Los modelos de lenguaje grande (LLM) son modelos de aprendizaje profundo entrenados para producir texto. Con esta impresionante capacidad, los LLM se han convertido en la columna vertebral del procesamiento del lenguaje natural (PLN) moderno. Tradicionalmente, son capacitados previamente por instituciones académicas y grandes empresas tecnológicas como OpenAI, Microsoft y NVIDIA. La mayoría de ellos se ponen a disposición del público. Este enfoque plug-and-play es un paso importante hacia la adopción de IA a gran escala: en lugar de gastar grandes recursos en la capacitación de modelos con conocimientos lingüísticos generales, las empresas ahora pueden concentrarse en ajustar los LLM existentes para casos de uso específicos.
Sin embargo, elegir el modelo correcto para su aplicación puede ser complicado. Los usuarios y otras partes interesadas tienen que abrirse camino a través de un panorama vibrante de modelos lingüísticos e innovaciones relacionadas. Estas mejoras abordan diferentes componentes del modelo de lenguaje, incluidos sus datos de entrenamiento, el objetivo previo al entrenamiento, la arquitectura y el enfoque de ajuste fino; podría escribir un libro sobre cada uno de estos aspectos. Además de toda esta investigación, el zumbido de marketing y el aura intrigante de la Inteligencia General Artificial en torno a modelos de lenguaje enorme ofuscan las cosas aún más.
Si este contenido educativo en profundidad es útil para usted, suscríbase a nuestra lista de correo de IA ser alertado cuando lancemos nuevo material.
En este artículo, explico los principales conceptos y principios detrás de los LLM. El objetivo es proporcionar a las partes interesadas no técnicas una comprensión intuitiva, así como un lenguaje para una interacción eficiente con desarrolladores y expertos en IA. Para una cobertura más amplia, el artículo incluye análisis basados en una gran cantidad de publicaciones relacionadas con la PNL. Si bien no profundizaremos en los detalles matemáticos de los modelos de lenguaje, estos se pueden recuperar fácilmente de las referencias.
El artículo está estructurado de la siguiente manera: primero, sitúo los modelos de lenguaje en el contexto del panorama en evolución de la PNL. La segunda sección explica cómo se construyen y entrenan previamente los LLM. Finalmente, describo el proceso de ajuste fino y brindo alguna guía sobre la selección del modelo.
El mundo de los modelos lingüísticos
Cerrando la brecha hombre-máquina
El lenguaje es una habilidad fascinante de la mente humana: es un protocolo universal para comunicar nuestro rico conocimiento del mundo, y también aspectos más subjetivos como intenciones, opiniones y emociones. En la historia de la IA, ha habido múltiples oleadas de investigación para aproximar ("modelar") el lenguaje humano con medios matemáticos. Antes de la era del aprendizaje profundo, las representaciones se basaban en conceptos algebraicos y probabilísticos simples, como representaciones únicas de palabras, modelos de probabilidad secuencial y estructuras recursivas. Con la evolución del Deep Learning en los últimos años, las representaciones lingüísticas han aumentado en precisión, complejidad y expresividad.
En 2018, BERT se presentó como el primer LLM sobre la base de la nueva arquitectura Transformer. Desde entonces, los LLM basados en Transformer han cobrado un gran impulso. El modelado del lenguaje es especialmente atractivo debido a su utilidad universal. Si bien muchas tareas de PNL del mundo real, como el análisis de sentimientos, la recuperación de información y la extracción de información, no necesitan generar lenguaje, se supone que un modelo que produce lenguaje también tiene las habilidades para resolver una variedad de desafíos lingüísticos más especializados.
