Introducción
Análisis y visualización de datos son herramientas poderosas que nos permiten dar sentido a conjuntos de datos complejos y comunicar conocimientos de manera efectiva. En esta exploración inmersiva de datos de conflictos del mundo real, profundizamos en las crudas realidades y complejidades de los conflictos. Nuestro enfoque está en Manipur, un estado en el noreste de la India, que lamentablemente se ha visto empañado por la violencia y los disturbios prolongados. Utilizando el Proyecto de datos de eventos y ubicación de conflictos armados (ACLED) [1], nos embarcamos en un viaje de análisis de datos en profundidad para descubrir la naturaleza multifacética de los conflictos.
OBJETIVOS DE APRENDIZAJE
- Obtenga competencia en técnicas de análisis de datos para el conjunto de datos ACLED.
- Desarrollar habilidades en la visualización efectiva de datos para la comunicación.
- Comprender el impacto de la violencia en las poblaciones vulnerables.
- Obtenga información sobre los aspectos temporales y espaciales de los conflictos.
- Apoyar enfoques basados en evidencia para abordar las necesidades humanitarias.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Conflicto de intereses
Ninguna organización o entidad específica es responsable del análisis e interpretación presentados en este blog. El objetivo es simplemente mostrar el potencial de la ciencia de datos en el análisis de conflictos. Además, no hay intereses ni sesgos personales involucrados en estos hallazgos, lo que garantiza un enfoque objetivo para comprender la dinámica del conflicto. Promover el uso de métodos basados en datos como una herramienta para mejorar los conocimientos e informar debates más amplios sobre el análisis de conflictos.
Implementación
¿Por qué ACLED Dataset?
Aprovechando el poder de las técnicas de ciencia de datos en el conjunto de datos ACLED. Podemos extraer ideas que no solo contribuyen a comprender la situación en Manipur, sino que también arrojan luz sobre los aspectos humanitarios asociados con la violencia. El Libro de códigos ACLED es una guía de referencia completa que proporciona información detallada sobre el esquema de codificación y las variables utilizadas en este conjunto de datos [2].
La importancia de ACLED radica en su análisis empático de datos, que mejora nuestra comprensión de la violencia de Manipur, ilumina las necesidades humanitarias y contribuye a abordar y mitigar la violencia. Promueve un futuro pacífico e inclusivo para las comunidades afectadas.
A través de este análisis basado en datos, no solo podemos desentrañar información valiosa, sino que también podemos resaltar el costo humano de la violencia de Manipur. Al analizar los datos de ACLED, espero que podamos arrojar luz sobre el impacto en las poblaciones civiles, el desplazamiento forzado y el acceso a los servicios esenciales, y así presentar una imagen completa de las realidades humanitarias que enfrenta la región.
Eventos de Conflicto
Como primer paso, exploraremos los eventos de conflicto en Manipur utilizando el conjunto de datos ACLED. El fragmento de código que se proporciona a continuación lee el conjunto de datos ACLED para India y filtra los datos específicamente para Manipur, lo que da como resultado un conjunto de datos filtrado con una forma de (número de filas, número de columnas). A continuación, se imprime la forma de los datos filtrados.
import pandas as pd #import country specific csv downloaded from acleddata.com file_path = './acled_India.csv' all_data = pd.read_csv(file_path) # Filter the data for Manipur df_filtered = all_data.loc[all_data['admin1'] == "Manipur"] shape = df_filtered.shape print("Filtered Data Shape:", shape) #Output: #Filtered Data Shape: (4495, 31)El número de filas en los datos ACLED representa el número de eventos o incidentes individuales registrados en el conjunto de datos. Cada fila normalmente corresponde a un evento específico, como un conflicto, protesta o violencia, y contiene varios atributos o columnas que brindan información sobre el evento, como la ubicación, la fecha, los actores involucrados y otros detalles relevantes.
Al contar la cantidad de filas en el conjunto de datos ACLED, puede determinar la cantidad total de eventos o incidentes registrados en los datos. Al filtrar el conjunto de datos específicamente para Manipur, obtuvimos un conjunto de datos filtrado que contenía información sobre eventos o incidentes individuales registrados desde enero de 2016 hasta el 9 de junio de 2023. El número total de eventos o incidentes registrados en Manipur, que se situó en 4495 filas, brindó información sobre el alcance y la escala del conflicto o eventos rastreados por ACLED.
