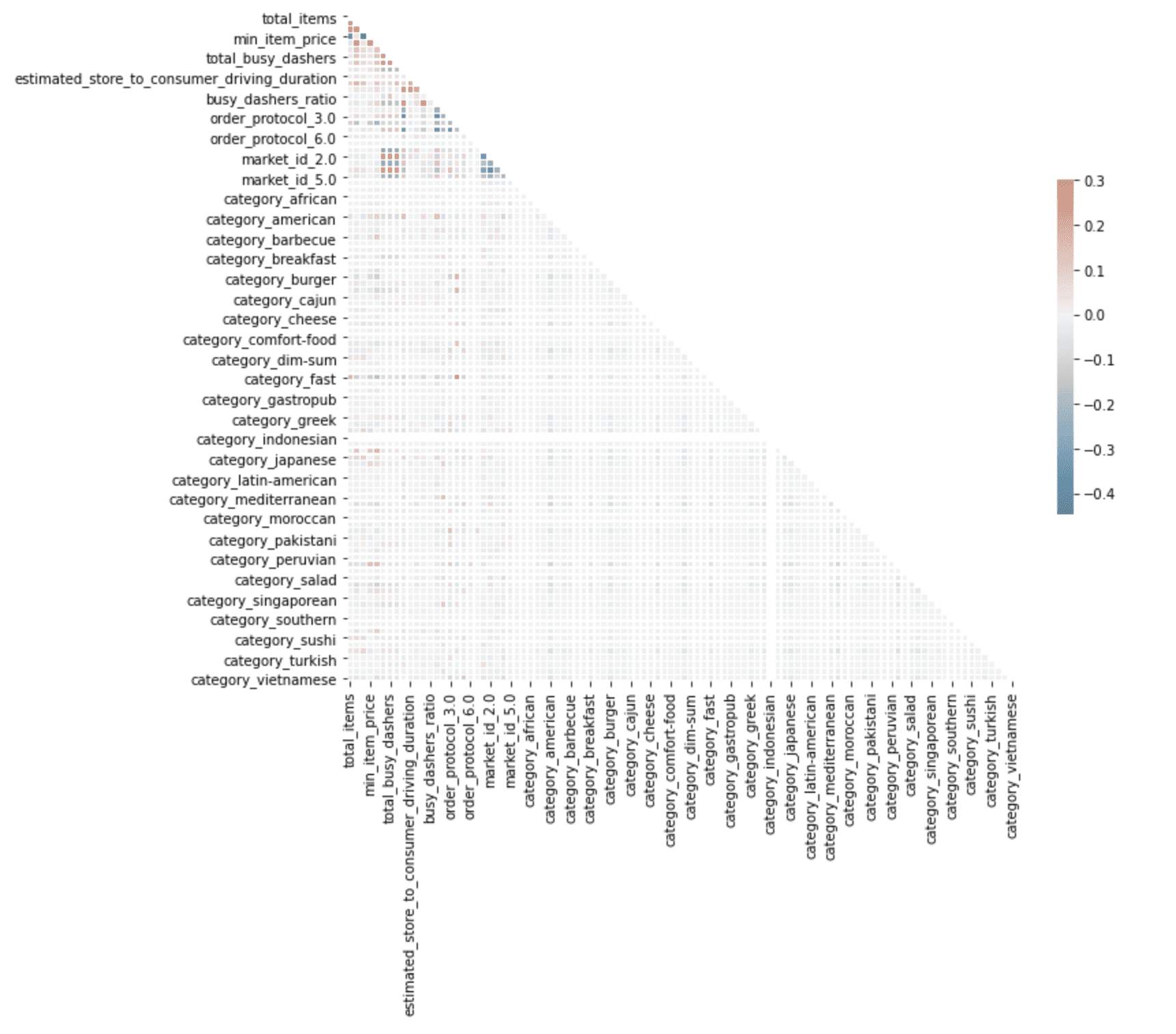
Imagen del autor
Aquí, el gráfico de correlación detecta predictores correlacionados, lo que disminuirá el rendimiento de su modelo. Puede ver la escala de color en el lado derecho del gráfico, que muestra que a medida que aumenta la densidad del color, también aumenta la correlación tanto para el negativo como para el positivo.

