En Primer comentario de esta serie, discutimos la necesidad de una solución de gestión de metadatos para las organizaciones. Nosotros usamos DataHub como una plataforma de metadatos de código abierto para la administración de metadatos y la implementó utilizando los servicios administrados de AWS con el Kit de desarrollo en la nube de AWS (CDK de AWS).
En esta publicación, nos enfocamos en cómo completar los metadatos técnicos de la Pegamento AWS Catálogo de datos y Desplazamiento al rojo de Amazon en DataHub y cómo aumentar los datos con un glosario empresarial y visualizar el linaje de datos de los trabajos de AWS Glue.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución y sus componentes clave:
- DataHub se ejecuta en un Servicio Amazon Elastic Kubernetes (Amazon EKS), utilizando Servicio Amazon OpenSearch, Streaming administrado por Amazon para Apache Kafka (Amazon MSK) y Amazon RDS para MySQL como la capa de almacenamiento para el modelo de datos y los índices subyacentes.
- La solución extrae metadatos técnicos de AWS Glue y Amazon Redshift a DataHub.
- Enriquecemos los metadatos técnicos con un glosario empresarial.
- Finalmente, ejecutamos un trabajo de AWS Glue para transformar los datos y observar el linaje de datos en DataHub.
En las siguientes secciones, demostramos cómo ingerir los metadatos usando varios métodos, enriquecer el conjunto de datos y capturar el linaje de datos.
Extraiga metadatos técnicos de AWS Glue y Amazon Redshift
En este paso, analizamos tres enfoques diferentes para ingerir metadatos en DataHub para búsqueda y descubrimiento.
DataHub es compatible tanto con push como con pull ingesta de metadatos. Las integraciones basadas en inserción (por ejemplo, Spark) le permiten emitir metadatos directamente desde sus sistemas de datos cuando los metadatos cambian, mientras que las integraciones basadas en extracción le permiten extraer metadatos de los sistemas de datos por lotes o por lotes incrementales. En esta sección, obtendrá metadatos técnicos de AWS Glue Data Catalog y Amazon Redshift mediante la interfaz web de DataHub, Python y la CLI de DataHub.
Ingerir datos mediante la interfaz web de DataHub
En esta sección, utiliza la interfaz web de DataHub para ingerir metadatos técnicos. Este método es compatible con AWS Glue Data Catalog y Amazon Redshift, pero aquí nos centramos en Amazon Redshift como demostración.
Como requisito previo, necesita un Clúster de Amazon Redshift con datos de muestra, accesible desde el clúster de EKS que aloja DataHub (puerto TCP predeterminado 5439).
Crear un token de acceso
Complete los siguientes pasos para crear un token de acceso:
- Vaya a la interfaz web de DataHub y elija Ajustes.
- Elige Generar nuevo token.
- Ingresa un nombre (
GMS_TOKEN), descripción opcional y fecha y hora de caducidad. - Copie el valor del token en un lugar seguro.