Como siguiente paso, calculamos la suma de valores nulos a lo largo de las columnas (eje = 0) en el marco de datos df_filtered. Proporciona información sobre el recuento de valores faltantes en cada columna del conjunto de datos filtrado.
df_filtered.isnull().sum(axis = 0) # Output: count of null values in each column
# event_id_cnty: 0 null values
# event_date: 0 null values
# year: 0 null values
# time_precision: 0 null values
# disorder_type: 0 null values
# event_type: 0 null values
# sub_event_type: 0 null values
# actor1: 0 null values
# assoc_actor_1: 1887 null values
# inter1: 0 null values
# actor2: 3342 null values
# assoc_actor_2: 4140 null values
# inter2: 0 null values
# interaction: 0 null values
# civilian_targeting: 4153 null values
# iso: 0 null values
# region: 0 null values
# country: 0 null values
# admin1: 0 null values
# admin2: 0 null values
# admin3: 0 null values
# location: 0 null values
# latitude: 0 null values
# longitude: 0 null values
# geo_precision: 0 null values
# source: 0 null values
# source_scale: 0 null values
# notes: 0 null values
# fatalities: 0 null values
# tags: 1699 null values
# timestamp: 0 null valuesEl fragmento de código siguiente genera el número de valores únicos en cada columna.
n = df_filtered.nunique(axis=0) print("No.of.unique values in each column:n", n) # Output:
# No.of.unique values in each column:
# event_id_cnty: 4495
# event_date: 1695
# year: 8
# time_precision: 3
# disorder_type: 4
# event_type: 6
# sub_event_type: 17
# actor1: 66
# assoc_actor_1: 323
# inter1: 8
# actor2: 61
# assoc_actor_2: 122
# inter2: 9
# interaction: 28
# civilian_targeting: 1
# iso: 1
# region: 1
# country: 1
# admin1: 1
# admin2: 16
# admin3: 37
# location: 495
# latitude: 485
# longitude: 480
# geo_precision: 3
# source: 233
# source_scale: 12
# notes: 4462
# fatalities: 10
# tags: 97
# timestamp: 1070
Un mapa interactivo usando Folium Library para visualizar los eventos ACLED
Manipur se divide geográficamente en dos regiones distintas: la región del valle y la región montañosa. La región del valle, ubicada en la parte central de Manipur, es relativamente plana y está rodeada de colinas. Es el área más densamente poblada y agrícolamente productiva del estado. La región montañosa, por otro lado, comprende las colinas y montañas circundantes, ofreciendo un terreno más accidentado y montañoso.
El código que se proporciona a continuación crea un mapa interactivo usando la biblioteca Folium para visualizar los eventos ACLED que ocurrieron en Manipur durante los años 2022 y 2023. Traza los eventos como marcadores circulares en el mapa, con el color de cada marcador representando el año correspondiente. También agrega una capa GeoJSON para mostrar los límites de Manipur e incluye un título de mapa, créditos y una leyenda que indica los códigos de color de los años. El mapa final se muestra con todos estos elementos.
import folium # Filter the data for the years 2022 and 2023 df_filtered22_23 = df_filtered[(df_filtered['year'] == 2022) | (df_filtered['year'] == 2023)] # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file manipur_geojson = 'Manipur.geojson' # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define color palette for different years color_palette = {2022: 'red', 2023: 'blue'} # Plot the events on the map with different colors based on the year for index, row in df_filtered22_23.iterrows(): folium.CircleMarker([row['latitude'], row['longitude']], radius=3, color=color_palette[row['year']], fill=True, fill_color=color_palette[row['year']], fill_opacity=0.5).add_to(map) # Add map features folium.TileLayer('cartodbpositron').add_to(map) # Set the map's center and zoom level map.fit_bounds(map.get_bounds()) map.get_root().html.add_child(folium.Element(legend_html)) # Display the map mapSalida:
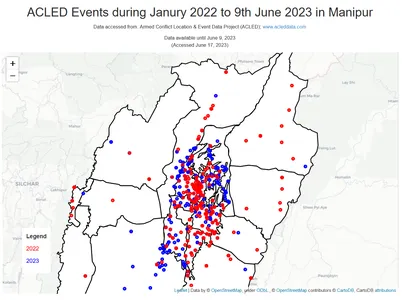
Puede ver que se observa una mayor concentración de eventos en la región del valle central. Esto puede deberse a varios factores, como la densidad de población, la infraestructura, la accesibilidad y la dinámica sociopolítica histórica. La región del valle central, al estar más densamente poblada y económicamente desarrollada, podría presenciar potencialmente más incidentes y eventos en comparación con las áreas montañosas.