Imagen del autor
Aquí puede ver las diferentes etapas de la construcción del modelo.
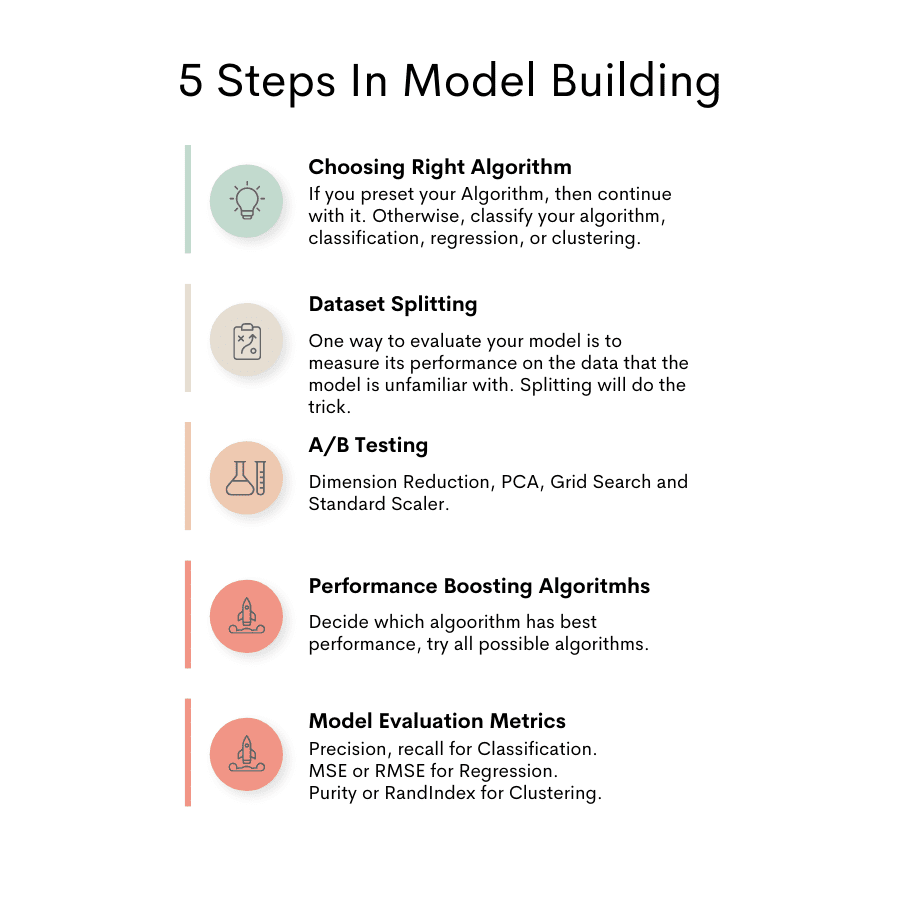
Imagen del autor
Elegir el algoritmo correcto
El primer paso en la construcción de modelos es elegir qué tipo de algoritmo usar. Por supuesto, depende de tu tema.
¿Trabajas con datos numéricos y planeas hacer predicciones? Entonces tu elección será Regresión. ¿O quieres clasificar la imagen con un Clasificación ¿algoritmo? Depende de tu proyecto. Por ejemplo, la detección de anomalías suele ser un contenido de proyecto popular. Se puede utilizar para la detección de fraudes con tarjetas de crédito y utiliza el Clustering algoritmos en el backend. Por supuesto, puedes usar Aprendizaje profundo en tu proyecto también.
División de conjuntos de datos
Una forma de evaluar su modelo es medir su rendimiento en los datos con los que el modelo no está familiarizado. Dividir los datos en conjuntos de datos de entrenamiento y prueba lo ayuda a lograrlo.
Entrena su modelo con el conjunto de datos de entrenamiento y luego prueba su rendimiento con el conjunto de prueba, que contiene datos con los que el modelo no está familiarizado.
