Introducción
El estrés es una respuesta natural del cuerpo y la mente a una situación exigente o desafiante. Es la forma en que el cuerpo reacciona a las presiones externas oa los pensamientos y sentimientos internos. El estrés puede desencadenarse por una variedad de factores, como la presión relacionada con el trabajo, las dificultades financieras, los problemas de relación, los problemas de salud o los eventos importantes de la vida. Los conocimientos de detección de estrés, impulsados por la ciencia de datos y el aprendizaje automático, tienen como objetivo pronosticar los niveles de estrés en individuos o poblaciones. Al analizar una variedad de fuentes de datos, como mediciones fisiológicas, datos de comportamiento y factores ambientales, los modelos predictivos pueden identificar patrones y factores de riesgo asociados con el estrés.

Este enfoque proactivo permite una intervención oportuna y un apoyo personalizado. La predicción del estrés tiene potencial en el cuidado de la salud para la detección temprana y la intervención personalizada, así como en entornos ocupacionales para optimizar los entornos laborales. También puede informar las iniciativas de salud pública y las decisiones políticas. Con la capacidad de predecir el estrés, estos modelos brindan información valiosa para mejorar el bienestar y aumentar la resiliencia en individuos y comunidades.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Descripción general de la detección de estrés mediante el aprendizaje automático
La detección de estrés mediante el aprendizaje automático implica recopilar, limpiar y preprocesar datos. Las técnicas de ingeniería de características se aplican para extraer información significativa o crear nuevas características que puedan capturar patrones relacionados con el estrés. Esto puede implicar la extracción de medidas estadísticas, análisis de dominio de frecuencia o análisis de series de tiempo para capturar indicadores fisiológicos o conductuales de estrés. Las características relevantes se extraen o se diseñan para mejorar el rendimiento.

Los investigadores entrenan modelos de aprendizaje automático como regresión logística, SVM, árboles de decisión, bosques aleatorios o redes neuronales utilizando datos etiquetados para clasificar los niveles de estrés. Evalúan el rendimiento de los modelos utilizando métricas como exactitud, precisión, recuperación y puntuación F1. La integración del modelo entrenado en aplicaciones del mundo real permite el monitoreo del estrés en tiempo real. El monitoreo continuo, las actualizaciones y los comentarios de los usuarios son cruciales para mejorar la precisión.
Es fundamental tener en cuenta las cuestiones éticas y las cuestiones de privacidad cuando se trata de datos personales confidenciales relacionados con el estrés. Se deben seguir procedimientos adecuados de consentimiento informado, anonimización de datos y almacenamiento seguro de datos para proteger la privacidad y los derechos de las personas. Las consideraciones éticas, la privacidad y la seguridad de los datos son importantes durante todo el proceso. La detección del estrés basada en el aprendizaje automático permite la intervención temprana, la gestión personalizada del estrés y la mejora del bienestar.
Descripción de datos
El conjunto de datos de "estrés" contiene información relacionada con los niveles de estrés. Sin la estructura y las columnas específicas del conjunto de datos, puedo proporcionar una descripción general de cómo sería una descripción de datos para un percentil.
El conjunto de datos puede contener variables numéricas que representan mediciones cuantitativas, como la edad, la presión arterial, la frecuencia cardíaca o los niveles de estrés medidos en una escala. También puede incluir variables categóricas que representan características cualitativas, como género, categorías de ocupación o niveles de estrés clasificados en diferentes categorías (bajo, medio, alto).
