amazona kendra es un servicio de búsqueda inteligente altamente preciso y fácil de usar impulsado por aprendizaje automático (ML). Amazon Kendra ofrece un conjunto de conectores de fuentes de datos para simplificar el proceso de ingesta e indexación de su contenido, dondequiera que resida.
Los datos valiosos en las organizaciones se almacenan en repositorios estructurados y no estructurados. Una solución de búsqueda empresarial debe poder reunir datos en varios repositorios estructurados y no estructurados para indexar y buscar.
Uno de esos repositorios de datos no estructurados es Confluence. Confluence es un espacio de trabajo en equipo que brinda a los equipos de trabajadores del conocimiento un lugar para crear, capturar y colaborar en cualquier proyecto o idea. Los espacios de equipo ayudan a los equipos a estructurar, organizar y compartir el trabajo, de modo que cada miembro del equipo tenga visibilidad del conocimiento institucional y acceso a la información que necesita.
Hay dos Confluencia ofertas:
- Soluciones – Esto se ofrece como un producto de software como servicio (SaaS). Siempre está activo, se actualiza continuamente y es muy seguro.
- Centro de datos (autogestionado) – Aquí, aloja Confluence en su infraestructura, que podría estar en las instalaciones o en la nube. Esto le permite mantener los datos dentro de su red y administrarlos usted mismo.
Nos complace anunciar que ahora puede utilizar el nuevo conector V2 de Amazon Kendra para Confluence para buscar información almacenada en su cuenta de Confluence tanto en la nube como en su centro de datos. En esta publicación, mostramos cómo indexar la información almacenada en Confluence y usar la función de búsqueda inteligente de Amazon Kendra. Además, la búsqueda inteligente impulsada por ML puede encontrar con precisión información de documentos no estructurados que tienen contenido narrativo en lenguaje natural, para los cuales la búsqueda de palabras clave no es muy efectiva.
Novedades de esta versión
Esta versión admite la autenticación OAuth 2.0 además de la autenticación básica para la edición Cloud. Para la edición Data Center (local), hemos agregado OAuth2 además de autenticación básica y tokens de acceso personal para mostrar los resultados de la búsqueda según los derechos de acceso del usuario. Puedes beneficiarte de las siguientes características:
- Ahora puede rastrear comentarios además de espacios, páginas, blogs y archivos adjuntos.
- Ahora tiene opciones detalladas para su ámbito de sincronización: puede especificar páginas, blogs, comentarios y archivos adjuntos.
- Puede elegir importar identidades (o no)
- Esta versión ofrece compatibilidad con expresiones regulares para elegir títulos de entidades y tipos de archivos
- Tiene la opción de múltiples modos de sincronización
Resumen de la solución
Con Amazon Kendra, puede configurar varias fuentes de datos para proporcionar un lugar central para buscar en su repositorio de documentos. Para nuestra solución, demostramos cómo indexar un repositorio de Confluence mediante el conector de Amazon Kendra para Confluence. La solución consta de los siguientes pasos:
- Elija un mecanismo de autenticación.
- Configure una aplicación en Confluence y obtenga los detalles de la conexión.
- Guarda los detalles en Director de secretos de AWS.
- Cree una fuente de datos de Confluence V2 a través de la consola de Amazon Kendra.
- Indexe los datos en el repositorio de Confluence.
- Ejecute una consulta de muestra para probar la solución.
Requisitos previos
Para probar el conector de Amazon Kendra para Confluence, necesita lo siguiente:
Elija un mecanismo de autenticación
Elija su método de autenticación preferido:
- Basic – Esto funciona en las ediciones Cloud y Data Center. Necesita un ID de usuario y una contraseña para configurar este método.
- Token de acceso personal – Esta opción solo funciona para la edición Data Center.
- OAuth2 – Esto es más complicado y funciona para las ediciones Cloud y Data Center.
Recopilar detalles de autenticación
En esta sección, mostramos los pasos para recopilar sus datos de autenticación según su método de autenticación.
La autenticación básica
Para la autenticación básica con la edición Data Center, todo lo que necesita es su nombre de usuario y contraseña. Asegúrese de que su inicio de sesión tenga privilegios para recopilar todo el contenido.
Para la edición Cloud, su ID de usuario sirve como inicio de sesión de usuario. Para su contraseña, necesita obtener un token. Complete los siguientes pasos:
- Inicia sesión en https://id.atlassian.com/manage-profile/security/api-tokens y elige Crear token de API.

- Label, ingrese un nombre para el token.
- Elige Crear.
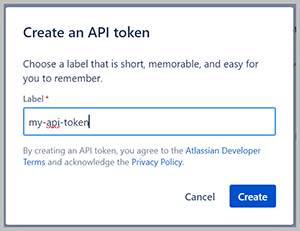
- Copie el valor y guárdelo para usarlo como su contraseña.

Token de acceso personal
Este método de autenticación funciona solo en las instalaciones (Centro de datos). Complete los siguientes pasos para adquirir los detalles de autenticación:
- Inicie sesión en su URL de Confluence con el ID de usuario y la contraseña que desea que use Amazon Kendra al recuperar contenido.
- Elige el icono de perfil y elige Ajustes.

- Elige Tokens de acceso personal en el panel de navegación, luego elija Crear token.

- Nombre del token, ingresa un nombre.
- Fecha de caducidad, deseleccionar Caducidad automática.
- Elige Crear.

- Copie el token y guárdelo en un lugar seguro.
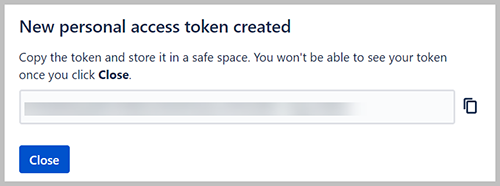
Para configurar Secrets Manager, usamos la URL de inicio de sesión y este valor.
Autenticación OAuth2 para la edición Confluence Cloud
Este método de autenticación sigue el completo Documentación de OAuth2.0 (3LO) de Confluencia. Primero creamos y configuramos una aplicación en Confluence y la habilitamos para OAuth2. El proceso es ligeramente diferente para las ediciones Cloud y Data Center. Luego obtenemos un token de autorización y lo cambiamos por un token de acceso. Finalmente, obtenemos la identificación del cliente, el secreto del cliente y el código del cliente. Complete los siguientes pasos:
- Inicie sesión en la aplicación Confluence.
- Navegue hasta https://developer.atlassian.com/.
- Al lado de Mis aplicaciones, escoger Crear y elige Integración OAuth2.

- Nombre, ingresa un nombre.
- Elige Crear.
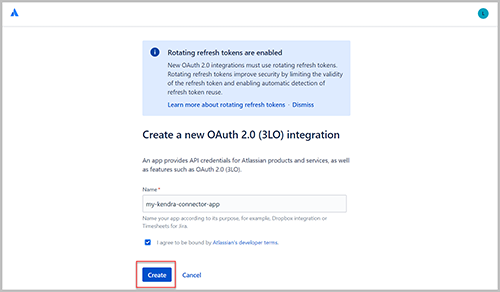
- Elige Autorización en el panel de navegación.
- Elige Añada junto a su tipo de autorización.
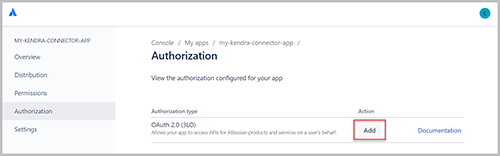
- URL de devolución de llamada, ingresa la URL que usas para iniciar sesión en Confluence.
- Elige Guardar los cambios.
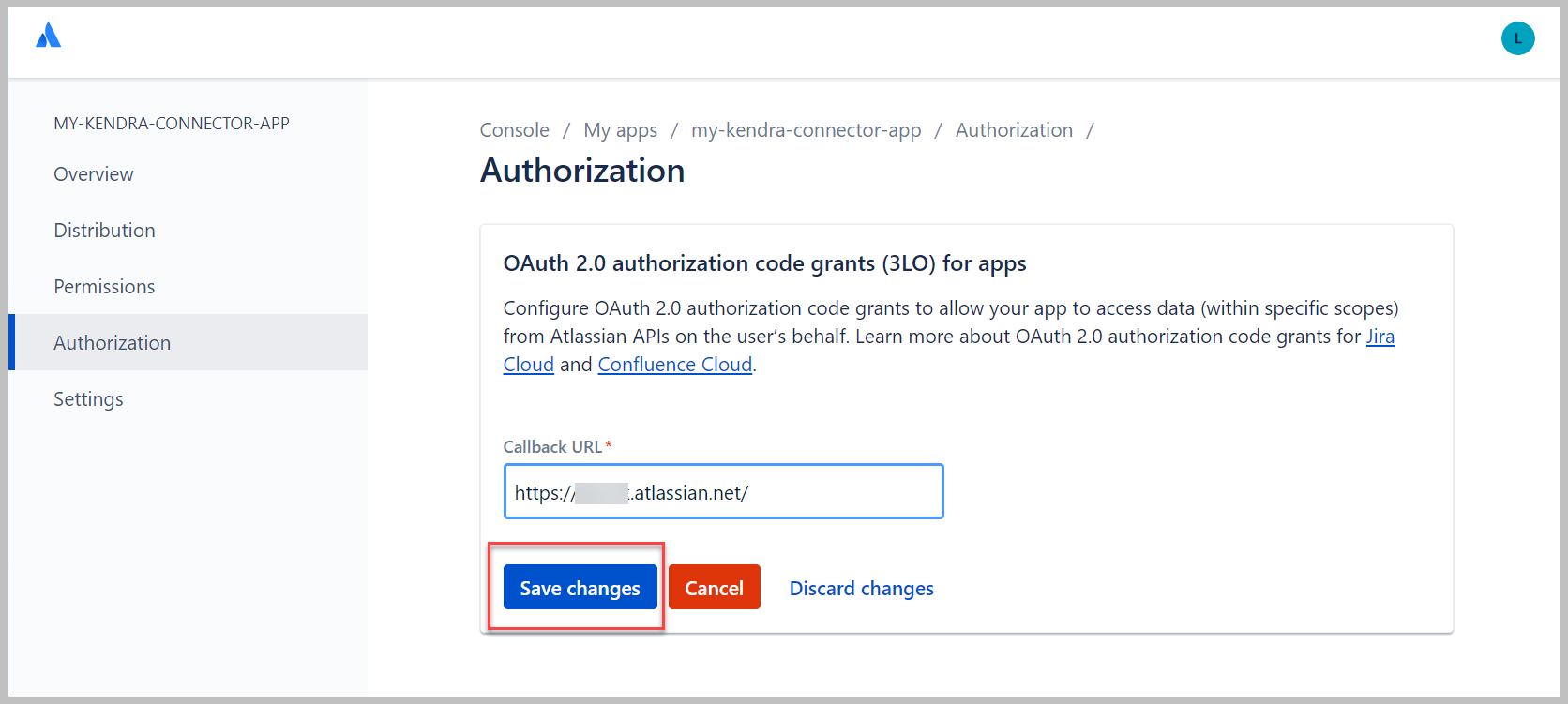
- under Generador de URL de autorización, escoger Agregar API.
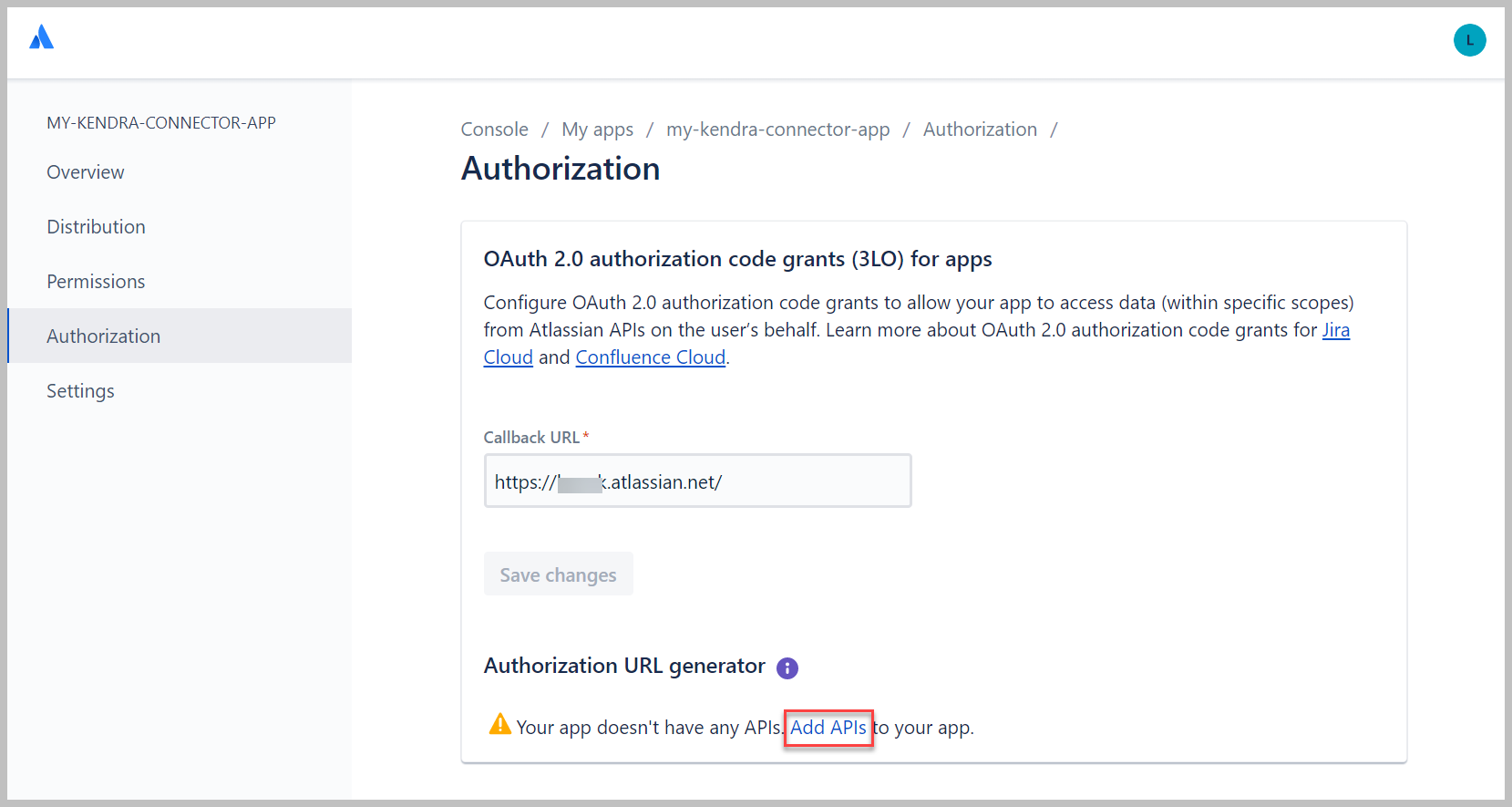
- Al lado de API de identidad de usuario, escoger Añada, A continuación, elija Configurar.
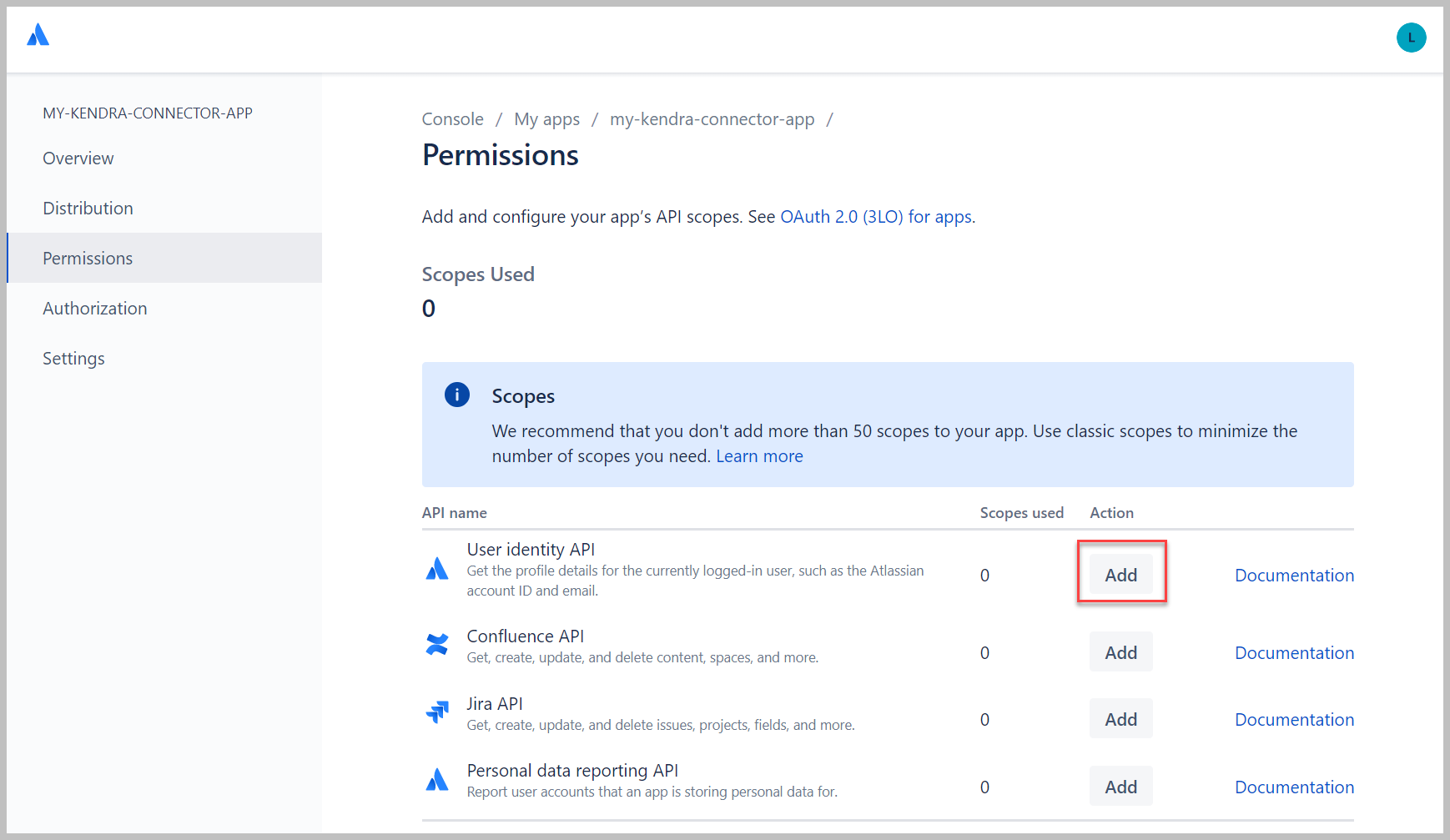
- Elige Editar ámbitos para configurar los ámbitos de lectura de la aplicación.
