Introducción
Noviembre ha sido dramático en el espacio de la IA. Ha sido todo un recorrido desde el lanzamiento de las tiendas GPT, GPT-4-turbo, hasta el fiasco de OpenAI. Pero esto plantea una pregunta importante: ¿cuán confiables son los modelos cerrados y las personas detrás de ellos? No será una experiencia agradable cuando el modelo que utiliza en producción deje de funcionar debido a algún drama corporativo interno. Esto no es un problema con los modelos de código abierto. Tienes control total sobre los modelos que implementas. Tienes soberanía sobre tus datos y modelos por igual. Pero, ¿es posible sustituir un modelo de sistema operativo por GPT? Afortunadamente, muchos modelos de código abierto ya tienen un rendimiento igual o superior al de los modelos GPT-3.5. Este artículo explorará algunas de las alternativas de mejor rendimiento para LLM y LMM de código abierto.
OBJETIVOS DE APRENDIZAJE
- Discuta sobre los modelos de lenguaje grande de código abierto.
- Explore modelos de lenguaje de código abierto y modelos multimodales de última generación.
- Una leve introducción a la cuantificación de modelos de lenguajes grandes.
- Obtenga información sobre herramientas y servicios para ejecutar LLM localmente y en la nube.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué es un modelo de código abierto?
Un modelo se denomina código abierto cuando los pesos y la arquitectura del modelo están disponibles gratuitamente. Estos pesos son parámetros previamente entrenados de un modelo de lenguaje grande, por ejemplo, La llama de Meta. Suelen ser modelos básicos o modelos básicos sin ningún ajuste. Cualquiera puede utilizar los modelos y ajustarlos con datos personalizados para realizar acciones posteriores.
¿Pero están abiertos? ¿Qué pasa con los datos? La mayoría de los laboratorios de investigación no publican los datos que se utilizan para entrenar los modelos base debido a muchas preocupaciones con respecto al contenido protegido por derechos de autor y la sensibilidad de los datos. Esto también nos lleva a la parte de licencias de modelos. Cada modelo de código abierto viene con una licencia similar a cualquier otro software de código abierto. Muchos modelos básicos como Llama-1 vienen con licencias no comerciales, lo que significa que no puedes usar estos modelos para ganar dinero. Pero modelos como Mistral7B y Zephyr7B vienen con licencias Apche-2.0 y MIT, que pueden usarse en cualquier lugar sin preocupaciones.
Alternativas de código abierto
Desde el lanzamiento de Llama, ha habido una carrera armamentista en el espacio de código abierto para alcanzar los modelos OpenAI. Y los resultados han sido alentadores hasta ahora. Dentro de un año de GPT-3.5, Tenemos modelos que funcionan a la par o mejor que GPT-3.5 con menos parámetros. Pero GPT-4 Sigue siendo el mejor modelo para realizar tareas generales, desde razonamiento y matemáticas hasta generación de código. Si analizamos más a fondo el ritmo de la innovación y la financiación en modelos de código abierto, pronto tendremos modelos que se aproximarán al rendimiento de GPT-4. Por ahora, analicemos algunas excelentes alternativas de código abierto a estos modelos.
La llama de Meta 2
Meta lanzó su mejor modelo, Llama-2, en julio de este año, y se convirtió en un éxito instantáneo debido a sus impresionantes capacidades. Meta lanzó cuatro modelos Llama-2 con diferentes tamaños de parámetros. Llama-7b, 13b, 34b y 70b. Los modelos eran lo suficientemente buenos como para superar a otros modelos abiertos en sus respectivas categorías. Pero ahora, varios modelos como mistral-7b y Zephyr-7b superan a los modelos Llama más pequeños en muchos puntos de referencia. Llama-2 70b sigue siendo uno de los mejores de su categoría y es digno de una alternativa al GPT-4 para tareas como resumir, traducir automáticamente, etc.
En varios puntos de referencia, Llama-2 tuvo un mejor desempeño que GPT-3.5 y pudo acercarse a GPT-4, lo que lo convierte en un digno sustituto de GPT-3.5 y, en algunos casos, de GPT-4. El siguiente gráfico es una comparación de rendimiento de los modelos Llama y GPT por Cualquierescala.
