Esta es una publicación de invitado coescrita con Moulham Zahabi de Matarat.
Probablemente todos han facturado su equipaje al volar y han esperado ansiosamente a que aparecieran sus maletas en la cinta transportadora. La entrega exitosa y oportuna de sus maletas depende de una infraestructura masiva llamada sistema de manejo de equipaje (BHS). Esta infraestructura es una de las funciones clave de las operaciones aeroportuarias exitosas. El manejo exitoso del equipaje y la carga para los vuelos de salida y llegada es fundamental para garantizar la satisfacción del cliente y brindar excelencia operativa en el aeropuerto. Esta función depende en gran medida del funcionamiento continuo del BHS y de la eficacia de las operaciones de mantenimiento. Como línea vital de los aeropuertos, un BHS es un activo lineal que puede superar los 34,000 70 metros de longitud (para un solo aeropuerto) y maneja más de XNUMX millones de maletas al año, lo que lo convierte en uno de los sistemas automatizados más complejos y un componente vital de las operaciones aeroportuarias.
El tiempo de inactividad no planificado de un sistema de manejo de equipaje, ya sea una cinta transportadora, un carrusel o una unidad clasificadora, puede interrumpir las operaciones del aeropuerto. Tal interrupción seguramente creará una experiencia desagradable para los pasajeros y posiblemente impondrá sanciones a los proveedores de servicios aeroportuarios.
El desafío predominante con el mantenimiento de un sistema de manejo de equipaje es cómo operar un sistema integrado de más de 7,000 activos y más de un millón de puntos de ajuste de forma continua. Estos sistemas también manejan millones de bolsas en diferentes formas y tamaños. Es seguro asumir que los sistemas de manejo de equipaje son propensos a errores. Debido a que los elementos funcionan en un circuito cerrado, si un elemento se rompe, afecta a toda la línea. Las actividades de mantenimiento tradicionales dependen de una fuerza laboral considerable distribuida en ubicaciones clave a lo largo del BHS enviada por los operadores en caso de una falla operativa. Los equipos de mantenimiento también dependen en gran medida de las recomendaciones de los proveedores para programar el tiempo de inactividad para el mantenimiento preventivo. Determinar si las actividades de mantenimiento preventivo se implementan correctamente o monitorear el rendimiento de este tipo de activo puede no ser confiable y no reduce el riesgo de tiempo de inactividad imprevisto.
La gestión de piezas de repuesto es un desafío adicional, ya que los plazos de entrega aumentan debido a las interrupciones de la cadena de suministro global, pero las decisiones de reabastecimiento de inventario se basan en tendencias históricas. Además, estas tendencias no incorporan el entorno dinámico volátil de los activos operativos de BHS a medida que envejecen. Para abordar estos desafíos, es necesario que ocurra un cambio sísmico en las estrategias de mantenimiento, pasando de una mentalidad reactiva a una mentalidad proactiva. Este cambio requiere que los operadores utilicen la última tecnología para agilizar las actividades de mantenimiento, optimizar las operaciones y minimizar los gastos operativos.
En esta publicación, describimos cómo el socio de AWS Airis Solutions utilizó Amazon Lookout para equipos, servicios de Internet de las cosas (IoT) de AWS y NubeRail tecnologías de sensores para proporcionar una solución de vanguardia para hacer frente a estos desafíos.
Descripción general del sistema de manejo de equipaje
El diagrama y la tabla siguientes ilustran las medidas tomadas en un carrusel típico en el Aeropuerto Internacional Rey Khalid en Riyadh.

Los datos se recopilan en las diferentes ubicaciones ilustradas en el diagrama.
| Tipo de sensor | Valor de negocio | Conjuntos de datos | Destino |
| Sensores de velocidad de enlace IO | Velocidad de carrusel homogéneo | PDV1 (1 por minuto) | C |
|
Sensor de vibración con integrado Sensor De Temperatura |
Tornillo suelto, Eje desalineado, daños en los rodamientos, Daños en el devanado del motor |
Fatiga (v-RMS) (m/s) Impacto (a-Pico) (m/s^2) Fricción (a-RMS) (m/s^2) Temperatura (C) Crest |
A y B |
| Sensor PEC de distancia | Rendimiento de equipaje | Distancia (cm) | D |
Las siguientes imágenes muestran el entorno y el equipo de monitoreo para las distintas mediciones.