- Seleccione Ver perfil de usuario activo y Ver perfiles de usuario.
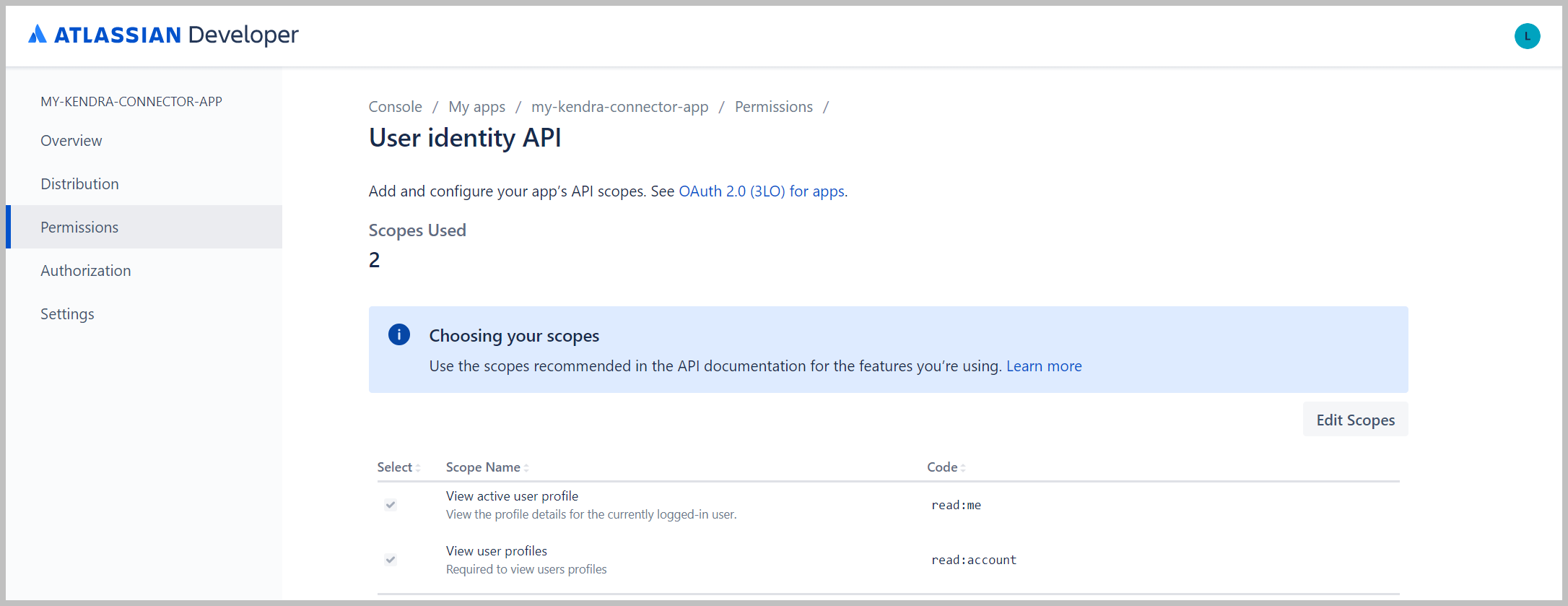
- Elige Permisos en el panel de navegación.
- Al lado de API de confluencia, escoger Añada, A continuación, elija Configurar.
- En Miras clásicas pestaña, elegir Editar ámbitos.
- Seleccione todos los ámbitos de lectura, búsqueda y descarga.
- Elige Guardar.
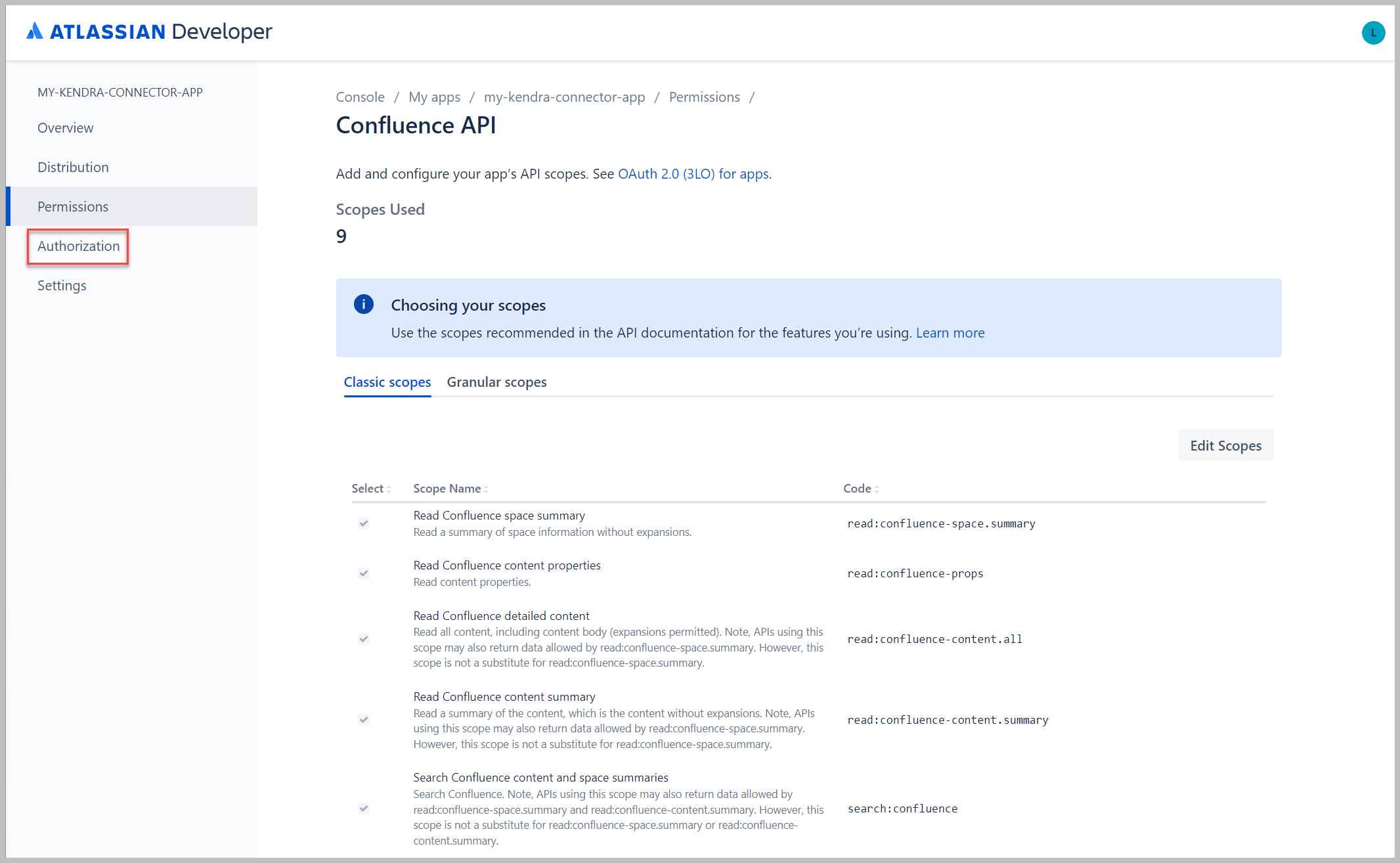
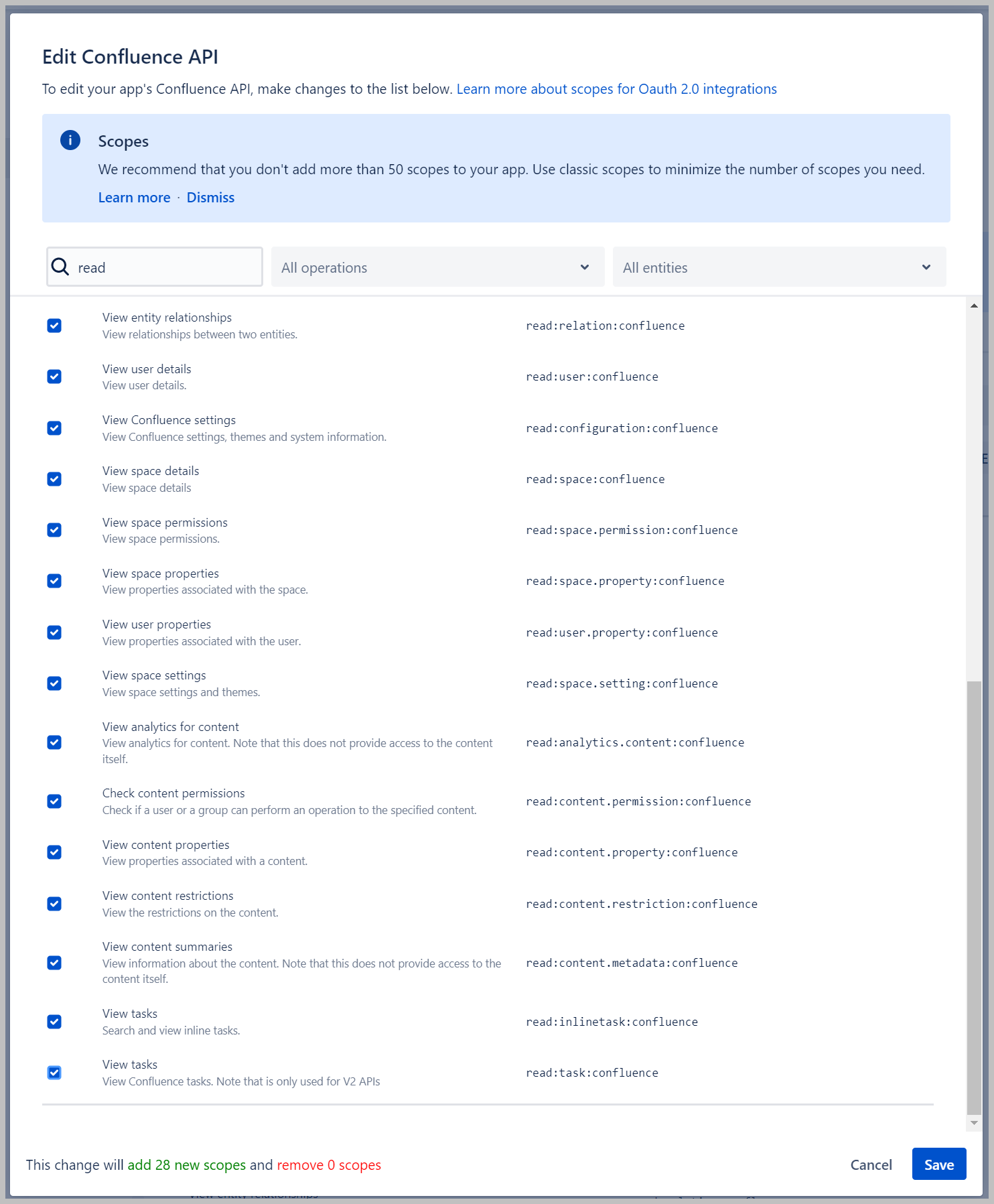
- En Ámbitos granulares pestaña, elegir Editar ámbitos.
- Busque leer y seleccione todos los ámbitos encontrados.
- Elige Guardar.
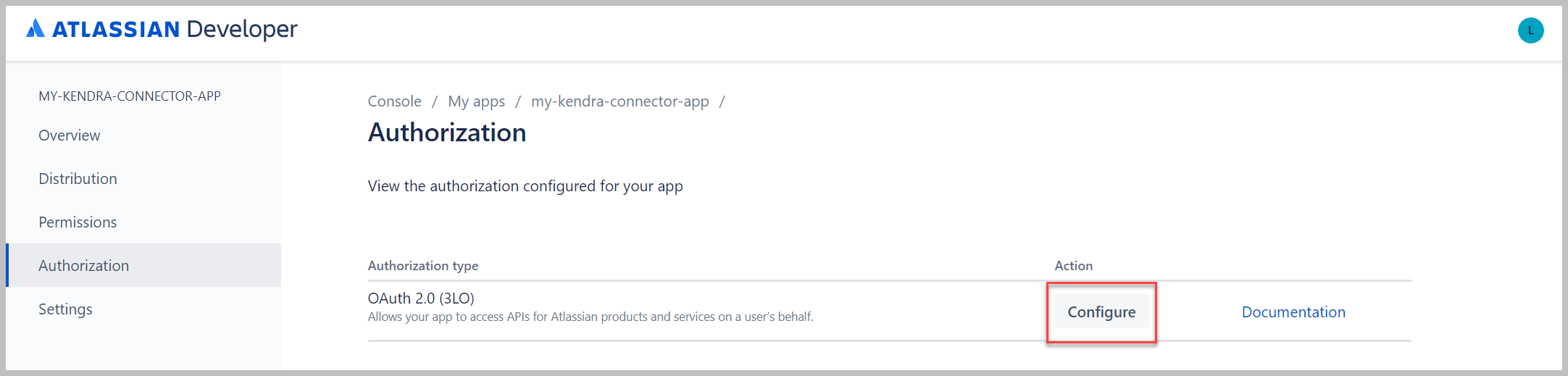
- Elige Autorización en el panel de navegación.
- Junto a su tipo de autorización, elija Configurar.
Debería ver tres URL en la lista.
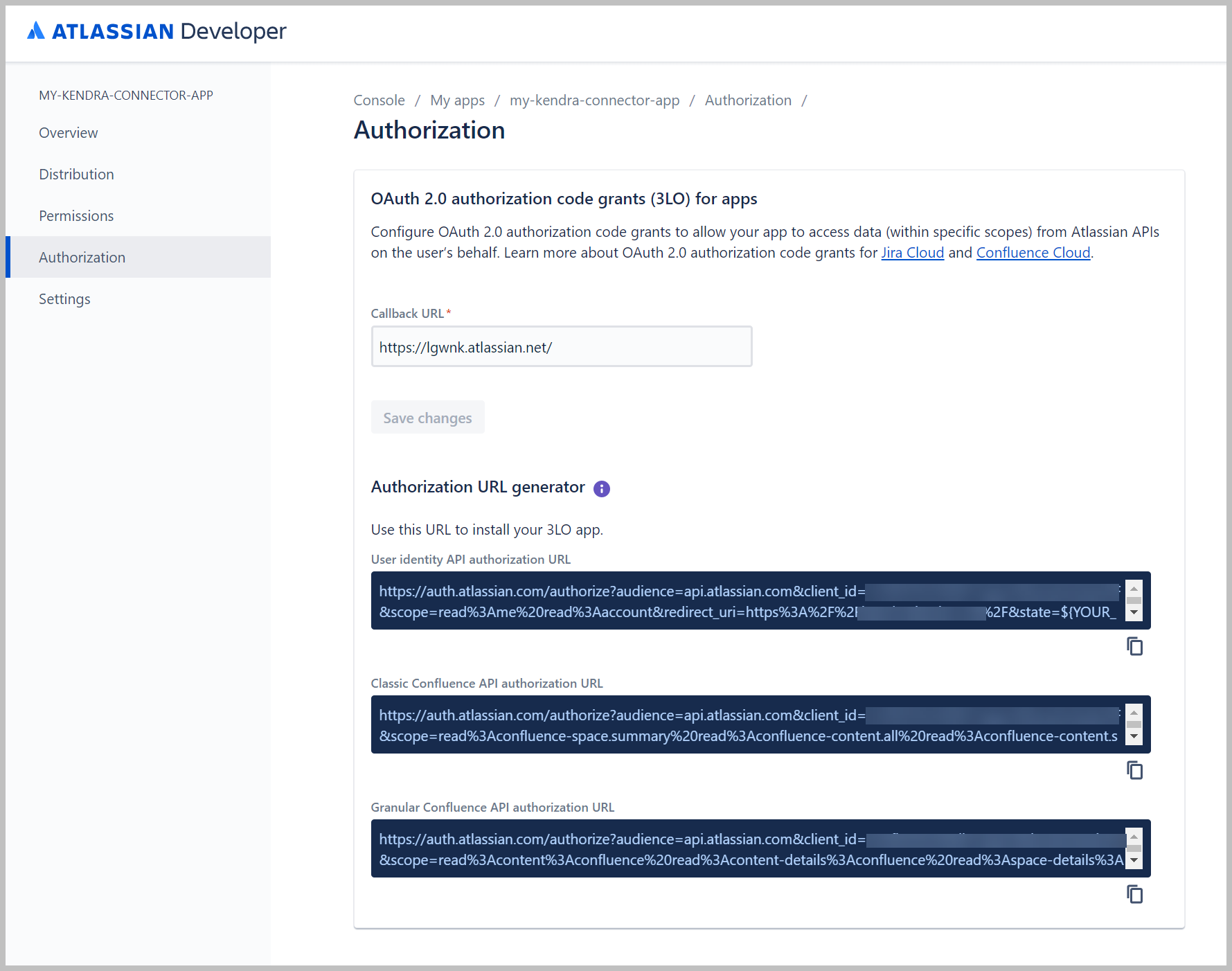
- Copie el código para URL de autorización de la API granular de Confluence.
