Introducción
Esta guía es la tercera y última parte de tres guías sobre Support Vector Machines (SVM). En esta guía, seguiremos trabajando con el caso de uso de billetes de banco falsificados, haremos un resumen rápido de la idea general detrás de las SVM, entenderemos cuál es el truco del kernel e implementaremos diferentes tipos de kernels no lineales con Scikit-Learn.
En la serie completa de guías de SVM, además de aprender sobre otros tipos de SVM, también aprenderá sobre SVM simples, parámetros predefinidos de SVM, hiperparámetros C y Gamma y cómo se pueden ajustar con búsqueda en cuadrícula y validación cruzada.
Si desea leer las guías anteriores, puede echar un vistazo a las dos primeras guías o ver qué temas le interesan más. A continuación se muestra la tabla de temas tratados en cada guía:
- Caso de uso: olvidar los billetes de banco
- Antecedentes de las SVM
- Modelo SVM simple (lineal)
- Acerca del conjunto de datos
- Importación del conjunto de datos
- Explorando el conjunto de datos
- Implementación de SVM con Scikit-Learn
- División de datos en conjuntos de prueba/entrenamiento
- Entrenando el modelo
- Haciendo predicciones
- Evaluación del modelo
- Interpretación de resultados
- El hiperparámetro C
- El hiperparámetro gamma
3. Implementar otras versiones de SVM con Scikit-Learn de Python
- La idea general de las SVM (un resumen)
- Núcleo (truco) SVM
- Implementación de SVM de kernel no lineal con Scikit-Learn
- Importando Bibliotecas
- Importación del conjunto de datos
- División de datos en características (X) y destino (y)
- División de datos en conjuntos de prueba/entrenamiento
- Entrenamiento del algoritmo
- Núcleo polinomial
- Haciendo predicciones
- Evaluación del algoritmo
- Kernel gaussiano
- Predicción y Evaluación
- Núcleo sigmoide
- Predicción y Evaluación
- Comparación de rendimientos de núcleos no lineales
Recordemos de qué se trata SVM antes de ver algunas variaciones interesantes del kernel de SVM.
La idea general de las SVM
En el caso de datos linealmente separables en dos dimensiones (como se muestra en la Fig. 1), el enfoque típico del algoritmo de aprendizaje automático sería tratar de encontrar un límite que divida los datos de tal manera que se minimice el error de clasificación errónea. Si observa detenidamente la figura 1, observe que puede haber varios límites (infinitos) que dividen los puntos de datos correctamente. Las dos líneas discontinuas, así como la línea continua, son todas clasificaciones válidas de los datos.
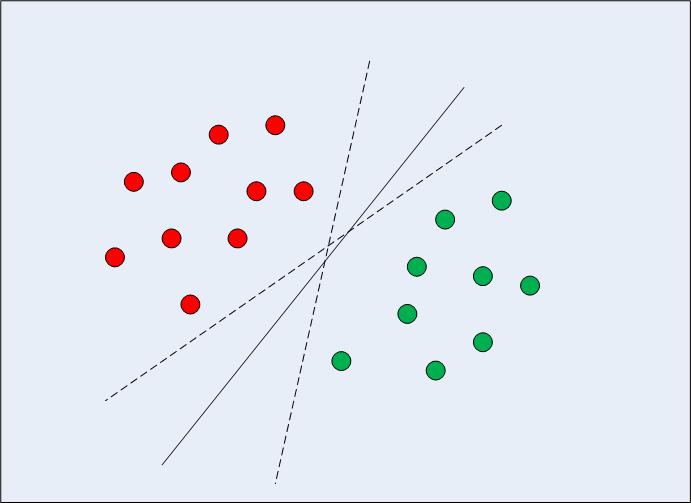
Fig 1: Límites de Decisión Múltiple
Cuando SVM elige el límite de decisión, elige un límite que maximiza la distancia entre él y los puntos de datos más cercanos de las clases. Ya sabemos que los puntos de datos más cercanos son los vectores soporte y que la distancia se puede parametrizar tanto por C y gamma hiperparámetros.
Al calcular ese límite de decisión, el algoritmo elige cuántos puntos considerar y hasta dónde puede llegar el margen; esto configura un problema de maximización del margen. Al resolver ese problema de maximización del margen, SVM usa los vectores de soporte (como se ve en la Fig. 2) e intenta descubrir cuáles son los valores óptimos que mantienen la distancia del margen más grande, mientras clasifica más puntos correctamente de acuerdo con la función que se está usando para separar los datos.
