Publicación de asociación
Si está trabajando en python con grandes conjuntos de datos, quizás de varios gigabytes de tamaño, es probable que pueda relacionarse con la frustración de esperar horas para que finalicen sus consultas mientras su Pandas DataFrame basado en CPU tiene dificultades para realizar operaciones. Esta situación exacta es donde un Los pandas el usuario debe considerar aprovechar el poder de las GPU para el procesamiento de datos con CUDF RÁPIDOS.
RAPIDS cuDF, con su API similar a pandas, permite a los científicos e ingenieros de datos aprovechar rápidamente el inmenso potencial de la computación paralela en GPU, con solo unos pocos cambios en la línea de código.
Si no está familiarizado con la aceleración de GPU, esta publicación es una introducción sencilla al ecosistema RAPIDS y muestra la funcionalidad más común de cuDF, la contraparte de Pandas DataFrame basada en GPU.
¿Quieres un resumen práctico de estos consejos? Siga junto con el descargable hoja de trucos de cuDF.
Aprovechamiento de las GPU con cuDF DataFrame
cuDF es un bloque de construcción de ciencia de datos para el RÁPIDOS conjunto de bibliotecas aceleradas por GPU. Es un caballo de batalla de EDA que puede usar para construir canalizaciones de datos que permitan procesar datos y derivar nuevas características. Como componente fundamental dentro de la suite RAPIDS, cuDF respalda las otras bibliotecas, consolidando su función como un bloque de construcción común. Como todos los componentes de la suite RAPIDS, cuDF emplea el backend CUDA para potenciar los cálculos de GPU.
Sin embargo, con una interfaz de Python fácil y familiar, los usuarios de cuDF no necesitan interactuar directamente con esa capa.
Cómo cuDF puede hacer que su ciencia de datos funcione más rápido
¿Estás cansado de mirar el reloj mientras se ejecuta tu script? Ya sea que esté manejando datos de cadena o trabajando con series de tiempo, hay muchas maneras en que puede usar cuDF para impulsar su trabajo de datos.
- Análisis de series temporales: Ya sea que esté remuestreando datos, extrayendo características o realizando cálculos complejos, cuDF ofrece una aceleración sustancial, potencialmente hasta 880 veces más rápida que pandas para el análisis de series temporales.
- Análisis de datos exploratorios en tiempo real (AED): Navegar a través de grandes conjuntos de datos puede ser una tarea ardua con las herramientas tradicionales, pero la potencia de procesamiento acelerada por GPU de cuDF hace posible la exploración en tiempo real incluso de los conjuntos de datos más grandes.
- Preparación de datos de aprendizaje automático (ML): Acelere las tareas de transformación de datos y prepare sus datos para algoritmos de ML de uso común, como regresión, clasificación y clustering, con las capacidades de aceleración de cuDF. El procesamiento eficiente significa un desarrollo de modelo más rápido y le permite avanzar más rápido hacia la implementación.
- Visualización de datos a gran escala: Ya sea que esté creando mapas de calor para datos geográficos o visualizando tendencias financieras complejas, los desarrolladores pueden implementar bibliotecas de visualización de datos con visualización de datos de alto rendimiento y alto FPS mediante el uso de cuDF y cuxfilter. Esta integración permite que la interactividad en tiempo real se convierta en un componente vital de su ciclo de análisis.
- Filtrado y transformación de datos a gran escala: Para grandes conjuntos de datos que excedan varios gigabytes, puede realizar tareas de filtrado y transformación usando cuDF en una fracción del tiempo que toma con pandas.
- Procesamiento de datos de cadenas: Tradicionalmente, el procesamiento de datos de cadenas ha sido una tarea desafiante y lenta debido a la naturaleza compleja de los datos textuales. Estas operaciones se realizan sin esfuerzo con la aceleración de GPU
- Operaciones agrupar por: Las operaciones GroupBy son un elemento básico en el análisis de datos, pero pueden consumir muchos recursos. cuDF acelera significativamente estas tareas, lo que le permite obtener información más rápidamente al dividir y agregar sus datos

Interfaz familiar para el procesamiento de GPU
La premisa central de RAPIDS es proporcionar una experiencia de usuario familiar a las herramientas populares de ciencia de datos para que el poder de las GPU NVIDIA sea fácilmente accesible para todos los profesionales. Ya sea que esté realizando ETL, creando modelos ML o procesando gráficos, si conoce pandas, NumPy, scikit-aprender or RedX, se sentirá como en casa cuando utilice RAPIDS.
