Introducción
Google Big Query es un servicio de plataforma como servicio (PaaS) seguro, accesible, completamente administrado, de pago por uso, sin servidor y de almacenamiento de datos de múltiples nubes proporcionado por Google Cloud Platform eso ayuda a generar conocimientos útiles a partir de big data que ayudarán a las partes interesadas del negocio en la toma de decisiones efectiva. Google Big Query proporciona una capacidad de aprendizaje automático integrada y un motor de consulta SQL para escribir SQL, que se puede usar para analizar grandes conjuntos de datos. Podemos desarrollar un almacén de datos seguro y altamente accesible utilizando Google Big Query.
Udemy es una de las plataformas de aprendizaje en línea más populares. Udemy ofrece contenido de aprendizaje de alta calidad en diseño, marketing, desarrollo, finanzas y contabilidad, TI y software, fotografía y video, salud y bienestar, productividad en la oficina, etc. en diferentes idiomas. Udemy es una importante fuente de información para muchos estudiantes, autónomos y profesionales en activo. Udemy es una de las mejores plataformas para aprender Python y React y prepararse para la certificación de AWS y Azure. Sin embargo, los alumnos pueden estar interesados en tomar cursos de instructores más alineados con sus títulos de trabajo, cursos tomados por muchos usuarios y desarrolladores certificados como AWS certificado, certificado de Salesforce, etc. Para abordar este problema, crearemos un almacén de datos para explorar las tendencias y las perspectivas de los cursos de Udemy mediante Google Big Query.
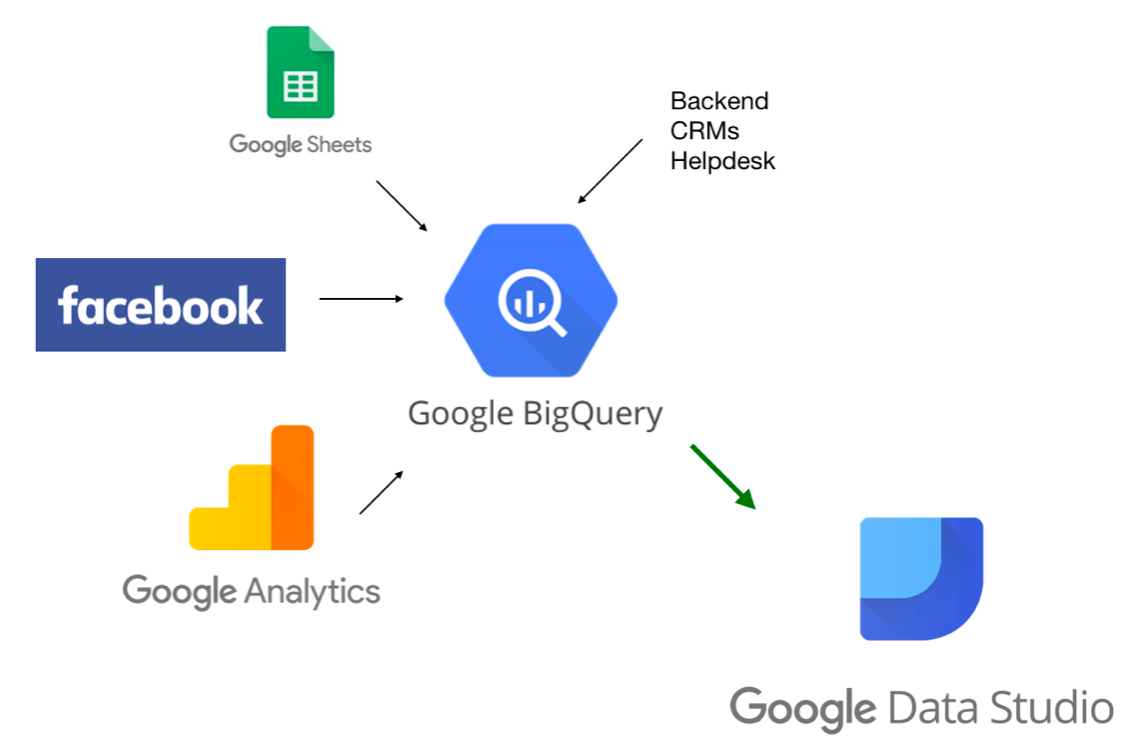
Casi todos los principales proveedores de servicios en la nube, como Google, Amazon, Microsoft, etc., actualmente brindan herramientas de almacenamiento de datos. Las herramientas de almacenamiento de datos basadas en la nube son altamente escalables y brindan recuperación ante desastres. Usando un almacenamiento de datos podemos almacenar y analizar una gran cantidad de datos y producir información útil con la ayuda de visualizaciones e informes de datos. Los almacenes de datos bien diseñados brindan datos de alta calidad y mejoran el rendimiento de las consultas definiendo correctamente el tipo de datos, utilizando minería de datos, inteligencia artificial, etc., y ayudando a tomar decisiones más inteligentes.
Este artículo analizará el enfoque de la creación de un almacén de datos para explorar las tendencias y los conocimientos de los cursos de Udemy mediante Google Big Query, lo que nos ayudará a identificar cosas como la clasificación de los cursos en función de los títulos de trabajo de los instructores, la calificación promedio de todos los cursos de un instructor, etc.
