Esta es una publicación invitada coescrita con el equipo PyTorch de Meta y es una continuación de Parte 1 de esta serie, donde demostramos el rendimiento y la facilidad de ejecutar PyTorch 2.0 en AWS.
La investigación sobre aprendizaje automático (ML) ha demostrado que los modelos de lenguaje grandes (LLM) entrenados con conjuntos de datos significativamente grandes dan como resultado una mejor calidad del modelo. En los últimos años, el tamaño de los modelos de la generación actual ha aumentado significativamente y requieren herramientas e infraestructura modernas para entrenarse de manera eficiente y a escala. El paralelismo de datos distribuidos (DDP) de PyTorch ayuda a procesar datos a escala de una manera simple y sólida, pero requiere que el modelo se ajuste a una GPU. La biblioteca PyTorch Fully Sharded Data Parallel (FSDP) rompe esta barrera al permitir la fragmentación de modelos para entrenar modelos grandes entre trabajadores de datos paralelos.
La capacitación de modelos distribuidos requiere un grupo de nodos trabajadores que puedan escalarse. Servicio Amazon Elastic Kubernetes (Amazon EKS) es un servicio popular compatible con Kubernetes que simplifica enormemente el proceso de ejecución de cargas de trabajo de IA/ML, haciéndolo más manejable y requiere menos tiempo.
En esta publicación de blog, AWS colabora con el equipo PyTorch de Meta para analizar cómo utilizar la biblioteca FSDP de PyTorch para lograr un escalado lineal de modelos de aprendizaje profundo en AWS sin problemas utilizando Amazon EKS y Contenedores de aprendizaje profundo de AWS (DLC). Demostramos esto a través de una implementación paso a paso del entrenamiento de los modelos Llama7 13B, 70B y 2B utilizando Amazon EKS con 16 Nube informática elástica de Amazon (Amazon EC2) p4de.24xgrande instancias (cada una con 8 GPU NVIDIA A100 Tensor Core y cada GPU con 80 GB de memoria HBM2e) o 16 EC2 p5.48xgrande instancias (cada una con 8 GPU NVIDIA H100 Tensor Core y cada GPU con 80 GB de memoria HBM3), logrando un escalado casi lineal en el rendimiento y, en última instancia, permitiendo un tiempo de entrenamiento más rápido.
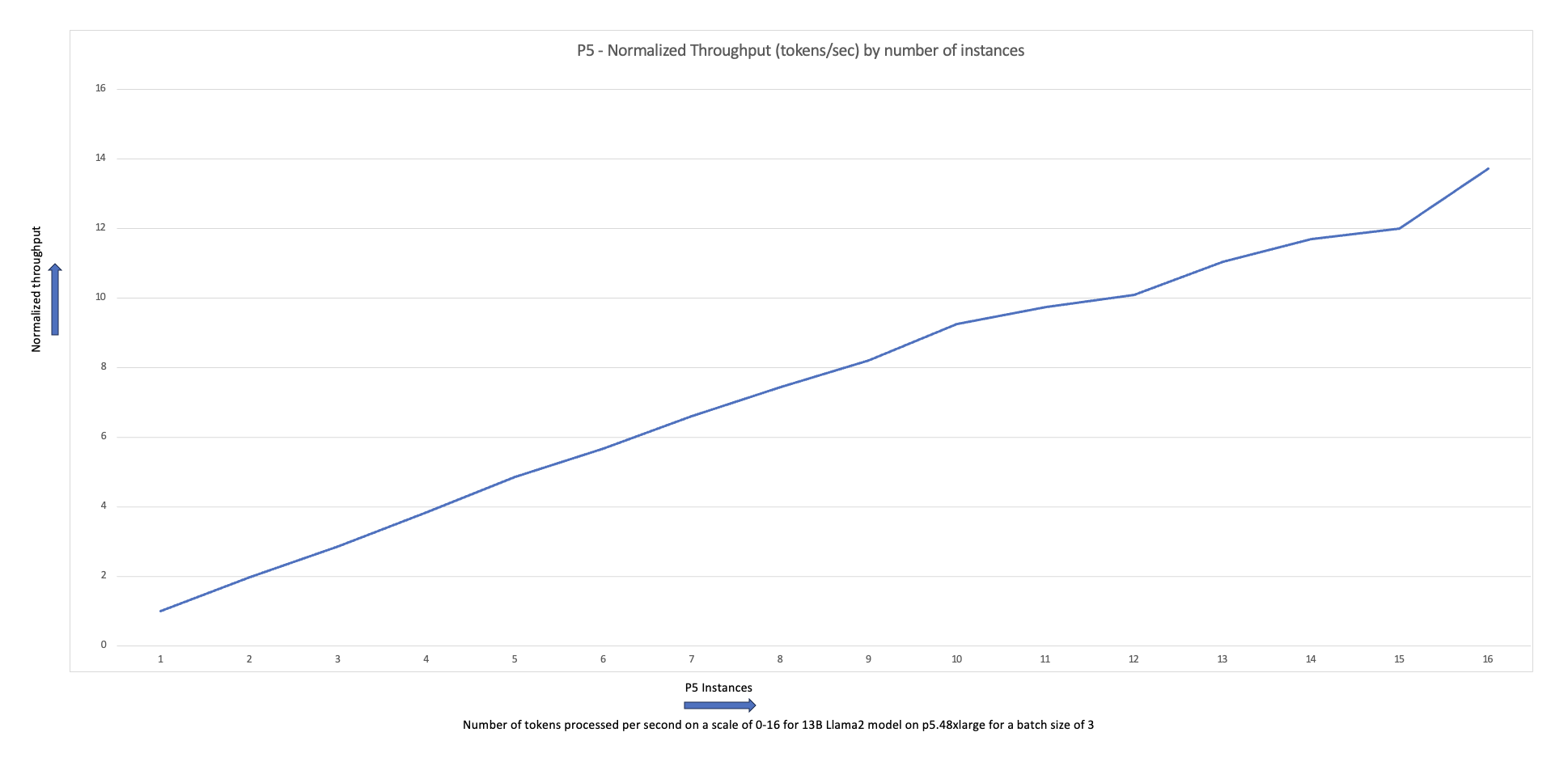