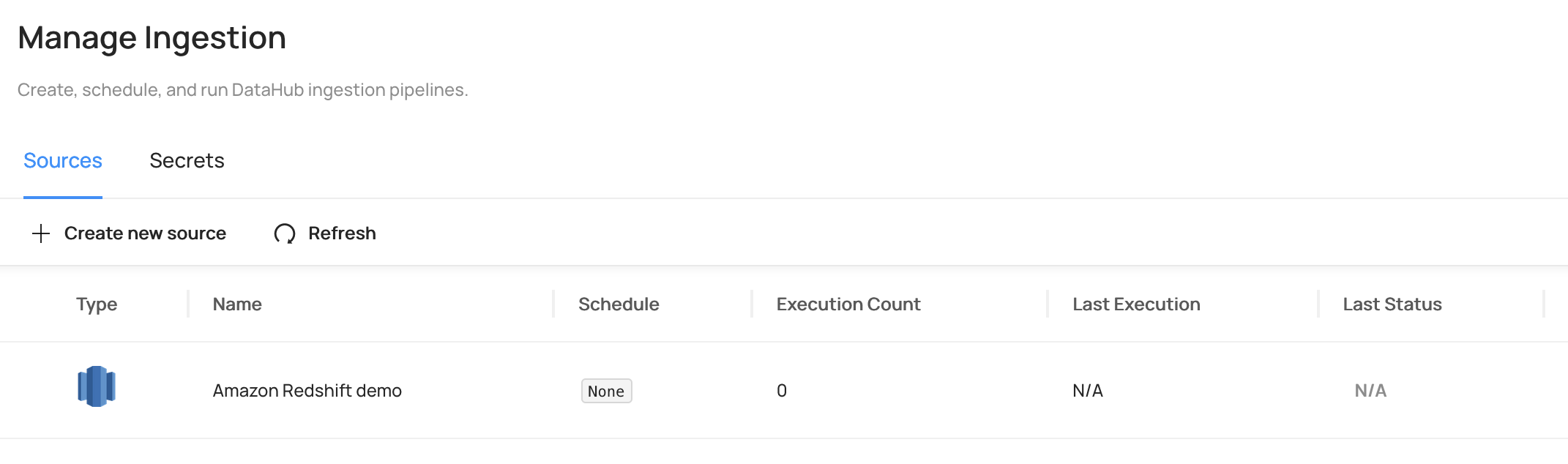
Crear una fuente de ingestión
A continuación, configuramos Amazon Redshift como nuestra fuente de ingesta.
- En la interfaz web de DataHub, seleccione Ingestión.
- Elige Generar nueva fuente.
- Elige Desplazamiento al rojo de Amazon.
- En Configurar Receta paso, introduzca los valores de
host_portydatabasede su clúster de Amazon Redshift y mantenga el resto sin cambios:
Los valores para ${REDSHIFT_USERNAME}, ${REDSHIFT_PASSWORD}y ${GMS_TOKEN} secretos de referencia que configuró en el siguiente paso.
- Elige Siguiente.
- Para el cronograma de ejecución, ingrese la sintaxis cron deseada o elija omitir.
- Introduzca un nombre para la fuente de datos (por ejemplo,
Amazon Redshift demo) y elige Terminado.
Crear secretos para la receta de la fuente de datos
Para crear sus secretos, complete los siguientes pasos:
- en el concentrador de datos Administrar ingesta página, elige Misterios.
- Elige Crear nuevo secreto.
- Nombre¸ entrar
REDSHIFT_USERNAME. - Valor¸ entrar
awsuser(usuario administrador predeterminado). - Descripción, ingrese una descripción opcional.
- Repita estos pasos para
REDSHIFT_PASSWORDyGMS_TOKEN.

Ejecutar ingesta de metadatos
Para ingerir los metadatos, complete los siguientes pasos:
- en el concentrador de datos Administrar ingesta página, elige Fuentes.
- Elige Implementación junto a la fuente de Amazon Redshift que acaba de crear.
- Elige Implementación de nuevo para confirmar
- Expanda la fuente y espere a que se complete la ingestión, o verifique los detalles del error (si corresponde).

Las tablas del clúster de Amazon Redshift ahora se completan en DataHub. Puede verlos navegando a Datasets > prod > redshift > dev > public > users.

Seguirá trabajando para enriquecer los metadatos de esta tabla mediante la CLI de DataHub en un paso posterior.
Ingerir datos usando el código de Python
En esta sección, utilizará el código de Python para incorporar metadatos técnicos en la CLI de DataHub, utilizando AWS Glue Data Catalog como fuente de datos de ejemplo.
Como requisito previo, necesita un ejemplo de base de datos y tabla en el Catálogo de Datos. También necesitas un Gestión de identidades y accesos de AWS (YO SOY) usuario con los permisos de IAM necesarios:
Nota la GMS_ENDPOINT valor para DataHub ejecutando kubectl get svcy localice la URL del balanceador de carga y el número de puerto (8080) para el servicio datahub-datahub-gms.