El tamaño importa
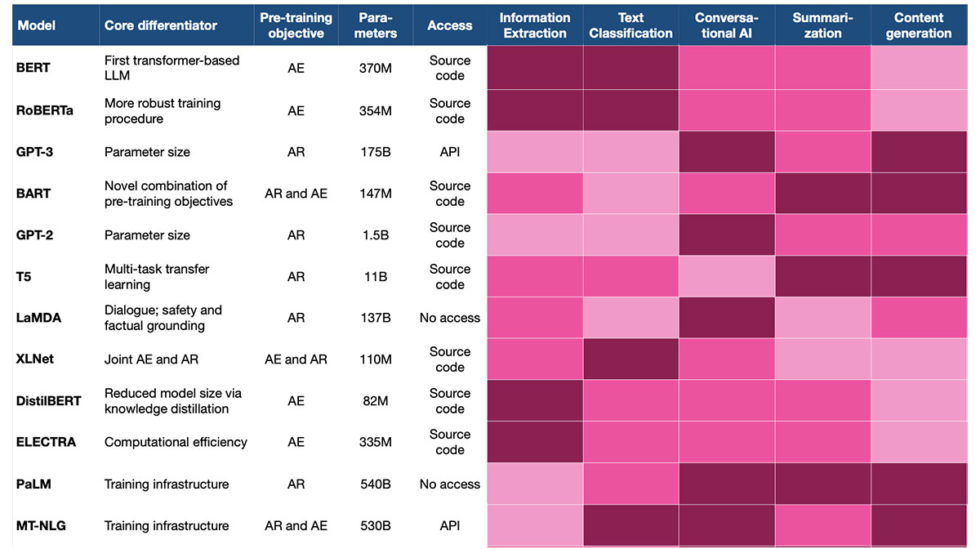
El aprendizaje ocurre en función de parámetros, variables que se optimizan durante el proceso de capacitación para lograr la mejor calidad de predicción. A medida que aumenta el número de parámetros, el modelo puede adquirir un conocimiento más granular y mejorar sus predicciones. Desde la introducción de los primeros LLM en 2017-2018, vimos una explosión exponencial en el tamaño de los parámetros, mientras que el innovador BERT se entrenó con parámetros de 340M, Megatron-Turing NLG, un modelo lanzado en 2022, se entrenó con parámetros de 530B, más de aumento de mil veces.
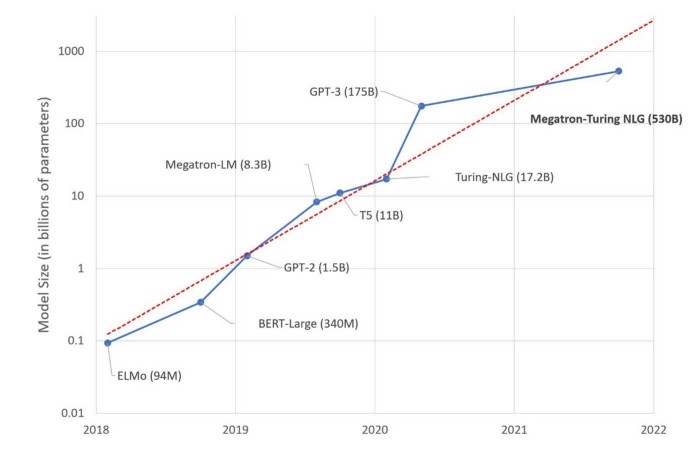
Por lo tanto, la corriente principal sigue cautivando al público con una cantidad cada vez mayor de parámetros. Sin embargo, ha habido voces críticas que señalan que el rendimiento del modelo no aumenta al mismo ritmo que el tamaño del modelo. Por otro lado, la formación previa de modelos puede dejar una huella de carbono considerable. Los esfuerzos de reducción han contrarrestado el enfoque de fuerza bruta para hacer que el progreso en el modelado del lenguaje sea más sostenible.