El siguiente es un código de ejemplo:
- Si desea generar un token de actualización para no tener que repetir este proceso, agregue
offline_access(o%20offline_access) hasta el final de todos los ámbitos de la URL (por ejemplo,&scope=REQUESTED_SCOPE%20REQUESTED_SCOPE_TWO%20offline_access). - Si está de acuerdo en generar un nuevo token cada vez, simplemente ingrese la URL en su navegador.
- Elige Aceptar.
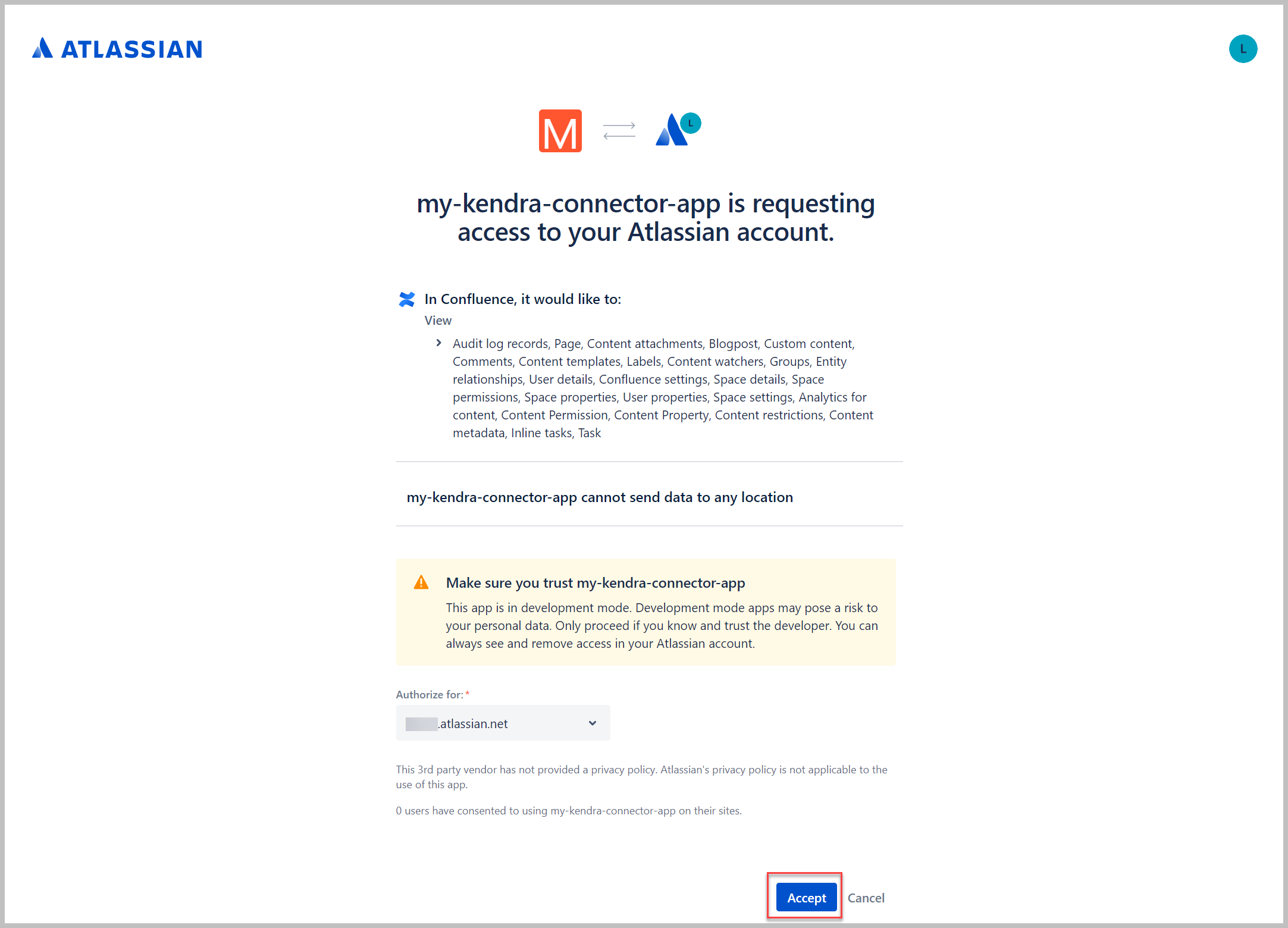
Serás redirigido a tu página de inicio de Confluence.
- Inspeccione la URL del navegador y localice
code=xxxxx. - Copia este código y guárdalo.
Este es el código de autorización que usamos para intercambiar con el token de acceso.

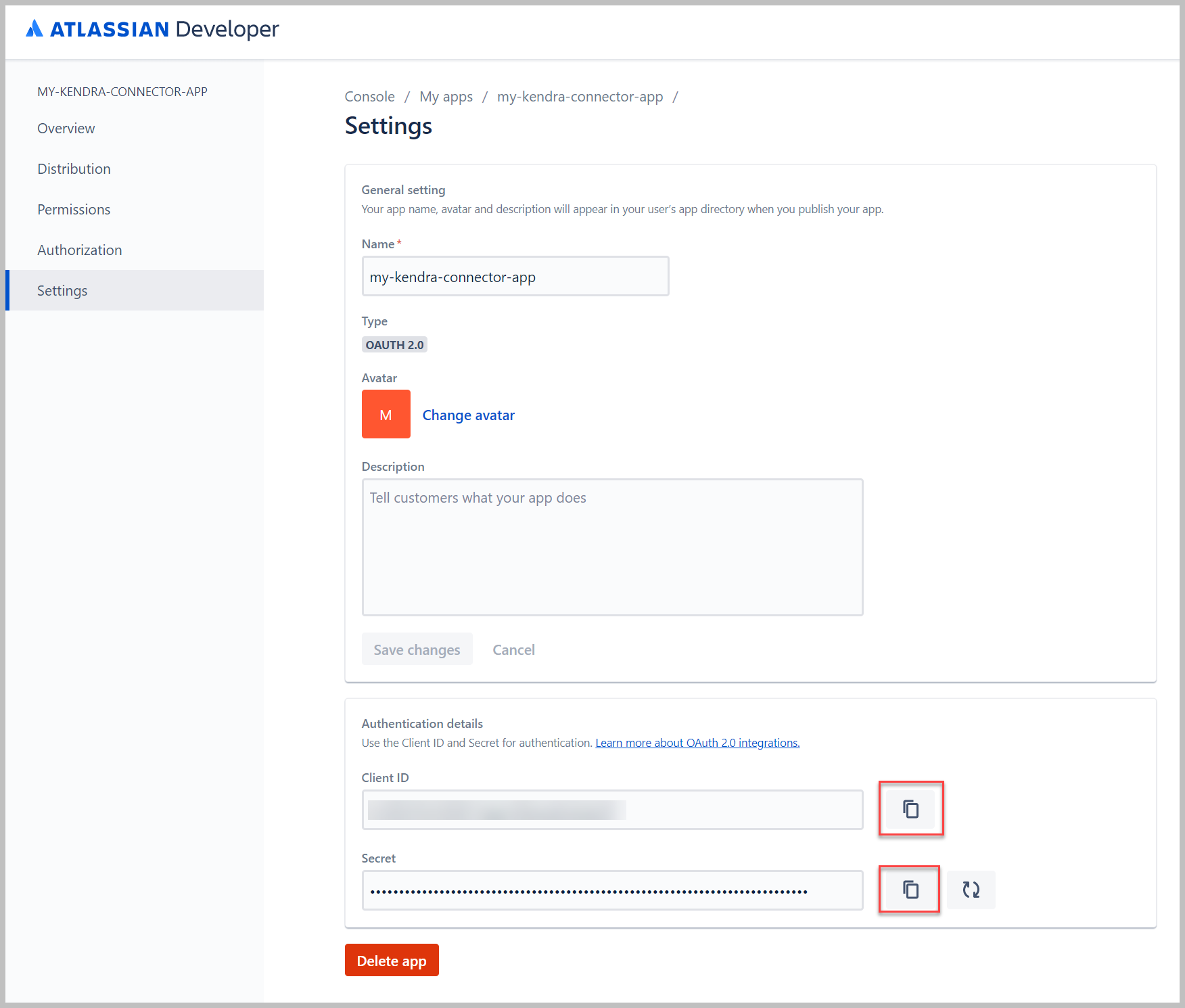
- Vuelve a la consola para desarrolladores de Atlassian y elige Ajustes en el panel de navegación.
- Copie los valores del ID de cliente y del ID secreto y guárdelos.
Necesitamos estos valores para hacer una llamada para intercambiar el token de autorización con el token de acceso.
A continuación, usamos el Cartero utilidad para publicar el código de autorización para obtener el token de acceso. Puede utilizar herramientas alternativas como rizo para hacer esto también.
- La URL para publicar el código de autorización es
https://auth.atlassian.com/oauth/token. - El cuerpo JSON para publicar es el siguiente:
La grant_type el parámetro está codificado. Recopilamos los valores de client_id y client_secret en un paso anterior. El valor del código es el código de autorización que recopilamos anteriormente.
Una respuesta exitosa devolverá el token de acceso. Si agregó acceso sin conexión a la URL anteriormente, también obtiene un token de actualización.
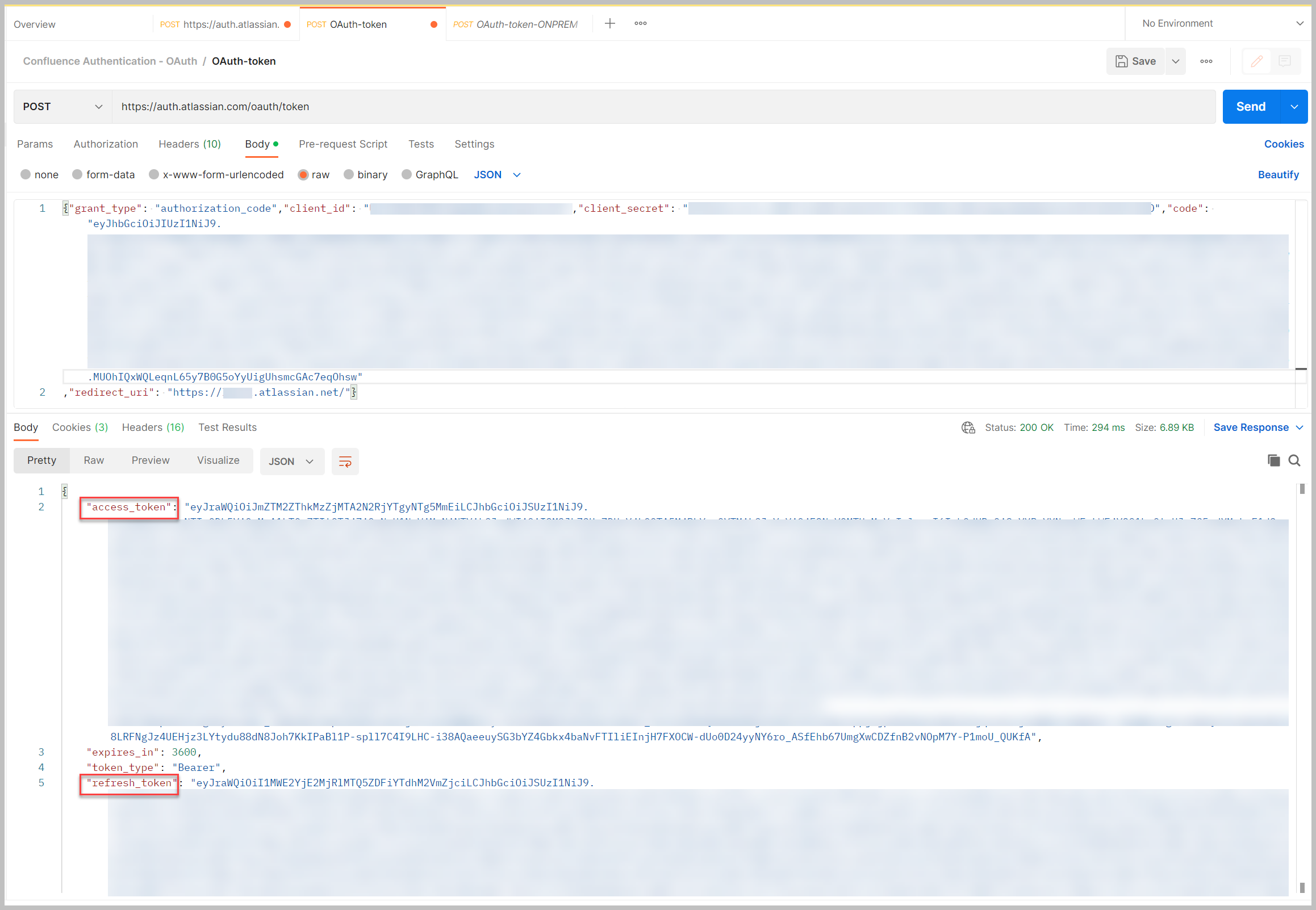
- Guarde el token de acceso para usarlo cuando configure Secrets Manager.
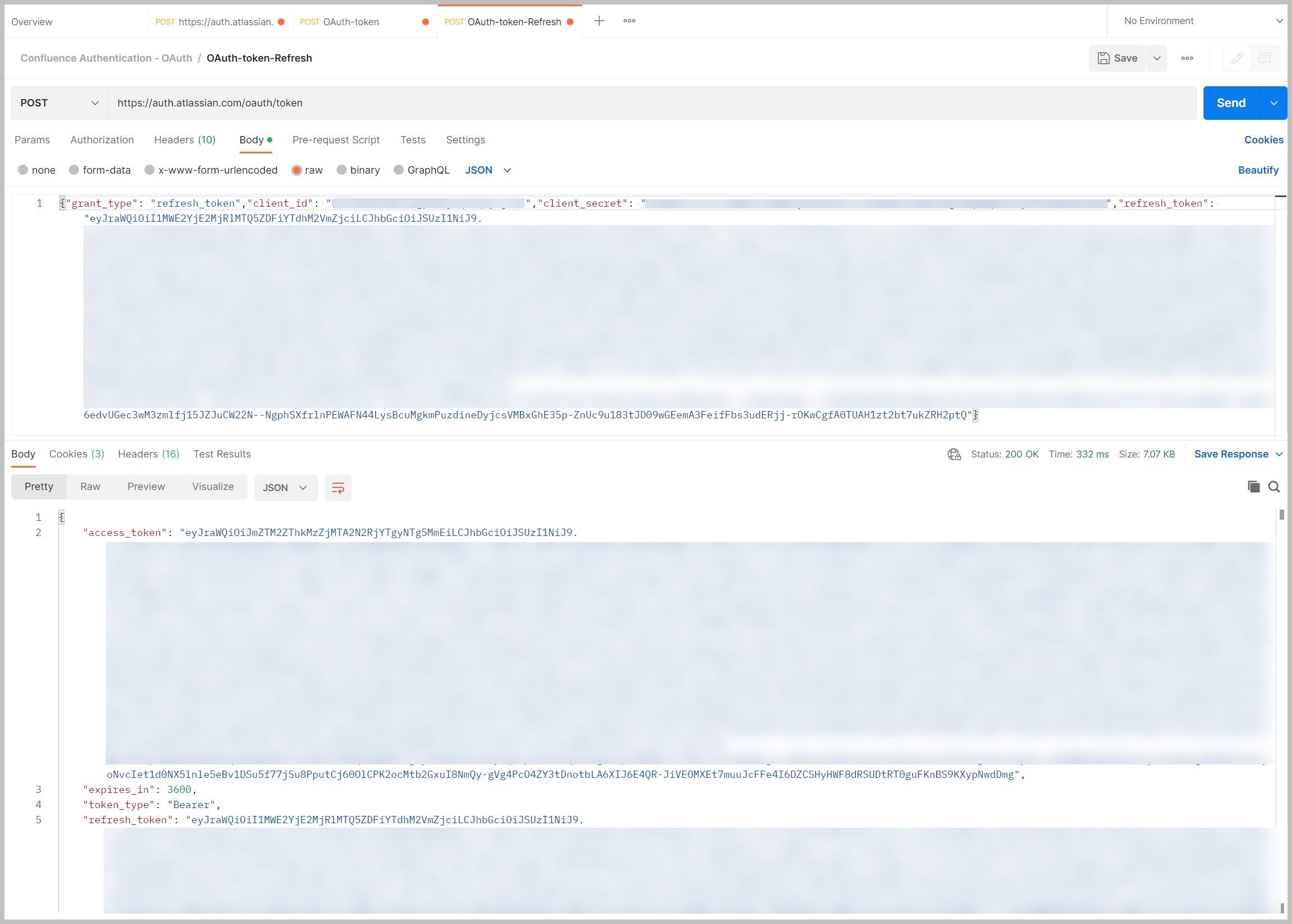
Si está generando un token nuevo a partir del token de actualización, el token actual solo es válido durante 1 hora. Si necesita obtener un nuevo token, puede comenzar de nuevo. Sin embargo, si tiene el token de actualización, como antes, use Postman para publicar en la siguiente URL: https://auth.atlassian.com/oauth/token. Utilice el siguiente formato JSON para el cuerpo del token:
La llamada devolverá un nuevo token de acceso
Autenticación OAuth2 para la edición Confluence Data Center
Si usa la edición Data Center con autenticación OAuth2, complete los siguientes pasos:
- Inicie sesión en la edición Confluence Data Center.