OBJETIVOS DE APRENDIZAJE
En este artículo aprenderemos:
- Cómo construir un almacén de datos usando Google Big Query
- Cómo utilizar la zona de pruebas de Google Big Query
- Obtenga conocimientos sobre la creación de conjuntos de datos y tablas en Big Query
- Consulta de datos de Udemy en el motor de consulta Big Query SQL
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
Descripción del Proyecto
Ahora, crearemos la tabla dentro del conjunto de datos en el motor de consultas SQL de Google Cloud Platform a partir de los datos descargados. Después de crear la tabla, formatearemos el esquema de la tabla y realizaremos la limpieza de datos. Podemos realizar consultas sobre datos importados para generar información útil, como la clasificación de cursos según los títulos de trabajo de los instructores, la identificación de cursos que tienen calificaciones máximas, los instructores cuyos cursos tienen buenas calificaciones, etc.
Actualmente, tenemos datos de una sola fuente y estamos importando datos en formato CSV a través de la ingesta por lotes mediante la interfaz de usuario de Google Cloud Platform. También podemos importar datos de múltiples fuentes, como Cloud Storage, Azure Storage Account, etc. Además de importar datos a través de la interfaz de usuario de Google Cloud Platform, los usuarios también pueden importar datos usando CLI y REST API, usando opciones de canalización de datos como Cloud Dataflow, Cloud Dataproc, etc. Google Big Query también admite formatos de archivo como Parquet, Avro, etc., para la carga y el procesamiento de datos. Los desarrolladores también pueden guardar, compartir y ejecutar consultas en el motor de consultas SQL en el momento programado.

Al consultar los datos de Udemy, los usuarios pueden determinar qué cursos deben comprar en función de la duración del curso, las calificaciones del curso, los títulos de trabajo de los instructores, la popularidad del curso, etc. Los usuarios pueden guardar y compartir estas consultas. Los usuarios también pueden guardar los resultados de estas consultas para crear paneles usando Power BI, Looker Studio, Tableau, etc. Los usuarios también pueden extraer más datos de Udemy usando técnicas de web scraping e ingerirlos en el motor de consultas Google Big Query SQL para mantener los datos actualizados. para que los usuarios puedan obtener resultados más precisos.
Planteamiento del problema
En este artículo, usaremos el conjunto de datos de Udemy Courses Data 2023 de Kaggle para desarrollar un almacén de datos para explorar las tendencias y los conocimientos de los cursos de Udemy usando Google Big Query, lo que nos ayudará a identificar cosas como la clasificación de cursos según los títulos de trabajo de los instructores, el calificación promedio de todos los cursos de un instructor, clasificación de cursos según la cantidad de conferencias en el curso, identificación de cursos recientemente publicados y modificados en Udemy, etc.
Como ya se mencionó, podemos extraer más datos de Udemy utilizando técnicas de web scraping a medida que los nuevos cursos e instructores siguen creciendo en la plataforma de Udemy. Crearemos tablas dentro del conjunto de datos en el motor de consultas SQL de Google Cloud Platform para importar los cursos y los datos del instructor descargados de Kaggle. Después de la creación de la tabla, realizaremos la limpieza de datos y el formateo del esquema de la tabla.
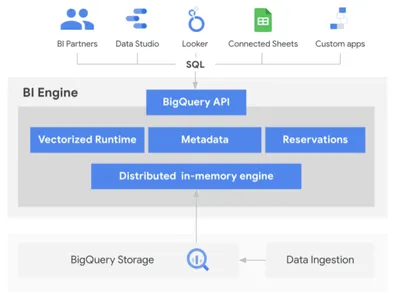
Podemos guardar, compartir y ejecutar consultas en el motor de consultas SQL en el momento programado. Aparte de esto, también podemos guardar los resultados de la ejecución de la consulta para que se puedan utilizar consultas para crear paneles usando Power BI, Looker Studio, Tableau, etc. Este proyecto tiene como objetivo desarrollar un almacén de datos usando datos de Udemy, consultando qué usuarios puede identificar cursos publicados y modificados recientemente en Udemy, clasificar cursos según la duración del curso y las calificaciones del curso, identificar calificaciones promedio de todos los cursos de un instructor, clasificar cursos según la cantidad de conferencias en el curso, etc.
Requisitos previos
A continuación se presentan algunos requisitos previos para llevar a cabo este proyecto:
- Comprensión del almacén de datos: En este proyecto, construiremos un almacén de datos para explorar las tendencias y los conocimientos de los cursos de Udemy utilizando Google Big Query. Por lo tanto, es importante comprender qué es un almacén de datos, por qué es útil un almacén de datos y qué proporciona el almacén de datos a través de varios proveedores de la nube, etc.
- Experiencia con Google Cloud Platform: Usaremos Google Big Query, un servicio de almacenamiento de datos disponible dentro de Google Cloud Platform. Por lo tanto, la experiencia con Google Cloud Platform es importante para navegar fácilmente por la plataforma y comprender el proceso de creación de recursos, las funciones y los permisos de acceso, etc.
- Experiencia con consultas SQL: Escribiremos consultas en el motor de consultas SQL para generar información útil, como la clasificación de cursos según los títulos de trabajo de los instructores, la identificación de cursos con calificaciones máximas, instructores cuyos cursos tienen buenas calificaciones, etc.
- Familiaridad con Udemy y Kaggle: Comprender qué es Kaggle, cómo es útil para descargar conjuntos de datos y la familiaridad básica con la plataforma de aprendizaje en línea Udemy será útil durante el desarrollo del proyecto.
- Comprensión de Google Big Query: Dado que este proyecto utiliza Google Big Query para crear un almacén de datos, sería beneficioso comprender las operaciones, los conceptos y las técnicas de datos comunes de Google Big Query.