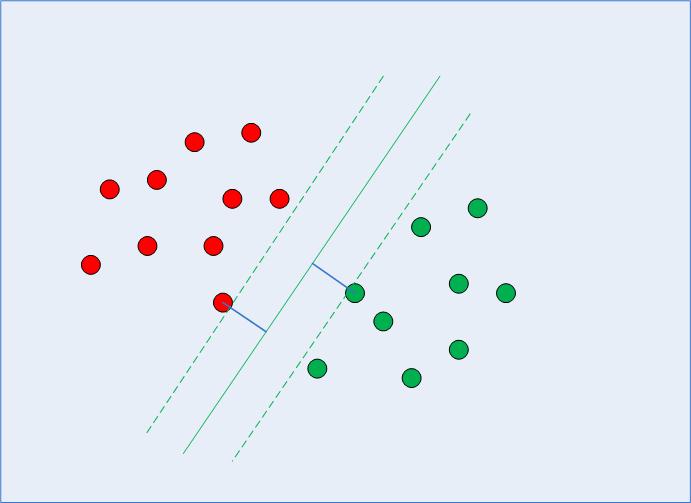
Fig. 2: Límite de decisión con vectores de soporte
Esta es la razón por la que SVM difiere de otros algoritmos de clasificación, ya que no solo encuentra un límite de decisión, sino que termina encontrando el límite de decisión óptimo.
Hay matemáticas complejas derivadas de estadísticas y métodos computacionales involucrados detrás de encontrar los vectores de soporte, calcular el margen entre el límite de decisión y los vectores de soporte y maximizar ese margen. Esta vez, no entraremos en los detalles de cómo se desarrollan las matemáticas.
Siempre es importante profundizar más y asegurarse de que los algoritmos de aprendizaje automático no sean una especie de hechizo misterioso, aunque no conocer todos los detalles matemáticos en este momento no impidió ni impedirá que pueda ejecutar el algoritmo y obtener resultados.
Consejo: ahora que hemos hecho un resumen del proceso algorítmico, está claro que la distancia entre los puntos de datos afectará el límite de decisión que elija SVM, por eso, escalando los datos suele ser necesario cuando se utiliza un clasificador SVM. Intenta usar Método de escalador estándar de Scikit-learn para preparar los datos y luego volver a ejecutar los códigos para ver si hay una diferencia en los resultados.
Núcleo (truco) SVM
En la sección anterior, recordamos y organizamos la idea general de SVM, viendo cómo se puede usar para encontrar el límite de decisión óptimo para datos linealmente separables. Sin embargo, en el caso de datos separables no linealmente, como el que se muestra en la Fig. 3, ya sabemos que una línea recta no se puede utilizar como límite de decisión.
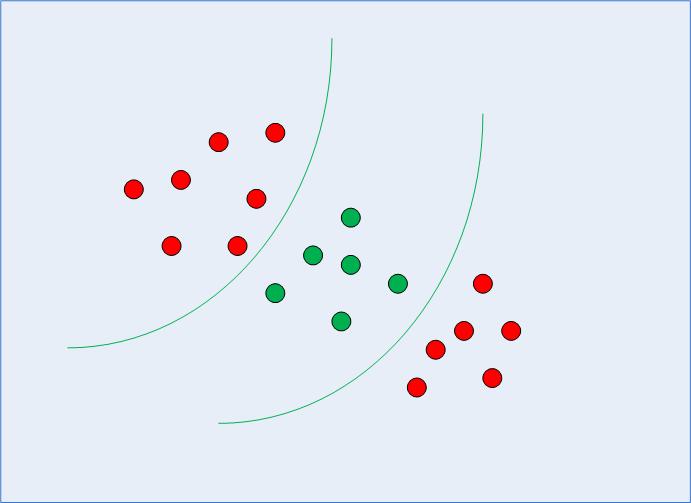
Fig. 3: Datos separables no lineales
Más bien, podemos usar la versión modificada de SVM que habíamos discutido al principio, llamada Kernel SVM.
Básicamente, lo que hará el kernel SVM es proyectar los datos separables no linealmente de dimensiones inferiores a su forma correspondiente en dimensiones superiores. Esto es un truco, porque cuando se proyectan datos separables no linealmente en dimensiones más altas, la forma de los datos cambia de tal manera que se vuelve separable. Por ejemplo, al pensar en 3 dimensiones, los puntos de datos de cada clase podrían terminar asignándose en una dimensión diferente, haciéndola separable. Una forma de aumentar las dimensiones de los datos puede ser mediante su exponenciación. Nuevamente, hay matemáticas complejas involucradas en esto, pero no tiene que preocuparse por eso para usar SVM. Más bien, podemos usar la biblioteca Scikit-Learn de Python para implementar y usar los núcleos no lineales de la misma manera que hemos usado el lineal.
