Esta publicación está coescrita con Jonathan Jung, Mike Band, Michael Chi y Thompson Bliss en la National Football League.
A esquema de cobertura se refiere a las reglas y responsabilidades de cada defensor de fútbol encargado de detener un pase ofensivo. Es el núcleo de la comprensión y el análisis de cualquier estrategia defensiva de fútbol. Clasificar el esquema de cobertura para cada jugada de pase brindará información sobre el juego de fútbol a los equipos, las emisoras y los fanáticos por igual. Por ejemplo, puede revelar las preferencias de los emisores de jugadas, permitir una comprensión más profunda de cómo los respectivos entrenadores y equipos ajustan continuamente sus estrategias en función de las fortalezas de sus oponentes y permitir el desarrollo de nuevos análisis orientados a la defensa, como la singularidad de las coberturas (Set et al.). Sin embargo, la identificación manual de estas coberturas por jugada es laboriosa y difícil porque requiere que los especialistas en fútbol inspeccionen cuidadosamente las imágenes del juego. Existe la necesidad de un modelo de clasificación de cobertura automatizado que pueda escalar de manera efectiva y eficiente para reducir los costos y el tiempo de respuesta.
los de la nfl Estadísticas de próxima generación captura la ubicación en tiempo real, la velocidad y más para cada jugador y jugada de los juegos de fútbol de la NFL, y obtiene varias estadísticas avanzadas que cubren diferentes aspectos del juego. A través de una colaboración entre el equipo de Next Gen Stats y el Laboratorio de soluciones de Amazon ML, hemos desarrollado la estadística de clasificación de cobertura impulsada por aprendizaje automático (ML) que identifica con precisión el esquema de cobertura de defensa en función de los datos de seguimiento del jugador. El modelo de clasificación de cobertura se entrena utilizando Amazon SageMaker, y la estadística ha sido lanzado para la temporada 2022 de la NFL.
En esta publicación, profundizamos en los detalles técnicos de este modelo ML. Describimos cómo diseñamos un modelo ML preciso y explicable para hacer una clasificación de cobertura a partir de los datos de seguimiento de los jugadores, seguido de nuestra evaluación cuantitativa y los resultados de la explicación del modelo.
Formulación de problemas y desafíos
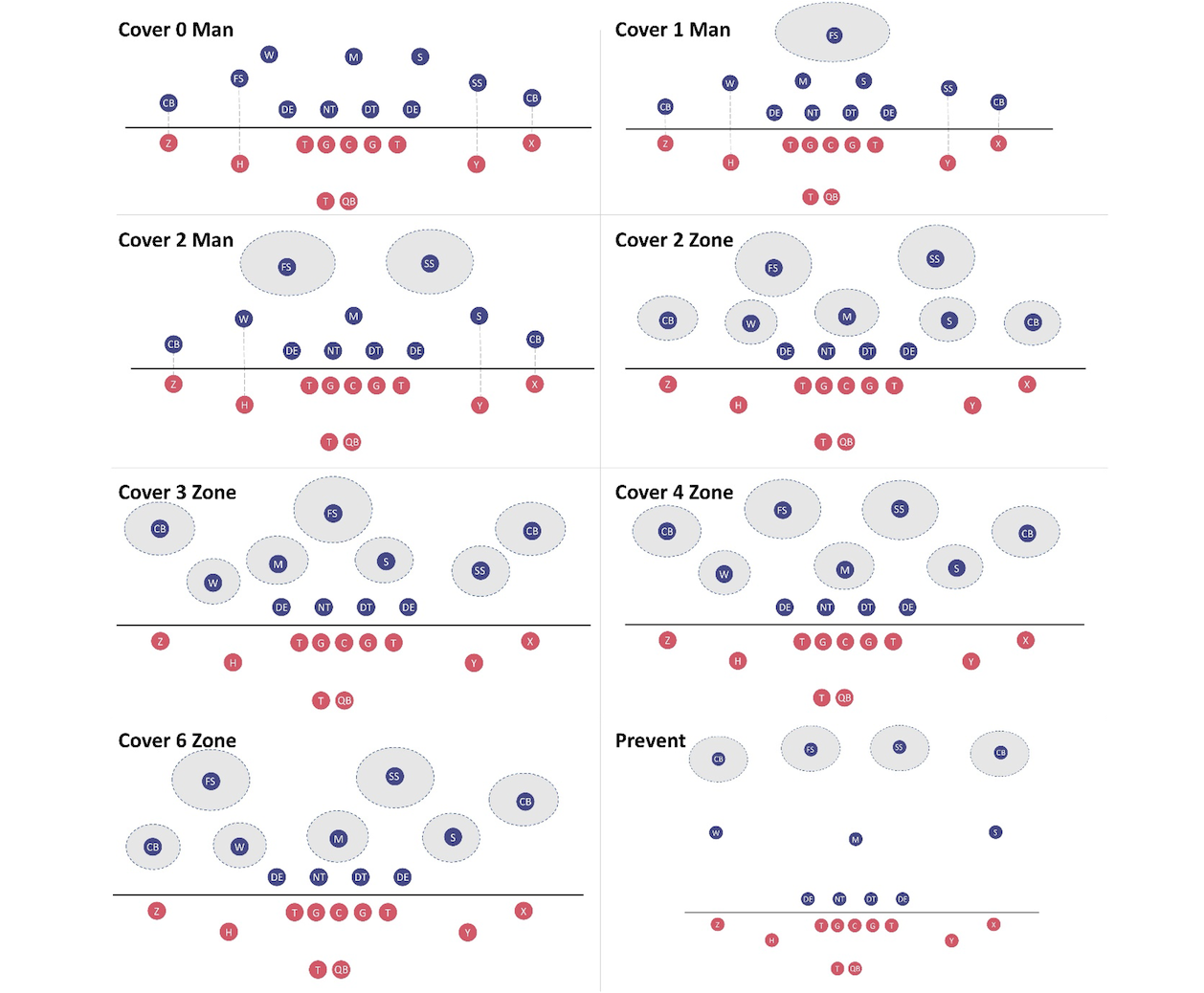
Definimos la clasificación de cobertura defensiva como una tarea de clasificación multiclase, con tres tipos de cobertura de hombre (donde cada jugador defensivo cubre a un jugador ofensivo determinado) y cinco tipos de cobertura de zona (cada jugador defensivo cubre un área determinada en el campo). Estas ocho clases se representan visualmente en la siguiente figura: Cobertura 0 hombre, Cobertura 1 hombre, Cobertura 2 hombre, Cobertura 2 zona, Cobertura 3 zona, Cobertura 4 zona, Cobertura 6 zona y Prevención (también cobertura de zona). Los círculos en azul son los jugadores defensivos dispuestos en un tipo particular de cobertura; los círculos en rojo son los jugadores ofensivos. Se proporciona una lista completa de los acrónimos de los jugadores en el apéndice al final de esta publicación.