El siguiente gráfico de escalamiento muestra que las instancias p5.48xlarge ofrecen una eficiencia de escalamiento del 87 % con el ajuste fino de FSDP Llama2 en una configuración de clúster de 16 nodos.
Desafíos de la formación de LLM
Las empresas están adoptando cada vez más LLM para una variedad de tareas, incluidos asistentes virtuales, traducción, creación de contenido y visión por computadora, para mejorar la eficiencia y precisión en una variedad de aplicaciones.
Sin embargo, entrenar o ajustar estos grandes modelos para un caso de uso personalizado requiere una gran cantidad de datos y potencia de cálculo, lo que aumenta la complejidad de ingeniería general de la pila de ML. Esto también se debe a la memoria limitada disponible en una sola GPU, lo que restringe el tamaño del modelo que se puede entrenar y también limita el tamaño del lote por GPU utilizado durante el entrenamiento.
Para abordar este desafío, varias técnicas de paralelismo de modelos, como Velocidad profunda cero y FSDP de PyTorch fueron creados para permitirle superar esta barrera de memoria GPU limitada. Esto se hace adoptando una técnica paralela de datos fragmentados, donde cada acelerador contiene solo una porción (una casco) de una réplica del modelo en lugar de la réplica completa del modelo, lo que reduce drásticamente la huella de memoria del trabajo de entrenamiento.
Esta publicación demuestra cómo puede usar PyTorch FSDP para ajustar el modelo Llama2 usando Amazon EKS. Lo logramos ampliando la capacidad de procesamiento y GPU para abordar los requisitos del modelo.
Descripción general del FSDP
En el entrenamiento de PyTorch DDP, cada GPU (denominada obrero en el contexto de PyTorch) contiene una copia completa del modelo, incluidos los pesos del modelo, los gradientes y los estados del optimizador. Cada trabajador procesa un lote de datos y, al final del paso hacia atrás, utiliza un todo reducido operación para sincronizar gradientes entre diferentes trabajadores.
Tener una réplica del modelo en cada GPU restringe el tamaño del modelo que se puede acomodar en un flujo de trabajo DDP. FSDP ayuda a superar esta limitación al fragmentar los parámetros del modelo, los estados del optimizador y los gradientes entre los trabajadores paralelos de datos y al mismo tiempo preservar la simplicidad del paralelismo de datos.