Sensor de vibración montado en uno de los motores del transportador |

Sonda de proximidad que mide la velocidad del carrusel |
|

Línea de visión del contador de tránsito de equipaje (utilizando un sensor de distancia) |
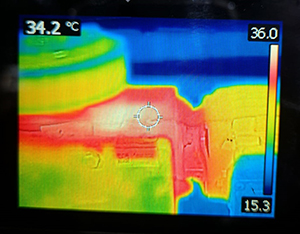
Imagen térmica de uno de los motores del transportador |
|
Resumen de la solución
El sistema de mantenimiento predictivo (PdMS) para los sistemas de manejo de equipaje es una arquitectura de referencia que ayuda a los operadores de mantenimiento de aeropuertos en su viaje para tener datos que permitan mejorar el tiempo de inactividad no planificado. Contiene componentes básicos para acelerar el desarrollo y la implementación de sensores y servicios conectados. El PdMS incluye servicios de AWS para administrar de manera segura el ciclo de vida de los dispositivos informáticos de borde y los activos de BHS, la ingesta de datos en la nube, el almacenamiento, los modelos de inferencia de aprendizaje automático (ML) y la lógica comercial para potenciar el mantenimiento proactivo de los equipos en la nube.
Esta arquitectura se construyó a partir de las lecciones aprendidas al trabajar con operaciones aeroportuarias durante varios años. La solución propuesta se desarrolló con el apoyo de Northbay Solutions, un socio principal de AWS, y se puede implementar en aeropuertos de todos los tamaños y escalas para miles de dispositivos conectados en un plazo de 90 días.
El siguiente diagrama de arquitectura expone los componentes subyacentes utilizados para crear la solución de mantenimiento predictivo:

Utilizamos los siguientes servicios para ensamblar nuestra arquitectura:
- CloudRail.DMC es una solución de software como servicio (SaaS) del experto alemán en IoT CloudRail GmbH. Esta organización administra flotas de puertas de enlace perimetrales distribuidas globalmente. Con este servicio, los sensores industriales, los medidores inteligentes y los servidores OPC UA se pueden conectar a un lago de datos de AWS con solo unos pocos clics.
- Núcleo de AWS IoT le permite conectar miles de millones de dispositivos IoT y enrutar billones de mensajes a los servicios de AWS sin administrar la infraestructura. Transmite mensajes de forma segura hacia y desde todos sus dispositivos y aplicaciones IoT con baja latencia y alto rendimiento. Usamos AWS IoT Core para conectarnos a los sensores de CloudRail y reenviar sus mediciones a la nube de AWS.
- Análisis de IoT de AWS es un servicio completamente administrado que facilita la ejecución y la puesta en funcionamiento de análisis sofisticados en volúmenes masivos de datos de IoT sin tener que preocuparse por el costo y la complejidad que normalmente se requieren para construir una plataforma de análisis de IoT. Es una manera fácil de ejecutar análisis en datos de IoT para obtener información precisa.
- Amazon Lookout para equipos analiza los datos de los sensores de los equipos para crear un modelo ML automáticamente para su equipo basado en datos específicos de activos, sin necesidad de conocimientos de ciencia de datos. Lookout for Equipment analiza los datos de los sensores entrantes en tiempo real e identifica con precisión las señales de alerta temprana que podrían provocar un tiempo de inactividad inesperado.
- Amazon QuickSight permite que todos en la organización comprendan los datos haciendo preguntas en lenguaje natural, visualizando información a través de paneles interactivos y buscando automáticamente patrones y valores atípicos con tecnología de ML.
Como se ilustra en el siguiente diagrama, esta arquitectura permite que los datos de los sensores fluyan hacia la información operativa.