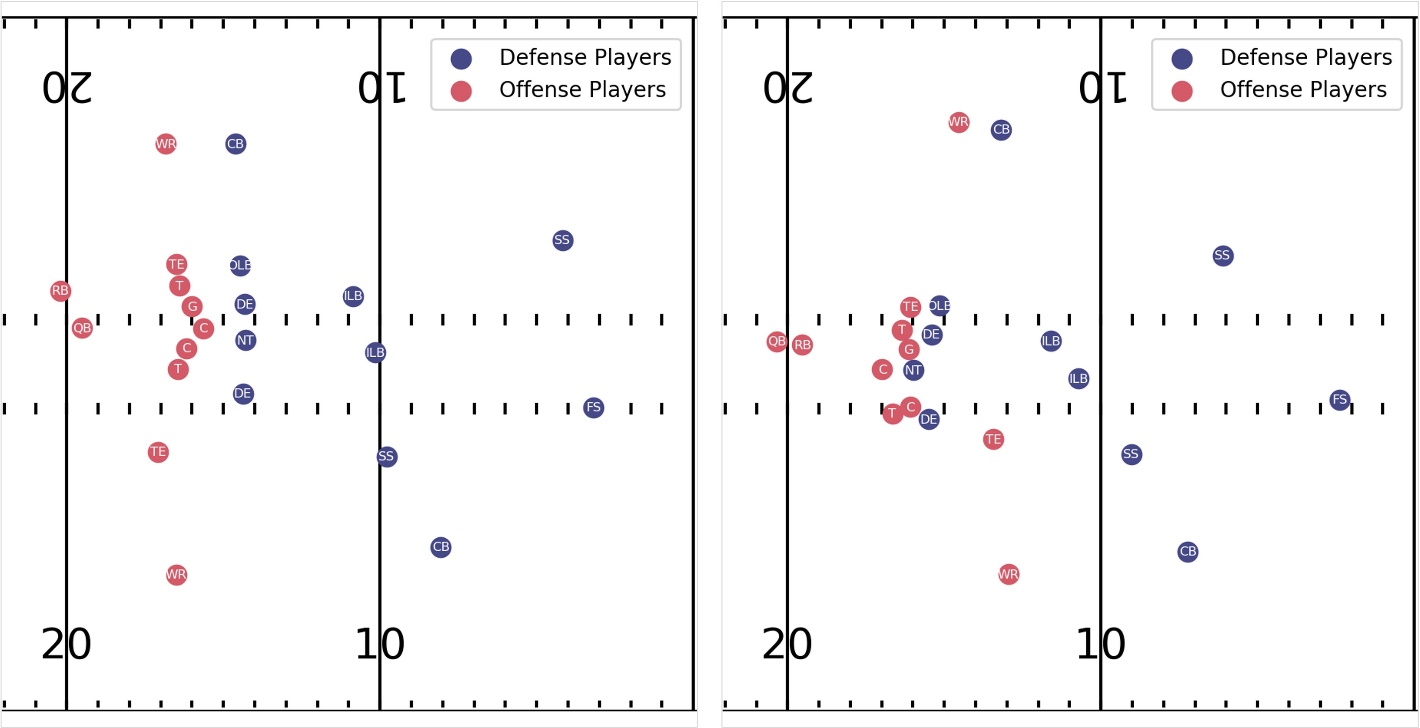
La siguiente visualización muestra una jugada de ejemplo, con la ubicación de todos los jugadores ofensivos y defensivos al comienzo de la jugada (izquierda) y en medio de la misma jugada (derecha). Para realizar la identificación correcta de la cobertura, se debe tener en cuenta una gran cantidad de información a lo largo del tiempo, incluida la forma en que se alinearon los defensores antes del centro y los ajustes en el movimiento del jugador ofensivo una vez que se realiza el centro. Esto plantea el desafío para que el modelo capture el movimiento y la interacción espacio-temporales, y a menudo sutiles, entre los jugadores.
Otro desafío clave que enfrenta nuestra asociación es la ambigüedad inherente en torno a los esquemas de cobertura implementados. Más allá de los ocho esquemas de cobertura comúnmente conocidos, identificamos ajustes en llamadas de cobertura más específicas que conducen a la ambigüedad entre las ocho clases generales tanto para el gráfico manual como para la clasificación del modelo. Abordamos estos desafíos utilizando estrategias de capacitación mejoradas y explicación de modelos. Describimos nuestros enfoques en detalle en la siguiente sección.
Marco de clasificación de cobertura explicable
Ilustramos nuestro marco general en la siguiente figura, con la entrada de datos de seguimiento de jugadores y etiquetas de cobertura que comienzan en la parte superior de la figura.
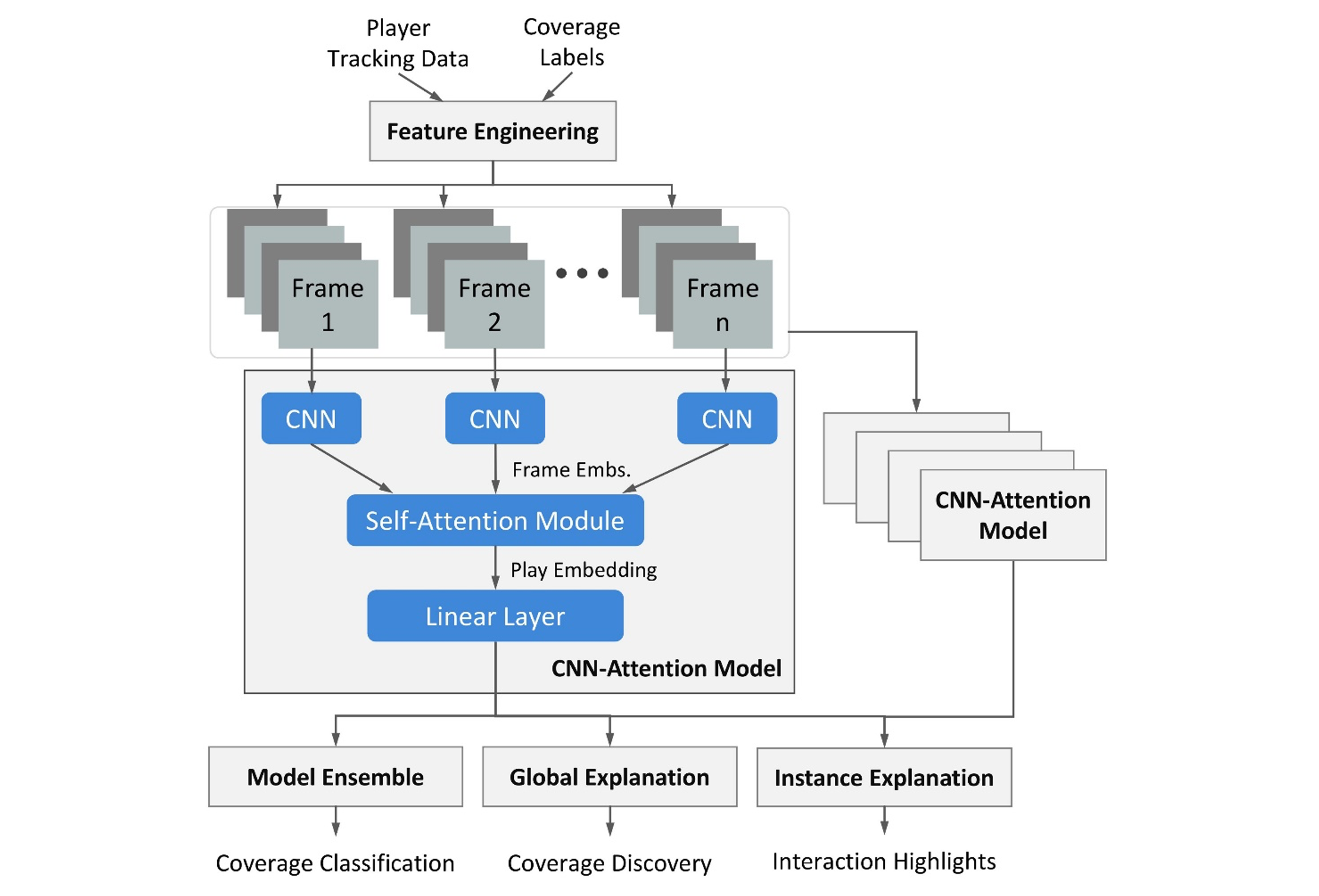
Ingeniería de características
Los datos de seguimiento del juego se capturan a 10 fotogramas por segundo, incluida la ubicación, la velocidad, la aceleración y la orientación del jugador. Nuestra ingeniería de funciones construye secuencias de funciones de juego como entrada para la digestión del modelo. Para un marco dado, nuestras características están inspiradas en la solución 2020 Big Data Bowl Kaggle Zoo (Gordeev et al.): construimos una imagen para cada paso de tiempo con los jugadores defensivos en las filas y los jugadores ofensivos en las columnas. Por lo tanto, el píxel de la imagen representa las características del par de jugadores que se cruzan. Diferente de Gordeev et al., extraemos una secuencia de las representaciones de fotogramas, lo que genera efectivamente un mini-video para caracterizar la obra.
