Introducción
Modelos de lenguaje grande (LLM) y la IA generativa representan un avance transformador en la inteligencia artificial y el procesamiento del lenguaje natural. Pueden comprender y generar lenguaje humano y producir contenido como texto, imágenes, audio y datos sintéticos, lo que los hace muy versátiles en diversas aplicaciones. La IA generativa tiene una inmensa importancia en las aplicaciones del mundo real al automatizar y mejorar la creación de contenido, personalizar las experiencias de los usuarios, optimizar los flujos de trabajo y fomentar la creatividad. En esta lectura, nos centraremos en cómo las empresas pueden integrarse con Open LLM al basar las indicaciones de manera efectiva utilizando Enterprise Knowledge Graphs.
OBJETIVOS DE APRENDIZAJE
- Adquiera conocimientos sobre conexión a tierra y construcción rápida mientras interactúa con sistemas LLM/Gen-AI.
- Comprender la relevancia empresarial de Grounding, el valor comercial de la integración con sistemas abiertos Gen-AI con un ejemplo.
- Analizar dos principales soluciones en competencia, gráficos de conocimiento y almacenes de vectores en varios frentes y comprender cuál se adapta y cuándo.
- Estudie un diseño empresarial de muestra de conexión a tierra y construcción rápida, aprovechando gráficos de conocimiento, modelado de datos de aprendizaje y modelado de gráficos en JAVA para un escenario de cliente de recomendación personalizado.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué son los modelos de lenguaje grande?
Un modelo de lenguaje grande es un modelo de inteligencia artificial avanzado entrenado utilizando técnicas de aprendizaje profundo en cantidades masivas de datos no estructurados (texto). Estos modelos son capaces de interactuar con el lenguaje humano, generar texto, imágenes y audio similares a los humanos y realizar diversas procesamiento natural del lenguaje tareas.
Por el contrario, la definición de modelo de lenguaje se refiere a asignar probabilidades a secuencias de palabras basándose en el análisis de corpus de texto. Un modelo de lenguaje puede variar desde simples modelos de n-gramas hasta modelos de redes neuronales más sofisticados. Sin embargo, el término “modelo de lenguaje grande” generalmente se refiere a modelos que utilizan técnicas de aprendizaje profundo y tienen una gran cantidad de parámetros, que pueden oscilar entre millones y miles de millones. Estos modelos pueden capturar patrones complejos en el lenguaje y producir textos a menudo indistinguibles del escrito por humanos.
¿Qué es un aviso?
Un aviso para cualquier LLM o un sistema de inteligencia artificial de chatbot similar es una entrada o mensaje basado en texto que usted proporciona para iniciar una conversación o interacción con la inteligencia artificial. Los LLM son versátiles, están capacitados con una amplia variedad de big data y pueden usarse para diversas tareas; por lo tanto, el contexto, el alcance, la calidad y la claridad de su mensaje influyen significativamente en las respuestas que recibe de los sistemas LLM.
¿Qué es la conexión a tierra/RAG?
Grounding, también conocido como Generación Aumentada de Recuperación (RAG), en el contexto del procesamiento de LLM en lenguaje natural, se refiere a enriquecer el mensaje con contexto, metadatos adicionales y alcance que brindamos a los LLM para mejorar y recuperar respuestas más personalizadas y precisas. Esta conexión ayuda a los sistemas de IA a comprender e interpretar los datos de una manera que se alinee con el alcance y el contexto requeridos. La investigación sobre LLM muestra que la calidad de su respuesta depende de la calidad del mensaje.
Es un concepto fundamental en la IA, ya que cierra la brecha entre los datos sin procesar y la capacidad de la IA para procesar e interpretar esos datos de una manera consistente con la comprensión humana y el contexto específico. Mejora la calidad y confiabilidad de los sistemas de IA y su capacidad para brindar información o respuestas precisas y útiles.
¿Cuáles son los inconvenientes de los LLM?
Los modelos de lenguajes grandes (LLM), como GPT-3, han ganado mucha atención y uso en diversas aplicaciones, pero también presentan varias desventajas o inconvenientes. Algunas de las principales desventajas de los LLM incluyen:
1. Sesgo y equidad: Los LLM a menudo heredan sesgos de los datos de capacitación. Esto puede dar lugar a la generación de contenido sesgado o discriminatorio, que puede reforzar estereotipos dañinos y perpetuar los prejuicios existentes.
