Esta es la segunda de una serie de dos partes sobre modelos de clasificación personalizados de Amazon Comprehend. En la Parte 1 de esta serie, analizamos cómo crear un flujo de trabajo de AWS Step Functions para crear, probar e implementar automáticamente modelos de clasificación y puntos de enlace personalizados de Amazon Comprehend. En la Parte 2, analizamos las API de clasificación en tiempo real, los ciclos de retroalimentación y los flujos de trabajo de revisión humana que ayudan con el entrenamiento continuo del modelo para mantener el modelo actualizado con nuevos datos y patrones. Puedes encontrar la Parte 1 esta página.
La Amazon Comprehend La API de clasificación personalizada le permite crear fácilmente modelos de clasificación de texto personalizados utilizando las etiquetas específicas de su negocio sin aprender el aprendizaje automático (ML). Por ejemplo, su organización de atención al cliente puede usar una clasificación personalizada para categorizar automáticamente las solicitudes entrantes por tipo de problema según cómo el cliente describió el problema. Puede utilizar clasificadores personalizados para etiquetar automáticamente los correos electrónicos de soporte con los tipos de problemas adecuados, enrutando así las llamadas telefónicas de los clientes a los agentes adecuados y categorizando las publicaciones de las redes sociales en segmentos de usuarios.
In Parte 1 de esta serie, analizamos cómo construir un Funciones de paso de AWS flujo de trabajo para crear, probar e implementar automáticamente modelos de clasificación y puntos de enlace personalizados de Amazon Comprehend. En esta publicación, cubrimos las API de clasificación en tiempo real, los ciclos de retroalimentación y los flujos de trabajo de revisión humana que ayudan con el entrenamiento continuo del modelo para mantenerlo actualizado con nuevos datos y patrones.
Arquitectura de soluciones
Esta publicación describe una arquitectura de referencia para reentrenar modelos de clasificación personalizados. La arquitectura comprende clasificación en tiempo real, canalizaciones de retroalimentación, flujos de trabajo de revisión humana utilizando IA aumentada de Amazon (Amazon A2I), preparando nuevos datos de entrenamiento a partir de los datos de revisión humana y activando el flujo de construcción del modelo que cubrimos en Parte 1 de esta serie
El siguiente diagrama ilustra esta arquitectura que cubre los últimos tres componentes. En las siguientes secciones, lo guiamos a través de cada paso del flujo de trabajo.

Clasificación en tiempo real
Para utilizar la clasificación personalizada en Amazon Comprehend en tiempo real, debe crear una API que llame al punto de enlace del modelo de clasificación personalizada con el texto que debe clasificarse. Esta etapa está representada por los pasos 1 a 3 de la arquitectura anterior:
- La aplicación del usuario final llama a un Puerta de enlace API de Amazon punto final con un texto que necesita ser clasificado.
- El punto final de API Gateway luego llama a un AWS Lambda función configurada para llamar a un punto de enlace de Amazon Comprehend.
- La función Lambda llama al extremo de Amazon Comprehend, que devuelve la clasificación de texto sin etiquetar y una puntuación de confianza.
Recopilación de comentarios
Cuando el punto final devuelve la clasificación y la puntuación de confianza durante la clasificación en tiempo real, puede enviar instancias con puntuaciones de confianza bajas a revisión humana. Este tipo de retroalimentación se llama retroalimentación implícita.
- La función Lambda envía la retroalimentación implícita a un Manguera de bomberos de datos de Amazon Kinesis flujo de entrega.
El otro tipo de retroalimentación se llama retroalimentación explícitay proviene de los usuarios finales de la aplicación que utilizan la función de clasificación personalizada. Este tipo de retroalimentación comprende las instancias de texto en las que el usuario no estaba satisfecho con la predicción. Puede enviar comentarios explícitos en tiempo real a través de una API o un proceso por lotes.
- Los usuarios finales de la aplicación envían comentarios explícitos en tiempo real a través de un punto final de API Gateway.
- La función Lambda que respalda el punto final de la API transforma los datos en un formato de comentarios estándar y los escribe en el flujo de entrega de Kinesis Data Firehose.
- Los usuarios finales de la aplicación también pueden enviar comentarios explícitos como un archivo por lotes cargándolos en un depósito de S3.