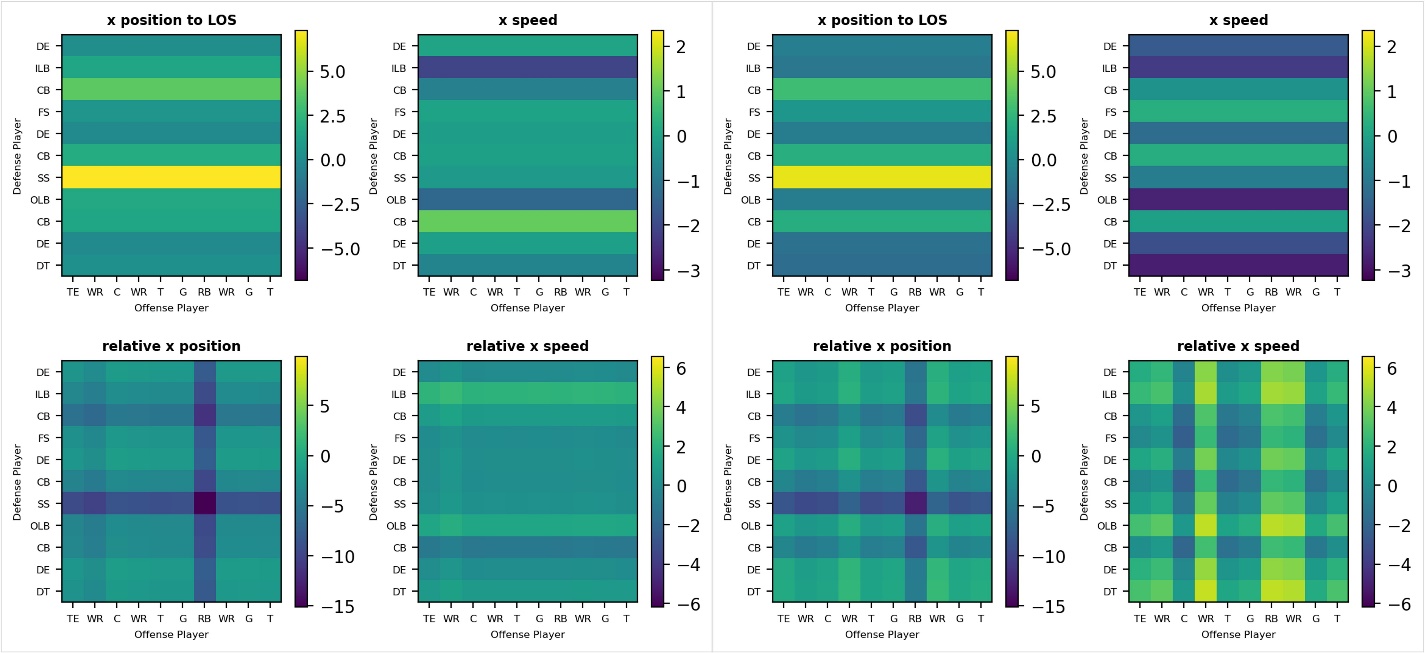
La siguiente figura visualiza cómo evolucionan las funciones con el tiempo en correspondencia con dos instantáneas de una obra de ejemplo. Para mayor claridad visual, solo mostramos cuatro características de todas las que extrajimos. "LOS" en la figura representa la línea de golpeo, y el eje x se refiere a la dirección horizontal a la derecha del campo de fútbol. Observe cómo los valores de las características, indicados por la barra de colores, evolucionan con el tiempo en correspondencia con el movimiento del jugador. En total, construimos dos conjuntos de características de la siguiente manera:
- Características del defensor que consisten en la posición, velocidad, aceleración y orientación del defensor, en el eje x (dirección horizontal hacia la derecha del campo de fútbol) y el eje y (dirección vertical hacia la parte superior del campo de fútbol)
- Características relativas defensor-ofensivo que consisten en los mismos atributos, pero calculados como la diferencia entre los jugadores defensivos y ofensivos.
Módulo CNN
Utilizamos una red neuronal convolucional (CNN) para modelar las complejas interacciones de los jugadores similares a Open Source Football (Balduino et al.) y la solución Big Data Bowl Kaggle Zoo (Gordeev et al.). La imagen obtenida de la ingeniería de características facilitó el modelado de cada marco de juego a través de una CNN. Modificamos el bloque convolucional (Conv) utilizado por la solución Zoo (Gordeev et al.) con una estructura ramificada que se compone de una CNN superficial de una capa y una CNN profunda de tres capas. La capa de convolución utiliza un kernel 1×1 internamente: hacer que el kernel mire a cada par de jugadores individualmente asegura que el modelo no varíe con el orden de los jugadores. Para simplificar, ordenamos a los jugadores según su ID de la NFL para todas las muestras de juego. Obtenemos las incrustaciones de cuadros como salida del módulo CNN.
