En el aprendizaje automático (ML), la calidad de los datos tiene un impacto directo en la calidad del modelo. Esta es la razón por la cual los científicos e ingenieros de datos dedican una gran cantidad de tiempo a perfeccionar los conjuntos de datos de entrenamiento. Sin embargo, ningún conjunto de datos es perfecto: existen compensaciones en las técnicas de preprocesamiento, como el sobremuestreo, la normalización y la imputación. Además, los errores y errores podrían aparecer en varias etapas de la canalización de análisis de datos.
En esta publicación, aprenderá cómo usar tipos de análisis incorporados en Wrangler de datos de Amazon SageMaker para ayudarlo a detectar los tres problemas de calidad de datos más comunes: multicolinealidad, fuga de objetivos y correlación de características.
Data Wrangler es una característica de Estudio Amazon SageMaker que proporciona una solución integral para importar, preparar, transformar, caracterizar y analizar datos. Las recetas de transformación creadas por Data Wrangler pueden integrarse fácilmente en sus flujos de trabajo de ML y ayudar a agilizar el preprocesamiento de datos, así como la ingeniería de características con poca o ninguna codificación. También puede agregar sus propios scripts y transformaciones de Python para personalizar las recetas.
Resumen de la solución
Para demostrar la funcionalidad de Data Wrangler en esta publicación, usaremos el popular Conjunto de datos del Titanic. El conjunto de datos describe el estado de supervivencia de los pasajeros individuales del Titanic y tiene 14 columnas, incluida la columna objetivo. Estas características incluyen pclass, name, survived, age, embarked, home. dest, room, ticket, boaty sex. La columna pclass se refiere a la clase de pasajeros (1.°, 2.°, 3.°) y es un indicador de la clase socioeconómica. La columna survived es la columna de destino.
Requisitos previos
Para usar Data Wrangler, necesita una instancia activa de Studio. Para obtener información sobre cómo lanzar una nueva instancia, consulte Incorporación al dominio de Amazon SageMaker.
Antes de comenzar, descargue el conjunto de datos del Titanic en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
Crea un flujo de datos
Para acceder a Data Wrangler en Studio, complete los siguientes pasos:
- Junto al usuario que desea usar para iniciar Studio, elija Open Studio.
- Cuando se abra Studio, elija el signo más en la Nuevo flujo de datos tarjeta debajo Tareas y componentes de ML.
Esto crea un nuevo directorio en Studio con un .flow archivo dentro, que contiene su flujo de datos. los .flow El archivo se abre automáticamente en Studio.
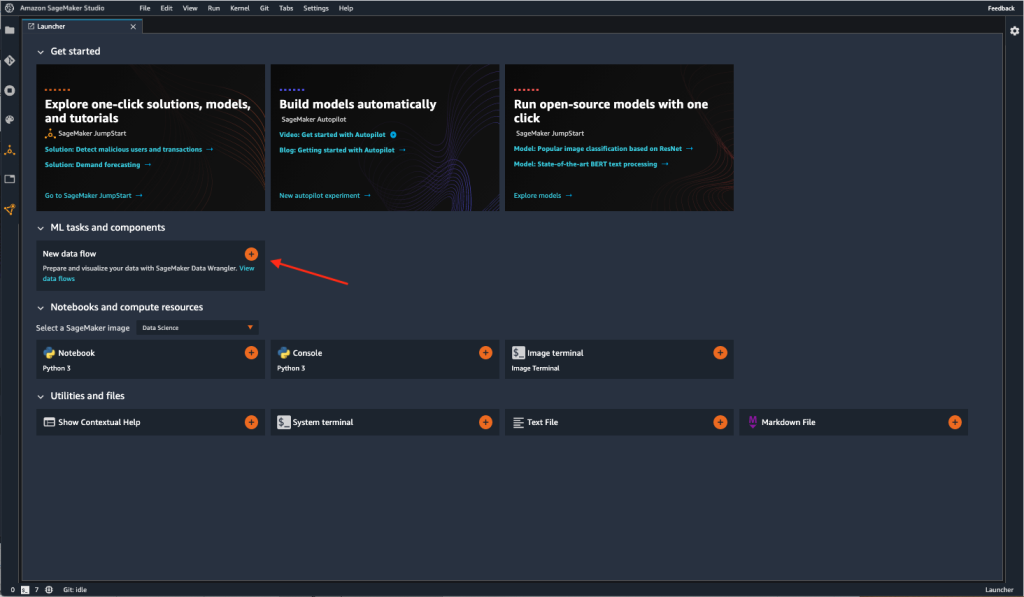
También puede crear un nuevo flujo eligiendo Archive, entonces Nuevoy eligiendo Flujo de Data Wrangler.
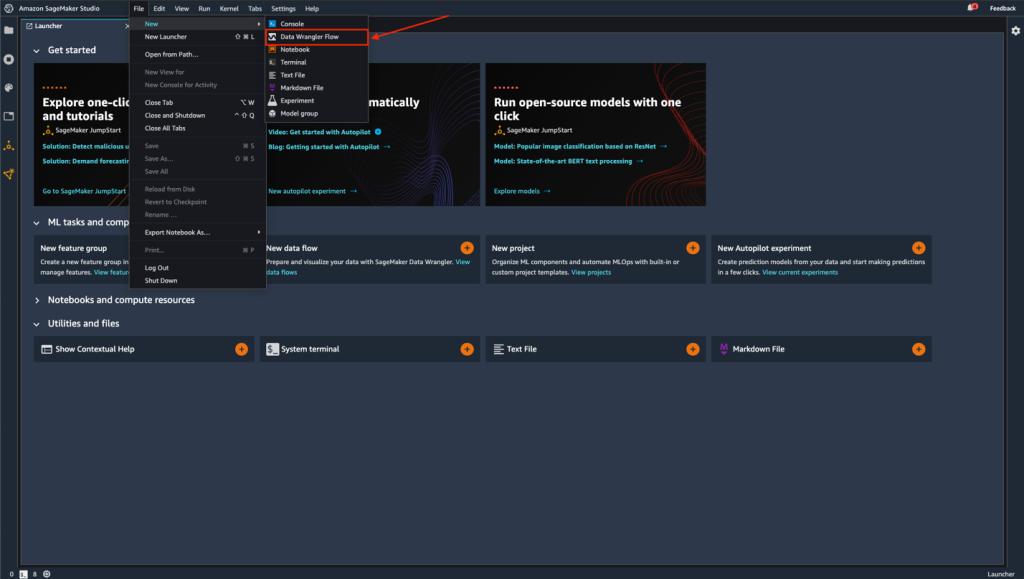
- Opcionalmente, cambie el nombre del nuevo directorio y el
.flowarchivo.
Cuando creas un nuevo .flow en Studio, es posible que vea un carrusel que le presenta Data Wrangler. Esto puede tomar unos pocos minutos.