En esta etapa, si ya sabe qué modelo usará, puede omitir el uso del conjunto de validación. Sin embargo, si desea probar diferentes modelos para ver cuál es el mejor, usar el conjunto de validación es para usted.
pruebas A/B
Después de elegir el algoritmo y dividir su conjunto de datos, es hora de realizar pruebas A/B.
Hay diferentes algoritmos. ¿Cómo puedes estar seguro de cuál será el mejor para tu modelo? Una cosa para verificar esto se llama prueba A/B en el aprendizaje automático. Las pruebas A/B en Machine Learning significan que probará diferentes modelos para encontrar el mejor para su proyecto.
Pruebe todos los algoritmos posibles para sus datos y encuentre el algoritmo de mejor rendimiento y continúe usándolo.
Algoritmos y técnicas de mejora del rendimiento

Imagen del autor
El rendimiento de su modelo a menudo se puede mejorar mediante el uso de diferentes técnicas. Centrémonos en tres de ellos.
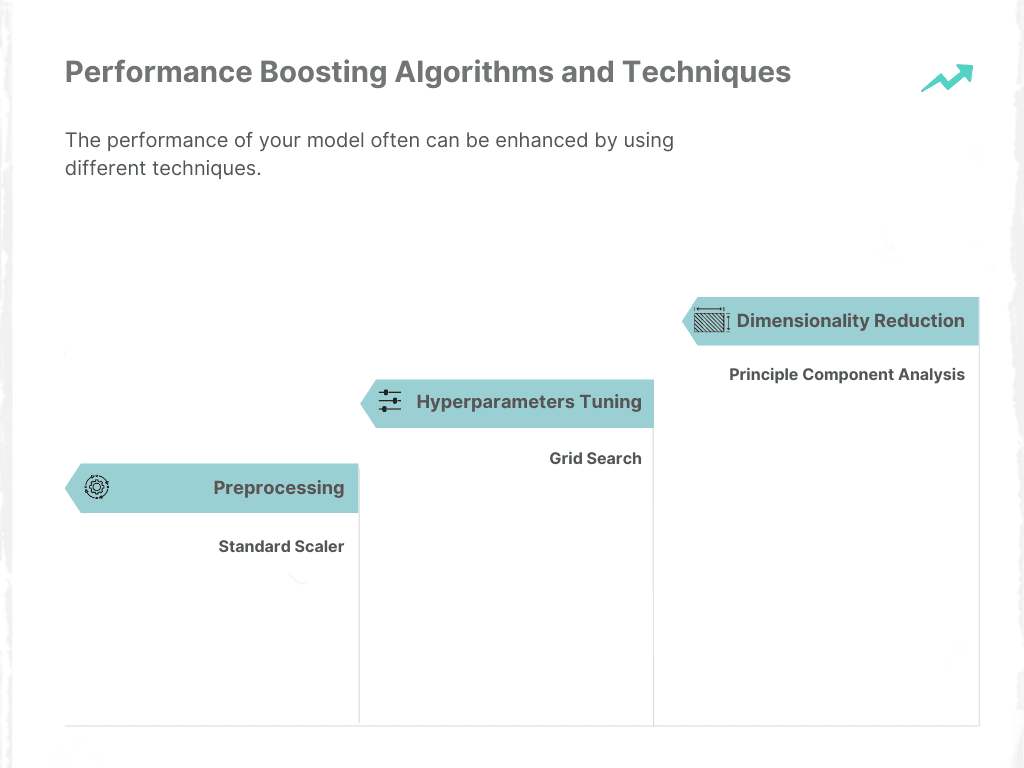
Imagen del autor
Reducción de dimensionalidad
La reducción de dimensionalidad se utiliza para encontrar los predictores que representarán sus datos mejor que otros. Esta técnica hace que su algoritmo funcione más rápido y su modelo predice mejor.
Aquí puede ver la aplicación de la técnica de reducción de dimensionalidad en la biblioteca de aprendizaje de sci-kit.
PCA
PCA significa Análisis de componentes principales, que lo ayuda a determinar la cantidad de predictores necesarios para explicar un cierto porcentaje de su conjunto de datos.