- Elija el ícono de ajustes, luego elija Configuración general.
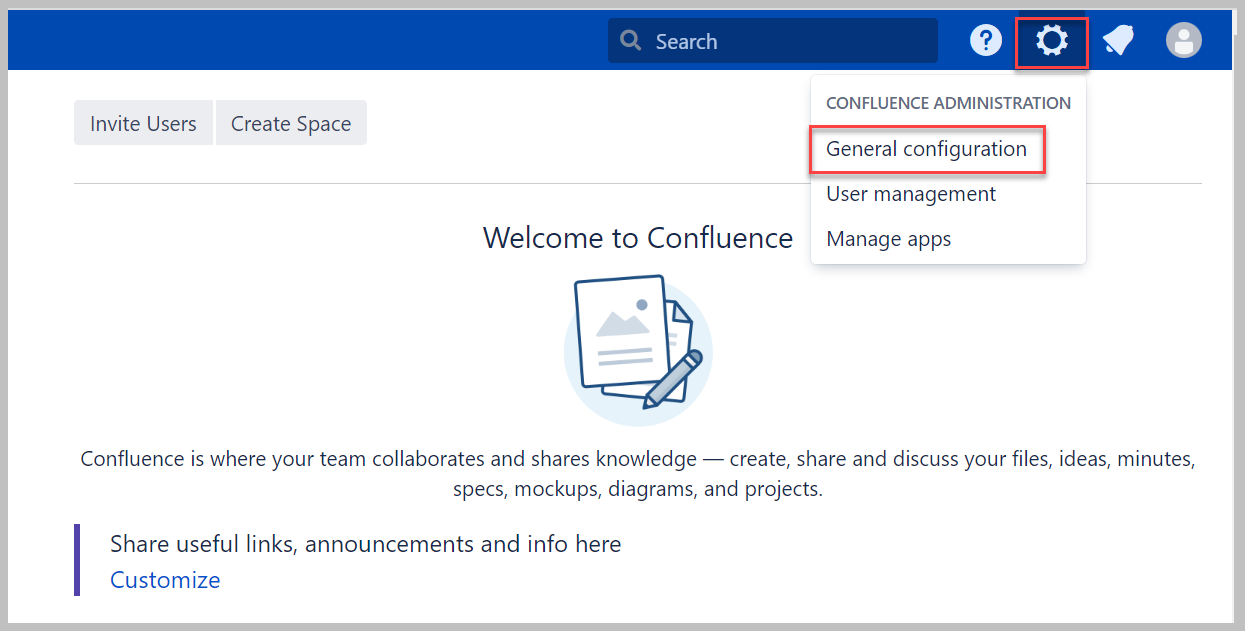
- En el panel de navegación, elija Vínculos de aplicación, A continuación, elija Crear vínculo.
- En Crear vínculo ventana emergente, seleccione Aplicación externa y Entrante, A continuación, elija Continúar.
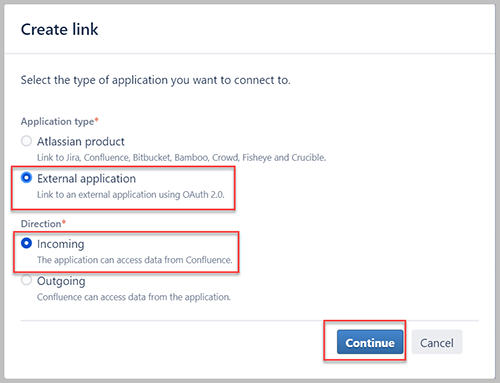
- Nombre, ingresa un nombre.
- URL a redirigir, introduzca
https://httpbin.org/. - Elige Guardar.
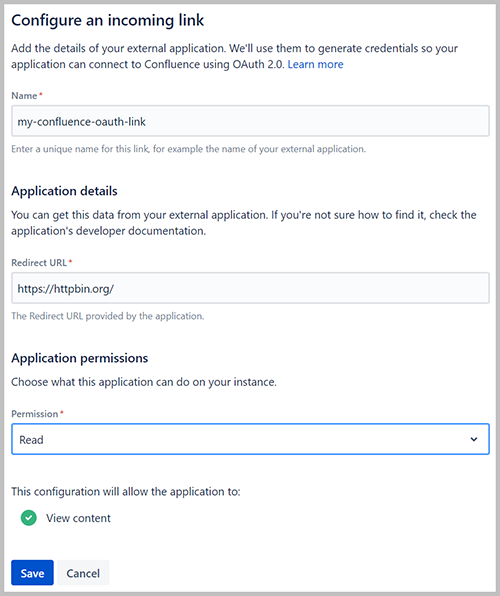
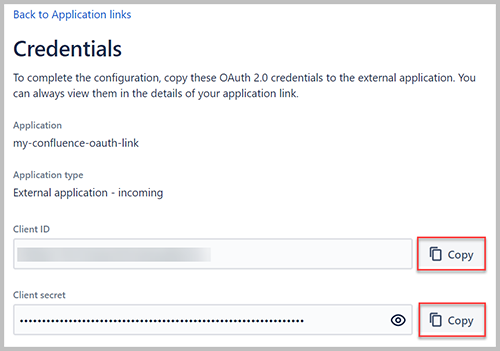
- Copie y guarde los valores para el ID de cliente y el secreto de cliente.
- En una pestaña separada del navegador, abra la URL https://example-app.com/pkce.
- Elige Generar cadena aleatoria y Calcular hash.
- Copie el valor bajo Desafío de código.
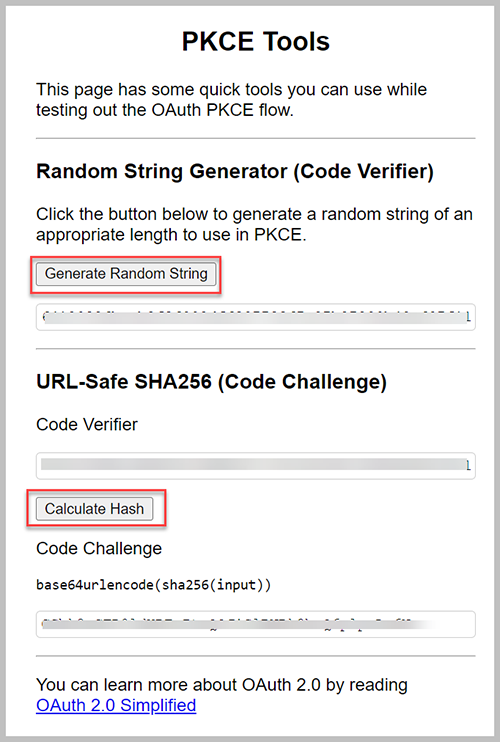
- Vuelve a tu pestaña original.
- Utilice la siguiente URL para obtener el código de autorización:
Utilice el ID de cliente que copió anteriormente y https://httpbin.org para el URI de redirección. Para CODE_CHALLENGE, ingrese el código que copió anteriormente.
- Elige Permitir.

eres redirigido a httpbin.org.
- Guarde el código para usarlo en el siguiente paso.

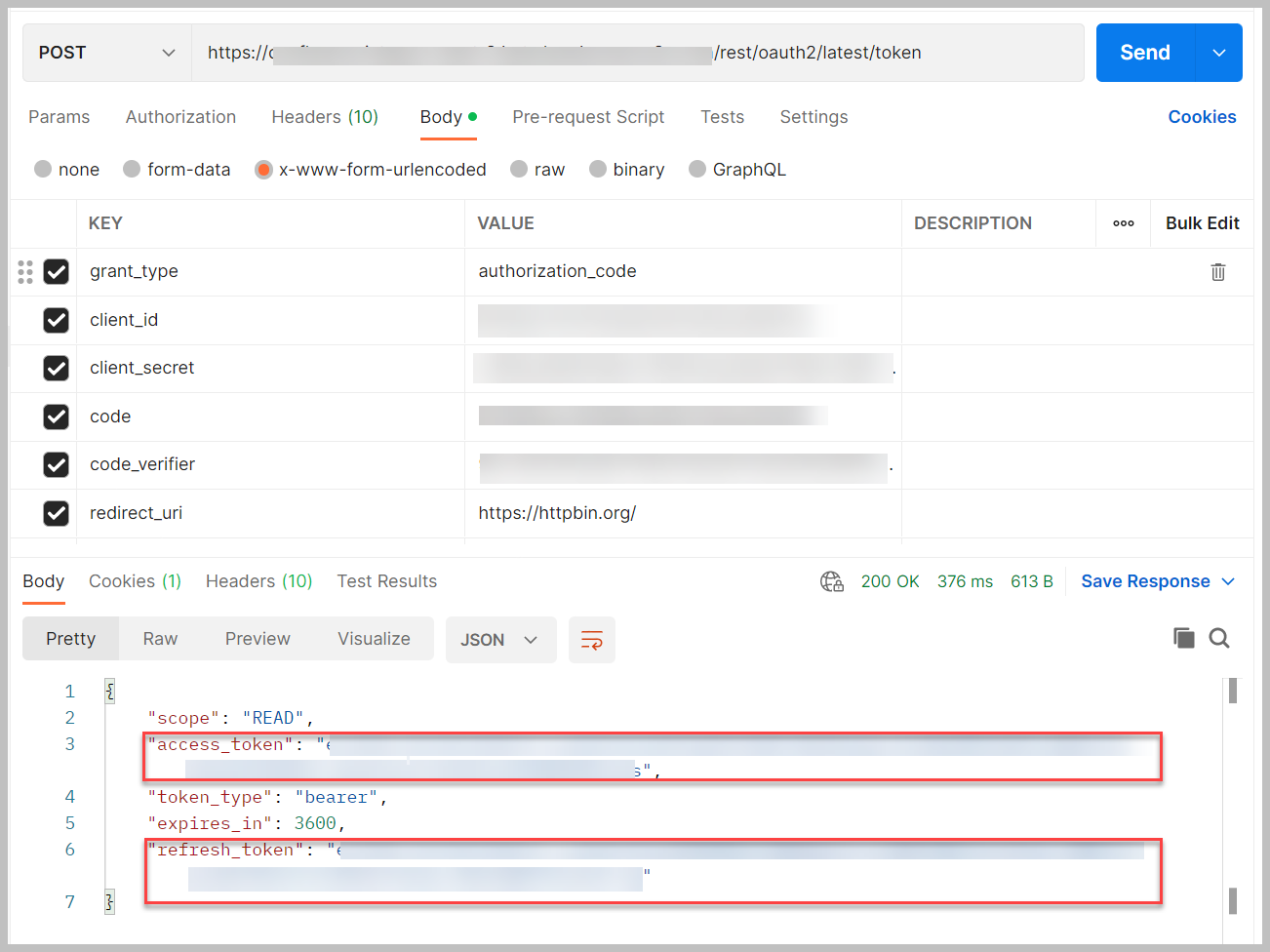
- Para obtener el token de acceso y el token de actualización, use una herramienta como rizo or Cartero publicar los siguientes valores en
https://<your confluence URL>/rest/oauth2/latest/token:
Utilice el ID de cliente, el secreto de cliente y el código de autorización que guardó anteriormente. Para CODE_VERIFIER, ingrese el valor de cuando generó el desafío del código.
- Copie el token de acceso y actualice el token para usarlo más tarde
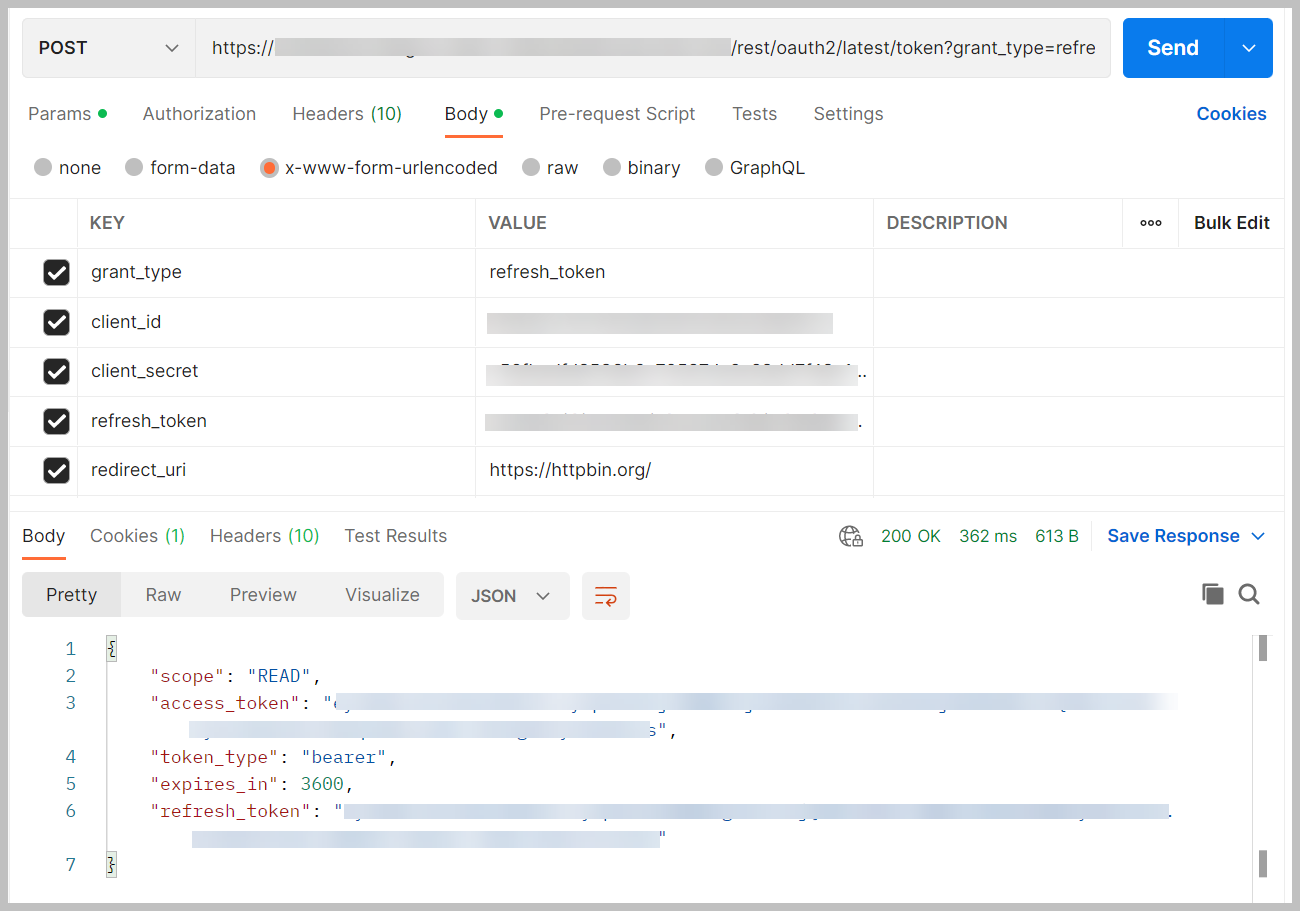
El token de acceso y el token de actualización son válidos solo por 1 hora. Para actualizar el token, publique el siguiente código en la misma URL para obtener nuevos valores:
Los nuevos tokens son válidos por 1 hora.