Cambiar de la pila de ciencia de datos de CPU a GPU nunca ha sido tan fácil: con un pequeño cambio como importar cuDF en lugar de pandas, puede aprovechar la enorme potencia de las GPU NVIDIA, acelerar las cargas de trabajo 10-100x (en el extremo inferior) y disfrutar más productividad, todo mientras usa sus herramientas favoritas.
Verifique el código de muestra a continuación que presenta cuán familiar es la API de cuDF para cualquiera que use pandas.
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')Cargar datos de sus fuentes de datos favoritas
Las capacidades de lectura y escritura de cuDF han crecido significativamente desde la primera versión de RAPIDS en octubre de 2018. Los datos pueden ser locales en una máquina, almacenados en un clúster local o en la nube. usos cuDF fsspec biblioteca para abstraer la mayoría de las tareas relacionadas con el sistema de archivos para que pueda concentrarse en lo que más importa: crear características y construir su modelo.
Gracias a fsspec, la lectura de datos del sistema de archivos local o en la nube solo requiere proporcionar credenciales a este último. El siguiente ejemplo lee el mismo archivo desde dos ubicaciones diferentes,
import cudf
df_local = cudf.read_csv('/data/sample.csv')
df_remote = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})cuDF admite múltiples formatos de archivo: formatos basados en texto como CSV/TSV o JSON, formatos orientados a columnas como parquet or ORC, o formatos orientados a filas como Avro. En términos de compatibilidad con el sistema de archivos, cuDF puede leer archivos del sistema de archivos local, proveedores de la nube como AWS S3, Google GS o Azure Blob/Data Lake, sistemas de archivos Hadoop dentro o fuera de las instalaciones, y también directamente desde HTTP o (S ) Servidores web FTP, Dropbox o Google Drive, o Jupyter File System.
Crear y guardar DataFrames con facilidad
Leer archivos no es la única forma de crear marcos de datos cuDF. De hecho, hay al menos 4 formas de hacerlo:
A partir de una lista de valores, puede crear DataFrame con una columna,
cudf.DataFrame([1,2,3,4], columns=['foo'])
Pasando un diccionario si desea crear un DataFrame con varias columnas,
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})Creando un DataFrame vacío y asignándolo a columnas,
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]Pasando una lista de tuplas,
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])También puede convertir hacia y desde otras representaciones de memoria:
- Desde una matriz de GPU interna representada como DeviceNDArray,
- A través de objetos de memoria DLPack utilizados para compartir tensores entre deep learning frameworks y formato Apache Arrow que facilita una forma mucho más conveniente de manipular objetos de memoria desde varios lenguajes de programación,
- Para convertir hacia y desde pandas DataFrames y Series.
Además, cuDF admite guardar los datos almacenados en un DataFrame en múltiples formatos y sistemas de archivos. De hecho, cuDF puede almacenar datos en todos los formatos que puede leer.
Todas estas capacidades hacen posible ponerse en marcha rápidamente sin importar cuál sea su tarea o dónde se encuentren sus datos.
Extraer, transformar y resumir datos
La tarea fundamental de la ciencia de datos, y de la que se quejan todos los científicos de datos, es limpiar, destacando y familiarizarse con el conjunto de datos. Pasamos el 80% de nuestro tiempo haciendo eso. ¿Por qué lleva tanto tiempo?
Una de las razones es porque las preguntas que contacta el conjunto de datos tarda demasiado en responder. Cualquiera que haya intentado leer y procesar un conjunto de datos de 2GB en una CPU sabe de lo que estamos hablando.
Además, dado que somos humanos y cometemos errores, volver a ejecutar una canalización puede convertirse rápidamente en un ejercicio de un día completo. Esto da como resultado una pérdida de productividad y, probablemente, una adicción al café si echamos un vistazo al cuadro a continuación.