# Array
import numpy as np # Dataframe
import pandas as pd #Visualization
import matplotlib.pyplot as plt
import seaborn as sns # warnings
import warnings
warnings.filterwarnings('ignore') #Data Reading
stress_c= pd.read_csv('/human-stress-prediction/Stress.csv') # Copy
stress=stress_c.copy() # Data
stress.head()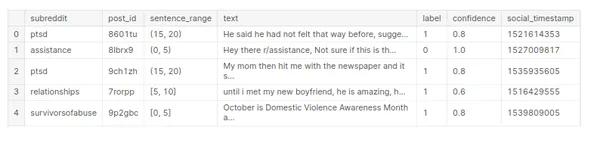
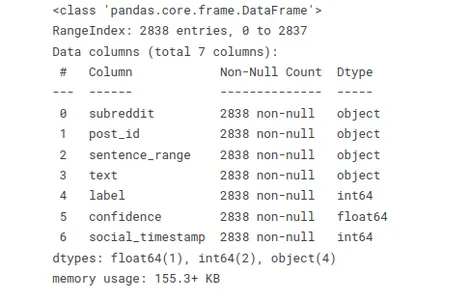
La siguiente función le permite evaluar rápidamente los tipos de datos y descubrir valores faltantes o nulos. Este resumen es útil cuando se trabaja con grandes conjuntos de datos o se realizan tareas de preprocesamiento y limpieza de datos.
# Info
stress.info()
Utilice el código stress.isnull().sum() para buscar valores nulos en el conjunto de datos de "estrés" y calcular la suma de los valores nulos en cada columna.
# Checking null values
stress.isnull().sum()

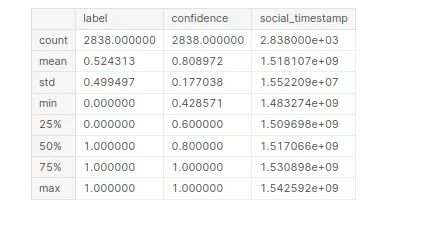
Generar información estadística sobre el conjunto de datos de “estrés”. Al compilar este código, obtendrá un resumen de estadísticas descriptivas para cada columna numérica en el conjunto de datos.
# Statistical Information
stress.describe()
Análisis de datos exploratorios (EDA)
El análisis exploratorio de datos (EDA) es un paso crucial para comprender y analizar un conjunto de datos. Implica explorar y resumir visualmente las principales características, patrones y relaciones dentro de los datos.
lst=['subreddit','label']
plt.figure(figsize=(15,12))
for i in range(len(lst)): plt.subplot(1,2,i+1) a=stress[lst[i]].value_counts() lbl=a.index plt.title(lst[i]+'_Distribution') plt.pie(x=a,labels=lbl,autopct="%.1f %%") plt.show()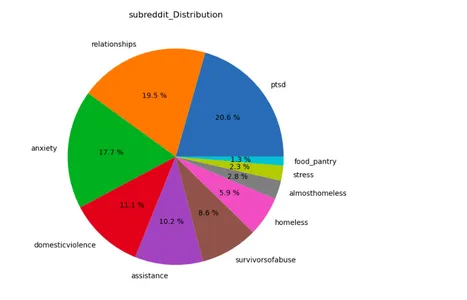
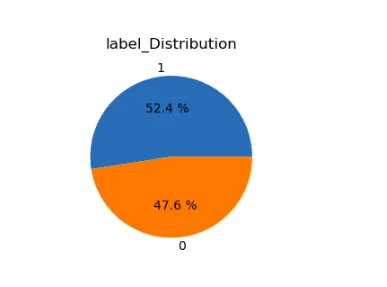
Las bibliotecas Matplotlib y Seaborn crean un gráfico de conteo para el conjunto de datos de "estrés". Visualiza el recuento de instancias de estrés en diferentes subreddits, con las etiquetas de estrés diferenciadas por diferentes colores.
plt.figure(figsize=(20,12))
plt.title('Subreddit wise stress count')
plt.xlabel('Subreddit')
sns.countplot(data=stress,x='subreddit',hue='label',palette='gist_heat')
plt.show()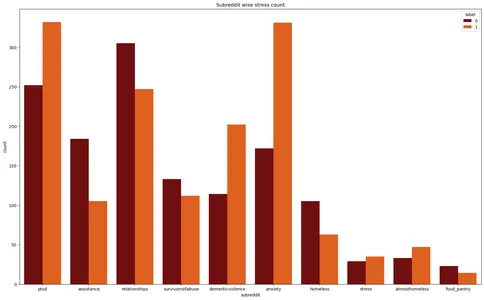
Preprocesamiento de texto
El preprocesamiento de texto se refiere al proceso de convertir datos de texto sin procesar en un formato más limpio y estructurado que sea adecuado para tareas de análisis o modelado. Implica especialmente una serie de pasos para eliminar el ruido, normalizar el texto y extraer características relevantes. Aquí agregué todas las bibliotecas relacionadas con este procesamiento de texto.