Tipos de eventos ACLED
ACLED event_type se refiere a la categorización de diferentes tipos de eventos registrados en el conjunto de datos ACLED. Estos tipos de eventos capturan diversas actividades e incidentes relacionados con conflictos, violencia, protestas y otros eventos de interés. Algunos tipos de eventos en el conjunto de datos de ACLED incluyen violencia contra civiles, explosiones/violencia remota, protestas, disturbios y más. Estos tipos de eventos brindan información sobre la naturaleza y la dinámica de los conflictos e incidentes relacionados registrados en la base de datos de ACLED.
El siguiente código genera un gráfico de barras con eventos agrupados por año que visualiza los tipos de eventos en Manipur, India a lo largo de los años.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Salida:
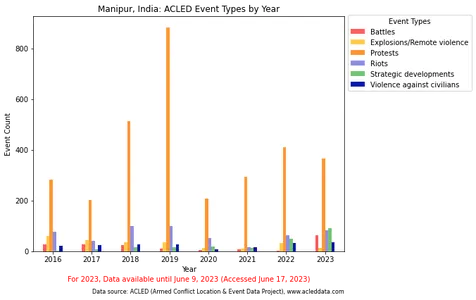
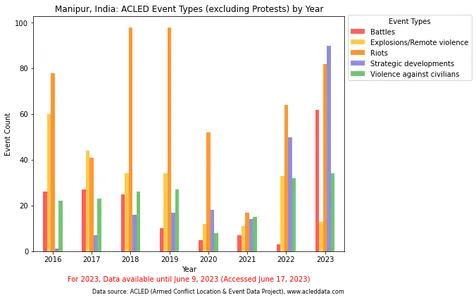
En particular, la visualización de los tipos de eventos en un gráfico de barras destacó el predominio de la categoría "Protestas", lo que podría oscurecer las diferencias relativas y dificultar la comparación precisa de otros tipos de eventos. La visualización se ajustó excluyendo o separando la categoría "Protestas", lo que resultó en una comparación más clara de los tipos de eventos restantes.
El fragmento de código siguiente filtra el tipo de evento "Protestas" de los datos. Luego agrupa los eventos restantes por año y los visualiza en un gráfico de barras, excluyendo la categoría dominante de “Protestas”. La visualización resultante proporciona una visión más clara de los tipos de eventos por año.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Filter out the "Protests" event type df_filteredevent = df_filteredevent[df_filteredevent['event_type'] != 'Protests'] # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types (excluding Protests) by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Salida:
Visualización de la dinámica de eventos: mapeo de tipos y frecuencias de eventos
Usamos los mapas interactivos para trazar eventos en un mapa con diferentes tamaños y colores de marcadores según el tipo de evento y la frecuencia. Representa la distribución espacial y la intensidad de diferentes eventos, lo que permite una rápida identificación de patrones, puntos críticos y tendencias. Este enfoque mejora la dinámica geográfica de los eventos, facilita la toma de decisiones basada en datos y permite la asignación efectiva de recursos e intervenciones específicas en respuesta a los patrones y frecuencias identificados.
Los eventos se trazan como marcadores circulares en el mapa, con colores y tamaños variables según el tipo de evento y la frecuencia, respectivamente.
import folium import json # Filter the data for the year 2023 df_filtered23 = df_filtered[df_filtered['year'] == 2023] # Calculate the event count for each location event_counts = df_filtered23.groupby(['latitude', 'longitude']).size().
