Introducción
Esta guía es la primera parte de tres guías sobre Support Vector Machines (SVM). En esta serie, trabajaremos en un caso de uso de billetes de banco falsificados, aprenderemos sobre el SVM simple, luego sobre los hiperparámetros del SVM y, finalmente, aprenderemos un concepto llamado truco del grano y explore otros tipos de SVM.
Si deseas leer todas las guías o ver cuáles te interesan más, a continuación se muestra la tabla de temas tratados en cada guía:
1. Implementación de SVM y Kernel SVM con Scikit-Learn de Python
- Caso de uso: olvidar los billetes de banco
- Antecedentes de las SVM
- Modelo SVM simple (lineal)
- Acerca del conjunto de datos
- Importación del conjunto de datos
- Explorando el conjunto de datos
- Implementación de SVM con Scikit-Learn
- División de datos en conjuntos de prueba/entrenamiento
- Entrenando el modelo
- Haciendo predicciones
- Evaluación del modelo
- Interpretación de resultados
2. Comprender los hiperparámetros de SVM (¡próximamente!)
- El hiperparámetro C
- El hiperparámetro gamma
3. Implementar otras versiones de SVM con Scikit-Learn de Python (¡próximamente!)
- La idea general de las SVM (un resumen)
- Núcleo (truco) SVM
- Implementación de kernel SVM no lineal con Scikit-Learn
- Importación de bibliotecas
- Importando el conjunto de datos
- Dividir datos en características (X) y destino (y)
- División de datos en conjuntos de prueba/entrenamiento
- Entrenamiento del algoritmo
- Núcleo polinomial
- Haciendo predicciones
- Evaluación del algoritmo
- Kernel gaussiano
- Predicción y Evaluación
- Núcleo sigmoide
- Predicción y Evaluación
- Comparación de rendimientos de núcleos no lineales
Caso de uso: billetes de banco falsificados
A veces la gente encuentra una manera de falsificar billetes de banco. Si hay una persona mirando esas notas y verificando su validez, puede ser difícil que te engañen.
Pero, ¿qué sucede cuando no hay una persona para mirar cada nota? ¿Hay alguna forma de saber automáticamente si los billetes son falsos o reales?
Hay muchas maneras de responder a esas preguntas. Una respuesta es fotografiar cada billete recibido, comparar su imagen con la imagen de un billete falsificado y luego clasificarlo como real o falsificado. Si bien puede ser tedioso o crítico esperar la validación de la nota, también sería interesante hacer esa comparación rápidamente.
Dado que se utilizan imágenes, se pueden compactar, reducir a escala de grises y extraer o cuantificar sus medidas. De esta forma, la comparación sería entre las medidas de las imágenes, en lugar del píxel de cada imagen.
Hasta ahora, hemos encontrado una forma de procesar y comparar billetes de banco, pero ¿cómo se clasificarán en reales o falsos? Podemos usar el aprendizaje automático para hacer esa clasificación. Hay un algoritmo de clasificación llamado Máquinas de vectores soporte, conocido principalmente por su forma abreviada: SVM.
Antecedentes de las SVM
Las SVM se introdujeron inicialmente en 1968 por Vladmir Vapnik y Alexey Chervonenkis. En ese momento, su algoritmo se limitaba a la clasificación de datos que podían separarse usando solo una línea recta, o datos que eran separables linealmente. Podemos ver cómo se vería esa separación:

En la imagen de arriba tenemos una línea en el medio, a la cual algunos puntos están a la izquierda y otros a la derecha de esa línea. Fíjate que ambos grupos de puntos están perfectamente separados, no hay puntos en medio ni cerca de la línea. Parece que hay un margen entre puntos similares y la línea que los divide, ese margen se llama margen de separación. La función del margen de separación es agrandar el espacio entre los puntos similares y la línea que los divide. SVM hace eso usando algunos puntos y calcula sus vectores perpendiculares para respaldar la decisión del margen de la línea. esos son los vectores de apoyo que forman parte del nombre del algoritmo. Vamos a entender más sobre ellos más adelante. Y la línea recta que vemos en el medio se encuentra por métodos que maximizarán ese espacio entre la línea y los puntos, o que maximicen el margen de separación. Esos métodos se originan en el campo de la Teoría de la optimización.
En el ejemplo que acabamos de ver, ambos grupos de puntos se pueden separar fácilmente, ya que cada punto individual está cerca de sus puntos similares, y los dos grupos están lejos el uno del otro.
Pero, ¿qué sucede si no hay forma de separar los datos usando una línea recta? ¿Si hay puntos desordenados fuera de lugar, o si se necesita una curva?
Para resolver ese problema, SVM se perfeccionó más tarde en la década de 1990 para poder clasificar también datos que tenían puntos que estaban lejos de su tendencia central, como valores atípicos o problemas más complejos que tenían más de dos dimensiones y no eran linealmente separables. .