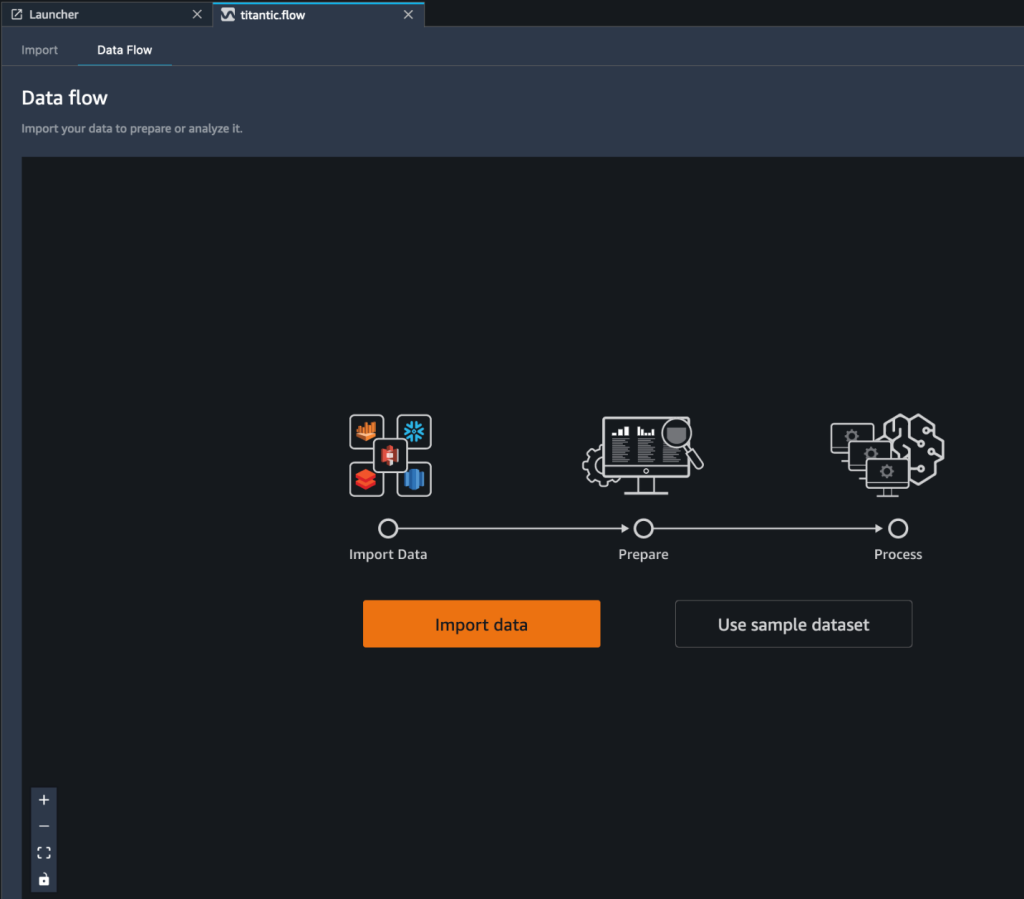
Cuando la instancia de Data Wrangler está activa, puede ver la pantalla de flujo de datos como se muestra en la siguiente captura de pantalla.
- Elige Usar conjunto de datos de muestra para cargar el conjunto de datos Titanic.
Crear un análisis de modelo rápido
Hay dos formas de tener una idea de un conjunto de datos nuevo (no visto anteriormente). uno es correr Informe de información y calidad de datos. Este informe proporcionará estadísticas de alto nivel (características numéricas, filas, valores faltantes, etc.) y alertas de alta prioridad de superficie (si las hay): filas duplicadas, fuga objetivo, muestras anómalas, etc.
Otra forma es ejecutar el análisis de modelo rápido directamente. Complete los siguientes pasos:
- Elija el signo más y elija Agregar análisis.
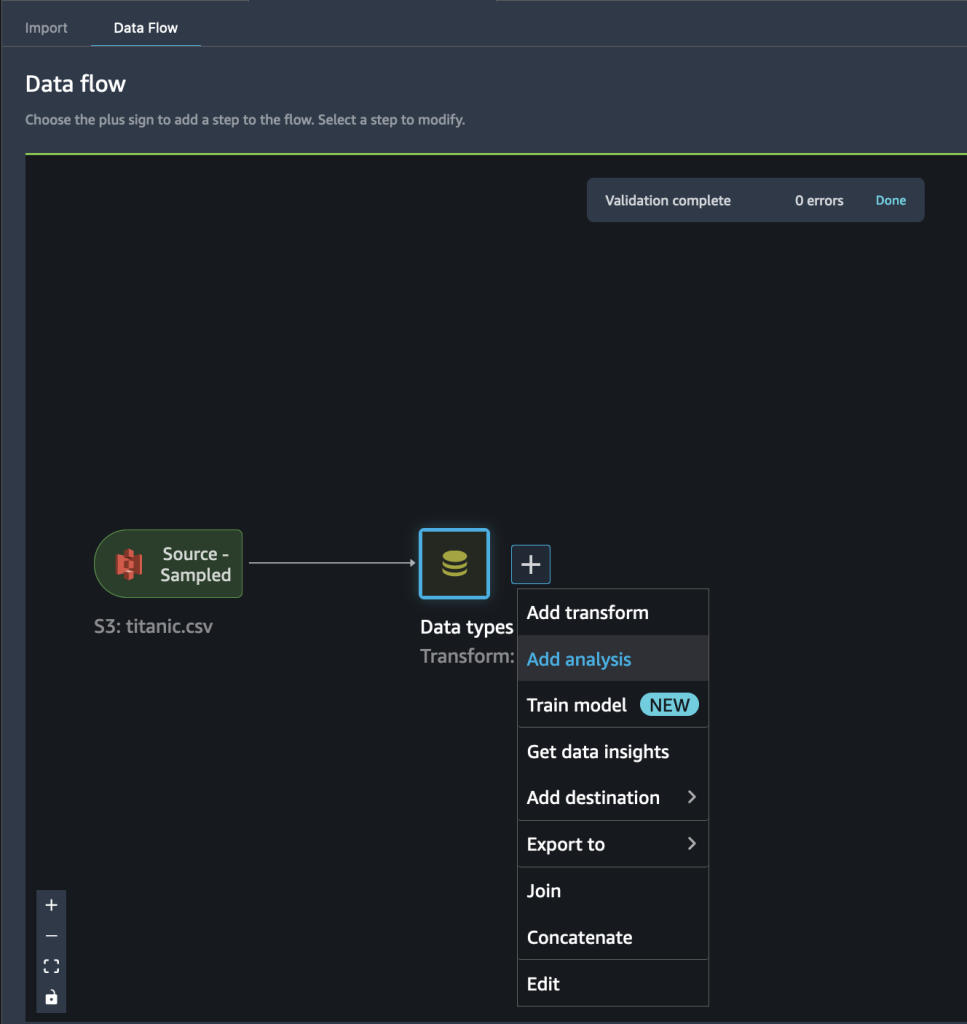
- Tipo de análisis, escoger Modelo rápido.
- Nombre del análisisingresa un nombre.
- Label, elija la etiqueta de destino de la lista de sus columnas de características (
Survived). - Elige Guardar.
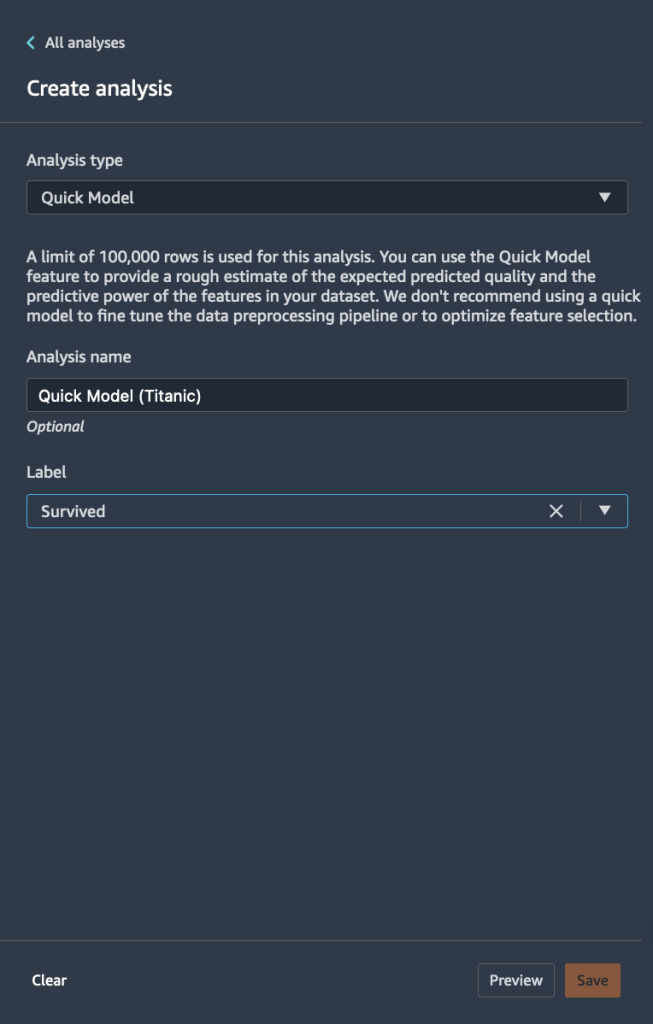
El siguiente gráfico visualiza nuestros hallazgos.