Modelado temporal
Dentro del breve período de reproducción que dura solo unos segundos, contiene dinámicas temporales ricas como indicadores clave para identificar la cobertura. El modelado CNN basado en cuadros, como se usa en la solución Zoo (Gordeev et al.), no ha tenido en cuenta la progresión temporal. Para afrontar este reto, diseñamos un módulo de autoatención (Vaswani et al.), apilados en la parte superior de la CNN, para el modelado temporal. Durante el entrenamiento, aprende a agregar los marcos individuales pesándolos de manera diferente (Alamar et al.). Lo compararemos con un enfoque LSTM bidireccional más convencional en la evaluación cuantitativa. Las incrustaciones de atención aprendidas como salida se promedian para obtener la incrustación de toda la obra. Finalmente, se conecta una capa completamente conectada para determinar la clase de cobertura del juego.
Conjunto de modelos y suavizado de etiquetas
La ambigüedad entre los ocho esquemas de cobertura y su distribución desequilibrada hacen que la separación clara entre las coberturas sea un desafío. Utilizamos el conjunto de modelos para abordar estos desafíos durante el entrenamiento de modelos. Nuestro estudio encuentra que un conjunto basado en votación, uno de los métodos de conjunto más simples, en realidad supera a los enfoques más complejos. En este método, cada modelo base tiene la misma arquitectura de atención de CNN y se entrena de forma independiente a partir de diferentes semillas aleatorias. La clasificación final toma el promedio de los resultados de todos los modelos base.
Incorporamos además suavizado de etiquetas (Müller et al.) en la pérdida de entropía cruzada para manejar el ruido potencial en las etiquetas de gráficos manuales. El suavizado de etiquetas dirige la clase de cobertura anotada ligeramente hacia las clases restantes. La idea es alentar al modelo a adaptarse a la ambigüedad de cobertura inherente en lugar de sobreajustarse a las anotaciones sesgadas.
Evaluación cuantitativa
Utilizamos datos de la temporada 2018-2020 para la capacitación y validación del modelo, y datos de la temporada 2021 para la evaluación del modelo. Cada temporada consta de alrededor de 17,000 jugadas. Realizamos una validación cruzada de cinco veces para seleccionar el mejor modelo durante el entrenamiento y realizamos una optimización de hiperparámetros para seleccionar la mejor configuración en múltiples parámetros de entrenamiento y arquitectura de modelo.
Para evaluar el rendimiento del modelo, calculamos la precisión de la cobertura, la puntuación F1, la precisión de los 2 principales y la precisión de la tarea hombre vs. zona más sencilla. El modelo Zoo basado en CNN utilizado en Balduino et al. es el más relevante para la clasificación de cobertura y lo usamos como línea de base. Además, consideramos versiones mejoradas de la línea de base que incorporan los componentes de modelado temporal para el estudio comparativo: un modelo CNN-LSTM que utiliza un LSTM bidireccional para realizar el modelado temporal y un modelo de atención de CNN único sin el conjunto y la etiqueta componentes de alisado. Los resultados se muestran en la siguiente tabla.
| Modelo | Exactitud de prueba 8 Coberturas (%) | Precisión de los 2 primeros 8 Coberturas (%) | Puntuación F1 8 Coberturas | Exactitud de prueba Hombre vs Zona (%) |
| Línea de base: modelo de zoológico | 68.8±0.4 | 87.7±0.1 | 65.8±0.4 | 88.4±0.4 |
| CNN-LSTM | 86.5±0.1 | 93.9±0.1 | 84.9±0.2 | 94.6±0.2 |
| CNN-atención | 87.7±0.2 | 94.7±0.2 | 85.9±0.2 | 94.6±0.2 |
| El nuestro: Conjunto de 5 modelos CNN-atención | 88.9±0.1 | 97.6±0.1 | 87.4±0.2 | 95.4±0.1 |
Observamos que la incorporación del módulo de modelado temporal mejora significativamente el modelo Zoo de línea de base que se basaba en un solo cuadro. En comparación con la línea de base sólida del modelo CNN-LSTM, nuestros componentes de modelado propuestos, incluidos el módulo de autoatención, el conjunto de modelos y el suavizado de etiquetado combinado, brindan una mejora significativa del rendimiento. El modelo final es eficiente como lo demuestran las medidas de evaluación. Además, identificamos una precisión muy alta entre los 2 primeros y una diferencia significativa con respecto a la precisión entre los 1 primeros. Esto se puede atribuir a la ambigüedad de la cobertura: cuando la clasificación superior es incorrecta, la segunda suposición a menudo coincide con la anotación humana.
Explicaciones y resultados del modelo
Para arrojar luz sobre la ambigüedad de la cobertura y comprender qué utilizó el modelo para llegar a una conclusión determinada, realizamos un análisis utilizando explicaciones del modelo. Consta de dos partes: explicaciones globales que analizan todas las incrustaciones aprendidas en conjunto y explicaciones locales que se acercan a jugadas individuales para analizar las señales más importantes capturadas por el modelo.