La vida de un modelo de lenguaje
El panorama LLM es competitivo y las innovaciones son de corta duración. El siguiente gráfico muestra los 15 LLM más populares en el período 2018–2022, junto con su participación en el tiempo:
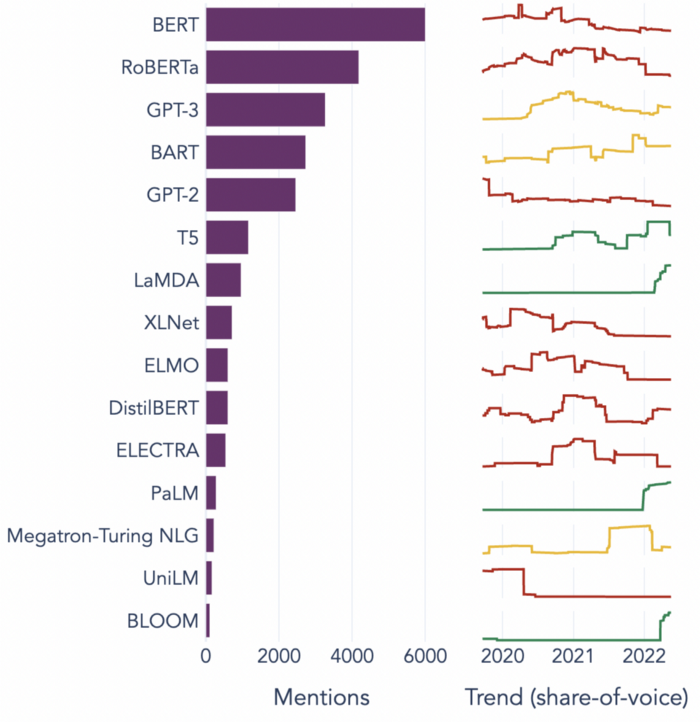
Podemos ver que la mayoría de los modelos pierden popularidad después de un tiempo relativamente corto. Para mantenerse a la vanguardia, los usuarios deben monitorear las innovaciones actuales y evaluar si valdría la pena una actualización.
La mayoría de los LLM siguen un ciclo de vida similar: primero, en el "ascendente", el modelo se entrena previamente. Debido a los estrictos requisitos en cuanto al tamaño y la computación de los datos, es principalmente un privilegio de las grandes empresas tecnológicas y universidades. Recientemente, también ha habido algunos esfuerzos de colaboración (por ejemplo, el Taller de BigScience) para el avance conjunto del campo LLM. Un puñado de nuevas empresas bien financiadas, como Cohere y AI21 Labs, también ofrecen LLM precapacitados.
Después del lanzamiento, los desarrolladores y las empresas centrados en las aplicaciones adoptan y despliegan el modelo en el nivel "descendente". En esta etapa, la mayoría de los modelos requieren un paso de ajuste adicional para tareas y dominios específicos. Otros, como GPT-3, son más convenientes porque pueden aprender una variedad de tareas lingüísticas directamente durante la predicción (predicción de cero o pocos intentos).
Finalmente, el tiempo llama a la puerta y aparece un mejor modelo a la vuelta de la esquina, ya sea con una cantidad aún mayor de parámetros, un uso más eficiente del hardware o una mejora más fundamental en el modelado del lenguaje humano. Los modelos que generaron innovaciones sustanciales pueden dar lugar a familias completas de modelos. Por ejemplo, BERT sigue vivo en BERT-QA, DistilBERT y Roberta, que se basan en la arquitectura original.
En las próximas secciones, veremos las dos primeras fases de este ciclo de vida: la capacitación previa y el ajuste para la implementación.
Preformación: cómo nacen los LLM
La mayoría de los equipos y practicantes de PNL no participarán en la capacitación previa de los LLM, sino en su puesta a punto y despliegue. Sin embargo, para elegir y usar con éxito un modelo, es importante comprender lo que sucede "debajo del capó". En esta sección, veremos los ingredientes básicos de un LLM:
- Datos de entrenamiento
- Representación de entrada
- Objetivo de pre-entrenamiento
- Modelo de arquitectura (codificador-decodificador)
Cada uno de estos afectará no solo la elección, sino también el ajuste y la implementación de su LLM.
Datos de entrenamiento
Los datos utilizados para la capacitación LLM son principalmente datos de texto que cubren diferentes estilos, como literatura, contenido generado por el usuario y datos de noticias. Después de ver una variedad de diferentes tipos de texto, los modelos resultantes toman conciencia de los detalles finos del lenguaje. Aparte de los datos de texto, el código se usa regularmente como entrada, enseñando al modelo a generar programas válidos y fragmentos de código.