Saber sobre el conjunto de datos
En este artículo, usaremos Datos de los cursos de Udemy 2023 datos de Kaggle. El conjunto de datos se puede descargar visitando https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023. El objetivo detrás del uso de este conjunto de datos es identificar los cursos publicados y modificados recientemente en Udemy, clasificar los cursos según la duración del curso y las calificaciones del curso, identificar las calificaciones promedio de todos los cursos de un instructor, clasificar los cursos según la cantidad de conferencias en el curso, etc.
El conjunto de datos de Udemy Courses Data 2023 tiene dos archivos llamados Courses.csv e instructors.csv. Courses.csv contiene información relacionada con los cursos de Udemy. El instructors.csv contiene la información relacionada con los instructores de Udemy. El Courses.csv contiene 11 columnas y 83,105 filas. El archivo instructors.csv contiene 10 columnas y 32,234 XNUMX filas. El Courses.csv contiene la columna instructors_id, que proporciona la identificación del instructor del curso. La columna instructors_id se usa para formar la relación entre los cursos.csv y los instructores.csv.
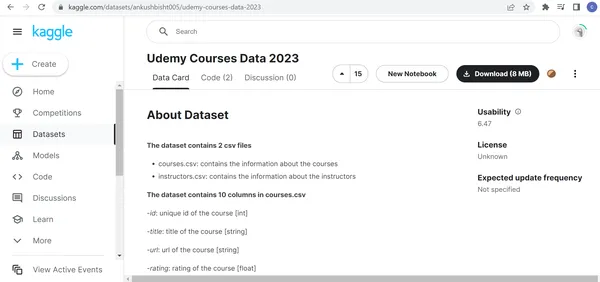
El cursos.csv contiene la identificación única del curso, el título del curso, la calificación del curso, la duración del curso, la cantidad de conferencias en el curso de Udemy, la URL del curso, la fecha de creación del curso, la fecha en la que se modificó por última vez el curso, número de revisiones del curso e id del instructor del curso. El instructores.csv contiene la identificación única del instructor, el nombre del instructor del curso, el nombre para mostrar del instructor del curso, el título del instructor del curso, el título del trabajo del instructor del curso, la clase del instructor, la URL del instructor, las iniciales de el instructor del curso, imagen 50 X 50 del instructor e imagen 100 X 100 del instructor. Para obtener más información sobre el conjunto de datos, visite https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023.
Aproximación al Proyecto
En este proyecto, utilizaremos Datos de los cursos de Udemy 2023 conjunto de datos de Kaggle para desarrollar un almacén de datos para explorar las tendencias y los conocimientos de los cursos de Udemy utilizando Google Big Query, lo que nos ayudará a identificar cosas como clasificar los cursos según los títulos de trabajo de los instructores, la calificación promedio de todos los cursos de un instructor, clasificar los cursos según la cantidad de conferencias en el curso, identificar cursos publicados y modificados recientemente en Udemy, etc.
Siga los pasos a continuación para crear un almacén de datos utilizando Datos de los cursos de Udemy 2023 conjunto de datos de Kaggle:
Paso 1: Cree un nuevo proyecto usando Big Query Sandbox
Para trabajar con Google Big Query, los desarrolladores pueden crear una cuenta en Google Cloud Platform o utilizar Google Big Query Sandbox. Usaré Google Big Query Sandbox en este artículo para crear un almacén de datos. El proyecto se utiliza para organizar todos los recursos de la nube de Google en GCP. Mediante la gestión de identidades y accesos, podemos especificar qué usuario está autorizado para acceder a qué recursos en un proyecto.
Visite el siguiente enlace para usar el Zona de pruebas de consultas grandes de Google: https://console.cloud.google.com/bigquery
Ahora, sigue los pasos que se describen a continuación:
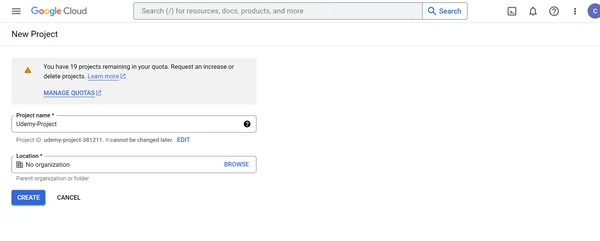
1. Haga clic en NUEVO PROYECTO, luego proporcione el nombre del proyecto como Udemy-Proyecto y ubicación en la siguiente pantalla. Haz clic en CREAR.
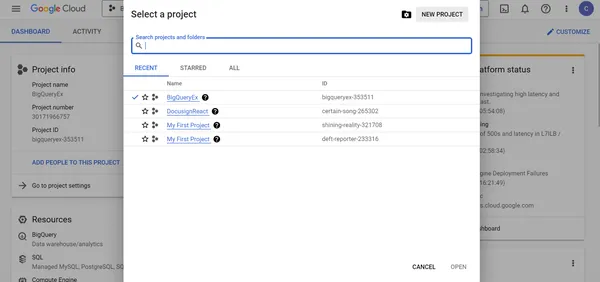
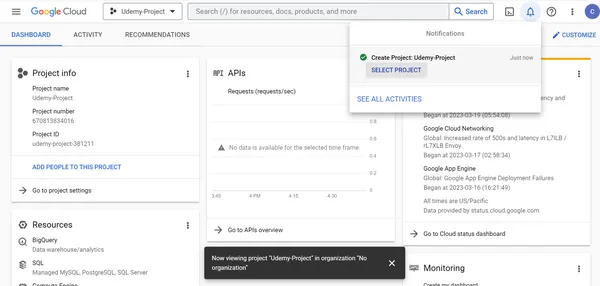
2. Udemy-Project se creó con éxito. Seleccione Udemy-Project para ver el proyecto y administrar los permisos de usuario y los recursos dentro del proyecto.