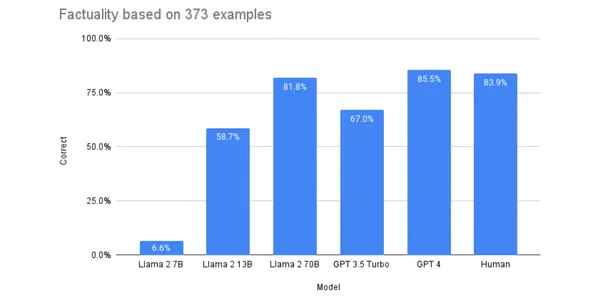
Para obtener más información sobre Llama-2, consulte este blog en HuggingFace. Se ha demostrado que estos LLM funcionan bien cuando se ajustan con precisión en conjuntos de datos personalizados. Podemos ajustar los modelos para que funcionen mejor en tareas específicas.
Diferentes laboratorios de investigación también han lanzado versiones mejoradas de Llama-2. Estos modelos han mostrado mejores resultados que los modelos originales en muchos puntos de referencia. Este modelo Llama-2 afinado, Nous-Hermes-Llama2-70b de Nous Research, ha sido ajustado en más de 300,000 instrucciones personalizadas, lo que lo hace mejor que el original. meta-llama/Llama-2-70b-chat-hf.
Echa un vistazo a HuggingFace clasificación. Puedes encontrar modelos Llama-2 afinados con mejores resultados que los modelos originales. Esta es una de las ventajas de los modelos de sistema operativo. Hay muchos modelos para elegir según los requisitos.
Mistral-7B
Desde el lanzamiento de Mistral-7B, se ha convertido en el favorito de la comunidad de código abierto. Se ha demostrado que funciona mucho mejor que cualquier modelo de la categoría y se acerca a las capacidades del GPT-3.5. Este modelo puede sustituir a Gpt-3.5 en muchos casos, como resumir, parafrasear, clasificar, etc.
Pocos parámetros del modelo garantizan un modelo más pequeño que pueda ejecutarse localmente o alojarse con tarifas más económicas que los más grandes. Aquí está el espacio original de HuggingFace para Mistral-7b. Además de ser un gran intérprete, una cosa que hace que Mistral-7b se destaque es que es un modelo en bruto sin censura alguna. La mayoría de los modelos son lobotomizados con pesados RLHF antes del lanzamiento, lo que los hace indeseables para muchas tareas. Pero esto hace que Mistral-7B sea deseable para realizar tareas específicas de temas del mundo real.
Gracias a la vibrante comunidad de código abierto, existen bastantes alternativas optimizadas con mejor rendimiento que los modelos Mistral7b originales.
AbiertoHermes-2.5
OpenHermes-2.5 es un modelo perfeccionado de Mistral. Ha mostrado resultados notables en todas las métricas de evaluación (GPT4ALL, TruthfullQA, AgiEval, BigBench). Para muchas tareas, esto es indistinguible de GPT-3.5. Para obtener más información sobre OpenHermes, consulte este repositorio de HF: teknio/OpenHermes-2.5-Mistral-7B.
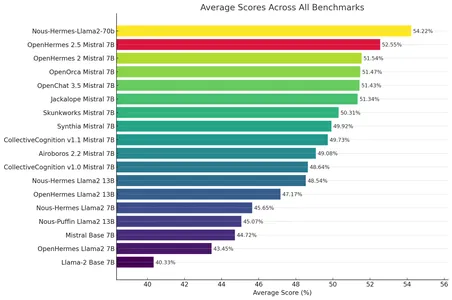
Céfiro-7b
Zephyr-7b es otro modelo perfeccionado de Mistral-7b de HuggingFace. Huggingface ha perfeccionado completamente el Mistral-7b utilizando DPO (Optimización de preferencia directa). Zephyr-7b-beta funciona a la par de modelos más grandes como GPT-3.5 y Llama-2-70b en muchas tareas, incluida la escritura, materias de humanidades y juegos de roles. A continuación se muestra una comparación entre Zephyr-7b y otros modelos en MTbench. Este puede ser un buen sustituto de GPT-3.5 en muchos sentidos.
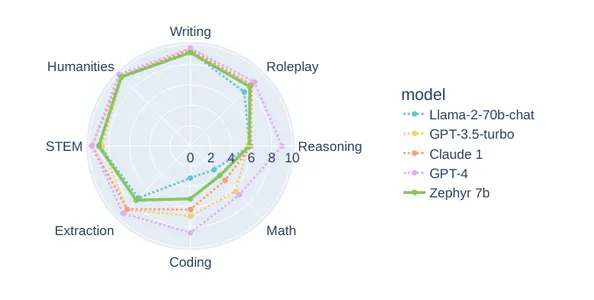
Aquí está el repositorio oficial de HuggingFace: HuggingFaceH4/zephyr-7b-beta.