# Regular Expression
import re # Handling string
import string # NLP tool
import spacy nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS # Importing Natural Language Tool Kit for NLP operations
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('omw-1.4') from nltk.stem import WordNetLemmatizer from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwords
from collections import Counter
Algunas técnicas comunes utilizadas en el preprocesamiento de texto incluyen:
Limpieza de texto
- Eliminación de caracteres especiales: elimine la puntuación, los símbolos o los caracteres no alfanuméricos que no contribuyen al significado del texto.
- Eliminación de números: elimine dígitos numéricos si no son relevantes para el análisis.
- Minúsculas: convierta todo el texto a minúsculas para garantizar la coherencia en la coincidencia y el análisis del texto.
- Eliminación de palabras vacías: elimine palabras comunes que no contienen mucha información, como "a", "the", "is", etc.
Tokenization
- Dividir el texto en palabras o tokens: divida el texto en palabras individuales o tokens para preparar un análisis posterior. Los investigadores pueden lograr esto empleando espacios en blanco o técnicas de tokenización más avanzadas, como el uso de bibliotecas como NLTK o spaCy.
Normalización
- Lematización: Reducir las palabras a su forma base o de diccionario (lemas). Por ejemplo, convertir "en ejecución" y "corrió" en "ejecutar".
- Stemming: Reduzca las palabras a su forma base eliminando prefijos o sufijos. Por ejemplo, convertir "en ejecución" y "corrió" en "ejecutar".
- Eliminación de signos diacríticos: elimine los acentos u otros signos diacríticos de los caracteres.
#defining function for preprocessing
def preprocess(text,remove_digits=True): text = re.sub('W+',' ', text) text = re.sub('s+',' ', text) text = re.sub("(?<!w)d+", "", text) text = re.sub("-(?!w)|(?<!w)-", "", text) text=text.lower() nopunc=[char for char in text if char not in string.punctuation] nopunc=''.join(nopunc) nopunc=' '.join([word for word in nopunc.split() if word.lower() not in stopwords.words('english')]) return nopunc
# Defining a function for lemitization
def lemmatize(words): words=nlp(words) lemmas = [] for word in words: lemmas.append(word.lemma_) return lemmas #converting them into string
def listtostring(s): str1=' ' return (str1.join(s)) def clean_text(input): word=preprocess(input) lemmas=lemmatize(word) return listtostring(lemmas)# Creating a feature to store clean texts
stress['clean_text']=stress['text'].apply(clean_text)
stress.head()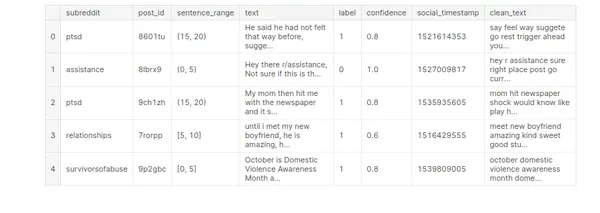
Construcción de modelos de aprendizaje automático
La construcción de modelos de aprendizaje automático es el proceso de creación de una representación o modelo matemático que puede aprender patrones y hacer predicciones o decisiones a partir de los datos. Implica entrenar un modelo usando un conjunto de datos etiquetados y luego usar ese modelo para hacer predicciones sobre datos nuevos e invisibles.
Seleccionar o crear características relevantes a partir de los datos disponibles. La ingeniería de características tiene como objetivo extraer información significativa de los datos sin procesar que pueden ayudar al modelo a aprender patrones de manera efectiva.