Lo curioso es que solo en los últimos años se han adoptado ampliamente los SVM, principalmente debido a su capacidad para lograr a veces más del 90% de las respuestas correctas o la exactitud, para problemas difíciles.
Las SVM se implementan de una manera única en comparación con otros algoritmos de aprendizaje automático, una vez que se basan en explicaciones estadísticas de lo que es el aprendizaje, o en Teoría estadística del aprendizaje.
En este artículo, veremos qué son los algoritmos de las máquinas de vectores de soporte, la breve teoría detrás de una máquina de vectores de soporte y su implementación en la biblioteca Scikit-Learn de Python. Luego avanzaremos hacia otro concepto de SVM, conocido como Núcleo SVMo truco del núcleo, y también lo implementará con la ayuda de Scikit-Learn.
Modelo SVM simple (lineal)
Acerca del conjunto de datos
Siguiendo el ejemplo dado en la introducción, utilizaremos un conjunto de datos que tiene medidas de imágenes de billetes de banco reales y falsificados.
Cuando miramos dos notas, nuestros ojos generalmente las escanean de izquierda a derecha y verifican dónde puede haber similitudes o diferencias. Buscamos un punto negro que viene antes de un punto verde, o una marca brillante que está encima de una ilustración. Esto significa que hay un orden en el que miramos las notas. Si supiéramos que hay verdes y puntos negros, pero no si el punto verde viene antes que el negro, o si el negro viene antes que el verde, sería más difícil discriminar entre notas.
Existe un método similar al que acabamos de describir que se puede aplicar a las imágenes de billetes de banco. En términos generales, este método consiste en traducir los píxeles de la imagen en una señal, luego tomar en consideración el orden en que sucede cada señal diferente en la imagen transformándola en pequeñas ondas, o ondículas. Después de obtener las wavelets, existe una forma de saber el orden en que una señal pasa antes que otra, o el equipo, pero no exactamente qué señal. Para saber eso, es necesario obtener las frecuencias de la imagen. Se obtienen por un método que hace la descomposición de cada señal, llamado método de Fourier.
Una vez obtenida la dimensión de tiempo a través de las wavelets, y la dimensión de frecuencia a través del método de Fourier, se hace una superposición de tiempo y frecuencia para ver cuando ambos tienen coincidencia, este es el circunvolución análisis. La convolución obtiene un ajuste que hace coincidir las ondículas con las frecuencias de la imagen y descubre qué frecuencias son más prominentes.
Este método que consiste en encontrar las ondículas, sus frecuencias y luego ajustarlas a ambas, se llama Transformada wavelet. La transformada wavelet tiene coeficientes, y esos coeficientes se usaron para obtener las medidas que tenemos en el conjunto de datos.
Importación del conjunto de datos
El conjunto de datos de billetes de banco que vamos a utilizar en esta sección es el mismo que se utilizó en la sección de clasificación del tutorial de arbol de decision.
Nota: Puede descargar el conjunto de datos esta página.
Importemos los datos en un pandas. dataframe estructura, y eche un vistazo a sus primeras cinco filas con el head() método.
Observe que los datos se guardan en un txt (texto), separado por comas y sin encabezado. Podemos reconstruirlo como una tabla leyéndolo como un csv, especificando el separator como una coma, y agregando los nombres de las columnas con el names argumento.
Sigamos esos tres pasos a la vez y luego observemos las primeras cinco filas de datos:
import pandas as pd data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()
Esto resulta en:
variance skewness curtosis entropy class
0 3.62160 8.6661 -2.8073 -0.44699 0
1 4.54590 8.1674 -2.4586 -1.46210 0
2 3.86600 -2.6383 1.9242 0.10645 0
3 3.45660 9.5228 -4.0112 -3.59440 0
4 0.32924 -4.4552 4.5718 -0.98880 0
Nota: También puede guardar los datos localmente y sustituirlos data_link para data_pathy pase la ruta a su archivo local.
Podemos ver que hay cinco columnas en nuestro conjunto de datos, a saber, variance, skewness, curtosis, entropyy class. En las cinco filas, las primeras cuatro columnas se llenan con números como 3.62160, 8.6661, -2.8073 o continuo valores y el último class columna tiene sus primeras cinco filas llenas de ceros, o un discreto .