Instalar el cliente DataHub
Para instalar el cliente DataHub con Nube de AWS9, completa los siguientes pasos:
- Abra el IDE de AWS Cloud9 e inicie el terminal.
- Cree un nuevo entorno virtual e instale el cliente DataHub:
- Verifique la instalación:
Si DataHub se instaló correctamente, verá el siguiente resultado:
- Instale el complemento DataHub para AWS Glue:
Preparar y ejecutar el script Python de ingestión
Complete los siguientes pasos para ingerir los datos:
- Descargar
glue_ingestion.pydel desplegable Repositorio GitHub. - Edite los valores de los objetos fuente y sumidero:
Para fines de producción, use el rol de IAM y almacene otros parámetros y credenciales en Almacén de parámetros de AWS Systems Manager or Director de secretos de AWS.
Para ver todas las opciones de configuración, consulte Detalles de configuración.
- Ejecute el script dentro del entorno virtual de DataHub:
Si vuelve a navegar a la interfaz web de DataHub, las bases de datos y las tablas de su catálogo de datos de AWS Glue deberían aparecer en Datasets > prod > glue.

Ingerir datos mediante la CLI de DataHub
En esta sección, utiliza la CLI de DataHub para ingerir un glosario empresarial de muestra sobre clasificación de datos, información personal y más.
Como requisito previo, debe tener la CLI de DataHub instalada en el IDE de AWS Cloud9. Si no es así, sigue los pasos de la sección anterior.
Preparar e ingerir el glosario de negocios
Complete los siguientes pasos:
- Abra el IDE de AWS Cloud9.
- Descargar
business_glossary.ymldel desplegable Repositorio GitHub. - Opcionalmente, puede explorar el archivo y agregar definiciones personalizadas (consulte Glosario de negocios ).
- Descargar
business_glossary_to_datahub.ymldel desplegable Repositorio GitHub. - Edite la ruta completa al archivo de definición del glosario empresarial, el punto final de GMS y el token de GMS:
- Ejecute el siguiente código:
- Vuelva a la interfaz de DataHub y elija Regir, entonces Glosario.
Ahora debería ver el nuevo glosario de negocios para usar en la siguiente sección.

Enriquecer el conjunto de datos con más metadatos
En esta sección, enriquecemos un conjunto de datos con contexto adicional, que incluye descripción, etiquetas y un glosario de negocios, para ayudar al descubrimiento de datos.
Como requisito previo, siga los pasos anteriores para ingerir los metadatos de la base de datos de muestra de Amazon Redshift e ingiera el glosario empresarial de un archivo YAML.
- En la interfaz web de DataHub, vaya a
Datasets > prod > redshift > dev > public > users. - Comenzando en el nivel de la tabla, agregamos documentación relacionada y un enlace a la sección Acerca de.
Esto permite a los analistas comprender las relaciones de la tabla de un vistazo, como se muestra en la siguiente captura de pantalla.

- Para mejorar aún más el contexto, agregue lo siguiente:
- Descripción de la columna.
- Etiquetas para la tabla y las columnas para facilitar la búsqueda y el descubrimiento.
- Términos del glosario empresarial para organizar los activos de datos utilizando un vocabulario compartido. Por ejemplo, definimos
useridexistentesUSERStabla como una cuenta en términos comerciales. - Propietarios.
- A dominio para agrupar activos de datos en colecciones lógicas. Esto es útil cuando se diseña un malla de datos en AWS.