Quick Model entrena un bosque aleatorio con 10 árboles en 730 observaciones y mide la calidad de la predicción en las 315 observaciones restantes. El conjunto de datos se muestrea automáticamente y se divide en pruebas de entrenamiento y validación (70:30). En este ejemplo, puede ver que el modelo logró una puntuación F1 de 0.777 en el conjunto de prueba. Esto podría ser un indicador de que los datos que está explorando tienen el potencial de ser predictivos.
Al mismo tiempo, algunas cosas se destacan de inmediato. Las columnas name y boat son las señales que más contribuyen a su predicción. Columnas de cadena como name pueden ser tanto útiles como no útiles según la información completa que contengan sobre la persona, como el nombre, segundo nombre y apellido junto con los períodos de tiempo históricos y las tendencias a las que pertenecen. Esta columna puede excluirse o conservarse según el resultado de la contribución. En este caso, una simple vista previa revela que los nombres de los pasajeros también incluyen sus títulos (Sr., Dr., etc.) que podrían contener información valiosa; por lo tanto, vamos a mantenerlo. Sin embargo, queremos echar un vistazo más de cerca a la boat columna, que también parece tener un fuerte poder predictivo.
Fuga objetivo
Primero, comencemos con el concepto de fuga. La fuga puede ocurrir durante diferentes etapas del ciclo de vida de ML. El uso de características que están disponibles solo durante el entrenamiento pero no durante la inferencia también se puede definir como fuga de objetivos. Por ejemplo, una bolsa de aire desplegada no es un buen predictor de un accidente automovilístico, porque en la vida real ocurre después del hecho.
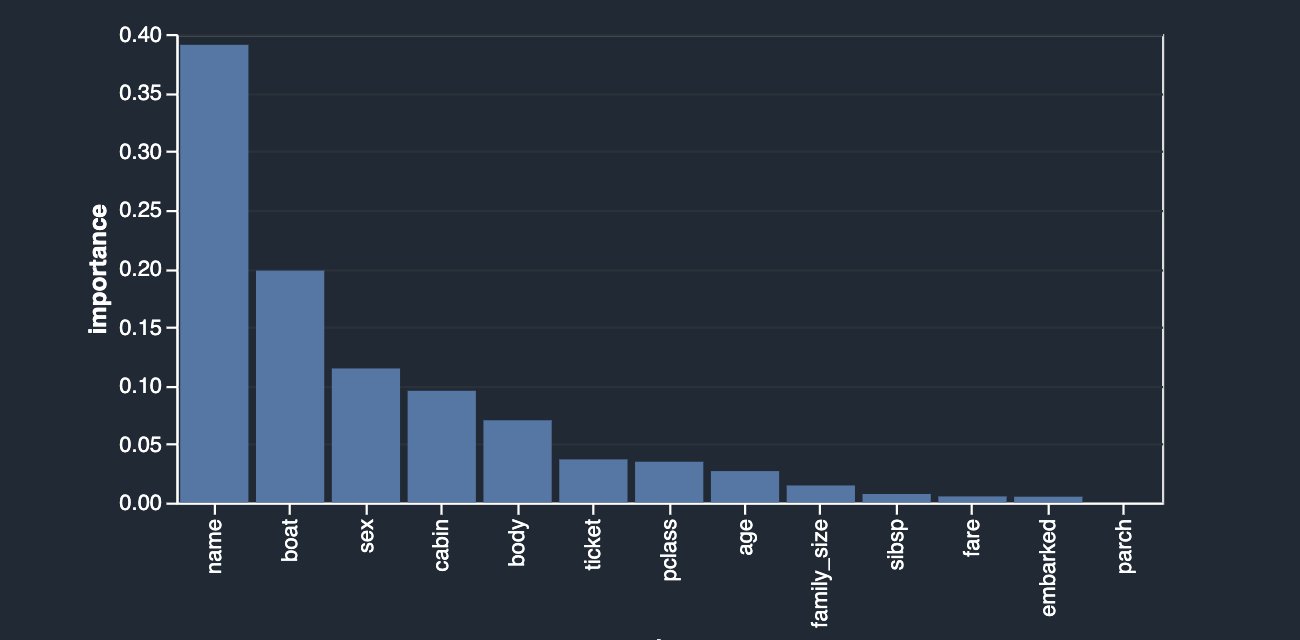
Una de las técnicas para identificar la fuga objetivo se basa en calcular los valores ROC para cada característica. Cuanto más cerca esté el valor de 1, más probable es que la función sea muy predictiva del objetivo y, por lo tanto, más probable es que sea un objetivo filtrado. Por otro lado, cuanto más cerca esté el valor de 0.5 e inferior (rara vez), es menos probable que esta característica contribuya en algo a la predicción. Finalmente, los valores que están por encima de 0.5 y por debajo de 1 indican que la característica no tiene poder predictivo por sí misma, pero puede contribuir en un grupo, que es lo que nos gustaría ver idealmente.
Vamos a crear un análisis de fuga objetivo en su conjunto de datos. Este análisis junto con un conjunto de análisis avanzados se ofrecen como tipos de análisis integrados en Data Wrangler. Para crear el análisis, seleccione Agregar análisis y elige Fuga objetivo. Esto es similar a cómo creó previamente un análisis de modelo rápido.
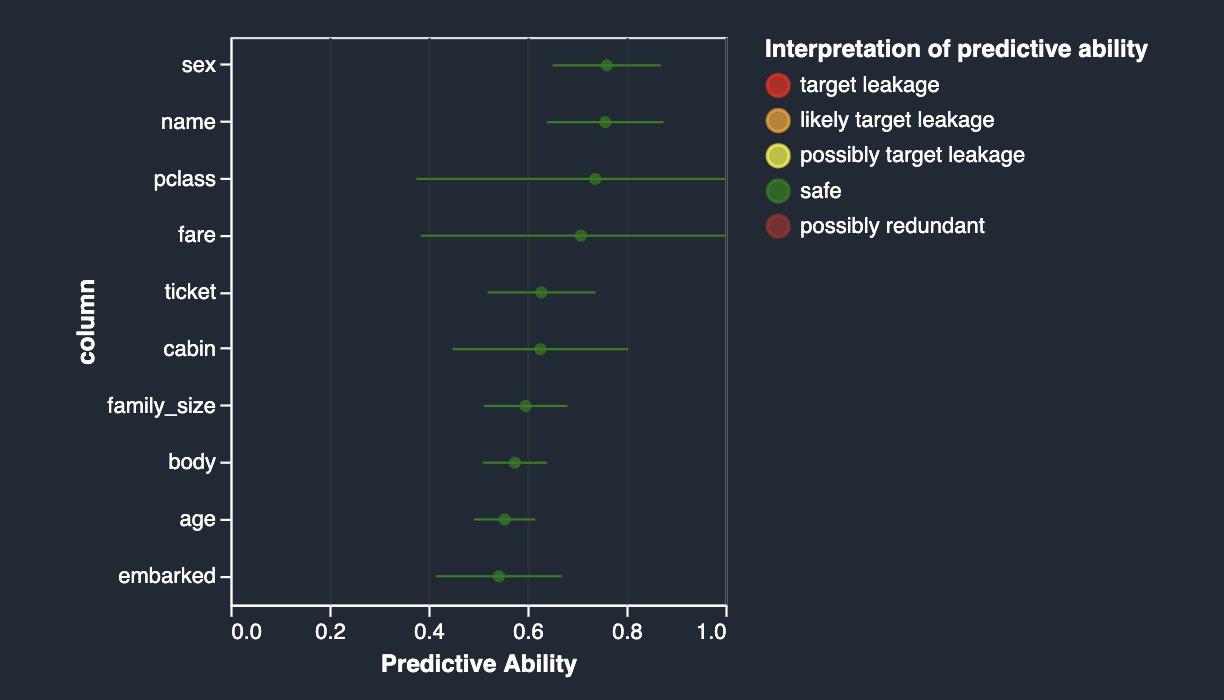
Como puede ver en la siguiente figura, su característica más predictiva boat tiene un valor ROC bastante cercano a 1, lo que lo convierte en un posible sospechoso de fuga de objetivos.