- Un activador configurado en el bucket de S3 activa una función Lambda.
- La función Lambda transforma los datos en un formato de retroalimentación estándar y los escribe en el flujo de entrega.
- Los datos de retroalimentación tanto implícitos como explícitos se envían a un flujo de entrega en un formato estándar. Todos estos datos se almacenan en búfer y se escriben en un bucket de S3.
Clasificación humana
La etapa de clasificación humana incluye los siguientes pasos:
- Un desencadenador configurado en el depósito de retroalimentación en el Paso 10 invoca una función Lambda.
- La función Lambda crea tareas de revisión humana de Amazon A2I para todos los datos de comentarios recibidos.
- Los trabajadores asignados a los trabajos de clasificación inician sesión en el portal de revisión humana y aprueban la clasificación por modelo o clasifican el texto con las etiquetas adecuadas.
- Después de la revisión humana, todas estas instancias se almacenan en un depósito S3 y se utilizan para volver a capacitar a los modelos.
Flujo de trabajo de reentrenamiento
La etapa del flujo de trabajo de reentrenamiento incluye los siguientes pasos:
- Un desencadenador configurado en el depósito de datos revisados por humanos en el Paso 14 invoca una función Lambda.
- La función transforma la carga útil de datos revisados por humanos en un formato de datos de entrenamiento separados por comas, requerido por los modelos de clasificación personalizados de Amazon Comprehend. Después de la transformación, estos datos se escriben en un flujo de entrega de Firehose, que actúa como un acumulador.
- Dependiendo del marco de tiempo establecido para los modelos de reentrenamiento, el flujo de entrega descarga los datos en el depósito de entrenamiento que se creó en Parte 1 de esta serie. Para esta publicación, configuramos las condiciones del búfer en 1 MiB o 60 segundos. Para su propio caso de uso, es posible que desee ajustar esta configuración para que el reentrenamiento del modelo se produzca de acuerdo con sus requisitos de tiempo o tamaño. Esto completa el ciclo de aprendizaje activo e inicia el flujo de trabajo de Step Functions para reentrenar modelos.
Resumen de la solución
Las siguientes secciones de la publicación explican cómo configurar esta arquitectura en su cuenta de AWS. Clasificamos las noticias en cuatro categorías: Mundo, Deportes, Negocios y Ciencia / Tecnología, usando el Conjunto de datos de AG News para una clasificación personalizada, y configure el ciclo de retroalimentación implícito y explícito. Debe completar dos pasos manuales:
- Cree un clasificador personalizado de Amazon Comprehend y un punto final.
- Crear una Amazon SageMaker fuerza de trabajo privada, plantilla de tareas del trabajador y flujo de trabajo de revisión humana.
Después de esto, ejecuta el Formación en la nube de AWS plantilla para configurar el resto de la arquitectura.
Requisitos previos
Si continúas desde Parte 1 de esta serie, puede saltar al paso Cree una plantilla privada de personal, una plantilla de tareas para el trabajador y un flujo de trabajo de revisión humana.
Cree un clasificador personalizado y un punto final
Antes de comenzar, descargue el conjunto de datos y cárguelo en Amazon S3. Este conjunto de datos comprende una colección de artículos de noticias y sus etiquetas de categoría correspondientes. Hemos creado un conjunto de datos de entrenamiento llamado train.csv del conjunto de datos original y lo puso a disposición para descargar.
La siguiente captura de pantalla muestra una muestra de train.csv archivo.

Después de descargar el train.csv , cárguelo en un depósito de S3 en su cuenta como referencia durante el entrenamiento. Para obtener más información sobre la carga de archivos, consulte ¿Cómo subo archivos y carpetas a un bucket de S3?
Para crear su clasificador para clasificar noticias, complete los siguientes pasos:
- En Consola Amazon Comprehend, escoger Clasificación personalizada.
- Elige Clasificador de trenes.
- Nombre, introduzca
news-classifier-demo. - Seleccione Usar el modo de clases múltiples.
- Ubicación de los datos de entrenamiento S3, ingrese el camino para
train.csven su bucket de S3, por ejemplo,s3://<tu-nombre-cubo>/train.csv. - Ubicación de los datos de salida S3, ingrese la ruta del depósito de S3 donde desea la salida, como
s3://<your-bucketname>/. - Rol de IAM, seleccione Crear un rol de IAM.