Como era de esperar, la calidad de los datos de entrenamiento tiene un impacto directo en el rendimiento del modelo, y también en el tamaño requerido del modelo. Si es inteligente al preparar los datos de entrenamiento, puede mejorar la calidad del modelo mientras reduce su tamaño. Un ejemplo es el modelo T0, que es 16 veces más pequeño que GPT-3 pero lo supera en una variedad de tareas de referencia. Aquí está el truco: en lugar de usar cualquier texto como datos de entrenamiento, funciona directamente con formulaciones de tareas, lo que hace que su señal de aprendizaje sea mucho más enfocada. La Figura 3 ilustra algunos ejemplos de entrenamiento.

Una nota final sobre los datos de entrenamiento: a menudo escuchamos que los modelos de lenguaje se entrenan sin supervisión. Si bien esto los hace atractivos, es técnicamente incorrecto. En cambio, el texto bien formado ya proporciona las señales de aprendizaje necesarias, ahorrándonos el tedioso proceso de anotación manual de datos. Las etiquetas a predecir corresponden a palabras pasadas y/o futuras en una oración. Por lo tanto, la anotación ocurre automáticamente ya escala, lo que hace posible el progreso relativamente rápido en el campo.
Representación de entrada
Una vez que se ensamblan los datos de entrenamiento, debemos empaquetarlos en un formato que pueda ser digerido por el modelo. Las redes neuronales se alimentan de estructuras algebraicas (vectores y matrices), y la representación algebraica óptima del lenguaje es una búsqueda continua, que va desde simples conjuntos de palabras hasta representaciones que contienen información de contexto altamente diferenciada. Cada nuevo paso confronta a los investigadores con la infinita complejidad del lenguaje natural, exponiendo las limitaciones de la representación actual.
La unidad básica del lenguaje es la palabra. En los inicios de la PNL, esto dio lugar a la ingenua bolsa de palabras Representación que une todas las palabras de un texto, independientemente de su orden. Considere estos dos ejemplos:

En el mundo de la bolsa de palabras, estas oraciones obtendrían exactamente la misma representación ya que consisten en las mismas palabras. Claramente, abarca sólo una pequeña parte de su significado.
Las representaciones secuenciales acomodan información sobre el orden de las palabras. En Deep Learning, el procesamiento de secuencias se implementó originalmente en orden consciente Redes neuronales recurrentes (RNN).[2] Sin embargo, yendo un paso más allá, la estructura subyacente del lenguaje no es puramente secuencial sino jerárquica. En otras palabras, no estamos hablando de listas, sino de árboles. Las palabras que están más separadas pueden tener lazos sintácticos y semánticos más fuertes que las palabras vecinas. Considere el siguiente ejemplo:

Aquí, aquí se refiere a la niña. Cuando un RNN llega al final de la oración y finalmente ve aquí, su memoria del comienzo de la oración podría estar ya desvaneciéndose, por lo que no le permitiría recuperar esta relación.
Para resolver estas dependencias a larga distancia, se propusieron estructuras neuronales más complejas para construir una memoria más diferenciada del contexto. La idea es mantener en la memoria las palabras que son relevantes para futuras predicciones mientras se olvidan las otras palabras. Esta fue la contribución de las células de memoria a largo y corto plazo (LSTM)[3] y las unidades recurrentes cerradas (GRU)[4]. Sin embargo, estos modelos no se optimizan para predecir posiciones específicas, sino para un contexto futuro genérico. Además, debido a su estructura compleja, son incluso más lentos de entrenar que los RNN tradicionales.
Finalmente, se ha acabado con la recurrencia y se ha propuesto la mecanismo de atención, como se incorpora en el transformador arquitectura.[5] La atención permite que el modelo se enfoque de un lado a otro entre diferentes palabras durante la predicción. Cada palabra se pondera según su relevancia para la posición específica que se va a predecir. Para la oración anterior, una vez que el modelo alcanza la posición de aquí, niña tendrá un peso mayor que at, a pesar de que está mucho más lejos en el orden lineal.