Los puntos de datos se recopilan mediante sensores IO-Link: IO-Link es una interfaz estandarizada que permite una comunicación fluida desde el nivel de control de un activo industrial (en nuestro caso, el sistema de manejo de equipaje) hasta el nivel del sensor. Este protocolo se utiliza para alimentar los datos del sensor en una puerta de enlace de borde de CloudRail y se carga en AWS IoT Core. Luego, este último proporciona datos de equipos a los modelos ML para identificar problemas operativos y de equipos que se pueden usar para determinar el momento óptimo para el mantenimiento o reemplazo de activos sin incurrir en costos innecesarios.
La recolección de datos
Adaptar los activos existentes y sus sistemas de control a la nube sigue siendo un enfoque desafiante para los operadores de equipos. Agregar sensores secundarios proporciona una forma rápida y segura de adquirir los datos necesarios sin interferir con los sistemas existentes. Por lo tanto, es más fácil, rápido y no invasivo en comparación con la conexión directa de los PLC de una máquina. Además, se pueden seleccionar sensores adaptados para medir con precisión los puntos de datos requeridos para modos de falla específicos.
Con CloudRail, todos los sensores IO-Link industriales se pueden conectar a servicios de AWS como AWS IoT Core, AWS IoT SiteWiseo AWS IoT Greengrass en unos segundos a través de un portal de administración de dispositivos basado en la nube (CloudRail.DMC). Esto permite a los expertos de IoT trabajar desde ubicaciones centralizadas y sistemas físicos integrados que están distribuidos globalmente. La solución resuelve los desafíos de la conectividad de datos para los sistemas de mantenimiento predictivo a través de un sencillo mecanismo plug-and-play.
La puerta de enlace actúa como la Zona Industrial Desmilitarizada (IDMZ) entre el equipo (OT) y el servicio en la nube (IT). A través de una aplicación de gestión de flotas integrada, CloudRail garantiza que los últimos parches de seguridad se implementen automáticamente en miles de instalaciones.
La siguiente imagen muestra un sensor IO-Link y la puerta de enlace de borde CloudRail (en naranja):

Entrenamiento de un modelo de detección de anomalías
Las organizaciones de la mayoría de los segmentos industriales ven que las estrategias modernas de mantenimiento se alejan de los enfoques reactivos de ejecución hasta el fallo y avanzan hacia métodos más predictivos. Sin embargo, pasar a un enfoque de mantenimiento predictivo o basado en la condición requiere datos recopilados de sensores instalados en todas las instalaciones. El uso de datos históricos capturados por estos sensores junto con el análisis ayuda a identificar los precursores de las fallas del equipo, lo que permite que el personal de mantenimiento actúe en consecuencia antes de una falla.
Los sistemas de mantenimiento predictivo se basan en la capacidad de identificar cuándo podrían ocurrir fallas. Los OEM de equipos generalmente brindan hojas de datos para sus equipos y recomiendan monitorear ciertas métricas operativas basadas en condiciones casi perfectas. Sin embargo, estas condiciones rara vez son realistas debido al desgaste natural del activo, las condiciones ambientales en las que opera, su historial de mantenimiento anterior o simplemente la forma en que necesita operarlo para lograr los resultados de su negocio. Por ejemplo, se instalaron dos motores idénticos (marca, modelo, fecha de producción) en el mismo carrusel para esta prueba de concepto. Estos motores operaron a diferentes rangos de temperatura debido a la diferente exposición climática (una parte de la cinta transportadora en el interior y la otra fuera de la terminal del aeropuerto).
El motor 1 funcionaba a una temperatura que oscilaba entre 32 y 35 °C. La velocidad de vibración RMS puede cambiar debido a la fatiga del motor (por ejemplo, errores de alineación o problemas de desequilibrio). Como se muestra en la siguiente figura, este motor muestra niveles de fatiga que oscilan entre 2 y 6, con algunos picos en 9.

El motor 2 operó en un ambiente más fresco, donde la temperatura oscilaba entre 20 y 25 °C. En este contexto, el motor 2 muestra niveles de fatiga entre 4 y 8, con algunos picos en 10:

La mayoría de los enfoques de ML esperan conocimientos e información de dominio muy específicos (a menudo difíciles de obtener) que deben extraerse de la forma en que opera y mantiene cada activo (por ejemplo, patrones de degradación de fallas). Este trabajo debe realizarse cada vez que desee monitorear un nuevo activo, o si las condiciones del activo cambian significativamente (como cuando reemplaza una pieza). Esto significa que un gran modelo entregado en la fase de creación de prototipos probablemente verá un impacto en el rendimiento cuando se implemente en otros activos, lo que reducirá drásticamente la precisión del sistema y, al final, perderá la confianza de los usuarios finales. Esto también puede causar muchos falsos positivos, y necesitaría las habilidades necesarias para encontrar sus señales válidas en todo el ruido.
Lookout for Equipment solo analiza sus datos de series de tiempo para conocer las relaciones normales entre sus señales. Luego, cuando estas relaciones comiencen a desviarse de las condiciones operativas normales (capturadas en el estado de entrenamiento), el servicio marcará la anomalía. Descubrimos que el uso estricto de datos históricos para cada activo le permite concentrarse en tecnologías que pueden aprender las condiciones operativas que serán exclusivas de un activo determinado en el mismo entorno en el que está operando. Esto le permite ofrecer predicciones que respaldan el análisis de la causa raíz y las prácticas de mantenimiento predictivo. a un nivel granular, por activo y macro (ensamblando el tablero apropiado para permitirle obtener una descripción general de múltiples activos a la vez). Este es el enfoque que tomamos y la razón por la que decidimos usar Lookout for Equipment.
Estrategia de formación: abordar el desafío del arranque en frío
El BHS al que nos dirigimos no estaba instrumentado al principio. Instalamos sensores CloudRail para comenzar a recopilar nuevas mediciones de nuestro sistema, pero esto significaba que solo teníamos una profundidad histórica limitada para entrenar nuestro modelo ML. Abordamos el desafío del arranque en frío en este caso al reconocer que estamos construyendo un sistema de mejora continua. Después de instalar los sensores, recopilamos una hora de datos y duplicamos esta información para comenzar a usar Lookout for Equipment lo antes posible y probar nuestra tubería general.
Como era de esperar, los primeros resultados fueron bastante inestables porque el modelo ML estuvo expuesto a un período muy pequeño de operaciones. Esto significaba que se marcaría cualquier comportamiento nuevo que no se observara durante la primera hora. Al observar los sensores de mayor rango, la temperatura en uno de los motores parecía ser el principal sospechoso (T2_MUC_ES_MTRL_TMP en naranja en la siguiente figura). Debido a que la captura de datos inicial fue muy limitada (1 hora), a lo largo del día, el principal cambio provino de los valores de temperatura (que es consistente con las condiciones ambientales en ese momento).

Al comparar esto con las condiciones ambientales alrededor de esta cinta transportadora específica, confirmamos que la temperatura exterior aumentó severamente, lo que, a su vez, aumentó la temperatura medida por este sensor. En este caso, después de que los nuevos datos (que representan el aumento de la temperatura exterior) se incorporen al conjunto de datos de entrenamiento, serán parte del comportamiento normal capturado por Lookout for Equipment y será menos probable que un comportamiento similar en el futuro genere algún problema. eventos.
Después de 5 días, el modelo se volvió a entrenar y las tasas de falsos positivos inmediatamente cayeron drásticamente:

Si bien este problema de arranque en frío fue un desafío inicial para obtener información útil, aprovechamos esta oportunidad para crear un mecanismo de capacitación que el usuario final pueda activar fácilmente. Después de un mes de experimentación, entrenamos un nuevo modelo duplicando los datos del sensor de un mes en 3 meses. Esto continuó reduciendo las tasas de falsos positivos a medida que el modelo estaba expuesto a un conjunto más amplio de condiciones. Una caída similar en la tasa de falsos positivos ocurrió después de este reentrenamiento: la condición modelada por el sistema estaba más cerca de lo que los usuarios experimentan en la vida real. Después de 3 meses, finalmente teníamos un conjunto de datos que podíamos usar sin usar este truco de duplicación.
A partir de ahora, lanzaremos un reentrenamiento cada 3 meses y, tan pronto como sea posible, utilizaremos hasta 1 año de datos para dar cuenta de la estacionalidad de las condiciones ambientales. Al implementar este sistema en otros activos, podremos reutilizar este proceso automatizado y utilizar la capacitación inicial para validar nuestra canalización de datos de sensores.
Después de entrenar el modelo, lo implementamos y comenzamos a enviar datos en vivo a Lookout for Equipment. Lookout for Equipment le permite configurar un programador que se activa regularmente (por ejemplo, cada hora) para enviar datos nuevos al modelo entrenado y recopilar los resultados.
Ahora que sabemos cómo entrenar, mejorar e implementar un modelo, veamos los paneles operativos implementados para los usuarios finales.
Visualización de datos e información
Los usuarios finales necesitan una forma de extraer más valor de sus datos operativos para mejorar mejor la utilización de sus activos. Con QuickSight, conectamos el tablero a los datos de medición sin procesar proporcionados por nuestro sistema IoT, lo que permite a los usuarios comparar y contrastar equipos clave en un BHS determinado.
En el siguiente panel, los usuarios pueden verificar los sensores clave utilizados para monitorear la condición del BHS y obtener cambios en las métricas de un período a otro.