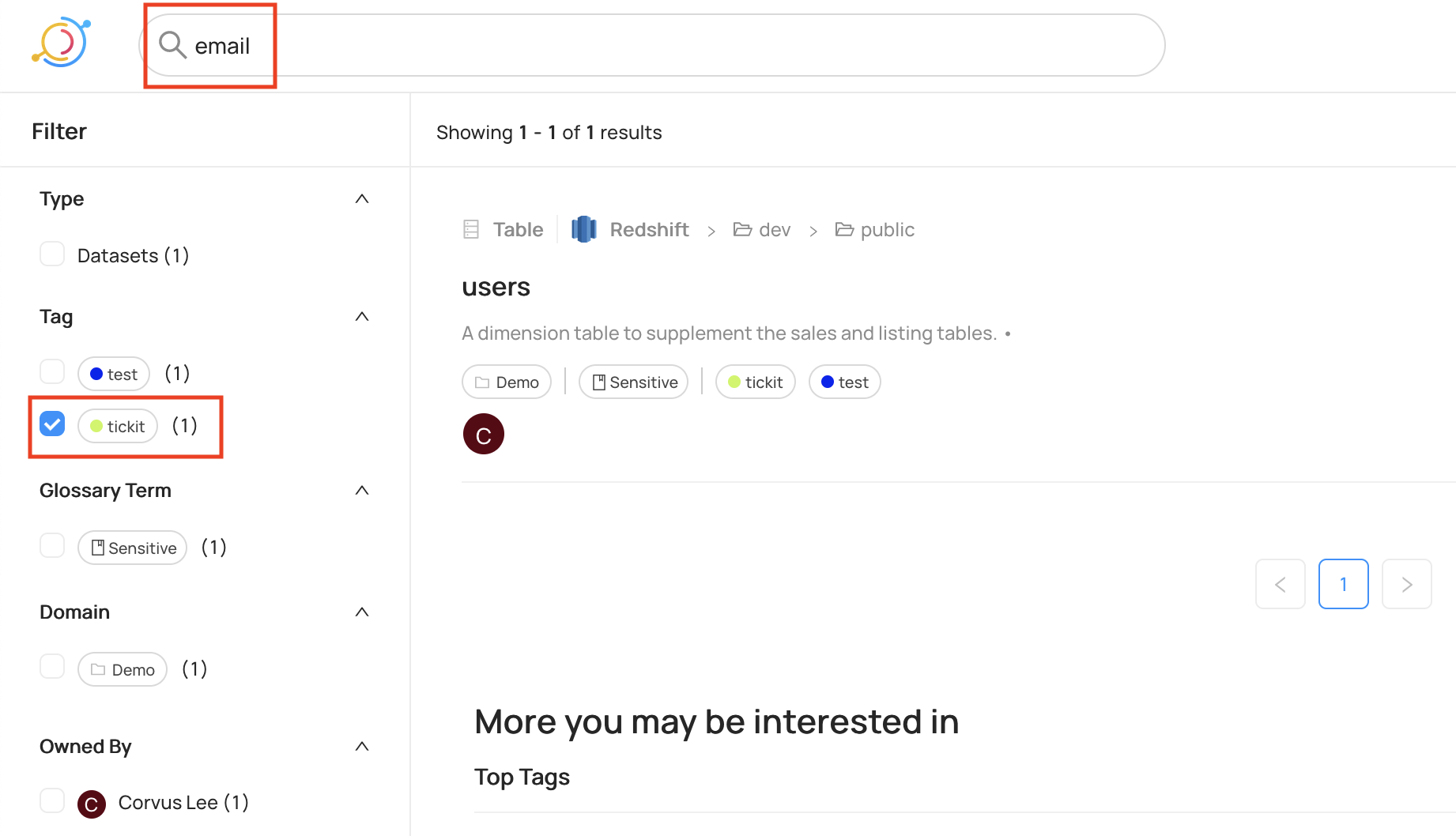
Ahora podemos buscar usando el contexto adicional. Por ejemplo, buscando el término email con la etiqueta tickit devuelve correctamente el USERS mesa.
También podemos buscar usando etiquetas, como tags:"PII" OR fieldTags:"PII" OR editedFieldTags:"PII".

En el siguiente ejemplo, buscamos usando la descripción del campo fieldDescriptions:The user's home state, such as GA.

Siéntase libre de explorar el características de búsqueda en DataHub para mejorar la experiencia de descubrimiento de datos.
Capturar linaje de datos
En esta sección, creamos un trabajo de AWS Glue para capturar el linaje de datos. Esto requiere el uso de un datahub-spark-lineage Archivo JAR como una dependencia adicional.
- Descargue los registros de viaje de taxi amarillo de NYC para 2022 enero (en formato de archivo de parquet) y guárdelo en
s3://<>/tripdata/. - Cree un rastreador de AWS Glue que apunte a
s3://<>/tripdata/y crea una tabla de aterrizaje llamadalanding_nyx_taxidentro de la base de datosnyx_taxi. - Descargar las
datahub-spark-lineageJAR (v0.8.41-3-rc3) y guárdelo ens3://<>/externalJar/. - Descargar el archivo log4j.properties y guárdelo en
s3://<>/externalJar/. - Cree una tabla de destino usando lo siguiente Secuencia de comandos SQL.
El trabajo de AWS Glue lee los datos en formato de archivo de parquet mediante la tabla de destino, realiza una transformación de datos básica y los escribe en la tabla de destino en formato de parquet.
- Cree un trabajo de AWS Glue usando lo siguiente guión y modifica tu
GMS_ENDPOINT,GMS_TOKENy el nombre de la tabla de la base de datos de origen y de destino. - En Detalles del trabajo pestaña, proporcione el rol de IAM y deshabilite los marcadores de trabajo.