# Vectorization
from sklearn.feature_extraction.text import TfidfVectorizer # Model Building
from sklearn.model_selection import GridSearchCV,StratifiedKFold, KFold,train_test_split,cross_val_score,cross_val_predict
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier,RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier #Model Evaluation
from sklearn.metrics import confusion_matrix,classification_report, accuracy_score,f1_score,precision_score
from sklearn.pipeline import Pipeline # Time
from time import time# Defining target & feature for ML model building
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)Elegir un algoritmo de aprendizaje automático o una arquitectura de modelo apropiados en función de la naturaleza del problema y las características de los datos. Diferentes modelos, como árboles de decisión, máquinas de vectores de soporte o redes neuronales, tienen diferentes fortalezas y debilidades.
Entrenamiento del modelo seleccionado utilizando los datos etiquetados. Este paso implica alimentar los datos de entrenamiento al modelo y permitirle aprender los patrones y las relaciones entre las características y la variable de destino.
# Self-defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Logistic regression def model_lr_tf(x_train, x_test, y_train, y_test): global acc_lr_tf,f1_lr_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = LogisticRegression() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_lr_tf=accuracy_score(y_test,y_pred) f1_lr_tf=f1_score(y_test,y_pred,average='weighted') print('Time :',time()-t0) print('Accuracy: ',acc_lr_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_lr_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by MultinomialNB def model_nb_tf(x_train, x_test, y_train, y_test): global acc_nb_tf,f1_nb_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = MultinomialNB() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_nb_tf=accuracy_score(y_test,y_pred) f1_nb_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_nb_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_nb_tf # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Decision Tree
def model_dt_tf(x_train, x_test, y_train, y_test): global acc_dt_tf,f1_dt_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = DecisionTreeClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_dt_tf=accuracy_score(y_test,y_pred) f1_dt_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_dt_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_dt_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by KNN def model_knn_tf(x_train, x_test, y_train, y_test): global acc_knn_tf,f1_knn_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = KNeighborsClassifier() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_knn_tf=accuracy_score(y_test,y_pred) f1_knn_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_knn_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Random Forest def model_rf_tf(x_train, x_test, y_train, y_test): global acc_rf_tf,f1_rf_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = RandomForestClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_rf_tf=accuracy_score(y_test,y_pred) f1_rf_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_rf_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Adaptive Boosting def model_ab_tf(x_train, x_test, y_train, y_test): global acc_ab_tf,f1_ab_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = AdaBoostClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_ab_tf=accuracy_score(y_test,y_pred) f1_ab_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_ab_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) Evaluación del modelo
La evaluación del modelo es un paso crucial en el aprendizaje automático para evaluar el rendimiento y la eficacia de un modelo entrenado. Implica medir qué tan bien se generalizan los modelos múltiples a datos no vistos y si cumple con los objetivos deseados. Evalúe el rendimiento del modelo entrenado en los datos de prueba. Calcule métricas de evaluación como exactitud, precisión, recuperación y puntaje F1 para evaluar la efectividad del modelo en la detección de estrés. La evaluación del modelo proporciona información sobre las fortalezas y debilidades del modelo y su idoneidad para la tarea prevista.