Dado que nuestro objetivo es predecir si un billete de banco es auténtico o no, podemos hacerlo basándonos en los cuatro atributos del billete:
-
variancede la imagen Wavelet transformada. Generalmente, la varianza es un valor continuo que mide cuánto los puntos de datos están cerca o lejos del valor promedio de los datos. Si los puntos están más cerca del valor promedio de los datos, la distribución está más cerca de una distribución normal, lo que generalmente significa que sus valores están mejor distribuidos y son algo más fáciles de predecir. En el contexto de la imagen actual, esta es la varianza de los coeficientes que resultan de la transformada wavelet. Cuanto menor sea la variación, más cerca estarán los coeficientes de traducir la imagen real. -
skewnessde la imagen Wavelet transformada. La asimetría es un valor continuo que indica la asimetría de una distribución. Si hay más valores a la izquierda de la media, la distribución es sesgado negativamente, si hay más valores a la derecha de la media, la distribución es positivamente sesgado, y si la media, la moda y la mediana son iguales, la distribución es simétrico. Cuanto más simétrica es una distribución, más se acerca a una distribución normal, teniendo también sus valores mejor distribuidos. En el presente contexto, esta es la asimetría de los coeficientes que resultan de la transformada wavelet. Cuanto más simétricos, más próximos serán los coeficientes quevariance,skewness,curtosis,entropyvolver a traducir la imagen real.
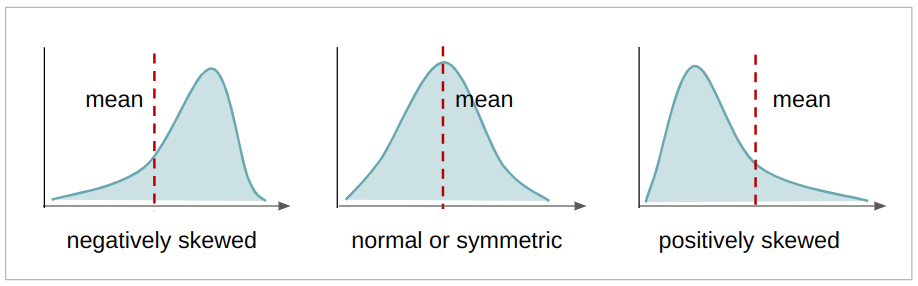
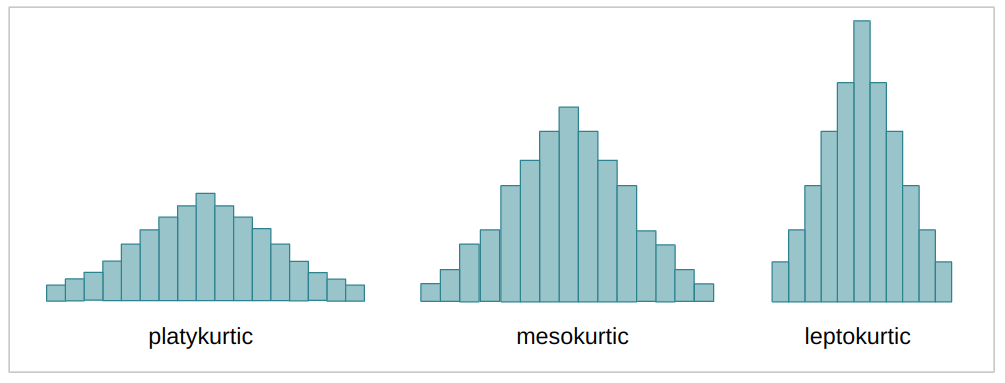
curtosis(o curtosis) de la imagen Wavelet transformada. La curtosis es un valor continuo que, al igual que la asimetría, también describe la forma de una distribución. Dependiendo del coeficiente de curtosis (k), una distribución, en comparación con la distribución normal, puede ser más o menos plana, o tener más o menos datos en sus extremos o colas. Cuando la distribución es más repartida y más plana, se denomina platicúrtico; cuando está menos disperso y más concentrado en el medio, mesocúrtico; y cuando la distribución está casi totalmente concentrada en el medio, se llama leptocúrtico. Este es el mismo caso que los casos anteriores de varianza y asimetría, cuanto más mesocúrtica es la distribución, más cerca estaban los coeficientes de traducir la imagen real.
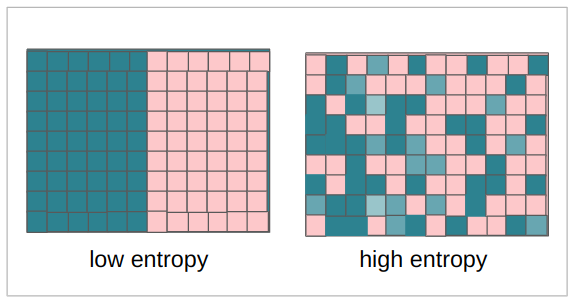
entropyde imagen La entropía también es un valor continuo, suele medir la aleatoriedad o desorden en un sistema. En el contexto de una imagen, la entropía mide la diferencia entre un píxel y los píxeles vecinos. Para nuestro contexto, cuanto más entropía tienen los coeficientes, más pérdida hay al transformar la imagen, y cuanto menor es la entropía, menor es la pérdida de información.
La quinta variable fue la class variable, que probablemente tiene valores 0 y 1, que dicen si el billete era real o falso.
