
Imagen de benzoix en Freepik
¿Qué es Pandas en realidad y por qué es tan famoso? Piense en Pandas como una hoja de Excel, pero una hoja de Excel de siguiente nivel con más funciones y flexibilidad que Excel.
Hay muchas razones para elegir pandas, algunas de ellas son
- Open Source
- Fácil de aprender
- Gran comunidad
- Construido sobre Numpy
- Fácil de analizar y preprocesar datos en él
- Visualización de datos incorporada
- Muchas funciones integradas para ayudar en el análisis exploratorio de datos
- Compatibilidad integrada con CSV, SQL, HTML, JSON, pickle, excel, portapapeles y mucho más
- y mucho más
Si está utilizando Anaconda, automáticamente tendrá pandas, pero por alguna razón, si no lo tiene, simplemente ejecute este comando
conda install pandas
Si no está utilizando Anaconda, instálelo a través de pip por
pip install pandas
Importador
Para importar pandas, use
import pandas as pd
import numpy as np
Es mejor importar numpy con pandas para tener acceso a más funciones numpy, lo que nos ayuda en el análisis exploratorio de datos (EDA).
Pandas tiene dos estructuras de datos principales.
- Serie
- Marcos de datos
Serie
Piense en Serie como una sola columna en una hoja de Excel. También puede pensar en ello como una matriz 1d Numpy. Lo único que lo diferencia de la matriz 1d Numpy es que podemos tener nombres de índice.
La sintaxis básica para crear una serie pandas es la siguiente:
newSeries = pd.Series(data , index)
Los datos pueden ser de cualquier tipo, desde el diccionario de Python hasta la lista o la tupla. También puede ser una matriz numpy.
Construyamos una serie a partir de Python List:
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
labels = ['Name', 'Career', 'Age', 'Country']
newSeries = pd.Series(mylist,labels)
print(newSeries)
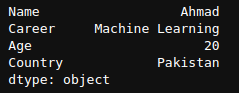
Salida de newSeries.
No es necesario agregar un índice en una Serie pandas. En ese caso, automáticamente iniciará el índice desde 0.
mylist = ['Ahmad','Machine Learning', 20, 'Pakistan']
newSeries = pd.Series(mylist)
print(newSeries)

Aquí podemos ver que el índice comienza desde 0 y continúa hasta el final de la Serie. Ahora veamos cómo podemos crear una Serie usando un Diccionario de Python,
myDict = {'Name': 'Ahmad', 'Career': 'Machine Learning', 'Age': 20, 'Country': 'Pakistan'}
mySeries = pd.Series(myDict)
print(mySeries)

Aquí podemos ver que no tenemos que pasar explícitamente los valores del índice, ya que se asignan automáticamente desde las claves del diccionario.
Acceder a los datos de la serie
El patrón normal para acceder a los datos de Pandas Series es
seriesName['IndexName']
Tomemos el ejemplo de mySeries que creamos anteriormente. Para obtener el valor de Nombre, Edad y Carrera, todo lo que tenemos que hacer es
print(mySeries['Name'])
print(mySeries['Age'])
print(mySeries['Career'])

Operaciones básicas en la serie Pandas
Vamos a crear dos nuevas series para realizar operaciones sobre ellas.
newSeries = pd.Series([10,20,30,40],index=['LONDON','NEWYORK','Washington','Manchester'])
newSeries1 = pd.Series([10,20,35,46],index=['LONDON','NEWYORK','Istanbul','Karachi'])
print(newSeries,newSeries1,sep='nn')
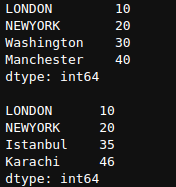
Las operaciones aritméticas básicas incluyen operaciones +-*/. Estos se realizan sobre el índice, así que vamos a realizarlos.
newSeries + newSeries1

Aquí podemos ver que, dado que el índice de Londres y el de NUEVA YORK están presentes en ambas series, se ha agregado el valor de ambos y la salida del resto es NaN (no es un número).
newSeries * newSeries1

newSeries / newSeries1

Element Wise Operations/Radiodifusión
Si está familiarizado con Numpy, debe conocer el concepto de transmisión. Referirse a este enlace si no está familiarizado con el concepto de radiodifusión.
Ahora, usando nuestra nueva Serie Serie, veremos operaciones realizadas usando el concepto de transmisión.
newSeries + 5

Aquí, agregó 5 a cada elemento individual en Series newSeries. Esto también se conoce como operaciones por elementos. Del mismo modo, para otras operaciones como *, /, -, ** y otros operadores también. Veremos solo el operador **, y debería probarlo también para otros operadores.
newSeries ** 1/2