Permítanme explicar esto en un ejemplo, se predice el tiempo esperado de entrega. Hay 100 predictores, por lo que eliminarlos nos ayudará a mejorar la velocidad del algoritmo y el resultado será un algoritmo que funcione mejor. Por eso se aplica el algoritmo PCA.
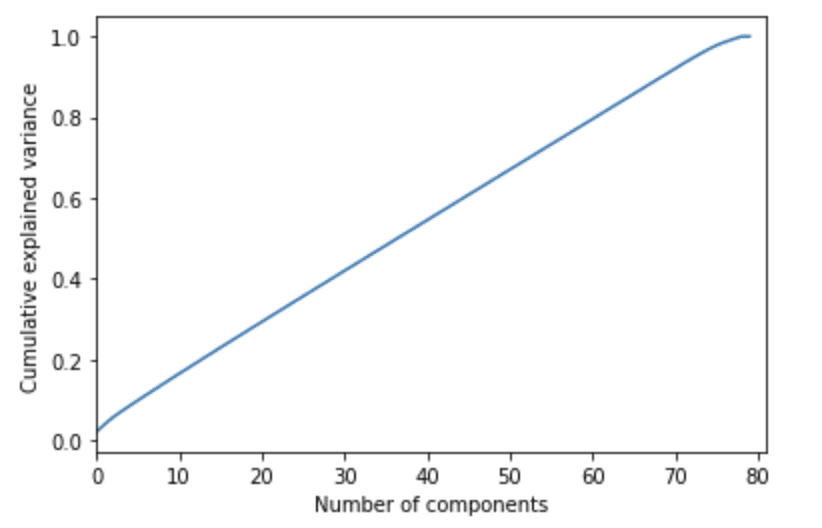
PCA muestra que se necesitan al menos 60 características representativas para explicar el 80% del conjunto de datos. Aquí está el código en la biblioteca de aprendizaje de sci-kit con una explicación.
Ajuste de hiperparámetros
Al construir un modelo de aprendizaje automático, habrá muchos parámetros diferentes que se pueden usar para hacer una predicción. Hyperparameters Tuning nos ayuda a encontrar lo mejor de estos parámetros de acuerdo a las necesidades de nuestro proyecto.
Búsqueda de cuadrícula
Grid Search lo ayuda a encontrar los mejores valores de parámetros para optimizar su modelo de aprendizaje automático.
Aquí es el código en la biblioteca de aprendizaje de sci-kit, que explica qué es la búsqueda de cuadrícula y le brinda el código de implementación.
preprocesamiento
Ayuda a escalar sus variables al mismo nivel, así es como su algoritmo, que funciona para la predicción, funciona más rápido.
Escalador estándar
La idea principal es cambiar la media, el cero y la desviación estándar de su predictor a 1. Aquí es el código de la biblioteca de aprendizaje de sci-kit para ayudarlo a calcular eso.
Métricas de evaluación del modelo

Imagen del autor
Este paso nos ayuda a interpretar el modelo. Es por eso que existen diferentes métricas de evaluación para diferentes algoritmos. La interpretación de los resultados del algoritmo diferirá según el problema: regresión, clasificación o agrupación.
Regresión
Es una técnica para encontrar relaciones entre variables numéricas. Simplemente, usaremos la regresión para predecir variables numéricas.
Aquí están las dos métricas de evaluación de los problemas de regresión.
MSE
El error cuadrático medio se calcula encontrando las diferencias entre el valor predicho y el valor real y elevando al cuadrado el resultado, para cada elemento de su conjunto de datos.
Aquí está la fórmula.