Almacenar las credenciales de Confluence en Secrets Manager
Para almacenar sus credenciales de Confluence en Secrets Manager, complete los siguientes pasos:
- En la consola de Secrets Manager, elija Almacenar un nuevo secreto.
- Seleccione Otro tipo de secreto.
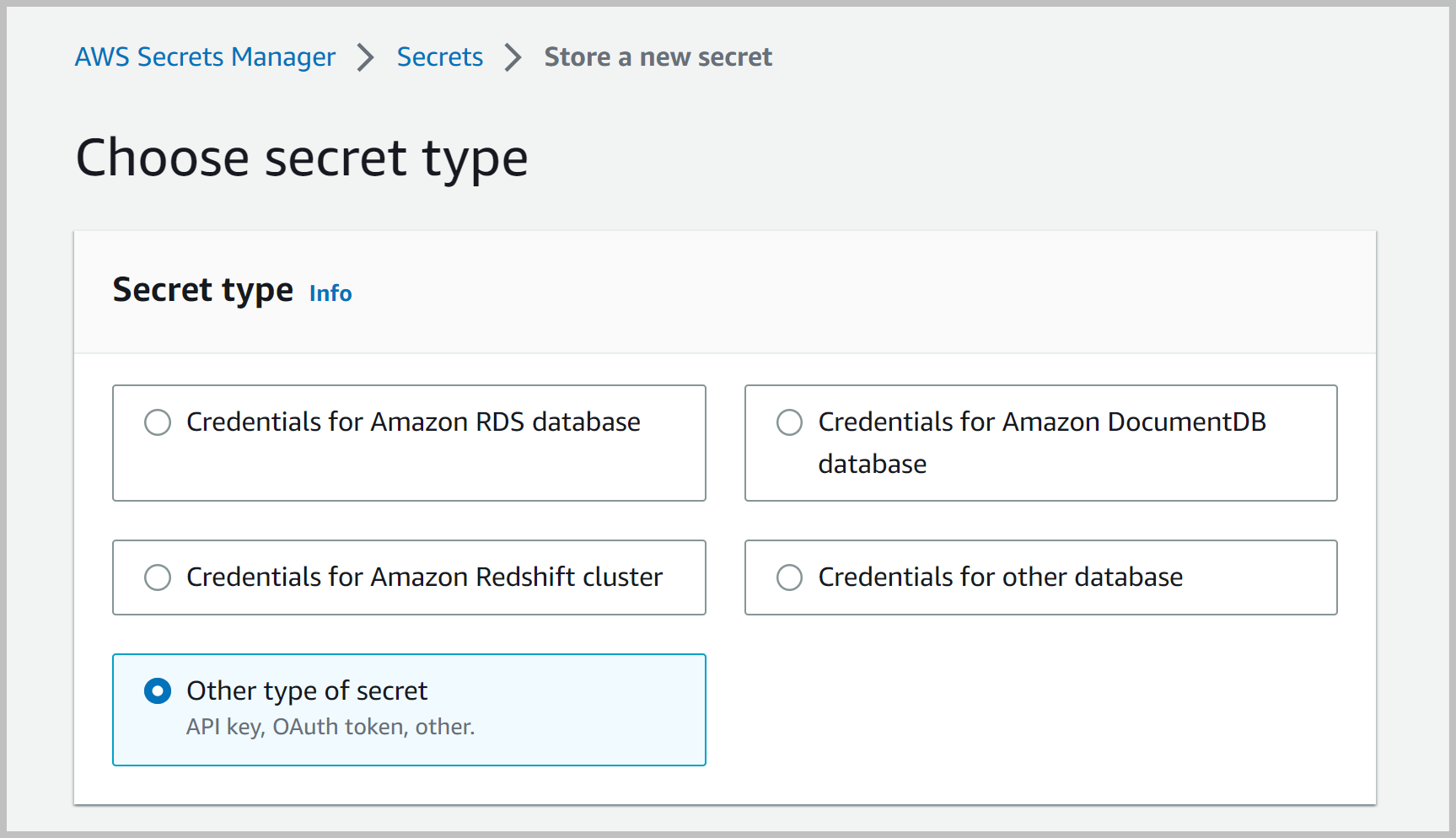
- Según el tipo de secreto, introduzca los valores-clave de la siguiente manera:
- Para la autenticación básica de Confluence Cloud, ingrese los siguientes pares clave-valor (tenga en cuenta que la contraseña no es la contraseña de inicio de sesión, sino el token que creó anteriormente):
- Para la autenticación OAuth de Confluence Cloud, ingrese los siguientes pares clave-valor:
- Para la autenticación básica de Confluence Data Center, ingrese los siguientes pares clave-valor:
- Para la autenticación del token de acceso personal de Confluence Data Center, ingrese los siguientes pares clave-valor:
- Para la autenticación OAuth de Confluence Data Center, ingrese los siguientes pares clave-valor:
- Elige Siguiente.
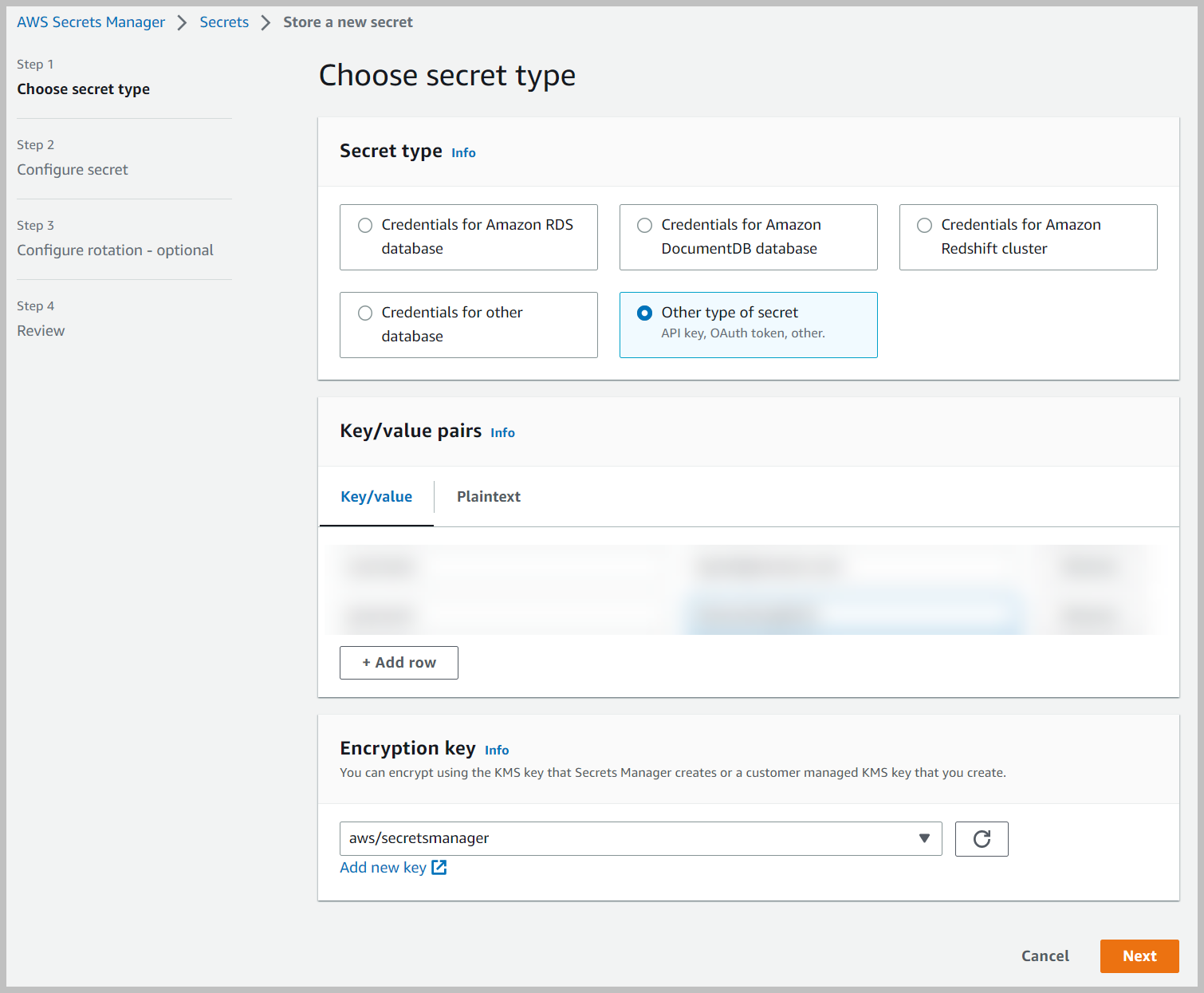
- Nombre secreto, ingrese un nombre (por ejemplo,
AmazonKendra-my-confluence-secret). - Introduzca una descripción opcional.
- Elige Siguiente.
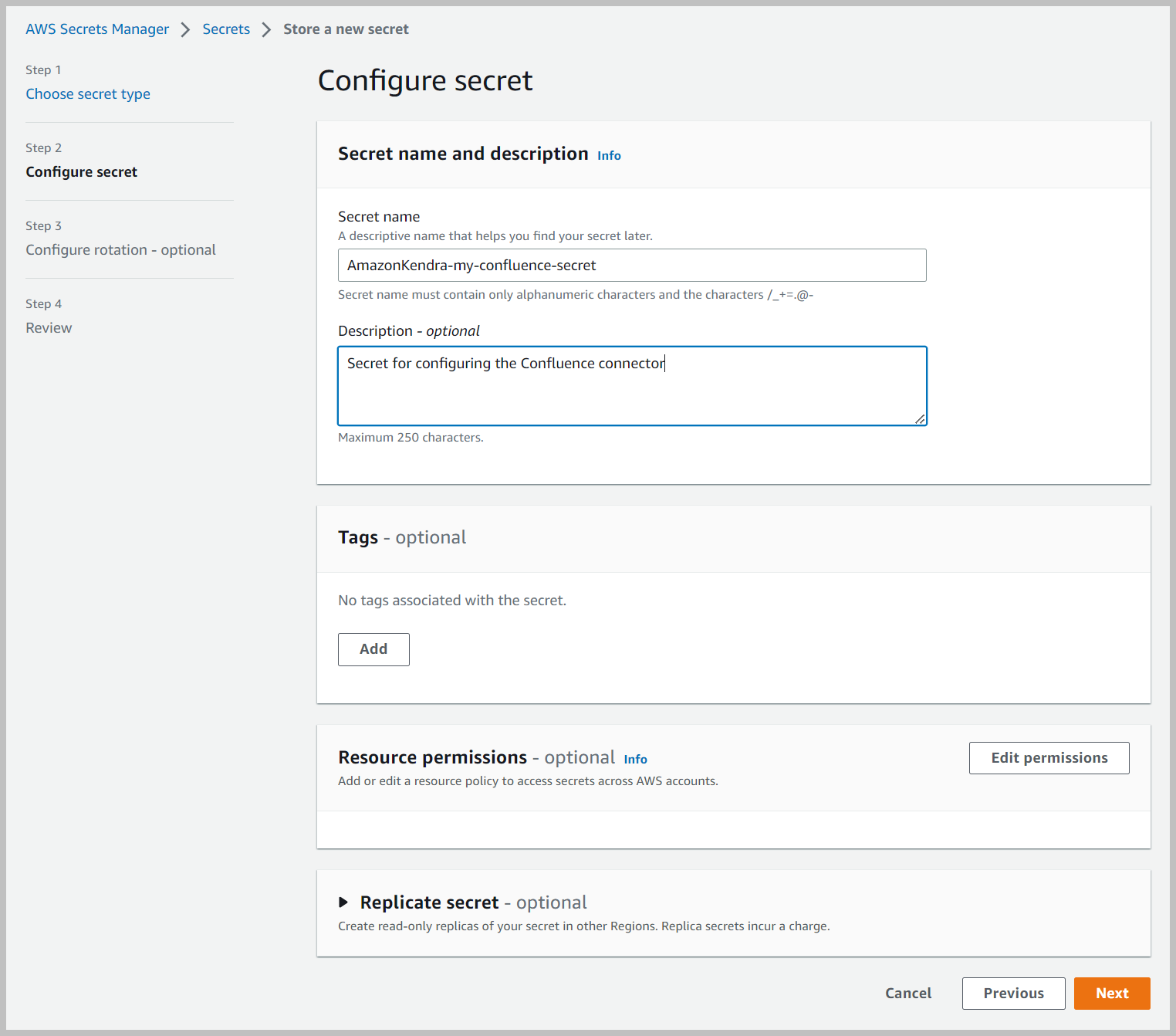
- En Configurar rotación sección, mantenga todas las configuraciones en sus valores predeterminados y elija Siguiente.
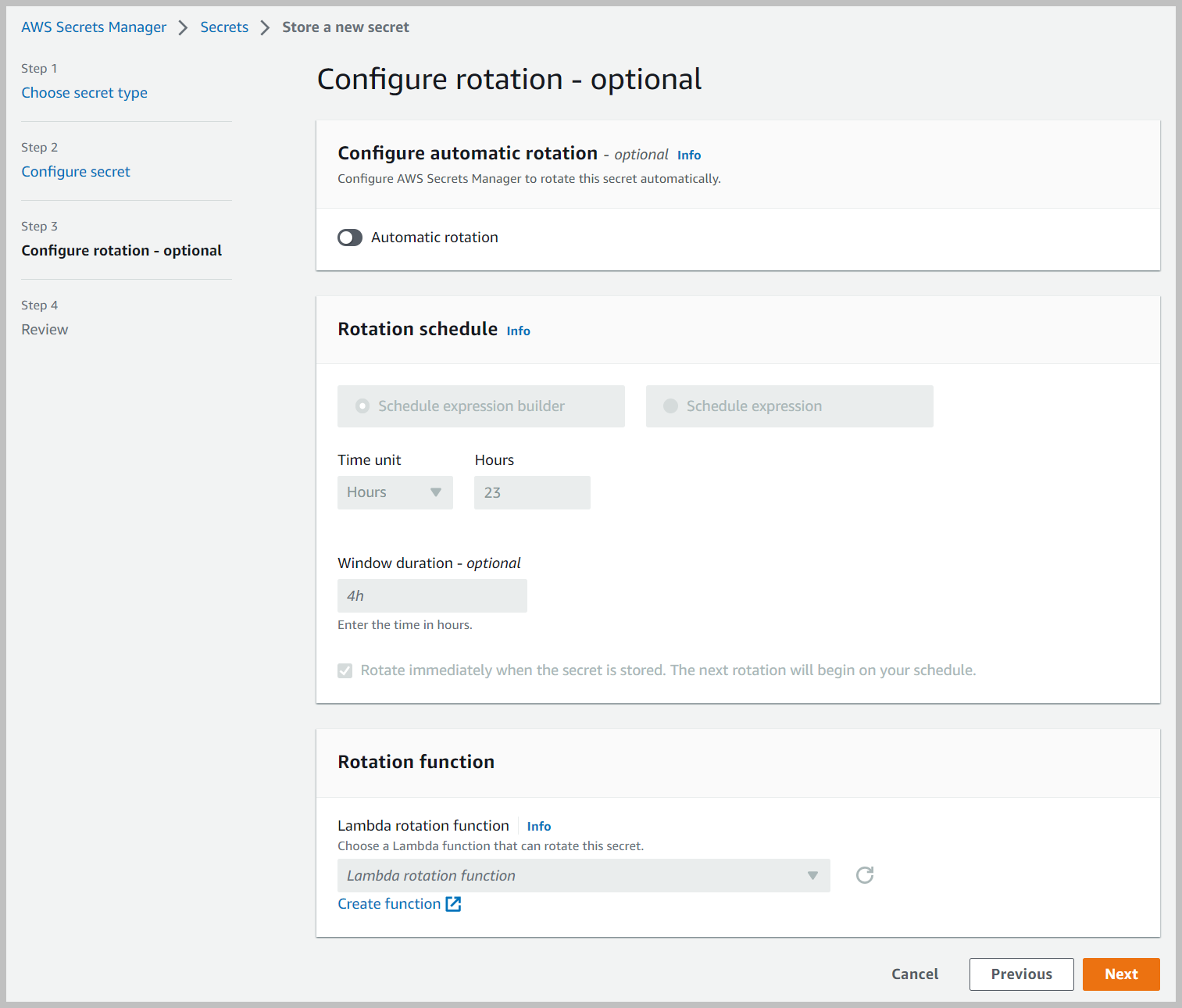
- En Revisar página, elige Tienda.
Configurar el conector de Amazon Kendra para Confluence
Para configurar el conector de Amazon Kendra, complete los siguientes pasos:
- En la consola de Amazon Kendra, elija Crear un índice.
- Nombre del índice, introduzca un nombre para el índice (por ejemplo,
my-confluence-index). - Introduzca una descripción opcional.
- Nombre de rol, introduzca un nombre de función de IAM.