Chat neuronal Intel
El chat neuronal es un 7B LLM modelo perfeccionado a partir del Mistral-7B por Intel. Ha demostrado un rendimiento notable, encabezando la clasificación de Huggingface entre todos los modelos 7B. El NeuralChat-7b está ajustado y entrenado sobre Gaudi-2, un chip Intel para acelerar las tareas de IA. El excelente rendimiento de NeuralChat es el resultado del ajuste supervisado y la preferencia de optimización directa (DPO) sobre los conjuntos de datos de Orca y Slim-Orca.
Aquí está el repositorio HuggingFace de NeuralChat: Intel/neural-chat-7b-v3-1.
Grandes modelos multimodales de código abierto
Después del lanzamiento de GPT-4 Vision, ha habido un mayor interés en modelos multimodales. Los modelos de lenguaje grandes con visión pueden ser excelentes en muchos casos de uso del mundo real, como la respuesta a preguntas en imágenes y la narración de videos. En uno de esos casos de uso, Tldraw ha lanzado un pizarra de IA que le permite crear componentes web a partir de dibujos en la pizarra utilizando la increíble capacidad del GPT-4V para interpretar imágenes en códigos.
Pero el código abierto está llegando más rápido. Muchos laboratorios de investigación lanzaron grandes modelos multimodales como Llava, Baklava, Fuyu-8b, etc.
llama
La Llava (Asistente de lenguaje y visión grande) es un modelo multimodal con 13 mil millones de parámetros. Llava conecta Vicuña-13b LLM y un codificador visual previamente entrenado CLIP ViT-L/14. Se ha perfeccionado a partir del conjunto de datos de control de calidad de Visual Chat y Science para lograr un rendimiento similar al de GPT-4V en muchas ocasiones. Esto se puede utilizar en tareas visuales de control de calidad.
BakLlava
BakLlava de SkunkWorksAI es otro gran modelo multimodal. Tiene Mistral-7b como LLM base aumentado con arquitectura Llava-1.5. Ha mostrado resultados prometedores a la par de Llava-13b a pesar de ser más pequeño. Este es el modelo que debe buscar cuando necesita un modelo más pequeño con buena inferencia visual.
Fuyu-8b
Otra alternativa de código abierto es Fuyu-8b. Es un modelo de lenguaje multimodal capaz de Adept. Fuyu es un transformador solo decodificador sin codificador visual; esto es diferente de Llava, donde se usa CLIP.
A diferencia de otros modelos multimodales que utilizan un codificador de imágenes para alimentar a LLM con datos de imágenes, este proyecta linealmente las partes de las imágenes en la primera capa del transformador. Trata al decodificador del transformador como un transformador de imagen. A continuación se muestra una ilustración de la arquitectura Fuyu.
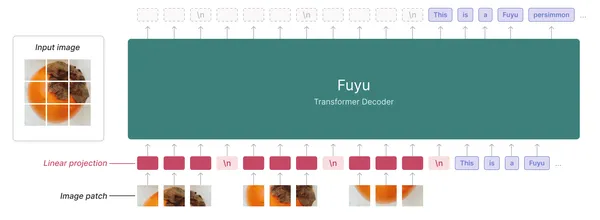
Para obtener más información sobre Fuyu-8b, consulte este artículo. Repositorio HuggingFace adepto/fuyu-8b
¿Cómo utilizar los LLM abiertos?
Ahora que estamos familiarizados con algunos de los LLM y LMM de código abierto de mejor rendimiento, la pregunta es cómo obtener inferencias a partir de un modelo abierto. Hay dos formas en que podemos obtener inferencias de los modelos de código abierto. O descargamos modelos en hardware personal o nos suscribimos a un proveedor de nube. Ahora, esto depende de su caso de uso. Estos modelos, incluso los más pequeños, requieren un uso intensivo de computación y exigen una gran cantidad de RAM y VRAM. Inferir estos modelos básicos en hardware comercial es muy difícil. Para facilitar esto, los modelos deben estar cuantizados. Entonces, comprendamos qué es la cuantificación del modelo.