2. Alucinaciones: Los LLM no comprenden realmente el contenido que generan; Generan texto basado en patrones en los datos de entrenamiento. Esto significa que pueden producir información objetivamente incorrecta o sin sentido, lo que los hace inadecuados para aplicaciones críticas como diagnóstico médico o asesoramiento legal.
3. Recursos Computacionales: La formación y ejecución de LLM requiere enormes recursos computacionales, incluido hardware especializado como GPU y TPU. Esto hace que su desarrollo y mantenimiento sean costosos.
4. Privacidad y seguridad de datos: Los LLM pueden generar contenido falso convincente, incluidos texto, imágenes y audio. Esto pone en riesgo la privacidad y la seguridad de los datos, ya que pueden explotarse para crear contenido fraudulento o hacerse pasar por personas.
5. Preocupaciones éticas: El uso de LLM en diversas aplicaciones, como deepfakes o generación automatizada de contenido, plantea cuestiones éticas sobre su potencial de mal uso e impacto en la sociedad.
6. Desafíos regulatorios: El rápido desarrollo de la tecnología LLM ha superado los marcos regulatorios, lo que dificulta el establecimiento de pautas y regulaciones apropiadas para abordar los riesgos y desafíos potenciales asociados con los LLM.
Es importante tener en cuenta que muchas de estas desventajas no son inherentes a los LLM, sino que reflejan cómo se desarrollan, implementan y utilizan. Se están realizando esfuerzos para mitigar estos inconvenientes y hacer que los LLM sean más responsables y beneficiosos para la sociedad. Aquí es donde se pueden aprovechar la conexión a tierra y el enmascaramiento y ser de gran ventaja para las empresas.
Relevancia empresarial de la conexión a tierra
Las empresas prosperan al incorporar modelos de lenguajes grandes (LLM) en sus aplicaciones de misión crítica. Entienden el valor potencial que los LLM podrían beneficiarse en varios dominios. Crear LLM, capacitarlos previamente y perfeccionarlos es bastante costoso y engorroso para ellos. Más bien, podrían utilizar los sistemas abiertos de IA disponibles en la industria para conectar y enmascarar las indicaciones en torno a los casos de uso empresarial.
Por lo tanto, Grounding es una consideración importante para las empresas y es más relevante y útil para ellas tanto para mejorar la calidad de las respuestas como para superar la preocupación por las alucinaciones, la seguridad de los datos y el cumplimiento, ya que puede generar un valor comercial increíble a la vista. LLM disponibles en el mercado para numerosos casos de uso que hoy tienen el desafío de automatizar.
Beneficios para las empresas
Existen varios beneficios para las empresas al implementar la conexión a tierra con LLM:
1. Credibilidad mejorada: Al garantizar que la información y el contenido generado por los LLM se basen en fuentes de datos verificadas, las empresas pueden mejorar la credibilidad de sus comunicaciones, informes y contenido. Esto puede ayudar a generar confianza con los clientes, los clientes y las partes interesadas.
2. Toma de decisiones mejorada: En aplicaciones empresariales, especialmente aquellas relacionadas con el análisis de datos y el soporte de decisiones, el uso de LLM con base de datos puede proporcionar información más confiable. Esto puede conducir a una toma de decisiones mejor informada, lo cual es crucial para la planificación estratégica y el crecimiento empresarial.
3. Cumplimiento de la normativa: Muchas industrias están sujetas a requisitos reglamentarios en materia de precisión y cumplimiento de los datos. La conexión a tierra de datos con LLM puede ayudar a cumplir con estos estándares de cumplimiento, reduciendo el riesgo de problemas legales o regulatorios.
4. Generación de contenido de calidad: Los LLM se utilizan a menudo en la creación de contenido, como marketing, atención al cliente y descripciones de productos. La conexión a tierra de datos garantiza que el contenido generado sea objetivamente exacto, lo que reduce el riesgo de difundir información o alucinaciones falsas o engañosas.