Podemos verificar si la quinta columna contiene ceros y unos con Pandas' unique() método:
bankdata['class'].unique()
El método anterior devuelve:
array([0, 1]) El método anterior devuelve una matriz con valores 0 y 1. Esto significa que los únicos valores contenidos en nuestras filas de clase son ceros y unos. Está listo para ser utilizado como el dirigidos en nuestro aprendizaje supervisado.
classde imagen Este es un valor entero, es 0 cuando la imagen es falsificada y 1 cuando la imagen es real.
Como tenemos una columna con las anotaciones de imágenes reales y olvidadas, esto quiere decir que nuestro tipo de aprendizaje es supervisados.
Consejo: Para saber más sobre el razonamiento detrás de Wavelet Transform en las imágenes de billetes de banco y el uso de SVM, lea el artículo publicado de los autores.
También podemos ver cuántos registros o imágenes tenemos mirando el número de filas en los datos a través de la shape propiedad:
bankdata.shape
Esto produce:
(1372, 5)
La línea anterior significa que hay 1,372 filas de imágenes de billetes de banco transformadas y 5 columnas. Estos son los datos que estaremos analizando.
Importamos nuestro conjunto de datos y realizamos algunas comprobaciones. Ahora podemos explorar nuestros datos para comprenderlos mejor.
Explorando el conjunto de datos
Acabamos de ver que en la columna de clase sólo hay ceros y unos, pero también podemos saber en qué proporción están, es decir, si hay más ceros que unos, más unos que ceros, o si los números de ceros es lo mismo que el número de unos, lo que significa que son equilibrado.
Para saber la proporción podemos contar cada uno de los valores cero y uno en los datos con value_counts() método:
bankdata['class'].value_counts()
Esto produce:
0 762
1 610
Name: class, dtype: int64
En el resultado anterior, podemos ver que hay 762 ceros y 610 unos, o 152 ceros más que unos. Esto significa que tenemos un poco más de falsificación que las imágenes reales, y si esa discrepancia fuera mayor, por ejemplo, 5500 ceros y 610 unos, podría impactar negativamente en nuestros resultados. Una vez que estamos tratando de usar esos ejemplos en nuestro modelo, cuantos más ejemplos haya, generalmente significa que más información tendrá el modelo para decidir entre notas falsas o reales, si hay pocos ejemplos de notas reales, el modelo es propenso a ser equivocarse al tratar de reconocerlos.
Ya sabemos que hay 152 billetes falsificados más, pero ¿podemos estar seguros de que esos son suficientes ejemplos para que el modelo aprenda? Saber cuántos ejemplos se necesitan para aprender es una pregunta muy difícil de responder, en cambio, podemos tratar de entender, en términos porcentuales, cuánto es esa diferencia entre clases.
El primer paso es usar pandas. value_counts() método de nuevo, pero ahora veamos el porcentaje incluyendo el argumento normalize=True:
bankdata['class'].value_counts(normalize=True)
El normalize=True calcula el porcentaje de los datos para cada clase. Hasta ahora, el porcentaje de datos falsificados (0) y reales (1) es:
0 0.555394
1 0.444606
Name: class, dtype: float64
Esto significa que aproximadamente (~) el 56 % de nuestro conjunto de datos es falso y el 44 % es real. Esto nos da una proporción del 56 % al 44 %, que es lo mismo que una diferencia del 12 %. Esto se considera estadísticamente una pequeña diferencia, porque está un poco por encima del 10 %, por lo que los datos se consideran equilibrados. Si en lugar de una proporción de 56:44, hubiera una proporción de 80:20 o 70:30, nuestros datos se considerarían desequilibrados y tendríamos que hacer algún tratamiento de desequilibrio, pero, afortunadamente, este no es el caso.
También podemos ver esta diferencia visualmente, observando la distribución de la clase o el objetivo con un histograma imbuido de Pandas, usando:
bankdata['class'].plot.hist();
Esto traza un histograma usando la estructura del marco de datos directamente, en combinación con el matplotlib biblioteca que está detrás de escena.

Al mirar el histograma, podemos estar seguros de que nuestros valores objetivo son 0 o 1 y que los datos están equilibrados.
Este fue un análisis de la columna que estábamos tratando de predecir, pero ¿qué pasa con el análisis de las otras columnas de nuestros datos?