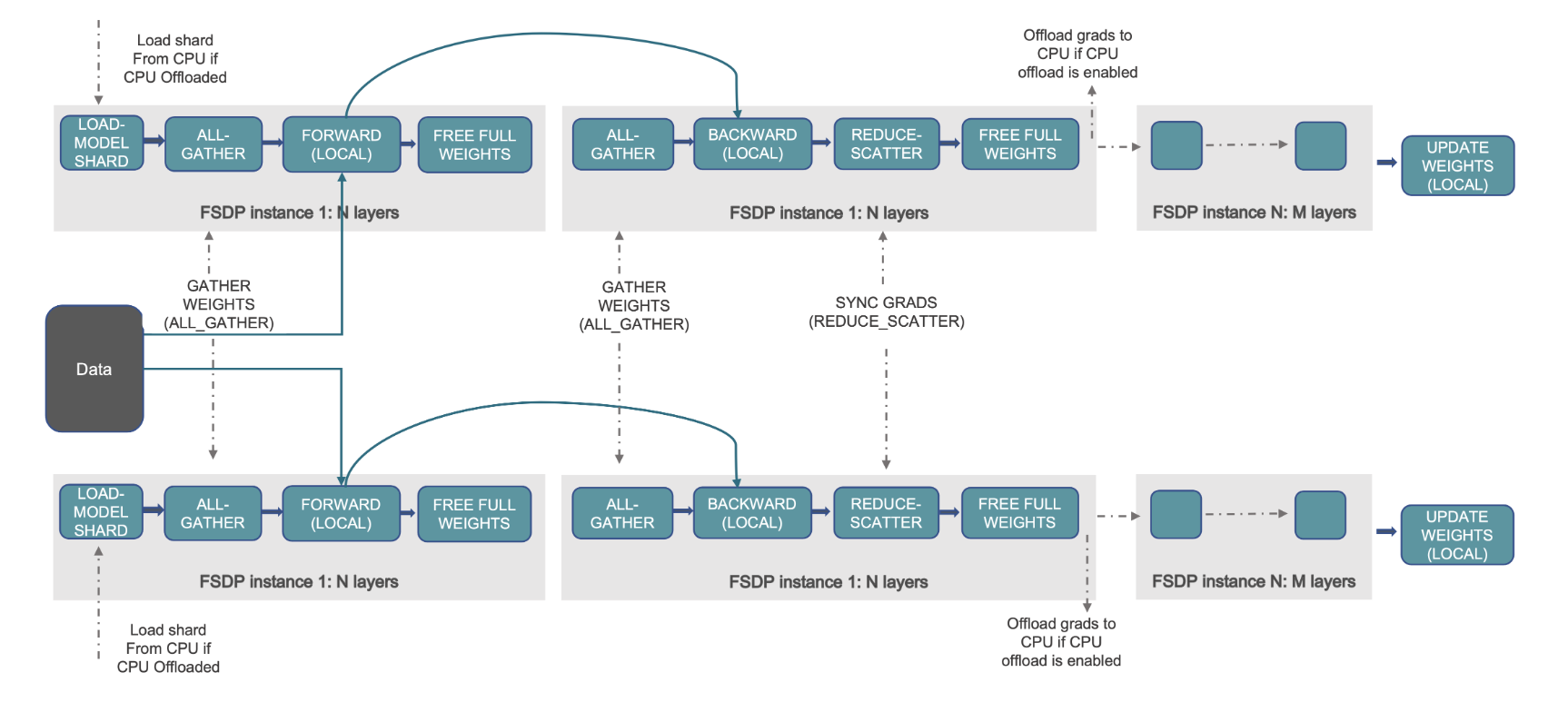
Esto se demuestra en el siguiente diagrama, donde en el caso de DDP, cada GPU contiene una copia completa del estado del modelo, incluido el estado del optimizador (OS), gradientes (G) y parámetros (P): M(OS + G +P). En FSDP, cada GPU contiene solo una porción del estado del modelo, incluido el estado del optimizador (OS), los gradientes (G) y los parámetros (P): M (SO + G + P). El uso de FSDP da como resultado una huella de memoria de GPU significativamente menor en comparación con DDP en todos los trabajadores, lo que permite el entrenamiento de modelos muy grandes o el uso de lotes de mayor tamaño para trabajos de entrenamiento.

Sin embargo, esto tiene el costo de una mayor sobrecarga de comunicación, que se mitiga mediante optimizaciones de FSDP, como la superposición de procesos de comunicación y cálculo con características como búsqueda previa. Para obtener información más detallada, consulte Introducción a datos paralelos totalmente fragmentados (FSDP).
FSDP ofrece varios parámetros que le permiten ajustar el rendimiento y la eficiencia de sus trabajos de capacitación. Algunas de las características y capacidades clave de FSDP incluyen:
- Política de envoltura de transformadores
- Precisión mixta flexible
- Control de activación
- Varias estrategias de fragmentación para adaptarse a diferentes velocidades de red y topologías de clúster:
- FULL_SHARD – Parámetros del modelo de fragmentos, gradientes y estados del optimizador.
- HYBRID_SHARD – Fragmento completo dentro de un nodo DDP entre nodos; admite un grupo de fragmentación flexible para una réplica completa del modelo (HSDP)
- SHARD_GRAD_OP – Gradientes de fragmentación únicamente y estados del optimizador
- NO_SHARD – Similar al DDP
Para obtener más información sobre FSDP, consulte Capacitación eficiente a gran escala con Pytorch FSDP y AWS.
La siguiente figura muestra cómo funciona FSDP para dos procesos de datos paralelos.