Explicaciones globales
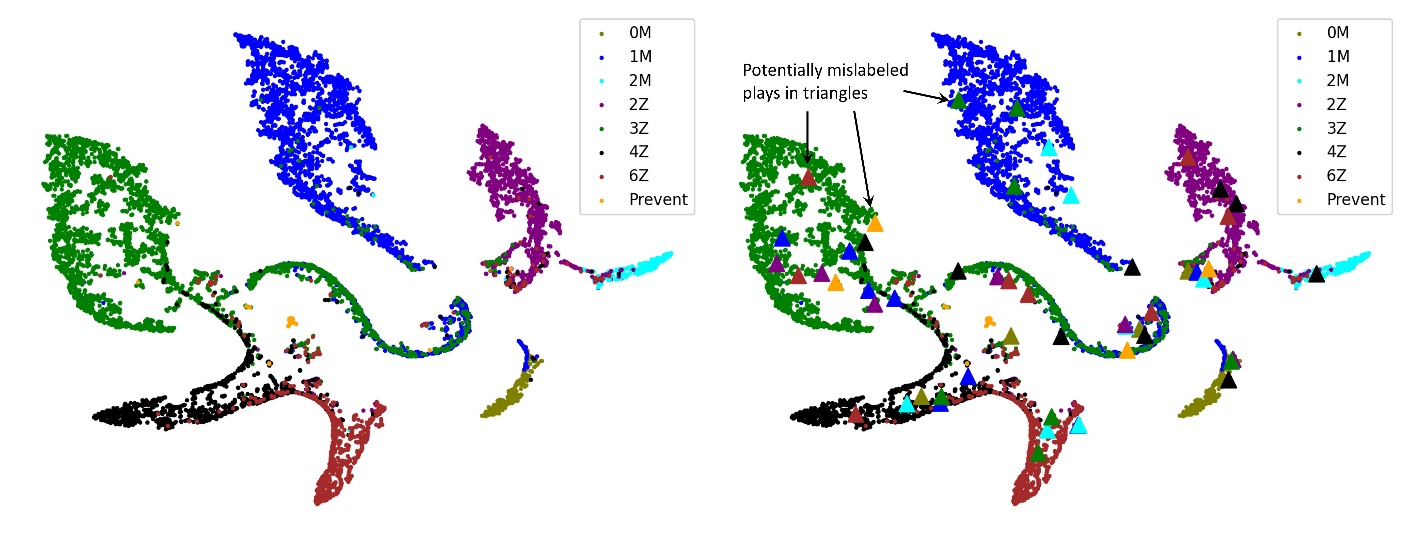
En esta etapa, analizamos globalmente las incrustaciones de juego aprendidas del modelo de clasificación de cobertura para descubrir cualquier patrón que requiera una revisión manual. Utilizamos incrustación de vecinos estocásticos distribuidos en t (t-SNE) (Maaten et al.) que proyecta las incrustaciones de juego en el espacio 2D, como un par de incrustaciones similares que tienen una alta probabilidad en su distribución. Experimentamos con los parámetros internos para extraer proyecciones 2D estables. Las incrustaciones de muestras estratificadas de 9,000 jugadas se visualizan en la siguiente figura (izquierda), donde cada punto representa una determinada jugada. Encontramos que la mayoría de cada esquema de cobertura están bien separados, lo que demuestra la capacidad de clasificación ganada por el modelo. Observamos dos patrones importantes y los investigamos más a fondo.
Algunas jugadas se mezclan con otros tipos de cobertura, como se muestra en la siguiente figura (derecha). Estas jugadas podrían estar mal etiquetadas y merecer una inspección manual. Diseñamos un clasificador K-Nearest Neighbors (KNN) para identificar automáticamente estas jugadas y enviarlas para revisión de expertos. Los resultados muestran que la mayoría de ellos fueron etiquetados incorrectamente.
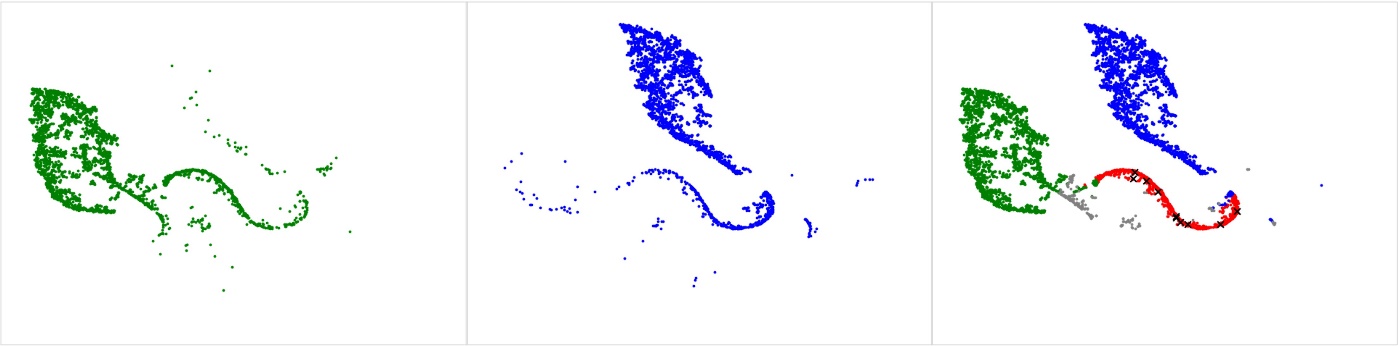
A continuación, observamos varias regiones superpuestas entre los tipos de cobertura, manifestando ambigüedad de cobertura en ciertos escenarios. Como ejemplo, en la siguiente figura, separamos Cover 3 Zone (grupo verde a la izquierda) y Cover 1 Man (grupo azul en el medio). Estos son dos conceptos diferentes de cobertura de altura única, donde la distinción principal es la cobertura de hombre frente a la de zona. Diseñamos un algoritmo que identifica automáticamente la ambigüedad entre estas dos clases como la región superpuesta de los grupos. El resultado se visualiza como los puntos rojos en la siguiente figura de la derecha, con 10 jugadas muestreadas al azar marcadas con una "x" negra para revisión manual. Nuestro análisis revela que la mayoría de los ejemplos de juego en esta región implican algún tipo de coincidencia de patrones. En estas jugadas, las responsabilidades de cobertura dependen de cómo se distribuyan las rutas de los receptores ofensivos, y los ajustes pueden hacer que la jugada parezca una mezcla de coberturas de zona y hombre. Uno de esos ajustes que identificamos se aplica a la Zona de Cobertura 3, cuando el esquinero (CB) de un lado está bloqueado en la cobertura del hombre ("Man Everywhere he Goes" o MEG) y el otro tiene una caída de zona tradicional.
Explicaciones de instancias
En la segunda etapa, las explicaciones de instancia se acercan al juego de interés individual y extraen los aspectos más destacados de la interacción del jugador cuadro por cuadro que contribuyen más al esquema de cobertura identificado. Esto se logra a través del algoritmo Guided GradCAM (Ramprasaath et al.). Utilizamos las explicaciones de la instancia en las predicciones del modelo de baja confianza.