Si lee la descripción del conjunto de datos, el boat columna contiene el número del bote salvavidas en el que el pasajero logró escapar. Naturalmente, existe una correlación bastante estrecha con la survival etiqueta. El número del bote salvavidas se conoce solo después del hecho, cuando se recogió el bote salvavidas y se identificó a los sobrevivientes en él. Esto es muy similar al ejemplo de la bolsa de aire. Por lo tanto, los boat columna es de hecho una fuga objetivo.
Puede eliminarlo de su conjunto de datos aplicando la transformación de columna desplegable en la interfaz de usuario de Data Wrangler (elija Manejar columnas, escoger Soltar, e indicar boat). Ahora, si vuelve a ejecutar el análisis, obtiene lo siguiente.
Multicolinealidad
La multicolinealidad ocurre cuando dos o más características en un conjunto de datos están altamente correlacionadas entre sí. Es importante detectar la presencia de multicolinealidad en un conjunto de datos porque la multicolinealidad puede reducir las capacidades predictivas de un modelo de ML. La multicolinealidad ya puede estar presente en los datos sin procesar recibidos de un sistema ascendente o puede introducirse inadvertidamente durante la ingeniería de características. Por ejemplo, el conjunto de datos del Titanic contiene dos columnas que indican el número de miembros de la familia con los que viajó cada pasajero: número de hermanos (sibsp) y número de padres (parch). Digamos que en alguna parte de su proceso de ingeniería de características, decidió que tendría sentido introducir una medida más simple del tamaño de la familia de cada pasajero combinando las dos.
Un paso de transformación muy simple puede ayudarnos a lograrlo, como se muestra en la siguiente captura de pantalla.
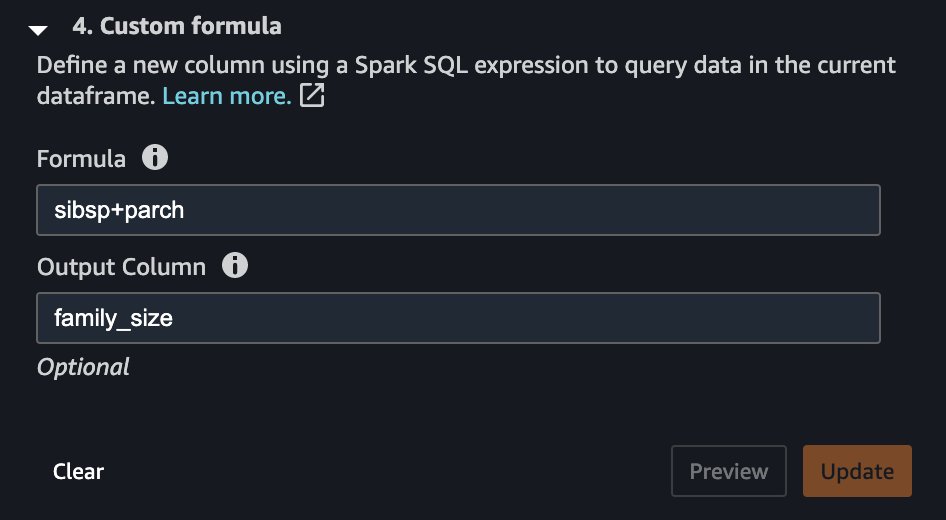
Como resultado, ahora tiene una columna llamada family_size, que refleja precisamente eso. Si no eliminó las dos columnas originales, ahora tiene una correlación muy fuerte entre ambos hermanos, así como el parents columnas y el tamaño de la familia. Creando otro análisis y eligiendo Multicolinealidad, ahora puede ver lo siguiente.
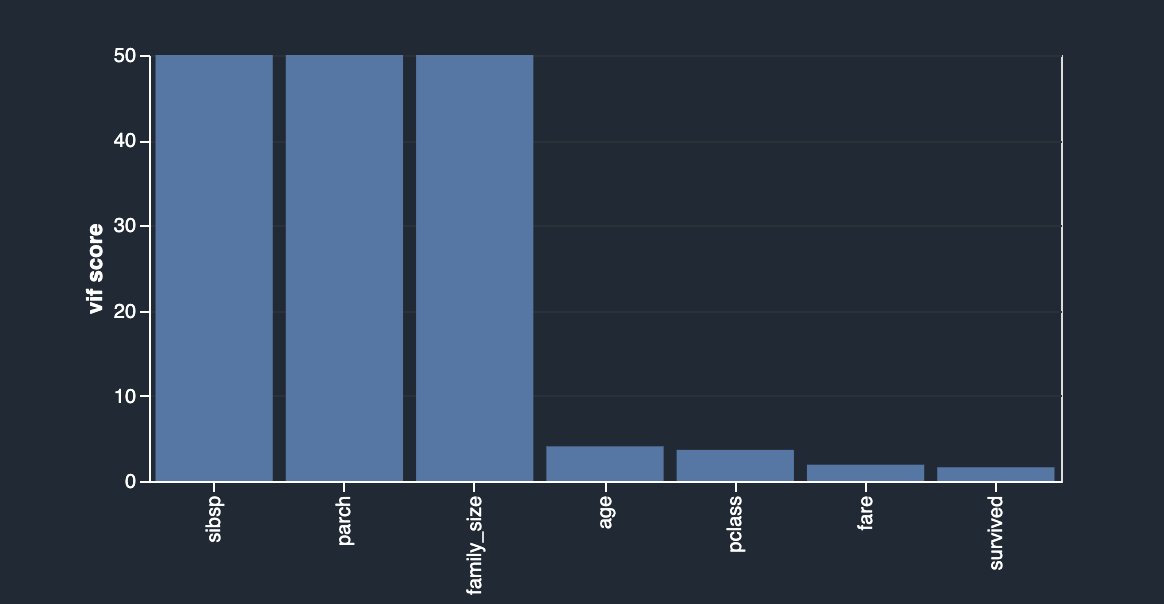
En este caso, está utilizando el enfoque del factor de inflación de varianza (VIF) para identificar características altamente correlacionadas. Los puntajes VIF se calculan resolviendo un problema de regresión para predecir una variable dado el resto, y pueden variar entre 1 e infinito. Cuanto más alto es el valor, más dependiente es una característica. La implementación del análisis VIF de Data Wrangler limita las puntuaciones a 50 y, en general, una puntuación de 5 significa que la característica está moderadamente correlacionada, mientras que cualquier valor superior a 5 se considera altamente correlacionado.