Resumen de la solución
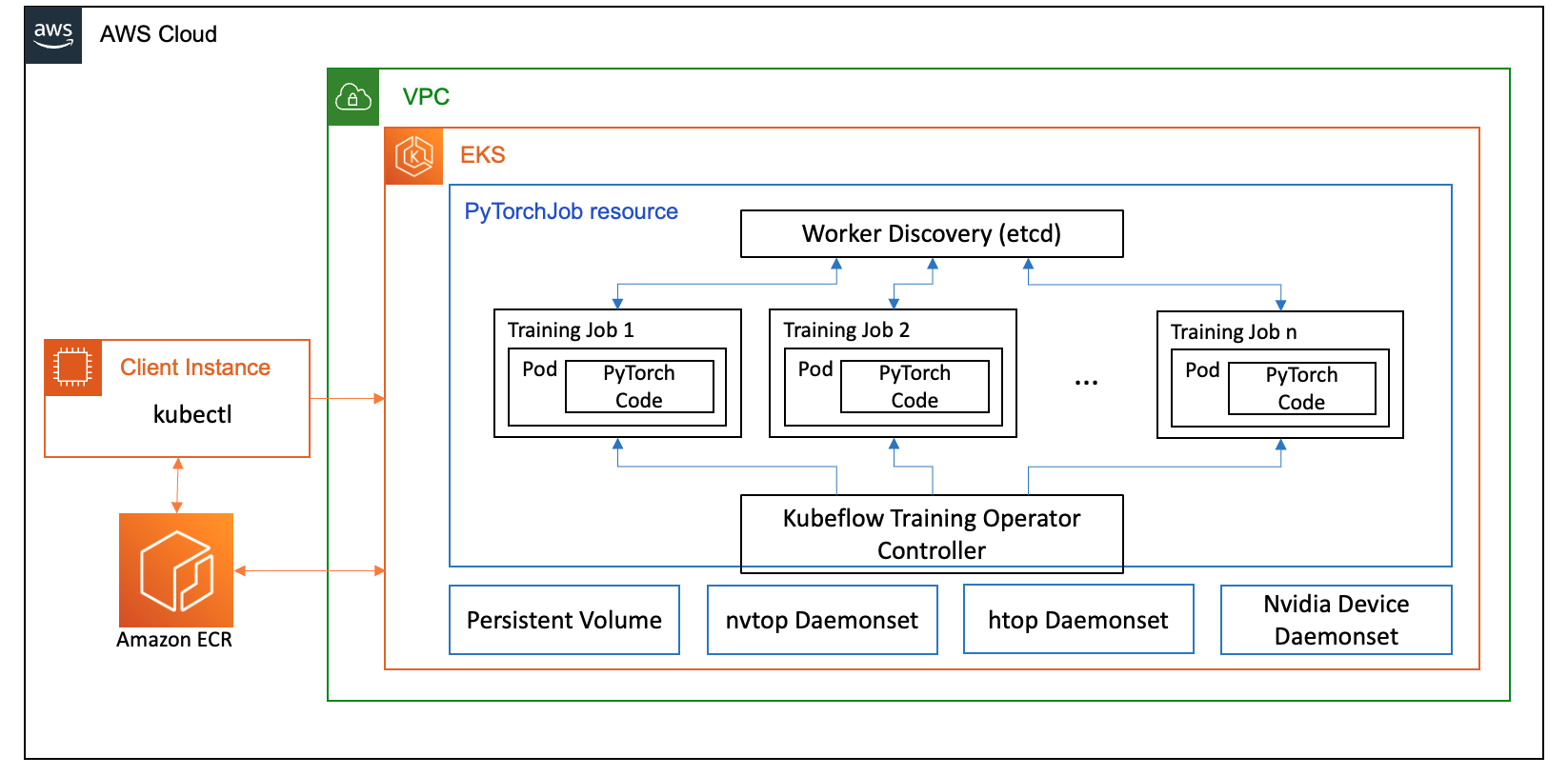
En esta publicación, configuramos un clúster informático utilizando Amazon EKS, que es un servicio administrado para ejecutar Kubernetes en la nube de AWS y en los centros de datos locales. Muchos clientes están adoptando Amazon EKS para ejecutar cargas de trabajo de IA/ML basadas en Kubernetes, aprovechando su rendimiento, escalabilidad, confiabilidad y disponibilidad, así como sus integraciones con redes, seguridad y otros servicios de AWS.
Para nuestro caso de uso de FSDP, utilizamos el Operador de capacitación de Kubeflow en Amazon EKS, que es un proyecto nativo de Kubernetes que facilita el ajuste fino y la capacitación distribuida escalable para modelos de aprendizaje automático. Admite varios marcos de aprendizaje automático, incluido PyTorch, que puede utilizar para implementar y administrar trabajos de capacitación de PyTorch a escala.
Utilizando el recurso personalizado PyTorchJob de Kubeflow Training Operador, ejecutamos trabajos de capacitación en Kubernetes con una cantidad configurable de réplicas de trabajadores que nos permite optimizar la utilización de recursos.