reset_index(name='count') # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file with open('Manipur.geojson') as f: manipur_geojson = json.load(f) # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define a custom color palette inspired by ACLED thematic categories event_type_palette = { 'Violence against civilians': '#FF5C5C', # Dark orange 'Explosions/Remote violence': '#FFC94C', # Bright yellow 'Strategic developments': '#FF9633', # Light orange 'Battles': '#8E8EE1', # Purple 'Protests': '#72C472', # Green 'Riots': '#0818A8' # Zaffre } # Plot the events on the map with varying marker size and color based on # the event type and frequency for index, row in event_counts.iterrows(): location = (row['latitude'], row['longitude']) count = row['count'] # Get the event type for the current location event_type = df_filtered23[(df_filtered23['latitude'] == row['latitude']) & (df_filtered23['longitude'] == row['longitude'])] ['event_type'].values[0] folium.CircleMarker( location=location, radius=2 + count * 0.1, color=event_type_palette[event_type], fill=True, fill_color=event_type_palette[event_type], fill_opacity=0.7 ).add_to(map) # Add legends for the year 2023 legend_html = """ <div style="position: fixed; bottom: 50px; right: 50px; z-index: 1000; font-size: 14px; background-color: rgba(255, 255, 255, 0.8); padding: 10px; border-radius: 5px;"> <p><strong>Legend</strong></p> <p><span style="color: #FF5C5C;">Violence against civilians</span></p> <p><span style="color: #FFC94C;">Explosions/Remote violence</span></p> <p><span style="color: #FF9633;">Strategic developments</span></p> <p><span style="color: #8E8EE1;">Battles</span></p> <p><span style="color: #72C472;">Protests</span></p> <p><span style="color: #0818A8;">Riots</span></p> </div> """ map.get_root().html.add_child(folium.Element(legend_html)) # Display the map map Salida:
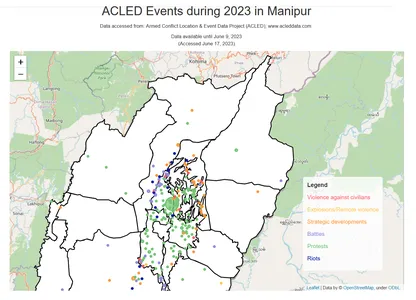
Actores primarios del conflicto
En este paso, obtenemos información sobre las diferentes entidades o grupos involucrados en el conflicto o los eventos en Manipur. En el conjunto de datos ACLED, el "actor1" se refiere al actor principal involucrado en un evento registrado. Representa a la principal entidad o grupo responsable de iniciar o participar en un conflicto o evento específico. La columna “actor1” brinda información sobre la identidad del actor principal, como un gobierno, grupo rebelde, milicia étnica u otras entidades involucradas en el conflicto o evento. Cada valor único en la columna "actor1" representa un actor o grupo distinto involucrado en los eventos registrados.
Luego visualizó los conteos de valores de 'actor1' usando el fragmento de código a continuación:
Este código filtra un DataFrame basado en los conteos de valores de la columna 'actor1', seleccionando solo aquellos con conteos mayores o iguales a 5. Luego visualiza los datos resultantes.
import matplotlib.pyplot as plt # Filter the DataFrame based on value counts >= 5 filtered_df = df_filtered[(df_filtered['year'] != 2023)]['actor1'].
value_counts().loc[lambda x: x >= 5] # Create a figure and axes for the horizontal bar chart fig, ax = plt.subplots(figsize=(8, 6)) # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the horizontal bar chart filtered_df.plot.barh(ax=ax, color=color_palette) # Add labels and title ax.set_xlabel('Count') ax.set_ylabel('Actor1') ax.set_title('Value Counts of Actor1 (>= 5) (January 2016 to 9th December 2022)', pad=55) # Set the data availability information data_info = "Accessed on June 17, 2023" # Add credits and data availability information plt.text(0.5, 1.1, "Data accessed from:", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.05, "Armed Conflict Location & Event Data Project (ACLED); www.acleddata.com", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.0, data_info, ha='center', transform=ax.transAxes, fontsize=10) # Display the count next to each bar for i, v in enumerate(filtered_df.values): ax.text(v + 3, i, str(v), color='black') # Display the plots plt.tight_layout() plt.show() Salida:
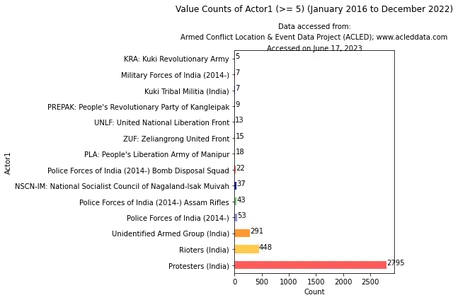
El gráfico representa datos desde enero de 2016 hasta el 9 de diciembre de 2022. Además, la condición "recuento mayor o igual a 5" significa que solo los actores con una frecuencia de ocurrencia de 5 o más se incluirán en el análisis y se mostrarán en el gráfico. .
Como se muestra en el siguiente fragmento de código, se utilizaron las siguientes visualizaciones para comparar los recuentos de categorías entre 2022 y 2023.