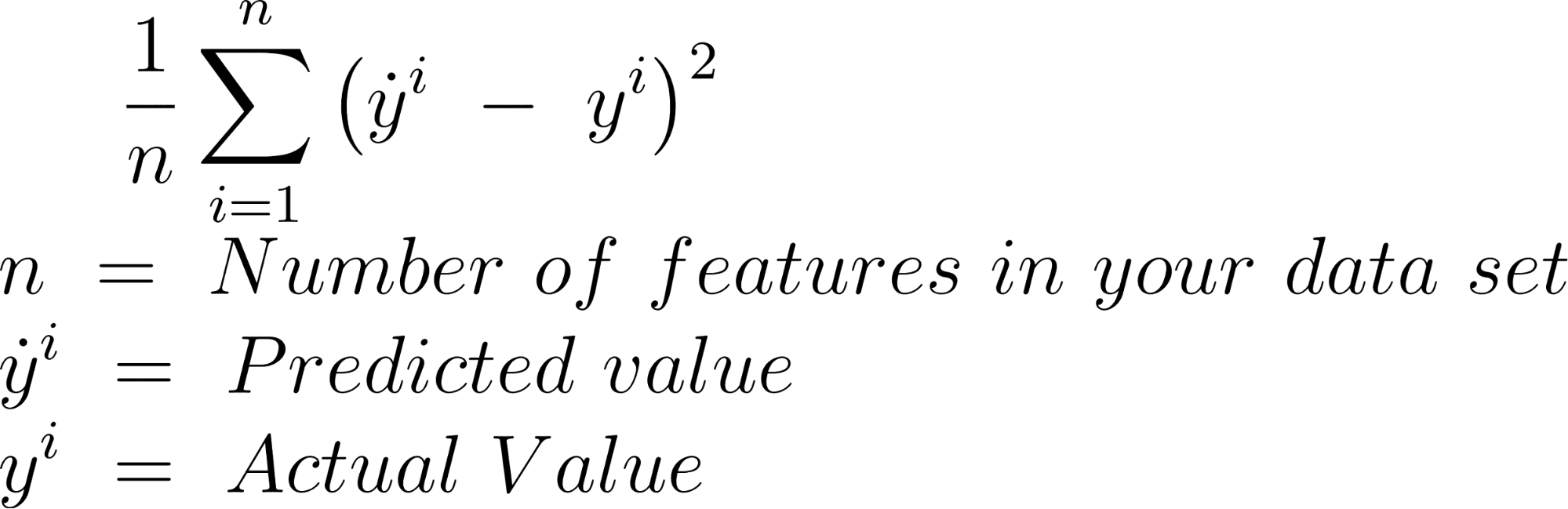
Aquí es la implementación de MSE en sci-kit learn con Python.
RMSE
RMSE es la raíz del MSE.
Aquí está la fórmula.

Aquí es la implementación de RMSE en sci-kit learn con Python.
Clasificación
Los algoritmos de clasificación dividen sus datos en diferentes grupos y los definen en consecuencia.
El proceso de evaluación de la clasificación a menudo incluye una matriz de confusión, que incluye la clase verdadera y la clase predicha. (Verdadero Positivo, Falso Positivo, Verdadero Negativo, Falso Negativo)
Aquí is la implementación de la matriz de confusión en sci-kit learn.
Precisión
Esto es para evaluar la precisión de las predicciones positivas.
Aquí está la fórmula.
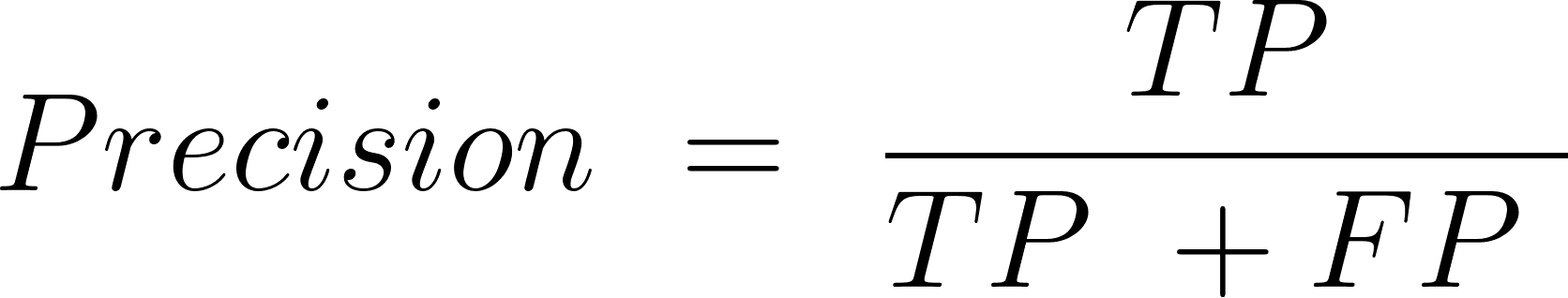
TP = Verdadero Positivo
FP = Falso Positivo
Aquí es la implementación de la precisión en Python con el sci-kit learn.