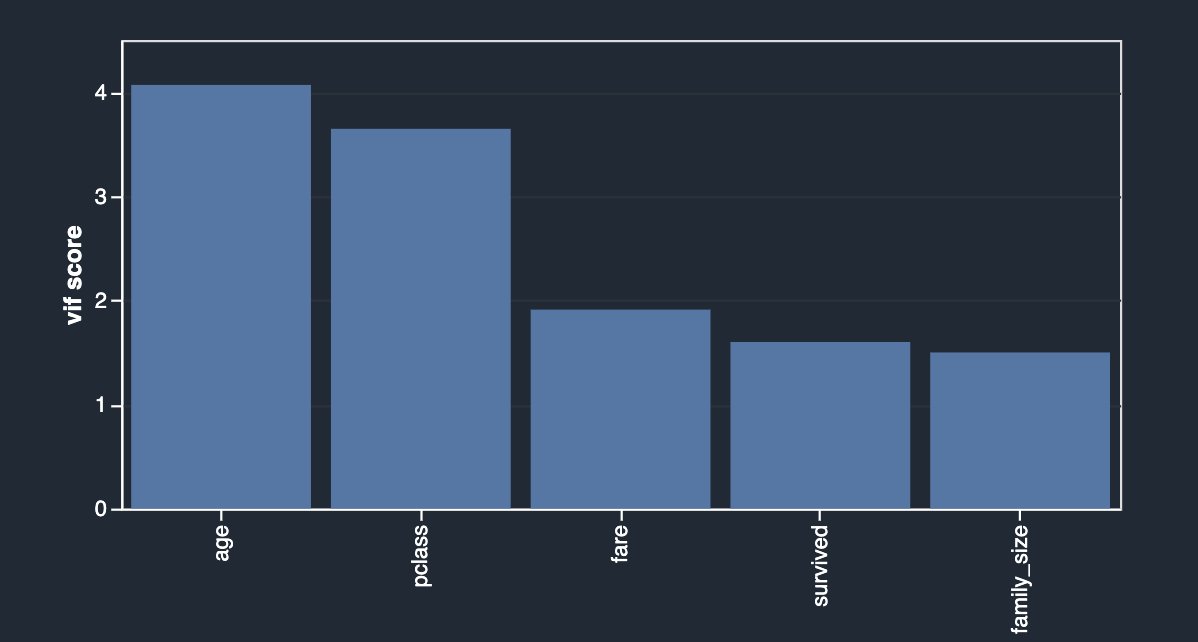
Su característica recién diseñada depende en gran medida de las columnas originales, que ahora puede simplemente eliminar usando otra transformación eligiendo Administrar columnas, Soltar columna.
Un enfoque alternativo para identificar características que tienen menos o más poder predictivo es usar el Selección de características de lazo tipo de análisis de multicolinealidad (por Tipo de problema, escoger Clasificación y para Columna de etiqueta, escoger survived).
Como se describe en la descripción, este análisis crea un clasificador lineal que proporciona un coeficiente para cada característica. El valor absoluto de este coeficiente también se puede interpretar como la puntuación de importancia de la característica. Como puedes observar en tu caso, family_size no tiene valor en términos de importancia de la característica debido a su redundancia, a menos que elimine las columnas originales.
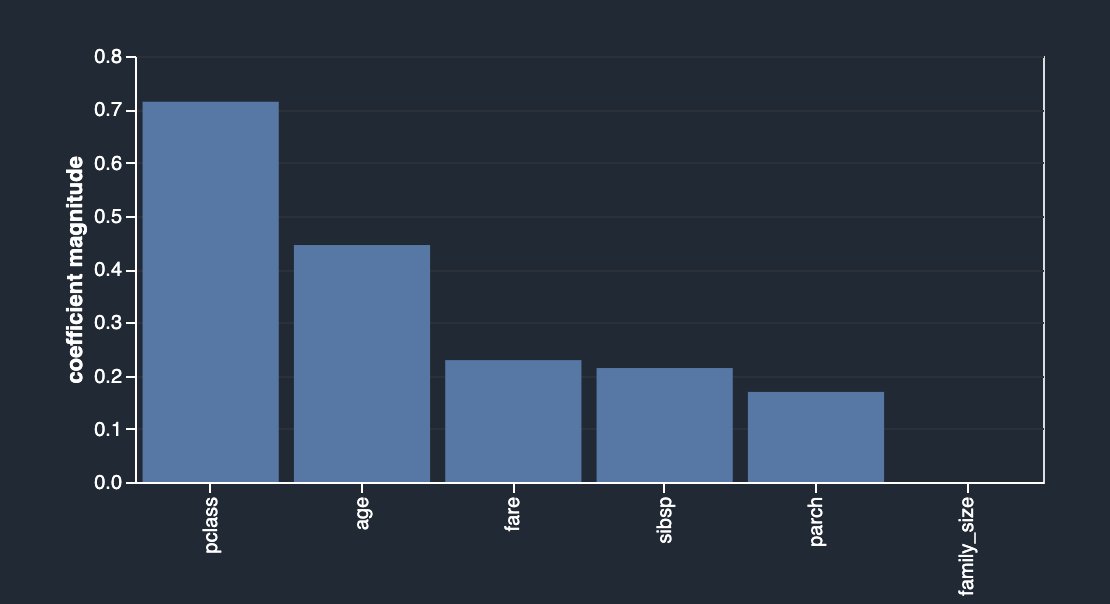
Después de caer sibsp y parch, obtienes lo siguiente.
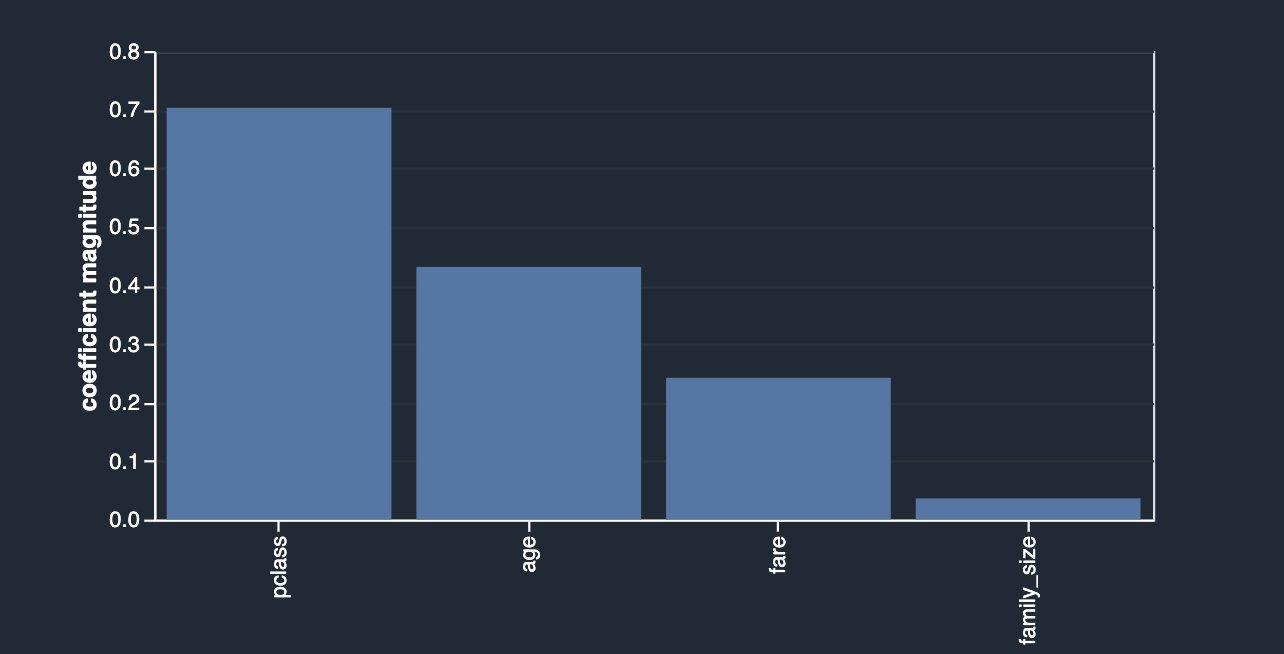
Data Wrangler también ofrece una tercera opción para detectar la multicolinealidad en su conjunto de datos facilitada a través del Análisis de componentes principales (PCA). PCA mide la varianza de los datos a lo largo de diferentes direcciones en el espacio de características. La lista ordenada de varianzas, también conocida como valores singulares, puede informar sobre la multicolinealidad en sus datos. Esta lista contiene números no negativos. Cuando los números son aproximadamente uniformes, los datos tienen muy pocas multicolinealidades. Sin embargo, cuando ocurre lo contrario, la magnitud de los valores superiores dominará al resto. Para evitar problemas relacionados con diferentes escalas, las características individuales se estandarizan para tener una media de 0 y una desviación estándar de 1 antes de aplicar PCA.
