
Imagen de unsplash
Los conceptos estadísticos se utilizan ampliamente para extraer información útil de los datos. Este artículo revisará los conceptos estadísticos esenciales aplicables en la ciencia de datos y el aprendizaje automático.
Una distribución de probabilidad muestra cómo se distribuyen los valores de las características alrededor del valor medio. Usando el conjunto de datos del iris, las distribuciones de probabilidad para la longitud del sépalo, el ancho del sépalo, la longitud del pétalo y el ancho del pétalo se pueden generar usando el código a continuación.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import seaborn as sns iris = sns.load_dataset("iris")
sns.kdeplot(data=iris)
plt.show()
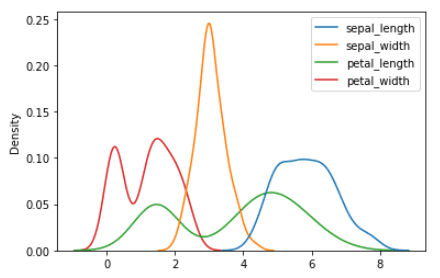
Distribución de probabilidad de longitud de sépalo, anchura de sépalo, anchura de sépalo, longitud de pétalo y anchura de pétalo | Imagen por autor
Centrémonos ahora en la variable de longitud del sépalo. La distribución de probabilidad de la variable longitud del sépalo se muestra a continuación.
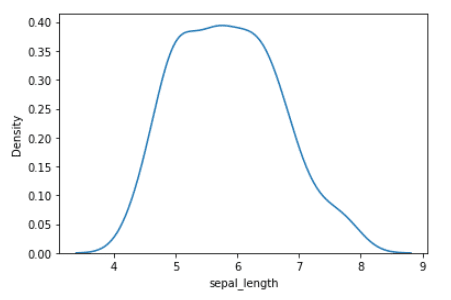
Distribución de probabilidad de la variable longitud del sépalo | Imagen por autor
Observamos que la distribución de probabilidad de la variable longitud del sépalo tiene un único máximo, por lo que es unimodal. El valor de la longitud del sépalo donde se produce el máximo es la moda, que es de aproximadamente 5.8.
A continuación se muestra un gráfico de la distribución de probabilidad de la variable ancho del pétalo.
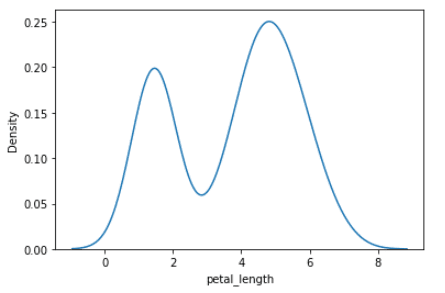
Distribución de probabilidad de la variable ancho de pétalo | Imagen por autor
A partir de este gráfico, observamos que la distribución de probabilidad de la variable longitud de los pétalos tiene 2 máximos, por lo que es bimodal. Los valores de la longitud del sépalo donde se produce el máximo son la moda, es decir, en 1.7 y 5.0.
El valor medio es una medida de tendencia central. El valor medio de la variable longitud del sépalo se obtiene de la siguiente manera:
data = datasets.load_iris().data
sepal_length = data[:,0]
mean = np.mean(sepal_length)
>>> 5.843333333333334
El valor de la mediana es también una medida de tendencia central. El valor mediano es menos susceptible a la presencia de valores atípicos, por lo tanto, una medida de tendencia central más confiable, en comparación con el valor medio. El valor de la mediana para la variable longitud del sépalo se obtiene de la siguiente manera:
data = datasets.load_iris().data
sepal_length = data[:,0]
np.median(sepal_length)
>>> 5.8La desviación estándar es una medida de las fluctuaciones de los valores de los datos alrededor del valor medio. Se utiliza para cuantificar el grado de incertidumbre en el conjunto de datos. La desviación estándar para la característica de longitud del sépalo se calcula utilizando el siguiente código.
data = datasets.load_iris().data
sepal_length = data[:,0]
std = np.std(sepal_length)
>>> 0.8253012917851409El intervalo de confianza es el rango de valores alrededor de la media. El intervalo de confianza del 65% es el rango de valores que están a una desviación estándar del valor medio. El intervalo de confianza del 95% es el rango de valores que están a dos desviaciones estándar del valor medio. El siguiente diagrama de caja muestra el valor medio y el intervalo de confianza del 65 % para la característica de longitud del sépalo.
sns.boxplot(data = iris, y='sepal_length')
plt.show()
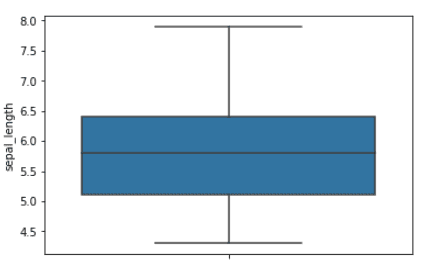
Diagrama de caja para la función de longitud del sépalo. La región azul indica el intervalo de confianza del 65% | Imagen por autor
Las distribuciones de probabilidad se pueden utilizar para el modelado predictivo. La función de longitud del sépalo solo tiene 150 puntos de datos. Supongamos que nos gustaría generar más puntos de datos. Luego, suponiendo que la característica de longitud del sépalo se distribuye normalmente, podemos generar más puntos de datos. En el siguiente ejemplo, generamos N = 1000 puntos de datos para la característica de longitud del sépalo.
np.random.seed(10**7)
mu = mean
sigma = std
x = np.random.normal(mean, std, N) num_bins = 50 n, bins, patches = plt.hist(x, num_bins, density = 1, color ='green', alpha = 0.7) y = ((1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-0.5 * (1 / sigma * (bins - mu))**2)) plt.plot(bins, y, '--', color ='black') plt.xlabel('sepal length')
plt.ylabel('probability distribution') plt.title('matplotlib.pyplot.hist() function Examplenn', fontweight ="bold") plt.show()
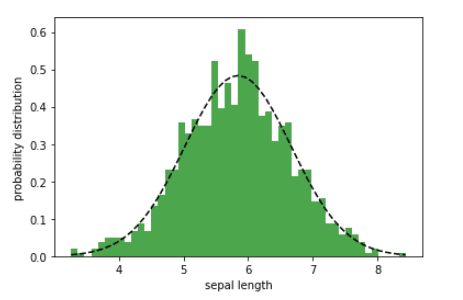
Distribución de probabilidad del ancho de la longitud del sépalo | Imagen por autor
El teorema de Bayes es un teorema importante en estadística y ciencia de datos. Se utiliza para evaluar el poder predictivo de los algoritmos de clasificación binaria. Un tutorial simple sobre cómo se usa el teorema de Bayes en un algoritmo de clasificación binaria se encuentra aquí: Teorema de Bayes en lenguaje sencillo.
En resumen, hemos revisado los conceptos estadísticos esenciales útiles para la ciencia de datos, como la moda, la mediana, la media, la desviación estándar, las distribuciones de probabilidad, la distribución normal y el teorema de Bayes. Cualquier persona interesada en la ciencia de datos debe aprender los fundamentos de la estadística.
Benjamín O. Tayo es físico, educador en ciencia de datos y escritor, además de propietario de DataScienceHub. Anteriormente, Benjamin enseñaba ingeniería y física en la U. of Central Oklahoma, la U. Grand Canyon y la U. del estado de Pittsburgh.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/05/practical-statistics-data-scientists.html?utm_source=rss&utm_medium=rss&utm_campaign=practical-statistics-for-data-scientists