Aquí, tomamos la raíz cuadrada de elementos de cada número. Recuerda, la raíz cuadrada es cualquier número elevado a la potencia 1/2.
Marco de datos de pandas
Dataframe es, de hecho, la estructura de datos más utilizada e importante de Pandas. Piense en un marco de datos como una hoja de Excel.
Las principales formas de crear marcos de datos son
- Lectura de un archivo CSV/Excel
- Diccionario de Python
- ndarray
Tomemos un ejemplo de cómo crear un marco de datos usando un diccionario.
Podemos crear un marco de datos pasando un diccionario donde cada valor del diccionario es una lista.
df1 = {"Name":["Ahmad","Ali",'Ismail',"John"],"Age": [20,21,19,17],"Height":[5.1,5.6,6.1,5.7]}
Para convertir este diccionario en un marco de datos, simplemente tenemos que llamar a la función de marco de datos en este diccionario.
df1 = pd.DataFrame(df1)
df1

df1
Obtener valores de una columna
Para obtener valores de una columna, podemos usar esta sintaxis
#df1['columnname']
#df1.columnname
Ambas sintaxis son correctas, pero debemos tener cuidado al elegir una. Si el nombre de nuestra columna tiene espacio, definitivamente no podemos usar el segundo método. Tenemos que usar el primer método. Solo podemos usar el segundo método cuando no hay espacio en el nombre de la columna.

df1.Nombre
Aquí podemos ver los valores de la columna, su número de índice, el nombre de la columna y el tipo de datos de la columna.
df1['Age']

df1['Edad']
Podemos ver que usar ambas sintaxis devuelve la columna del marco de datos donde podemos analizarlo.
Valores de varias columnas
Para obtener valores de varias columnas en un marco de datos, pase el nombre de las columnas como una lista.
df1[["Name","Age"]]

df1[[“Nombre”,”Edad”]]
Podemos ver que devolvió el marco de datos con dos columnas Nombre y Edad.
Exploremos funciones importantes de DataFrame usando un conjunto de datos conocido como 'Titanic'. Este conjunto de datos suele estar disponible en línea, o puede obtenerlo en Kaggle.
Leer datos
Pandas tiene un buen soporte integrado para leer datos de varios tipos, incluidos CSV, fether, excel, HTML, JSON, pickle, SAS, SQL y muchos más.
La sintaxis común para leer datos es
# pd.read_fileExtensionName("File Path")
CSV
Para leer datos de un archivo CSV, todo lo que tiene que hacer es usar la función pandas read_csv.
df = pd.read_csv('Path_To_CSVFile')
Dado que Titanic también está disponible en formato CSV, lo leeremos usando la función read_csv. Cuando descargue el conjunto de datos, tendrá dos archivos llamados train.csv y test.csv, que ayudarán a probar los modelos de aprendizaje automático, por lo que solo nos centraremos en el archivo train_csv.
df = pd.read_csv('train.csv')
Ahora df es automáticamente un marco de datos. Exploremos algunas de sus funciones.
cabeza()
Si imprime su conjunto de datos normalmente, mostrará un conjunto de datos completo, que puede tener un millón de filas o columnas, que es difícil de ver y analizar. La función df.head() nos permite ver las primeras 'n' filas del conjunto de datos (por defecto 5) para que podamos hacer una estimación aproximada de nuestro conjunto de datos y qué funciones importantes aplicar en él a continuación.

df.head ()
Ahora podemos ver nuestras columnas en el conjunto de datos y sus valores para las primeras 5 filas. Como no hemos pasado ningún valor, muestra las primeras 5 filas.
cola()
Similar a la función de cabeza, tenemos una función de cola que muestra la última n valores.
df.tail(3)

df. cola (3)
Podemos ver las últimas 3 filas de nuestro conjunto de datos, cuando pasamos df.tail(3).
forma()
La forma () es otra función importante para analizar la forma del conjunto de datos, lo cual es bastante útil cuando creamos nuestros modelos de aprendizaje automático y queremos que nuestras dimensiones sean exactas.
df.shape()
![]()
![]() df.forma()
df.forma()
Aquí podemos ver que nuestra salida es (891,12), que es igual a 891 filas y 12 columnas, lo que significa que en total tenemos 12 características o 12 columnas y 891 filas o 891 ejemplos.
Anteriormente, cuando usábamos la función df.tail(), el número de índice de nuestra última columna era 890 porque nuestro índice comenzaba desde 0, no desde 1. Si el número de índice comenzaba desde 1, entonces tendríamos un número de índice de la última columna como 891.
es nulo ()
Esta es otra función importante que se usa para encontrar los valores nulos en un conjunto de datos. Podemos ver en resultados anteriores que algunos valores son NaN, lo que significa "No es un número", y tenemos que lidiar con estos valores faltantes para obtener buenos resultados. isnull() es una función importante para manejar estos valores nulos.
df.isnull().head()
Estoy usando la función head para que podamos ver los primeros 5 ejemplos, no todo el conjunto de datos.

df.isnull().head()
Aquí, podemos ver que algunos valores en las columnas "Cabina" son verdaderos. Verdadero significa que el valor es NaN o falta. Podemos ver que esto no es claro de ver y entender, por lo que podemos usar la función sum() para obtener información más detallada.
sum ()
La función de suma se utiliza para sumar todos los valores en un marco de datos. Recuerde que Verdadero significa 1 y Falso significa 0, por lo que para obtener todos los valores Verdaderos devueltos por la función isnull(), podemos usar la función sum(). Vamos a ver.
df.isnull().sum()

df.isnull (). sum ()
Aquí, podemos ver que solo los valores faltantes están en las columnas de "Edad", "Cabina" y "Embarcado".
info ()
La función de información también es una función de pandas de uso común, que "Imprime un resumen conciso de un DataFrame".