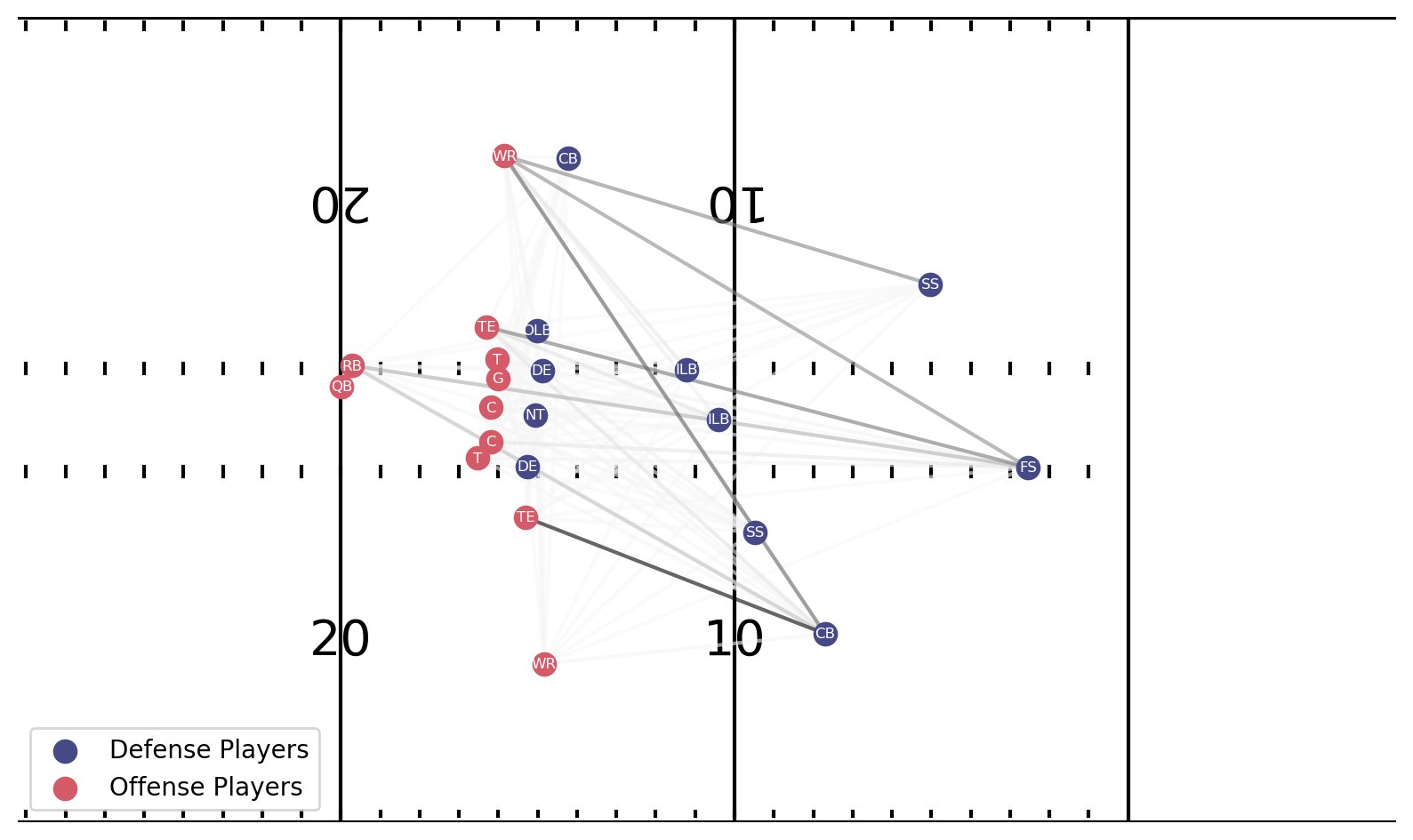
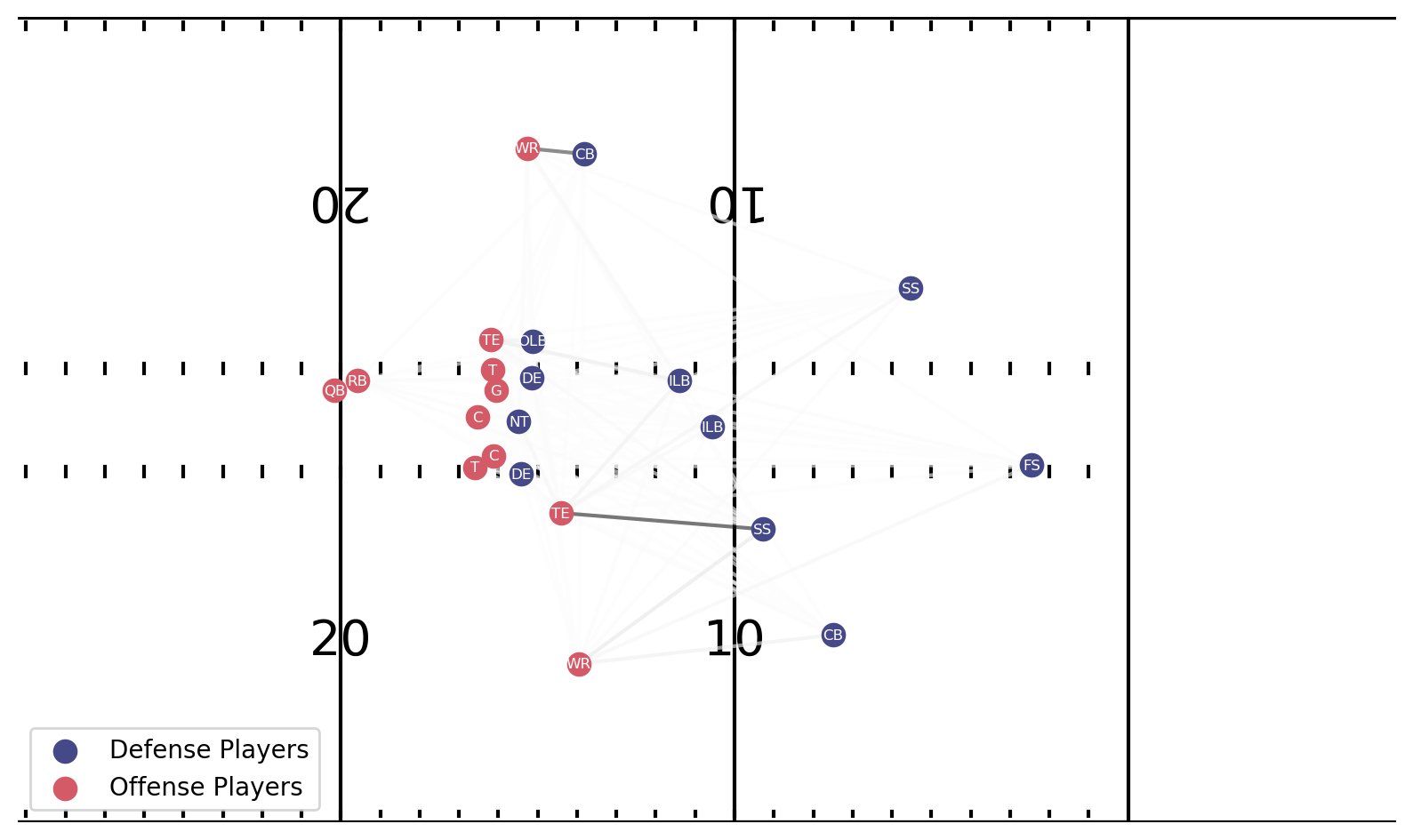
Para la jugada que ilustramos al comienzo de la publicación, el modelo predijo Cobertura 3 Zona con 44.5 % de probabilidad y Cobertura 1 Hombre con 31.3 % de probabilidad. Generamos los resultados de la explicación para ambas clases como se muestra en la siguiente figura. El grosor de línea anota la fuerza de interacción que contribuye a la identificación del modelo.
La trama superior para la explicación de Cover 3 Zone viene justo después del chasquido de la pelota. El CB a la derecha de la ofensiva tiene las líneas de interacción más fuertes, porque está frente al QB y permanece en su lugar. Termina cuadrando y emparejando con el receptor de su lado, quien lo amenaza de fondo.