# Evaluating Models print('********************Logistic Regression*********************')
print('n')
model_lr_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
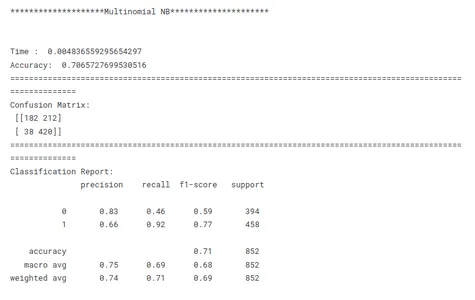
print('********************Multinomial NB*********************')
print('n')
model_nb_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
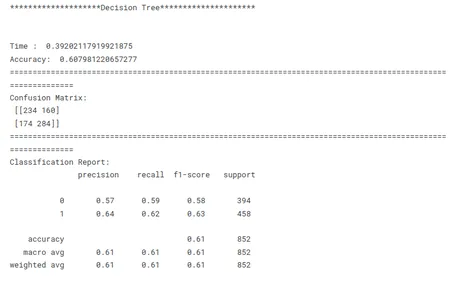
print('********************Decision Tree*********************')
print('n')
model_dt_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
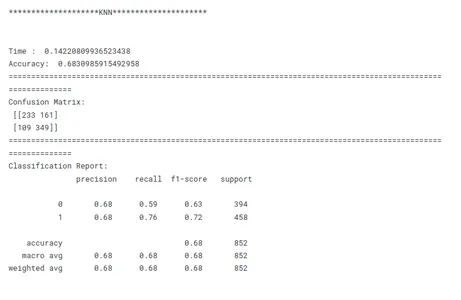
print('********************KNN*********************')
print('n')
model_knn_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
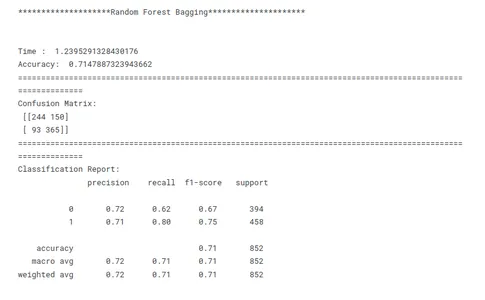
print('********************Random Forest Bagging*********************')
print('n')
model_rf_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
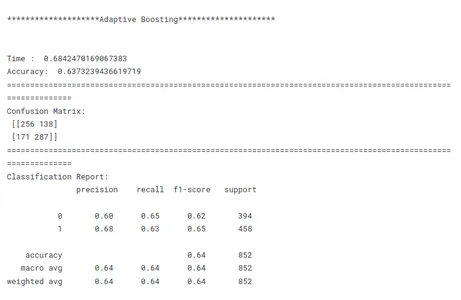
print('********************Adaptive Boosting*********************')
print('n')
model_ab_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')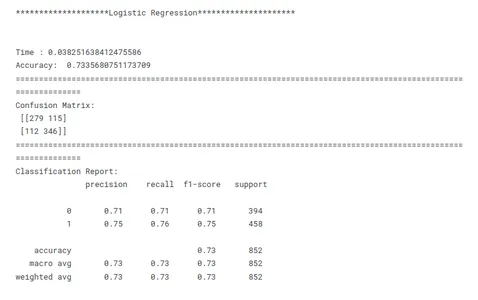
Comparación de rendimiento del modelo
Este es un paso crucial en el aprendizaje automático para identificar el modelo de mejor rendimiento para una tarea determinada. Al comparar modelos, es importante tener un objetivo claro en mente. Ya sea maximizando la precisión, optimizando la velocidad o priorizando la interpretabilidad, las métricas y técnicas de evaluación deben alinearse con el objetivo específico.
La consistencia es clave en la comparación del rendimiento del modelo. El uso de métricas de evaluación coherentes en todos los modelos garantiza una comparación justa y significativa. También es importante dividir los datos en conjuntos de entrenamiento, validación y prueba de manera consistente en todos los modelos. Al garantizar que los modelos evalúen los mismos subconjuntos de datos, los investigadores permiten una comparación justa de su desempeño.
Teniendo en cuenta estos factores anteriores, los investigadores pueden realizar una comparación completa y justa del rendimiento del modelo, lo que conducirá a decisiones informadas con respecto a la selección del modelo para el problema específico en cuestión.