Podemos echar un vistazo a las medidas estadísticas con el describe() método de marco de datos. También podemos usar .T de transposición: para invertir columnas y filas, lo que hace que sea más directo comparar valores:
Consulte nuestra guía práctica y práctica para aprender Git, con las mejores prácticas, los estándares aceptados por la industria y la hoja de trucos incluida. Deja de buscar en Google los comandos de Git y, de hecho, aprenden ella!
bankdata.describe().T
Esto resulta en:
count mean std min 25% 50% 75% max
variance 1372.0 0.433735 2.842763 -7.0421 -1.773000 0.49618 2.821475 6.8248
skewness 1372.0 1.922353 5.869047 -13.7731 -1.708200 2.31965 6.814625 12.9516
curtosis 1372.0 1.397627 4.310030 -5.2861 -1.574975 0.61663 3.179250 17.9274
entropy 1372.0 -1.191657 2.101013 -8.5482 -2.413450 -0.58665 0.394810 2.4495
class 1372.0 0.444606 0.497103 0.0000 0.000000 0.00000 1.000000 1.0000
Note que las columnas de asimetría y curtosis tienen valores medios que están lejos de los valores de desviación estándar, esto indica que aquellos valores están más lejos de la tendencia central de los datos, o tienen una mayor variabilidad.
También podemos echar un vistazo a la distribución de cada función visualmente, trazando el histograma de cada función dentro de un bucle for. Además de ver la distribución, sería interesante ver cómo se separan los puntos de cada clase con respecto a cada característica. Para ello, podemos trazar un diagrama de dispersión haciendo una combinación de características entre ellas, y asignar diferentes colores a cada punto con respecto a su clase.
Comencemos con la distribución de cada característica y tracemos el histograma de cada columna de datos excepto la class columna. los class la columna no se tendrá en cuenta por su posición en la matriz de columnas de datos bancarios. Se seleccionarán todas las columnas excepto la última con columns[:-1]:
import matplotlib.pyplot as plt for col in bankdata.columns[:-1]: plt.title(col) bankdata[col].plot.hist() plt.show();
Después de ejecutar el código anterior, podemos ver que ambos skewness y entropy las distribuciones de datos tienen un sesgo negativo y curtosis está sesgada positivamente. Todas las distribuciones son simétricas y variance es la única distribución que se acerca a la normal.
Ahora podemos pasar a la segunda parte y trazar el diagrama de dispersión de cada variable. Para ello, también podemos seleccionar todas las columnas excepto la clase, con columns[:-1], usa Seaborn's scatterplot() y dos bucles for para obtener las variaciones de emparejamiento de cada una de las características. También podemos excluir el emparejamiento de una característica consigo misma, probando si la primera característica es igual a la segunda con una if statement.
import seaborn as sns for feature_1 in bankdata.columns[:-1]: for feature_2 in bankdata.columns[:-1]: if feature_1 != feature_2: print(feature_1, feature_2) sns.scatterplot(x=feature_1, y=feature_2, data=bankdata, hue='class') plt.show();
Tenga en cuenta que todos los gráficos tienen puntos de datos reales y falsos que no están claramente separados entre sí, lo que significa que hay algún tipo de superposición de clases. Dado que un modelo SVM usa una línea para separar las clases, ¿alguno de esos grupos en los gráficos podría separarse usando solo una línea? No parece probable. Así es como se ven la mayoría de los datos reales. Lo más cerca que podemos llegar a una separación es en la combinación de skewness y varianceo entropy y variance parcelas Esto probablemente se deba a variance datos que tienen una forma de distribución más cercana a la normal.
Pero mirar todos esos gráficos en secuencia puede ser un poco difícil. Tenemos la alternativa de ver todas las gráficas de diagramas de distribución y de dispersión juntas usando Seaborn's pairplot().
Los dos bucles anteriores que habíamos hecho se pueden sustituir solo por esta línea:
sns.pairplot(bankdata, hue='class');
Mirando el diagrama de pares, parece que, en realidad, curtosis y variance sería la combinación más fácil de características, por lo que las diferentes clases podrían estar separadas por una línea, o separables linealmente.
Si la mayoría de los datos están lejos de ser linealmente separables, podemos intentar preprocesarlos, reduciendo sus dimensiones, y también normalizar sus valores para tratar de acercar la distribución a una normal.
Para este caso, usemos los datos tal como están, sin más preprocesamiento, y luego, podemos retroceder un paso, agregar al preprocesamiento de datos y comparar los resultados.
Consejo: Cuando se trabaja con datos, la información suele perderse al transformarlos, porque estamos haciendo aproximaciones, en lugar de recopilar más datos. Trabajar primero con los datos iniciales tal como son, si es posible, ofrece una línea de base antes de probar otras técnicas de preprocesamiento. Al seguir esta ruta, el resultado inicial que usa datos sin procesar se puede comparar con otro resultado que usa técnicas de preprocesamiento en los datos.