- Permisos de acceso, escoger Entrada y salida (si se especifica) S3 bucket.
- Sufijo de nombre, introduzca
ComprehendCustom.

- Desplázate hacia abajo y elige Clasificador de trenes para comenzar el proceso de entrenamiento.
La formación tarda algún tiempo en completarse. Puede esperar para crear un punto final o volver a este paso más tarde después de finalizar los pasos de la sección Cree una plantilla privada de personal, una plantilla de tareas para el trabajador y un flujo de trabajo de revisión humana.
Cree un punto final en tiempo real de clasificador personalizado
Para crear su punto final, complete los siguientes pasos:
- En la consola de Amazon Comprehend, elija Clasificación personalizada.
- Desde el Clasificadores lista, elija el nombre del modelo personalizado para el que desea crear el punto final y seleccione su modelo
news-classifier-demo. - En Acciones menú desplegable, elija Crear punto final.
- Nombre de punto final, introduzca
classify-news-endpointy darle una unidad de inferencia. - Elige Crear punto final.
- Copie el ARN del punto final como se muestra en la siguiente captura de pantalla. Lo usa cuando ejecuta la plantilla de CloudFormation en un paso futuro.

Cree una plantilla privada de personal, una plantilla de tareas para el trabajador y un flujo de trabajo de revisión humana
Esta sección lo guía a través de la creación de una fuerza laboral privada en SageMaker, una plantilla de tareas de trabajador y su flujo de trabajo de revisión humana.
Cree una fuerza laboral de etiquetado
Para esta publicación, crea un equipo de trabajo privado y agrega solo un usuario (usted). Para obtener instrucciones, consulte Crear una fuerza laboral privada (Consola de Amazon SageMaker).
Una vez que el usuario acepta la invitación, lo agrega a la fuerza laboral. Para obtener instrucciones, consulte el Agregar un trabajador a un equipo de trabajo sección el Administrar una fuerza laboral (Consola de Amazon SageMaker).
Crear una plantilla de tarea de trabajador
Para crear una plantilla de tarea de trabajador, complete los siguientes pasos:
- En Consola de Amazon A2I, escoger Plantillas de tareas de los trabajadores.
- Elija Crea una plantilla.
- Nombre de la plantilla, introduzca
custom-classification-template. - Tipo de plantilla, escoger Personalizado,
- En Editor de plantillas, introduzca la siguiente Código de plantilla de interfaz de usuario de GitHub.
- Elige Crear.

Cree un flujo de trabajo de revisión humana
Para crear su flujo de trabajo de revisión humana, complete los siguientes pasos:
- En Consola Amazon A2I, escoger Flujos de trabajo de revisión humana.
- Elige Crear flujo de trabajo de revisión humana.
- Nombre, entrar
classify-workflow. - Cree un depósito de S3 para almacenar la salida de la revisión humana. Tome nota de este cubo, porque lo usamos en la parte posterior de la publicación.
- Especifique un Cucharón S3 para almacenar la salida:
s3://<tu nombre de cubo>/. Utilice el depósito creado anteriormente. - Rol de IAM, seleccione Crear un nuevo rol.
- Tipo de tarea, escoger Personalizado.
- under Creación de plantillas de tareas de trabajo, seleccione la plantilla de clasificación personalizada que creó.
- Descripción de la tarea, introduzca
Read the instructions and review the document. - under Trabajadores, selecciona Privado.
- Utilice la lista desplegable para elegir el equipo privado que creó.
- Elige Crear.
- Copie el ARN del flujo de trabajo (consulte la siguiente captura de pantalla). Lo usará al inicializar los parámetros de la plantilla de CloudFormation en un paso posterior.

Implemente la plantilla de CloudFormation para configurar comentarios de aprendizaje activos
Ahora que ha completado los pasos manuales, puede ejecutar la plantilla de CloudFormation para configurar los bloques de construcción de esta arquitectura, incluida la clasificación en tiempo real, la recopilación de comentarios y la clasificación humana.