Recordar
Recall o sensibilidad, es la proporción de ejemplos positivos que tu algoritmo clasifica correctamente.
Aquí está la fórmula.
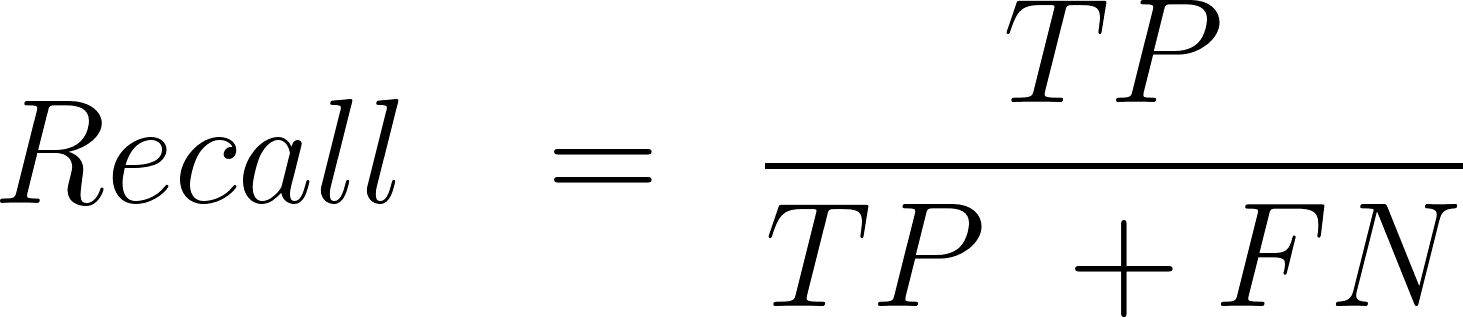
FN: falso negativo
Aquí es la implementación de la recuperación en Python con el sci-kit learn.
Puntuación F1
Es el medio armónico de precisión y recuerdo.
Aquí está la fórmula
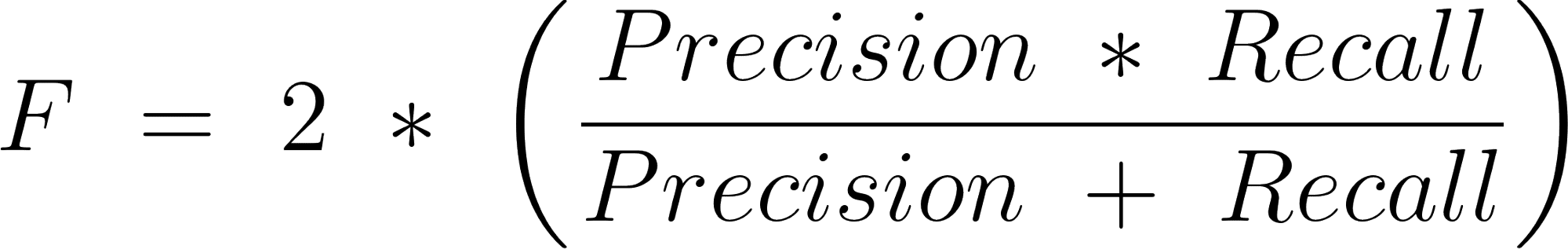
Clustering
El primer paso de la agrupación es agrupar los puntos de datos como un grupo. El segundo paso es asignarlos.