Cuantización
La cuantificación es la técnica de reducir la precisión de números enteros de coma flotante. Por lo general, los laboratorios lanzan modelos con pesos y activaciones con mayor precisión de punto flotante para lograr un rendimiento de última generación (SOTA). Esto hace que la informática de los modelos sea hambrienta y no sea ideal para ejecutarse localmente o alojarse en la nube. La solución a esto es reducir la precisión de los pesos y las incrustaciones. Esto se llama cuantificación.
Los modelos SOTA suelen tener precisión float32. Hay diferentes casos en cuantización, desde fp32 -> fp16, fp-32-> int8, fp32->fp8 y fp32->fp4. Esta sección solo discutirá la cuantización a int8 o la cuantización de enteros de 8 bits.
Cuantización a int8
La representación int8 solo puede contener 256 caracteres (con signo [-128,127], sin signo [0, 256]), mientras que fp32 puede tener una amplia gama de números. La idea es encontrar la proyección equivalente de los valores de fp32 en [a,b] al formato int8.
Si X es un número fp32 en el rango [a,b,], entonces el esquema de cuantificación es
X = S*(X_q – z)
- X_q = el valor cuantificado asociado con X
- S es el parámetro de escala. Un número positivo de fp32.
- z es el punto cero. Es el valor int8 correspondiente al valor 0 en fp32.
Por lo tanto, X_q = redondo(X/S + z) ∀X ∈ [a,b]
Para fp3,2, los valores más allá de [a,b] se recortan a la representación más cercana
X_q = clip( X_q = redondo(a/S + z) + redondo(X/S + z) + X_q = redondo(b/S + z) )
- round(a/S + z) es el número más pequeño y round(b/S + z) es el número más grande en dicho formato numérico.
Esta es la ecuación para Cuantización afín o de punto cero.. Se trataba de una cuantificación de enteros de 8 bits; También existen esquemas de cuantificación para fp8 de 8 bits, 4 bits (fp4, nf4) y 2 bits (fp2). Para obtener más información sobre la cuantificación, consulte este artículo sobre AbrazandoCara.
La cuantificación de modelos es una tarea compleja. Existen múltiples herramientas de código abierto para cuantificar LLM, como llama.cpp, AutoGPTQ, llm-awq, etc. Llama cpp cuantifica modelos usando GGUF, AutoGPTQ usando GPTQ y llm-awq usando el formato AWQ. Estos son diferentes métodos de cuantificación para reducir el tamaño del modelo.
Por lo tanto, si desea utilizar un modelo de código abierto para la inferencia, tiene sentido utilizar un modelo cuantificado. Sin embargo, cambiará algo de calidad de inferencia por un modelo más pequeño que no cuesta una fortuna.
Consulte este repositorio de HuggingFace para ver modelos cuantificados: https://huggingface.co/TheBloke
Ejecución de modelos localmente
A menudo, para diversas necesidades, es posible que necesitemos ejecutar modelos localmente. Hay mucha libertad al ejecutar modelos localmente. Ya sea que cree una solución personalizada para documentos confidenciales o con fines de experimentación, los LLM locales brindan mucha más libertad y tranquilidad que los modelos de código cerrado.
Existen múltiples herramientas para ejecutar modelos localmente. Los más populares son vLLM, Ollama y LMstudio.
VLLM
La vllm es un software alternativo de código abierto escrito en Python que le permite ejecutar LLM localmente. La ejecución de modelos en vLLM requiere ciertas especificaciones de hardware, generalmente con una capacidad de cálculo de vRAM de más de siete y una RAM superior a 16 GB. Debería poder ejecutarlo en un Collab para realizar pruebas. VLLM actualmente admite el formato de cuantificación AWQ. Estos son los modelos con los que puedes utilizar vllm. Y así es como podemos ejecutar un modelo localmente.
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="mistralai/Mistral-7B-v0.1")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")El vLLM también admite puntos finales OpenAI. Por lo tanto, puede utilizar el modelo como reemplazo directo de la implementación OpenAI existente.
import openai
# Modify OpenAI's API key and API base to use vLLM's API server.
openai.api_key = "EMPTY"
openai.api_base = "http://localhost:8000/v1"
completion = openai.Completion.create(model="mistralai/Mistral-7B-v0.1",
prompt="San Francisco is a")
print("Completion result:", completion)Aquí, inferiremos del modelo local utilizando OpenAI SDK.