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip
(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Adjust the spacing between lines plt.subplots_adjust(top=0.9) # Display the plot plt.show()Salida:
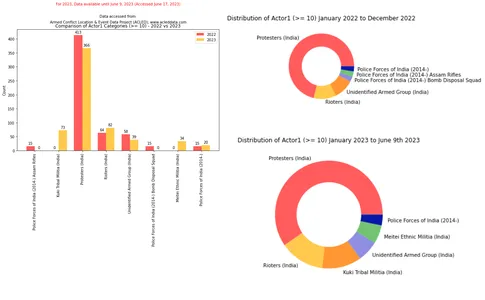
La comparación de los datos ACLED de Manipur para el año 2022 y los datos hasta el 9 de junio de 2023 se puede obtener utilizando el siguiente fragmento de código:
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Display the plot plt.show() Salida:
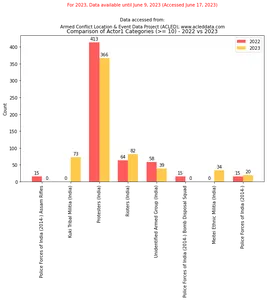
Análisis de intensidad de conflicto
El siguiente fragmento de código prepara los datos para su posterior análisis o visualización al convertir la columna 'event_date' a datetime. Realice una tabulación cruzada y reestructure el DataFrame para facilitar la interpretación y el uso. Utiliza la función pd.crosstab() para crear una tabulación cruzada (tabla de frecuencia) entre 'event_date' (convertido a períodos mensuales usando dt.to_period('m')) y la columna 'inter1' en 'df_filtered'. Posteriormente, agrupa el DataFrame filtrado por 'event_date' y calcula la suma de 'fatalities' para cada fecha. Calcule y agregue la suma de muertes por mes al DataFrame de tabulación cruzada existente, lo que da como resultado 'df_conflicts'. Incluye tanto los datos de eventos categorizados como la información correspondiente a las muertes para un análisis posterior.
Implementación de código
import pandas as pd # Convert 'event_date' column to datetime data type df_filtered['event_date'] = pd.to_datetime(df_filtered['event_date']) # Perform the crosstab operation df_cross = pd.crosstab(df_filtered['event_date'].dt.to_period('m'), df_filtered['inter1']) # Rename the columns df_cross.columns = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Convert the period index to date df_cross['event_date'] = df_cross.index.to_timestamp() # Reset the index df_cross.reset_index(drop=True, inplace=True) df2 = df_filtered.copy() df2['event_date'] = pd.to_datetime(df2['event_date']) fatality_filtered = (df2 .filter(['event_date','fatalities']) .groupby(['event_date']) .fatalities .sum() ) df_fatality_filtered = fatality_filtered.to_frame().reset_index() df_fatality_month= df_fatality_filtered.resample('M', on="event_date").sum() df_fatality_month = df_fatality_month.reset_index() df_fatalities = df_fatality_month.drop(columns=['event_date']) df_concat = pd.concat([df_cross, df_fatalities], axis=1) df_conflicts = df_concat.copy() Salida:
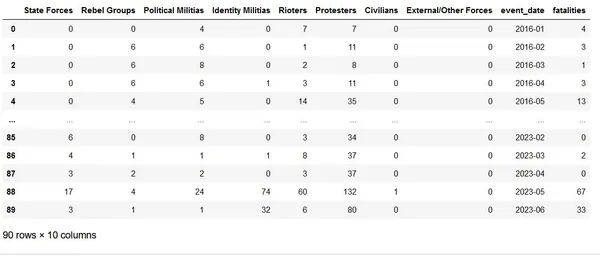
El código visualiza el análisis de la intensidad del conflicto para eventos mensuales en Manipur categorizados por tipo de actor, ponderados por muertes reportadas. El ancho de las líneas se basa en el número de muertes para cada tipo de actor. Este tipo de análisis nos permite identificar patrones y el impacto relativo de los diferentes tipos de actores involucrados en los conflictos. Proporcione información valiosa para un mayor análisis y toma de decisiones en los estudios de conflictos.