Hasta la fecha, el mecanismo de atención se acerca más al funcionamiento biológico del cerebro humano durante el procesamiento de la información. Los estudios han demostrado que la atención aprende estructuras sintácticas jerárquicas, incl. una gama de fenómenos sintácticos complejos (cf. Introducción a BERTology y los documentos a los que se hace referencia). También permite el cálculo paralelo y, por lo tanto, un entrenamiento más rápido y eficiente.
Objetivos de pre-entrenamiento
Con la representación de datos de entrenamiento adecuada, nuestro modelo puede comenzar a aprender. Hay tres objetivos genéricos que se utilizan para los modelos de lenguaje de pre-entrenamiento: transducción de secuencia a secuencia, autorregresión y autocodificación. Todos ellos requieren que el modelo domine amplios conocimientos lingüísticos.
La tarea original abordada por la arquitectura de codificador-decodificador, así como el modelo de Transformador es transducción de secuencia a secuencia: una secuencia se transduce a una secuencia en un marco de representación diferente. La tarea clásica de secuencia a secuencia es la traducción automática, pero otras tareas como el resumen se formulan con frecuencia de esta manera. Tenga en cuenta que la secuencia de destino no es necesariamente texto; también pueden ser otros datos no estructurados, como imágenes, así como datos estructurados, como lenguajes de programación. Un ejemplo de LLM de secuencia a secuencia es la familia BART.
La segunda tarea es autorregresión, que también es el objetivo de modelado del lenguaje original. En la autorregresión, el modelo aprende a predecir la siguiente salida (token) en función de los tokens anteriores. La señal de aprendizaje está restringida por la unidireccionalidad de la empresa: el modelo solo puede usar información de la derecha o de la izquierda del token predicho. Esta es una limitación importante ya que las palabras pueden depender tanto de posiciones pasadas como futuras. Como ejemplo, considere cómo el verbo escrito impacta la siguiente oración en ambas direcciones:

Aquí, la posición de está restringida a algo que se puede escribir, mientras que la posición de estudiante está restringida a un ser humano o, en todo caso, a otra entidad inteligente capaz de escribir.
Muchos de los LLM que aparecen en los titulares de hoy son autorregresivos, incl. la familia GPT, PaLM y BLOOM.
La tercera tarea, la codificación automática, resuelve el problema de la unidireccionalidad. La codificación automática es muy similar al aprendizaje de incrustaciones de palabras clásicas.[6] En primer lugar, corrompemos los datos de entrenamiento ocultando una determinada parte de los tokens, normalmente entre un 10 y un 20 %, en la entrada. Luego, el modelo aprende a reconstruir las entradas correctas en función del contexto circundante, teniendo en cuenta tanto los tokens anteriores como los siguientes. El ejemplo típico de codificadores automáticos es la familia BERT, donde BERT significa Bidireccional Representaciones de codificadores de transformadores.
Modelo de arquitectura (codificador-decodificador)
Los componentes básicos de un modelo de lenguaje son el codificador y el decodificador. El codificador transforma la entrada original en una representación algebraica de alta dimensión, también llamada vector "oculto". Espera un momento, ¿oculto? Bueno, en realidad no hay grandes secretos en este punto. Por supuesto, puede mirar esta representación, pero un vector extenso de números no transmitirá nada significativo a un ser humano. Se necesita la inteligencia matemática de nuestro modelo para manejarlo. El decodificador reproduce la representación oculta en una forma inteligible, como otro lenguaje, código de programación, una imagen, etc.

La arquitectura de codificador-decodificador se introdujo originalmente para redes neuronales recurrentes. Desde la introducción del modelo Transformer basado en la atención, la recurrencia tradicional ha perdido su popularidad, mientras que la idea del codificador-descodificador sigue viva. La mayoría de las tareas de comprensión del lenguaje natural (NLU) se basan en el codificador, mientras que las tareas de generación del lenguaje natural (NLG) necesitan el decodificador y la transducción de secuencia a secuencia requiere ambos componentes.
No entraremos en los detalles de la arquitectura del Transformador y el mecanismo de atención aquí. Para aquellos que quieren dominar los detalles, prepárense para pasar una buena cantidad de tiempo para entenderlo. Más allá del artículo original, [7] y [8] brindan excelentes explicaciones. Para una introducción ligera, recomiendo las secciones correspondientes en Andrew Ng's curso de modelos de secuencias.