Los siguientes son algunos componentes del operador de capacitación que desempeñan un papel en nuestro caso de uso de ajuste fino de Llama2:
- Un controlador centralizado de Kubernetes que organiza trabajos de capacitación distribuidos para PyTorch.
- PyTorchJob, un recurso personalizado de Kubernetes para PyTorch, proporcionado por el operador de capacitación de Kubeflow, para definir e implementar trabajos de capacitación de Llama2 en Kubernetes.
- etcd, que está relacionado con la implementación del mecanismo de encuentro para coordinar el entrenamiento distribuido de modelos PyTorch. Este
etcdEl servidor, como parte del proceso de encuentro, facilita la coordinación y sincronización de los trabajadores participantes durante la formación distribuida.
El siguiente diagrama ilustra la arquitectura de la solución.
La mayoría de los detalles serán resumidos por los scripts de automatización que usamos para ejecutar el ejemplo de Llama2.
Usamos las siguientes referencias de código en este caso de uso:
¿Qué es Llama2?
Llama2 es un LLM previamente capacitado en 2 billones de tokens de texto y código. Es uno de los LLM más grandes y potentes disponibles en la actualidad. Puede utilizar Llama2 para una variedad de tareas, incluido el procesamiento del lenguaje natural (NLP), la generación de texto y la traducción. Para obtener más información, consulte Empezando con Llama.
Llama2 está disponible en tres tamaños de modelo diferentes:
- Llama2-70b – Este es el modelo Llama2 más grande, con 70 mil millones de parámetros. Es el modelo Llama2 más potente y puede utilizarse para las tareas más exigentes.
- Llama2-13b – Este es un modelo Llama2 de tamaño mediano, con 13 mil millones de parámetros. Es un buen equilibrio entre rendimiento y eficiencia y puede usarse para una variedad de tareas.
- Llama2-7b – Este es el modelo Llama2 más pequeño, con 7 mil millones de parámetros. Es el modelo Llama2 más eficiente y puede usarse para tareas que no requieren el más alto nivel de rendimiento.
Esta publicación le permite ajustar todos estos modelos en Amazon EKS. Para proporcionar una experiencia simple y reproducible al crear un clúster EKS y ejecutar trabajos FSDP en él, utilizamos el aws-do-eks proyecto. El ejemplo también funcionará con un clúster EKS preexistente.
Un tutorial escrito está disponible en GitHub para una experiencia innovadora. En las siguientes secciones, explicamos el proceso de un extremo a otro con más detalle.
Aprovisionar la infraestructura de la solución
Para los experimentos descritos en esta publicación, utilizamos clústeres con nodos p4de (A100 GPU) y p5 (H100 GPU).
Clúster con nodos p4de.24xlarge
Para nuestro clúster con nodos p4de, utilizamos lo siguiente eks-gpu-p4de-odcr.yaml script:
Usar eksctl y el manifiesto del clúster anterior, creamos un clúster con nodos p4de:
Clúster con nodos p5.48xlarge
Una plantilla de terraform para un clúster EKS con nodos P5 se encuentra a continuación Repositorio GitHub.
Puede personalizar el clúster mediante el variables.tf archivo y luego créelo a través de Terraform CLI:
Puede verificar la disponibilidad del clúster ejecutando un comando kubectl simple:
El clúster está en buen estado si el resultado de este comando muestra la cantidad esperada de nodos en estado Listo.
Implementar requisitos previos
Para ejecutar FSDP en Amazon EKS, utilizamos el PyTorchJob recurso personalizado. Requiere etcd y Operador de capacitación de Kubeflow como requisitos previos.
Implemente etcd con el siguiente código:
Implemente Kubeflow Training Operador con el siguiente código:
Cree y envíe una imagen de contenedor FSDP a Amazon ECR
Utilice el siguiente código para crear una imagen de contenedor FSDP y enviarla a Registro de contenedores elásticos de Amazon (Amazon ECR):
Cree el manifiesto FSDP PyTorchJob
Inserte su Ficha de cara de abrazo en el siguiente fragmento antes de ejecutarlo:
Configure su PyTorchJob con .env archivo o directamente en sus variables de entorno como se muestra a continuación:
Genere el manifiesto PyTorchJob usando el plantilla fsdp y generar.sh script o créelo directamente usando el siguiente script:
Ejecute el trabajo PyTorch
Ejecute PyTorchJob con el siguiente código:
Verá la cantidad especificada de pods de trabajadores FDSP creados y, después de extraer la imagen, entrarán en estado En ejecución.
Para ver el estado de PyTorchJob, utilice el siguiente código:
Para detener PyTorchJob, use el siguiente código:
Una vez completado un trabajo, es necesario eliminarlo antes de iniciar una nueva ejecución. También hemos observado que eliminar eletcdpod y dejar que se reinicie antes de iniciar un nuevo trabajo ayuda a evitar RendezvousClosedError.