import plotly.graph_objects as go fig = go.Figure() fig.add_trace(go.Scatter( name='State Forces', x=df_conflicts['event_date'].dt.strftime('%Y-%m'), y=df_conflicts['State Forces'], mode='markers+lines', marker=dict(color='darkviolet', size=4), showlegend=True )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']+df_conflicts['fatalities']/5, mode='lines', marker=dict(color="#444"), line=dict(width=1), hoverinfo='skip', showlegend=False )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']-df_conflicts['fatalities']/5, marker=dict(color="#444"), line=dict(width=1), mode='lines', fillcolor='rgba(68, 68, 68, 0.3)', fill='tonexty', hoverinfo='text', hovertemplate='<br>%{x|%bn%Y}<br><i>Fatalities: %{text}</i>', text=['{}'.format(i) for i in df_conflicts['fatalities']], showlegend=False )) #similiray insert add_trace for other event types too here... fig.update_xaxes( dtick="M3", # Set the tick frequency to 3 months (quarterly) tickformat="%bn%Y" ) fig.update_layout( yaxis_title='No: of Events', title={ 'text': 'Conflict Intensity Analysis: Events in Manipur categorized by actor type, weighted by reported fatalities', 'y': 0.95, 'x': 0.5, 'xanchor': 'center', 'yanchor': 'top', 'font': {'size': 20} }, annotations=[ dict( text="January 2016 to June 9th 2023|Data accessed from: Armed Conflict Location & Event Data Project (ACLED),www.acleddata.com", xref="paper", yref="paper", x=0.5, y=1.06, showarrow=False, font={'size': 12} ) ], hovermode="x", xaxis=dict( showgrid=False ), yaxis=dict( showgrid=False ) ) fig.data[0].marker.size = 4 fig.data[3].marker.size = 4 fig.data[6].marker.size = 4 fig.data[9].marker.size = 4 fig.data[12].marker.size = 4 fig.data[15].marker.size = 4 fig.data[18].marker.size = 4 fig.data[21].marker.size = 4 fig.show()Salida:
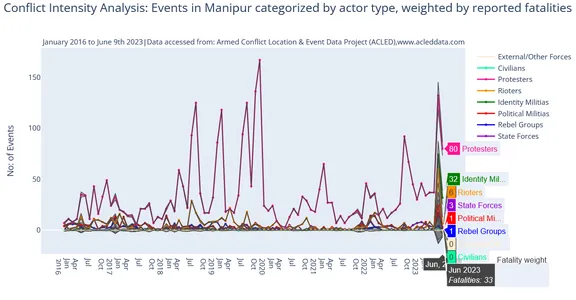
Un valor de variable más alto (en este caso, 'Manifestantes') que otros en un gráfico de varias líneas. Puede distorsionar la percepción, lo que dificulta comparar e interpretar con precisión las tendencias de diferentes variables. El predominio de una variable puede reducirse, ya que se vuelve un desafío evaluar los cambios relativos y las relaciones entre las otras variables. La visualización puede sufrir, con imágenes comprimidas o desordenadas, pérdida de detalles en variables de menor valor y un énfasis desequilibrado que puede sesgar las interpretaciones.
Para mitigar estos contras y tener una visualización clara de la intensidad del conflicto reciente, filtró los datos para los eventos de conflicto de 2023 y 2022 y a continuación se muestra el resultado:
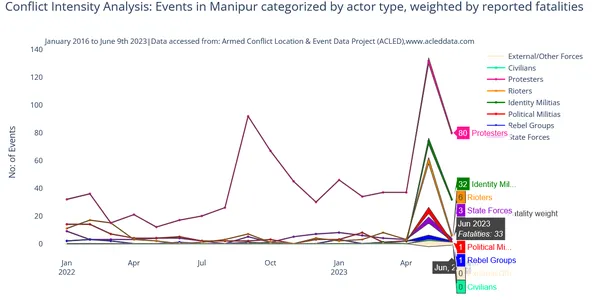
Establezca la fecha como índice para el análisis de tendencias de conflictos utilizando los datos diarios y obtenga el siguiente marco de datos para un análisis más detallado.
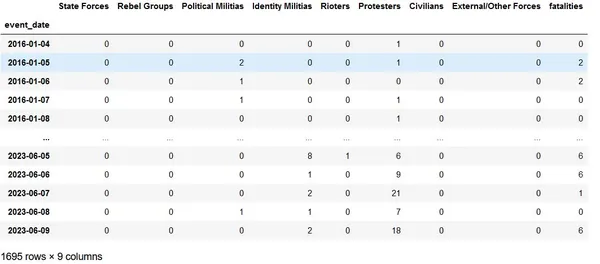
Promedios móviles y análisis de tendencias de conflictos
En el análisis de tendencias de conflictos, las ventanas móviles de 30 y 7 días son comunes. Se utilizan para calcular promedios móviles o medios de datos relacionados con conflictos durante un período de tiempo específico.
La ventana móvil se refiere a un intervalo de tiempo de tamaño fijo que se mueve a lo largo de la línea de tiempo, incluida una cantidad específica de puntos de datos dentro de ese intervalo. Por ejemplo, en una ventana móvil de 30 días, el intervalo incluye el día actual más los 29 días anteriores. En una ventana móvil de 7 días, el intervalo incluye el día actual más los 6 días anteriores, lo que representa el valor de los datos de una semana.
El promedio móvil se calcula tomando el promedio de los puntos de datos dentro de la ventana. Proporciona una representación suavizada de los datos, lo que reduce las fluctuaciones a corto plazo y destaca las tendencias a más largo plazo.