Uso de modelos de lenguaje en el mundo real
Sintonia FINA
El modelado del lenguaje es una poderosa tarea previa: si tiene un modelo que genera lenguaje con éxito, felicitaciones, es un modelo inteligente. Sin embargo, el valor comercial de tener un modelo lleno de texto aleatorio es limitado. En cambio, la PNL se utiliza principalmente para fines más específicos. tareas posteriores tales como análisis de sentimientos, respuesta a preguntas y extracción de información. Este es el momento de aplicar transferencia de aprendizaje y reutilizar el conocimiento lingüístico existente para desafíos más específicos. Durante el ajuste fino, una parte del modelo se "congela" y el resto se entrena aún más con datos específicos del dominio o la tarea.
El ajuste fino explícito agrega complejidad en el camino hacia la implementación de LLM. También puede llevar a una explosión de modelos, donde cada tarea comercial requiere su propio modelo ajustado, escalando a una variedad de modelos imposible de mantener. Por lo tanto, la gente se ha esforzado por deshacerse del paso de ajuste fino mediante el aprendizaje de pocos o cero disparos (por ejemplo, en GPT-3 [9]). Este aprendizaje ocurre sobre la marcha durante la predicción: el modelo se alimenta con un "mensaje" (una descripción de la tarea y, potencialmente, algunos ejemplos de capacitación) para guiar sus predicciones para futuros ejemplos.
Si bien es mucho más rápido de implementar, el factor de conveniencia del aprendizaje de cero o pocos disparos se ve contrarrestado por su menor calidad de predicción. Además, es necesario acceder a muchos de estos modelos a través de API en la nube. Esta podría ser una buena oportunidad al comienzo de su desarrollo; sin embargo, en etapas más avanzadas, puede convertirse en otra dependencia externa no deseada.
Elegir el modelo adecuado para su tarea posterior
Observar el suministro continuo de nuevos modelos de lenguaje en el mercado de la IA, seleccionar el modelo correcto para una tarea posterior específica y mantenerse sincronizado con el estado del arte puede ser complicado.
Los trabajos de investigación normalmente comparan cada modelo con tareas y conjuntos de datos posteriores específicos. Conjuntos de tareas estandarizados como Super pegamento y BIG-banco permitir una evaluación comparativa unificada frente a una multitud de tareas de PNL y proporcionar una base de comparación. Aún así, debemos tener en cuenta que estas pruebas se preparan en un entorno muy controlado. Actualmente, la capacidad de generalización de los modelos de lenguaje es bastante limitada; por lo tanto, la transferencia a conjuntos de datos de la vida real podría afectar significativamente el rendimiento del modelo. La evaluación y selección de un modelo apropiado debe implicar la experimentación con datos que estén lo más cerca posible de los datos de producción.
Como regla general, el objetivo de preentrenamiento proporciona una pista importante: los modelos autorregresivos funcionan bien en tareas de generación de texto como inteligencia artificial conversacional, respuesta a preguntas y resumen de texto, mientras que los codificadores automáticos sobresalen en la "comprensión" y la estructuración del lenguaje, por ejemplo. para el análisis de sentimientos y diversas tareas de extracción de información. Los modelos destinados al aprendizaje de tiro cero teóricamente pueden realizar todo tipo de tareas siempre que reciban las indicaciones adecuadas; sin embargo, su precisión es generalmente menor que la de los modelos ajustados.
Para hacer las cosas más concretas, el siguiente gráfico muestra cómo las tareas populares de PNL se asocian con modelos de lenguaje prominentes en la literatura de PNL. Las asociaciones se calculan en función de múltiples métricas de similitud y agregación, incl. incrustación de similitud y co-ocurrencia ponderada por distancia. Los pares modelo-tarea con puntajes más altos, como BART/Resumen de texto y LaMDA/IA conversacional, indican un buen ajuste según los datos históricos.