Escalar el clúster
Puede repetir los pasos anteriores para crear y ejecutar trabajos mientras varía el número y el tipo de instancia de nodos trabajadores en el clúster. Esto le permite producir gráficos de escala como el que se mostró anteriormente. En general, debería ver una reducción en el uso de memoria de la GPU, una reducción en el tiempo de época y un aumento en el rendimiento cuando se agregan más nodos al clúster. El gráfico anterior se produjo mediante la realización de varios experimentos utilizando un grupo de nodos p5 que varía de 1 a 16 nodos en tamaño.
Observe la carga de trabajo de capacitación de FSDP
La observabilidad de las cargas de trabajo de inteligencia artificial generativa es importante para permitir la visibilidad de sus trabajos en ejecución, así como para ayudar a maximizar la utilización de sus recursos informáticos. En esta publicación, utilizamos algunas herramientas de observabilidad de código abierto y nativas de Kubernetes para este propósito. Estas herramientas le permiten realizar un seguimiento de errores, estadísticas y comportamiento del modelo, lo que hace que la observabilidad de la IA sea una parte crucial de cualquier caso de uso empresarial. En esta sección, mostramos varios enfoques para observar los trabajos de capacitación de FSDP.
Registros de grupos de trabajadores
En el nivel más básico, debes poder ver los registros de tus módulos de entrenamiento. Esto se puede hacer fácilmente utilizando comandos nativos de Kubernetes.
Primero, recupere una lista de pods y localice el nombre de aquel cuyos registros desea ver:
Luego vea los registros del pod seleccionado:

Solo un registro del grupo de trabajadores (líder electo) enumerará las estadísticas generales del trabajo. El nombre del grupo líder elegido está disponible al principio de cada registro del grupo de trabajadores, identificado por la clave master_addr=.
Utilización de la CPU
Las cargas de trabajo de capacitación distribuidas requieren recursos de CPU y GPU. Para optimizar estas cargas de trabajo, es importante comprender cómo se utilizan estos recursos. Afortunadamente, hay disponibles algunas excelentes utilidades de código abierto que ayudan a visualizar la utilización de CPU y GPU. Para ver la utilización de la CPU, puede utilizarhtop. Si sus pods de trabajo contienen esta utilidad, puede usar el siguiente comando para abrir un shell en un pod y luego ejecutarhtop.
Alternativamente, puede implementar un htopdaemonsetcomo el que se proporciona a continuación Repositorio GitHub.
El daemonsetejecutará un pod htop liviano en cada nodo. Puede ejecutar cualquiera de estos pods y ejecutar elhtopmando:
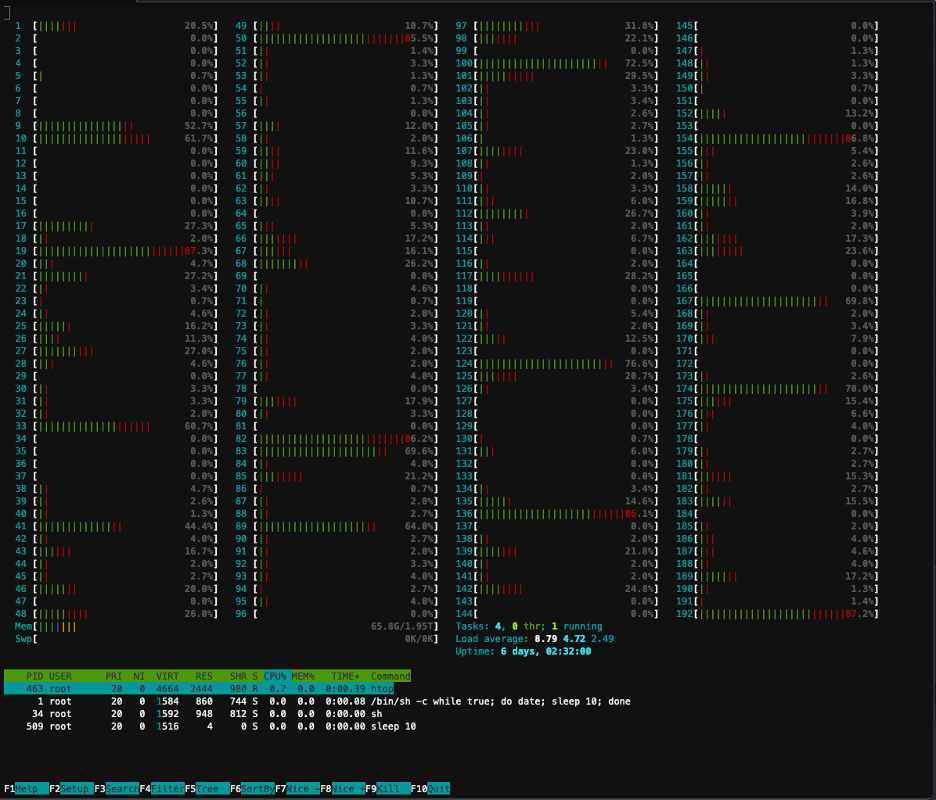
La siguiente captura de pantalla muestra la utilización de la CPU en uno de los nodos del clúster. En este caso, estamos ante una instancia P5.48xlarge, que tiene 192 vCPU. Los núcleos del procesador están inactivos mientras se descargan los pesos de los modelos, y vemos una utilización creciente mientras los pesos de los modelos se cargan en la memoria de la GPU.