Nota: Usualmente en Estadística, al construir modelos, es común seguir un procedimiento dependiendo del tipo de datos (discretos, continuos, categóricos, numéricos), su distribución y los supuestos del modelo. Mientras que en Ciencias de la Computación (CS), hay más espacio para prueba, error y nuevas iteraciones. En CS es común tener una línea de base para comparar. En Scikit-learn, hay una implementación de modelos ficticios (o estimadores ficticios), algunos no son mejores que lanzar una moneda y simplemente responder si (o 1) 50% del tiempo. Es interesante utilizar modelos ficticios como referencia para el modelo real al comparar resultados. Se espera que los resultados del modelo real sean mejores que una suposición aleatoria; de lo contrario, no sería necesario utilizar un modelo de aprendizaje automático.
Implementación de SVM con Scikit-Learn
Antes de profundizar en la teoría de cómo funciona SVM, podemos construir nuestro primer modelo de referencia con los datos y Scikit-Learn. Clasificador de vectores de soporte or SVC clase.
Nuestro modelo recibirá los coeficientes wavelet e intentará clasificarlos en función de la clase. El primer paso en este proceso es separar los coeficientes o Características de la clase o dirigidos. Después de ese paso, el segundo paso es dividir aún más los datos en un conjunto que se utilizará para el aprendizaje del modelo o juego de trenes y otro que se utilizará para la evaluación del modelo o equipo de prueba.
Nota: La nomenclatura de prueba y evaluación puede ser un poco confusa, porque también puede dividir sus datos entre conjuntos de entrenamiento, evaluación y prueba. De esta forma, en lugar de tener dos juegos, tendrías un juego intermedio solo para usar y ver si el rendimiento de tu modelo está mejorando. Esto significa que el modelo se entrenaría con el conjunto de entrenamiento, se mejoraría con el conjunto de evaluación y se obtendría una métrica final con el conjunto de prueba.
Algunas personas dicen que la evaluación es ese conjunto intermedio, otras dirán que el conjunto de prueba es el conjunto intermedio y que el conjunto de evaluación es el conjunto final. Esta es otra forma de tratar de garantizar que el modelo no está viendo el mismo ejemplo de ninguna manera, o que algún tipo de fuga de datos no está sucediendo, y que hay una generalización del modelo por la mejora de las últimas métricas establecidas. Si desea seguir ese enfoque, puede dividir aún más los datos una vez más como se describe en este Train_test_split() de Scikit-Learn: conjuntos de entrenamiento, prueba y validación guía.
División de datos en conjuntos de prueba/entrenamiento
En la sesión anterior, entendimos y exploramos los datos. Ahora, podemos dividir nuestros datos en dos matrices: una para las cuatro funciones y otra para la quinta función o función de destino. Dado que queremos predecir la clase en función de los coeficientes de wavelets, nuestro y será el class columna y nuestra X será el variance, skewness, curtosisy entropy columnas
Para separar el objetivo y las características, podemos atribuir solo el class columna a y, luego soltándolo del marco de datos para atribuir las columnas restantes a X .drop() método:
y = bankdata['class']
X = bankdata.drop('class', axis=1) Una vez que los datos se dividen en atributos y etiquetas, podemos dividirlos aún más en conjuntos de entrenamiento y prueba. Esto podría hacerse a mano, pero el model_selection biblioteca de Scikit-Learn contiene la train_test_split() método que nos permite dividir aleatoriamente los datos en conjuntos de entrenamiento y prueba.
Para usarlo, podemos importar la biblioteca, llamar al train_test_split() método, pasar X y y datos y definir un test_size pasar como argumento. En este caso, lo definiremos como 0.20– esto significa que el 20% de los datos se usarán para pruebas y el otro 80% para entrenamiento.
Este método toma muestras al azar respetando el porcentaje que hemos definido, pero respeta los pares Xy, para que el muestreo no confunda totalmente la relación.
Dado que el proceso de muestreo es inherentemente aleatorio, siempre obtendremos diferentes resultados al ejecutar el método. Para poder tener los mismos resultados, o resultados reproducibles, podemos definir una constante llamada SEED con el valor de 42.
Puede ejecutar el siguiente script para hacerlo:
from sklearn.model_selection import train_test_split SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Observe que el train_test_split() El método ya devuelve el X_train, X_test, y_train, y_test conjuntos en este orden. Podemos imprimir el número de muestras separadas para entrenar y probar obteniendo el primer (0) elemento de la shape propiedad devuelta tupla:
xtrain_samples = X_train.shape[0]
xtest_samples = X_test.shape[0] print(f'There are {xtrain_samples} samples for training and {xtest_samples} samples for testing.')
Esto muestra que hay 1097 muestras para entrenamiento y 275 para prueba.
Entrenando el modelo
Hemos dividido los datos en conjuntos de entrenamiento y de prueba. Ahora es el momento de crear y entrenar un modelo SVM en los datos del tren. Para hacer eso, podemos importar Scikit-Learn's svm biblioteca junto con la Clasificador de vectores de soporte clase, o SVC clase.