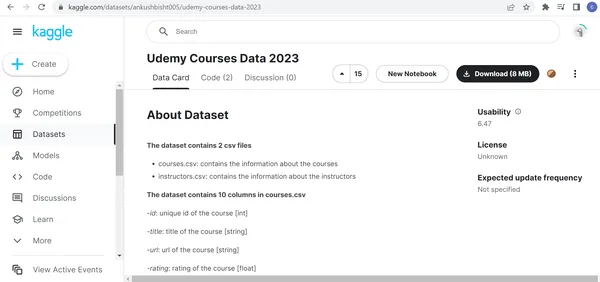
Paso 2: descargue el conjunto de datos de Kaggle y guárdelo en la máquina local
Visite https://www.kaggle.com/datasets/ankushbisht005/udemy-courses-data-2023 y haga clic en Descargar. Después de descomprimir el archivo zip descargado, encontrará dos archivos CSV llamados cursos.csv e instructores.csv. Courses.csv contiene información relacionada con los cursos de Udemy. El instructors.csv contiene la información relacionada con los instructores de Udemy. El Courses.csv contiene 11 columnas y 83,105 filas. El archivo instructors.csv contiene 10 columnas y 32,234 XNUMX filas. La columna instructors_id se usa para formar la relación entre los cursos.csv y los instructores.csv.
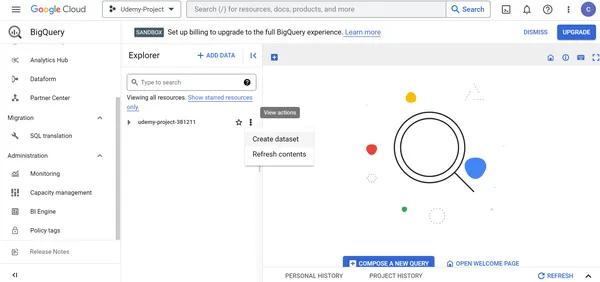
Paso 3: Creación de un conjunto de datos dentro del recurso Google Big Query
Siga los pasos que se describen a continuación para crear un conjunto de datos dentro de Google Big Query:
1. Seleccione el nombre del proyecto -> Gran consulta en la tarjeta de recursos -> Haga clic en Crear conjunto de datos.
2. Proporcione Udemy_dataset como ID de conjunto de datos, elija Región en Tipo de ubicación, elija Asia-sur1 (Mumbai) como Región y habilite la caducidad de la tabla.
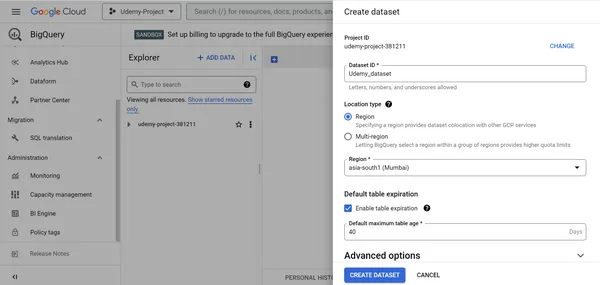
3. Haga clic en CREAR CONJUNTO DE DATOS
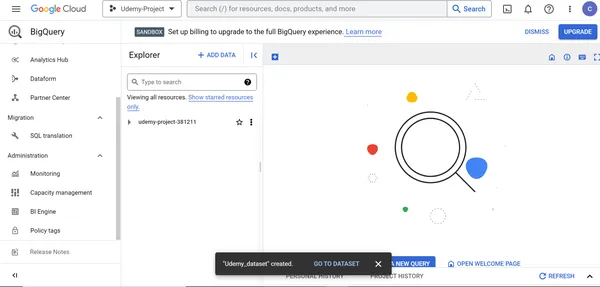
Paso 4: Cree tablas en el conjunto de datos dentro del recurso Big Query de Google
Siga los pasos que se describen a continuación para crear tablas en el conjunto de datos dentro de Google Big Query:
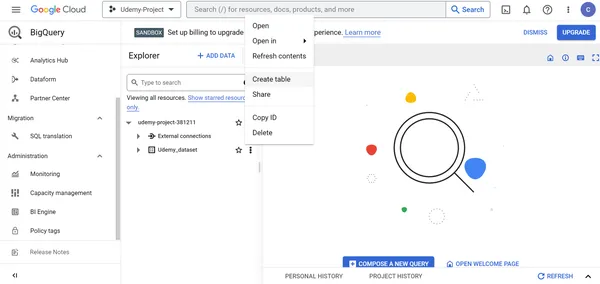
1. Seleccione el conjunto de datos Udemy_dataset -> Crear tabla
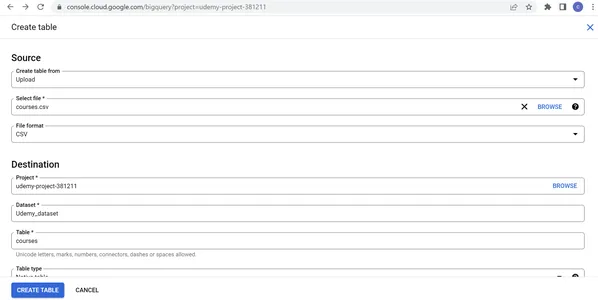
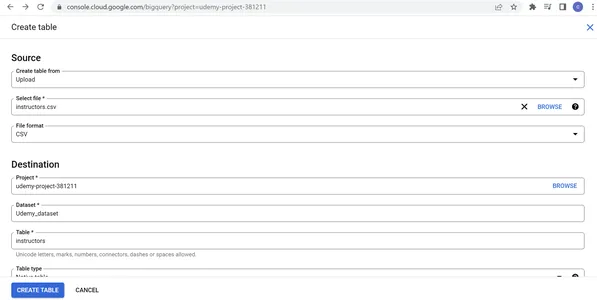
2. Elija crear una tabla a partir de la carga, seleccione el archivo Courses.csv descargado de Kaggle, seleccione el formato de archivo como CSV, proporcione cursos como nombre de tabla, tabla nativa como tipo de tabla, elija Auto para detectar en el esquema y partición y clúster ajustes según nuestros requisitos. En las opciones Avanzadas, proporcione 1 en las filas del encabezado para omitir y elija Cifrado adecuado según el requisito. Haz clic en CREAR TABLA.