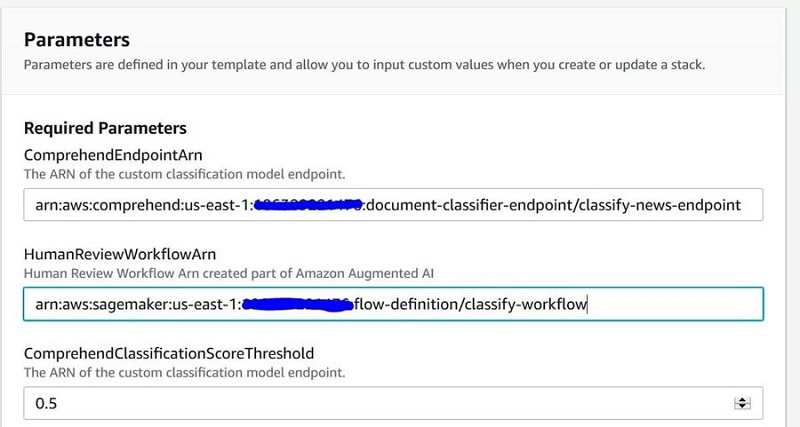
Antes de implementar la plantilla de CloudFormation, asegúrese de tener lo siguiente para pasar como parámetros:
- ARN de punto final de clasificador personalizado
- ARN del flujo de trabajo de Amazon A2I
- Elige Pila de lanzamiento:
![]()
- Debe establecer este parámetro, solo si continúa desde Parte 1 de esta serie. Para CuboDeBlogPart1, ingrese el nombre del depósito que se creó para almacenar datos de entrenamiento en la Parte 1 de esta serie de blogs.
- Debe establecer este parámetro, solo si continúa desde la Parte 1 de esta serie. Para ComprenderEndpointParameterKey, introduzca
/<<StackName del blog de Part1>>/CURRENT_CLASSIFIER_ENDPOINT. Este parámetro se puede encontrar en la sección Almacén de parámetros del Administrador de sistemas.
- Eres No se requiere para establecer este parámetro si continúa desde la Parte 1. ComprenderEndpointARN, ingrese el ARN del extremo de su modelo de clasificación personalizado de Amazon Comprehend.
- Flujo de trabajo de revisión humanaARN, ingrese el ARN del flujo de trabajo que copió.
- ComrehendClasificaciónPuntuaciónUmbral, introduzca
0.5, lo que significa un umbral del 50% para puntuaciones de confianza bajas.
- Elige Siguiente hasta el Capacidades
- Seleccione la casilla de verificación para proporcionar reconocimiento a AWS CloudFormation para crear Gestión de identidades y accesos de AWS (IAM) y expanda la plantilla.
Para obtener más información sobre estos recursos, vea Recursos de AWS IAM.
- Elige Crear pila.

Espere hasta que el estado de la pila cambie de CREATE_IN_PROGRESS a CREATE_COMPLETE.

- En Salidas pestaña de la pila (ver la siguiente captura de pantalla), copie el valor para
BatchUploadS3Bucket,FeedbackAPIGatewayID,yTextClassificationAPIGatewayIDpara interactuar con el circuito de retroalimentación.
Ambos TextClassificationAPI y FeedbackAPI requieren una clave API para interactuar con ellos. La salida de la pila de CloudFormation ApiGWKey hace referencia al nombre de la clave API. Al momento de escribir este artículo, esta clave de API está asociada con un plan de uso que permite 2,000 solicitudes por mes.
- En Consola de API Gateway, elija el
TextClassificationAPIo deFeedbackAPI. - En el panel de navegación, elija Claves de la API.
- Ampliar la opción Clave API sección y copie el valor.

Puede administrar el plan de uso siguiendo las instrucciones en Cree, configure y pruebe planes de uso con la consola de API Gateway.
También puede agregar autenticación y autorización detalladas a sus API. Para obtener más información sobre cómo proteger sus API, consulte Controlar y administrar el acceso a una API REST en API Gateway.