Si elige el algoritmo de agrupación, aquí hay dos métricas de evaluación para interpretar el rendimiento de su modelo. Además, agregué su fórmula y el enlace a la biblioteca de aprendizaje de sci-kit.
Pureza
La pureza es el porcentaje del total de puntos de datos clasificados correctamente.
Aquí está la fórmula

Para calcular la pureza, primero debe calcular el matriz de confusión.
ÍndiceRand
Mide la similitud entre dos grupos.

TP = Verdadero Positivo
FP = Falso Positivo
TN = Verdadero Negativo
FN = Falso Negativo
Aquí es la implementación de RandIndex en Python con el sci-kit learn.

Imagen del autor
Después de construir su modelo de aprendizaje automático, es hora de ver su rendimiento presentándolo a diferentes usuarios que utilizan servicios en la nube. Aquí explicaré cómo hacerlo usando dos bibliotecas diferentes en Python: Flask y Django.
Además, hay diferentes opciones para ejecutar y alojar su modelo, como Heroku, océano digital, pythonanywhere.com, que puede utilizar para su propio proyecto.
Aplicación web con petaca
Flask es una biblioteca de Python que te dará la oportunidad de escribir aplicaciones web. Para obtener más información, visite el sitio web oficial aquí.
Suponga que usted desarrolló un modelo de aprendizaje automático para predecir el peso de los usuarios utilizando las medidas corporales y la edad.
Para hacer eso, primero necesita acceder a los datos para poder construir una regresión lineal múltiple. Aquí puede acceder a la predicción de grasa corporal de código abierto datos para crear un modelo de aprendizaje automático que prediga el peso.
Al usar pythonanywhere.com, puede ejecutar su modelo y alojarlo en el sitio web al mismo tiempo.
API con Django REST
Ya mencioné qué es la API, y ahora aquí mencionaré sus opciones de implementación. Puede escribir su API utilizando el marco Django REST. Django es como un frasco; es un marco micro web. Al usarlo, también puede codificar el backend y también el frontend de la aplicación y también escribir API.
Hablemos de las ventajas de desarrollar API con Django REST.
La comunidad es activa y la documentación es extensa.
También, esta página son los otros frameworks de Python; al usarlos, puede desarrollar una API.
Además de estas seis etapas principales del proyecto, aquí están las dos adicionales.
Agregar suscripción a su aplicación
Puedes incluir un plan de suscripción en tu Web APP. Supongamos que desarrolló un algoritmo de OCR cuyo objetivo es distraer la información de los documentos mediante el procesamiento de imágenes, como Docsumo.
Aquí están las diferentes opciones de su sistema de precios.

Imagen de docsumo.com
Por supuesto, antes de convertir tu aplicación web en un negocio, existen muchas etapas a seguir, pero el destino final podría ser como este.
Para obtener ingresos mediante el uso de API, aquí hay un página web del NDN Collective donde puede cargar su API, y también contiene miles de API diferentes.
Puede monetizar su API agregando diferentes opciones de suscripción y obtener ingresos después.
Aquí hay un reconocimiento facial. abejas, que le ayuda a convertir su texto en voz. Esta API posiblemente use CNN en el backend para reconocer rostros.