- Añadir la ruta de
datahub-spark-lineage(s3://<>/externalJar/datahub-spark-lineage-0.8.41-3-rc3.jar) para Ruta JAR dependiente. - Entra en la ruta de
log4j.propertiespara Ruta de los archivos a los que se hace referencia.

El trabajo lee los datos de la tabla de destino como un Spark DataFrame y luego inserta los datos en la tabla de destino. El JAR es un agente ligero de Java que escucha los eventos de trabajo de la aplicación Spark y envía los metadatos a DataHub en tiempo real. Se captura el linaje de los conjuntos de datos que se leen y escriben. Eventos como el inicio y el final de la aplicación, y SQLExecution se capturan el inicio y el final. Esta información se puede ver en tuberías (DataJob) y tareas (DataFlow) en DataHub.
- Ejecute el trabajo de AWS Glue.
Cuando se completa el trabajo, puede ver que la información de linaje se completa en la interfaz de usuario de DataHub.


El linaje anterior muestra que los datos se leen de una tabla respaldada por un Servicio de almacenamiento simple de Amazon (Amazon S3) y se escribe en una tabla de AWS Glue Data Catalog. Se capturan los detalles de la ejecución de Spark, como el ID de ejecución de la consulta, que se puede volver a asignar a la interfaz de usuario de Spark mediante el nombre de la aplicación Spark y el ID de la aplicación Spark.
Limpiar
Para evitar incurrir en cargos futuros, complete los siguientes pasos para eliminar los recursos:
- Ejecutar
helm uninstall datahubyhelm uninstall prerequisites. - Ejecutar
cdk destroy --all. - Elimine el entorno de AWS Cloud9.
Conclusión
En esta publicación, demostramos cómo buscar y descubrir activos de datos almacenados en su lago de datos (a través de AWS Glue Data Catalog) y almacén de datos en Amazon Redshift. Puede aumentar los activos de datos con un glosario empresarial y visualizar el linaje de datos de los trabajos de AWS Glue.
Acerca de los autores
 Debadatta Mohapatra es un arquitecto de laboratorio de datos de AWS. Tiene una amplia experiencia en big data, ciencia de datos e IoT, en consultoría e industria. Es un defensor de las plataformas de datos nativas de la nube y el valor que pueden generar para los clientes en todas las industrias.
Debadatta Mohapatra es un arquitecto de laboratorio de datos de AWS. Tiene una amplia experiencia en big data, ciencia de datos e IoT, en consultoría e industria. Es un defensor de las plataformas de datos nativas de la nube y el valor que pueden generar para los clientes en todas las industrias.
 Corvus Lee es arquitecto de soluciones para AWS Data Lab. Disfruta de todo tipo de debates relacionados con los datos y ayuda a los clientes a crear MVP utilizando bases de datos, análisis y servicios de aprendizaje automático de AWS.
Corvus Lee es arquitecto de soluciones para AWS Data Lab. Disfruta de todo tipo de debates relacionados con los datos y ayuda a los clientes a crear MVP utilizando bases de datos, análisis y servicios de aprendizaje automático de AWS.
 suraj bang es Arquitecto de Soluciones Sr en AWS. Suraj ayuda a los clientes de AWS en este rol en sus casos de uso de análisis, bases de datos y aprendizaje automático, diseña una solución para resolver sus problemas comerciales y los ayuda a construir un prototipo escalable.
suraj bang es Arquitecto de Soluciones Sr en AWS. Suraj ayuda a los clientes de AWS en este rol en sus casos de uso de análisis, bases de datos y aprendizaje automático, diseña una solución para resolver sus problemas comerciales y los ayuda a construir un prototipo escalable.