Implementación de SVM de kernel no lineal con Scikit-Learn
En esta sección, usaremos el mismo conjunto de datos para predecir si un billete de banco es real o falso según las cuatro características que ya conocemos.
Verá que el resto de los pasos son pasos típicos de aprendizaje automático y necesitan muy poca explicación hasta que lleguemos a la parte en la que entrenamos nuestras SVM de kernel no lineal.
Importando Bibliotecas
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
Importación del conjunto de datos
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
División de datos en características (X) y destino (y)
X = bankdata.drop('class', axis=1)
y = bankdata['class']
División de datos en conjuntos de prueba/entrenamiento
SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Entrenamiento del algoritmo
Para entrenar el kernel SVM, usaremos el mismo SVC clase de Scikit-Learn's svm biblioteca. La diferencia radica en el valor del parámetro kernel del SVC clase.
En el caso de la SVM simple, hemos utilizado "lineal" como valor para el parámetro del núcleo. Sin embargo, como mencionamos anteriormente, para kernel SVM, podemos usar kernels gaussianos, polinómicos, sigmoides o computables. Implementaremos núcleos polinómicos, gaussianos y sigmoides y veremos sus métricas finales para ver cuál parece encajar en nuestras clases con una métrica más alta.
1. Núcleo polinomial
En álgebra, un polinomio es una expresión de la forma:
$$
2a*b^3 + 4a – 9
$$
Esto tiene variables, tales como a y b, constantes, en nuestro ejemplo, 9 y coeficientes (constantes acompañadas de variables), como 2 y 4. 3 se considera que es el grado del polinomio.
Hay tipos de datos que se pueden describir mejor cuando se usa una función polinomial, aquí, lo que hará el kernel es asignar nuestros datos a un polinomio en el que elegiremos el grado. Cuanto mayor sea el grado, más intentará la función acercarse a los datos, por lo que el límite de decisión es más flexible (y más propenso a sobreajustarse); cuanto menor sea el grado, menos flexible.
Consulte nuestra guía práctica y práctica para aprender Git, con las mejores prácticas, los estándares aceptados por la industria y la hoja de trucos incluida. Deja de buscar en Google los comandos de Git y, de hecho, aprenden ella!
Entonces, para implementar el núcleo polinomial, además de elegir la poly kernel, también pasaremos un valor para el degree parámetro de la SVC clase. A continuación se muestra el código:
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', degree=8)
svc_poly.fit(X_train, y_train)
Haciendo predicciones
Ahora, una vez que hemos entrenado el algoritmo, el siguiente paso es hacer predicciones sobre los datos de prueba.
Como hemos hecho antes, podemos ejecutar el siguiente script para hacerlo:
y_pred_poly = svclassifier.predict(X_test)
Evaluación del algoritmo
Como de costumbre, el paso final es hacer evaluaciones en el núcleo polinomial. Ya que hemos repetido el código para el informe de clasificación y la matriz de confusión varias veces, transformémoslo en una función que display_results después de recibir los respectivos y_test, y_pred y el título de la matriz de confusión de Seaborn con cm_title:
def display_results(y_test, y_pred, cm_title): cm = confusion_matrix(y_test,y_pred) sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title) print(classification_report(y_test,y_pred))
Ahora, podemos llamar a la función y ver los resultados obtenidos con el núcleo polinomial:
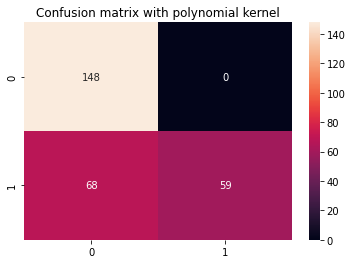
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
El resultado se ve así:
precision recall f1-score support 0 0.69 1.00 0.81 148 1 1.00 0.46 0.63 127 accuracy 0.75 275 macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275
Ahora podemos repetir los mismos pasos para los núcleos gaussiano y sigmoide.
2. Núcleo gaussiano
Para usar el kernel gaussiano, solo necesitamos especificar 'rbf' como valor para el kernel parámetro de la clase SVC:
svc_gaussian = SVC(kernel='rbf', degree=8)
svc_gaussian.fit(X_train, y_train)
Al explorar más a fondo este núcleo, también puede usar la búsqueda en cuadrícula para combinarlo con diferentes C y gamma valores.