# Creating tabular format for better comparison
tbl=pd.DataFrame()
tbl['Model']=pd.Series(['Logistic Regreesion','Multinomial NB', 'Decision Tree','KNN','Random Forest','Adaptive Boosting'])
tbl['Accuracy']=pd.Series([acc_lr_tf,acc_nb_tf,acc_dt_tf,acc_knn_tf, acc_rf_tf,acc_ab_tf])
tbl['F1_Score']=pd.Series([f1_lr_tf,f1_nb_tf,f1_dt_tf,f1_knn_tf, f1_rf_tf,f1_ab_tf])
tbl.set_index('Model')
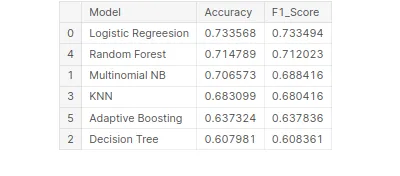
# Best model on the basis of F1 Score
tbl.sort_values('F1_Score',ascending=False)
Validación cruzada para evitar el sobreajuste
La validación cruzada es, de hecho, una técnica valiosa para ayudar a evitar el sobreajuste al entrenar modelos de aprendizaje automático. Proporciona una evaluación sólida del rendimiento del modelo mediante el uso de múltiples subconjuntos de datos para entrenamiento y prueba. Ayuda a evaluar la capacidad de generalización del modelo mediante la estimación de su rendimiento en datos no vistos.
# Using cross validation method to avoid overfitting
import statistics as st
vector = TfidfVectorizer() x_train_v = vector.fit_transform(x_train)
x_test_v = vector.transform(x_test) # Model building
lr =LogisticRegression()
mnb=MultinomialNB()
dct=DecisionTreeClassifier(random_state=1)
knn=KNeighborsClassifier()
rf=RandomForestClassifier(random_state=1)
ab=AdaBoostClassifier(random_state=1)
m =[lr,mnb,dct,knn,rf,ab]
model_name=['Logistic R','MultiNB','DecTRee','KNN','R forest','Ada Boost'] results, mean_results, p, f1_test=list(),list(),list(),list() #Model fitting,cross-validating and evaluating performance def algor(model): print('n',i) pipe=Pipeline([('model',model)]) pipe.fit(x_train_v,y_train) cv=StratifiedKFold(n_splits=5) n_scores=cross_val_score(pipe,x_train_v,y_train,scoring='f1_weighted', cv=cv,n_jobs=-1,error_score='raise') results.append(n_scores) mean_results.append(st.mean(n_scores)) print('f1-Score(train): mean= (%.3f), min=(%.3f)) ,max= (%.3f), stdev= (%.3f)'%(st.mean(n_scores), min(n_scores), max(n_scores),np.std(n_scores))) y_pred=cross_val_predict(model,x_train_v,y_train,cv=cv) p.append(y_pred) f1=f1_score(y_train,y_pred, average = 'weighted') f1_test.append(f1) print('f1-Score(test): %.4f'%(f1)) for i in m: algor(i) # Model comparison By Visualizing fig=plt.subplots(figsize=(20,15))
plt.title('MODEL EVALUATION BY CROSS VALIDATION METHOD')
plt.xlabel('MODELS')
plt.ylabel('F1 Score')
plt.boxplot(results,labels=model_name,showmeans=True)
plt.show() 
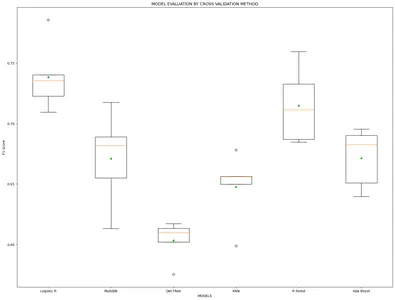
Como las puntuaciones de F1 de los modelos son bastante similares en ambos métodos. Así que ahora estamos aplicando el método Leave One Out para construir el modelo de mejor desempeño.