En el gráfico anterior, los usuarios pueden visualizar cualquier desequilibrio inesperado de la medición de cada motor (gráficos izquierdo y derecho de temperatura, fatiga, vibración, fricción e impacto). En la parte inferior, se resumen los indicadores clave de rendimiento, con pronóstico y tendencias de un período a otro.
Los usuarios finales pueden acceder a la información para los siguientes propósitos:
- Ver datos históricos en intervalos de 2 horas hasta 24 horas.
- Extraiga datos sin procesar a través del formato CSV para la integración externa.
- Visualice el rendimiento de los activos durante un período de tiempo determinado.
- Produzca información para la planificación operativa y mejore la utilización de activos.
- Realizar análisis de correlación. En el siguiente gráfico, el usuario puede visualizar varias medidas (como la fatiga del motor frente a la temperatura, o el rendimiento del equipaje frente a la velocidad del carrusel) y utilizar este tablero para informar mejor la próxima mejor acción de mantenimiento.


Eliminar el ruido de los datos
Después de algunas semanas, notamos que Lookout for Equipment estaba emitiendo algunos eventos que se creía que eran falsos positivos.

Al analizar estos eventos, descubrimos caídas irregulares en la velocidad del motor del carrusel.

Nos reunimos con el equipo de mantenimiento y nos informaron que estas paradas eran paradas de emergencia o actividades de mantenimiento de tiempo de inactividad planificadas. Con esta información, etiquetamos las paradas de emergencia como anomalías y las enviamos a Lookout for Equipment, mientras que los tiempos de inactividad planificados se consideraron un comportamiento normal para este carrusel.
Comprender tales escenarios donde los datos anormales pueden verse influenciados por acciones externas controladas es fundamental para mejorar la precisión del modelo de detección de anomalías con el tiempo.
Prueba de humo
Después de unas horas de volver a entrenar el modelo y lograr relativamente ninguna anomalía, nuestro equipo estresó físicamente los activos, lo que el sistema detectó de inmediato. Esta es una solicitud común de los usuarios porque necesitan familiarizarse con el sistema y cómo reacciona.

Construimos nuestro tablero para permitir a los usuarios finales visualizar anomalías históricas con un período ilimitado. El uso de un servicio de inteligencia empresarial les permite organizar sus datos a voluntad, y hemos descubierto que los gráficos de barras durante un período de 24 horas o los gráficos circulares son la mejor manera de obtener una buena visión del estado del BHS. Además de los paneles que los usuarios pueden ver cuando lo necesiten, configuramos alertas automáticas enviadas a una dirección de correo electrónico designada y por mensaje de texto.
Extraer conocimientos más profundos de los modelos de detección de anomalías
En el futuro, tenemos la intención de extraer conocimientos más profundos de los modelos de detección de anomalías entrenados con Lookout for Equipment. Continuaremos usando QuickSight para crear un conjunto ampliado de widgets. Por ejemplo, hemos encontrado que los widgets de visualización de datos expuestos en el Ejemplos de GitHub para Lookout for Equipment nos permite extraer aún más información de los resultados sin procesar de nuestros modelos.

Resultados
El mantenimiento reactivo en los sistemas de manejo de equipaje se traduce en lo siguiente:
- Menor satisfacción de los pasajeros debido a largos tiempos de espera o equipaje dañado
- Menor disponibilidad de activos debido a fallas no planificadas y escasez de inventario de repuestos críticos
- Mayores gastos operativos debido al aumento de los niveles de inventario además de mayores costos de mantenimiento
La evolución de su estrategia de mantenimiento para incorporar análisis fiables y predictivos en el ciclo de toma de decisiones tiene como objetivo mejorar el funcionamiento de los activos y ayudar a evitar paradas forzadas.