- Configure los ajustes de cifrado y las etiquetas opcionales.
- Elige Siguiente.
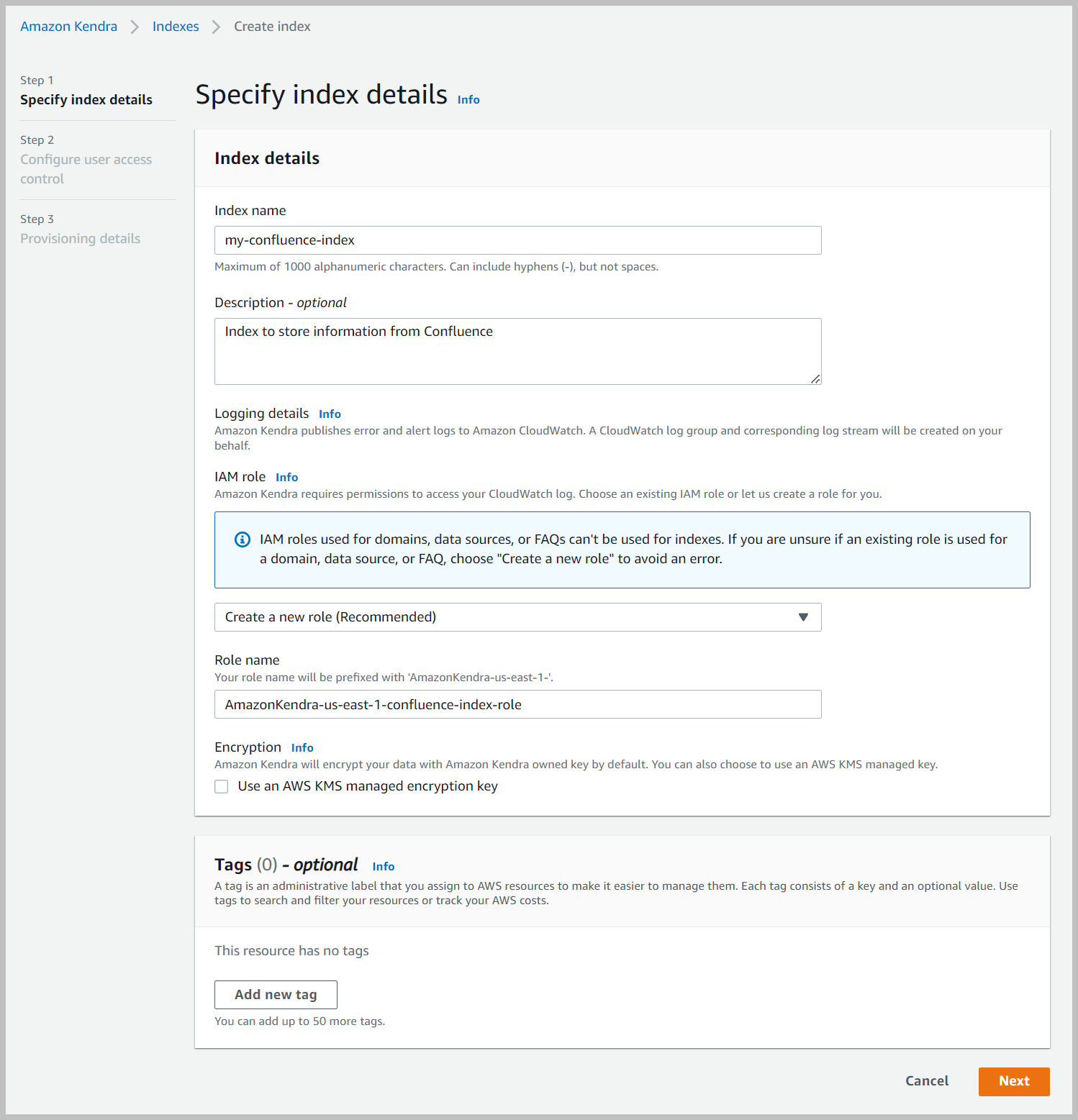
- En Configurar el control de acceso de usuarios sección, deje la configuración en sus valores predeterminados y elija Siguiente.
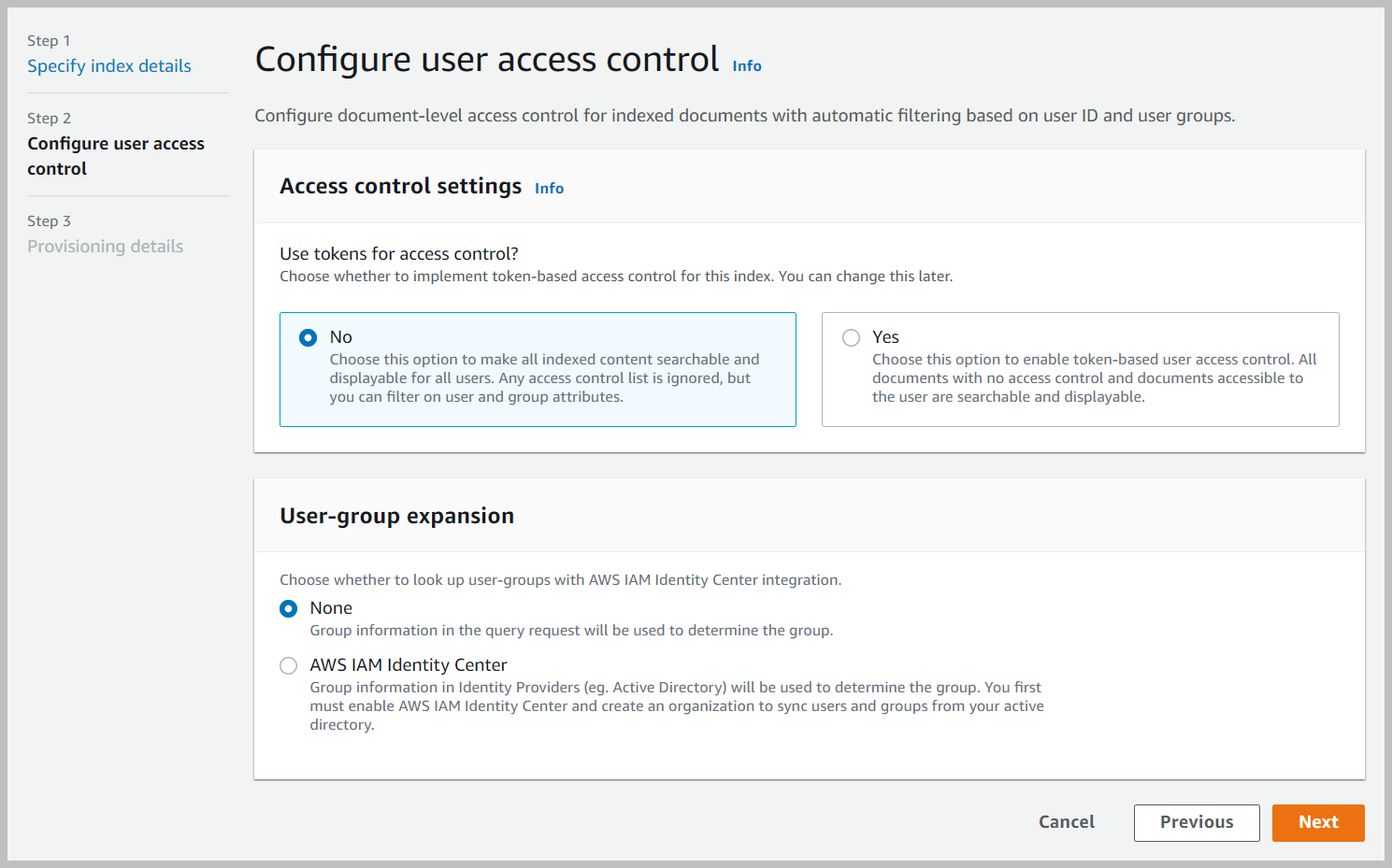
- En Especificar aprovisionamiento sección, seleccionar Edición para desarrolladores y elige Siguiente.
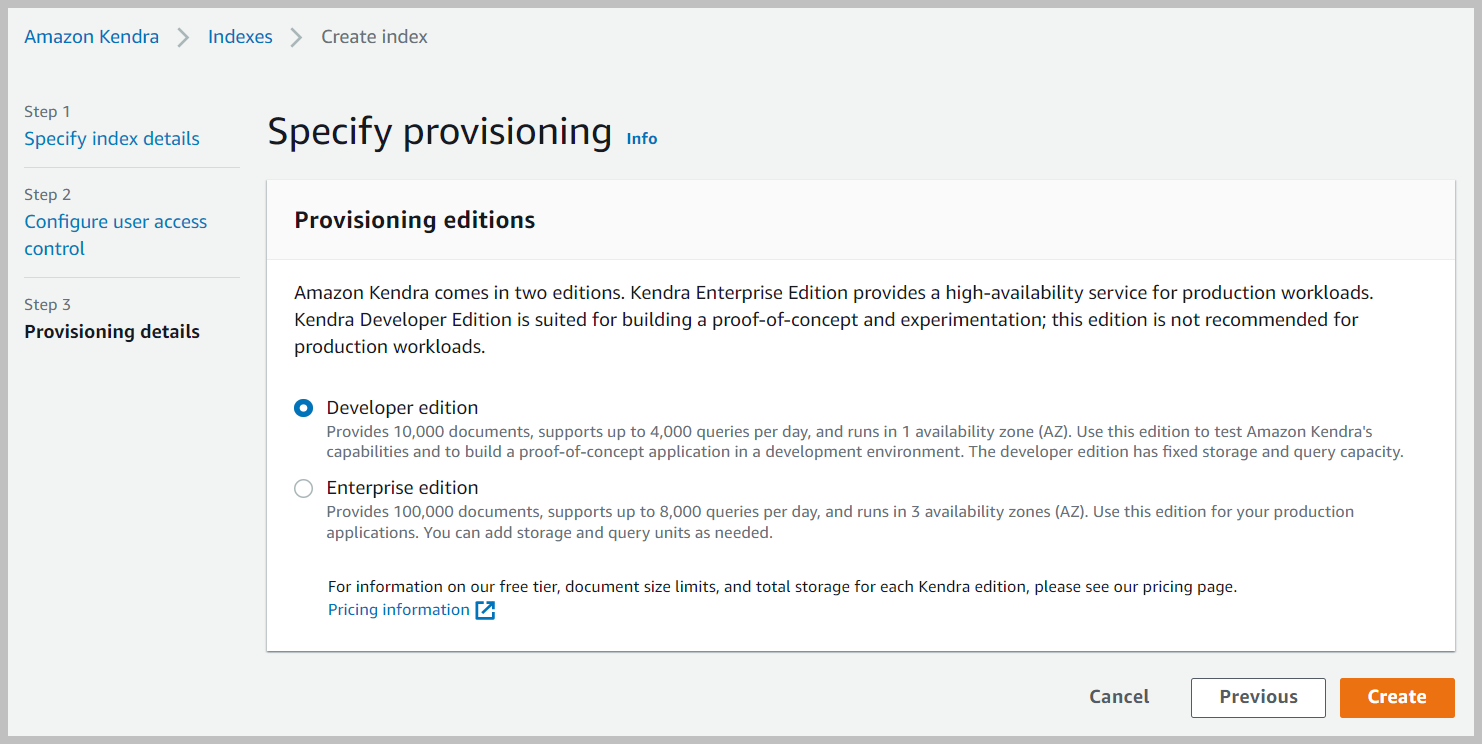
- En la página de revisión, elija Crear.
Esto crea y propaga el rol de IAM y luego crea el índice de Amazon Kendra, lo que puede demorar hasta 30 minutos.
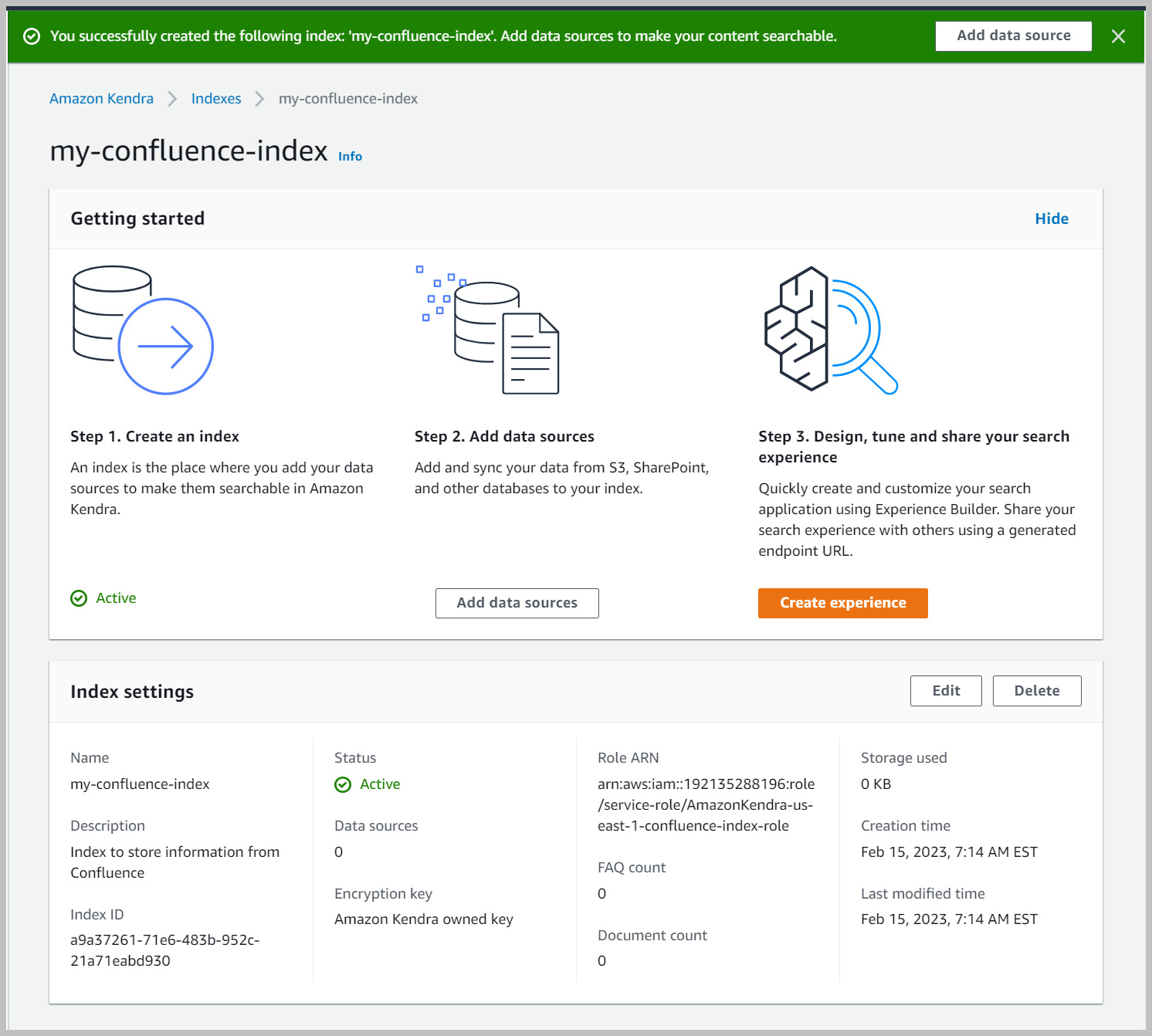
Crear una fuente de datos de Confluence
Complete los siguientes pasos para crear su fuente de datos:
- En la consola de Amazon Kendra, elija Fuentes de datos en el panel de navegación.
- under Conector de confluencia V2.0, escoger Agregar conector.
.