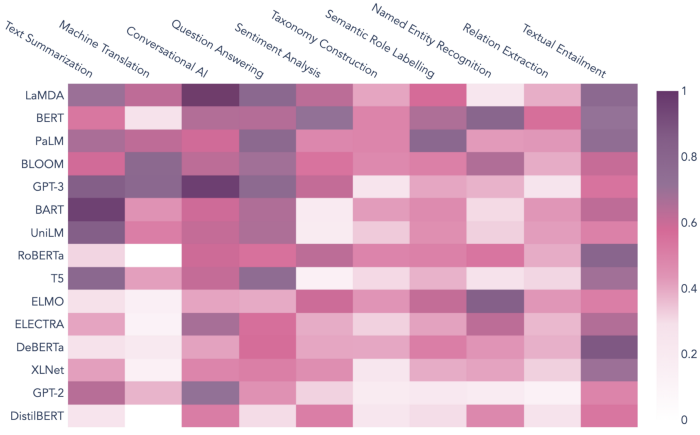
Puntos clave
En este artículo, hemos cubierto las nociones básicas de los LLM y las principales dimensiones en las que se está produciendo la innovación. La siguiente tabla proporciona un resumen de las características clave de los LLM más populares:
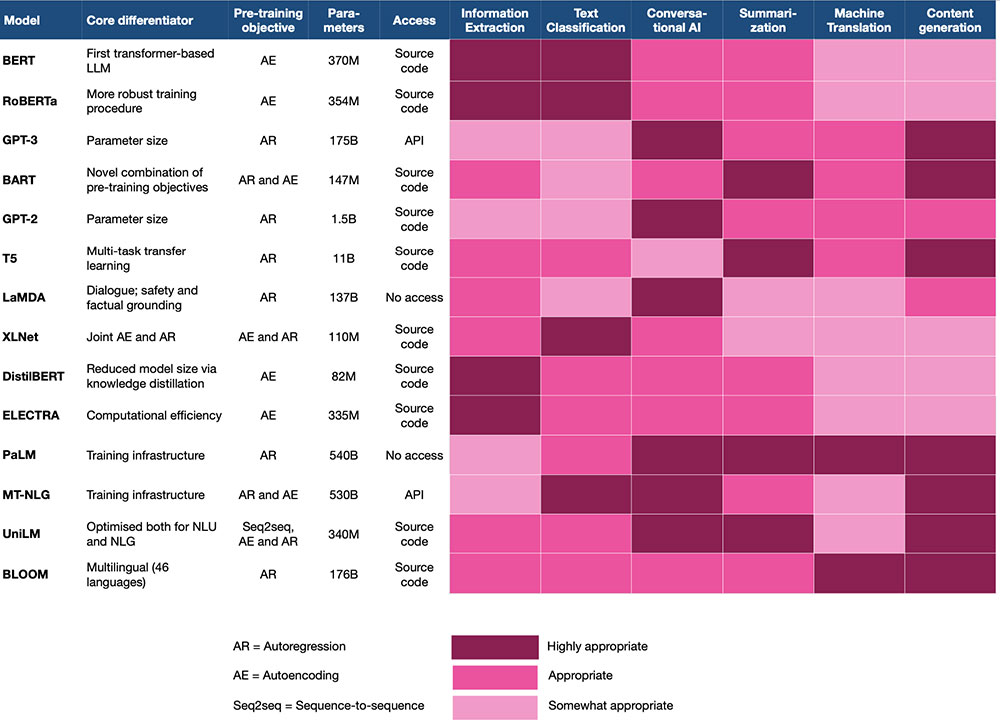
Resumamos algunas pautas generales para la selección e implementación de LLM:
1. Al evaluar modelos potenciales, sea claro acerca de dónde se encuentra en su viaje de IA:
- Al principio, podría ser una buena idea experimentar con LLM implementados a través de API en la nube.
- Una vez que haya encontrado el producto adecuado para el mercado, considere alojar y mantener su modelo de su lado para tener más control y mejorar aún más el rendimiento del modelo para su aplicación.