5. Reducción de la desinformación: En una era de noticias falsas y desinformación, la conexión a tierra de datos puede ayudar a las empresas a combatir la difusión de información falsa al garantizar que el contenido que generan o comparten se basa en fuentes de datos validadas.
6. La satisfacción del cliente: Proporcionar a los clientes información precisa y confiable puede mejorar su satisfacción y confianza en los productos o servicios de una empresa.
7. Mitigación de riesgos: La conexión a tierra de datos puede ayudar a reducir el riesgo de tomar decisiones basadas en información inexacta o incompleta, lo que podría provocar daños financieros o de reputación.
Ejemplo: escenario de recomendación de producto de un cliente
Veamos cómo la conexión a tierra de datos podría ayudar en un caso de uso empresarial utilizando openAI chatGPT
Indicaciones básicas
Generate a short email adding coupons on recommended products to customer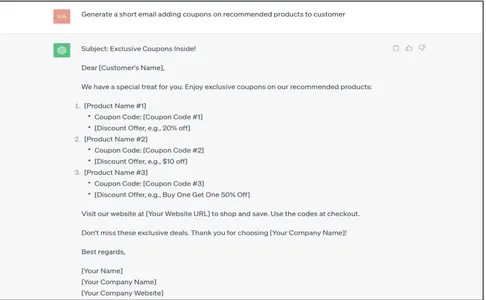
La respuesta generada por ChatGPT es muy genérica, no contextualizada y cruda. Esto debe actualizarse/asignarse manualmente con los datos correctos del cliente empresarial, lo cual es costoso. Veamos cómo se podría automatizar esto con técnicas de conexión a tierra de datos.
Digamos, supongamos que la empresa ya posee los datos de los clientes empresariales y un sistema de recomendación inteligente que puede generar cupones y recomendaciones para los clientes; Es muy posible que podamos fundamentar el mensaje anterior enriqueciéndolo con los metadatos correctos para que el texto del correo electrónico generado desde chatGPT sea exactamente igual a como queremos que sea y pueda automatizarse para enviar un correo electrónico al cliente sin intervención manual.
Supongamos que nuestro motor de conexión a tierra obtendrá los metadatos de enriquecimiento correctos de los datos del cliente y actualizará el siguiente mensaje. Veamos cómo sería la respuesta de ChatGPT para el mensaje de conexión a tierra.
Aviso conectado a tierra
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off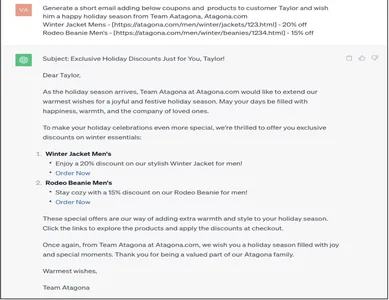
La respuesta generada con el mensaje de tierra es exactamente cómo la empresa desearía que se notificara al cliente. Los datos enriquecidos de los clientes incorporados en una respuesta de correo electrónico de Gen AI es una automatización que sería extraordinaria para ampliar y sostener las empresas.
Enterprise LLM Soluciones de puesta a tierra para sistemas de software
Hay varias formas de conectar los datos a los sistemas empresariales, y se podría utilizar una combinación de estas técnicas para una conexión efectiva de los datos y una generación rápida específica para el caso de uso. Los dos principales contendientes como posibles soluciones para implementar la generación aumentada de recuperación (conexión a tierra) son
- Datos de aplicación|Gráficos de conocimiento
- Incorporaciones de vectores y búsqueda semántica.
El uso de estas soluciones dependerá del caso de uso y de la base que desee aplicar. Por ejemplo, las respuestas proporcionadas por los almacenes vectoriales pueden ser inexactas y vagas, mientras que los gráficos de conocimiento arrojarían resultados precisos, exactos y almacenados en un formato legible por humanos.
Algunas otras estrategias que podrían combinarse además de las anteriores podrían ser
- Vinculación a API externas, motores de búsqueda
- Sistemas de cumplimiento y enmascaramiento de datos
- Integración con almacenes de datos internos y sistemas.
- Unificación de datos en tiempo real de múltiples fuentes
En este blog, veamos un diseño de software de muestra sobre cómo lograr gráficos de datos de aplicaciones empresariales.