Después de importar la clase, podemos crear una instancia de ella, dado que estamos creando un modelo SVM simple, estamos tratando de separar nuestros datos linealmente, por lo que podemos dibujar una línea para dividir nuestros datos, que es lo mismo que usar un función lineal – al definir kernel='linear' como argumento para el clasificador:
from sklearn.svm import SVC
svc = SVC(kernel='linear')
De esta forma, el clasificador intentará encontrar una función lineal que separe nuestros datos. Después de crear el modelo, entrenémoslo, o cómodo con los datos del tren, empleando el fit() método y dando el X_train características y y_train objetivos como argumentos.
Podemos ejecutar el siguiente código para entrenar el modelo:
svc.fit(X_train, y_train)
Así como así, el modelo está entrenado. Hasta ahora, hemos entendido los datos, los hemos dividido, hemos creado un modelo SVM simple y hemos ajustado el modelo a los datos del tren.
El siguiente paso es comprender qué tan bien ese ajuste logró describir nuestros datos. En otras palabras, responder si una SVM lineal era una elección adecuada.
Haciendo predicciones
Una forma de responder si el modelo logró describir los datos es calcular y observar alguna clasificación. métrica.
Teniendo en cuenta que el aprendizaje es supervisado, podemos hacer predicciones con X_test y comparar esos resultados de predicción, que podríamos llamar y_pred – con el real y_testo verdad fundamental.
Para predecir algunos de los datos, el modelo predict() puede emplearse el método. Este método recibe las características de prueba, X_test, como argumento y devuelve una predicción, ya sea 0 o 1, para cada uno de X_testfilas de .
Después de predecir el X_test datos, los resultados se almacenan en un y_pred variable. Entonces, cada una de las clases predichas con el modelo SVM lineal simple ahora están en el y_pred variable.
Este es el código de predicción:
y_pred = svc.predict(X_test)
Teniendo en cuenta que tenemos las predicciones, ahora podemos compararlas con los resultados reales.
Evaluación del modelo
Hay varias formas de comparar las predicciones con los resultados reales y miden diferentes aspectos de una clasificación. Algunas métricas de clasificación más utilizadas son:
-
Matriz de confusión: cuando necesitamos saber para cuántas muestras obtuvimos bien o mal cada clase. Los valores que fueron correctos y correctamente predichos se llaman verdaderos positivos, los que se pronosticaron como positivos pero no lo fueron se llaman falsos positivos. La misma nomenclatura de verdaderos negativos y falsos negativos se utiliza para valores negativos;
-
Precisión: cuando nuestro objetivo es entender qué valores de predicción correctos fueron considerados correctos por nuestro clasificador. La precisión dividirá esos valores positivos verdaderos por las muestras que se pronosticaron como positivas;
$$
precision = frac{texto{verdaderos positivos}}{texto{verdaderos positivos} + texto{falsos positivos}}
$$
- Recordar: comúnmente calculado junto con precisión para comprender cuántos de los verdaderos positivos fueron identificados por nuestro clasificador. El recuerdo se calcula dividiendo los verdaderos positivos por cualquier cosa que debería haber sido pronosticada como positiva.
$$
recordar = frac{texto{verdaderos positivos}}{texto{verdaderos positivos} + texto{falsos negativos}}
$$
- Puntuación F1: es el equilibrado o Significado armonico de precisión y recuerdo. El valor más bajo es 0 y el más alto es 1. Cuando
f1-scorees igual a 1, significa que todas las clases se predijeron correctamente; esta es una puntuación muy difícil de obtener con datos reales (casi siempre existen excepciones).
$$
texto{f1-score} = 2* frac{texto{precisión} * texto{recordar}}{texto{precisión} + texto{recordar}}
$$
Ya nos hemos familiarizado con la matriz de confusión, la precisión, el recuerdo y las medidas de puntuación F1. Para calcularlos, podemos importar Scikit-Learn's metrics biblioteca. Esta biblioteca contiene la classification_report y confusion_matrix métodos, el método de informe de clasificación devuelve la precisión, la recuperación y la puntuación f1. Ambos classification_report y confusion_matrix se puede usar fácilmente para averiguar los valores de todas esas métricas importantes.
Para calcular las métricas, importamos los métodos, los llamamos y pasamos como argumentos las clasificaciones predichas, y_test, y las etiquetas de clasificación, o y_true.
Para una mejor visualización de la matriz de confusión, podemos graficarla en un Seaborn's heatmap junto con las anotaciones de cantidad, y para el informe de clasificación, es mejor imprimir su resultado, para que sus resultados estén formateados. Este es el siguiente código:
from sklearn.metrics import classification_report, confusion_matrix cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title('Confusion matrix of linear SVM') print(classification_report(y_test,y_pred))
Esto muestra:
precision recall f1-score support 0 0.99 0.99 0.99 148 1 0.98 0.98 0.98 127 accuracy 0.99 275 macro avg 0.99 0.99 0.99 275
weighted avg 0.99 0.99 0.99 275

En el informe de clasificación, sabemos que hay una precisión de 0.99, una recuperación de 0.99 y una puntuación f1 de 0.99 para los billetes falsificados, o clase 0. Esas medidas se obtuvieron utilizando 148 muestras, como se muestra en la columna de apoyo. Mientras tanto, para la clase 1, o notas reales, el resultado fue una unidad por debajo, un 0.98 de precisión, 0.98 de recordación y la misma puntuación de f1. Esta vez, se utilizaron 127 medidas de imágenes para obtener esos resultados.