Habilite el activador para iniciar el flujo de trabajo de reentrenamiento
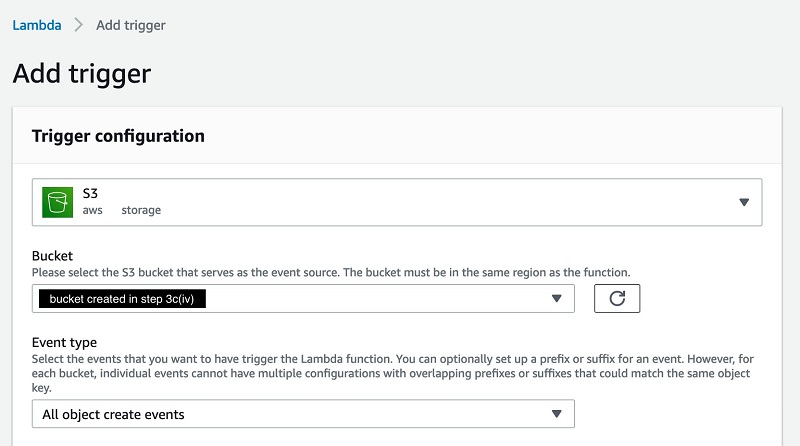
El último paso del proceso es agregar un disparador al depósito de S3 que creamos anteriormente para almacenar la salida revisada por humanos. El disparador invoca la función Lambda que comienza la transformación de la carga útil del formato de salida de revisión humana de Amazon A2I a un formato CSV necesario para entrenar modelos de clasificación personalizados de Amazon Comprehend.
- Abra la función Lambda
HumanReviewTrainingDataTransformerFunction, creado al ejecutar la plantilla de CloudFormation. - En Configuración de disparo sección, elija S3.
- Cubo, ingrese el depósito que creó anteriormente en el paso 4 de Cree un flujo de trabajo de revisión humana .
Prueba el circuito de retroalimentación
En esta sección, lo guiamos a través de la prueba de su ciclo de retroalimentación, incluida la clasificación en tiempo real, la retroalimentación implícita y explícita y las tareas de revisión humana.
Clasificación en tiempo real
Para interactuar y probar estas API, debe descargar Cartero.
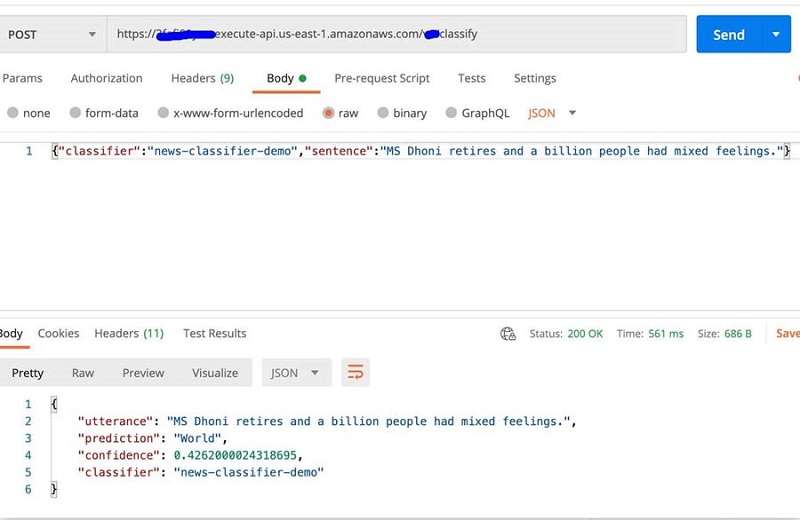
El punto final de API Gateway recibe un documento de texto sin etiquetar de una aplicación cliente y llama internamente al punto final de clasificación personalizado, que devuelve la etiqueta prevista y una puntuación de confianza.
- Abra Cartero e ingrese al
TextClassificationAPIGatewayURL en el método POST. - En Cabezales sección, configure la clave API: x-api-key: << Su clave API >>.
- En el campo de texto, ingrese el siguiente código JSON (asegúrese de tener JSON seleccionado y habilitar crudo):
- Elige Enviar.
Obtiene una respuesta con una puntuación de confianza y clase, como se ve en la siguiente captura de pantalla.
Retroalimentación implícita
Cuando el punto final devuelve la clasificación y la puntuación de confianza durante la clasificación en tiempo real, puede enrutar todas las instancias en las que la puntuación de confianza no alcanza el umbral de revisión humana. Este tipo de retroalimentación se denomina retroalimentación implícita. Para esta publicación, establecemos el umbral en 0.5 como una entrada para el parámetro de pila de CloudFormation.