Predicción y Evaluación
y_pred_gaussian = svc_gaussian.predict(X_test)
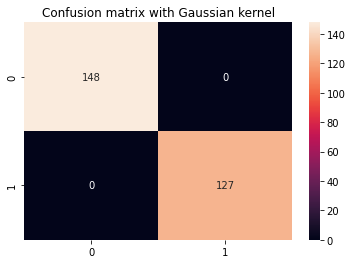
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
La salida del kernel SVM de Gauss se ve así:
precision recall f1-score support 0 1.00 1.00 1.00 148 1 1.00 1.00 1.00 127 accuracy 1.00 275 macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275
3. Núcleo sigmoide
Finalmente, usemos un kernel sigmoide para implementar Kernel SVM. Echa un vistazo al siguiente script:
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.fit(X_train, y_train)
Para usar el kernel sigmoide, debe especificar 'sigmoid' como valor para el kernel parámetro de la SVC clase.
Predicción y Evaluación
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
La salida de Kernel SVM con Sigmoid kernel se ve así:
precision recall f1-score support 0 0.67 0.71 0.69 148 1 0.64 0.59 0.61 127 accuracy 0.65 275 macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

Comparación de rendimientos de núcleos no lineales
Si comparamos brevemente el rendimiento de los diferentes tipos de núcleos no lineales, podría parecer que el núcleo sigmoide tiene las métricas más bajas, por lo tanto, el peor rendimiento.
Entre los núcleos gaussiano y polinómico, podemos ver que el núcleo gaussiano logró una tasa de predicción perfecta del 100 %, lo que suele ser sospechoso y puede indicar un sobreajuste, mientras que el núcleo polinómico clasificó erróneamente 68 instancias de clase 1.
Por lo tanto, no existe una regla estricta y rápida sobre qué kernel funciona mejor en cada escenario o en nuestro escenario actual sin buscar más hiperparámetros, comprender cada forma de función, explorar los datos y comparar los resultados del entrenamiento y la prueba para ver si el algoritmo funciona. está generalizando.
Se trata de probar todos los kernels y seleccionar el que con la combinación de parámetros y preparación de datos dé los resultados esperados según el contexto de tu proyecto.
Yendo más allá: proyecto portátil de extremo a extremo
¿Tu naturaleza inquisitiva te hace querer ir más allá? Recomendamos revisar nuestro Proyecto Guiado: “Predicción práctica del precio de la vivienda: aprendizaje automático en Python”.

En este proyecto guiado, aprenderá a crear potentes modelos tradicionales de aprendizaje automático, así como modelos de aprendizaje profundo, utilizar Ensemble Learning y capacitar a los meta-aprendices para predecir los precios de la vivienda a partir de una bolsa de modelos Scikit-Learn y Keras.
Usando Keras, la API de aprendizaje profundo construida sobre Tensorflow, experimentaremos con arquitecturas, construiremos un conjunto de modelos apilados y entrenaremos un meta-aprendiz red neuronal (modelo de nivel 1) para calcular el precio de una casa.
El aprendizaje profundo es sorprendente, pero antes de recurrir a él, se recomienda intentar resolver el problema con técnicas más simples, como con aprendizaje superficial algoritmos Nuestro rendimiento de referencia se basará en un Regresión de bosque aleatorio algoritmo. Además, exploraremos la creación de conjuntos de modelos a través de Scikit-Learn a través de técnicas como harpillera y votación.
Este es un proyecto integral y, como todos los proyectos de Machine Learning, comenzaremos con: con Análisis exploratorio de datos (XNUMX %) Preprocesamiento de datos y finalmente edificio poco profundo y Modelos de aprendizaje profundo para ajustarse a los datos que hemos explorado y limpiado previamente.
Conclusión
En este artículo, hicimos un resumen rápido de las SVM, estudiamos el truco del kernel e implementamos diferentes tipos de SVM no lineales.
Le sugiero que implemente cada kernel y siga avanzando. Puede explorar las matemáticas utilizadas para crear cada uno de los diferentes núcleos, por qué se crearon y las diferencias con respecto a sus hiperparámetros. De esa manera, aprenderá sobre las técnicas y qué tipo de kernel es mejor aplicar según el contexto y los datos disponibles.
Tener una comprensión clara de cómo funciona cada núcleo y cuándo usarlo definitivamente lo ayudará en su viaje. ¡Háganos saber cómo va el progreso y feliz codificación!
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://stackabuse.com/implementing-other-svm-flavors-with-pythons-scikit-learn/