utilización de la GPU
SinvtopLa utilidad está disponible en su pod, puede ejecutarla usando a continuación y luego ejecutarnvtop.
Alternativamente, puede implementar un nvtopdaemonsetcomo el que se proporciona a continuación Repositorio GitHub.
Esto ejecutará unnvtopvaina en cada nodo. Puedes ejecutar en cualquiera de esos pods y ejecutarnvtop:
La siguiente captura de pantalla muestra la utilización de GPU en uno de los nodos del clúster de entrenamiento. En este caso, estamos ante una instancia P5.48xlarge, que tiene 8 GPU NVIDIA H100. Las GPU están inactivas mientras se descargan los pesos del modelo, luego la utilización de la memoria de la GPU aumenta a medida que los pesos del modelo se cargan en la GPU y la utilización de la GPU aumenta al 100 % mientras se realizan las iteraciones de entrenamiento.

Panel de control de Grafana
Ahora que comprende cómo funciona su sistema a nivel de pod y nodo, también es importante observar las métricas a nivel de clúster. NVIDIA DCGM Exporter y Prometheus pueden recopilar métricas de utilización agregadas y visualizarlas en Grafana.
Un ejemplo de implementación de Prometheus-Grafana está disponible en el siguiente Repositorio GitHub.
Un ejemplo de implementación del exportador DCGM está disponible a continuación Repositorio GitHub.
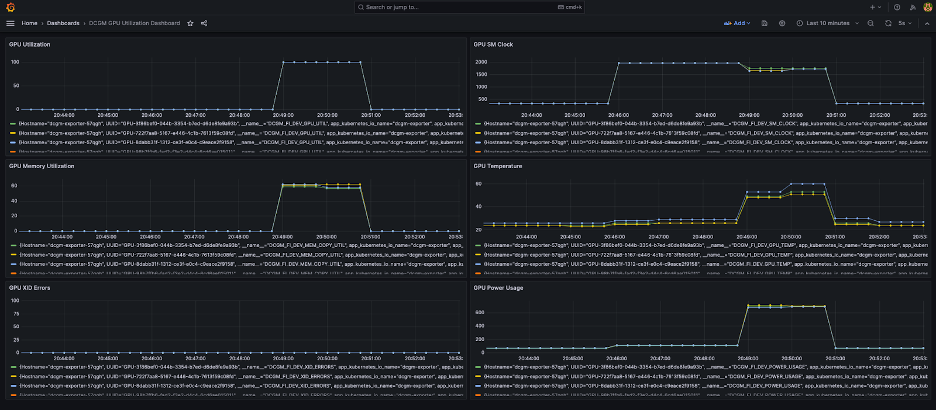
En la siguiente captura de pantalla se muestra un panel de control simple de Grafana. Fue construido seleccionando las siguientes métricas DCGM: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPy DCGM_FI_DEV_POWER_USAGE. El panel se puede importar a Prometheus desde GitHub.
El siguiente panel muestra una ejecución de un trabajo de entrenamiento de una sola época de Llama2 7b. Los gráficos muestran que a medida que aumenta el reloj del multiprocesador (SM) de transmisión, el consumo de energía y la temperatura de las GPU también aumentan, junto con la utilización de la GPU y la memoria. También puede ver que no hubo errores de XID y que las GPU estaban en buen estado durante esta ejecución.
Desde marzo de 2024, la observabilidad de GPU para EKS es compatible de forma nativa en Información sobre contenedores de CloudWatch. Para habilitar esta funcionalidad, simplemente implemente el complemento CloudWatch Observability en su clúster EKS. Luego podrá explorar métricas a nivel de pod, nodo y clúster a través de paneles preconfigurados y personalizables en Container Insights.
Limpiar
Si creó su clúster usando los ejemplos proporcionados en este blog, puede ejecutar el siguiente código para eliminar el clúster y cualquier recurso asociado con él, incluida la VPC:
Para eksctl:
Para terraformar:
Próximas funciones
Se espera que FSDP incluya una función de fragmentación por parámetro, con el objetivo de mejorar aún más su uso de memoria por GPU. Además, el desarrollo continuo del soporte del FP8 tiene como objetivo mejorar el rendimiento de FSDP en las GPU H100. Finalmente, cuando FSDP se integra contorch.compile, esperamos ver mejoras de rendimiento adicionales y la habilitación de funciones como puntos de control de activación selectiva.