Antes de soltar las columnas originales (sibsp y parch), su análisis de PCA se muestra a continuación.
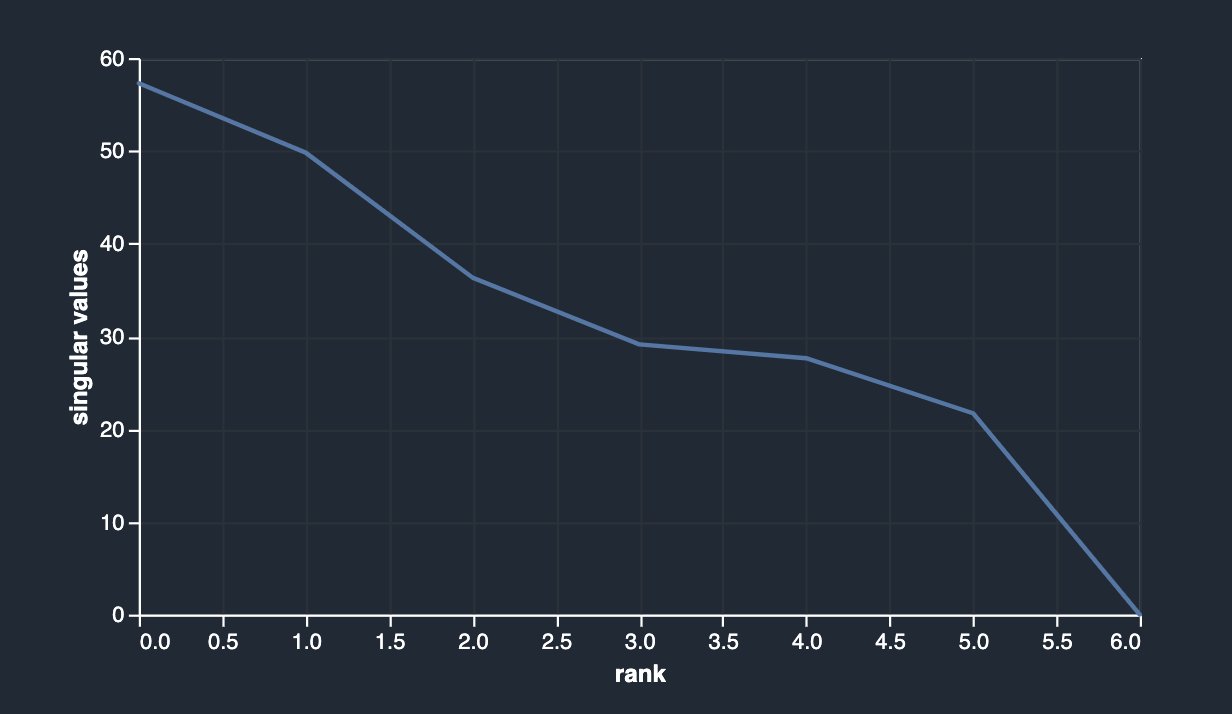
Después de caer sibsp y parch, tienes lo siguiente.
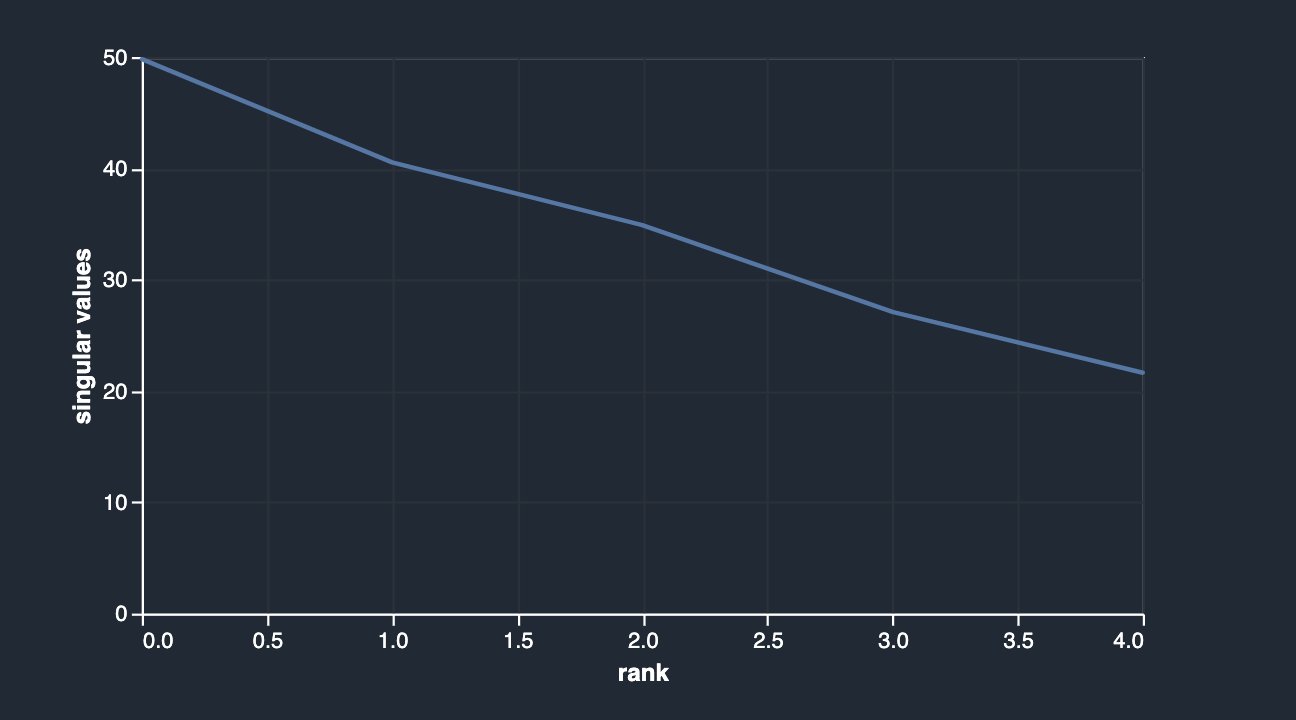
Correlación de características
La correlación es una medida del grado de dependencia entre variables. Las funciones correlacionadas en general no mejoran los modelos, pero pueden tener un impacto en los modelos. Hay dos tipos de funciones de detección de correlación disponibles en Data Wrangler: lineales y no lineales.
La correlación de características lineales se basa en correlación de Pearson. La correlación numérica a numérica está en el rango [-1, 1] donde 0 implica que no hay correlación, 1 implica una correlación perfecta y -1 implica una correlación inversa perfecta. Las correlaciones de numérico a categórico y de categórico a categórico están en el rango [0, 1] donde 0 implica que no hay correlación y 1 implica una correlación perfecta. Las características que no son numéricas ni categóricas se ignoran.