La trama inferior de la explicación de Cover 1 Man llega un momento después, cuando la acción de juego falsa está ocurriendo. Una de las interacciones más fuertes es con el CB a la izquierda de la ofensiva, que cae con el WR. Las imágenes de reproducción revelan que él mantiene sus ojos en el QB antes de dar la vuelta y correr con el WR que lo amenaza profundamente. El SS a la derecha de la ofensiva también tiene una fuerte interacción con el TE de su lado, ya que comienza a moverse cuando el TE irrumpe en el interior. Termina siguiéndolo a través de la formación, pero el TE comienza a bloquearlo, lo que indica que la jugada probablemente era una opción de pase de carrera. Esto explica la incertidumbre de la clasificación del modelo: el TE se apega al SS por diseño, creando sesgos en los datos.
Conclusión
El laboratorio de soluciones de Amazon ML y el equipo Next Gen Stats de la NFL desarrollaron conjuntamente la estadística de clasificación de cobertura de defensa que fue recientemente lanzado para la temporada de fútbol americano de la NFL 2022. Esta publicación presentó los detalles técnicos de ML de esta estadística, incluido el modelado de la progresión temporal rápida, estrategias de capacitación para manejar la ambigüedad de la clase de cobertura y explicaciones integrales del modelo para acelerar la revisión de expertos tanto a nivel global como de instancia.
La solución hace que las tendencias de cobertura defensiva en vivo y las divisiones estén disponibles para las emisoras en el juego por primera vez. Asimismo, el modelo permite a la NFL mejorar su análisis de los resultados posteriores al juego e identificar mejor los enfrentamientos clave previos a los juegos.
Si desea ayuda para acelerar su uso de ML, comuníquese con el Laboratorio de soluciones de Amazon ML .
Apéndice
| Acrónimos de la posición del jugador | |
| Posiciones defensivas | |
| W | “Will” Linebacker, o el lateral débil LB |
| M | “Mike” Linebacker, o el medio LB |
| S | “Sam” Linebacker, o el lado fuerte LB |
| CB | Cornerback |
| DE | Final defensivo |
| DT | Entrada defensiva |
| NT | Entrada de nariz |
| FS | Seguridad libre |
| SS | Seguridad fuerte |
| S | Safety |
| LB | Linebacker |
| ILB | Apoyador interior |
| OLB | Linebacker externo |
| MLB | Apoyador medio |
| Posiciones ofensivas | |
| X | Por lo general, el receptor abierto número 1 en una ofensiva, se alinean en el LOS. En formaciones de viajes, este receptor a menudo se alinea aislado en la parte trasera. |
| Y | Por lo general, el ala cerrada inicial, este jugador a menudo se alineará en línea y en el lado opuesto a la X. |
| Z | Por lo general, es más un receptor de tragamonedas, este jugador a menudo se alineará fuera de la línea de golpeo y en el mismo lado del campo que el ala cerrada. |
| H | Tradicionalmente un fullback, este jugador es más a menudo un tercer receptor abierto o un segundo ala cerrada en la liga moderna. Pueden alinearse en toda la formación, pero casi siempre están fuera de la línea de golpeo. Dependiendo del equipo, este jugador también podría ser designado como F. |
| T | El corredor destacado. Aparte de las formaciones vacías, este jugador se alineará en el backfield y será una amenaza para recibir el traspaso. |
| QB | El mariscal de campo |
| C | Reubicación |
| G | Guardia |
| RB | Corriendo hacia atrás |
| FB | Retroceso |
| WR | El receptor abierto |
| TE | Tight End |
| LG | Guardia Izquierda |
| RG | Guardia Derecha |
| T | Entrada |
| LT | Entrada izquierda |
| RT | Entrada derecha |
Referencias
- Tej Seth, Ryan Weisman, "Estudio de datos de PFF: singularidad del esquema de cobertura para cada equipo y lo que eso significa para los cambios de entrenador", https://www.pff.com/news/nfl-pff-data-study-coverage-scheme-uniqueness-for-each-team-and-what-that-means-for-coaching-changes
- Ben Balduino. "Visión por computadora con datos de seguimiento de jugadores de la NFL usando antorcha para R: clasificación de cobertura usando CNN". https://www.opensourcefootball.com/posts/2021-05-31-computer-vision-in-r-using-torch/
- Dmitri Gordeev, Philipp Singer. “1er lugar solución El Zoológico.” https://www.kaggle.com/c/nfl-big-data-bowl-2020/discussion/119400
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser e Illia Polosukhin. “La atención es todo lo que necesitas.” Avances en los sistemas de procesamiento de información neuronal. 30 (2017).
- Jay Alammar. "El transformador ilustrado". https://jalammar.github.io/illustrated-transformer/
- Müller, Rafael, Simon Kornblith y Geoffrey E. Hinton. "¿Cuándo ayuda el suavizado de etiquetas?". Avances en los sistemas de procesamiento de información neuronal 32 (2019).
- Van der Maaten, Laurens y Geoffrey Hinton. "Visualización de datos usando t-SNE". Revista de investigación de aprendizaje automático 9, no. 11 (2008).
- Selvaraju, Ramprasaath R., Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh y Dhruv Batra. "Grad-cam: explicaciones visuales de redes profundas a través de la localización basada en gradientes". En Actas de la conferencia internacional de IEEE sobre visión por computadorapp. 618-626 de junio. 2017.
Acerca de los autores
 Huan Song es un científico aplicado en Amazon Machine Learning Solutions Lab, donde trabaja en la entrega de soluciones de ML personalizadas para casos de uso de clientes de alto impacto de una variedad de verticales de la industria. Sus intereses de investigación son las redes neuronales gráficas, la visión artificial, el análisis de series temporales y sus aplicaciones industriales.
Huan Song es un científico aplicado en Amazon Machine Learning Solutions Lab, donde trabaja en la entrega de soluciones de ML personalizadas para casos de uso de clientes de alto impacto de una variedad de verticales de la industria. Sus intereses de investigación son las redes neuronales gráficas, la visión artificial, el análisis de series temporales y sus aplicaciones industriales.
 Mohamad Al Jazaery es científico aplicado en Amazon Machine Learning Solutions Lab. Ayuda a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar sus desafíos comerciales en áreas como logística, personalización y recomendaciones, visión artificial, prevención de fraudes, pronósticos y optimización de la cadena de suministro. Antes de AWS, obtuvo su MCS de la Universidad de West Virginia y trabajó como investigador de visión artificial en Midea. Fuera del trabajo, disfruta del fútbol y los videojuegos.