3. Ahora, seleccione nuevamente el conjunto de datos Udemy_dataset
-> Crear tabla. Elija crear una tabla desde la carga, seleccione el archivo instructors.csv descargado de Kaggle, seleccione el formato de archivo como CSV, proporcione instructores como nombre de tabla, tabla nativa como tipo de tabla, elija Auto para detectar en el esquema y configuración de partición y clúster según nuestros requisitos. En las opciones Avanzadas, proporcione 1 en las filas del encabezado para omitir y elija Cifrado adecuado según el requisito. Haz clic en CREAR TABLA.
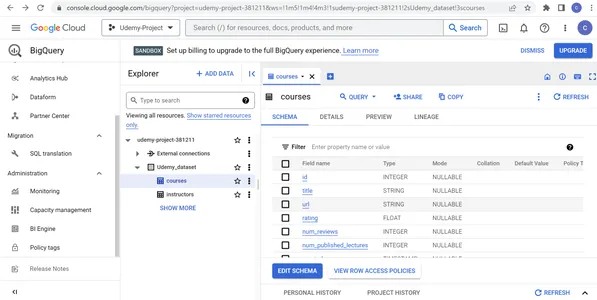
Paso 5: Verificación del esquema de tablas y vista previa de datos
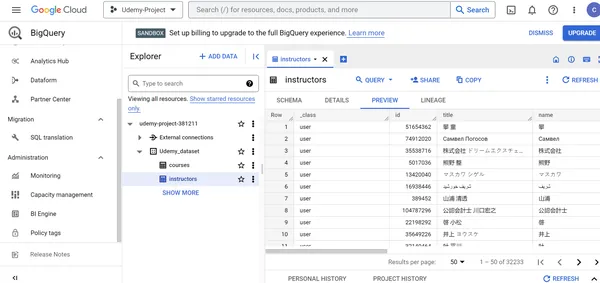
Vaya a la tabla de cursos y verifique de forma cruzada el nombre, el tipo y el modo del campo en el Esquema pestaña. Vea las políticas de acceso a las filas de la tabla de cursos y edite el esquema de la tabla, si es necesario. Ver la información de la tabla en el DETALLES pestaña y edite los detalles en caso de correcciones. También podemos obtener una vista previa, copiar, actualizar y compartir los datos. De manera similar, vaya a la tabla de instructores y verifique de forma cruzada el nombre del campo, el tipo y el modo en el Esquema pestaña. Vea las políticas de acceso a las filas de la tabla de instructores y edite el esquema de la tabla si es necesario.
Paso 6: Explorar las tendencias y perspectivas de los cursos de Udemy consultando los datos
Para ver 5000 registros de la cursos table, ejecute la siguiente consulta en el motor de consultas SQL:
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` LIMIT 5000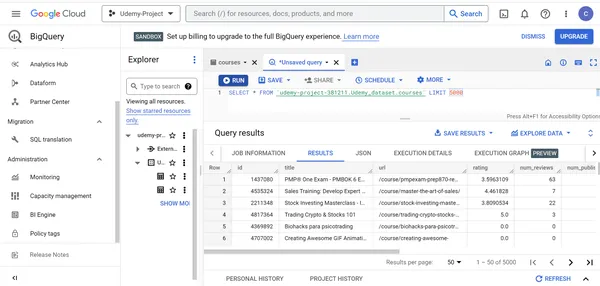
Para ver 5000 registros de la instructores table, ejecute la siguiente consulta en el motor de consultas SQL:
SELECT * FROM `udemy-project-381211.Udemy_dataset.instructors` LIMIT 5000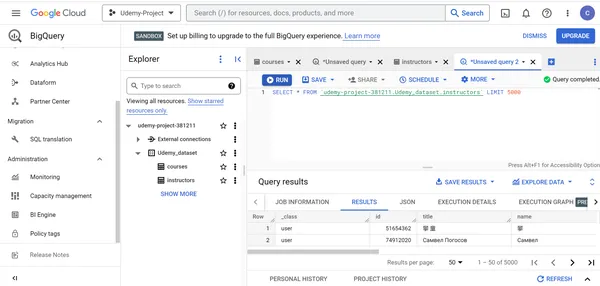
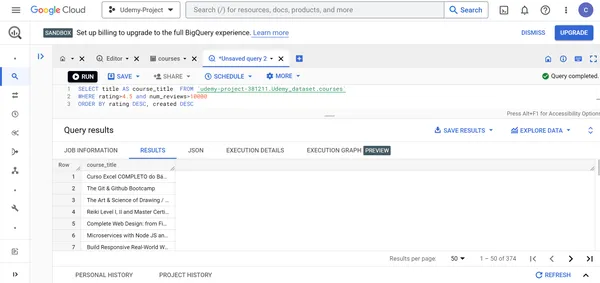
A. Encuentre el título de todos los cursos cuyas calificaciones sean superiores a 4.5 y más de 10000 personas hayan dado la calificación a estos cursos. Muestre estos cursos en orden decreciente de calificaciones del curso y fecha de creación.