Puede cambiar este umbral al implementar la plantilla de CloudFormation según sus necesidades.
Retroalimentación explícita
Los comentarios explícitos provienen de los usuarios finales de la aplicación que utiliza la función de clasificación personalizada. Este tipo de retroalimentación comprende las instancias de texto en las que el usuario no estaba satisfecho con la predicción. Puede enviar la etiqueta predicha por los comentarios explícitos del modelo a través de los siguientes métodos:
- Tiempo real a través de una API, que generalmente se activa a través de un botón Me gusta / No me gusta en una interfaz de usuario
- Proceso por lotes, en el que se recopila un archivo con una colección de expresiones mal clasificadas en función de una encuesta de usuarios realizada por el equipo de contacto con el cliente.
Invocar el ciclo de retroalimentación explícito en tiempo real
Para probar la API de comentarios, complete los siguientes pasos:
- Abra Cartero e ingrese al
FeedbackAPIGatewayIDvalor de la salida de la pila de CloudFormation en el método POST. - En Cabezales sección, configure la clave API:
x-api-key: < Tu clave API >>. - En el campo de texto, ingrese el siguiente código JSON (para
classifier, ingrese el clasificador que creó, comonews-classifier-demoy asegúrate de tener JSON seleccionado y habilitar crudo):
- Elige Enviar.
Le recomendamos que envíe al menos cuatro muestras de prueba que darán como resultado una puntuación de confianza menor que su umbral establecido.

Envíe comentarios explícitos como un archivo por lotes
Descargue lo siguiente comentarios de prueba JSON, complételo con sus datos y cárguelo en el BatchUploadS3Bucket creado cuando implementó su plantilla de CloudFormation. Le recomendamos que envíe al menos cuatro entradas de comentarios en este archivo. El siguiente código muestra algunos datos de muestra en el archivo:
La carga del archivo activa la función Lambda que inicia su ciclo de revisión humana.
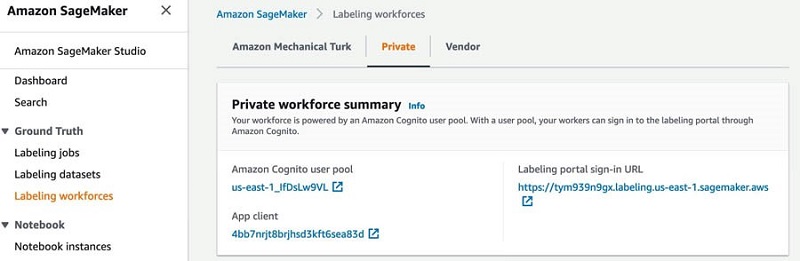
Tareas de revisión humana
Todos los comentarios recopilados a través de los métodos implícitos y explícitos se envían para la clasificación humana. La mano de obra de etiquetado puede incluir Amazon Mechanical Turk, equipos privados o proveedores de AWS Marketplace. Para esta publicación, creamos una fuerza laboral privada. La URL del portal de etiquetado se encuentra en la consola de SageMaker, en la Etiquetado de mano de obra página, en el Privado .
Después de iniciar sesión, puede ver las tareas de revisión humana que se le asignaron. Seleccione la tarea a completar y elija Empezar a trabajar.
Verá las tareas que se muestran según la plantilla de trabajador utilizada al crear el flujo de trabajo humano.

Después de completar la clasificación humana y enviar las tareas, los datos revisados por personas se almacenan en el depósito de S3 que configuró al crear el flujo de trabajo de revisión humana. Este cubo se encuentra debajo Ubicación de salida en la página de detalles del flujo de trabajo.
Estos datos revisados por humanos se utilizan para volver a entrenar el modelo de clasificación personalizado para aprender patrones más nuevos y mejorar su precisión general. La siguiente captura de pantalla muestra el archivo de salida anotado por humanos output.json en el cubo S3.

Estos datos revisados por humanos se convierten luego a un formato de datos de entrenamiento de modelo de clasificación personalizado y se transfieren al depósito de entrenamiento que se creó Parte 1 de esta serie, que inicia el flujo de trabajo Step Functions para reentrenar modelos. El proceso de reentrenar los modelos con datos revisados por humanos, seleccionar el mejor modelo e implementar automáticamente los nuevos puntos finales completa el flujo de trabajo de aprendizaje activo.