Al calcular las medias móviles de 30 y 7 días en el análisis de conflictos, los analistas pueden obtener información sobre los patrones y tendencias generales en los eventos de conflicto a lo largo del tiempo. Puede identificar tendencias a largo plazo al mismo tiempo que captura fluctuaciones a corto plazo en los datos. Estos promedios móviles pueden ayudar a revelar patrones subyacentes y brindar una imagen más clara de la evolución de la dinámica del conflicto.
Fragmentos de código
El siguiente fragmento de código crea las tramas para cada escenario de conflicto.
import matplotlib.pyplot as plt import pandas as pd # Variables to calculate rolling means for variables = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Calculate rolling means for each variable data_7d_rol = {} data_30d_rol = {} for variable in variables: data_7d_rol[variable] = data_ts[variable].rolling(window=7, min_periods=1).mean() data_30d_rol[variable] = data_ts[variable].rolling(window=30, min_periods=1).mean() # Plotting separate graphs for each variable for variable in variables: fig, ax = plt.subplots(figsize=(11, 4)) # Plotting 7-day rolling mean ax.plot(data_ts.index, data_7d_rol[variable], linewidth=2, label='7-d Rolling Mean') # Plotting 30-day rolling mean ax.plot(data_ts.index, data_30d_rol[variable], color='0.2', linewidth=3, label='30-d Rolling Mean') # Beautification of plot ax.legend() ax.set_xlabel('Year') ax.set_ylabel('Events accounted by ' + variable) ax.set_title('Trends in ' + variable + ' Conflicts') # Add main heading and subheading fig.suptitle(main_title, fontsize=14, fontweight='bold', y=1.05) #ax.text(0.5, -0.25, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') ax.text(0.5, 0.95, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') plt.tight_layout() plt.show() Salida:
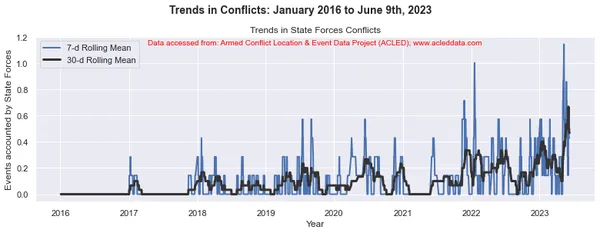
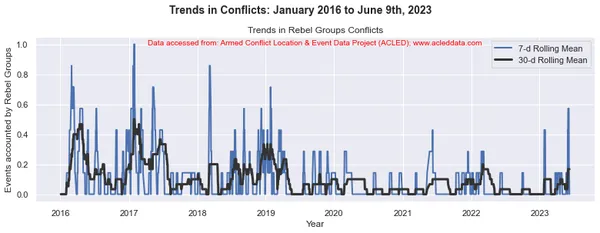
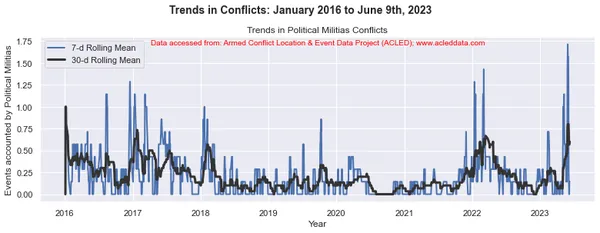
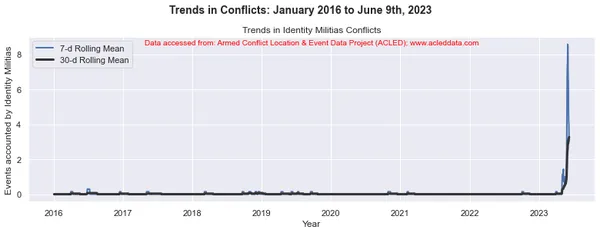

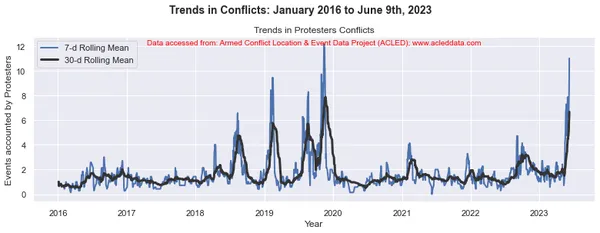
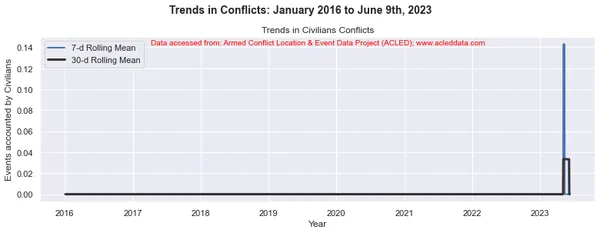
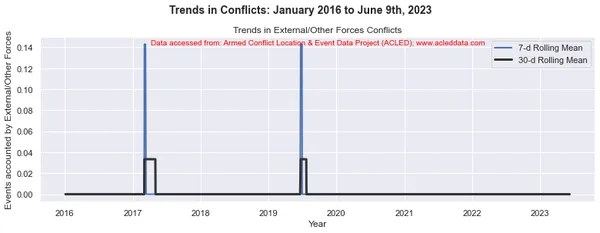
Note: Los gráficos generados y el análisis de datos realizado en este blog tienen el único propósito de demostrar la aplicación de técnicas de ciencia de datos. Estos análisis no extraen conclusiones ni interpretaciones definitivas sobre la compleja dinámica de los conflictos. Abordar el análisis de conflictos con cautela, reconociendo la naturaleza multifacética de los conflictos y la necesidad de una comprensión integral y específica del contexto más allá del alcance de este análisis.