Si observamos la matriz de confusión, también podemos ver que de 148 muestras de clase 0, 146 se clasificaron correctamente y hubo 2 falsos positivos, mientras que para 127 muestras de clase 1, hubo 2 falsos negativos y 125 verdaderos positivos.
Podemos leer el informe de clasificación y la matriz de confusión, pero ¿qué significan?
Interpretación de resultados
Para averiguar el significado, veamos todas las métricas combinadas.
Casi todas las muestras para la clase 1 se clasificaron correctamente, hubo 2 errores para nuestro modelo al identificar los billetes de banco reales. Esto es lo mismo que 0.98, o 98%, recuerdo. Algo similar puede decirse de la clase 0, solo 2 muestras fueron clasificadas incorrectamente, mientras que 148 son verdaderos negativos, totalizando una precisión del 99%.
Además de esos resultados, todos los demás marcan 0.99, que es casi 1, una métrica muy alta. La mayoría de las veces, cuando una métrica tan alta ocurre con datos de la vida real, esto podría indicar un modelo que está demasiado ajustado a los datos, o sobreajustado.
Cuando hay un sobreajuste, el modelo puede funcionar bien al predecir los datos que ya se conocen, pero pierde la capacidad de generalizar a nuevos datos, lo cual es importante en escenarios del mundo real.
Una prueba rápida para averiguar si se está produciendo un sobreajuste también es con los datos del tren. Si el modelo ha memorizado algo los datos del tren, las métricas estarán muy cerca de 1 o 100%. Recuerde que los datos del tren son más grandes que los datos de prueba, por esta razón, intente verlos proporcionalmente, más muestras, más posibilidades de cometer errores, a menos que haya habido algún sobreajuste.
Para predecir con datos de tren, podemos repetir lo que hemos hecho con datos de prueba, pero ahora con X_train:
y_pred_train = svc.predict(X_train) cm_train = confusion_matrix(y_train,y_pred_train)
sns.heatmap(cm_train, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with train data') print(classification_report(y_train,y_pred_train))
Esto produce:
precision recall f1-score support 0 0.99 0.99 0.99 614 1 0.98 0.99 0.99 483 accuracy 0.99 1097 macro avg 0.99 0.99 0.99 1097
weighted avg 0.99 0.99 0.99 1097
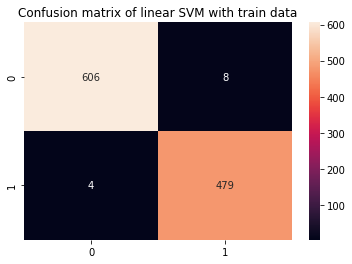
Es fácil ver que parece haber un sobreajuste, una vez que las métricas del tren son del 99 % al tener 4 veces más datos. ¿Qué se puede hacer en este escenario?
Para revertir el sobreajuste, podemos agregar más observaciones de trenes, usar un método de entrenamiento con diferentes partes del conjunto de datos, como validación cruzada, y también cambiar los parámetros por defecto que ya existen antes del entrenamiento, al crear nuestro modelo, o hiperparámetros. La mayoría de las veces, Scikit-learn establece algunos parámetros como predeterminados, y esto puede suceder de manera silenciosa si no se dedica mucho tiempo a leer la documentación.
Puedes consultar la segunda parte de esta guía (muy pronto!) para ver cómo implementar la validación cruzada y realizar un ajuste de hiperparámetros.
Conclusión
En este artículo estudiamos el kernel lineal simple SVM. Obtuvimos la intuición detrás del algoritmo SVM, usamos un conjunto de datos real, exploramos los datos y vimos cómo estos datos se pueden usar junto con SVM implementándolos con la biblioteca Scikit-Learn de Python.
Para seguir practicando, puede probar otros conjuntos de datos del mundo real disponibles en lugares como Kaggle, UCI, Conjuntos de datos públicos de Big Query, universidades y sitios web gubernamentales.
También le sugiero que explore las matemáticas reales detrás del modelo SVM. Aunque no necesariamente lo necesitará para usar el algoritmo SVM, sigue siendo muy útil para saber qué sucede realmente detrás de escena mientras su algoritmo encuentra límites de decisión.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://stackabuse.com/implementing-svm-and-kernel-svm-with-pythons-scikit-learn/