Gráficos de conocimiento empresarial
Un gráfico de conocimiento puede representar información semántica de varias entidades y relaciones entre ellas. En el mundo empresarial, almacenan conocimientos sobre clientes, productos y más. Los gráficos de clientes empresariales serían una herramienta poderosa para fundamentar los datos de manera efectiva y generar indicaciones enriquecidas. Los gráficos de conocimiento permiten la búsqueda basada en gráficos, lo que permite a los usuarios explorar información a través de conceptos y entidades vinculados, lo que puede conducir a resultados de búsqueda más precisos y diversos.
Comparación con bases de datos vectoriales
La elección de la solución de conexión a tierra dependería de cada caso de uso. Sin embargo, existen múltiples ventajas con los gráficos sobre los vectores como
| Criterios | Conexión a tierra del gráfico | Conexión a tierra vectorial |
| Consultas analíticas | Los gráficos de datos son adecuados para datos estructurados y consultas analíticas, y brindan resultados precisos debido a su diseño de gráfico abstracto. | Es posible que los almacenes de datos vectoriales no funcionen tan bien con consultas analíticas, ya que operan principalmente con datos no estructurados, búsqueda semántica con incrustaciones de vectores y dependen de la puntuación de similitud. |
| Precisión y credibilidad | Los gráficos de conocimiento utilizan nodos y relaciones para almacenar datos y devuelven solo la información presente. Evitan resultados incompletos o irrelevantes. | Las bases de datos vectoriales pueden proporcionar resultados incompletos o irrelevantes, principalmente debido a su dependencia de la puntuación de similitud y límites de resultados predefinidos. |
| Corregir alucinaciones | Los gráficos de conocimiento son transparentes con una representación de datos legible por humanos. Ayudan a identificar y corregir información errónea, rastrear el camino de la consulta y realizar correcciones, lo que mejora la precisión del LLM (modelo de lenguaje grande). | Las bases de datos vectoriales a menudo se consideran cajas negras que no se almacenan en un formato legible y pueden no facilitar la identificación y corrección de información errónea. |
| Seguridad y gobernanza | Los gráficos de conocimiento ofrecen un mejor control sobre la generación de datos, la gobernanza y el cumplimiento, incluidas regulaciones como GDPR. | Las bases de datos de vectores pueden enfrentar desafíos al imponer restricciones y gobernanza debido a su naturaleza poco transparente. |
Diseño de alto nivel
Veamos en un nivel muy alto cómo el sistema puede buscar una empresa que utilice gráficos de conocimiento y LLM abiertos para la conexión a tierra.
La capa base es donde se almacenan los datos y metadatos de los clientes empresariales en varias bases de datos, almacenes de datos y lagos de datos. Puede haber un servicio que cree gráficos de conocimiento de datos a partir de estos datos y los almacene en una base de datos de gráficos. Puede haber numerosos microservicios (servicios empresariales) en un mundo nativo de nube distribuida que interactuarían con estos almacenes de datos. Por encima de estos servicios podrían haber varias aplicaciones que aprovecharían la infraestructura subyacente.
Las aplicaciones pueden tener numerosos casos de uso para incorporar IA en sus escenarios o flujos de clientes automatizados inteligentes, lo que requiere interactuar con sistemas de IA internos y externos. En el caso de escenarios de IA generativa, tomemos un ejemplo simple de un flujo de trabajo en el que una empresa quiere dirigirse a los clientes a través de un correo electrónico ofreciendo algunos descuentos en productos recomendados personalizados durante una temporada navideña. Pueden lograrlo con una automatización de primera clase, aprovechando la IA de manera más efectiva.
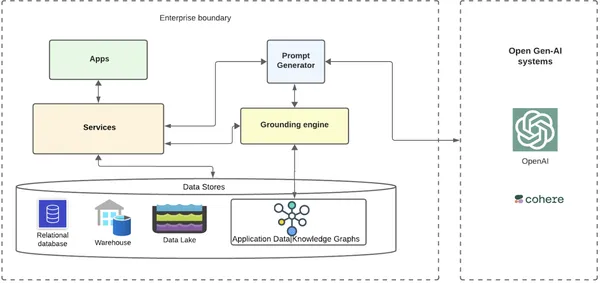
El flujo de trabajo
- El flujo de trabajo que desea enviar un correo electrónico puede contar con la ayuda de los sistemas abiertos Gen-AI enviando un mensaje fundamentado con datos contextualizados del cliente.