Conclusión
El blog explora los eventos y patrones de conflicto en Manipur, India, utilizando el análisis de datos de ACLED. Para visualizar los eventos de ACLED en Manipur, use mapas interactivos y otras visualizaciones. El análisis de los tipos de eventos en Manipur reveló varias actividades e incidentes relacionados con conflictos, violencia, protestas y otros eventos de interés. Para comprender las tendencias en los eventos de conflicto, calculamos las medias móviles de 30 y 7 días. Estos promedios móviles proporcionaron una representación suavizada de los datos, reduciendo las fluctuaciones a corto plazo y destacando las tendencias a más largo plazo. En general, estos hallazgos pueden contribuir a una mejor comprensión de la dinámica del conflicto en la región y pueden respaldar más investigaciones y procesos de toma de decisiones.
Puntos clave
- Análisis interactivo de datos ACLED: sumérjase en datos de conflictos del mundo real y obtenga información.
- Los mapas interactivos visualizan la dinámica espacial y temporal de los conflictos.
- Destaca la importancia de visualizar y analizar datos para una comprensión efectiva.
- La identificación de los actores principales revela las entidades clave que configuran el panorama del conflicto.
- Los cálculos de la media móvil descubren fluctuaciones a corto plazo y tendencias a largo plazo en los conflictos.
Espero que hayas encontrado este artículo informativo. No dude en ponerse en contacto conmigo en Etiqueta LinkedIn. Conectémonos y trabajemos para aprovechar los datos para un cambio positivo.
Preguntas frecuentes
R. El conjunto de datos ACLED (Armed Conflict Location & Event Data Project) es un recurso integral que rastrea y registra información detallada sobre eventos de conflicto en todo el mundo, incluida la violencia política, las protestas y los disturbios. Contribuye a analizar los eventos de conflicto al proporcionar a los investigadores y a los encargados de formular políticas información valiosa sobre los patrones, la dinámica y los actores involucrados, lo que ayuda a la toma de decisiones informada y la investigación relacionada con el conflicto.
R. Los mapas interactivos y las visualizaciones permiten la exploración y el análisis de patrones espaciales y temporales de conflictos al proporcionar una representación visual de datos que permite la identificación de tendencias, puntos críticos y correlaciones, mejorando la comprensión de la dinámica del conflicto.
R. Es importante visualizar y comparar cuidadosamente los tipos de eventos, especialmente cuando una categoría domina el conjunto de datos, para evitar eclipsar las diferencias relativas y evaluar con precisión la importancia y la dinámica de otros tipos de eventos.
A. La identificación y el análisis de los principales actores involucrados en los conflictos brinda información sobre las entidades y grupos clave responsables de iniciar o participar en los eventos, lo que ayuda a comprender la dinámica, las motivaciones y las posibles interacciones entre los diferentes actores.
R. Los cálculos de la media móvil brindan una representación suavizada de los incidentes de conflicto al promediar los puntos de datos durante una ventana de tiempo específica, lo que permite identificar tanto las fluctuaciones a corto plazo como las tendencias a largo plazo en los datos.
Referencias
1. Raleigh, Clionadh, Andrew Linke, Håvard Hegre y Joakim Karlsen. (2010). "Presentación de datos de eventos y ubicación de conflictos armados ACLED". Revista de Investigación para la Paz 47(5) 651-660.
2. ALED. (2023). “Proyecto de Datos de Eventos y Ubicación de Conflictos Armados (ACLED) Codebook, 2023.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/exploring-conflict-trends-and-patterns-manipur-acled-data-analysis/