Mohamad Al Jazaery es científico aplicado en Amazon Machine Learning Solutions Lab. Ayuda a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar sus desafíos comerciales en áreas como logística, personalización y recomendaciones, visión artificial, prevención de fraudes, pronósticos y optimización de la cadena de suministro. Antes de AWS, obtuvo su MCS de la Universidad de West Virginia y trabajó como investigador de visión artificial en Midea. Fuera del trabajo, disfruta del fútbol y los videojuegos.
 haibo ding es científico aplicado sénior en Amazon Machine Learning Solutions Lab. Está muy interesado en el aprendizaje profundo y el procesamiento del lenguaje natural. Su investigación se centra en el desarrollo de nuevos modelos de aprendizaje automático explicables, con el objetivo de hacerlos más eficientes y confiables para los problemas del mundo real. Obtuvo su Ph.D. de la Universidad de Utah y trabajó como científico investigador sénior en Bosch Research North America antes de unirse a Amazon. Además del trabajo, le gusta caminar, correr y pasar tiempo con su familia.
haibo ding es científico aplicado sénior en Amazon Machine Learning Solutions Lab. Está muy interesado en el aprendizaje profundo y el procesamiento del lenguaje natural. Su investigación se centra en el desarrollo de nuevos modelos de aprendizaje automático explicables, con el objetivo de hacerlos más eficientes y confiables para los problemas del mundo real. Obtuvo su Ph.D. de la Universidad de Utah y trabajó como científico investigador sénior en Bosch Research North America antes de unirse a Amazon. Además del trabajo, le gusta caminar, correr y pasar tiempo con su familia.
 Lin Lee Cheong es gerente de ciencias aplicadas en el equipo de Amazon ML Solutions Lab en AWS. Trabaja con clientes estratégicos de AWS para explorar y aplicar inteligencia artificial y aprendizaje automático para descubrir nuevos conocimientos y resolver problemas complejos. Recibió su Ph.D. del Instituto Tecnológico de Massachusetts. Fuera del trabajo, le gusta leer y caminar.
Lin Lee Cheong es gerente de ciencias aplicadas en el equipo de Amazon ML Solutions Lab en AWS. Trabaja con clientes estratégicos de AWS para explorar y aplicar inteligencia artificial y aprendizaje automático para descubrir nuevos conocimientos y resolver problemas complejos. Recibió su Ph.D. del Instituto Tecnológico de Massachusetts. Fuera del trabajo, le gusta leer y caminar.
 jonathan jung es ingeniero de software sénior en la Liga Nacional de Fútbol. Ha estado con el equipo de Next Gen Stats durante los últimos siete años ayudando a desarrollar la plataforma desde la transmisión de datos sin procesar, la creación de microservicios para procesar los datos, hasta la creación de API que exponen los datos procesados. Ha colaborado con Amazon Machine Learning Solutions Lab para proporcionarles datos limpios con los que trabajar, además de proporcionar conocimientos de dominio sobre los datos en sí. Fuera del trabajo, disfruta andar en bicicleta en Los Ángeles y hacer caminatas en las Sierras.
jonathan jung es ingeniero de software sénior en la Liga Nacional de Fútbol. Ha estado con el equipo de Next Gen Stats durante los últimos siete años ayudando a desarrollar la plataforma desde la transmisión de datos sin procesar, la creación de microservicios para procesar los datos, hasta la creación de API que exponen los datos procesados. Ha colaborado con Amazon Machine Learning Solutions Lab para proporcionarles datos limpios con los que trabajar, además de proporcionar conocimientos de dominio sobre los datos en sí. Fuera del trabajo, disfruta andar en bicicleta en Los Ángeles y hacer caminatas en las Sierras.
 mike banda es gerente sénior de investigación y análisis para Next Gen Stats en la National Football League. Desde que se unió al equipo en 2018, ha sido responsable de la ideación, el desarrollo y la comunicación de estadísticas e información clave derivadas de los datos de seguimiento de jugadores para fanáticos, socios de transmisión de la NFL y los 32 clubes por igual. Mike aporta una gran cantidad de conocimientos y experiencia al equipo con una maestría en análisis de la Universidad de Chicago, una licenciatura en gestión deportiva de la Universidad de Florida y experiencia tanto en el departamento de exploración de los Minnesota Vikings como en el departamento de reclutamiento. de Fútbol Florida Gator.
mike banda es gerente sénior de investigación y análisis para Next Gen Stats en la National Football League. Desde que se unió al equipo en 2018, ha sido responsable de la ideación, el desarrollo y la comunicación de estadísticas e información clave derivadas de los datos de seguimiento de jugadores para fanáticos, socios de transmisión de la NFL y los 32 clubes por igual. Mike aporta una gran cantidad de conocimientos y experiencia al equipo con una maestría en análisis de la Universidad de Chicago, una licenciatura en gestión deportiva de la Universidad de Florida y experiencia tanto en el departamento de exploración de los Minnesota Vikings como en el departamento de reclutamiento. de Fútbol Florida Gator.
 miguel chi es un director sénior de tecnología que supervisa las estadísticas de próxima generación y la ingeniería de datos en la Liga Nacional de Fútbol Americano. Tiene una licenciatura en Matemáticas y Ciencias de la Computación de la Universidad de Illinois en Urbana Champaign. Michael se unió a la NFL por primera vez en 2007 y se ha centrado principalmente en tecnología y plataformas para estadísticas de fútbol. En su tiempo libre, disfruta pasar tiempo con su familia al aire libre.
miguel chi es un director sénior de tecnología que supervisa las estadísticas de próxima generación y la ingeniería de datos en la Liga Nacional de Fútbol Americano. Tiene una licenciatura en Matemáticas y Ciencias de la Computación de la Universidad de Illinois en Urbana Champaign. Michael se unió a la NFL por primera vez en 2007 y se ha centrado principalmente en tecnología y plataformas para estadísticas de fútbol. En su tiempo libre, disfruta pasar tiempo con su familia al aire libre.
 felicidad de thompson es Gerente de Operaciones de Fútbol, Científico de Datos en la Liga Nacional de Fútbol. Comenzó en la NFL en febrero de 2020 como científico de datos y fue ascendido a su cargo actual en diciembre de 2021. Completó su maestría en ciencia de datos en la Universidad de Columbia en la ciudad de Nueva York en diciembre de 2019. Recibió una licenciatura en ciencias en Física y Astronomía con menciones en Matemáticas y Ciencias de la Computación en la Universidad de Wisconsin - Madison en 2018.
felicidad de thompson es Gerente de Operaciones de Fútbol, Científico de Datos en la Liga Nacional de Fútbol. Comenzó en la NFL en febrero de 2020 como científico de datos y fue ascendido a su cargo actual en diciembre de 2021. Completó su maestría en ciencia de datos en la Universidad de Columbia en la ciudad de Nueva York en diciembre de 2019. Recibió una licenciatura en ciencias en Física y Astronomía con menciones en Matemáticas y Ciencias de la Computación en la Universidad de Wisconsin - Madison en 2018.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/identifying-defense-coverage-schemes-in-nfls-next-gen-stats/