- La aplicación de flujo de trabajo enviaría una solicitud a su servicio backend para obtener el texto del correo electrónico aprovechando los sistemas GenAI.
- El servicio backend enrutaría el servicio a un servicio de generador rápido, que lo encamina a un motor en tierra.
- El motor de conexión a tierra toma todos los metadatos del cliente de uno de sus servicios y recupera el gráfico de conocimiento de los datos del cliente.
- El motor de conexión a tierra recorre el gráfico a través de los nodos y las relaciones relevantes extraen la información final requerida y la envía de regreso al generador de mensajes.
- El generador de mensajes agrega los datos fundamentados con una plantilla preexistente para el caso de uso y envía el mensaje fundamentado a los sistemas abiertos de IA con los que la empresa elige integrarse (por ejemplo, OpenAI/Cohere).
- Los sistemas abiertos GenAI devuelven una respuesta mucho más relevante y contextualizada a la empresa, enviada al cliente por correo electrónico.
Dividamos esto en dos partes y comprendamos en detalle:
1. Generación de gráficos de conocimiento del cliente
El siguiente diseño se adapta al ejemplo anterior; el modelado se puede realizar de varias maneras según los requisitos.
Modelado de datos: Supongamos que tenemos varias tablas modeladas como nodos en un gráfico y unidas entre tablas como relaciones entre nodos. Para el ejemplo anterior, necesitamos
- una tabla que contiene los datos del Cliente,
- una tabla que contiene los datos del producto,
- una tabla que contiene los datos de CustomerInterests(Clicks) para recomendaciones personalizadas
- una tabla que contiene los datos de ProductDiscounts
Es responsabilidad de la empresa incorporar todos estos datos de múltiples fuentes de datos y actualizarlos periódicamente para llegar a los clientes de manera efectiva.
Veamos cómo se pueden modelar estas tablas y cómo se pueden transformar en un gráfico de clientes.
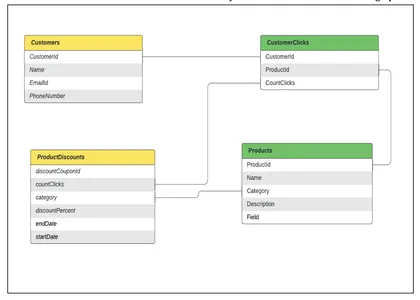
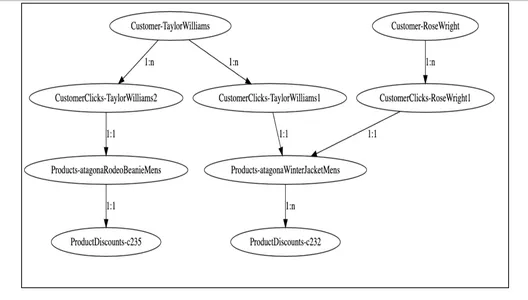
2. Modelado de gráficos
En el visualizador de gráficos anterior, podemos ver cómo los nodos de clientes se relacionan con varios productos en función de los datos de participación de sus clics y, además, con los nodos de descuentos. Es fácil para el servicio de conexión a tierra consultar estos gráficos de clientes, atravesar estos nodos a través de relaciones y obtener la información requerida sobre los descuentos elegibles para los respectivos clientes.
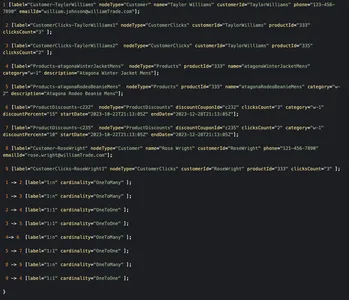
Un ejemplo de nodo gráfico y relación de POJO JAVA para lo anterior podría ser similar al siguiente
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Un ejemplo de gráfico sin procesar en este escenario podría verse como a continuación
Recorrer el gráfico desde el nodo del cliente 'Taylor Williams' nos resolvería el problema y obtendríamos las recomendaciones de productos correctas y los descuentos elegibles.
