
Imagen de Unsplash
En el proceso de aprendizaje automático, el escalado de datos se incluye en el preprocesamiento de datos o ingeniería de características. Escalar sus datos antes de usarlos para la construcción de modelos puede lograr lo siguiente:
- El escalado asegura que las entidades tengan valores en el mismo rango
- El escalado garantiza que las funciones utilizadas en la creación de modelos no tengan dimensiones
- El escalado se puede utilizar para detectar valores atípicos
Hay varios métodos para escalar datos. Las dos técnicas de escalamiento más importantes son la Normalización y la Estandarización.
Cuando los datos se escalan usando la normalización, los datos transformados se pueden calcular usando esta ecuación
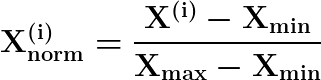
donde 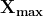
y 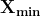 son los valores máximo y mínimo de los datos, respectivamente. Los datos escalados obtenidos están en el rango [0, 1].
son los valores máximo y mínimo de los datos, respectivamente. Los datos escalados obtenidos están en el rango [0, 1].
Implementación de normalización de Python
El escalado usando la normalización se puede implementar en Python usando el siguiente código:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)
Sea X un dato dado con 
y 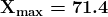 . El dato X se muestra en la siguiente figura:
. El dato X se muestra en la siguiente figura:
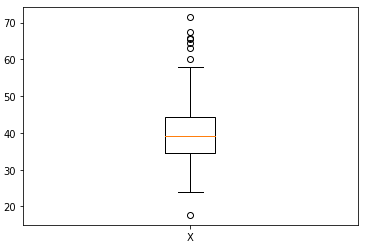
Figura 1. Boxplot de datos X con valores entre 17.7 y 71.4. Imagen por Autor.
La X normalizada se muestra en la siguiente figura:
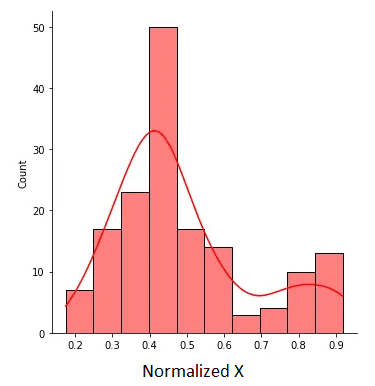
Figura 2. X normalizado con valores entre 0 y 1. Imagen del autor.
Idealmente, la estandarización debe usarse cuando los datos se distribuyen de acuerdo con la distribución normal o guassiana. Los datos estandarizados se pueden calcular de la siguiente manera:
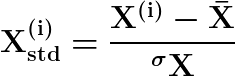
Aquí, 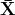
es la media de los datos, y 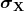 es la desviación estándar. Los valores estandarizados generalmente deben estar en el rango [-2, 2], que representa el intervalo de confianza del 95%. Los valores estandarizados inferiores a -2 o superiores a 2 pueden considerarse atípicos. Por lo tanto, la estandarización se puede utilizar para la detección de valores atípicos.
es la desviación estándar. Los valores estandarizados generalmente deben estar en el rango [-2, 2], que representa el intervalo de confianza del 95%. Los valores estandarizados inferiores a -2 o superiores a 2 pueden considerarse atípicos. Por lo tanto, la estandarización se puede utilizar para la detección de valores atípicos.
Implementación Python de la estandarización
El escalado mediante la estandarización se puede implementar en Python utilizando el siguiente código:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)
Utilizando los datos descritos anteriormente, los datos estandarizados se muestran a continuación:
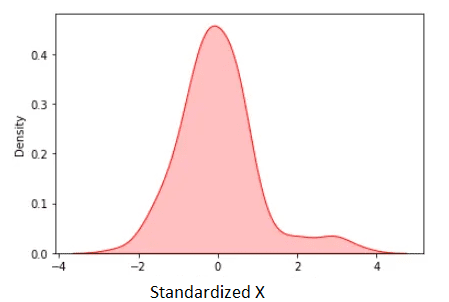
Figura 3. X estandarizada. Imagen por autor.
La media estandarizada es cero. Observamos en la figura anterior que, a excepción de algunos valores atípicos, la mayoría de los datos estandarizados se encuentran en el rango [-2, 2].
En resumen, hemos discutido dos de los métodos más populares para escalar características, a saber: estandarización y normalización. Los datos normalizados se encuentran en el rango [0, 1], mientras que los datos estandarizados generalmente se encuentran en el rango [-2, 2]. La ventaja de la estandarización es que se puede utilizar para la detección de valores atípicos.
Benjamín O. Tayo es físico, educador en ciencia de datos y escritor, además de propietario de DataScienceHub. Anteriormente, Benjamin enseñaba ingeniería y física en la U. of Central Oklahoma, la U. Grand Canyon y la U. del estado de Pittsburgh.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/07/data-scaling-python.html?utm_source=rss&utm_medium=rss&utm_campaign=data-scaling-with-python