Limpiar
Para eliminar todos los recursos creados durante este proceso y evitar costos adicionales, complete los siguientes pasos:
- En la consola de Amazon S3, elimine el bucket de S3 que contiene el conjunto de datos de entrenamiento.
- En la consola de Amazon Comprehend, elimine el punto final y el clasificador.
- En la consola de Amazon A2I, elimine el flujo de trabajo de revisión humana, la plantilla de trabajador y la fuerza laboral privada.
- En la consola de AWS CloudFormation, elimine la pila que creó. (Esto elimina los recursos que creó la plantilla de CloudFormation).
Conclusión
Amazon Comprehend lo ayuda a desarrollar capacidades de procesamiento de lenguaje natural escalables y precisas sin ninguna experiencia de aprendizaje automático. Esta publicación proporciona un patrón e infraestructura reutilizables para flujos de trabajo de aprendizaje activo para modelos de clasificación personalizados. Los canales de retroalimentación y el flujo de trabajo de revisión humana ayudan al clasificador personalizado a aprender nuevos patrones de datos continuamente. Para obtener más información sobre la creación, selección e implementación de modelos automáticos de modelos de clasificación personalizados, puede consultar Flujo de trabajo de aprendizaje activo para modelos de clasificación personalizados de Amazon Comprehend - Parte 1.
Para más información, consulte la Clasificación personalizada. Puede descubrir otras funciones de Amazon Comprehend y obtener inspiración de otras Publicaciones de blog de AWS sobre cómo usar Amazon Comprehend más allá de la clasificación.
Acerca de los autores
 shanthan kesharaju es un arquitecto sénior en el equipo de AWS ProServe. Ayuda a nuestros clientes con la estrategia, la arquitectura y el desarrollo de productos de IA / ML con un propósito. Shanthan tiene una maestría en marketing de la Universidad de Duke y una maestría en sistemas de información gerencial de la Universidad Estatal de Oklahoma.
shanthan kesharaju es un arquitecto sénior en el equipo de AWS ProServe. Ayuda a nuestros clientes con la estrategia, la arquitectura y el desarrollo de productos de IA / ML con un propósito. Shanthan tiene una maestría en marketing de la Universidad de Duke y una maestría en sistemas de información gerencial de la Universidad Estatal de Oklahoma.
 mona mona es un arquitecto de soluciones especializado en AI / ML con sede en Arlington, VA. Trabaja con el equipo del sector público mundial y ayuda a los clientes a adoptar el aprendizaje automático a gran escala. Le apasionan las áreas de explicabilidad de PNL y ML en AI / ML.
mona mona es un arquitecto de soluciones especializado en AI / ML con sede en Arlington, VA. Trabaja con el equipo del sector público mundial y ayuda a los clientes a adoptar el aprendizaje automático a gran escala. Le apasionan las áreas de explicabilidad de PNL y ML en AI / ML.
 Joyson Neville Lewis obtuvo su maestría en Tecnología de la Información de la Universidad de Rutgers en 2018. Ha trabajado como ingeniero de software / datos antes de sumergirse en el dominio de la IA conversacional en 2019, donde trabaja con empresas para conectar los puntos entre los negocios y la IA utilizando soluciones de voz y chatbot. Joyson se unió a Amazon Web Services en febrero de 2018 como consultor de Big Data para el equipo de servicios profesionales de AWS en Nueva York.
Joyson Neville Lewis obtuvo su maestría en Tecnología de la Información de la Universidad de Rutgers en 2018. Ha trabajado como ingeniero de software / datos antes de sumergirse en el dominio de la IA conversacional en 2019, donde trabaja con empresas para conectar los puntos entre los negocios y la IA utilizando soluciones de voz y chatbot. Joyson se unió a Amazon Web Services en febrero de 2018 como consultor de Big Data para el equipo de servicios profesionales de AWS en Nueva York.
Coinsmart. Mejor Bitcoin-Börse en Europa
Fuente: https://aws.amazon.com/blogs/machine-learning/active-learning-workflow-for-amazon-comprehend-custom-classification-part-2/