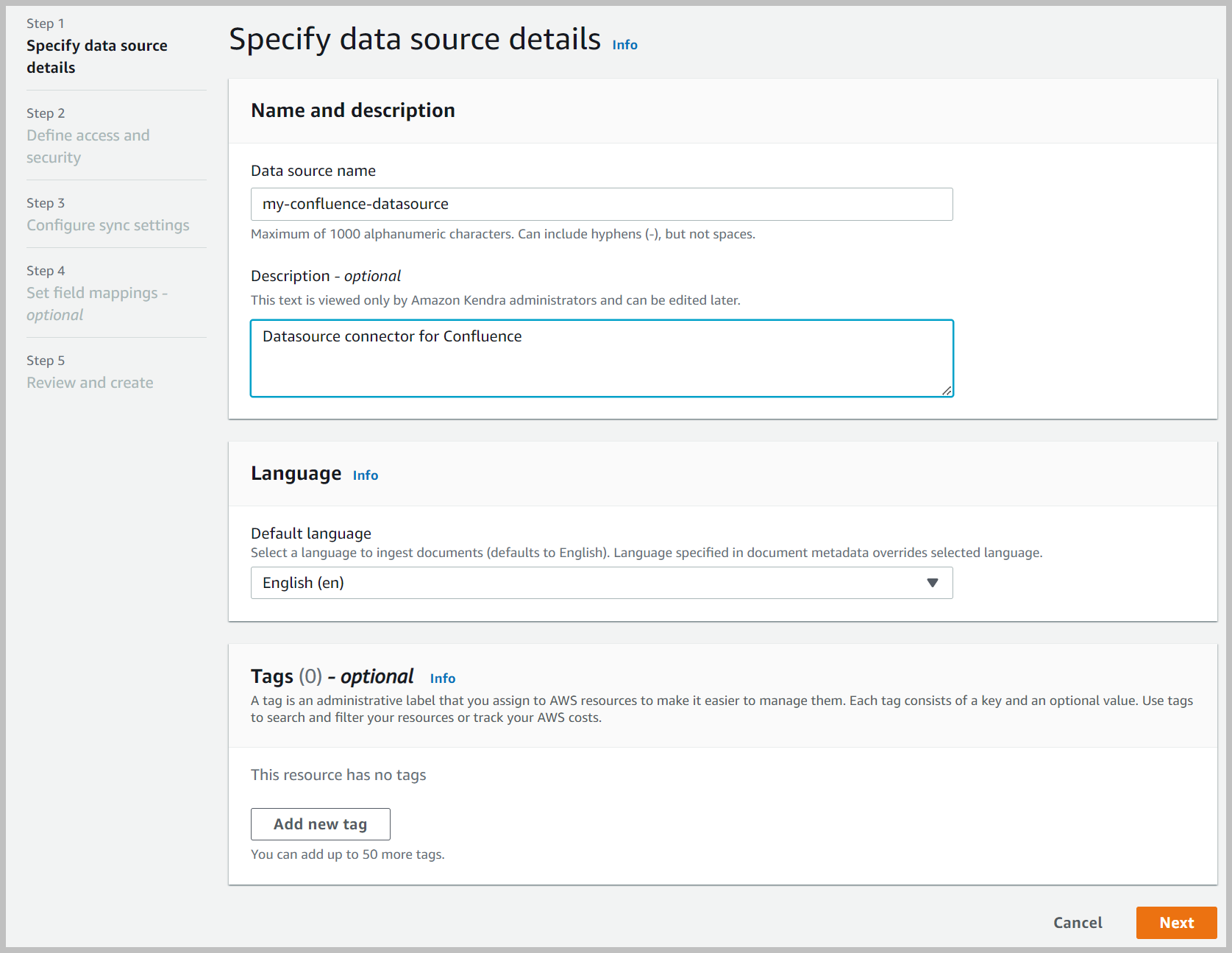
- Nombre de fuente de datos, ingrese un nombre (por ejemplo,
my-Confluence-data-source). - Introduzca una descripción opcional.
- Elige Siguiente.
- Elija cualquiera Nube de confluencia or Servidor de confluencia dependiendo de su fuente de datos.
- Autenticación, elija su opción de autenticación.
- Seleccione El rastreador de identidad está activado.
- Rol de IAMescoger Crear un nuevo rol.
- Nombre de rol, ingrese un nombre (por ejemplo,
AmazonKendra-my-confluence-datasource-role). - Elige Siguiente.
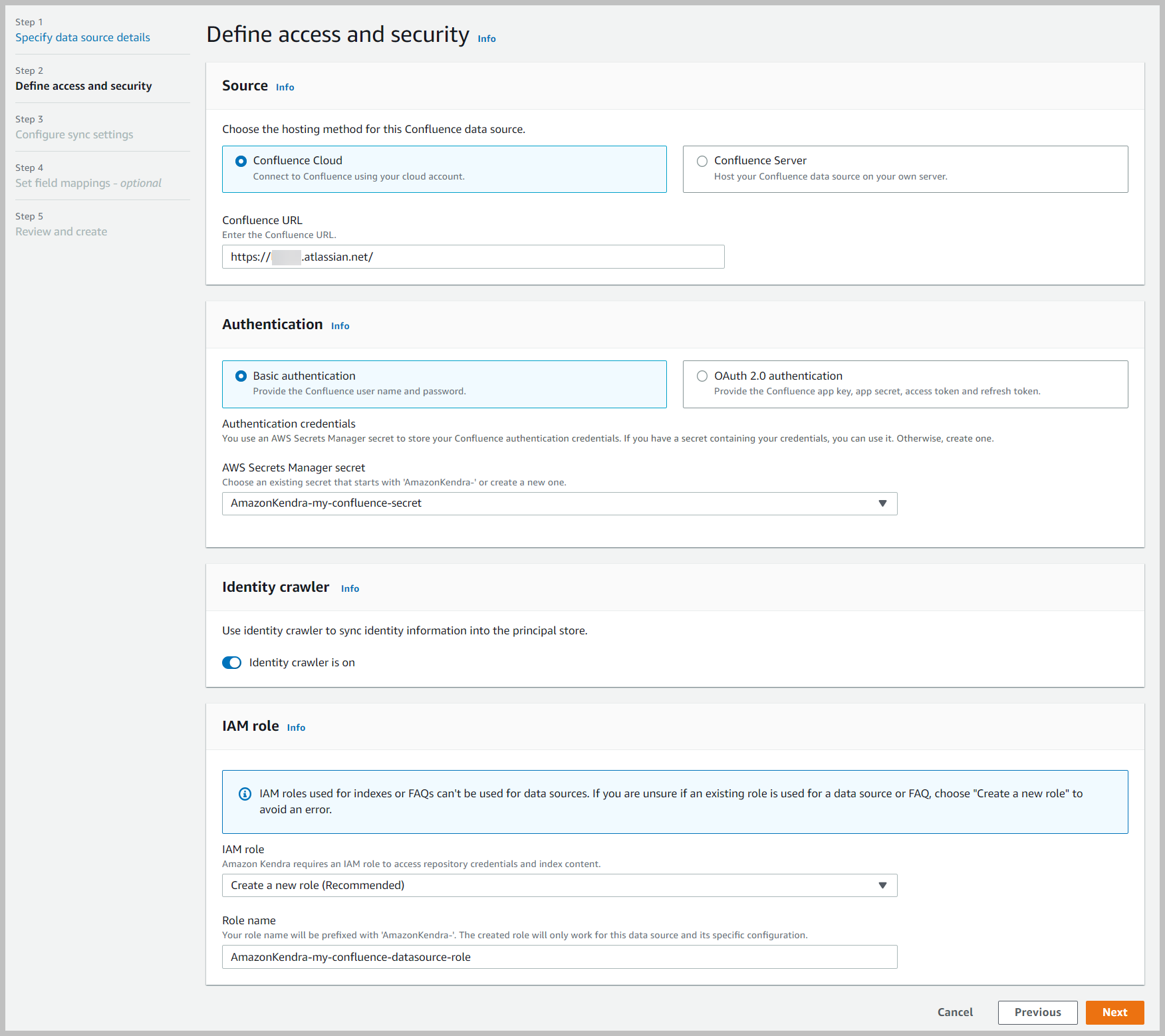
Para las ediciones Confluence Data Center y Cloud, podemos agregar información opcional adicional (no se muestra) como la VPC. Solo para la edición Data Center, podemos agregar información adicional para el proxy web. También hay una opción de autenticación adicional si se usa un token de acceso personal que es válido solo para Data Center y no para la edición Cloud.
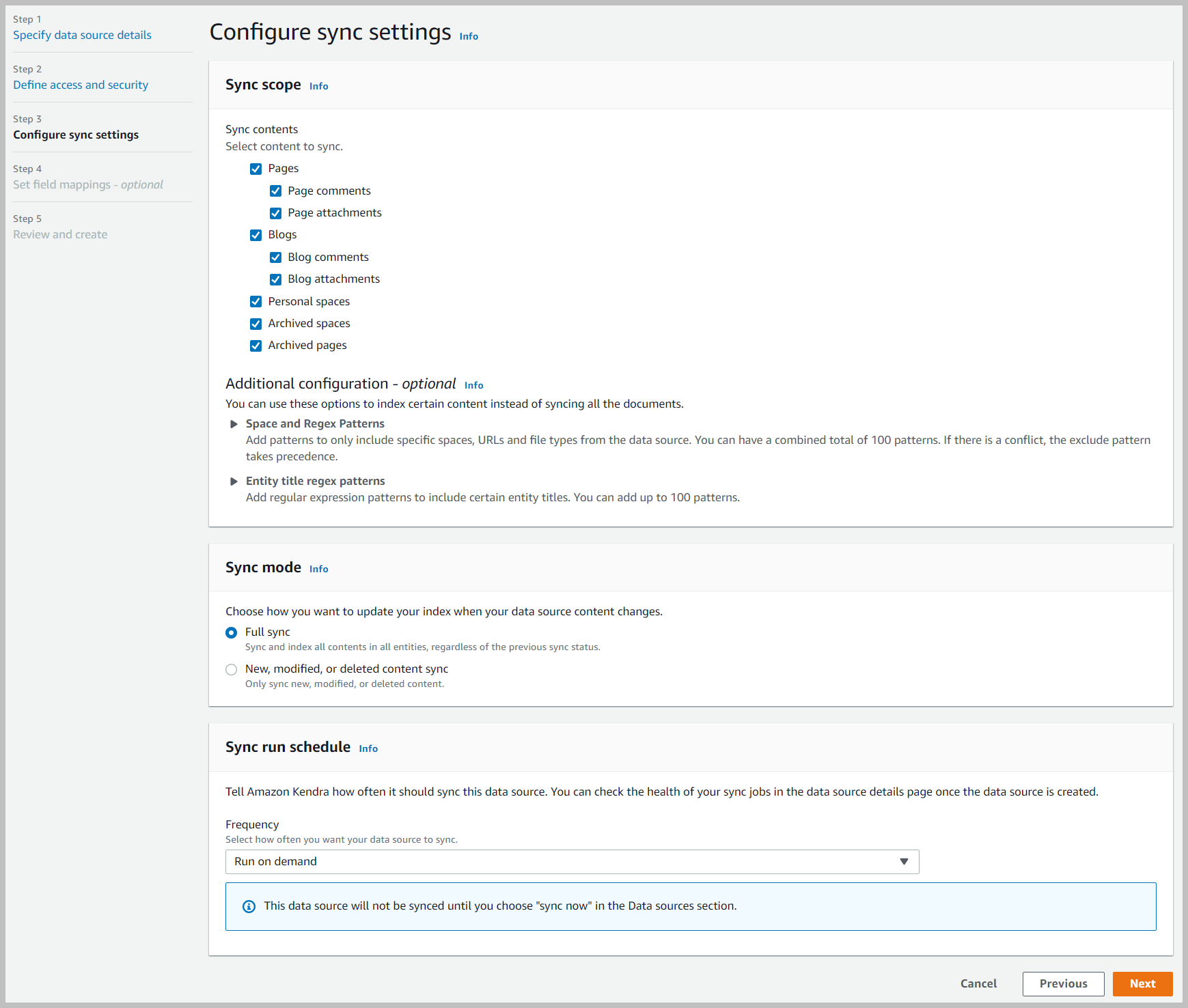
- Ámbito de sincronización, seleccione todo el contenido para sincronizar.
- Modo de sincronización, seleccione sincronización completa.
- Frecuencia, escoger Ejecutar bajo demanda.
- Elige Siguiente.
- Opcionalmente, puede establecer campos de mapeo.
La asignación de campos es un ejercicio útil en el que puede sustituir los nombres de los campos por valores que sean fáciles de usar y se ajusten al vocabulario de su organización.
- Para esta publicación, mantenga todos los valores predeterminados y elija Siguiente.
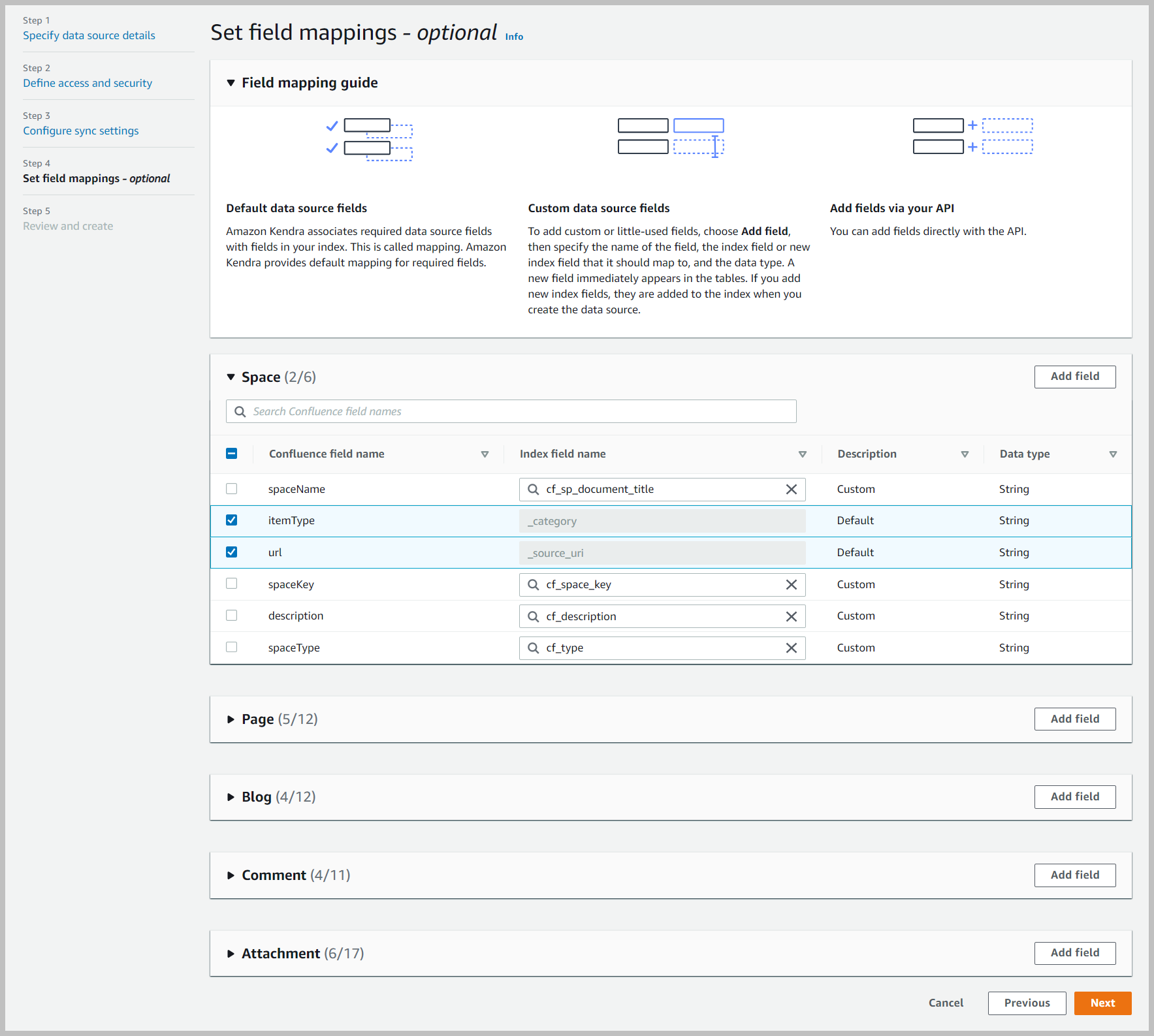
- Revise la configuración y elija Añadir fuente de datos.
- Para sincronizar la fuente de datos, seleccione Sincronizar ahora.
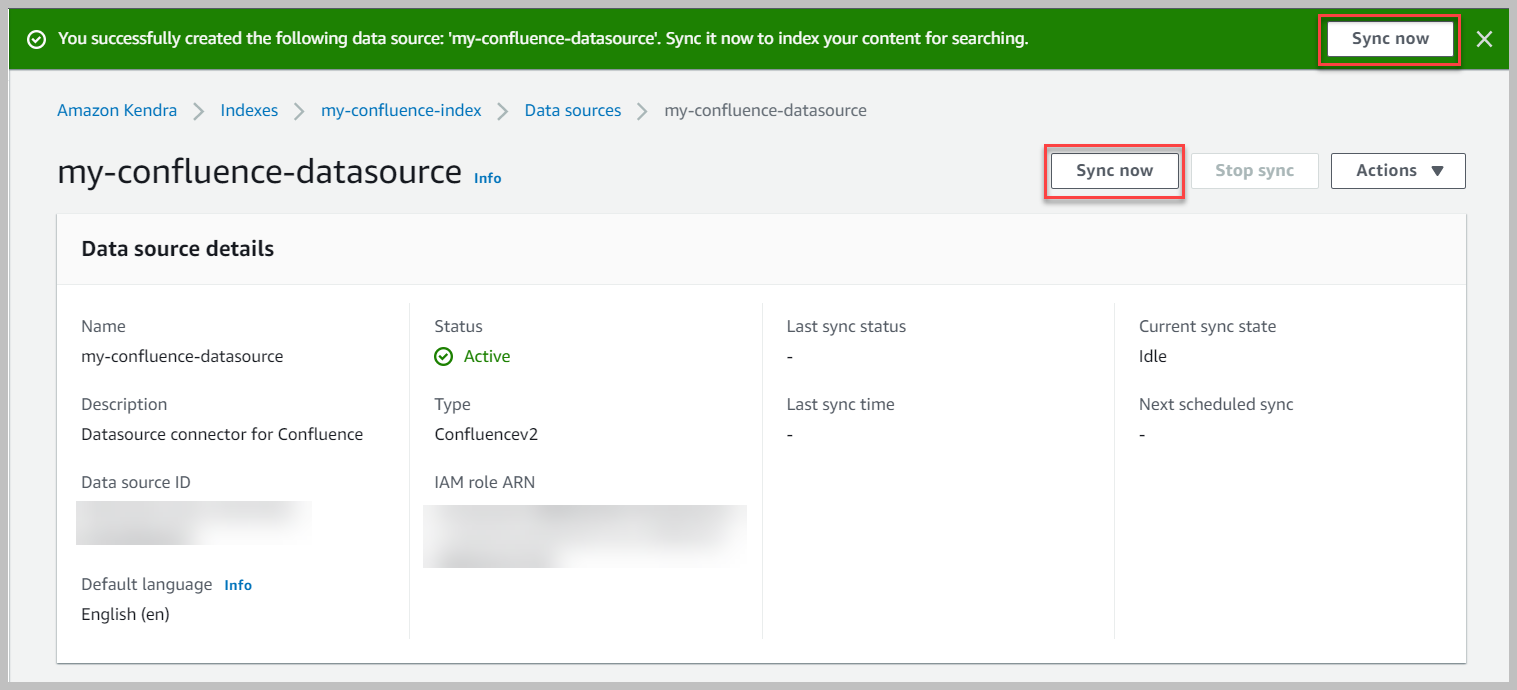
Aparece un mensaje de banner cuando se completa la sincronización.