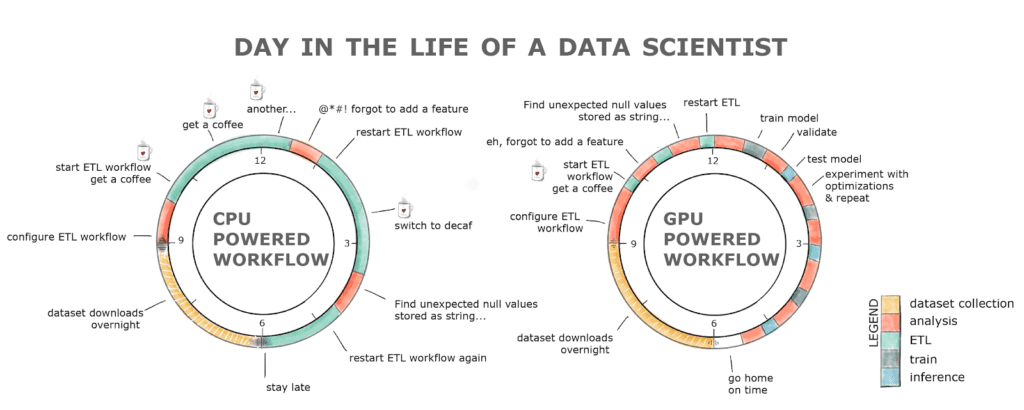
Figura 1. Jornada laboral típica de un desarrollador que utiliza un flujo de trabajo impulsado por GPU frente a CPU
RAPIDS con el flujo de trabajo impulsado por GPU alivia todos estos obstáculos. La etapa ETL normalmente es entre 8 y 20 veces más rápida, por lo que cargar ese conjunto de datos de 2 GB toma segundos en comparación con minutos en una CPU, ¡limpiar y transformar los datos también es mucho más rápido! Todo esto con una interfaz familiar y cambios mínimos de código.
Trabajar con cadenas y fechas en GPU
Hace no más de 5 años, trabajar con cadenas y fechas en GPU se consideraba casi imposible y fuera del alcance de lenguajes de programación de bajo nivel como CUDA. Después de todo, las GPU se diseñaron para procesar gráficos, es decir, para manipular grandes arreglos y matrices de números enteros y flotantes, no cadenas ni fechas.
RAPIDS le permite no solo leer cadenas en la memoria de la GPU, sino también extraer funciones, procesarlas y manipularlas. Si está familiarizado con Regex, extraer información útil de un documento en una GPU ahora es una tarea trivial gracias a cuDF. Por ejemplo, si desea buscar y extraer todas las palabras en su documento que coincidan con el patrón de flujo [az]* (como, datade tus señales, trabajode tus señaleso de tus señales) todo lo que necesitas hacer es,
df['string'].str.findall('([a-z]*flow)')
Extraer características útiles de fechas o consultar los datos para un período de tiempo específico ahora es más fácil y rápido gracias a RAPIDS también.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')Empoderar a los usuarios de Pandas con aceleración de GPU
La transición de una pila de ciencia de datos de CPU a GPU es sencilla con RAPIDS. Importar cuDF en lugar de pandas es un pequeño cambio que puede generar inmensos beneficios. Ya sea que esté trabajando en una caja de GPU local o escalando a centros de datos completos, la potencia acelerada por GPU de RAPIDS proporciona mejoras de velocidad de 10 a 100 veces (en el extremo inferior). Esto no solo conduce a una mayor productividad, sino que también permite la utilización eficiente de sus herramientas favoritas, incluso en los escenarios a gran escala más exigentes.
RAPIDS realmente ha revolucionado el panorama del procesamiento de datos, permitiendo a los científicos de datos completar tareas en minutos que antes tomaban horas o incluso días, lo que lleva a una mayor productividad y costos generales más bajos.
Para empezar a aplicar estas técnicas a su conjunto de datos, lea el serie de análisis de datos acelerados en el blog técnico de NVIDIA.
Nota del editor: este post se actualizó con permiso y se adaptó originalmente del blog técnico de NVIDIA.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/07/mastering-gpus-beginners-guide-gpu-accelerated-dataframes-python.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-gpus-a-beginners-guide-to-gpu-accelerated-dataframes-in-python