El equipo de monitoreo fue instalado localmente en 1 día y configurado de forma completamente remota por expertos en IoT. La arquitectura de nube descrita en la descripción general de la solución se implementó con éxito en 90 días. Un tiempo de implementación rápido demuestra los beneficios propuestos para el usuario final, lo que lleva rápidamente a un cambio en la estrategia de mantenimiento de reactivo basado en humanos (reparación de averías) a proactivo basado en datos y basado en máquinas (prevención de tiempos de inactividad).
Conclusión
La cooperación entre Airis, CloudRail, Northbay Solutions y AWS condujo a un nuevo logro en el Aeropuerto Internacional King Khalid (ver el comunicado de prensa para más detalles). Como parte de su estrategia de transformación digital, el aeropuerto de Riyadh planea implementar más para cubrir otros sistemas electromecánicos como puentes de embarque de pasajeros y sistemas HVAC.
Si tiene comentarios sobre esta publicación, envíelos en la sección de comentarios. Si tiene preguntas sobre esta solución o su implementación, inicie un nuevo hilo en re:Publicar, donde los expertos de AWS y la comunidad en general pueden ayudarlo.
Sobre los autores
 moulham zahabi es un especialista en aviación con más de 11 años de experiencia en el diseño y la gestión de proyectos de aviación y en la gestión de activos aeroportuarios críticos en la región del CCG. También es uno de los cofundadores de Airis-Solutions.ai, cuyo objetivo es liderar la transformación digital de la industria de la aviación a través de soluciones innovadoras de IA/ML para aeropuertos y centros logísticos. En la actualidad, Moulham dirige la Dirección de Gestión de Activos de Saudi Civil Aviation Holding Company (Matarat).
moulham zahabi es un especialista en aviación con más de 11 años de experiencia en el diseño y la gestión de proyectos de aviación y en la gestión de activos aeroportuarios críticos en la región del CCG. También es uno de los cofundadores de Airis-Solutions.ai, cuyo objetivo es liderar la transformación digital de la industria de la aviación a través de soluciones innovadoras de IA/ML para aeropuertos y centros logísticos. En la actualidad, Moulham dirige la Dirección de Gestión de Activos de Saudi Civil Aviation Holding Company (Matarat).
 fauzan khan es un arquitecto sénior de soluciones que trabaja con clientes del sector público y brinda orientación para diseñar, implementar y administrar sus cargas de trabajo y arquitecturas de AWS. A Fauzan le apasiona ayudar a los clientes a adoptar tecnologías de nube innovadoras en el área de HPC y AI/ML para abordar los desafíos comerciales. Fuera del trabajo, a Fauzan le gusta pasar tiempo en la naturaleza.
fauzan khan es un arquitecto sénior de soluciones que trabaja con clientes del sector público y brinda orientación para diseñar, implementar y administrar sus cargas de trabajo y arquitecturas de AWS. A Fauzan le apasiona ayudar a los clientes a adoptar tecnologías de nube innovadoras en el área de HPC y AI/ML para abordar los desafíos comerciales. Fuera del trabajo, a Fauzan le gusta pasar tiempo en la naturaleza.
 Michael Hoarau es un arquitecto de soluciones especialista en IA/ML en AWS que alterna entre científico de datos y arquitecto de aprendizaje automático, según el momento. Le apasiona llevar el poder de AI/ML a los talleres de sus clientes industriales y ha trabajado en una amplia gama de casos de uso de ML, que van desde la detección de anomalías hasta la calidad predictiva del producto o la optimización de la fabricación. Él publicó un libro sobre analisis de series de tiempo en 2022 y escribe regularmente sobre este tema en Etiqueta LinkedIn y Medio. Cuando no está ayudando a los clientes a desarrollar las próximas mejores experiencias de aprendizaje automático, le gusta observar las estrellas, viajar o tocar el piano.
Michael Hoarau es un arquitecto de soluciones especialista en IA/ML en AWS que alterna entre científico de datos y arquitecto de aprendizaje automático, según el momento. Le apasiona llevar el poder de AI/ML a los talleres de sus clientes industriales y ha trabajado en una amplia gama de casos de uso de ML, que van desde la detección de anomalías hasta la calidad predictiva del producto o la optimización de la fabricación. Él publicó un libro sobre analisis de series de tiempo en 2022 y escribe regularmente sobre este tema en Etiqueta LinkedIn y Medio. Cuando no está ayudando a los clientes a desarrollar las próximas mejores experiencias de aprendizaje automático, le gusta observar las estrellas, viajar o tocar el piano.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/deploy-a-predictive-maintenance-solution-for-airport-baggage-handling-systems-with-amazon-lookout-for-equipment/