SELECT title AS course_title FROM `udemy-project-381211.Udemy_dataset.courses` WHERE rating>4.5 and num_reviews>10000
ORDER BY rating DESC, created DESC
B. Encuentra los detalles de los 10 cursos de Udemy recién creados.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` ORDER BY created DESC
LIMIT 10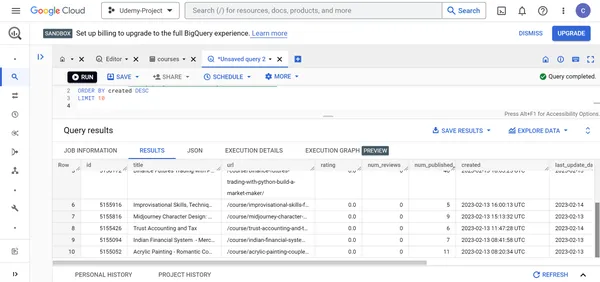
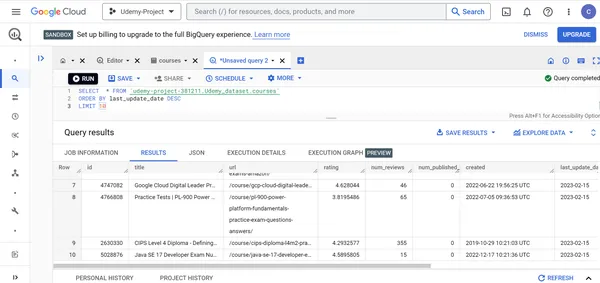
C. Encuentra los detalles de los 10 cursos de Udemy modificados recientemente.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` ORDER BY last_update_date DESC
LIMIT 10
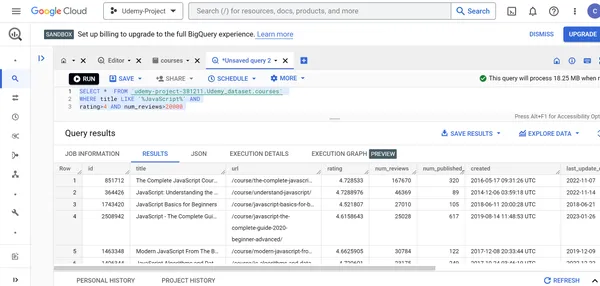
D. Encuentre los detalles de los cursos de JavaScript cuyas calificaciones son superiores a 4 y más de 20000 personas han dado la calificación a estos cursos.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%JavaScript%' AND
rating>4 AND num_reviews>20000
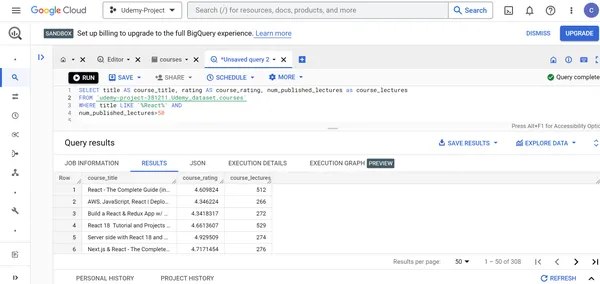
E. Muestra el título, la calificación y la cantidad de conferencias de los cursos de Udemy React que tienen más de 50 conferencias de cursos.
SELECT title AS course_title, rating AS course_rating, num_published_lectures as course_lectures FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%React%' AND
num_published_lectures>50
F. Encuentre la cantidad de cursos y el nombre del instructor del curso desarrollado por los instructores del curso con calificaciones de cursos superiores a las calificaciones promedio de los cursos.
SELECT COUNT(courses.id), instructors.name
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.instructors_id IN (SELECT instructors_id FROM `Udemy_dataset.courses` WHERE rating >(SELECT AVG(rating) FROM `Udemy_dataset.courses`))
GROUP BY instructors.name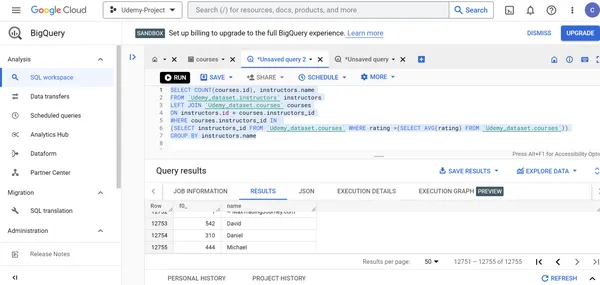
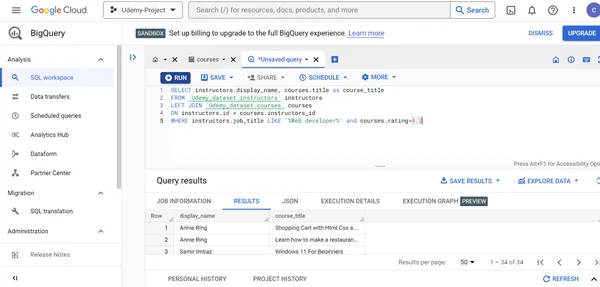
G. Mostrar el nombre del instructor del curso y el título de los cursos de Udemy creados por personas cuyo puesto de trabajo es desarrollador web
y cuyas calificaciones del curso sean superiores a 4.2.