2. Para alinearse con su tarea posterior, su equipo de IA debe crear una lista corta de modelos basada en los siguientes criterios:
- Resultados de evaluación comparativa en la literatura académica, con un enfoque en su tarea posterior
- Alineación entre el objetivo previo al entrenamiento y la tarea posterior: considere la codificación automática para NLU y la autorregresión para NLG
- Experiencia previa informada para esta combinación modelo-tarea (cf. Figura 5)
4. Los modelos preseleccionados deben probarse luego con su tarea y conjunto de datos del mundo real para tener una primera idea del rendimiento.
5. En la mayoría de los casos, es probable que logre una mejor calidad con un ajuste fino específico. Sin embargo, considere el aprendizaje de pocos o cero disparos si no tiene las habilidades tecnológicas internas o el presupuesto para el ajuste fino, o si necesita cubrir una gran cantidad de tareas.
6. Las innovaciones y tendencias de LLM son de corta duración. Cuando utilice modelos de lenguaje, vigile su ciclo de vida y la actividad general en el panorama LLM y esté atento a las oportunidades para mejorar su juego.
Finalmente, tenga en cuenta las limitaciones de los LLM. Si bien tienen la asombrosa capacidad humana de producir lenguaje, su poder cognitivo general está a galaxias de distancia de nosotros, los humanos. El conocimiento del mundo y la capacidad de razonamiento de estos modelos se limitan estrictamente a la información que encuentran en la superficie del lenguaje. Tampoco pueden situar los hechos en el tiempo y pueden brindarle información desactualizada sin pestañear. Si está creando una aplicación que se basa en la generación de conocimiento actualizado o incluso original, considere combinar su LLM con fuentes adicionales de conocimiento multimodal, estructurado o dinámico.
Referencias
[1] Víctor Sanh et al. 2021. El entrenamiento impulsado por tareas múltiples permite la generalización de tareas de disparo cero. CoRR, abs/2110.08207.
[2] Yoshua Bengio et al. 1994. Aprender dependencias a largo plazo con descenso de gradiente es difícil. Transacciones IEEE en redes neuronales5 (2): 157–166.
[3] Sepp Hochreiter y Jürgen Schmidhuber. 1997. Memoria a corto plazo largo. Computación neuronal, 9 (8): 1735–1780.
[4] Kyung Hyun Cho et al. 2014. Sobre las propiedades de la traducción automática neuronal: enfoques de codificador-decodificador. En Actas de SSST-8, Octavo Taller sobre Sintaxis, Semántica y Estructura en Traducción Estadística, páginas 103–111, Doha, Catar.
[5]Ashish Vaswani et al. 2017. La atención es todo lo que necesitas. In Avances en los sistemas de procesamiento de información neuronal, volumen 30. Curran Associates, Inc.
[6] Tomás Mikolov et al. 2013. Representaciones distribuidas de palabras y frases y su composición.. CoRR, abs/1310.4546.
[7] Jay Jalammar. 2018. El transformador ilustrado.
[8]Alexander Rush et al. 2018. El transformador anotado.
[9] Tom B. Brown y otros. 2020. Los modelos de lenguaje son aprendices de pocas oportunidades. En Actas de la 34ª Conferencia Internacional sobre Sistemas de Procesamiento de Información Neural, NIPS'20, Red Hook, Nueva York, EE. UU. Curran Associates Inc.
[10] Jacob Devlin y otros. 2019. BERT: Pre-entrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje. En Actas de la Conferencia de 2019 del Capítulo de América del Norte de la Asociación de Lingüística Computacional: Tecnologías del lenguaje humano, Volumen 1 (Artículos largos y cortos), páginas 4171–4186, Minneapolis, Minnesota.
[11] Julien Simón 2021. Grandes modelos de lenguaje: ¿una nueva ley de Moore?
[12] Conjunto de datos subyacente: más de 320 2018 artículos sobre IA y PNL publicados entre 2022 y XNUMX en recursos especializados de IA, blogs de tecnología y publicaciones de los principales grupos de expertos en IA.
Todas las imágenes, a menos que se indique lo contrario, son del autor.
Este artículo se publicó originalmente el El sitio web de Janna Lipenkova y re-publicado a TOPBOTS con permiso del autor.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.topbots.com/choosing-the-right-language-model/