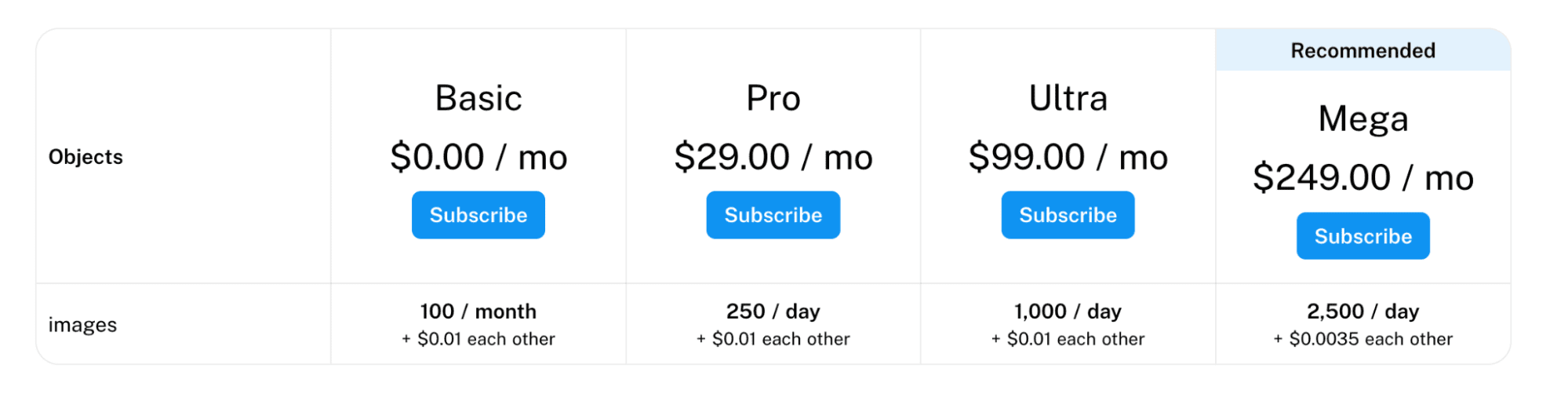
Imagen de API rápida
Si quieres desarrollar un algoritmo para el reconocimiento facial, aquí puedes llegar a un gran tutoriales escrito por Adem Geitgay, que explica las etapas del reconocimiento facial sin profundizar y lo facilita desarrollando su propia biblioteca.
Mantenimiento del modelo

Imagen del autor
Después de cargar su modelo en producción, se debe realizar un mantenimiento regular. Dado que su modelo utilizará la información de su usuario, su algoritmo debe actualizarse regularmente.
Supongamos que crea un modelo de aprendizaje profundo que predecirá la distancia entre dos objetos en la foto del usuario. Al entrenar a su modelo, posiblemente use imágenes de alta calidad para hacerlo. Sin embargo, es posible que los datos de la vida real no tengan la calidad que espera.
Al mirar sus métricas de evaluación, puede ver la caída en el rendimiento de su modelo debido a este problema técnico. Por supuesto, hay muchas soluciones posibles para superar este problema.
Uno de ellos es agregar ruido a las imágenes de su modelo.
Así es como su modelo también tendrá la capacidad de predecir imágenes de baja calidad.
Entonces, para mantener el rendimiento de su modelo siempre alto, necesita actualizaciones periódicas como esa. Además, debe cuidar los comentarios de sus clientes regularmente para mantenerlos satisfechos con su trabajo y solucionar sus problemas.
La creación de un proyecto a menudo comienza con la recopilación de datos. Para diferenciarse de los demás, use algunas o todas las opciones de recopilación de datos que cubrí en el artículo. Junto con eso, use diferentes sitios web de código abierto donde pueda acceder a diferentes conjuntos de datos.
Después de recopilar sus datos, lo siguiente es construir una canalización y convertir sus datos en el formato correcto. Después de eso, es hora de extraer información significativa explorándola y luego visualizándola. La siguiente etapa es construir un modelo.
Aquí examinamos la creación de modelos y los algoritmos de mejora del rendimiento, junto con las métricas de evaluación.
Por supuesto, hay muchas opciones para implementar sus modelos en producción, de las cuales cubrí algunas.
Seguir estas etapas te ayudará a sacar el máximo partido a tu proyecto, enriquecer tu cartera y obtener posibles ingresos.
A medida que adquiera experiencia, siéntase libre de agregar el escenario de acuerdo con sus necesidades entre ellos.
Después de terminar el proyecto, intente mapear estas etapas en su mente. Porque explicárselos a los entrevistadores en detalle también te ayudará a sobresalir en la entrevista y conseguir un nuevo trabajo.
Nate Rosidi es científico de datos y en estrategia de producto. También es profesor adjunto de enseñanza de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Gorjeo: StrataScratch or Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/01/data-collection-model-deployment-6-stages-data-science-project.html?utm_source=rss&utm_medium=rss&utm_campaign=from-data-collection-to-model-deployment-6-stages-of-a-data-science-project