Prueba la solución
Ahora que ha ingerido el contenido de su cuenta de Confluence en su índice de Amazon Kendra, puede probar algunas consultas. A los efectos de nuestra prueba, hemos creado un sitio web de Confluence con dos equipos: el equipo 1 con el miembro Analista 1 y el equipo 2 con el miembro Analista 2.
- En la consola de Amazon Kendra, navegue hasta su índice y elija Buscar contenido indexado.
- Ingrese una consulta de búsqueda de muestra y revise sus resultados de búsqueda (sus resultados variarán según el contenido de su cuenta).
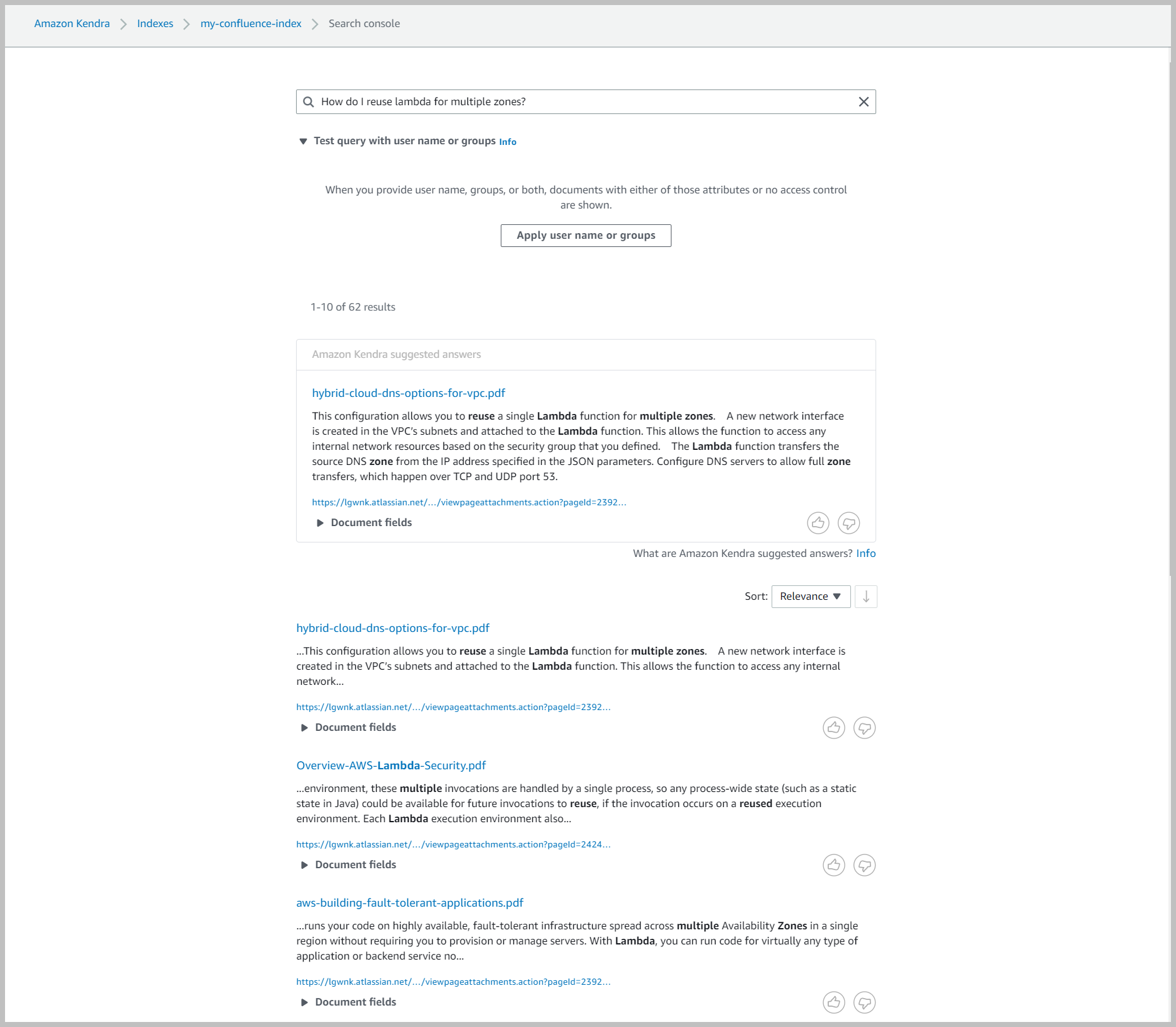
El conector de Confluence también rastrea información de identidad local de Confluence. Puede usar esta función para restringir su consulta por usuario. Confluence ofrece amplias opciones de visibilidad. Los usuarios pueden elegir su contenido para que lo vean otros usuarios, a nivel de espacio o por grupos. Cuando filtra sus búsquedas por usuarios, la consulta devuelve solo aquellos documentos a los que el usuario tiene acceso en el momento de la ingestión.
- Para usar esta función, expanda Consulta de prueba con nombre de usuario o grupos y elige Aplicar nombre de usuario o grupos.
- Ingrese el nombre de usuario de su usuario y elija Aplicá.
Tenga en cuenta que para la edición Confluence Data Center, el nombre de usuario es el ID de correo electrónico.
Vuelva a ejecutar su consulta de búsqueda.
Esto le trae un conjunto filtrado de resultados. Observe que traemos solo 62 resultados.
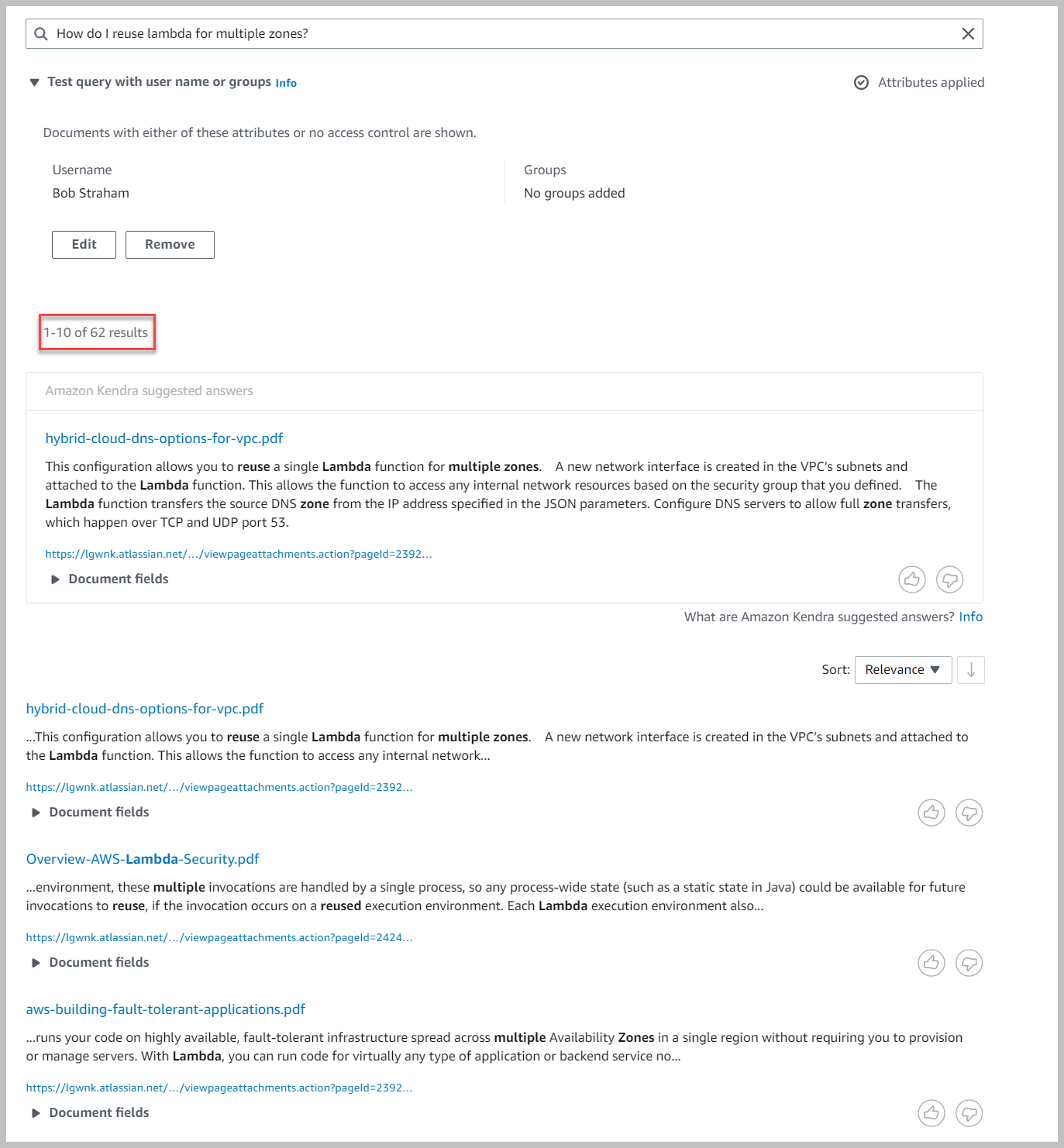
Ahora regresamos y restringimos a Bob Straham para que solo pueda acceder a su espacio de trabajo y ejecutar la búsqueda nuevamente.
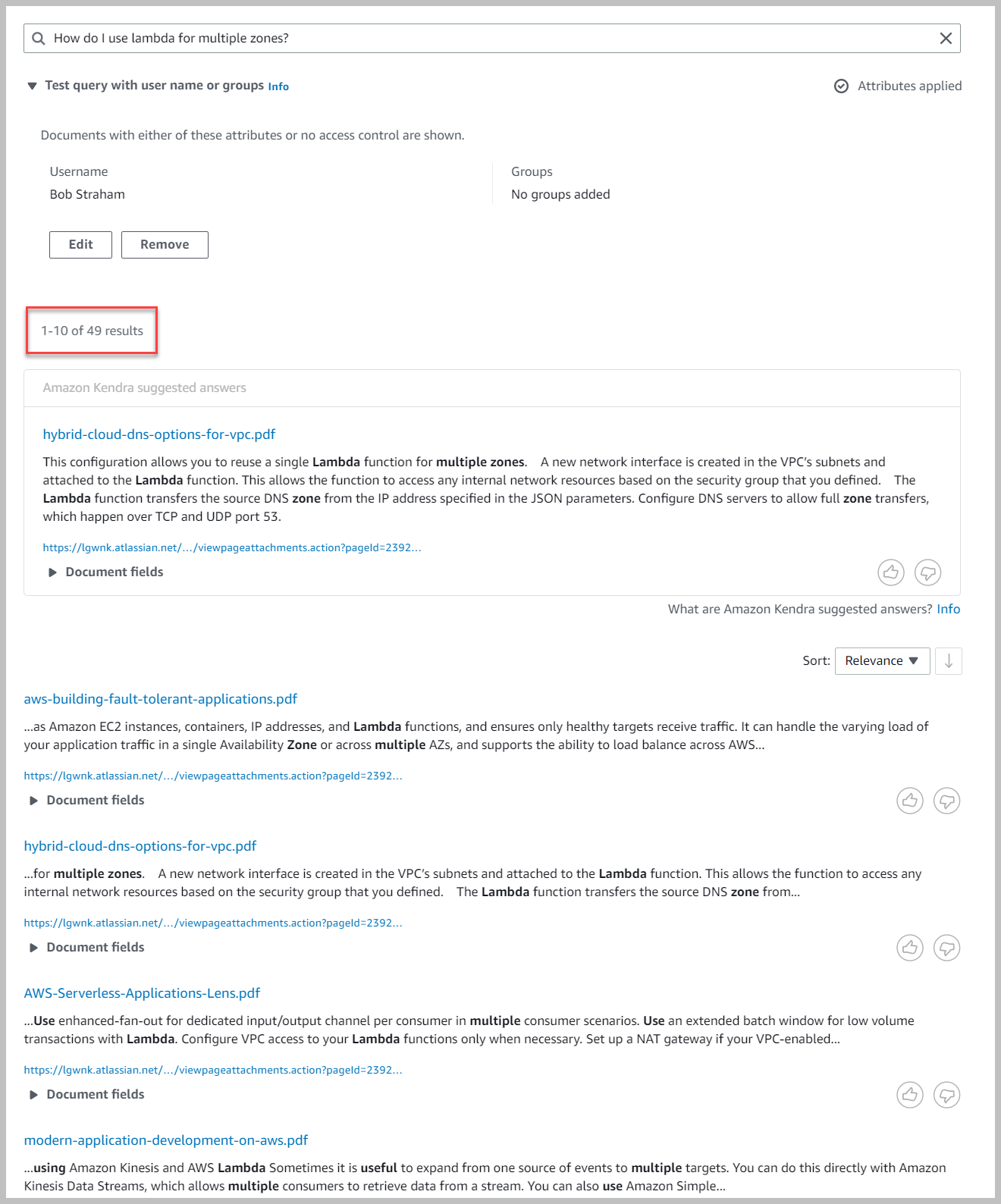
Tenga en cuenta que solo obtenemos un subconjunto de los resultados porque la búsqueda está restringida solo al contenido de Bob.
Al presentar Amazon Kendra con una aplicación, como una aplicación creada con Creador de experiencias, puede pasar la identidad del usuario (en forma de ID de correo electrónico para la edición Cloud o nombre de usuario para la edición Data Center) a Amazon Kendra para asegurarse de que cada usuario solo vea el contenido específico de su ID de usuario. Como alternativa, puede utilizar Centro de identidad de AWS IAM (sucesor de AWS Single Sign-On) para controlar el contexto del usuario que se pasa a Amazon Kendra para limitar las consultas por usuario.
¡Felicidades! Ha utilizado con éxito Amazon Kendra para mostrar respuestas e información basada en el contenido indexado desde su cuenta de Confluence.
Limpiar
Para evitar incurrir en costos futuros, limpie los recursos que creó como parte de esta solución. Si creó un nuevo índice de Amazon Kendra mientras probaba esta solución, elimínelo. Si solo agregó una nueva fuente de datos mediante el conector de Amazon Kendra para Confluence V2, elimine esa fuente de datos.
Conclusión
Con el nuevo conector Confluence V2 para Amazon Kendra, las organizaciones pueden acceder al repositorio de información almacenada en su cuenta de forma segura mediante la búsqueda inteligente con tecnología de Amazon Kendra.
Para obtener más información sobre estas posibilidades y más, consulte el Guía para desarrolladores de Amazon Kendra. Para obtener más información sobre cómo puede crear, modificar o eliminar metadatos y contenido al ingerir sus datos de Confluence, consulte Enriquecer sus documentos durante la ingestión y Enriquezca su contenido y metadatos para mejorar su experiencia de búsqueda con el enriquecimiento de documentos personalizados en Amazon Kendra.
Acerca del autor.
 Ashish Lagwankar es arquitecto sénior de soluciones empresariales en AWS. Sus principales intereses incluyen tecnologías de contenedores, AI/ML y sin servidor. Ashish vive en el área de Boston, MA, y disfruta leer, estar al aire libre y pasar tiempo con su familia.
Ashish Lagwankar es arquitecto sénior de soluciones empresariales en AWS. Sus principales intereses incluyen tecnologías de contenedores, AI/ML y sin servidor. Ashish vive en el área de Boston, MA, y disfruta leer, estar al aire libre y pasar tiempo con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/index-your-confluence-content-using-the-new-confluence-connector-v2-for-amazon-kendra/