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1) vector = TfidfVectorizer()
x_train = vector.fit_transform(x_train)
x_test = vector.transform(x_test)
model_lr_tf=LogisticRegression() model_lr_tf.fit(x_train,y_train)
y_pred=model_lr_tf.predict(x_test)
# Model Evaluation conf=confusion_matrix(y_test,y_pred)
acc_lr=accuracy_score(y_test,y_pred)
f1_lr=f1_score(y_test,y_pred,average='weighted') print('Accuracy: ',acc_lr)
print('F1 Score: ',f1_lr)
print(10*'===========')
print('Confusion Matrix: n',conf)
print(10*'===========')
print('Classification Report: n',classification_report(y_test,y_pred))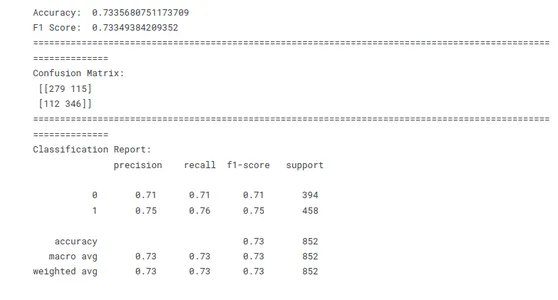
Nubes de palabras de palabras acentuadas y no acentuadas
El conjunto de datos contiene mensajes de texto o documentos que están etiquetados como estresados o no estresados. El código recorre las dos etiquetas para crear una nube de palabras para cada etiqueta usando la biblioteca de WordCloud y muestra la visualización de la nube de palabras. Cada nube de palabras representa las palabras más utilizadas en la categoría respectiva, con palabras más grandes que indican una mayor frecuencia. La elección del mapa de colores ('invierno', 'otoño', 'magma', 'Viridis', 'plasma') determina el esquema de color de las nubes de palabras. Las visualizaciones resultantes proporcionan una representación concisa de las palabras más frecuentes asociadas con mensajes o documentos acentuados y no acentuados.
Aquí hay nubes de palabras que representan palabras acentuadas y no acentuadas comúnmente asociadas con la detección de estrés:
for label, cmap in zip([0,1], ['winter', 'autumn', 'magma', 'viridis', 'plasma']): text = stress.query('label == @label')['text'].str.cat(sep=' ') plt.figure(figsize=(12, 9)) wc = WordCloud(width=1000, height=600, background_color="#f8f8f8", colormap=cmap) wc.generate_from_text(text) plt.imshow(wc) plt.axis("off") plt.title(f"Words Commonly Used in ${label}$ Messages", size=20) plt.show()

Predicción
Los nuevos datos de entrada se procesan previamente y las características se extraen para que coincidan con las expectativas del modelo. La función de predicción se usa luego para generar predicciones basadas en las características extraídas. Finalmente, las predicciones se imprimen o utilizan según sea necesario para un análisis posterior o para la toma de decisiones.
data=["""I don't have the ability to cope with it anymore. I'm trying, but a lot of things are triggering me, and I'm shutting down at work, just finding the place I feel safest, and staying there for an hour or two until I feel like I can do something again. I'm tired of watching my back, tired of traveling to places I don't feel safe, tired of reliving that moment, tired of being triggered, tired of the stress, tired of anxiety and knots in my stomach, tired of irrational thought when triggered, tired of irrational paranoia. I'm exhausted and need a break, but know it won't be enough until I journey the long road through therapy. I'm not suicidal at all, just wishing this pain and misery would end, to have my life back again."""] data=vector.transform(data)
model_lr_tf.predict(data)
data=["""In case this is the first time you're reading this post... We are looking for people who are willing to complete some online questionnaires about employment and well-being which we hope will help us to improve services for assisting people with mental health difficulties to obtain and retain employment. We are developing an employment questionnaire for people with personality disorders; however we are looking for people from all backgrounds to complete it. That means you do not need to have a diagnosis of personality disorder – you just need to have an interest in completing the online questionnaires. The questionnaires will only take about 10 minutes to complete online. For your participation, we’ll donate £1 on your behalf to a mental health charity (Young Minds: Child & Adolescent Mental Health, Mental Health Foundation, or Rethink)"""] data=vector.transform(data)
model_lr_tf.predict(data)
Conclusión
La aplicación de técnicas de aprendizaje automático para predecir los niveles de estrés proporciona información personalizada para el bienestar mental. Mediante el análisis de una variedad de factores, como mediciones numéricas (presión arterial, frecuencia cardíaca) y características categóricas (p. ej., género, ocupación), los modelos de aprendizaje automático pueden aprender patrones y hacer predicciones sobre un nivel de estrés individual. Con la capacidad de detectar y monitorear con precisión los niveles de estrés, el aprendizaje automático contribuye al desarrollo de estrategias e intervenciones proactivas para administrar y mejorar el bienestar mental.