Ollama
Ollama es otra herramienta CLI alternativa de código abierto en Go que nos permite ejecutar modelos de código abierto en hardware local. Ollama soporta los modelos cuantificados GGUF.
Cree un archivo de modelo en su directorio y ejecútelo
FROM ./mistral-7b-v0.1.Q4_0.ggufCree un modelo de Ollama a partir del archivo del modelo.
ollama create example -f ModelfileAhora, ejecuta tu modelo.
ollama run example "How to kill a Python process?"Ollama también te permite ejecutar modelos Pytorch y HuggingFace. Para obtener más información, consulte su repositorio oficial.
LMstudio
LMstudio es un software de código cerrado que le permite ejecutar cómodamente cualquier modelo en su PC. Esto es ideal si desea un software dedicado para ejecutar modelos. Tiene una buena interfaz de usuario para usar modelos locales. Está disponible en Mac (M1, M2), Linux (beta) y Windows.
También admite modelos formateados GGUF. Echa un vistazo a sus Página oficial para más. Asegúrese de que sea compatible con las especificaciones de su hardware.
Modelos de proveedores de nube
Ejecutar modelos localmente es excelente para experimentación y casos de uso personalizados, pero usarlos en aplicaciones requiere que los modelos estén alojados en la nube. Puede alojar su modelo en la nube a través de proveedores de modelos LLM dedicados, como Reproducir exactamente y Breve desarrollo. Puede alojar, ajustar y obtener inferencias de modelos. Proporcionan un servicio elástico y escalable para alojar LLM. La asignación de recursos cambiará según el tráfico de su modelo.
Conclusión
El desarrollo de modelos de código abierto se está produciendo a un ritmo vertiginoso. Dentro de un año de ChatGPT, tenemos modelos mucho más pequeños que compiten con él en muchos puntos de referencia. Esto es solo el comienzo y un modelo a la par del GPT-4 podría estar a la vuelta de la esquina. Últimamente, han surgido dudas sobre la integridad de las organizaciones detrás de modelos de código cerrado. Como desarrollador, no querrá que su modelo y los servicios creados sobre él se pongan en peligro. El código abierto resuelve esto. Usted conoce su modelo y es dueño del modelo. Los modelos de código abierto brindan mucha libertad. También puede tener una estructura híbrida con modelos OS y OpenAI para reducir costos y dependencia. Por lo tanto, este artículo trata sobre una introducción a algunos modelos de sistemas operativos de excelente rendimiento y conceptos relacionados con su ejecución.
Entonces, aquí están las conclusiones clave:
- Los modelos abiertos son sinónimo de soberanía. Los modelos de código abierto proporcionan el factor de confianza tan necesario que los modelos cerrados no logran.
- Los modelos de lenguajes grandes como Llama-2 y Mistral y sus ajustes han superado a GPT-3.5 en muchas tareas, lo que los convierte en sustitutos ideales.
- Los grandes modelos multimodales como Llava, BakLlava y Fuyu-8b han demostrado ser útiles en muchas tareas de clasificación y control de calidad.
- Los LLM son grandes y requieren mucha computación. Por lo tanto, ejecutarlos localmente requiere cuantificación.
- La cuantización es una técnica para reducir el tamaño del modelo mediante la conversión de pesos y flotadores de activación a bits más pequeños.
- El alojamiento y la inferencia local desde modelos de sistema operativo requieren herramientas como LMstudio, Ollama y vLLM. Para implementar en la nube, utilice servicios como Replicate y Brev.
Preguntas frecuentes
R. Sí, existen alternativas a ChatGPT, como Llama-2 chat, Mistral-7b, Vicuña-13b, etc.
R. Es posible ejecutar LLM de código abierto en la máquina local utilizando herramientas como LMstudio, Ollama y vLLM. También depende de la capacidad de la máquina local.
R. Los modelos de código abierto son mejores y más efectivos que Gpt-3.5 en muchas tareas, pero GPT-4 sigue siendo el mejor modelo disponible.
R. Dependiendo del caso de uso, los modelos de código abierto pueden ser más baratos que los modelos GPT, pero deben ajustarse para funcionar mejor en tareas específicas.
Respuesta. Los chatbots son LLM que se han perfeccionado a través de conversaciones similares a las de un chat.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/open-source-alternatives-to-openai-models/