3. Tiendas Graph populares en la industria
Existen numerosas tiendas de gráficos disponibles en el mercado que pueden adaptarse a las arquitecturas empresariales. Neo4j, TigerGraph, Amazon Neptune y OrientDB se adoptan ampliamente como bases de datos de gráficos.
Presentamos el nuevo paradigma de Graph Data Lakes, que permite consultas de gráficos sobre datos tabulares (datos estructurados en lagos, almacenes y casas de lago). Esto se logra con las nuevas soluciones que se enumeran a continuación, sin la necesidad de hidratar o persistir los datos en almacenes de datos de gráficos, aprovechando Zero-ETL.
- PuppyGraph (lago de datos de gráficos)
- Timbr.ai
Cumplimiento y consideraciones éticas
Protección de Datos: Las empresas deben ser responsables de almacenar y utilizar los datos de los clientes respetando el RGPD y otros requisitos de PII. Los datos almacenados deben controlarse y limpiarse antes de procesarlos y reutilizarlos para obtener información valiosa o aplicar IA.
Alucinaciones y reconciliación: Las empresas también pueden agregar servicios de conciliación que identificarían información errónea en los datos, rastrearían el camino de la consulta y le harían correcciones, lo que puede ayudar a mejorar la precisión del LLM. Con los gráficos de conocimiento, dado que los datos almacenados son transparentes y legibles por humanos, esto debería ser relativamente fácil de lograr.
Políticas de retención restrictivas: Para cumplir con la protección de datos y evitar el uso indebido de los datos de los clientes al interactuar con sistemas LLM abiertos, es muy importante tener políticas de retención cero para que los sistemas externos con los que interactúan las empresas no retengan los datos solicitados para ningún propósito analítico o comercial adicional.
Conclusión
En conclusión, los modelos de lenguaje grande (LLM) representan un avance notable en la inteligencia artificial y el procesamiento del lenguaje natural. Pueden transformar diversas industrias y aplicaciones, desde la comprensión y generación del lenguaje natural hasta ayudar con tareas complejas. Sin embargo, el éxito y el uso responsable de los LLM requieren una base y una base sólidas en varias áreas clave.
Puntos clave
- Las empresas pueden beneficiarse enormemente de una conexión a tierra y de indicaciones efectivas mientras utilizan LLM para diversos escenarios.
- Los gráficos de conocimiento y las tiendas de vectores son soluciones de conexión a tierra populares y la elección de una dependerá del propósito de la solución.
- Los gráficos de conocimiento pueden tener información más precisa y confiable que los almacenes de vectores, lo que brinda una ventaja para los casos de uso empresarial sin tener que agregar capas adicionales de seguridad y cumplimiento.
- Transforme el modelado de datos tradicional con entidades y relaciones en gráficos de conocimiento con nodos y aristas.
- Integre los gráficos de conocimiento empresarial con varias fuentes de datos con empresas de almacenamiento de big data existentes.
- Los gráficos de conocimiento son ideales para consultas analíticas. Los lagos de datos de gráficos permiten consultar datos tabulares como gráficos en el almacenamiento de datos empresariales.
Preguntas frecuentes
R. LLM es un algoritmo de inteligencia artificial que utiliza técnicas de DL y conjuntos de datos enormemente grandes para comprender, resumir, generar y predecir contenido nuevo.
R. Un gráfico de datos de aplicación es una estructura de datos que almacena datos en forma de nodos y bordes. Modelelos como las relaciones entre diferentes nodos de datos.
R. Una base de datos vectorial almacena y administra datos no estructurados como texto, audio y video. Destaca en la indexación y recuperación rápidas de aplicaciones como motores de recomendación, aprendizaje automático y Gen-AI.
R. En un almacén de vectores, las incrustaciones son representaciones numéricas de objetos, palabras o puntos de datos en un espacio vectorial de alta dimensión. Estas incorporaciones capturan relaciones semánticas y similitudes entre elementos, lo que permite un análisis de datos eficiente, búsquedas de similitudes y tareas de aprendizaje automático.
R. Los datos estructurados están bien organizados con tablas y esquemas definidos. Los datos no estructurados, como texto, imágenes, audio o vídeo, son más difíciles de analizar debido a su falta de formato.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/