Exploramos los conocimientos del uso del aprendizaje automático en la predicción del estrés y su potencial para revolucionar nuestro enfoque para abordar este problema crítico.
- Predicciones precisas: Los algoritmos de aprendizaje automático analizan grandes cantidades de datos históricos para predecir con precisión las ocurrencias de estrés, proporcionando información y pronósticos valiosos.
- Detección temprana: El aprendizaje automático puede detectar señales de advertencia desde el principio, lo que permite medidas proactivas y apoyo oportuno en áreas vulnerables.
- Planificación mejorada y asignación de recursos: El aprendizaje automático permite pronosticar los puntos de acceso y las intensidades de las calles, optimizando la asignación de recursos, como servicios de emergencia e instalaciones médicas.
- Seguridad pública mejorada: Las alertas y advertencias oportunas emitidas a través de predicciones de aprendizaje automático permiten a las personas tomar las precauciones necesarias, reduciendo el impacto de la calle y mejorando la seguridad pública.
En conclusión, este análisis de predicción de estrés proporciona información valiosa sobre los niveles de estrés y su predicción mediante el aprendizaje automático. Utilice los hallazgos para desarrollar herramientas e intervenciones para el manejo del estrés, promoviendo el bienestar general y una mejor calidad de vida.
Preguntas frecuentes
A: 1 Evaluación objetiva: Proporciona un enfoque objetivo y basado en datos para evaluar los niveles de estrés, eliminando posibles sesgos que pueden surgir en las evaluaciones subjetivas.
2. Escalabilidad: Los algoritmos de aprendizaje automático pueden procesar grandes volúmenes de datos de texto de manera eficiente, lo que los hace escalables para analizar una amplia gama de expresiones textuales.
3. Monitoreo en tiempo real: Al automatizar la detección de estrés, permite el monitoreo en tiempo real de los niveles de estrés, lo que permite intervenciones y apoyo oportunos.
4. Perspectivas e investigación: Puede descubrir ideas y tendencias relacionadas con el estrés, contribuyendo a la comprensión de los desencadenantes del estrés, los impactos y las posibles intervenciones.
A: 1 Publicaciones en redes sociales: contenido textual de plataformas como Twitter, Facebook o foros en línea donde las personas expresan sus pensamientos y emociones.
2. Registros de chat: datos conversacionales de aplicaciones de mensajería, sistemas de soporte en línea o chatbots de salud mental.
3. Encuestas o cuestionarios en línea: Respuestas textuales a preguntas relacionadas con el estrés o el bienestar mental.
4. Registros electrónicos de salud: Notas clínicas o narraciones de pacientes que contienen información relevante sobre experiencias relacionadas con el estrés.
R: 1. Las expresiones textuales de estrés pueden variar mucho entre individuos, lo que dificulta capturar todos los indicadores y patrones relevantes.
2. La comprensión contextual es crucial en la detección del estrés, ya que el mismo texto puede leerse de manera diferente según el contexto y el individuo.
3. La adquisición de datos etiquetados para entrenar modelos de aprendizaje automático puede llevar mucho tiempo y recursos, lo que requiere aportes de expertos o juicios subjetivos.
4. Garantizar la privacidad de los datos, la confidencialidad y el manejo ético de la información confidencial sobre salud mental es primordial cuando se trabaja con datos de texto relacionados con el estrés.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/machine-learning-unlocks-insights-for-stress-detection/