df.info ()
Aquí, podemos ver que nos dice cuántas entidades no nulas tenemos, como en el caso de Edad, tenemos 714 entidades de tipo flotante64 no nulas. También nos habla del uso de la memoria, que en este caso es de 83.6 KB.
describir()
Describe también es una función súper útil para analizar los datos. Nos informa sobre las estadísticas descriptivas de un marco de datos, incluidas aquellas que resumen la tendencia central, la dispersión y la forma de la distribución de un conjunto de datos, excluyendo los valores.
df.describe()

df.describe ()
Aquí podemos ver algunos análisis estadísticos importantes de cada columna, incluida la media, la desviación estándar, el valor mínimo y mucho más. Lea más sobre esto en su documentación.
Este es también uno de los conceptos importantes y ampliamente utilizados tanto en Numpy como en Pandas.
Como sugiere el nombre, indexamos usando variables booleanas, es decir, Verdadero y Falso. Si el índice es Verdadero, muestra esa fila, y si el Índice es Falso, no muestra esa fila.
Nos ayuda mucho cuando intentamos extraer características importantes de nuestro conjunto de datos. Tomemos un ejemplo en el que solo queremos ver las entradas donde "Sexo" es "masculino". Veamos cómo vamos a abordar esto.
df["Sex"]=="male"
Esto devolverá una Serie de valores booleanos Verdadero y Falso, donde Verdadero es la fila donde "Sexo" es "masculino", de lo contrario, Falso.
Para ver solo los primeros 10 resultados, puedo usar la función de cabeza como
(df["Sex"]=="male").head(10)
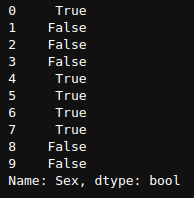
(df[“sexo”]==”masculino”).head(10)
Ahora, para ver el marco de datos completo con solo aquellas filas donde "Sexo" es "masculino", debemos pasar df["Sexo"]=="masculino" en el marco de datos para obtener todos los resultados donde "Sexo" es "masculino". ”.
df[df["Sex"]=="male"].head(5)

Aquí, podemos ver que todos los resultados que tenemos son aquellos en los que Sex es Male.
Ahora obtengamos información útil utilizando la indexación booleana.
Para obtener filas basadas en múltiples condiciones, usamos paréntesis “()” y signos “&,|,!=” entre múltiples condiciones.
Averigüemos cuál es el porcentaje de todos los pasajeros masculinos que han sobrevivido.
df[(df["Sex"]=="male") & (df["Survived"]==1)]

Dale a este código un segundo para leer y comprender lo que está sucediendo. Estamos recopilando todas las filas del marco de datos donde df[“Sexo”] == “masculino” y df[“Sobrevivido”]==1. El valor devuelto es un marco de datos con todas las filas de pasajeros masculinos que sobrevivieron.
Averigüemos el porcentaje de pasajeros masculinos que sobrevivieron.
Ahora, la fórmula para el porcentaje de pasajeros masculinos que sobrevivieron es Número total de hombres sobrevivientes / Número total de pasajeros masculinos

En pandas, podemos escribir esto como
men = df[df['Sex']=='male']['Survived']
perc = sum(men) / len(men) * 100
Vamos a descifrar este código paso a paso.
df['Sex']=='male' devolverá una serie booleana de ejemplos donde el sexo es masculino.
df[df[“Sexo”]==”masculino”] devolverá el marco de datos completo con todos los ejemplos donde “Sexo” es “masculino”.
men = df[df['Sex']=='male']['Survived'] devolverá la columna "Sobrevividos" del marco de datos de todos los pasajeros que son hombres.
sum(men) sumará todos los hombres que sobrevivieron. Como es una serie de 0 y 1, len(men) devolverá el número total de hombres.
Ahora póngalos en la fórmula dada arriba y encontraremos el porcentaje de todos los hombres que sobrevivieron en el Titanic, que es
![]()
![]()
18%!!!!!. Sí, solo el 18 % de los hombres de nuestro conjunto de datos han sobrevivido al desastre del Titanic.
Del mismo modo, podemos codificarlo para mujeres, que no lo haré, pero es su tarea, descubrimos que el 74 % de las pasajeras han sobrevivido a este desastre.
Esto nos lleva al final de este artículo. Ahora, obviamente, hay toneladas de otras funciones importantes en Pandas que son muy importantes, como agrupar, aplicar, iloc, renombrar, reemplazar, etc. Le recomiendo que consulte la “Python para análisis de datos” libro de Wes, quien es el creador de esta biblioteca de Pandas.
Además, la salida esta hoja de trucos por Dataquest para una referencia rápida.
Ahmad está interesado en Machine Learning, Deep Learning y Computer Vision. Actualmente trabajo como ingeniero de Machine Learning Jr. en Redbuffer.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2020/06/introduction-pandas-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-pandas-for-data-science