SELECT instructors.display_name, courses.title as course_title
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE instructors.job_title LIKE '%Web developer%' and courses.rating>4.2
H. Muestra el título del curso, el nombre del instructor del curso, las calificaciones y la duración del curso de los cursos de Udemy cuando la duración del curso es superior a 40 minutos, 40 horas o 40 preguntas.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.duration
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE CASE WHEN courses.duration LIKE '%.%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'.')-1) AS FLOAT64)>40 WHEN courses.duration LIKE '%total%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'t')-1) AS FLOAT64)>40 WHEN courses.duration LIKE '%ques%' THEN CAST(LEFT(courses.duration, STRPOS(courses.duration,'q')-1) AS FLOAT64)>40
END
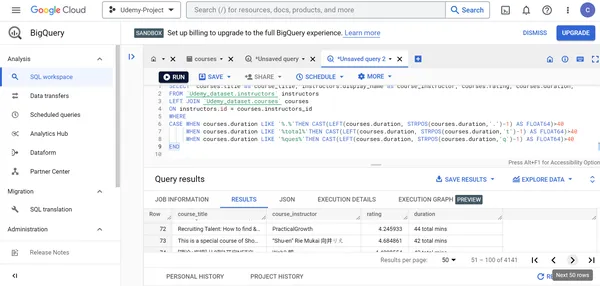
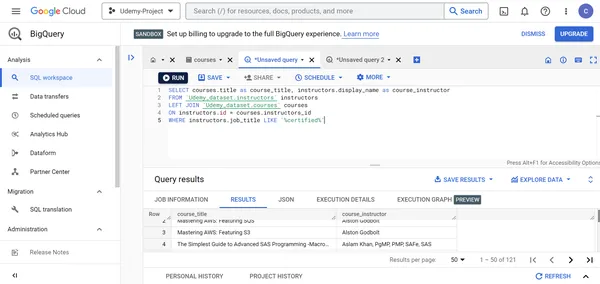
I. Mostrar el nombre del instructor del curso y el título de los cursos de Udemy creados por desarrolladores certificados.
SELECT courses.title as course_title, instructors.display_name as course_instructor
FROM `Udemy_dataset.instructors` instructors LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE instructors.job_title LIKE '%certified%'
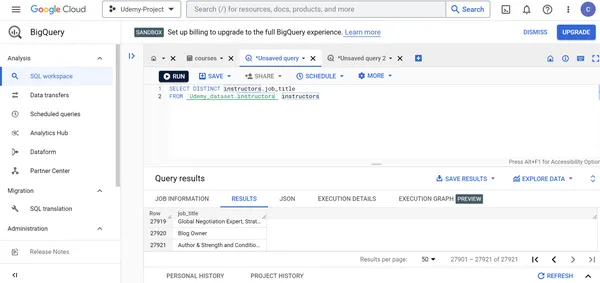
J. Encuentra todos los títulos de trabajo distintos de los instructores de cursos de Udemy.
SELECT DISTINCT instructors.job_title
FROM `Udemy_dataset.instructors` instructors
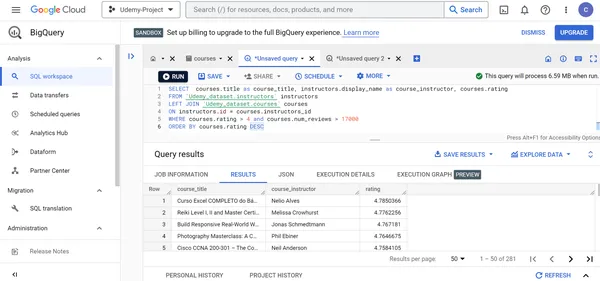
K. Encuentre el título, las calificaciones y el instructor de todos los cursos cuyas calificaciones sean superiores a 4 y más de 17000 personas hayan dado la calificación para estos cursos. Muestre estos cursos en orden decreciente de calificaciones del curso.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.rating > 4 and courses.num_reviews > 17000
ORDER BY courses.rating DESC
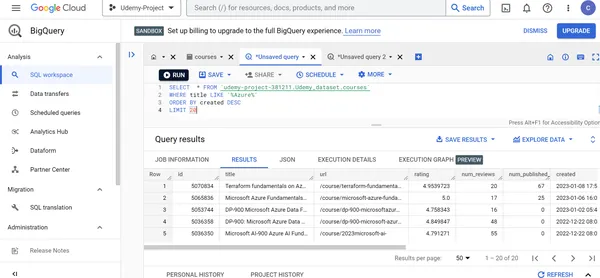
L. Encuentre los detalles de los 20 cursos de Azure Udemy recién creados.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%Azure%'
ORDER BY created DESC
LIMIT 20
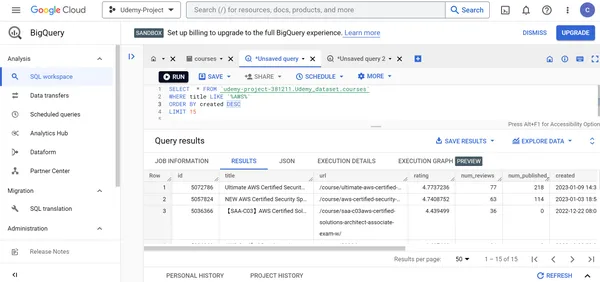
M. Encuentre los detalles de los 15 cursos de AWS Udemy recién creados.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%AWS%'
ORDER BY created DESC
LIMIT 15
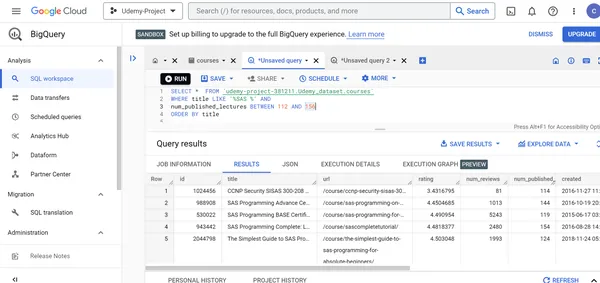
N. Muestre todos los detalles de los cursos de Udemy SAS que tienen clases de curso entre 112 y 156 en orden creciente del título del curso.