Conclusión
En esta publicación, analizamos cómo FSDP reduce la huella de memoria en cada GPU, lo que permite entrenar modelos más grandes de manera más eficiente y lograr un escalamiento casi lineal en el rendimiento. Demostramos esto mediante una implementación paso a paso del entrenamiento de un modelo Llama2 usando Amazon EKS en instancias P4de y P5 y utilizamos herramientas de observabilidad como kubectl, htop, nvtop y dcgm para monitorear los registros, así como la utilización de CPU y GPU.
Le recomendamos que aproveche PyTorch FSDP para sus propios trabajos de formación de LLM. Comience en aws-do-fsdp.
Acerca de los autores
 Kanwaljit Khurmi es arquitecto principal de soluciones de IA/ML en Amazon Web Services. Trabaja con clientes de AWS para brindarles orientación y asistencia técnica, ayudándolos a mejorar el valor de sus soluciones de aprendizaje automático en AWS. Kanwaljit se especializa en ayudar a los clientes con aplicaciones de aprendizaje profundo y computación distribuida en contenedores.
Kanwaljit Khurmi es arquitecto principal de soluciones de IA/ML en Amazon Web Services. Trabaja con clientes de AWS para brindarles orientación y asistencia técnica, ayudándolos a mejorar el valor de sus soluciones de aprendizaje automático en AWS. Kanwaljit se especializa en ayudar a los clientes con aplicaciones de aprendizaje profundo y computación distribuida en contenedores.
 Alex Iankoulski es arquitecto principal de soluciones y aprendizaje automático autogestionado en AWS. Es un ingeniero de infraestructura y software completo al que le gusta hacer un trabajo profundo y práctico. En su puesto, se centra en ayudar a los clientes con la contenerización y la orquestación de cargas de trabajo de aprendizaje automático e inteligencia artificial en servicios de AWS basados en contenedores. También es el autor del código abierto. hacer marco y un capitán de Docker al que le encanta aplicar tecnologías de contenedores para acelerar el ritmo de la innovación mientras resuelve los mayores desafíos del mundo.
Alex Iankoulski es arquitecto principal de soluciones y aprendizaje automático autogestionado en AWS. Es un ingeniero de infraestructura y software completo al que le gusta hacer un trabajo profundo y práctico. En su puesto, se centra en ayudar a los clientes con la contenerización y la orquestación de cargas de trabajo de aprendizaje automático e inteligencia artificial en servicios de AWS basados en contenedores. También es el autor del código abierto. hacer marco y un capitán de Docker al que le encanta aplicar tecnologías de contenedores para acelerar el ritmo de la innovación mientras resuelve los mayores desafíos del mundo.
 ana simoes es especialista principal en aprendizaje automático, ML Frameworks en AWS. Ella apoya a los clientes que implementan IA, ML e IA generativa a gran escala en infraestructura HPC en la nube. Ana se centra en ayudar a los clientes a lograr una relación precio-rendimiento para nuevas cargas de trabajo y casos de uso de IA generativa y aprendizaje automático.
ana simoes es especialista principal en aprendizaje automático, ML Frameworks en AWS. Ella apoya a los clientes que implementan IA, ML e IA generativa a gran escala en infraestructura HPC en la nube. Ana se centra en ayudar a los clientes a lograr una relación precio-rendimiento para nuevas cargas de trabajo y casos de uso de IA generativa y aprendizaje automático.
 Hamid Shojanazeri es un ingeniero asociado en PyTorch que trabaja en código abierto, optimización de modelos de alto rendimiento y capacitación distribuida (FSDP), e inferencia. Es el cocreador de receta-llama y colaborador de AntorchaServir. Su principal interés es mejorar la rentabilidad, haciendo que la IA sea más accesible para la comunidad en general.
Hamid Shojanazeri es un ingeniero asociado en PyTorch que trabaja en código abierto, optimización de modelos de alto rendimiento y capacitación distribuida (FSDP), e inferencia. Es el cocreador de receta-llama y colaborador de AntorchaServir. Su principal interés es mejorar la rentabilidad, haciendo que la IA sea más accesible para la comunidad en general.
 Menos Wright es un ingeniero asociado/AI en PyTorch. Trabaja en kernels Triton/CUDA (Acelerando Dequant con descomposición del trabajo SplitK); optimizadores paginados, de streaming y cuantificados; y PyTorch distribuido (FSDP de PyTorch).
Menos Wright es un ingeniero asociado/AI en PyTorch. Trabaja en kernels Triton/CUDA (Acelerando Dequant con descomposición del trabajo SplitK); optimizadores paginados, de streaming y cuantificados; y PyTorch distribuido (FSDP de PyTorch).
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