La siguiente matriz de correlación y tabla de puntuación validan y refuerzan sus hallazgos anteriores.
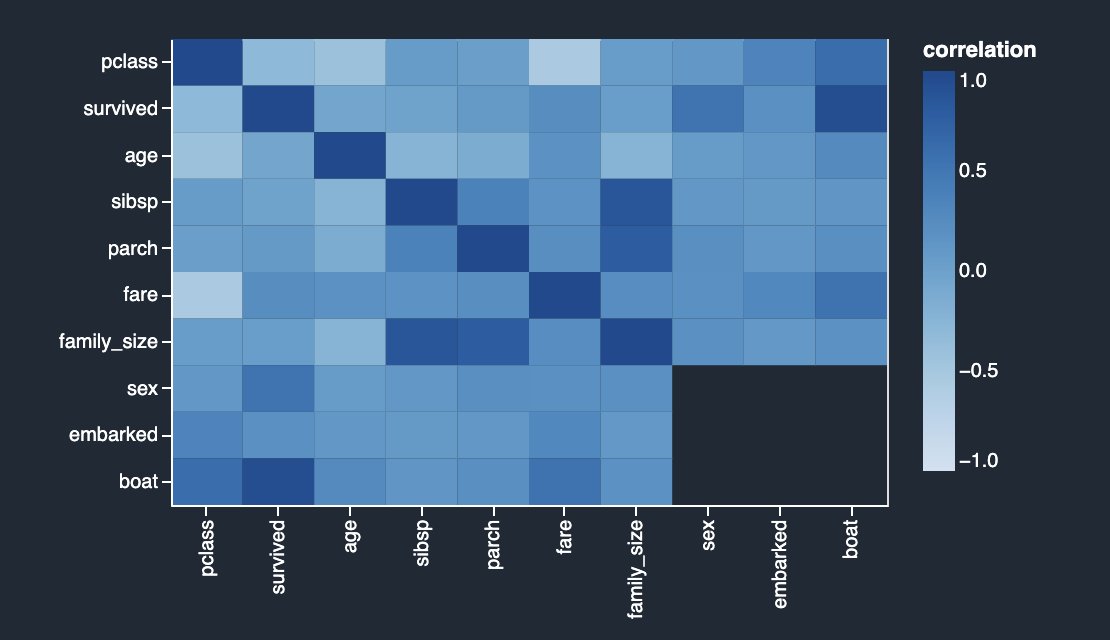
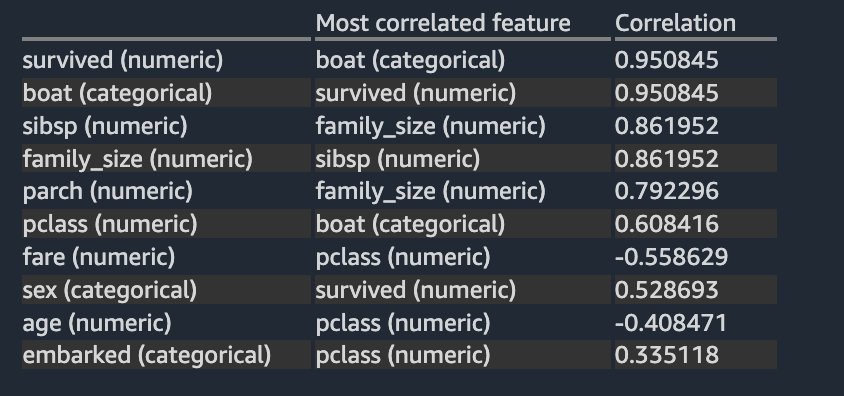
Las columnas survived y boat están altamente correlacionados entre sí. Para este ejemplo, survived es la columna de destino o la etiqueta que intenta predecir. Ya vio esto anteriormente en su análisis de fuga objetivo. Por otro lado, las columnas sibsp y parch están altamente correlacionados con la característica derivada family_size. Esto se confirmó en su análisis de multicolinealidad anterior. No vemos ninguna correlación lineal inversa fuerte en el conjunto de datos.
Cuando dos variables cambian en una proporción constante, se llama correlación lineal, mientras que cuando las dos variables no cambian en una proporción constante, la relación es no lineal. La correlación es perfectamente positiva cuando el cambio proporcional en dos variables tiene la misma dirección. Por el contrario, la correlación es perfectamente negativa cuando el cambio proporcional en dos variables es en dirección opuesta.
La diferencia entre la correlación de características y la multicolinealidad (discutida anteriormente) es la siguiente: la correlación de características se refiere a la relación lineal o no lineal entre dos variables. Con este contexto, puede definir la colinealidad como un problema en el que dos o más variables independientes (predictores) tienen una fuerte relación lineal o no lineal. La multicolinealidad es un caso especial de colinealidad en el que existe una fuerte relación lineal entre tres o más variables independientes, incluso si ningún par de variables tiene una correlación alta.
La correlación de características no lineales se basa en correlación de rango de Spearman. La correlación de numérico a categórico se calcula codificando las características categóricas como los números de punto flotante que mejor predicen la característica numérica antes de calcular la correlación de rango de Spearman. La correlación categórica a categórica se basa en la prueba V de Cramer normalizada.
La correlación numérica a numérica está en el rango [-1, 1] donde 0 implica que no hay correlación, 1 implica una correlación perfecta y -1 implica una correlación inversa perfecta. Las correlaciones de numérico a categórico y de categórico a categórico están en el rango [0, 1] donde 0 implica que no hay correlación y 1 implica una correlación perfecta. Las características que no son numéricas o categóricas se ignoran.
La siguiente tabla enumera para cada característica cuál es la característica más correlacionada con ella. Muestra una matriz de correlación para un conjunto de datos con hasta 20 columnas.