SELECT * FROM `udemy-project-381211.Udemy_dataset.courses` WHERE title LIKE '%SAS %' AND
num_published_lectures BETWEEN 112 AND 156
ORDER BY title
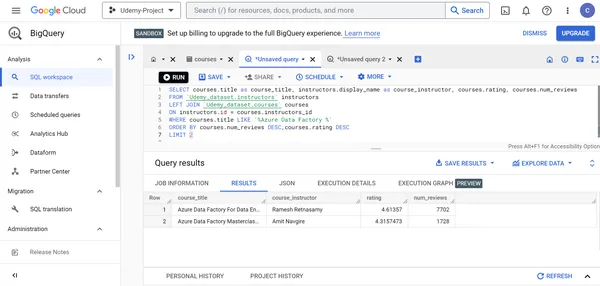
O. Muestra el nombre del instructor del curso, el título, las calificaciones y las revisiones del curso de los dos mejores cursos de Udemy Azure Data Factory según las calificaciones del curso y la cantidad de revisiones del curso.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.num_reviews
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.title LIKE '%Azure Data Factory %'
ORDER BY courses.num_reviews DESC, courses.rating DESC LIMIT 2
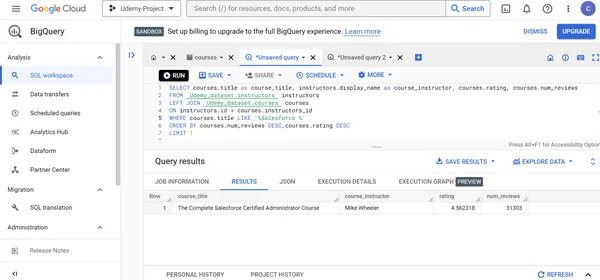
P. Muestra el nombre del instructor del curso, el título, las calificaciones y las revisiones del curso del mejor curso de Udemy Salesforce en función de las calificaciones del curso y la cantidad de revisiones del curso.
SELECT courses.title as course_title, instructors.display_name as course_instructor, courses.rating, courses.num_reviews
FROM `Udemy_dataset.instructors` instructors
LEFT JOIN `Udemy_dataset.courses` courses
ON instructors.id = courses.instructors_id
WHERE courses.title LIKE '%Salesforce %'
ORDER BY courses.num_reviews DESC, courses.rating DESC LIMIT 1
Tendencias e información clave descubiertas al explorar los datos de los cursos de Udemy
A partir de lo anterior, sabemos cómo crear un almacén de datos para explorar las tendencias y los conocimientos de los cursos de Udemy utilizando Gran consulta de Google. A continuación se muestran algunas tendencias y conocimientos clave descubiertos al explorar los datos de los cursos de Udemy:
1. Los cursos de JavaScript más populares tienen una calificación promedio superior a 4.6.
2. Solo 34 cursos de Udemy son creados por instructores cuyo título de trabajo es desarrollador web y cuyas calificaciones del curso son superiores a 4.2.
3. Casi 150 cursos de Udemy son creados por desarrolladores certificados por AWS, Azure, GCP o Salesforce.
4. Ramesh Retnasamy crea el curso Azure Data Factory más popular en Udemy.
5. Los cursos de Azure y AWS creados recientemente son muy populares en Udemy.
6. Los usuarios de Udemy prefieren inscribirse en cursos de SAS con alrededor de 100-150 conferencias con buenas calificaciones.
Conclusión
En este artículo, hemos visto cómo crear un almacén de datos para explorar las tendencias y las perspectivas de los cursos de Udemy utilizando Google Big Query. Un almacén de datos almacena y analiza una gran cantidad de datos y produce información útil sobre los datos con la ayuda de visualizaciones e informes de datos. Hemos visto cómo crear una tabla importando datos de Kaggle en Google Big Query. También entendemos cómo crear relaciones entre tablas para comprender mejor los datos. Analizamos cómo analizar los datos con la ayuda de consultas para obtener información significativa de los datos. A continuación se presentan las principales conclusiones del artículo anterior:
- Hemos visto cómo podemos crear tablas en Google Big Query.
- Entendimos cómo consultar datos en el motor de consultas Big Query SQL.
- También hemos identificado detalles de los cursos de Udemy creados por personas cuyo título de trabajo es desarrollador web y cuyas calificaciones del curso son superiores a 4.2.
- También hemos visto cuántos cursos en Udemy son creados por desarrolladores certificados.
- Hemos descubierto los cursos de Azure y AWS recién creados en base a las tendencias de Udemy.
- Aparte de eso, también hemos visto otras tendencias de cursos en Udemy al explorar los datos de Udemy dentro del motor de consultas SQL.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/04/exploring-udemy-courses-trends-and-insights-with-google-big-query/