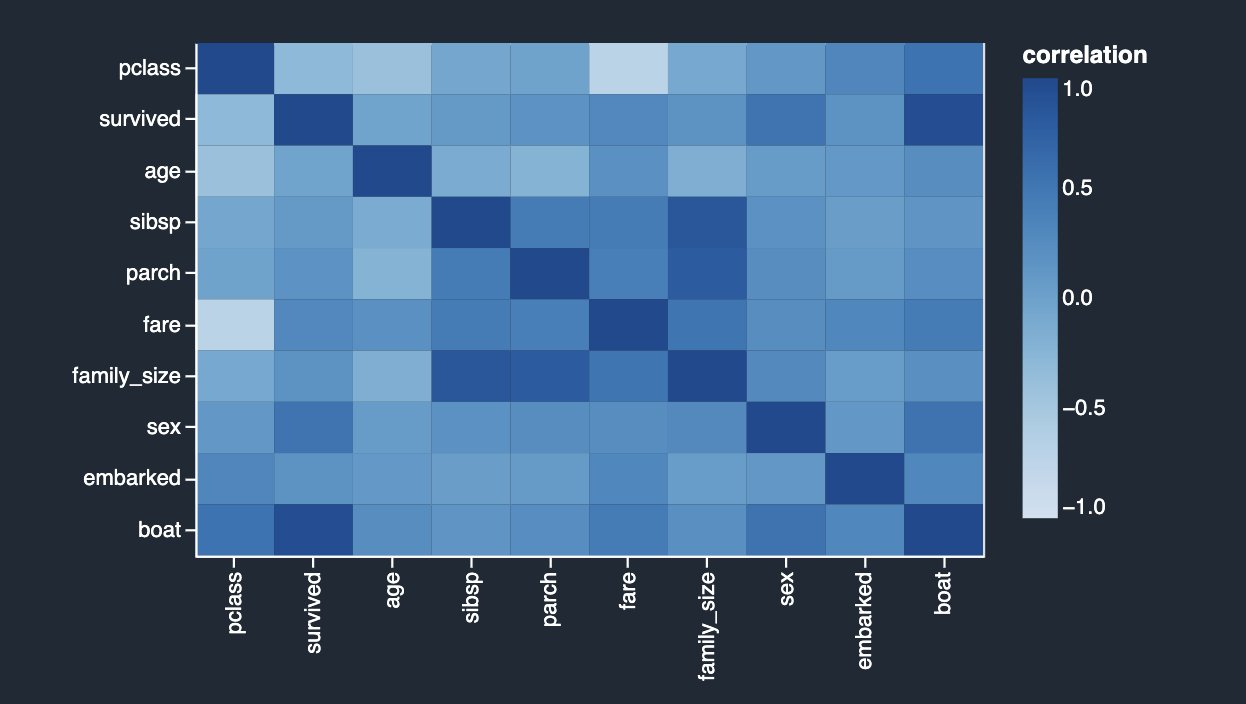
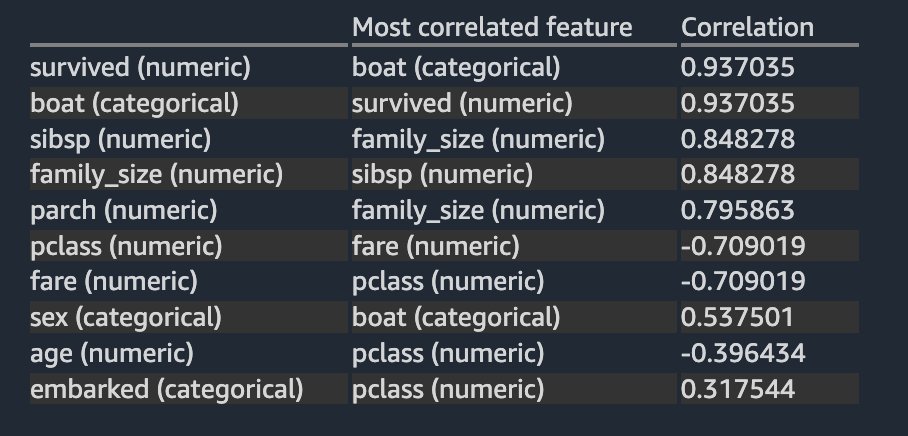
Los resultados son muy similares a los que vio en el análisis de correlación lineal anterior, excepto que también puede ver una fuerte correlación negativa no lineal entre el pclass y fare columnas numéricas.
Finalmente, ahora que identificó la posible fuga de objetivos y eliminó las funciones en función de sus análisis, volvamos a ejecutar el análisis del modelo rápido para ver nuevamente el desglose de la importancia de las funciones.
Los resultados se ven bastante diferentes de lo que comenzó inicialmente. Por lo tanto, Data Wrangler facilita la ejecución de análisis avanzados específicos de ML con unos pocos clics y obtiene información sobre la relación entre sus variables independientes (características) entre sí y también con la variable de destino. También le proporciona el tipo de análisis de modelo rápido que le permite validar el estado actual de las funciones entrenando un modelo rápido y probando qué tan predictivo es el modelo.
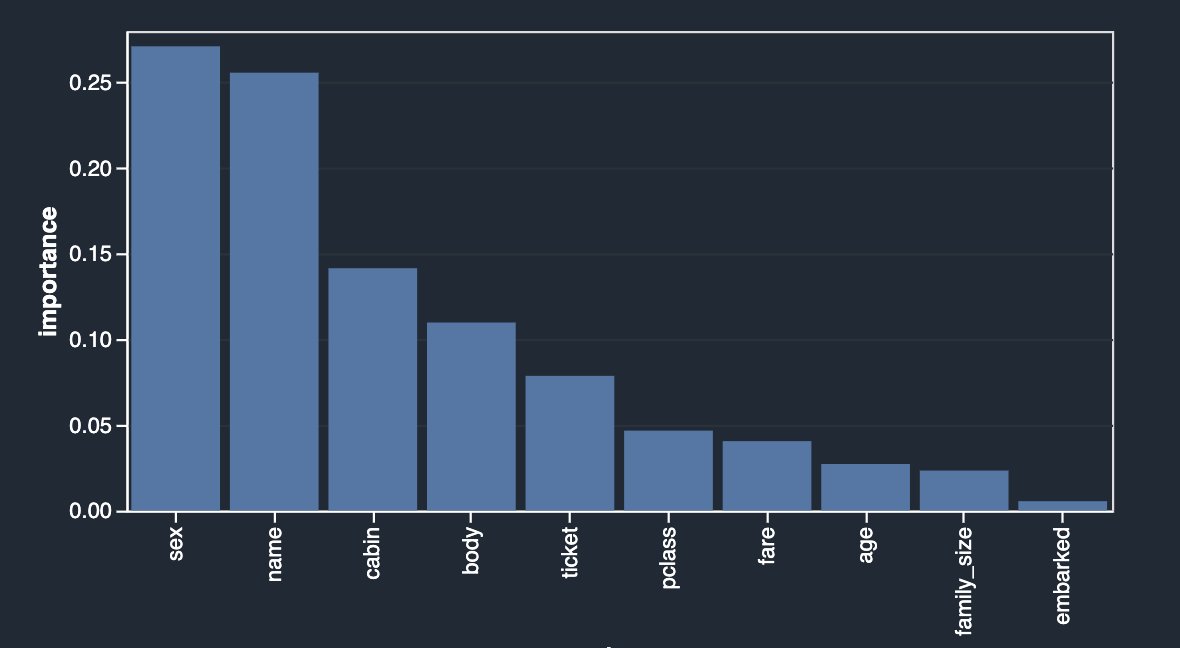
Idealmente, como científico de datos, debe comenzar con algunos de los análisis que se muestran en esta publicación y obtener información sobre qué características es bueno conservar frente a qué descartar.
Resumen
En esta publicación, aprendió a usar Data Wrangler para el análisis exploratorio de datos, centrándose en la fuga de objetivos, la correlación de características y los análisis de multicolinealidad para identificar posibles problemas con los datos de entrenamiento y mitigarlos con la ayuda de transformaciones integradas. Como próximos pasos, le recomendamos que replique el ejemplo de esta publicación en su flujo de datos de Data Wrangler para experimentar lo que se discutió aquí en acción.
Si es nuevo en Data Wrangler o Studio, consulte Comience con Data Wrangler. Si tiene alguna pregunta relacionada con esta publicación, agréguela en la sección de comentarios.
Sobre los autores
 Vadim Omeltchenko es un arquitecto sénior de soluciones de inteligencia artificial y aprendizaje automático apasionado por ayudar a los clientes de AWS a innovar en la nube. Su experiencia anterior en TI fue predominantemente en el terreno.
Vadim Omeltchenko es un arquitecto sénior de soluciones de inteligencia artificial y aprendizaje automático apasionado por ayudar a los clientes de AWS a innovar en la nube. Su experiencia anterior en TI fue predominantemente en el terreno.
 Arunprasath Shankar es un arquitecto sénior de soluciones de inteligencia artificial/aprendizaje automático en AWS, que ayuda a los clientes globales a escalar sus soluciones de inteligencia artificial de manera eficaz y eficiente en la nube. En su tiempo libre, Arun disfruta viendo películas de ciencia ficción y escuchando música clásica.
Arunprasath Shankar es un arquitecto sénior de soluciones de inteligencia artificial/aprendizaje automático en AWS, que ayuda a los clientes globales a escalar sus soluciones de inteligencia artificial de manera eficaz y eficiente en la nube. En su tiempo libre, Arun disfruta viendo películas de ciencia ficción y escuchando música clásica.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/detect-multicollinearity-target-leakage-and-feature-correlation-with-amazon-sagemaker-data-wrangler/

